论文作者信息:Changhao Miao, Yuntian Zhang, Tongyu Wu, Fang Deng, and Chen Chen. 2024. Deep Reinforcement Learning for Multi-Period Facility Location:
p
k
p_{k}
pk-median Dynamic Location Problem. In The 32nd ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL ’24), October 29-November 1, 2024, Atlanta, GA, USA. ACM, New York, NY, USA, 11 pages.
推文作者:缪昌昊
编者按
本论文于2024年被第32届ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL 2024) 录用为长文并应邀做口头报告,首次将深度强化学习方法应用于求解多周期设施选址问题。本论文针对多周期设施选址的复杂时空特性,提出了一种基于动态注意力网络的深度强化学习方法,可以同时捕捉问题的空间特征与时间特征。该方法采用了编码器-解码器的架构,并引入了门控循环单元对动态信息进行编码。实验表明,所提出的方法能够快速求解大规模多周期设施选址问题,在求解速度上比精确求解器Gurobi快2个数量级且拥有良好的泛化性能。
1. 背景
近十年来,随着城市化的快速发展,城市中的基础设施规模急剧扩张。如图1所示,从2005年到2022年,北京市海淀区的应急服务设施规模呈现出快速扩张的趋势。随着设施数量的增加,城市将面临着各种各样的挑战,例如交通堵塞、设施老化以及设施开设等问题。出现这些问题的原因在于城市空间利用不合理、资源配置不均衡、交通规划不完善,上述问题均对城市的规划带来了重大挑战。为了保证城市的可持续发展,空间优化(Spatial Optimization)侧重于利用数学计算方法更好地解决地理决策问题,以实现更高效的城市规划和管理。
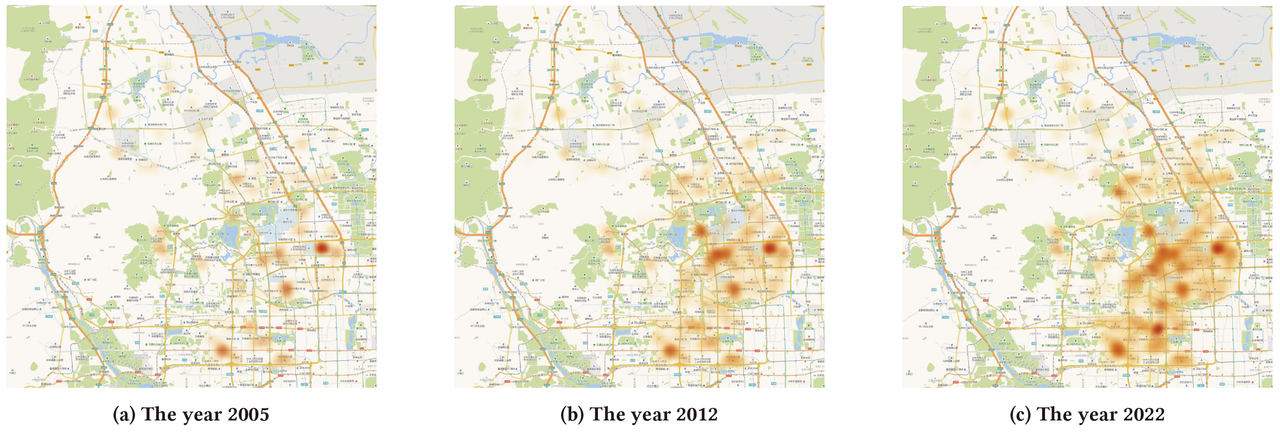
图1: 2005年、2012年和2022年(从左至右)北京市海淀区的应急服务设施分布密度图
设施选址问题(Facility Location Problem, FLP)是空间优化中一个经典且关键的问题,在供应链网络、物流配送、应急管理、泛在传感器网络等诸多实际场景中有着广泛的应用。设施选址问题主要被分为单周期问题和多周期问题。单周期问题通常假设某些问题参数保持不变,即使它们在实际应用中可能是动态变化的。在参数可预测的前提下,考虑未来参数的潜在变化通常对决策是有帮助的,因此多周期设施选址问题(Multi-period FLP)往往更加符合实际应用的需求。
与此同时,由于多周期设施选址问题的参数会随着周期动态变化,该问题的求解是一项艰巨的任务。在相关研究中,多周期设施选址问题的求解方法主要分为两大类:精确方法和启发式方法。精确方法往往通过建模技巧和分支定界框架来寻找问题的最优解,而在处理大规模问题时,该方法的计算代价会十分昂贵。因此,人们提出了启发式方法,其能够在可接受的时间内提供满意的解决方案。然而,启发式方法严重依赖于复杂的手工设计,忽略了周期之间的时间相关性,从而导致算法性能不理想。与此同时,对于大规模的多周期设施选址问题,其决策变量数目和搜索空间均十分庞大,这一特点给精确方法和启发式方法都带来了巨大的挑战。
随着人工智能技术的兴起,深度学习的发展为空间优化问题的求解提供了新的思路。尽管深度学习在路由问题中已经得到了广泛的应用,但与设施选址问题相关的研究仍然较少,且大部分研究更多地关注于单周期设施选址问题。相对于单周期设施选址问题,多周期设施选址问题的一大难点在于,当前周期期的最佳决策可能不是下一周期期的最佳决策。为了解决这一问题,作者提出了一种基于动态注意力网络(Attention-Dynamic Network, ADNet)的深度强化学习方法,用于求解多周期设施选址问题中 p k p_k pk-中值动态选址问题( p k p_k pk-median Dynamic Location Problem, DLP- p k p_k pk)。该方法能够有效地考虑周期之间的时间相关性,并捕捉问题的空间特征与时间特征,快速提供高质量的解决方案。下面将对DLP- p k p_k pk的数学模型和所提出的算法流程进行介绍。
2. 问题建模
在多周期的设施选址问题中,运输成本和开设成本会随着周期的不同而变化,因此多周期设施选址问题的决策变量数目非常庞大。与此同时,决策过程中不仅需要考虑备选点的静态信息,还需要考虑它们在时间尺度上的相互关系。图2给出了一个具有10个备选点和3个周期的问题示例,其中每个周期运营的设施数量分别为1、3和5个。由图中可以发现,每个周期中设施的运营数量以及设施与客户之间的分配关系均会随着周期的变化而变化。
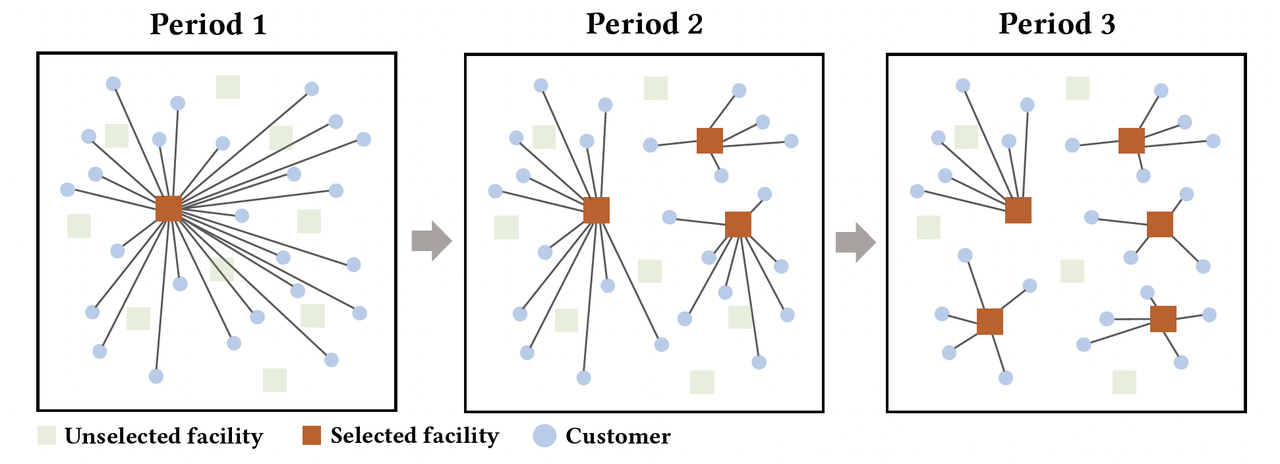
图2: 拥有10个备选点和3个周期,且pk = 1, 3, 5的pk-中值动态选址问题示例
DLP- p k p_k pk问题的目标是使运输成本与开设成本的总和最小,且在每个周期中仅考虑设施的开设而不考虑设施的关闭。考虑一个顾客点集 J J J,其中的每个顾客点 j ∈ J j \in J j∈J都拥有对应的需求,且该需求需要由运营中的设施来满足。这些设施在一个有限的多周期时间跨度 ∣ K ∣ |K| ∣K∣内运营,其中 K K K代表周期集合。考虑一个设施备选点集合 I I I,该集合为顾客点集 J J J的子集,其中每个备选点 i ∈ I i \in I i∈I均可以开设设施。对于每个周期 k ∈ K k \in K k∈K,指定数量 p k p_k pk个设施必须处于运营状态。DLP- p k p_k pk问题的数学化表达如下所示:
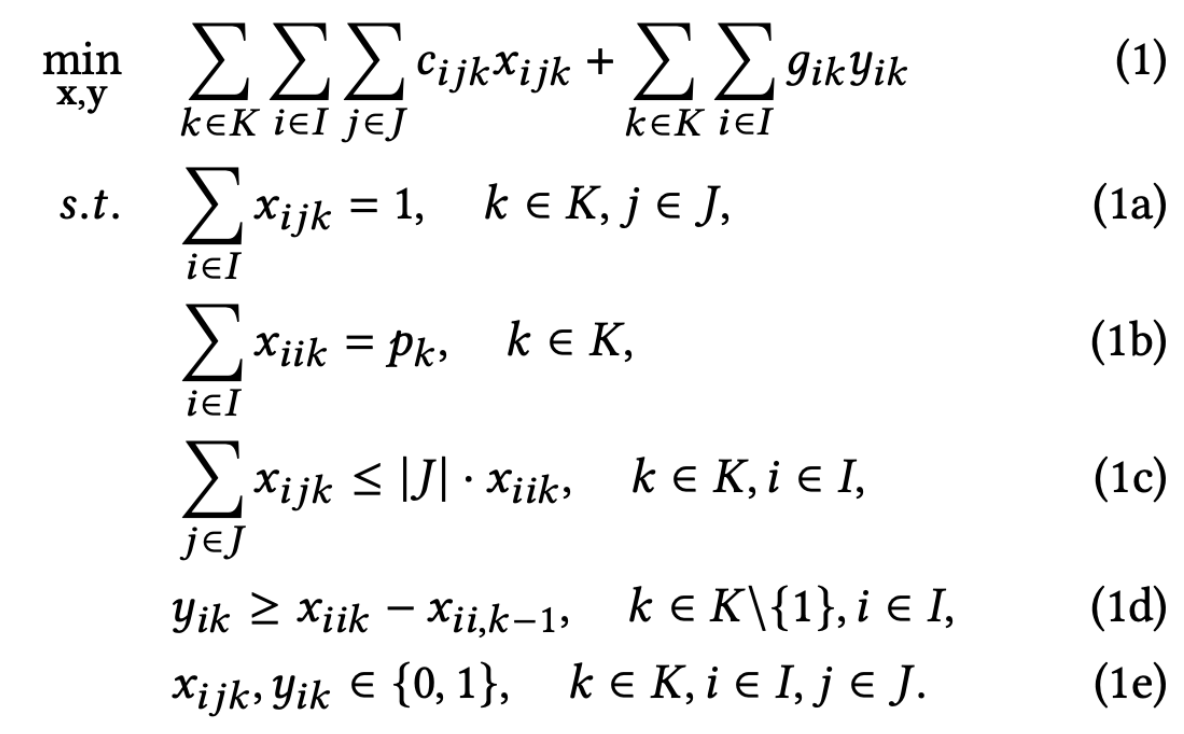
其中 x i j k x_{ijk} xijk和 y i k y_{ik} yik为决策变量,如果客户 j j j在 k k k时期由设施 i i i提供服务,则决策变量 x i j k = 1 x_{ijk} = 1 xijk=1,否则为0;如果设施 i i i在周期 k k k内被打开,则决策变量 y i k = 1 y_{ik} = 1 yik=1,否则为0; c i j k c_{ijk} cijk表示在周期 k k k由设施 i i i服务客户 j j j的运输成本; g i k g_{ik} gik表示设施 i i i在周期 k k k的开设费用。需要注意的是 x i i k = 1 x_{iik} = 1 xiik=1表示设施 i i i在周期 k k k是运营中的,而与是否在周期 k k k开设无关。另外,假设客户集合 J J J和备选设施点集合 I I I相同,即 I = J I= J I=J。由于 x i j k x_{ijk} xijk和 y i k y_{ik} yik为决策变量,可以通过公式 D = ∣ I ∣ × ∣ J ∣ × ∣ K ∣ + ∣ I ∣ × ∣ K ∣ D=|I|\times|J|\times|K|+|I|\times|K| D=∣I∣×∣J∣×∣K∣+∣I∣×∣K∣来计算决策变量的维数,以此来反映问题的复杂性。在上述数学化表达中,目标函数(1)旨在使所有周期内的运输成本与开设成本总和最小化;约束(1a)保证每个客户的需求在每个周期由有且仅有一个设施来提供;约束(1b)限制了在周期 k k k运营的设施数量为 p k p_k pk;约束(1c)表明只有运营中的设施能够为客户提供服务;约束(1d)确保了设施 i i i在周期 k k k打开时满足 y i k = 1 y_{ik} = 1 yik=1。
3. 算法流程
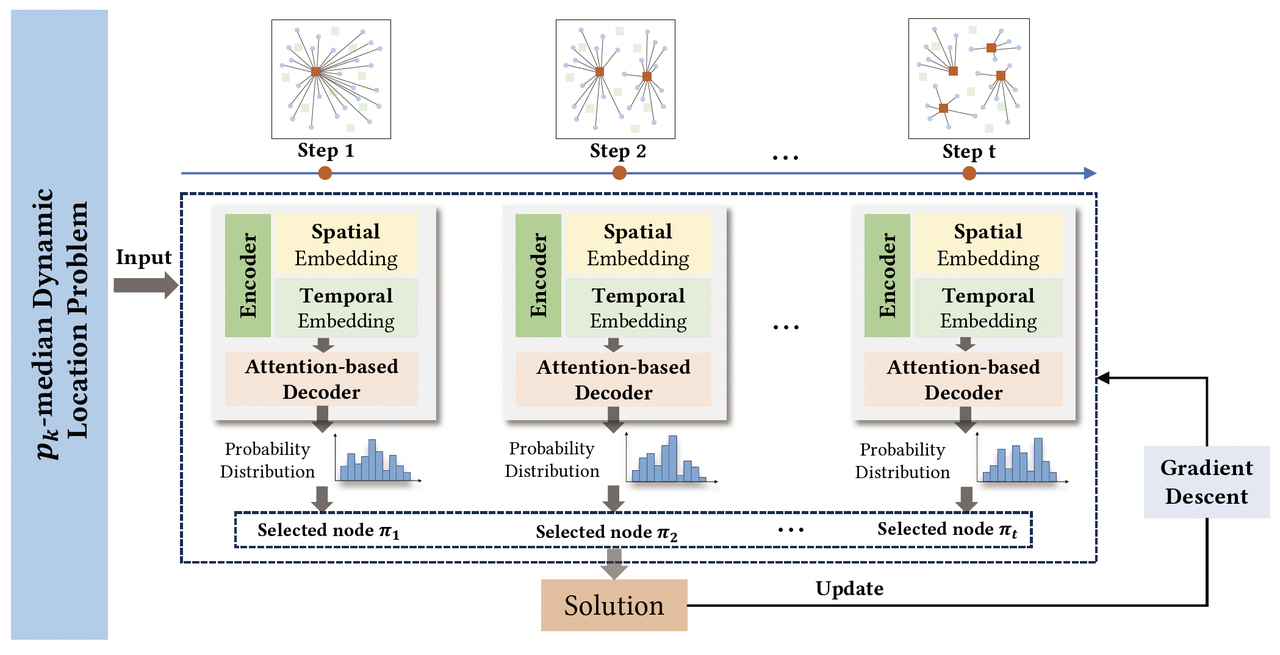
图3: 所提出算法的流程图
为了将深度强化学习方法应用于问题的求解,本节中首先将数学模型重新表示为马尔可夫决策过程的形式,并对ADNet的具体网络结构和训练流程进行介绍。作者所提出算法的流程图如图3所示。
3.1 马尔可夫决策过程
为了应用深度强化学习对问题进行求解,作者采用了构造(Construction)的形式对DLP- p k p_k pk问题进行建模,将其转化为马尔可夫决策过程的形式。作者引入了一个五元组表示形式,包括了状态、动作、转移、奖励和折扣因子。假设整个过程总共需要选择 p p p个节点,且每一步选择一个节点,选择 p p p个节点后便停止。在整个构造过程中,第 t t t步的五元组定义如下:
- 状态:当前步的解集被定义为状态 s t s_t st,其中 s t s_t st包含到第 t t t步为止所选择的所有设施点。具体而言, s t s_t st在第 t = p t=p t=p步之前始终是一个部分解,而 s 0 s_0 s0是一个空集。
- 动作:在解的构造过程中,每一步都需要从备选点中选择一个节点 π t \pi_t πt作为设施点。因此,第 t t t步的动作 a t a_t at被定义为 π t \pi_t πt。
- 转移:表示从状态 s t s_t st转移到下一个状态 s t + 1 s_{t+1} st+1时采取动作 a t a_t at的概率分布。
- 奖励:状态 s t s_t st转移到状态 s t + 1 s_{t+1} st+1时采取动作 a t a_t at所获得的即时奖励 r t r_t rt,它决定了策略的优化方向。
- 折扣因子:折扣因子
γ
\gamma
γ是一个0到1之间的值,它决定了未来奖励的重要程度,在本文中最后的奖励是直接由目标函数获得的。
由于每个周期内运营的设施数量是事先给定的,问题的解可以被看作是设施点的排列。因此,问题的解可以被表示为 π = { π 1 , . . . , π p , p ≤ n } \pi=\{\pi_1,...,\pi_p,p\leq n\} π={π1,...,πp,p≤n},其中 p p p为最后一个周期需要运营的设施总数,也即总共需要开设的设施数量, n n n为备选点总数。对于一个给定算例 s s s,ADNet定义了一个策略 p θ ( π ∣ s ) p_\theta (\pi|s) pθ(π∣s)来表示每一步选择节点 π \pi π的策略,其中 θ \theta θ表示ADNet的网络参数。
p
θ
(
π
∣
s
)
=
∏
t
=
1
p
p
θ
(
π
t
∣
s
,
π
1
∼
t
−
1
)
,
p
≤
n
(
2
)
p_\theta(\pi|s)=\prod \limits_{t=1}^p p_\theta (\pi_t|s,\pi_{1\sim t-1}),p\leq n\qquad(2)
pθ(π∣s)=t=1∏ppθ(πt∣s,π1∼t−1),p≤n(2)
为了使用REINFORCE算法训练ADNet,需要定义损失函数
L
(
θ
∣
s
)
=
E
p
θ
(
π
∣
s
)
[
L
(
π
)
]
L(\theta|s)=E_{p_{\theta(\pi|s)}}[L(\pi)]
L(θ∣s)=Epθ(π∣s)[L(π)],其表示代价函数
L
(
π
)
L(\pi)
L(π)的期望。具体而言,DLP-
p
k
p_k
pk问题的代价函数
L
(
π
)
L(\pi)
L(π)可以被定义为
L
(
π
)
=
∑
t
∈
T
∑
i
∈
I
∑
j
∈
J
c
i
j
t
x
i
j
t
+
∑
t
∈
T
∑
i
∈
I
g
i
t
z
i
t
′
(
3
)
L(\pi)=\sum_{t \in T} \sum_{i \in I} \sum_{j \in J} c_{i j t} x_{i j t} + \sum_{t \in T} \sum_{i \in I}g_{it}z_{it}^\prime \qquad (3)
L(π)=t∈T∑i∈I∑j∈J∑cijtxijt+t∈T∑i∈I∑gitzit′(3)
REINFORCE算法采用梯度下降法对参数迭代更新,并直接以最小化代价函数为优化目标。
3.2 ADNet网络结构
ADNet采用了编码器-解码器架构来更好地处理问题特征。编码器负责将所有输入节点的原始特征转换为隐藏编码,而解码器负责一次一个节点地生成节点序列。因此,解码器将编码后的隐藏编码作为输入,并输出下一个节点被选中的概率分布。ADNet模型的网络结构如图4所示。
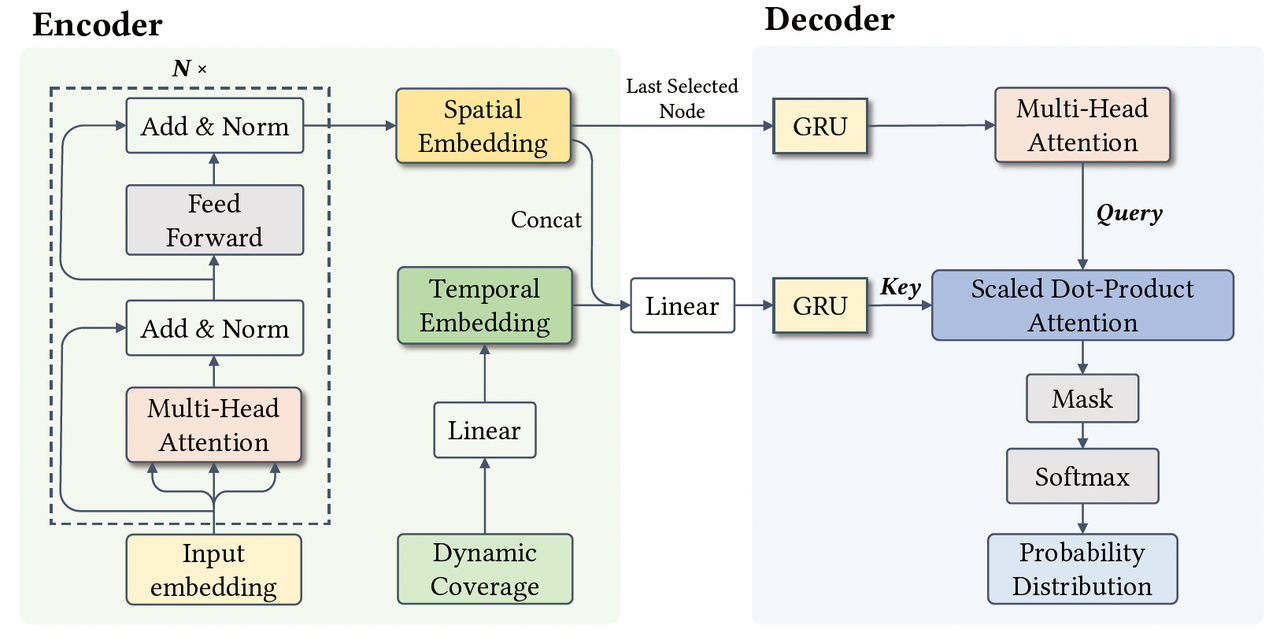
图4: ADNet模型网络结构
3.2.1 编码器
编码器将原始特征作为输入,为每个节点生成一个节点编码,该编码后续在解码器中被用于生成每个节点对应的 k e y key key。具体而言,每个节点的 k e y key key主要由两个部分构成:(1)通过自注意力层获得的空间特征编码(Spatial Embedding),其代表问题内部的结构模式;(2)通过考虑问题动态信息获得的时间特征编码(Temporal Embedding),其代表与每步决策相关的动态特征。
(1)空间特征编码
空间特征编码包含了每个节点的空间信息,包括二维欧式坐标和开设成本。首先,空间信息经过线性映射后获得节点的初始编码,然后经过 N N N层自注意力层,最后得到每个节点的空间特征编码。具体而言,每个自注意力层包括两个子网络层:用于节点间信息传递的多头注意力层(Multi-Head Attention)和前馈网络层(Feed-Foward Layer)。其中,每个子网络层均被连接至一个跳跃连接层(Skip-Connection Layer)和一个批归一化层(Batch Normalized Layer)。
(2)时间特征编码
空间特征编码 f N f^N fN可以直接被用作求解路由问题的 k e y key key,然而在DLP- p k p_k pk的问题背景下,节点的状态信息在解码的过程中并不是静态不变的。因此,选址问题中包括动态覆盖和动态开设成本在内的时间信息也应当被考虑在编码的设计中。
首先,当一个设施被开设在某个备选点之后,在该备选点附近再次开设新设施的概率应当会下降。因此,将动态覆盖的概念融入到
k
e
y
key
key的设计中是非常有必要的。为了解决这一问题,定义了一个指示函数
δ
i
\delta_i
δi来为每个节点
i
i
i表示覆盖状态,其中
i
=
1
,
2
,
.
.
.
,
n
i=1,2,...,n
i=1,2,...,n。同时,假设每个设施点有一个最大的服务半径
r
r
r,并使用
π
t
\pi_t
πt来表示第
t
t
t个时间步选中的节点,那么在节点
π
t
\pi_t
πt服务半径覆盖下的节点集合可以被表示为
C
r
(
π
t
)
C_r(\pi_t)
Cr(πt)。在每个时间步,指示函数
δ
i
\delta_i
δi会根据下述规则动态更新:
δ
i
=
{
0
,
i
∈
C
r
(
π
t
)
1
,
o
t
h
e
r
w
i
s
e
(
4
)
\delta_i= \begin{cases} 0, \quad i\in C_r(\pi_t)\\ 1, \quad otherwise\\ \end{cases}\qquad (4)
δi={0,i∈Cr(πt)1,otherwise(4)
根据方程(4),指示函数
δ
i
\delta_i
δi包含了每个节点的动态覆盖信息,并作为选择下一个设施点的指引信息。例如,对于已开设设施点而言,其服务半径内的节点会具有更低的选中概率。此外,DLP-
p
k
p_k
pk的开设成本会随周期的不同而变化,这一因素也应与动态覆盖一同考虑。与此同时,在某些情况下,距离已开设设施点较近的节点也可能是不错的选择。因此,作者对动态覆盖和动态开设成本信息进行线性映射和门控循环单元(Gate Recurrent Unit, GRU)等一系列变换,让ADNet自身去学习如何利用这些动态特性。通过结合空间特征编码和时间特征编码的方式,模型可以学习到一个更有效的策略。
3.2.2 解码器
为了对编码器提供的节点编码进行解码,作者提出了一种基于注意机制的可学习解码器,通过逐步选择需要开设的设施点构造解。解码器包含两个部分:(1)用于构建 q u e r y query query的GRU网络;(2)用于计算每个设施被选中概率的注意机制。
(1) q u e r y query query的构建
对于多周期选址问题,解的构造是一个序贯决策过程,因此考虑决策之间的时序依赖关系十分重要。为了捕捉这种依赖关系,作者引入了GRU网络对 q u e r y query query进行构建。作者使用编码器输出节点编码的平均值来对GRU的隐藏状态初始化。在第 t = 1 t= 1 t=1步时,由于尚未有节点被选中,作者将一个可学习的参数 v 1 \mathbf{v}_1 v1作为GRU的输入。对于后续 t > 1 t>1 t>1步,GRU的输入是上一步所选择节点 π t − 1 \pi_{t-1} πt−1对应的节点编码。尽管GRU的输出可以直接被用作 q u e r y query query,之前选择节点 π 1 ∼ t − 1 \pi_{1\sim t-1} π1∼t−1之间的关系也不应被忽略。为了增强对信息的表示,作者应用了注意力机制对编码进一步处理。通过引入注意力机制, q u e r y query query包含了更丰富的信息,对后续决策起辅助作用并提高了决策的有效性。
(2)注意力的计算
在解码的每一步,所有节点的选择概率均由 q u e r y − k e y query-key query−key对 ( q t , k i ) (\mathbf{q_t}, \mathbf{k_i}) (qt,ki)进行缩放点积注意力(Scaled Dot-Product Attention)计算得到。此外,由于相同的节点无法被选中多次,节点的选择概率需要根据覆盖的状态信息进行掩码操作。节点的选择概率是利用GRU生成的 q u e r y query query和编码器生成的 k e y key key通过注意机制计算获得的。对于解码策略,作者提供了贪心解码和采样解码两种策略。在每个时间步 t t t上,贪婪解码意味着在概率 p p p最高的节点处开设设施,而采样解码则从当前概率分布中采样节点来选择开设设施的节点。
3.3 训练流程
给定一个算例 s s s,定义网络模型的可学习参数为 θ \theta θ,该模型在每一个时间步提供一个概率分布 p θ ( π ∣ s ) p_\theta(\pi|s) pθ(π∣s)。通过应用对应的解码策略,可以基于策略 p θ ( π ∣ s ) p_\theta(\pi|s) pθ(π∣s)对解 π ∣ s \pi|s π∣s进行逐步构造。问题的目标是最小化定义的目标函数,目标函数如公式(1)所示,由运输成本和开设成本两部分组成。因此,作者采用REINFORCE的方法训练ADNet网络,并对策略进行优化。为了减少方差,模型参数通过带基线 b ( s ) b(s) b(s)的梯度下降法进行更新。

图5: 基于REINFORCE的训练算法伪代码
图5描述了REINFORCE的训练过程,该过程采用了贪婪滚动基线(Greedy Rollout Baseline)和Adam优化器。基线 b ( s ) b(s) b(s)表示基线策略 p θ ∗ p_{\theta^*} pθ∗由贪婪解码获得解对应的目标函数。具体而言,基线策略是训练过程中出现的性能最佳的网络模型,基线会在每个epoch结束时更新。
4. 实验分析
为了验证所提出方法的有效性,作者在合成数据集、泛化数据集和真实数据集上分别进行了实验分析,并与精确求解器、启发式方法和元启发式方法进行了对比(代码可公开获取https://github.com/JackeyMiao/ADNet)。
4.1 实验设定
下面首先对实验想定、超参数设置、对比算法和硬件设备等实验设定进行了介绍。
(1)实验想定
为了验证所提出算法的性能表现,作者在随机生成的合成数据集上进行了测试,不同规模的数据集设置如图6所示。具体而言,作者假定共有3种不同的问题规模,分别包含20、50和100个节点,3、5和7个周期数目。如第2节中所介绍的,问题的决策变量维数可以由 D = ∣ I ∣ × ∣ J ∣ × ∣ K ∣ + ∣ I ∣ × ∣ K ∣ D=|I|\times|J|\times|K|+|I|\times|K| D=∣I∣×∣J∣×∣K∣+∣I∣×∣K∣计算得到,三个问题规模对应的决策变量维数分别为1260、12750和70700个。与此同时,所有设施备选点均在一个 [ 0 , 1 ] [0,1] [0,1]的单位方形区域内随机生成。
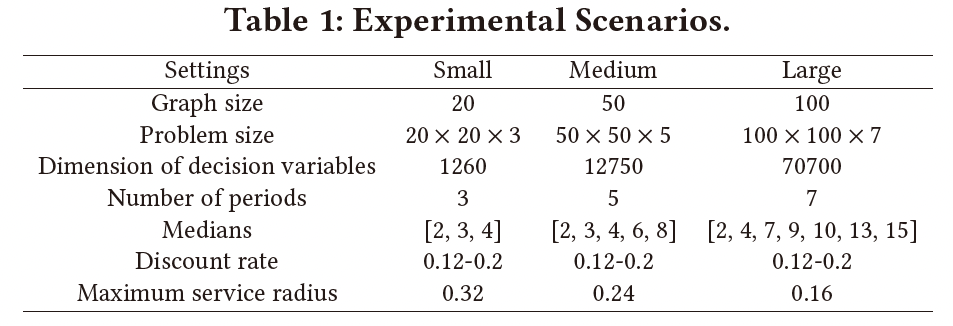
图6: 不同规模的实验想定(小、中、大三个规模)
问题中的运输成本由节点之间的欧式距离计算得到,且在所有规划周期中保持恒定。而对于设施的开设成本,作者假定每个设施点第一个周期内的开设成本在2到4的范围内随机生成,且在之后的每一个周期中都会有12%-20%的随机比例缩减。上述包括运输成本和开设成本在内的问题参数,均与该数学模型的原论文中保持一致。为了对3.2.1节中提到的动态覆盖信息进行特征刻画,作者假设每个设施点均有一个最大服务半径 r r r,对于20、50和100个节点规模的问题,最大服务半径 r r r分别为0.32、0.24和0.16。
(2)超参数设置
实验中所涉及的超参数设置如图7所示。为了保证对比的公平性,所有关于模型训练和模型结构的超参数都与基线方法保持一致。在模型的训练阶段,训练轮次设置为250个epoch,每个epoch中包含了128000个算例,且批大小设置为512。对于模型的验证阶段,每次验证共使用12800个算例,且批大小为1280。该模型使用Adam优化器进行训练,学习率为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4。在网络参数方面,模型的隐藏层维度为128,共计3个编码层。
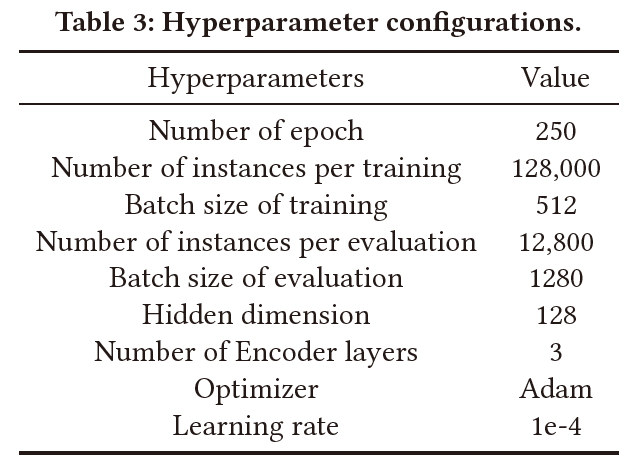
图7: 模型训练与模型网络的超参数设置
(3)对比算法
作者将ADNet与一系列有代表性的基线算法进行了比较,以此验证所提出算法的有效性。为了使实验结果更加全面,作者与不同类型的方法进行了对比,其中包括精确求解器、深度学习算法、传统启发式方法和元启发式方法。具体而言,用于对比的基线算法如下所示:
- 精确求解器Gurobi
- 深度学习基线算法,注意力模型(Attention Model, AM)
- 置换类启发式算法(Teitz and Bart, Teitz-Bart)
- 传统元启发式算法,模拟退火算法(Simulated Annealing, SA)
此外,作者将算法的运行时间(Execution Time)与最优间隔(Optimal Gap)作为性能指标,且在所有场景中均将所有算例下的平均值作为最终结果。
(4)硬件设备
所有实验均在2个GTX 3090 GPU和Intel® Xeon® Silver 4210R CPU @ 2.40GHz的设备上完成,所有代码均由Python实现。
4.2 对比分析
ADNet在三个不同规模的问题下与上述基线算法进行了对比,并记录对比算法给出的目标函数值、最优间隔和运行时间。其中,最优间隔以精确求解器Gurobi给出的目标函数值作为基准进行计算。对于每个问题规模,记录的结果均为1000个随机生成算例下的平均值。此外,作者也对比分析了不同解码策略对模型性能的影响,包括贪婪策略和采样策略。对于采样策略,作者进一步比较了采样128次和采样1280次采样的性能差异。
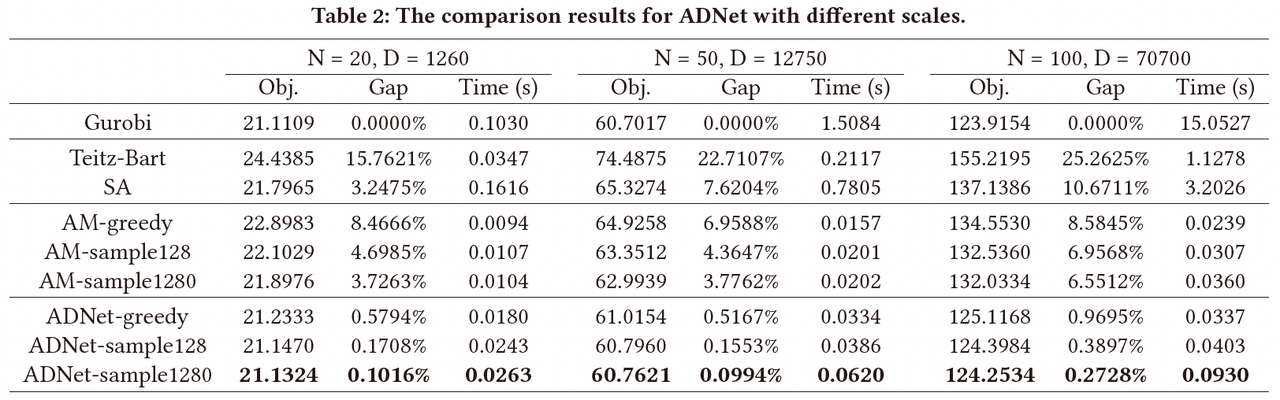
图8: 不同问题规模下ADNet网络与其他基线算法的对比结果
如图8所示,ADNet在20、50和100个节点规模下与最优值的间隔分别达到了0.1016%、0.0994%和0.2728%,超过了其他所有启发式方法和学习类方法。
(1)与精确求解器的对比
对于较小规模的算例,现代商业求解器Gurobi可以给出有理论保证的最优解。然而,当问题的规模不断扩大时,Gurobi的运行时间也会随之不断上升。尤其是当问题规模 N N N变为200、300、400和500时,Gurobi无法在可接受的时间内给出问题的最优解。对于ADNet而言,尽管其无法给出问题的最优解,但是其可以在很短的时间内给出令人满意的解。与此同时,即使在100个节点的问题规模下,ADNet的平均最优间隔也不会超过0.2728%。
(2)与(元)启发式算法的对比
对于Teitz-Bart算法和SA,二者的性能很大程度上取决于算法参数,求解的时间越长对应的最优间隔也会越小。为了保证对比的公平性,作者对算法的参数进行了调整,使得其运行时间与ADNet贪婪解码策略的运行时间基本一致。由于多周期设施选址问题需要考虑时间维度的决策,导致问题的搜索空间非常庞大,因此(元)启发式算法无法快速给出令人满意的解决方案。
(3)与学习类算法的对比
作者对比了ADNet与AM在不同问题规模下的结果,并测试了不同解码策略对模型性能影响。由于采样策略会多次采样概率分布以获得最佳值,因此采样策略应当优于贪婪策略。实验结果表明,即使是贪婪策略解码的ADNet仍然在最优间隔上大幅超过了1280次采样下的AM模型。与此同时,尽管AM模型的运行时间比ADNet更短,但二者所相差的运行时间以0.01s为单位,这种时间和性能之间的置换是可以接受的。
(4)解的可视化展示
为了更好地说明问题的特点,作者对ADNet提供的解进行了可视化展示。如图9所示,用于可视化的算例共包含50个节点和5个周期,在每个周期中分别需要运营2、3、4、6和8个设施。图中的蓝色点代表客户位置,红色点代表开设的设施位置,而线段代表设施与客户之间的分配关系。

图9: 一个包含50个节点和5个周期的算例,以及对ADNet求解方案的可视化展示
4.3 泛化性能分析
在上一节的实验中,针对不同的问题规模,均分别训练了对应的预训练模型用于验证测试,且每个问题规模下的 p k p_k pk分布是固定的。然而在实际应用中,模型的泛化性能也是非常重要的。因此,作者通过测试算法在更大问题规模和不同 p k p_k pk分布下的性能效果,来验证模型的泛化性能。
(1)更大规模的泛化性能测试
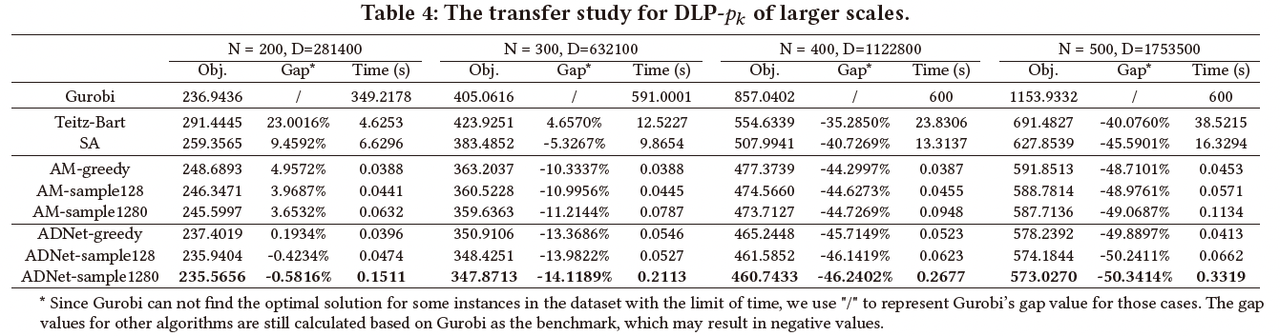
图10: 更大问题规模的泛化性能测试结果
由于深度学习类方法具备自适应处理大规模问题的能力,作者尝试将小规模场景下训练的模型用于求解更大规模的算例,并对比分析了不同算法之间的性能差异。作者在100个节点的规模下对模型进行训练,并分别在200、300、400和500个节点规模的算例上对算法的性能进行评估。对于大规模场景, p k p_k pk的设置与100个节点规模下保持一致,均为 p k = [ 2 , 4 , 7 , 9 , 10 , 13 , 15 ] p_k = [2, 4, 7, 9, 10, 13, 15] pk=[2,4,7,9,10,13,15]。随着问题规模的扩大,Gurobi无法在短时间内给出问题的最优解,因此作者将Gurobi中每个算例的运行时间上限限制为600秒。在给定时间内,Gurobi无法将所有算例求解至理论最优,故Gurobi的最优间隔Gap用’/'表示,其余算法的最优间隔仍以Gurobi的解为基准进行计算。为了节约时间,大规模场景下每个问题规模仅包含100个随机生成的算例。如图10所示,相比于其他基线算法,ADNet在更大规模下的性能有着明显的优势。特别是当与Gurobi进行对比时,ADNet可以在更短的时间内提供显著优于Gurobi的解决方案。
(2)不同 p k p_k pk分布的泛化性能测试
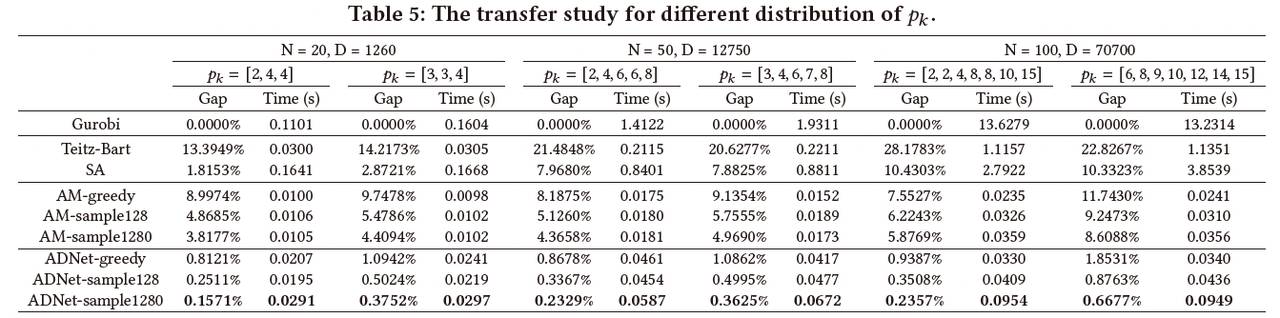
图11: 不同pk分布的泛化性能测试结果
在实际的应用中, p k p_k pk的分布往往不是固定不变的。因此,算法在不同 p k p_k pk分布算例下的性能也是模型有效性的一个重要体现。具体而言,作者在20、50和100三个问题规模上进行了类似的实验。作者选择了与训练场景中 p k p_k pk分布不同的算例进行测试验证,并将ADNet的结果与其他基线算法进行了对比。如图11所示,ADNet在处理不同 p k p_k pk分布的算例时仍然能够保持很好的泛化性能,且始终优于其他基线算法。
4.4 实际场景性能分析
本节中,作者利用所提出的ADNet模型对北京市海淀区的基础设施的位置进行选址优化,旨在最小化多个周期的运输成本与安装成本的同时保证服务的高效响应。所用数据集中共计包含4749个住宅单位,作者从中随机采样了100个点作为求解的算例,以便更好地可视化。数据集中的所有数据均来自真实的城市数据,且在求解之前经过了必要的预处理,包括坐标转换和归一化。具体而言,假设总共有三个周期,且每一周期需要运营的设施数目为 p k = [ 2 , 3 , 4 ] p_k = [2, 3, 4] pk=[2,3,4]。为了清晰地展示不同算法间求解方案的差异,作者分别采用Gurobi、ADNet和SA来对算例进行求解并进行可视化。
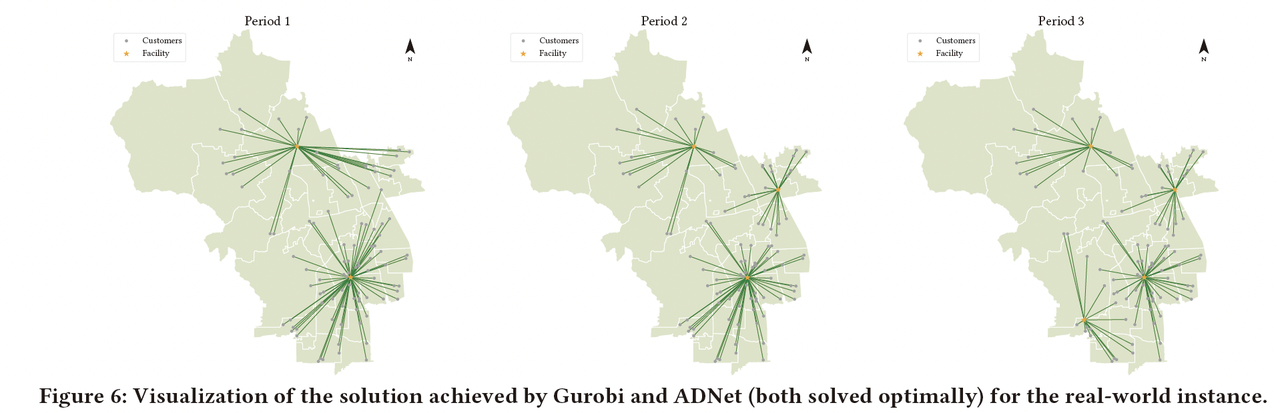
图12: Gurobi和ADNet所提供求解方案的可视化,二者均将算例求解至了最优
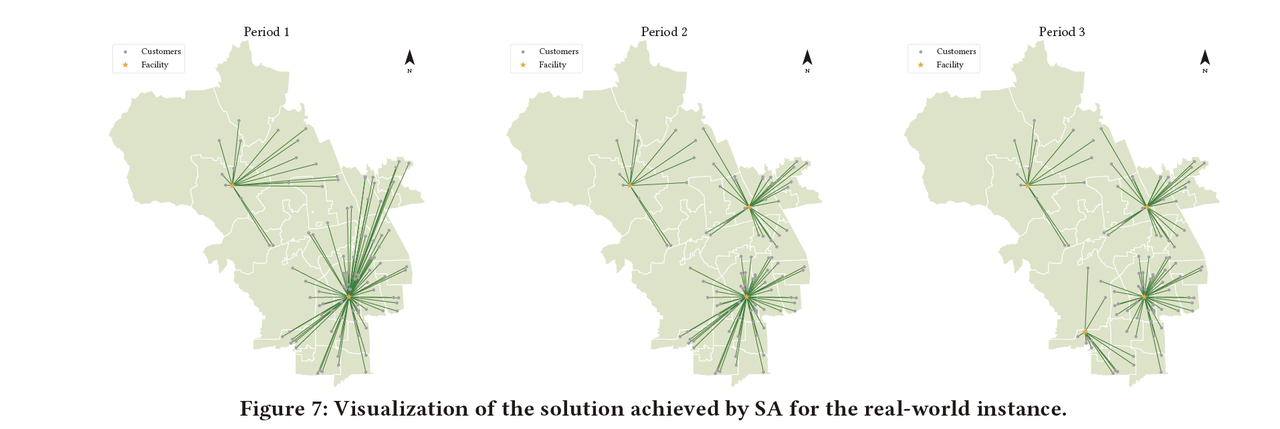
图13: SA所提供求解方案的可视化
如图12和图13所示,Gurobi和ADNet均能将算例求解至最优,而SA只能给出近优解。很明显在第一个周期中,Gurobi和ADNet所提供的解决方案在客户的分配关系上更加合理。相反,SA提供的解可能会导致某些设施和客户之间的运输成本更高,从而导致分配关系的不平衡。在实际数据下的可视化结果强调了多周期设施选址在战略层面的重要性,选址阶段的决策会直接影响后续物流决策的效率。这一简单的例子直观地展示了ADNet模型在求解实际问题时的出色效果,表明了它在未来研究和实际应用中的巨大潜力。
5. 总结
本文中,作者提出了一种深度强化学习方法用于求解DLP- p k p_k pk问题。为了有效处理多周期问题的时间信息,作者专门设计了一种结构对问题的动态特征进行捕捉,以此提高模型的性能。此外,作者首次将深度强化学习技术用于求解多周期设施选址问题。充分的实验结果表明,作者所提出的方法拥有出色的性能和泛化能力。在未来,作者将尝试将ADNet扩展到其他多周期设施选址问题,例如同时考虑设施的开启和关闭,以及设施的服务容量约束。针对问题的特点,作者将尝试设计更有效的模型结构来提高算法的性能。此外,作者将考虑实际应用中的不确定性因素,并设计更加鲁棒且自适应的学习算法。
参考文献:
Changhao Miao, Yuntian Zhang, Tongyu Wu, Fang Deng, and Chen Chen. 2024. Deep Reinforcement Learning for Multi-Period Facility Location: -median Dynamic Location Problem. In The 32nd ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL ’24), October 29-November 1, 2024, Atlanta, GA, USA. ACM, New York, NY, USA, 11 pages.