最近大家热议的ChatGPT和AI绘画工具的底层技术原理是什么?是如何发展到现在的?有哪些应用场景、热门工具?AIGC产业上下游有哪些公司?作为普通用户,我们还能接触哪些应用AI技术打造的商业解决方案?……
我们查阅了AIGC相关相关的调研报告和各类资料,按照优化后的目录框架对内容进行了摘录和编排,希望能够帮助大家也能更快了解和入门。

MidjourneyAI绘画工具社区作品
内容主要来自:《腾讯研究院-AIGC发展趋势报告2023》和《量子位智库-AI生成内容产业展望报告》这两篇行业报告,以及各类平台的相关文章、视频,文末也对参考内容的来源进行标注,想要深度了解的话可以留意下。
文章比较长,大概需要1-2个小时才能完整阅读,可以找个安静的地方一口气读完。里面的专业词汇如果不懂,可以先忽略,对于普通人来说,我们只需要了解大概的历程和应用场景以及代表工具即可。
本文逻辑:
1、技术定义
2、发展历程和经典事件
3、行业现状(基础层、中间层、应用层)
4、应用场景
5、国内外AIGC工具
可点击查看大图 ▼

一、技术定义
AIGC全称为AI-Generated Content,指基于生成对抗网络GAN、大型预训练模型等人工智能技术,通过已有数 据寻找规律,并通过适当的泛化能力生成相关内容的技术。与之相类似的概念还包括Synthetic media,合成式媒体,主要指基于AI生成的文字、图像、音频等。
从字面意思上看,AIGC是相对于过去的 PCG、UCG 而提出的。因此,AIGC的狭义概念是利用Al自动生成内容的生产方式。但是 AIGC已经代表了AI技术发展的新趋势。
过去传统的人工智能偏向于分析能力,即通过分析一组数据,发现其中的规律和模式并用于其他多种用途,比如应用最为广泛的个性化推荐算法。而现在人工智能正在生成新的东西,而不是仅仅局限于分析已经存在的东西,实现了人工智能从感知理解世界到生成创造世界的跃迁。
因此,从这个意义上来看,广义的 AIGC 可以看作是像人类一样具备生成创造能力的 AI技术,即生成式 AL它可以基于训练数据和生成算法模型,自主生成创造新的文本,图像、音乐、视频、3D交互内容(如虚拟化身、虚拟物品、虚拟环境)等各种形式的内容和数据,以及包括开启科学新发现,创造新的价值和意义等。"因此,AIGC已经加速成为了Al 领域的新疆域,推动人工智能迎来下一个时代。
MIT 科技评论也将A1 合成数据列为 2022 年十大突破性技术之一,甚至将生成性 Al(Generative AI)称为是AI领域过去十年最具前景的进展。Gartner 将生成性 A1 列为 2022 年5大影响力技术之一。
Gartner 也提出了相似概念Generative AI,也即生成式AI。生成式AI是指该技术从现有数据中生成相似的原始数据。相较于量子位智库认为的AIGC,这一概念的范围较狭窄。
一方面,这一概念忽略了跨模态生成(如基于文本生成图像或基于文本生成视频)这一愈加重要的AIGC部分。我们会在下一部分对跨模态生成进行重点讲解。另一方面,在结合现有技术能力和落地场景进行分析后,我们认为“生 成”和“内容”都应该采取更为广泛的概念。
例如,生成中可以包含基于线索的部分生成、完全自主生成和基于底稿的优化生成。内容方面,不仅包括常见的图像、文本、音频等外显性内容,同样也包括策略、剧情、训练数据等 内在逻辑内容。
从特定角度来看,AI内容生成意味着AI开始在现实内容中承担新的角色,从“观察、预测”拓展到“直接生成、决策”。
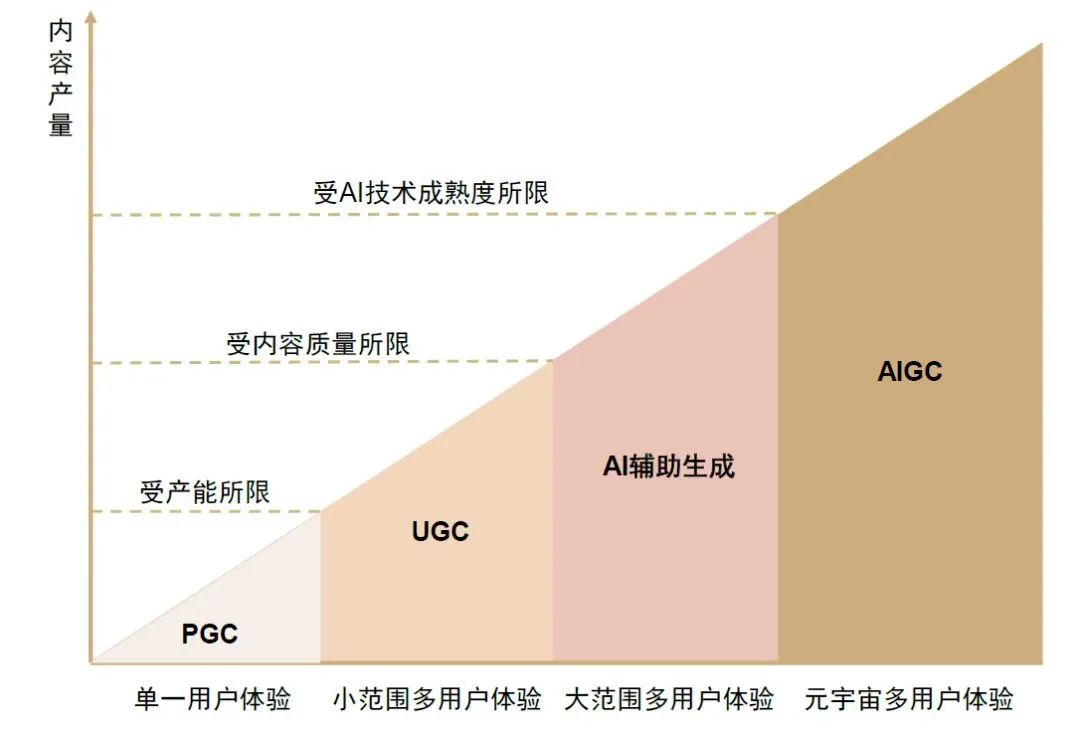
从商业模式来看,我们认为,AIGC本质上是一种AI赋能技术,能够通过其高通量、低门槛、高自由度的生成能力广泛服务于各类内容的相关场景及生产者。因此,我们不会将其定义为PGC\UGC之后 的新内容创作模式,而是认为其在商业模式上会有大量其他交叉。
未来,兼具大模型和多模态模型的 AIGC模型有望成为新的技术平台。如果说 Al 推荐算法是内容分发的强大引整,AIGC则是数据与内容生产的强大引整。
AIGC朝着效率和品质更高、成本更低的方向发展,在某些情况下,它比人类创造的东西更好。包括从社交媒休到游戏,从广告到建筑,从编码到平面设计、从产品设计到法律,从营销到销售等各个需要人类知识创造的行业都可能被 AIGC 所影响和变革。数字经济和人工智能发展所需的海量数据也能通过 AIGC技术生成、合成出来,即合成数据(synthetic data)。
未来,人类的某些创造性的工作可能会被生成性 AI 完全取代,也有一些创造性工作会加速进入人机协同时代–人类与 AIGC技术共同创造比过去单纯人的创造之下更高效、更优质。
在本质上AIGC 技术的最大影响在于,AIGC技术将会把创造和知识工作的边际成本降至零,以产生巨大的劳动生产率和经济价值。换句话说,正如互联网实现了信息的零成本传播、复制。未来AIGC 的关键影响在于,将实现低成本甚至零成本的自动化内容生产,这一内容生产的范式转变,将升级甚至重塑内容生产供给,进而给依赖于内容生产供给的行业和领域带来巨大影响。
二、起源历程
AIGC发展历程和典型事件
虽然从严格意义上来说,1957 年莱杰伦·希勒(Lejaren Hiller)和伦纳德·艾萨克森(Leon-ard saacson)完成了人类历史上第一支由计算机创作的音乐作品就可以看作是 AIGC的开端,距今已有 65 年,这期间也不断有各种形式的生成模型、Al 生成作品出现。
但是 2022年才真正算是 AIGC 的爆发之年,人们看到了 AIGC无限的创造潜力和未来应用可能性。目前,AIGC 技术沉淀、产业生态已初步形成,保持强劲发展和创新势头。

主流生成模型诞生历程
生成算法、预训练模型、多模态等AI技术累积融合,催生了AIGC 的大爆发。
一是,基础的生成算法模型不断突破创新。
2014年,伊恩·古德费洛(lan Goodfellow)提出的生成对抗网络(Generative Adversarial Network,GAN)成为早期最为著名的生成模型。
GAN 使用合作的零和博弈框架来学习,被广泛用于生成图像、视频、语音和三维物体模型等。GAN 也产生了许多流行的架构或变种,如DCGAN,StyleGAN,BigGAN,StackGAN.Pix2pix,Age-cGAN,CycleGAN、对抗自编码器(Adversarial Autoencoders,AAE)、对抗推断学习(Adversarially Learned Inference,ALI)等。
随后,Transformer、基于流的生成模型(Flow-based models)、扩散模型(Diffusion Model)等深度学习的生成算法相继涌现。其中,Transformer 模型是一种采用自注意力机制的深度学习模型,这一机制可以按照输入数据各部分重要性的不同而分配不同的权重,可以用在自然语言处理(NLP)、计算机视觉(CV)领域应用。后来出现的 BERT、GPT-3、LaMDA等预训练模型都是基于Transformer 模型建立的。
而扩散模型(Diffusion Mode)是受非平衡热力学的启发,定义一个扩散步骤的马尔可夫链,逐渐向数据添加随机噪声,然后学习逆扩散过程,从噪声中构建所需的数据样本。扩散模型最初设计用于去除图像中的噪声。随着降噪系统的训练时间越来越长并且越来越好,它们最终可以从纯噪声作为唯一输入生成逼直的图片。
然而,从最优化模型性能的角度出发,扩散模型相对 GAN 来说具有更加灵活的模型架构和精确的对数似然计算,已经取代 GAN 成为最先进的图像生成器。2021年6月,OpenAl 发表论文已经明确了这个结论和发展趋势。



二是,预训练模型引发了 AIGC技术能力的质变。
虽然过去各类生成模型层出不穷,但是使用门槛高、训练成本高、内容生成简单和质量偏低,远远不能满足真实内容消费场景中的灵活多变、高精度、高质量等需求。预训练模型的出现引发了 AIGC技术能力的质变,以上的诸多落地问题得到了解决。
随着 2018 年谷歌发布基于 Transformer 机器学习方法的自然语言处理预训练模型 BERT,人工智能领域进入了大炼模型参数的预训练模型时代。AI预训练模型,又称为大模型、基础模型(foundation mode),即基于大量数据(通常使用大规模自我监督学习)训练的、拥有巨量参数的模型,可以适应广泛的下游任务。
这些模型基于迁移学习的思想和深度学习的最新进展,以及大规模应用的计算机系统,展现了令人惊讶的涌现能力,并显著提高各种下游任务的性能。”鉴于这种潜力,预训练模型成为 AI技术发展的范式变革,许多跨领域的Al系统将直接建立在预训练模型上。具体到 AIGC 领域,AI 预训练模型可以实现多任务、多语言、多方式,在各种内容的生成上将扮演关键角色。按照基本类型分类,预训练模型包括:(1)自然语言处理(NLP)预训练模型,如谷歌的 LaMDA和 PaLM、Open AI的 GPT 系列:(2)计算机视觉(CV)预训练模型,如微软的 Florence:(3)多模态预训练模型,即融合文字、图片、音视频等多种内容形式。
可点击查看大图 ▼

三是,多模态技术推动了AIGC的内容多样性,让 AIGC 具有了更通用的能力。
预训练模型更具通用性,成为多才多艺、多面手的 Al模型,主要得益于多模型技术(multimodal technol-ogy)的使用,即多模态表示图像、声音、语言等融合的机器学习。
2021年,OpenAI团队将跨模态深度学习模型CLIP(Contrastive Lanquaqe-Image Pre-Training,以下简称“CLIP")进行开源。CLIP 模型能够将文字和图像进行关联,比如将文字“狗”和狗的图像进行关联,并且关联的特征非常丰富。因此,CLIP 模型具备两个优势:一方面同时进行自然语言理解和计算机视觉分析,实现图像和文本匹配。另一方面为了有足够多标记好的“文本-图像”进行训练,CLIP 模型广泛利用互联网上的图片,这些图片一般都带有各种文本描述,成为 CLIP 天然的训练样本。
据统计,CLIP 模型搜集了网络上超过 40 亿个“文本-图像”训练数据,这为后续 AIGC 尤其是输入文本生成图像/视频应用的落地奠定了基础。在多模态技术的支持下,目前预训练模型已经从早期单一的 NLP或CV模型,发展到现在语言文字、图形图像、音视频等多模态、跨模态模型。
2021年3月OpenAl发布Al绘画产品DALL·E,只需要输入一句文字,DALL·E 就能理解并自动生成一幅意思相符的图像,且该图像是独一无二的。DALL·E 背后的关键技术即是 CLIP。CLIP 让文字与图片两个模态找到能够对话的交界点,成为 DALL·E、DALL·E2.0、Stable Diffusion 等突破性 AIGC成果的基****石。
**总的来看,AIGC 在 2022 年的爆发,主要是得益于深度学习模型方面的技术创新。不断创新的生成算法、预训练模型、多模态等技术融合带来了 AIGC技术变革,**拥有通用性、基础性、多模态、参数多、训练数据量大、生成内容高质稳定等特征的 AIGC模型成为了自动化内容生产的“工厂”和“流水线”。
三、行业现状
AIGC 产业生态加速形成和发展,走向模型即服务(MaaS)的未来,目前,AIGC 产业生态体系的雏形已现,呈现为上中下三层架构:

第一层,为上游基础层,也就是由预训练模型为基础搭建的 AIGC技术基础设施层。由于预训练模型的高成本和技术投入,因此具有较高的进入门槛。
以 2020 年推出的 GPT-3 模型为例Alchemy APl 创始人 Elliot Turner 推测训练 GPT-3 的成本可能接近 1200 万美元。
因此,目前进入预训练模型的主要机构为头部科技企业、科研机构等。目前在AIGC领域,美国的基础设施型公司(处于上游生态位)有OpenAl、Stability.ai等。
OpenAl的商业模式为对受控的 api调用进行收费。Stabilitv.ai以基础版完全开源为主,然后通过开发和销售专业版和定制版实现商业获利,目前估值已经超过 10 亿美金。因为有了基础层的技术支撑,下游行业才能如雨后春笋般发展,形成了目前美国的 AIGC 商业流。
第二层,为中间层,即垂直化、场景化、个性化的模型和应用工具。
预训练的大模型是基础设施,在此基础上可以快速抽取生成场景化、定制化、个性化的小模型,实现在不同行业、垂直领域、功能场景的工业流水线式部署,同时兼具按需使用、高效经济的优势。随着兼具大模型和多模态模型的AIGC模型加速成为新的技术平台,模型即服务(Model-as-a-Service,MaaS)开始成为现实,预计将对商业领域产生巨大影响。
Stable Diffusion 开源之后,有很多基于开源模型的二次开发,训练特定风格的垂直领域模型开始流行,比如著名的二次元画风生成的 Novel-Al,还有各种风格的角色生成器等。
第三层,为应用层,即面向C端用户的文字、图片、音视频等内容生成服务。
在应用层,侧重满足用户的需求,将 AIGC 模型和用户的需求无缝衔接起来实现产业落地。以 Stable Diffusion 开源为例,它开放的不仅仅是程序,还有其已经训练好的模型,后继创业者能更好的借助这一开源工具,以 C端消费级显卡的算力门槛,挖掘出更丰富的内容生态,为 AIGC 在更广泛的C端用户中的普及起到至关重要的作用。
现在贴近C端用户的工具越发丰富多样,包括网页、本地安装的程序、移动端小程序、群聊机器人等,甚至还有利用 AIGC工具定制代出图的内容消费服务。
目前,从提供预训练模型的基础设施层公司到专注打造 AIGC产品和应用工具的应用层公司,美国围绕 AIGC 生长出繁荣的生态,技术创新引发的应用创新浪潮迭起:中国也有望凭借领先的 AIGC 技术赋能千行百业。


随着数字技术与实体经济融合程度不断加深,以及互联网平台的数字化场景向元宇宙转型,人类对数字内容总量和丰富程度的整体需求不断提高。
AIGC作为当前新型的内容生产方式,已经率先在传媒、电商、影视、娱乐等数字化程度高、内容需求丰富的行业取得重大创新发展。市场潜力逐渐显现。与此同时,在推进数实融合、加快产业升级的进程中,金融、医疗、工业等各行各业的 AIGC 应用也都在快速发展。
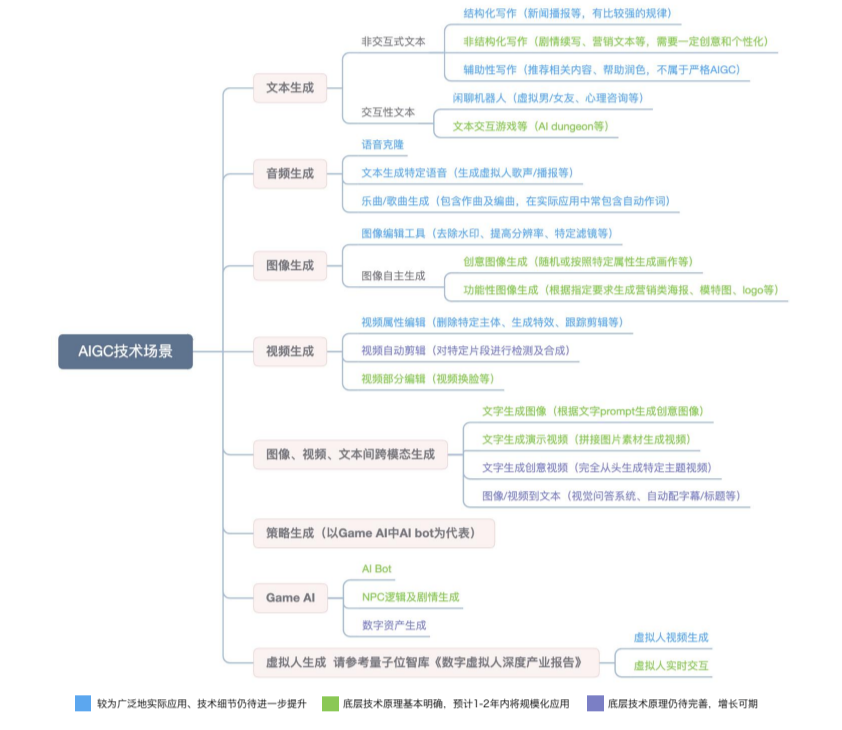
四、应用场景
可点击查看大图 ▼

文本生成

从现有的落地场景来看,我们将其划分为应用型文本和创作型文本生成,前者的进展明显优于后者。此外,从应用推广的角度来说,辅助文本创作是目前落地最为广泛的场景。
应用型文本生成
应用型文本大多为结构化写作,以客服类的聊天问答、新闻撰写等为核心场景。2015年发展至今,商业化应用已较为广泛,最为典型的是基于结构化数据或规范格式,在特定情景类型下的文本生成,如体育新闻、金融新闻、公司财报、重大灾害等简讯写作。据分析师评价,由AI完成的新闻初稿已经接近人类记者在30分钟内完成的报道水准。Narrative Science 创始人甚至曾预测,到 2030 年,90%以上的新闻将由机器人完成。
在结构化写作场景下,代表性垂直公司包括Automated Insights(美联社Wordsmith)、NarrativeScience、textenaine.io、AX Semantics、Yseop、Arria、Retresco、Viable、澜舟科技等。同时也是小冰公司、腾讯、百度等综合性覆盖AIGC领域公司的重点布局领域。
创作型文本生成
创作型文本主要适用于剧情续写、营销文本等细分场景等,具有更高的文本开放度和自由度,需要一定的创意和个性化,对生成能力的技术要求更高。
我们使用了市面上的小说续写、文章生成等AIGC工具。发现长篇幅文字的内部逻辑仍然存在较明显的问题、且生成稳定性不足,尚不适合直接进行实际使用。据聆心智能创始人黄民烈教授介绍,目前文字生成主要捕捉的是浅层次,词汇上统计贡献的问题。但长文本生成还需要满足语义层次准确,在篇章上连贯通顺的要求,长文本写作对干
议论文写作、公文写作等等具有重要意义。未来四到五年,可能会出现比较好的千字内容。
除去本身的技术能力之外,由于人类对文字内容的消费并不是单纯理性和基干事实的,创作型文本还需要特别关注情感和语言表达艺术。我们认为,短期内创作型文本更适合在特定的赛道下,基于集中的训练数据及具体的专家规则进行场景落地。
在创作型文本领域,代表性的国内外公司包括Anyword、Phrasee、Persado、Pencil、Copy.ai、Friday.ai、Retresco、Writesonic、Conversion.ai、Snazzy Al、Rasa.io、LongShot.Al、彩云小梦等。
文本辅助生成
除去端到端进行文本创作外,辅助文本写作其实是目前国内供给及落地最为广泛的场景。主要为基于素材爬取的协助作用,例如定向采集信息素材、文本素材预处理、自动聚类去重,并根据创作者的需求提供相关素材。尽管目前能够提升生产力,但我们认为相对于实现技术意义上的AI生成,能否结合知识图谱等提供素材联想和语句参考等更具有实用意义。
这部分的国内代表产品包括写作猫、Gilso写作机器人、Get写作、写作狐、沃沃AI人工智能写作。
- 重点关注场景
长期来看,我们认为闲聊型文本交互将会成为重要潜在场景,例如虚拟伴侣、游戏中的NPC个性化交互等。2022年夏季上线的社交AIGC叙事平台Hidden Door以及基干GPT 3开发的文本探索类游戏Aldungeon均已获得了不错的消费者反馈。
随着线上社交逐渐成为了一种常态,社交重点向转移AI具有其合理性,我们预估未来1-2年内就会出现明显增长。目前较为典型的包括小冰公司推出的小冰岛,集中在精神心理领域的聆心智能、开发了AIdungeon的Latitude.io等。
音频及文字—音频生成
整体而言,此类技术可应用于流行歌曲、乐曲、有声书的内容创作,以及视频、游戏、影视等领域的配乐创作,大大降低音乐版权的采购成本。我们目前最为看好的场景是自动生成实时配乐,语音克隆以及心理安抚等功能性音乐的自动生成。
TTS(Text-to-speech)场景
TTS在AIGC领域下已相当成熟,广泛应用于客服及硬件机器人、有声读物制作、语音播报等任务。例如倒映有声与音频客户端“云听”APP合作打造AI新闻主播,提供音频内容服务的一站式解决方案,以及喜马拉雅运用TTS技术重现单田芳声音版本的《毛氏三兄弟》和历史类作品。这种场景为文字内容的有声化提供了规模化能力。
目前技术上的的关键,在于如何通过富文本信息(如文本的深层情感、深层语义了解等)更好的表现其中的抑扬顿挫以及基于用户较少的个性化数据得到整体的复制能力(如小样本迁移学习》。基于深度学习的端到端语音合成模式也正在逐步替代传统的拼接及参数法,代表模型包括WaveNet、Deep Voice及Tacotron等。
目前的垂直代表公司包括倒映有声、科大讯飞、思必驰(DUl)、Readspeaker、DeepZen和Sonantic。
随着内容媒体的变迁,短视频内容配音已成为重要场景。部分软件能够基干文档自动生成解说配音,上线有150+款包括不同方言和音色的AI智能配音主播。代表公司有九锤配音、加音、XAudioPro、剪映等。
在TTS领域,语音克隆值得特别关注。语音克隆是本质上属于指定了目标语音(如特定发言人)的TTS。技术流程如下:

该技术目前被应用于虚拟歌手演唱、自动配音等,在声音IP化的基础上,对于动画、电影、以及虚拟人行业有重要意义。代表公司包括标贝科技、Modulate、overdub、replika、Replica Studios、Lovo、Voice mod.Resemble Ai、Respeecher、DeepZen、Sonantic、VoicelD、Descript。
乐曲/歌曲生成
AIGC在词曲创作中的功能可被逐步拆解为作词(NLP中的文本创作/续写)、作曲、编曲、人声录制和整体混音。目前而言,AIGC已经支持基于开头旋律、图片、文字描述、音乐类型、情绪类型等生成特定乐曲。
其中,AI作曲可以简单理解为“以语言模型(目前以Transformer为代表,如谷歌Megenta、OpenAlJukebox、AIVA等)为中介,对音乐数据进行双向转化(通过MIDI等转化路径)”。此方面代表性的模型包括MelodyRNN、Music Transformer。据Deepmusic介绍,为提升整体效率,在这一过程中,由于相关数据巨大往往需要对段落,调性等高维度的乐理知识进行专业提取,而节奏、音高、音长等低维度乐理信息由AI自动完成提取。

通过这一功能,创作者即可得到AI创作的纯音乐或乐曲中的主旋律。2021年末,贝多芬管弦乐团在波恩首演人工智能谱写完成的贝多芬未完成之作《第十交响曲》,即为AI基于对贝多芬过往作品的大量学习,进行自动续写。
Al编曲则指对AI基于主旋律和创作者个人的偏好,生成不同乐器的对应和弦(如鼓点、贝斯、钢琴等),完成整体编配。在这部分中,各乐器模型将通过无监督模型,在特定乐曲/情绪风格内学习主旋律和特定要素间的映射关系,从而基于主旋律生成自身所需和弦。对于人工而言,要达到乐曲编配的职业标准,需要7-10年的学习实践。
人声录制则广泛见于虚拟偶像的表演现场(前面所说的语音克隆),通过端到端的声学模型和神经声码器完成.
可以简单理解为将输入文本替换为输入MIDI数据的声音克隆技术。混音指将主旋律、人声和各乐器和弦的音轨进行渲染及混合,最终得到完整乐曲。该环节涉及的AI生成能力较少。
该场景下的代表企业包括Deepmusic、网易-有灵智能创作平台、Amper Music、AIVA、Landr、IBM、Watson Music、Magenta、Loudly、Brain.FM、Splash、Flow machines。其中,自动编曲功能已在国内主流音乐平台上线,并成为相关大厂的重点关注领域。以QQ音乐为例,就已成为Amper music的API合作伙伴。
对这一部分工作而言,最大的挑战在于音乐数据的标注。在标注阶段,不仅需要需要按时期、流派、作曲家等特征,对训练集中乐曲的旋律、曲式结构、和声等特征进行描述,还要将其有效编码为程序语言。此外,还需要专业人员基于乐理进行相关调整润色。以Deepmusic为例,音乐标注团队一直专注在存量歌曲的音乐信息标注工作上,目前已经形成了全球最精确的华语歌曲音乐信息库,为音乐信息检索(MIR)技术研究提供数据支持。
- 场景推荐
我们认为,以乐曲二创、辅助创作等场景为代表,Al编曲将在短期内成为AI音频生成中的快速成长赛道。特别是由于可以指定曲目风格、情绪、乐器等,AIGC音乐生成对干影视剧、游戏等多样化,乃至实时的背景音乐生成有重要意义。
图像生成
基于对不同技术原理的梳理,我们将图像生成领域的技术场景划分为图像属性编辑、图像局部生成及更改、以及端到端的图像生成。其中,前两者的落地场景为图像编辑工具,而端到端的图像生成则对应创意图像及功能性图像生成两大落地场景。
图像属性及部分编辑
属性编辑部分,可以直观的将其理解为经AI降低门槛的PhotoShop。目前而言,图片去水印、自动调整光影、设置滤镜(如Prisma、Versa、Vinci和Deepart)、修改颜色纹理(如DeepAl)、复刻/修改图像风格(DALL·E2已经可以仅凭借单张冬像进行风格复刻,NiahtCafe等)、提升分辨率等已经常见。
关于此类场景,初创公司数量庞大,Adobe等相关业务公司(Adobe Sensai)也在进入这一领域。我们认为,对于此类业务而言,引流渠道和与技术流程挂钩的产品使用体验非常重要。现有的代表公司包括美图秀秀(美图AI开放平台)、Radius5、Photokit、Imglarger、Hotpot、Remove.bg、Skylum (Mask Al)、Photodiva。
图像部分编辑部分,指部分更改图像部分构成(如英伟达CvcleGAN支持将图内的斑马和马进行更改)、修改面部特征(Metaphysics,可调节自身照片的情绪、年龄、微笑等;以Deepfake为代表的图像换脸)。由干技术限制,图像的各部分之间需要通过对齐来避免扭曲,伪影等问题,目前GAN还难以直接生成高质量的完整图像。2019年,曾宣传能够直接生成完整模特图的日本公司DataGrid目前已无动向。但同时,也出现了由局部生成并接为完整冬像的生成惠路。典型代表为选入CVPR2022的InsetGAN,该模型由Adobe推出。

同时,细粒度、分区域的图像编辑能力也较为关键,代表为英伟达的EditGAN。该模型将需要编辑的原图像x嵌入到EditGAN的潜空间,借助语义分割冬的相同潜码,将原冬x分割成高度精细的语义块(seamentation mask)并得到分割冬v。接着,使用简单的交互式数字绘画或标签工且进行手动修改。模型最终会共宣潜码的优化,以保持新分割图与真实图像的RGB外观一致。如图所示:

图像端到端生成
此处则主要指基于草图生成完整图像(VansPortrait、谷歌Chimera painter可画出怪物、英伟达GauGAN可画出风景、基于草图生成人脸的DeepFaceDrawing)、有机组合多张图像生成新图像(Artbreeder)、根据指定属性生成目标图像(如Rosebud.ai支持生成虚拟的模特面部)等。
该部分包含两类场景,分别为创意图像生成与功能性图像生成。前者大多以NFT等形式体现,后者则大多以营销类海报/界面、loao、模特图、用户头像为主。
垂直代表公司/产品包括Deepdream Generator、Rosebud.ai、AGahaku、artbreeder、nightcafe、starryai、wombo、deepart、obvious、阿里鹿班、ZMO.ai、Datagrid、诗云科技、道子智能绘画系统等。
由干冬像的生成复杂度远高干文字,在整体生成上,目前仍然难以达到稳定可靠的生成高质量图像。但据高林教授评价,人脸生成的应用将预计有更快的发展。从VAQ、VAE等技术选型开始,人脸生成的技术研究已经有了较好的效果,同时人脸数据集也较为充足。同时,单张的人脸生成价值相对有限。
要进一步发挥其价值,可以考虑将其与NeRE、也即3D内容生成相结合,支持从不同的视角和动作还原特定对象面部,能够在发布会、面见客户等场景中有重要作用。而对于近年视频换脸效果不佳的情况,高教授认为这与底层设计优化,例如除纹理相似度之外,在解编码中考虑更多的时间、动作、甚至情感等因素,并叠加考虑数据、渲染能力等因素。
视频生成
视频属性编辑
例如视频画质修复、删除画面中特定主体、自动跟踪主题剪辑、生成视频特效、自动添加特定内容、视频自动美颜等。代表公司包括RunwayML、Wisecut、Adobe Sensei、Kaleido、帝视科技、CCTV AIGC、影谱科技、Versa(不咕剪辑)、美图影像研究院等。
视频自动剪辑
其干视频中的画面,声音等多模态信息的特征融合进行学习,按照氛围,情绪等高级语义限定,对满足条件片段进行检测井合成。目前还主要在技术尝试阶段。典型案例包括Adobe与斯坦福共同研发的A视频重标系统、IBMWatson自动前标电影饰告片,以及Flow Machine。我国的影谱科技推出了相关产品,能够其干视频中的画面,声音等多模态信息的特征融合进行学习,按照氛围,情绪等高级语义限定,对满足条件片段进行检洳并合成。
视频部分生成(以Deepfake为典型代表)
技术原理:视频到视频生成技术的本质是其千目标图像或视频对源视频进行编辑及调试,通过其干语音等要素诼帧复刻,能够完成人脸替换,人脸再现人物表情或面部特征的改变),人脸合成(构建全新人物)其至全身合成,虚拟环境合成等功能。
其原理本质与图像生成类似,强调将视频切案成师,再对每一帧的图像进行外理。视频生成的流程通常可以分为三个步骤,即数据提取,数据训练及转换。以人脸合成为例,首先需要对源人物及目标人物的多角度特作数据提取,然后基于数据对模型进行训练并进行图像的合成,最后基干合成的图像将原始视频进行转换,即插入生成的内容并进行调试,确保每一帧之间的流程度及真实度。目前的技术正在提升修改精准度与修改实时性两方面。
落地分析
在我们看来,该场景的底层商业逻辑与虚拟偶像类似。本质上是以真人的肖像权作为演员,实际表演者承担“中之人”的角色。其主要落地场景包含两方面:
一方面,可以选择服务于明星,在多语言广告、碎片化内容生成等领域使用,快速提升明星的IP价值。例如Svnthesia 为SnoopDoaa制作的广告,通过使用deepfake改变其嘴部动作,就能够将原始广告匹配到另一品牌。
另一方面,则可以服务干特定商务场景,例如培训材料分发(如WPP的全球培训视频),素人直播及短视频拍摄等。
由于技术要求,需要对最终脸部所有者进行大量数据采集,需要相关从业公司获取大量面部数据授权,对针对市场需求进行相关运营,完善后续的配套监管和溯源措施。
除了deepfake之外,我们还观察到了在视频中的虚拟内容植入,也即利用计算机图形学和目标检测在视频中生成物理世界并不存在的品牌虚拟元素,如logo、产品、吉祥物等。以国外公司Marriad为代表,该公司目前已经为腾讯视频服务,后者准备在插入虚拟资产的基础上,个性化展示广告。这将极大的简化商业化内容的生成过程。
图像、视频、文本间跨模态生成
模态是指不同的信息来源或者方式。目前的模态,大多是按照信息媒介所分类的音频、文字、视觉等。而事实上.在能够导找到合适的载体之后,很多信息,诸如人的触觉、听觉、情绪、生理指标、甚至于不同传感器所对应的点云、红外线、电磁波等都能够变为计算机可理解可处理的模态。
对人工智能而言,要更为精准和综合的观察并认知现实世界,就需要尽可能向人类的多模态能力靠拢,我们将这种能力称为多模态学习MML(Multi-modal Learning),其中的技术分类及应用均十分多样。我们可以简单将其分为跨模态理解(例如通过结合街景和汽车的声音判断交通潜在危险、结合说话人的唇形和语音判定其说话内容)和跨模态生成(例如在参考其他图画的基础上命题作画:触景生情并创作诗歌等)。

Transformer架构的跨界应用成为跨模态学习的重要开端之一。
Transformer架构的核心是Self-Attention机制,该机制使得Transformer能够有效提取长序列特征,相较于CNN能够更好的还原全局。而多模态训练普遍需要将图片提取为区域序列特征,也即将视觉的区域特征和文本特征序列相匹配,形成Transformer架构擅长处理的一维长序列,对Transformer的内部技术架构相符合。
与此同时Transformer架构还且有更高的计算效率和可扩展性,为训练大型跨模态模型奠定了基础。Vision Transformer将Transformer架构首次应用于图像领域。该模型在特定大规模数据集上的训练成果超出了ResNet。
随后,谷歌的VideoBERT尝试了将Transformer拓展到“视频-文本”领域。该模型能够完成看图猜词和为视频生成字幕两项功能,首次验证了Transformer+预训练在多模态融合上的技术可行性。基于Transformer的多模态模型开始受到关注,ViLBERT、LXMERT、UNITER、Oscar等纷纷出现。
CLIP模型的出现,成为跨模态生成应用的一个重要节点。
CLIP.ContrastiveLanguage-Image Pre-training,由OpenAl在2021年提出,图像编码器和文本编码器以对比方式进行联合训练,能够链接文本和图片。可以简单将其理解为,利用CIP测定冬片和文本描述的贴切程度。
自CHP出现后,“CLP+其他模型”在跨模态生成领域成为一种较为通用的做法。以Disco Diffusion为例,该模型将CLIP模型和用于生成图像的Diffusion模型进行了关联。CLIP模型将持续计算Diffusion模型随机生成噪声与文本表征的相似度,持续迭代修改,直至生成可达到要求的图像。
除去图像领域,CLIP后续还在视频、音频、3D模型等领域扮演了关联不同模态的角色。例如入选CVPR2022.基于文本生成3D参像的Dreamfields(类似工作还包括CP-Forae)。不过目前,已经出现了在所需数据量和算力上表现更为优秀的匹配模型。例如南加州大学的TONICS。

在此基础上,大型预训练模型的发展重点开始向横跨文本、图像、语音、视频的全模态通用模型发展。通过计算策略、数据调用策略、深度学习框架等方法提升模型效果成为目前研究的进展关键。与此同时,覆盖更多模态的训练数据同样值得关注。例如,MultiBench提供了包括10个模态的数据集,PanoAVQA提供了360度视频数据,X-World提供用于自动驾驶的各类模态数据。目前,华为诺亚方舟已经开源了全球首个亿级中文多模态数据集“悟空”。
**跨模态大型预训练模型的代表包括:**开启了跨模态预训练模型的Open ALDALL·E及CLIP、NVIDIA GauGAN2.微软及北大 NÜWA女娲、NVIDIA PoEGAN、DeepMind的Gato、百度ERNIE-ViLG、Facebook及Meta 的AV-HuBERT(基于语音和唇语输出文本)及Data2vec(横跨CV、NIP和语音)、中科院“紫东太初”、哥大及Facebook开发的VX2Text(基干视频、音频等输出文本)。

多模态能力的提升将成为AI真正实现认知智能和决策智能的关键转折点。在未来1-2年,“文字一图像”的生成将快速落地。目前,“文字-视频”的生成也已有相对理想的实验效果,三个模态的跨模态生成也已经开始尝试。
接下来,我们将区分具体模态,对跨模态生成领域的代表模型进行介绍
文字生成图像
2021年,OpenAI的CLIP和DALLE开启了AI绘画重要的一年。同年,CVPR2021收录的VQGAN也引发了广泛关注。2022年被称为“AI绘画“之年,多款模型/软件证明了基于文字提示得到效果良好的图画的可行性,DiffusionModel受到广泛关注。
首先,OpenAI推出了GLIDE。GLIDE全称Guided Lanquage to Image Diffusion for Generation andEditing,是一种扩散模型,参数仅35亿。支持CLIP引导(经训练后的噪声感知64x64 ViT-L CLIP模型)和无分类器引导,支持部分P图和迭代生成。
随后为Disco Diffusion,该免费开源项目搭载在Google Colab上,需要一定的代码知识,更擅长梦境感的抽象田面,在具象生成和较多的描述语句上效果较差。随后,Disco Diffusion的作者之一推出了AI绘画聊天机器人Midiournev。该软件搭载在Discord上,商业化和产品化更为成熟,并提出了明确的分润模式(商业变现达到两万美金后需要20%分润)。
类似的软件及公司包括Bia Sleep、StarrvAl、WOMBO Dream。国内相关软件则包括Timmat,以及百度文心ERNIE-ViLG、小冰框架、悟道文澜、阿里M6等跨模态生成模型。
更擅长具象、对文本指令还原度更高的DALL。E2和Imagen Al证实了AI绘画的实际应用价值。但需要注意的是两者的技术思路并不相同。尽管扩散模型等引发了巨大关注,但不同的技术思路同样呈现出了较好效果。目前尚无法确定未来AI绘画的关键技术里程碑。


文字生成视频
在一定程度上,文本生成视频可以看作是文本生成图像的进阶版技术。我们预估,AI绘画和AI生成视频将分别在3年和5年后迎来较为广泛的规模应用。
一方面,两者的本质比较接近。文本生成视频同样是以Token为中介,关联文本和图像生成,逐帧生成所需图片,最后逐帧生成完整视频。而另一方面,视频生成会面临不同帧之间连续性的问题。对生成图像间的长序列建模问题要求更高,以确保视频整体连贯流程。从数据基础来看,视频所需的标注信息量远高于图像。
按照技术生成难度和生成内容,可以区分为拼凑式生成和完全从头生成两种方式。
拼凑式生成的技术是指基干文字(涉及NLP语义理解)搜索合适的配图、音乐等素材,在已有模板的参考下完成自动剪辑。这类技术本质是“搜索推荐+自动拼接”,门槛较低,背后授权素材库的体量、已有模版数量等成为关键因素。目前已经进入可商用阶段,国外有较为成熟的产品。代表公司/产品方面,2C的包括百度智能视频合成平台
VidPress,彗川智能,Gliacloud. Svnths video.lumen5.2B端代表公司为Pencil.

完全从头生成视频则是指由AI模型基于自身能力,不直接引用现有素材,生成最终视频。该领域目前仍处于技术尝试阶段,所生成视频的时长、清晰度、逻辑程度等仍有较大的提升空间。以Cogvideo为例.该模型基于预训练文本-图像模型CogView2打造,一共分为两个模块。第一部分先基于CogView2,通过文本生成几帧图像,这时候合成视频的帧率还很低;第二部分则会基于双向注意力模型对生成的几帧图像进行插帧,来生成帧率更高的完整视频。
由于从静态内容生成进入到了动态生成阶段,需要考虑其中时序性、连续性的问题。视频生成对于内容生成领域将具有节点性意义。同时,由于视频中会包括文本中难以表现的逻辑或尝试,相较于图像或纯文本训练,视频预训练模型有助于进一步释放语言模型的能力。
其他相关预训练模型还包括NVIDIA推出的GauGAN、微软亚洲研究院推出的GODIVA、清华及智源研究院提出的VideoGPT、TGAN、Ground Truth等。
图像/视频到文本
具体应用包括视觉问答系统、配字幕、标题生成等,这一技术还将有助于文本一图像之间的跨模态搜索。代表模型包括METER、ALIGN等。除了在各个模态之间进行跨越生成之外,目前,包括小冰公司在内的多家机构已经在究多模态生成,同时将多种模态信息作为特定任务的输入,例如同时包括图像内的人物、时间、地点、事件、动作及情感理解、甚至包含背后深度知识等。以保证生成结果更加精准。
策略生成
游戏AI
以腾讯AI Lab在游戏制作领域的布局为例,人工智能在游戏前期制作、游戏中运营的体验及运营优化、游戏周边内容制作的全流程中均有应用。
我们将其中的核心生成要素提炼为Al Bot、NPC相关生成和相关资产生成。

Al Bot,也即游戏操作策略生成。可以将其简单理解为人工智能玩家,重点在干生成真实对战策略。2016年Deepmind AlphaGO在围棋中有所展示,随后,AI决策在Dota2、StarCraft2、德扑、麻将等游戏领域中均展现出了良好的实力。
技术关键在于强化学习方案优化设计,体现为多智能体使用、可适应游戏/环境复杂度、具体策略多样性等。目前,包括网易在内的我国主流游戏公司已经形成共识,除去直接以陪玩等形式服务C端玩家,也在通过游戏跑图。
平衡度等方式服务于游戏开发/运营等B端。
相关业务场景
- 前期平衡性测试
游戏策划会根据具体的游戏内容,为角色本身的属性、技能、状态等,以及道具、环境、货币等参数,设定一系列的数值。平衡性测试能够充分地模拟玩家在某一套数值体系下的游戏体验,提出优化策略,为玩家带来更加平衡的多样性游戏交互。
之前需要在测试服上邀请人类玩家试玩1-2个月后才能得到结果。现在由AlBot直接在内部完成相关工作即可。
- 游戏跑图/功能测试
通过Albot针对性的找出游戏中所有交互的可能性,通过发现潜在漏洞辅助游戏策划
- 对局陪伴
包括平衡匹配、冷启动、玩家掉线接管等
- 特定风格模拟
在绝悟中,AI通过模仿职业选手,掌握他们的典型个人风格,玩家则感觉像在与真实的职业选手对抗
- 基于玩法教学的新型人机互动
在游戏内“绝悟试炼”玩法中,在玩家发出各种指令后,AI会根据而量、距离等实际情况,评估指令的合理性,选择执行或拒绝,身兼队友及老师,与玩家在真实对战环境中交流协作,并在过程中向玩家传授职业级的策略与操作技术,帮助玩家迅速熟悉英雄操作与游戏玩法。在引入王者绝悟AI教学后,玩家单局游戏主动沟通的次数有明显提升,提高了PVE玩法的可玩性。
代表机构:腾讯Al Lab (腾讯“绝悟”)
「绝悟、AI通过强化学习的方法来模仿真实玩家,包括发育、运营、协作等指标类别,以及每分钟手速、技能释放频率、命中率、击杀数等具体参数,让AI更接近正式服玩家真实表现,将测试的总体准确性提升到95%。
目前腾讯绝悟在环境观测、图像信息处理、探索效率等方面的创新算法已经突破了可用英雄限制(英雄池数量从40增为100),让 AI完全掌握所有英雄的所有技能并达到职业电竞水平,能应对高达10的15次方的英雄组合数变化。基干绝悟,王者荣耀的数值平衡性偏差已经从1.05%下降到0.68%,其所涉及的“多智能体”决策过程中,可以在高达 10 的 20000 次方种操作可能性的复杂环境中进行决策。
目前,腾讯AI Lab还与腾讯 Al Lab 还与王者荣耀联合推出了AI开放研究平台「开悟」,并积极举办相关赛事。
代表公司:超参数
估值已达独角兽,业内率先实现在3D FPS(游戏的帧数)领域的大规模商业化落地,服务对象包括数款千万级日活的游戏产品。超参数科技的AI服务已经为数款年流水超过10亿元的游戏产品贡献了巨大的商业价值,涵盖沙盒、开放世界、FPS、MOBA、休闲竞技等多个品类。
其Al Bot支持玩家陪玩、多人团队竞技、非完美信息博弈A,并提供了自研小游戏《轮到你了》中的虚拟玩家。目前,Albot已在多款千万日活的产品中上线:每日在线数峰值将近百万。游戏Al平台“Delta”三具备跨云调度超过50万核的计算能力,承载超过50万个AI并发在线:每天服务全球40余个国家的上亿玩家、提供数千亿次调用。
在我国,网易伏养,商汤科技也已在其业务布局中提及该部分业务。
NPC逻辑及剧情生成,也即由AI生成底层逻辑。此前,NPC具体的对话内容及底层剧情需要人工创造驱动脚本,由制作人主观联想不同NPC所对应的语言、动作、操作逻辑等,这种动态的个性化匹配背后依旧是不同的静态分支,创造性及个性化相对有限。
而以rct AI的智能NPC为例,其NPC能够分析玩家的实时输入,并动态地生成交互反应,从而构建几乎无限目不重复的剧情,增强自户体验并延长游戏生命周期。特别是在养成类游戏中,Al所提供的个性化生成能够带来画面,剧情及具体交互的个性化全新游戏体验。而实时剧情生成则有助于在特定框架内生成全新的可能性,增加游戏整体的叙事可能性。
虚拟数字人
虚拟数字人指存在于非物理世界(如图片、视频、直播、一体服务机、VR)中,并具有多重人类特征的综合产物。
目前“深度合成+计算驱动”型的虚拟人,综合运用文本、图像、音频等生成技术,打造综合外观、面部表情、发声习惯等产出全面拟人化的数字内容,属于AIGC领域。
此种多模态生成技术的聚合应用在虚拟偶像、虚拟主播等领域已有广泛应用。在《量子位虚拟数字人深度产业报告》中,我们将虚拟人按照产业应用划分为两种,即服务型虚拟人及身份型虚拟人。
计算驱动型/AIGC型虚拟人制作流程
1.设计形象:扫描真人形态及表演、采集驱动数据,利用多方位摄像头,对通用/特定模特进行打点扫描,采集其说话时的唇动、表情、面部肌肉变化细节、姿态等数据。
2.形象建模,进行绑定:设计所需的模型,或基于特定真人进行高还原度建模,进行关键点绑定。关键点绑定的数量及位置影响最终效果。
3.训练各类驱动模型:决定最终效果的核心步骤 利用深度学习,学习模特语音,唇形,表情参数间的潜在映射关系,形成各自的驱动模型与驱动方式。
充足的吸动关键占配合以精度较高的驱动模型,能够高还原度的复原人脸骨骼和肌肉的细微变化,得到逼真的表情驱动模型。
4.内容制作:基于输入的语音(或由输入文本转化的语音),预测唇动、表情等参数 核心的技术流程是基于输入的语音,或首先基于TTS技术(Text-to-speech,语音合成技术)。
将输入的本文转化为语音。基于语音,结合第3步得到的驱动模型,并利用生成对抗模型GAN选出最符合现实的图片,推理得到每帧数字人的图片。通过时间戳,将语音和每帧的数字人图片进行结合。
5.进行渲染,生成最终内容:直播时进行实时渲染。为保证在特定场景下能够实现实时低延迟渲染,计算框架的大小、算力供给等技术问题同样会影响到虚拟数字人的最终生成效果
综合来看,我们认为虚拟人生成代表着从文本/音频等低密度模态向图像/视频/实时交互等信息密度更高的模态的转化。其中,视频是短期的发展重点,而长期来看,乃至在元宇宙阶段,通过实时交互成为社交节点,都将是虚拟人重要的应用场景。
在AIGC领域,我们将虚拟人生成分为虚拟人视频生成和虚拟人实时互动。
虚拟人视频生成是目前计算驱动型虚拟人应用最为广泛的领域之一,不同产品间主要的区分因素包括:唇形及动作驱动的自然程度、语音播报自然程度、模型呈现效果(2D/3D、卡通/高保真等)、视频渲染速度等。
我们在此关注到了小冰公司与每日财经新闻合作的虚拟人实时直播,除虚拟人的自动生成外,还包括了摘要、图示、表格等的自动生成,在虚拟人的基础上,交付了更为完整的AIGC内容播报产品。此外,倒映有声的TTSA除虚拟人外,还包括整个画面中的素材呈现,相较于市面上嘴形、面部和身体律动的有限覆盖,虚拟人播报的整体效果也有所提升。
代表公司:倒映有声
一家以技术为核心的创新型公司和无人驱动数字分身技术解决方案供应商。通过自研神经渲染引整和TTSA技术,实现基于文本实时生成高质量语音(音频)和动画(视频)。
在试用了倒映有声的产品后。我们发现其虚拟人自然度高于市面产品,倒映有声将其归结于神经渲染(NeuralRendering)、TTSA(基于文本和语音合成实时生成音频和视频)、ETTS(富情感语音合成)、Diqital Twin(数字孪生)。通过神经渲染技术快速构建AI数字分身,通过语音+图像生成技术,生成和驱动教字分身的唇形、表情、动作、肢体姿态,创造表情自然,动作流畅,语音充满情感的高拟真度数字分身IP。
而虚拟人的实时互动则广泛应用于可视化的智能客服,多见于APP、银行大堂等。在AIGC的虚拟人领域,由于更能够体现AI在个性化、高并发性等方面的优势,我们更强调虚拟人的实时交互功能。我们可以将这一功能理解为以人为单位的数字变生,其中会进一步涉及思维及策略相关的生成。但由于文本生成的局限性,该场景目前只能适用于特定行业。
该领域的代表公司包括:HourOne.ai、Synthesia、Rephrase.ai、小冰公司、倒映有声、数字王国、影谱科技、科大讯飞、相芯科技、追一科技、网易伏羲、火山引擎、百度、搜狗等。
除了基干NLP进行问答外,以小冰公司和腾讯Alab(A虚拟人艾灵)为代表,部分公司也在尝试将不同的生成能力融合在虚拟人下,使虚拟人能够更好的融入现实世界。
以小冰公司的小冰框架为例,虚拟人不仅在人格化形式上涉及了虚拟面容生成,虚拟语音定制、交互等,并进一步被赋予了写诗、绘画、演唱、音乐创作等AI内容创作能力,以虚拟人为接口,对外提供全栈式的AIGC能力。
虚拟人及综合性AIGC代表公司:小冰公司
小冰是全球领先的人工智能科技公司,旗下小冰框架是全球承载交互量最大的完备人工智能框架之一,在开放域对话、多模态交互、超级自然语音、神经网络渲染及内容生成领域居于全球领先。
作为“Albeing”派虚拟人。小冰的产品始终是人+交互+内容。具体包括虚拟人(夏语冰等somebodyinstance、虚拟男友等nobodyinstance和国家队人工智能助判与教练系统观君等在乖直场景中工作的虚拟人类),音精生成(主攻超级语言及歌声,在线歌曲生成平台与歌手歌声合成软件Xstudio)、视觉创造(毕业作品集《或然世界》、为国家纺织品开发中心、万事利等数百家机构提供了图案和纹样设计)、文本创造(2017年即推出小冰诗集)、虚拟社交、Game Al(Xiaoice Game Studio)等。
商业客户已覆盖金融、智能车机、零售、体育、纺织、地产、文旅等十多个垂直领域,并提出了以“人力”的逻辑去进行商业报价的虚拟人商业模式。
如何系统的去学习大模型 ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容
:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容
:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容
:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容
:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓