文章目录
- 1 Kafka简介
- 1.1 什么是Kafka
- 1.2 Kafka的应用场景
- 1.3 Kafka的优势
- 2 搭建Kafka集群
- 2.1 搭建Zookeeper集群
- 2.1.1 上传并解压安装包
- 2.1.2 修改配置文件
- 2.2.3 创建dataDir和myid文件
- 2.2.4 分发到另外两个节点
- 2.2.5 修改node-02节点、node-03节点的配置文件和myid文件
- 2.2.6 启动Zookeeper集群
- 2.2 搭建Kafka集群
- 2.2.1 下载Kafka安装包
- 2.2.2 上传并解压
- 2.2.3 修改配置文件server.properties
- 2.2.4 将`kafka01`目录分发至node-02、node-03节点
- 2.2.5 分别修改node-02节点、node-03节点的配置文件
- 2.2.6 启动Kafka集群
- 2.3 使用工具连接Kafka集群
- 2.3.1 连接Kafka集群
- 2.3.2 创建topic
- 2.4 问题处理
- 3 Kafka的架构
- 3.1 Broker(服务器节点)
- 3.2 Topic(主题)
- 3.3 Partition(分区)
- 3.4 Producer(生产者)、Consumer(消费者)
- 3.5 Consumer Group(消费者组)
- 3.6 Leader Partition(领导者分区)
- 3.7 Follower Partition(跟随者分区)
- 3.8 Offset(偏移量)
1 Kafka简介
1.1 什么是Kafka
以下是 Kafka官网 的介绍:

Apache Kafka 是一个开源的分布式事件流平台,被数千家公司用做高性能数据管道、流分析、数据集成和关键任务应用程序。超过80%的财富100强公司信任并使用Kafka。

Kafka 组合了三个关键功能,是一个经过实战测试的实现了端到端事件流的解决方案:
- 发布(写入)和订阅(读取)事件流,包括从其他系统连续导入/导出数据。
- 根据需要持久可靠地存储事件流。
- 在事件发生时或回顾性地处理事件流。
1.2 Kafka的应用场景
Kafka 通常用在两类程序中:
- 建立实时数据管道,以可靠地在系统或应用程序之间获取数据
- 构建实时流应用程序,以转换或响应数据流

- Producers:生产者,可以有很多的应用程序,将消息数据放入到Kafka集群中。
- Consumers:消费者,可以有很多的应用程序,将消息数据从Kafka集群中拉取出来。
- Connectors:连接器,可以将数据库中的数据导入到Kafka,也可以将Kafka的数据导出到
数据库中。 - Stream Processors:流处理器,可以从Kafka中拉取数据,也可以将数据写入到Kafka中。
1.3 Kafka的优势

2 搭建Kafka集群
2.1 搭建Zookeeper集群
在2.8.0版本以前,Kafka集群的搭建依赖于Zookeeper环境,需要将Kafka集群节点IP及topic等相关的元数据存入Zookeeper服务中。所以在搭建Kafka集群前,需要先搭建Zookeeper集群。
准备在3台网络互通的虚拟机上搭建Zookeeper集群,信息如下:
| 节点 | IP | 端口 |
|---|---|---|
| node-01 | 192.168.245.130 | 2181 |
| node-02 | 192.168.245.131 | 2181 |
| node-03 | 192.168.245.132 | 2181 |
2.1.1 上传并解压安装包
先在node-01主机上操作:
[root@node-01 ~]$ tar -zxvf apache-zookeeper-3.8.4-bin.tar.gz
[root@node-01 ~]$ mv apache-zookeeper-3.8.4-bin zookeeper01
2.1.2 修改配置文件
# 进入配置文件目录
[root@node-01 ~]$ cd zookeeper01/conf/
# 拷贝一份配置文件并重新命名
[root@node-01 conf]$ cp zoo_sample.cfg zoo.cfg
# 修改配置文件
[root@node-01 conf]$
vim zoo.cfg
修改如下内容:
# 数据目录修改为指定目录
dataDir=/root/zookeeper01/data
# zookeeper集群的3个节点
server.1=192.168.245.130:2888:3888
server.2=192.168.245.131:2888:3888
server.3=192.168.245.132:2888:3888
2.2.3 创建dataDir和myid文件
# 创建zoo.cfg配置文件指定的数据目录
[root@node-01 ~]$ cd zookeeper01
[root@node-01 zookeeper01]$ mkdir data
# 在数据目录下创建myid文件,内容也是zoo.cfg配置文件中server.1指定的
[root@node-01 zookeeper01]$ echo 1 > zookeeper/myid
[root@node-01 zookeeper01]$ cat data/myid
1
2.2.4 分发到另外两个节点
# 分发到node-02节点
[root@node-01 ~]# scp -r zookeeper01/ root@192.168.245.131:~/zookeeper02
# 分发到node-03节点
[root@node-01 ~]# scp -r zookeeper01/ root@192.168.245.132:~/zookeeper03
此时可以在node-02节点、node-03节点看到对应的目录:

2.2.5 修改node-02节点、node-03节点的配置文件和myid文件
- 修改node-02节点的配置文件的数据目录
# zookeeper02/config/zoo.cfg
dataDir=/root/zookeeper02/data
- 修改node-02节点的myid的内容为2
[root@node-02 zookeeper02]$ cat data/myid
2
- 修改node-03节点的配置文件的数据目录
# zookeeper03/config/zoo.cfg
dataDir=/root/zookeeper03/data
- 修改node-03节点的myid的内容为3
[root@node-03 zookeeper03]$ cat data/myid
3
2.2.6 启动Zookeeper集群
分别进入Zookeeper的bin目录下,然后借助Xshell工具,同时向3个节点发送启动命令:
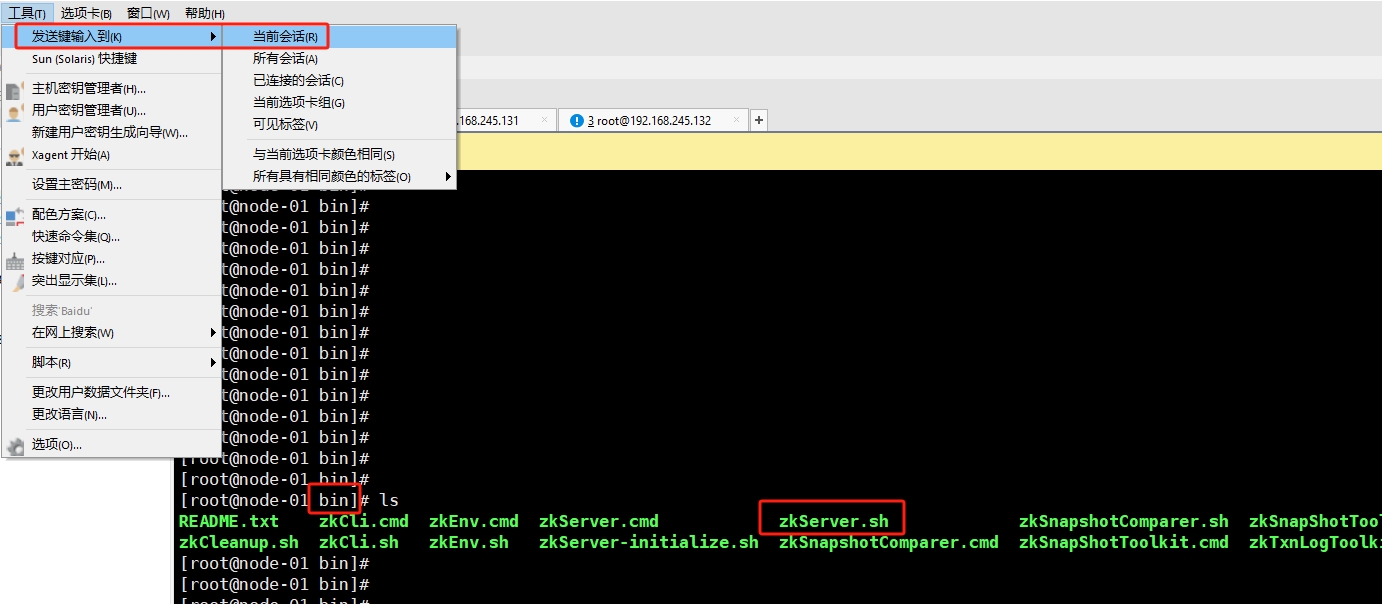
[root@node-01 bin]$ zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /root/zookeeper01/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看Zookeeper集群状态,可以发现leader是编号最大的服务器,即node-03:

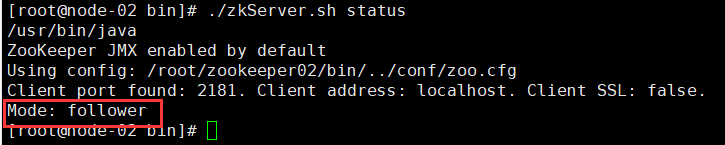

至此,Zookeeper集群搭建好了。
2.2 搭建Kafka集群
2.2.1 下载Kafka安装包
Kafka目前最新的版本是3.8.0,可以依赖Zookeeper环境,也可以不依赖Zookeeper环境:
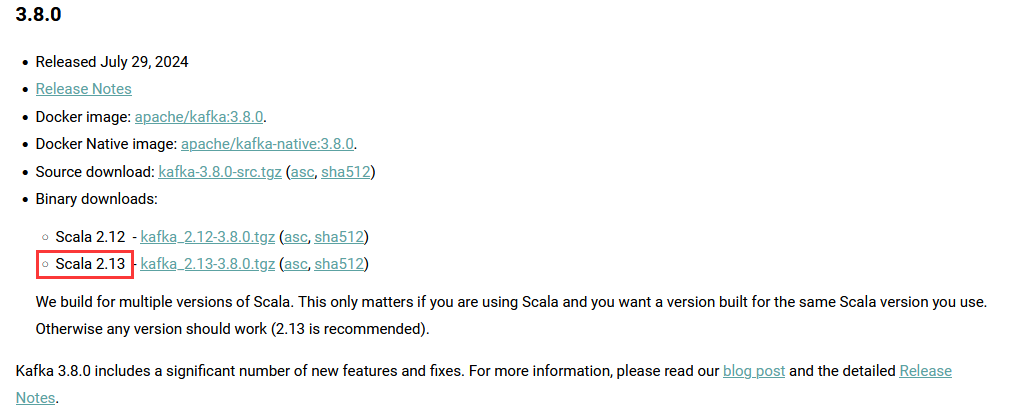
2.2.2 上传并解压
将Kafka安装包上传至node-01节点并解压,修改文件夹名为kafka01:
[root@node-01 ~]$ tar -zxvf kafka_2.13-3.8.0.tgz
[root@node-01 ~]$ mv kafka_2.13-3.8.0 kafka01
2.2.3 修改配置文件server.properties
[root@node-01 ~]$ vim kafka01/config/server.properties
修改内容如下:
# kafka01/config/server.properties
# 指定broker的id
broker.id=1
# 指定Kafka数据的位置
log.dirs=/root/kafka01/data
# 配置zookeeper的三个节点
zookeeper.connect=192.168.245.130:2181,192.168.245.131:2181,192.168.245.132:2181
2.2.4 将kafka01目录分发至node-02、node-03节点
scp -r kafka01/ root@192.168.245.131:~/kafka02
scp -r kafka01/ root@192.168.245.132:~/kafka03
此时可以在node-02节点、node-03节点看到对应的目录:
2.2.5 分别修改node-02节点、node-03节点的配置文件
- 修改node-02节点的配置文件
# kafka02/config/server.properties
broker.id=2
log.dirs=/root/kafka02/data
- 修改node-03节点的配置文件
# kafka03/config/server.properties
broker.id=3
log.dirs=/root/kafka03/data
2.2.6 启动Kafka集群
进入kafka安装目录下的bin目录,同时启动3个节点:
[root@node-01 ~]$ cd kafka01/bin/
[root@node-01 bin]$ nohup ./kafka-server-start.sh ../config/server.properties &

这样,Kafka集群就搭建完成了。
2.3 使用工具连接Kafka集群
2.3.1 连接Kafka集群
在 Offset Explorer官网 下载Kafka连接工具:
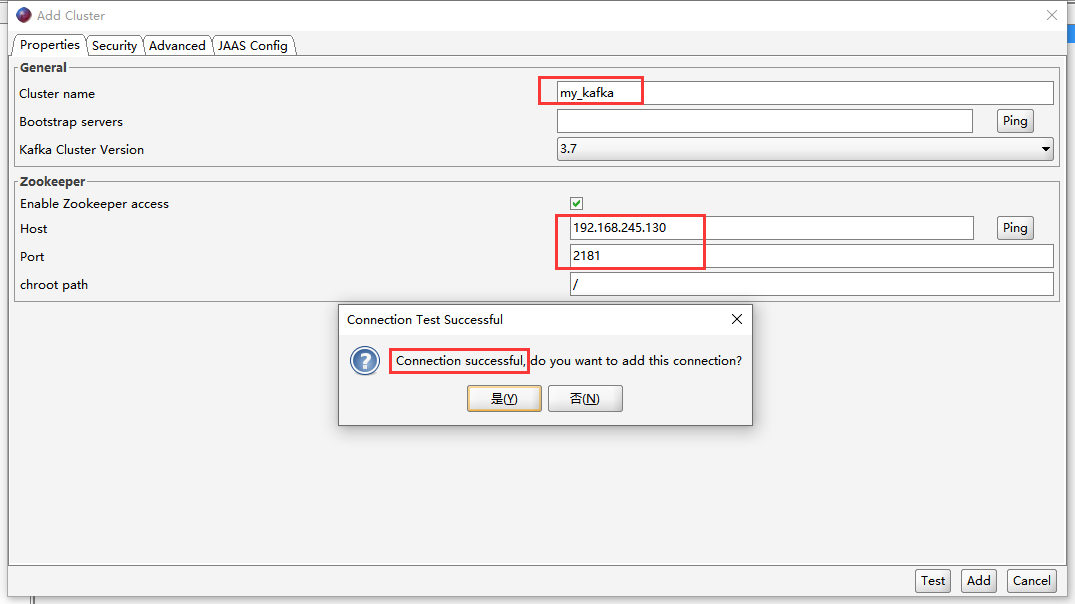
安装后新建Kafka集群连接:
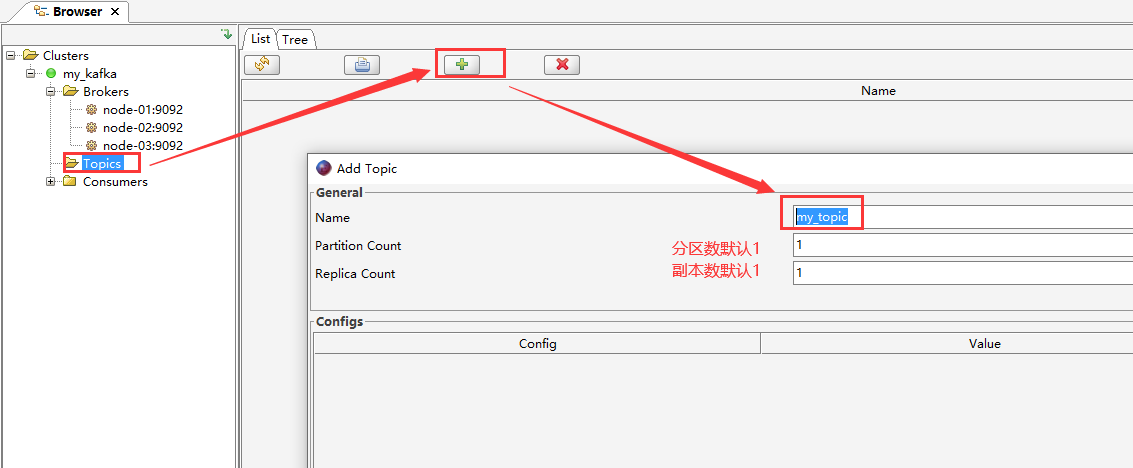
连接成功后可以看到Kafka集群的3个节点:

2.3.2 创建topic
2.4 问题处理
- 问题1
部署Kafka过程中,出现java.net.UnknownHostException: node-02异常:
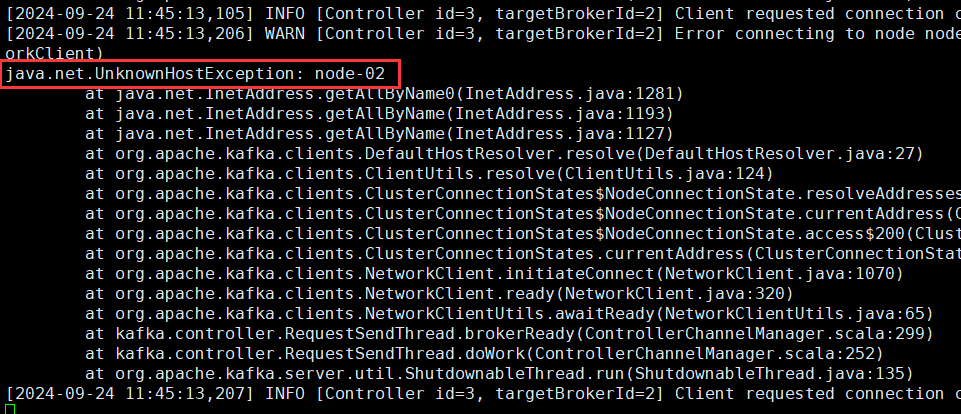
出现这个问题是因为3台主机之间没有实现主机名互通。
- 修改node-01节点的
/etc/hosts文件,新增以下内容:
192.168.245.131 node-02
192.168.245.132 node-03
配置完成后,即可通过主机名访问其他节点:
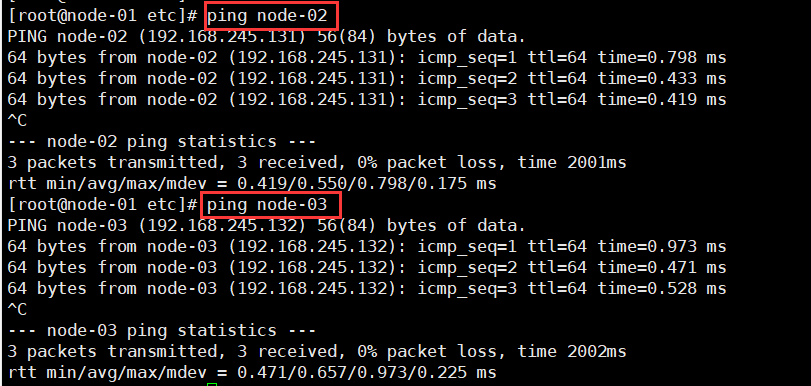
同样的方法配置node-02节点、node-03节点。随后重启Kafka集群,不再报错。
- 问题2
使用工具创建topic时,报错:
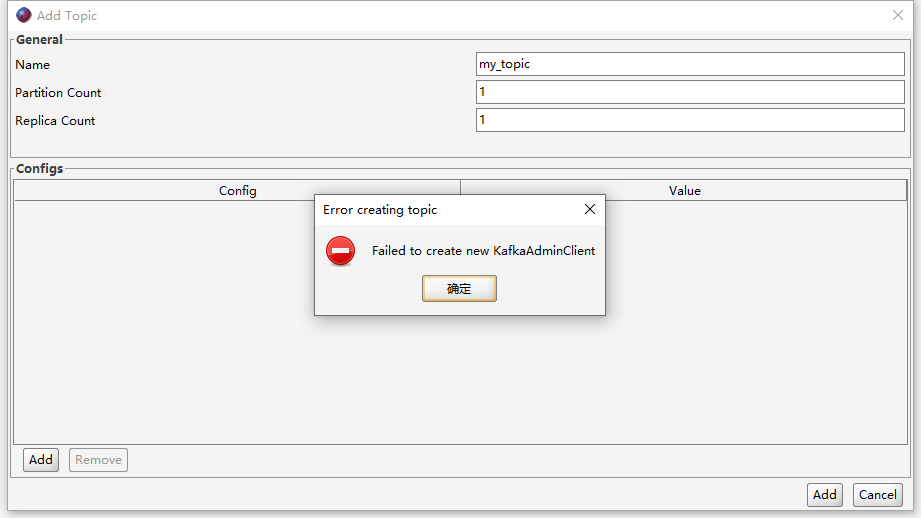
经过排查发现出现这个问题的原因仍然是无法解析主机名。
修改C:\Windows\System32\drivers\etc\hosts文件,添加以下内容:
192.168.245.130 node-01
192.168.245.131 node-02
192.168.245.132 node-03
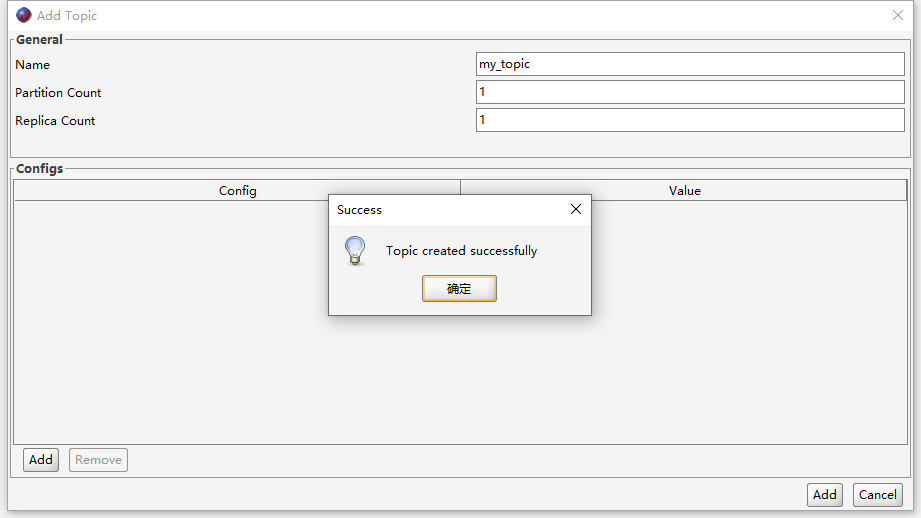
再次尝试创建topic,成功:
3 Kafka的架构

3.1 Broker(服务器节点)
Kafka集群包含一个或多个服务器节点,服务器节点称为Broker,用于存储Topic的数据。
如果某Topic有N个Partition(分区),集群也有N个Broker,那么每个Broker就存储其中一个Partition,刚好是一对一。
如果某Topic有N个Partition,集群有(N+M)个Broker,那么其中有N个Broker存储N个Partition,剩下的M个Broker不存储该Topic的Partition数据。
如果某Topic有N个partition,但集群中Broker数目少于N个,那么一个Broker就需要存储该Topic的一个或多个Partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
3.2 Topic(主题)
每条发布到Kafka集群的消息都有一个类别,这个类别就被称为主题(Topic)。
在物理上,不同Topic的消息会分开存储;在逻辑上,一个Topic的消息虽然保存于一个或多个Broker上,但用户只需指定消息的Topic,而不必关心数据存于何处。
3.3 Partition(分区)
每个Topic被分割为一个或多个Partition(分区),而每个Partition中的数据使用多个Segment文件存储。Partition中的数据是有序的,但不同Partition间的数据则丢失了顺序。
因此,如果一个Topic有多个Partition,消费数据时就不能保证数据的顺序,在需要严格保证消息的消费顺序的场景下,需要将Partition数目设为1。
3.4 Producer(生产者)、Consumer(消费者)
Producer即数据的发布者,将消息发布到Kafka的某个Topic中。
Broker接收到生产者发送的消息后,将该消息存储到一个Partition中。生产者也可以指定数据存储的Partition。
Consumer即数据的消费者,可以消费一个多个Topic中的数据。
3.5 Consumer Group(消费者组)
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定Group名称,若不指定Group名称则属于默认的Group)。
这是Kafka用来实现一个Topic消息的广播(发给某个Consumer Group下的所有Consumer)和单播(发给某个Consumer Group下的任意一个Consumer)的手段。一个Topic可以有多个Consumer Group。
3.6 Leader Partition(领导者分区)
每个Partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的Partition。
3.7 Follower Partition(跟随者分区)
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,使得Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。
3.8 Offset(偏移量)
Kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可(从00.kafka开始)。
…
本节完,更多内容请查阅分类专栏:微服务学习笔记
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析
- MyBatis3源码深度解析
- Redis从入门到精通
- MyBatisPlus详解
- SpringCloud学习笔记