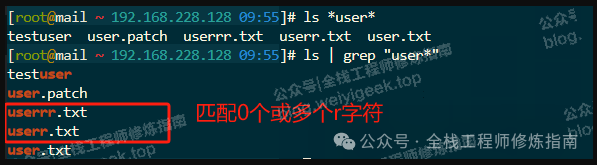
前言
本来有个500块钱的单子,用机器学习做一个不知道什么鸟的识别,正好有数据集,跑个小项目,过一下机器学习图像识别的流程,用很短的时间记录下来.....
一、数据预处理
将数据集分为训练集和测试集,直接使用sklearn库就行,这是一个机器学习的库,我就知道这么多,能用就用上,怎么用,组织好prompt问gpt就好了,也足够了.....
使用train_test_split了解了一个参数,想了两个问题,记录一下吧!
random_state=42是train_test_split函数中的一个参数,用于控制随机数生成器的种子。作用:
可重复性:设置随机种子后,每次运行代码时,数据集的划分结果(训练集和测试集的样本)都是相同的。这在调试和实验时非常重要,可以确保你得到一致的结果。
随机性:当你不设置
random_state(或者将其设为None)时,train_test_split每次运行可能会产生不同的训练集和测试集。这可能导致模型的性能评估不一致。为什么是42?
42 常被用作随机数生成的“宇宙的终极答案”,这个数字在编程和数学中有一种幽默的文化象征。实际上,你可以选择任何整数作为种子,使用相同的种子将得到相同的划分结果。因此,选择42只是一个约定,任何其他整数都可以达到相同的效果。
from sklearn.model_selection import train_test_split
import os
import numpy as np
import cv2
# 定义数据集的路径
dataset_path = './syh' # 替换为你的小狗图片数据集的路径
# 获取数据集中的所有图片文件名
all_images = [f for f in os.listdir(dataset_path) if f.endswith('.jpg') or f.endswith('.png')]
all_image_paths = [os.path.join(dataset_path, img) for img in all_images]
# 使用train_test_split将数据集分为训练集和测试集
train_images, test_images = train_test_split(all_image_paths, test_size=0.1, random_state=42)
print(train_images)
print(test_images) 二、提取特征和标签
二、提取特征和标签
这个代码注意一下几点:
1、提取特征点有很多种方法,由于之前搞过视觉slam,知道slam系统的原理所以知道一些,这里用的是ORB,是因为情怀,我第一个slam系统就是ORB-slam,大家也可以试试其他SIFT、SURF等等.....
2、因为任务是识别是不是就ok了,我的label是随机0和1,但是图片应该都是正标签,我懒得找负标签了,大家可以多种类的话,标签是文件夹名称就好了(要改一下数据预处理的代码哦),可以改一下试试......
3、描述子我只取了前100个展平,是因为在对高维度list列表进行转换时,里面的子列表长度不同导致转换成numpy的失败,后续可以试试弄一个很长的全是0的去填充,效果可能会好,毕竟“特征”多了嘛.....
# 提取特征和标签
def extract_features(image_paths):
features = []
labels = []
orb = cv2.ORB_create() # 创建ORB特征检测器
for img_path in image_paths:
img = cv2.imread(img_path) # 读取图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转为灰度图
keypoints, descriptors = orb.detectAndCompute(gray, None) # 提取关键点和描述符
if descriptors is not None: # 如果有描述符
# 仅保留前N个特征,或对描述符进行处理
features.append(descriptors[:100].flatten()) # 保留前100个描述符并展平
random_labels = np.random.randint(0, 2)
labels.append(random_labels) # 假设标签为文件名的前缀
return np.array(features), np.array(labels)
# 提取训练集和测试集的特征
X_train, y_train = extract_features(train_images)
print(X_train)
print(y_train)
X_test, y_test = extract_features(test_images)
print(X_test)
print(y_test)
三、定义模型、训练模型、推理模型
使用直接使用sklearn库,几行代码就ok了,刚开始学习的我建议,点进去看看源码(我没看过,有时间看看吧,不过估计过段时间就忘了,不会看的),根据自己掌握的原理,看看代码中模型是怎么定义的,用相同的数据集,可以看看这三个在图像识别上哪个效果好,有时候简单的任务可以直接用机器学习解决的最好用,就跟搞对象一样,合适才是最好的,哈哈哈!
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 定义并训练SVM分类器
svm_classifier = SVC(kernel='linear') # 使用线性核SVM
svm_classifier.fit(X_train, y_train) # 训练模型
y_pred_svm = svm_classifier.predict(X_test) # 对测试集进行预测
accuracy_svm = accuracy_score(y_test, y_pred_svm) # 计算准确率
print(f"SVM测试集准确率: {accuracy_svm * 100:.2f}%") # 输出准确率
# 定义并训练决策树分类器
dt_classifier = DecisionTreeClassifier() # 创建决策树分类器
dt_classifier.fit(X_train, y_train) # 训练模型
y_pred_dt = dt_classifier.predict(X_test) # 对测试集进行预测
accuracy_dt = accuracy_score(y_test, y_pred_dt) # 计算准确率
print(f"决策树测试集准确率: {accuracy_dt * 100:.2f}%") # 输出准确率
# 定义并训练KNN分类器
knn_classifier = KNeighborsClassifier(n_neighbors=3) # 使用KNN分类器,选择邻居数为3
knn_classifier.fit(X_train, y_train) # 训练模型
y_pred_knn = knn_classifier.predict(X_test) # 对测试集进行预测
accuracy_knn = accuracy_score(y_test, y_pred_knn) # 计算准确率
print(f"KNN测试集准确率: {accuracy_knn * 100:.2f}%") # 输出准确率