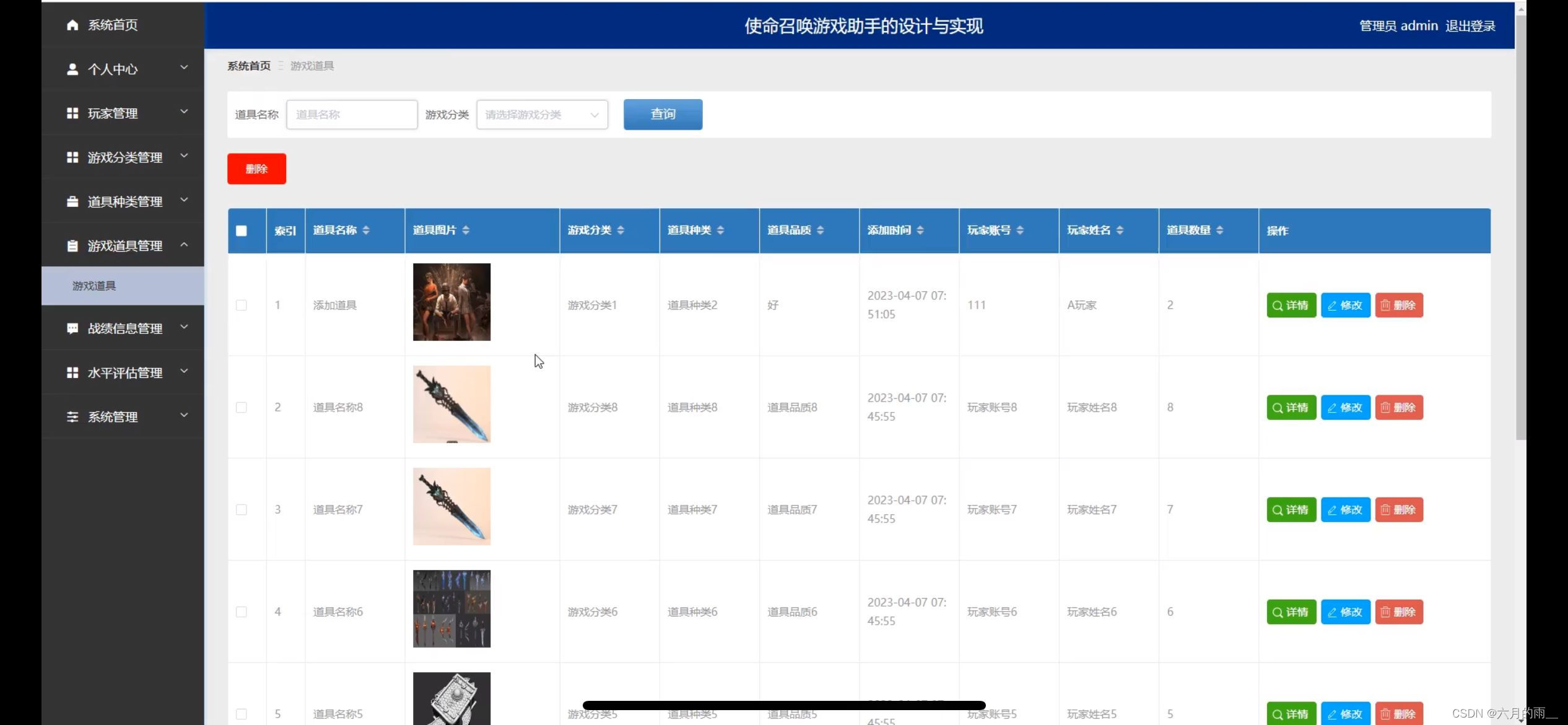
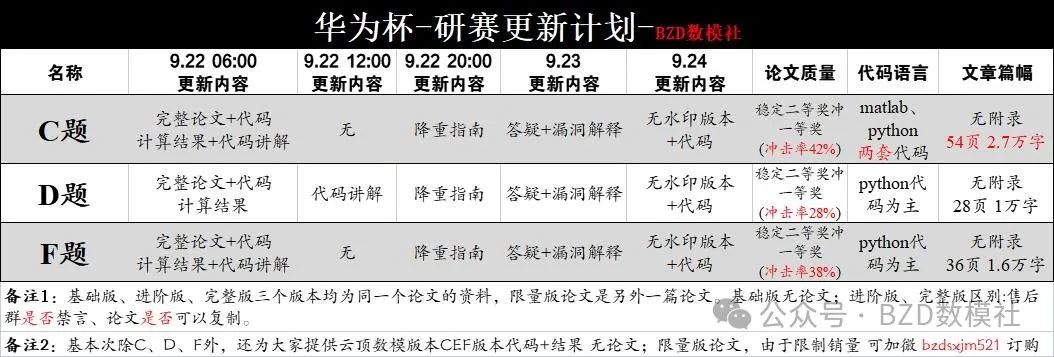
本届研赛助攻题目 C D F三题论文均已经全部完成。后更新计划 如图所示。
免费给大家分享 三个问题的论文+部分代码
2024年华为杯-研赛分享资料(论文+部分代码)(已更新部分代码):
链接:https://pan.baidu.com/s/1HGIYjV3lqzUc_3H0vg5H8w
提取码:sxjm

中国研究生创新实践系列大赛
“华为杯”第二十一届中国研究生
数学建模竞赛
题 目: 大数据驱动的地理综合问题
摘 要:
地理系统是自然、人文多要素综合作用的复杂巨系统,地理学家常用地理综合的方式对地理系统进行主导特征的表达,本文利用大数据的手段对地理系统进行综合,探索全球气候变化下中国地理环境的演化。
针对问题一,本文首先对数据进行清洗,替换一些取值较大或较小的特殊值,并利用准则确定一些离群点,然后使用数字、图表等方式,对原始数据进行定量总结、概括,得出了一些降水量、土地利用/土地覆被面积两个变量的在1990至2020年间中国范围内的时空演化特征。
针对问题二,首先利用逻辑回归模型量化地形-气候相互作用在极端天气形成过程中的作用,再用格兰杰因果检验和斯皮尔曼相关系数加以检验,确定它们之间的相互作用,验证了本文模型建立的有效性,为后文预测的准确性奠定基础。
针对问题三,首先对题目中提到的自变量进行量化,建立逻辑回归模型,再利用移动平均线模型和LSTM神经网络进行预测,将预测的数据代入前面建立的逻辑回归模型进行降水量的预测,利用不同的成灾临界值可确定不同的防范政策。若需要推
关键词:逻辑回归;LSTM;大数据可视化;格兰杰因果检验;斯皮尔曼相关系数
三、模型假设
1、假设所有使用的气象、地形和土地利用数据都是准确和可靠的。
2、假设在研究期间内,中国的地形变化不大,可以认为是稳定的。
3、假设在未来预测期间,现有的社会经济发展趋势和政策导向将持续
4、在模型中,假设人类活动对土地利用变化的影响可以通过现有数据进行合理估计,并在模型中得到体现。
五、模型建立与求解
5.1 数据清洗
对于数据集3,数据集中将中国以外的经纬度上的降水量数据均设为了-99.9,在后续数据处理中,因问题一中需要建立统计指标与统计图表,将-99.9设为0,防止这些数据对一些边界地区的降水量指标造成影响。对于人口、GDP等数据的处理方式相同,将其中的-NAN或NAN替换为0.
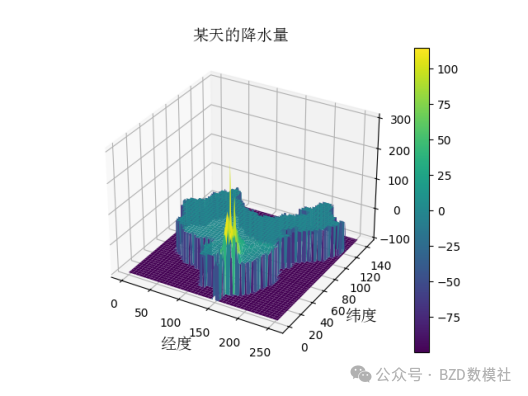
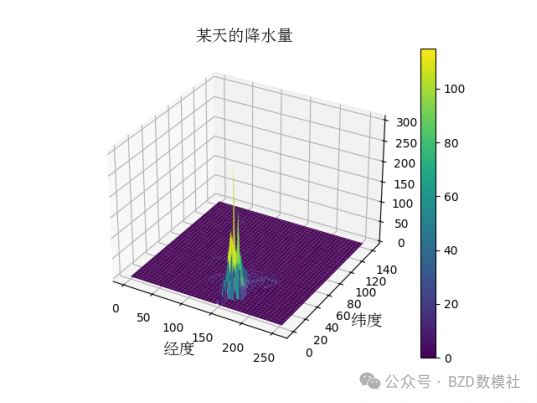
图1 数据集3中取某一天的降水量的可视化
利用Python进行编程将负值设为0,并进行可视化后的结果可见图2。将NetCDF文件中的数据daily precipitation也即pre的数据取出转化为矩阵的形式,利用准则对异常数据进行分析,此时并不进行剔除,在问题二和三中对“暴雨”和“成灾”界定后再进行剔除。于此同时,对于其他数据集的如GDP、人口、地形、气温,土地利用和覆盖,以每一年为一个样本,利用准则对异常数据进行分析并剔除。
5.2 问题一模型的建立与求解
5.2.1 问题一模型的建立与求解
首先对这降水量在1990至2020年间中国范围内的时空演化特征进行描述和总结,首先固定空间分析该变量随时间变化的趋势,
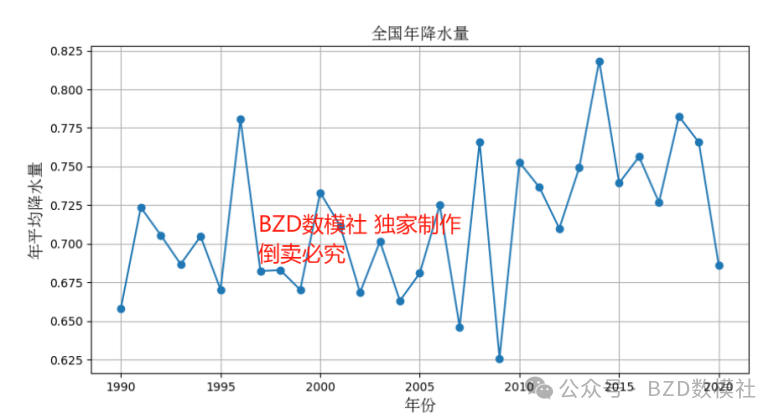
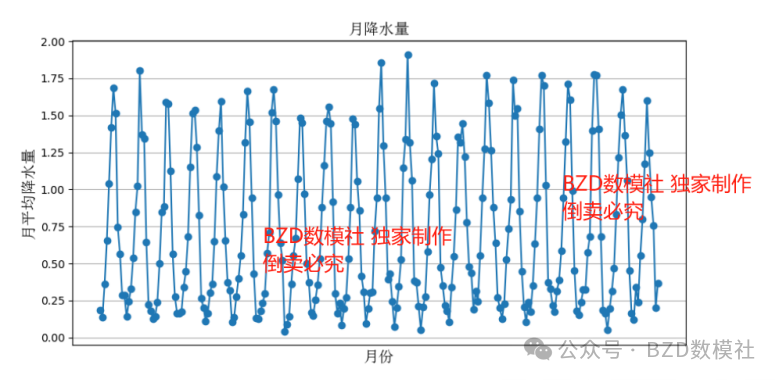
从波动来看最大值与最小值的差距并不是特别明显,每年基本上都维持在当地的一个平均水平上。但从月降水量的波动来看,全国的月降水量明显呈现出季节趋势,存在着明显的波峰与波谷。(为降重考虑,大家可以自行补充语文描述,分析全国的降雨量随时间的变化趋势)
表1 固定的地区的经纬度范围
| 经度 | 纬度 | |
| 山东省 | 114.8 - 122.7 | 34.37 - 39.4 |
| 北京市 | 115.4 - 117.5 | 39.4 - 41.0 |
| 西藏自治区 | 78.3 - 99.1 | 26.8 - 36.4 |
| 吉林省 | 121.6 - 131.3 | 40.8 - 46.3 |
| 江苏省 | 116.3 - 121.9 | 30.8 - 35.1 |
| 四川省 | 97.3 - 108.5 | 26.0 - 34.3 |
根据表1,计算特定地区的年降水量,见下图,从各个省份或城市的降水量波动来看,与年降水量变化时一致的,最大值与最小值的差距并不是特别明显,每年基本上都维持在当地的一个平均水平上。但不同地区的年降水量就截然不同,可以明显的看出南方的省份和城市降水量要明显高于其他地区的城市。