本文浅析淘汰策略与工作中结合使用、选取,并非针对算法本身如何实现的
文章目录
- FIFO
- LFU
- LRU
- W-TinyLFU
- 实践与优化
- 监控与调整
FIFO
first input first output , 先进先出,即最早存入的元素最先取出,
典型数据结构代表:Queue (队列)
优点:
是最简单直观的一种策略,
一般适用于随机访问、缓存的元素都是随机性或频率大致相等的;对于不常变化的数据,如配置文件、静态资源等,FIFO(先进先出)可能是一个简单且有效的选择。这些数据的访问频率通常较低,且不需要频繁更新,FIFO能确保缓存中的旧数据被定期清理,为新数据腾出空间。
缺点:对于访问频率高且经常变化的动态数据,如热点新闻等则不适用

LFU
least frequently used , 最不经常使用,即把最不经常使用的数据淘汰掉,粗略一听 是很符合逻辑的, 它可以很好的命中高访问频率数据;
我们可以假设一个场景,比如9:00秒杀手机,9:05秒杀笔记本,9:10正常开售平板,那么之前秒杀缓存的数据就显得很苍白无力,它频率确实是非常高,但由于后续业务变更(访问模式转变),变得不再那么需要访问。
LFU也能够有效的保护缓存,相对场景来说,比LRU有更好的缓存命中率。由于是以次数为基准,因此更加准确,天然能有效的保证和提升命中率。
所以LFU 优缺点总结如下:
优点:平稳业务场景来说,比LRU有更好的缓存命中率。由于是以次数为基准,因此更加准确,能有效的保证和提升命中率
缺点:由于LFU须要记录数据的访问频率,所以需要额外的空间;当访问模式改变(业务转变)的时候,算法命中率会急剧降低,这也是他最大弊端。
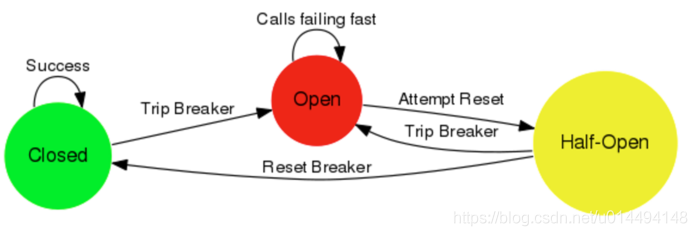
LRU
Least Recently Used,即最近最少使用,LRU认为 最近访问的数据 在接下来访问的频率也会更高,在平常业务中 LRU可以覆盖较广的范围
典型代表:mysql 缓冲池
mysql的缓冲池就是使用的LRU淘汰算法
我们可以看看一个简单的LRU实现方式:
来自jsonpath包下的源码: 如果值存在 就将它置顶

removeThenAddKey 方法如下:
private void removeThenAddKey(String key) {
this.lock.lock();
try {
this.queue.removeFirstOccurrence(key);
this.queue.addFirst(key);
} finally {
this.lock.unlock();
}
}
W-TinyLFU
减少了LFU的内存占用,同时结合了LFU和LRU的特点,是一种比较不错的淘汰算法
典型容器代表:java中的Caffeine
maven:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<!-- 检查是否有最新版本 -->
<version>3.1.8</version>
</dependency>
优点结合了LRU和LFU的特点,
缺点则是算法难度本身比较复杂 ,一般使用写好的开源组件,自己实现一个优秀的算法还是比较困难的
实践与优化
监控与调整
性能监控:定期监控缓存系统的性能指标,如命中率、缓存大小、访问延迟等,以便及时发现并解决问题。
策略调整:根据业务需求和监控结果,适时调整缓存淘汰策略。例如,在访问模式发生显著变化时,可以考虑切换淘汰策略或调整策略参数。
缓存预热:在系统启动或数据更新后,主动对缓存进行预热,即提前将预计会被频繁访问的数据加载到缓存中。这可以显著提高缓存命中率,减少数据访问延迟。