并查集简要介绍:
我们先讲并查集的一般使用场景,之后再讲并查集的具体细节以及原理。
并查集的使用一般是如下的场景:
- 一开始每个元素都拥有自己的集合,在自己的集合里只有这个元素自己。
- f i n d ( i ) find(i) find(i):查找 i i i所在集合的代表元素,代表元素来代表 i i i所在的集合。
- b o o l i s S a m e S e t ( a , b ) bool ~isSameSet(a,b) bool isSameSet(a,b):判断 a a a和 b b b在不在一个集合里。
- v o i d u n i o n ( a , b ) void ~union(a,b) void union(a,b): a a a所在集合所有元素 与 b b b所在集合所有元素 合并成一个集合。
- 各种操作单次调用的均摊时间复杂度为 O ( 1 ) O(1) O(1)。
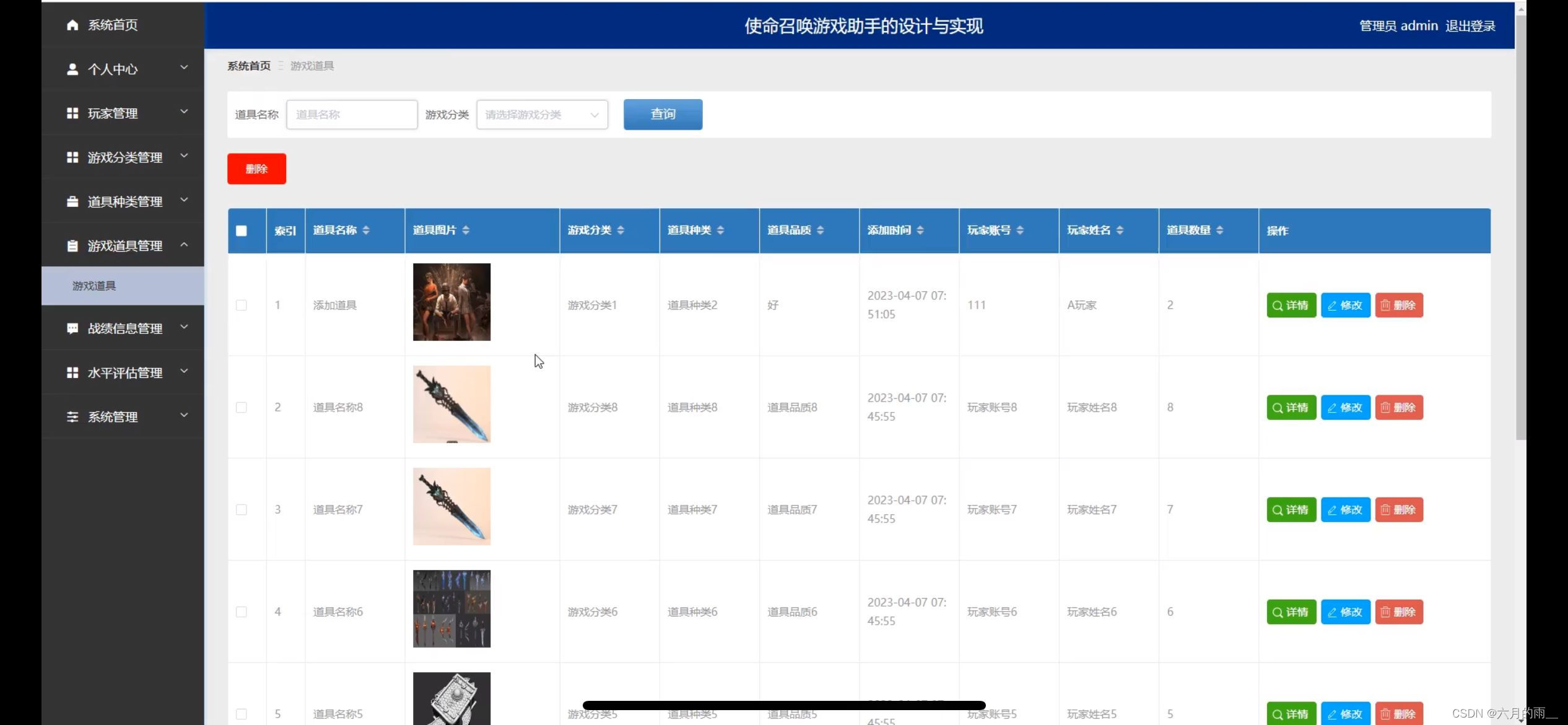
并查集的原理也比较简单,看下面原理图解就明白了:

这张图清晰地表现了 u n i o n union union操作的原理,我们很容易分析出来,时间复杂度是 O ( 1 ) O(1) O(1),两个集合进行合并,本质上就是两个集合的代表元素进行合并,如上图,我们选了集合2代表元素d作为新集合代表,那么集合1代表元素d就要解除自环并指向d,d仍然保持自环。

f i n d ( i ) find(i) find(i)操作就是从元素 i i i开始沿着指针向上找,当找到自环元素时,说明找到了 i i i元素所在集合的代表元素,这个代表元素就是我们要找的结果。
i s S a m e S e t ( a , b ) isSameSet(a,b) isSameSet(a,b)操作就是找 a a a和 b b b分别所在集合的代表元素,如果两个元素所在集合的代表元素相同,则说明这两个元素在同一个集合里。
并查集的数组实现
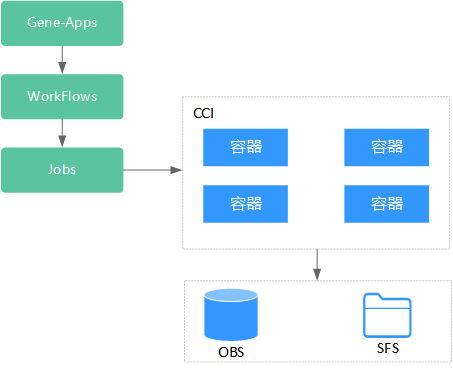
在前两张图中,最明显的是我们使用了指针这个概念,我的第一反应是用链表去实现并查集,但是链表查找起来太麻烦了,参考链表的静态数组实现,我们对并查集也有对应的数组实现。
并查集数组实现方式的关键成员:
int father[]: f a t h e r [ i ] father[i] father[i]中存储的是元素i的父元素 j j j,也就是说并查集中存在关系 i − > j i -> j i−>j 。int size[]: s i z e [ i ] size[i] size[i]中存储的是元素 i i i所代表的集合的元素个数,用于 u n i o n ( ) union() union()函数中进行小挂大优化,小集合挂载到大集合下。int stack[]: s t a c k [ ] stack[] stack[]用于 F i n d ( i ) Find(i) Find(i)函数中,对数据进行扁平化处理。
扁平化处理原理如下图:
上图中是一个比较极端的并查集,现在我们依次找 a , b , c , d , e , f , g a,b,c,d,e,f,g a,b,c,d,e,f,g 的代表元素,如果我们不做扁平化处理,只利用简单循环去做的话,需要找 7 + 6 + 5 + 4 + 3 + 2 + 1 7+6+5+4+3+2+1 7+6+5+4+3+2+1次,而做了扁平化处理的话,中间某个节点被重复遍历的次数就会减少,最优情况下,只需要找7次。这个最优情况也就是一开始就找最底层元素 a a a的代表元素。
$ Problem1 $ 并查集的实现 牛客
https://www.nowcoder.com/practice/e7ed657974934a30b2010046536a5372
描述
给定一个没有重复值的整形数组arr,初始时认为arr中每一个数各自都是一个单独的集合。请设计一种叫UnionFind的结构,并提供以下两个操作。
boolean isSameSet(int a, int b): 查询a和b这两个数是否属于一个集合void union(int a, int b): 把a所在的集合与b所在的集合合并在一起,原本两个集合各自的元素以后都算作同一个集合
[要求]
如果调用isSameSet和union的总次数逼近或超过O(N),请做到单次调用isSameSet或union方法的平均时间复杂度为O(1)
输入描述:
第一行两个整数N, M。分别表示数组大小、操作次数
接下来M行,每行有一个整数opt
若opt = 1,后面有两个数x, y,表示查询(x, y)这两个数是否属于同一个集合
若opt = 2,后面有两个数x, y,表示把x, y所在的集合合并在一起
输出描述:
对于每个opt = 1的操作,若为真则输出"Yes",否则输出"No"
示例1
输入:
4 5
1 1 2
2 2 3
2 1 3
1 1 1
1 2 3
输出:
No
Yes
Yes
说明:
每次2操作后的集合为
({1}, {2}, {3}, {4})
({1}, {2, 3}, {4})
({1, 2, 3}, {4})
套用并查集模板即可,解决代码如下:
#include<cstdio>
#include <iostream>
#include <vector>
using namespace std;
int MAXN = 1000000;
vector<int> father(MAXN);
vector<int> setSize(MAXN);
vector<int> stack(MAXN); // 利用栈进行扁平化处理
void build(int N) {
for (int i = 0; i < N; i++) {
father[i] = i;
setSize[i] = 1;
}
}
int Find(int i) {
int Size = 0;
while (father[i] != i) {
stack[Size++] = i;
i = father[i];
}
// 沿途节点收集完毕,找到代表元素,同时也是栈中所有元素的代表元素
while (Size > 0) {
father[stack[--Size]] = i;
}
return i;
}
void Union(int x, int y) {
int fx = Find(x);
int fy = Find(y);
if (fx != fy) {
if (setSize[fx] > setSize[fy]) {
setSize[fx] += setSize[fy];
father[fy] = fx;
} else {
setSize[fy] += setSize[fx];
father[fx] = fy;
}
}
}
bool isSameSet(int x, int y) {
return Find(x) == Find(y);
}
int main() {
int N, M;
scanf("%d", &N);
scanf("%d", &M);
build(N);
vector<vector<int>> Edge(M, vector<int>(3));
for (int i = 0; i < M; i++) {
int opt, x, y;
scanf("%d", &opt);
scanf("%d", &x);
scanf("%d", &y);
Edge[i][0] = opt;
Edge[i][1] = x;
Edge[i][2] = y;
}
for (int i = 0; i < M; i++) {
if(Edge[i][0] == 1){
if(isSameSet(Edge[i][1],Edge[i][2])){
printf("Yes\n");
}else{
printf("No\n");
}
}
if(Edge[i][0] == 2){
Union(Edge[i][1], Edge[i][2]);
}
}
return 0;
}
并查集的小挂大操作在一些场景中是不必要的,对于不进行小挂大操作,我们有另一种实现并查集的方式,用下面这个例子来给你详细说明。
P
r
o
b
l
e
m
2
Problem2
Problem2 【模板】并查集 洛谷P3367
如题,现在有一个并查集,你需要完成合并和查询操作。
第一行包含两个整数 N , M N,M N,M ,表示共有 N N N 个元素和 M M M 个操作。
接下来 M M M 行,每行包含三个整数 Z i , X i , Y i Z_i,X_i,Y_i Zi,Xi,Yi 。
当 Z i = 1 Z_i=1 Zi=1 时,将 X i X_i Xi 与 Y i Y_i Yi 所在的集合合并。
当
Z
i
=
2
Z_i=2
Zi=2 时,输出
X
i
X_i
Xi 与
Y
i
Y_i
Yi 是否在同一集合内,是的输出 Y ;否则输出 N 。
输出格式
对于每一个
Z
i
=
2
Z_i=2
Zi=2 的操作,都有一行输出,每行包含一个大写字母,为 Y 或者 N 。
输入:
4 7
2 1 2
1 1 2
2 1 2
1 3 4
2 1 4
1 2 3
2 1 4
输出
N
Y
N
Y
提示
对于 30 % 30\% 30% 的数据, N ≤ 10 N \le 10 N≤10, M ≤ 20 M \le 20 M≤20。
对于 70 % 70\% 70% 的数据, N ≤ 100 N \le 100 N≤100, M ≤ 1 0 3 M \le 10^3 M≤103。
对于 100 % 100\% 100% 的数据, 1 ≤ N ≤ 1 0 4 1\le N \le 10^4 1≤N≤104, 1 ≤ M ≤ 2 × 1 0 5 1\le M \le 2\times 10^5 1≤M≤2×105, 1 ≤ X i , Y i ≤ N 1 \le X_i, Y_i \le N 1≤Xi,Yi≤N, Z i ∈ { 1 , 2 } Z_i \in \{ 1, 2 \} Zi∈{1,2}。
#include <cstdio>
#include <iostream>
#include <vector>
using namespace std;
int MAXN = 1000000;
vector<int> father(MAXN);
void build(int N) {
for (int i = 1; i <= N; i++) {
father[i] = i;
}
}
int Find(int i) {
// 利用堆栈进行扁平化处理
if (i != father[i]) {
father[i] = Find(father[i]);
}
return father[i];
}
void Union(int x, int y) { father[Find(x)] = Find(y); }
bool isSameSet(int x, int y) { return Find(x) == Find(y); }
int main() {
int N, M;
scanf("%d", &N);
scanf("%d", &M);
build(N);
vector<vector<int>> Edge(M, vector<int>(3));
for (int i = 0; i < M; i++) {
int opt, x, y;
scanf("%d", &opt);
scanf("%d", &x);
scanf("%d", &y);
Edge[i][0] = opt;
Edge[i][1] = x;
Edge[i][2] = y;
}
for (int i = 0; i < M; i++) {
if (Edge[i][0] == 2) {
if (isSameSet(Edge[i][1], Edge[i][2])) {
printf("Y\n");
} else {
printf("N\n");
}
}
if (Edge[i][0] == 1) {
Union(Edge[i][1], Edge[i][2]);
}
}
return 0;
}
P
r
o
b
l
e
m
3
Problem3
Problem3 情侣牵手LeetCode765
n 对情侣坐在连续排列的 2n 个座位上,想要牵到对方的手。
人和座位由一个整数数组 row 表示,其中 row[i] 是坐在第 i 个座位上的人的 ID。情侣们按顺序编号,第一对是 (0, 1),第二对是 (2, 3),以此类推,最后一对是 (2n-2, 2n-1)。
返回 最少交换座位的次数,以便每对情侣可以并肩坐在一起。 每次交换可选择任意两人,让他们站起来交换座位。
示例 1:
输入: row = [0,2,1,3]
输出: 1
解释: 只需要交换row[1]和row[2]的位置即可。
示例 2:
输入: row = [3,2,0,1]
输出: 0
解释: 无需交换座位,所有的情侣都已经可以手牵手了。
提示:
2n == row.length2 <= n <= 30n是偶数0 <= row[i] < 2nrow中所有元素均无重复
问题分析:
乍一眼看去,这道题好像和并查集扯不上关系,这种一眼看过去并不能快速反应出来需要使用哪种算法的题需要我们仔细地去分析,去挖掘其中的数学关系。
我们先枚举几个简单的例子来看看题目具体情况:
如果只有1对情侣在2个座位上,那么他们一定是并肩坐在一起的,
如果2对情侣坐在4个座位上(没有任何一对情侣坐在一起),那么我们只需要交换1次。

如果3对情侣坐在6个座位上,那么我们只需要交换2次。

由于座位一直是 2 n 2n 2n个, n n n对情侣最终要并肩坐在一起,我们就可以形象地表示成 最终n对情侣都坐在各自的沙发上。
现在继续往下分析,如果 n n n对情侣分别坐在 n n n个沙发上(并且没有任何一对情侣坐在同一张沙发上),我们需要交换几次呢?
我们从第一张沙发开始分析,要想让第一张沙发中的两个人 a , b a,b a,b坐上一对情侣,可以让第一张沙发中的其中一人(假设让b)和 a a a的男(女)朋友进行交换,这样第一张沙发就安排好了,现在安排第二张沙发,继续同样的操作,一直这样下去做 n − 2 n-2 n−2次操作,最终只剩下最后两张沙发,最后两张沙发只要再做一次交换操作就好了。
所以我们可以得出结论:
【结论1】如果有 K K K对情侣混坐在一起,那么我们至少需要 K − 1 K-1 K−1次交换操作。
所以现在所有情侣的情况如下:
N 1 N_1 N1对情侣混坐在一起, N 2 N_2 N2对情侣混坐在一起, … , N r N_r Nr对情况混坐在一起,
剩余对情侣都是配对好了的。
按照结论1,我们最终的结果是 N 1 + N 2 + N 3 + N 4 + . . . + N r − r N_1 + N_2 + N_3 + N_4 + ... + N_r - r N1+N2+N3+N4+...+Nr−r, N 1 N_1 N1对情况混坐在一起我们将其看成集合 A 1 A_1 A1, N 2 N_2 N2对情况混坐在一起我们将其看成集合 A 2 A_2 A2, …, N r N_r Nr对情侣混坐在一起我们将其看成集合 A r A_r Ar。最朴素的想法是求出这 r r r个集合分别的元素个数,之后累加再 − r -r −r。
注意,这里每个集合的元素个数是情侣对数,现在就剩下一个问题了,怎么判断 N N N对情侣混坐在一起?
为了简单化,我们把一对一对情侣进行编号:第0对:0,1;第1对:2,3…;第n对, 2 ∗ n 2*n 2∗n, 2 ∗ n + 1 2*n + 1 2∗n+1。所以 i i i会出现两次,情侣两人各出现一次。现在我将原来的编号转化为情侣对数编号并将混在一起的情侣进行合并,原理如下图:
合并结束之后,我们就可以利用并查集来找那些集合中元素大于1个的集合。
for(int i = 0;i < n;i++){
if(father[i] == i){
if(size[i] > 1){
result += size[i] - 1;
}
}
}
但是利用循环去找太浪费时间了,我们继续分析,这个
N
1
+
N
2
+
N
3
+
.
.
.
+
N
r
N_1 + N_2 + N_3 + ... + N_r
N1+N2+N3+...+Nr加起来是没有坐在一起的情侣的总对数,剩下的情侣都是坐在一起的,我们记坐在一起的情侣有
N
s
N_s
Ns对,那么
N
1
+
N
2
+
N
3
+
.
.
.
+
N
r
+
N
s
=
情侣总对数
n
N_1 + N_2 + N_3 + ... + N_r + N_s = 情侣总对数n
N1+N2+N3+...+Nr+Ns=情侣总对数n
而
N
s
N_s
Ns对情侣都是单独坐好的,在并查集中表现为
N
s
N_s
Ns个元素个数为1的集合,所以
N
1
+
N
2
+
N
3
+
.
.
.
+
N
r
−
r
=
N
1
+
N
2
+
N
3
+
.
.
.
.
+
N
r
+
N
s
−
r
−
N
s
=
n
−
(
r
+
N
s
)
=
n
−
s
e
t
s
N_1 + N_2 + N_3 +... + N_r - r \\ = N_1 + N_2 + N_3 + .... + N_r + N_s - r -N_s\\ = n - (r + N_s)\\ = n - sets
N1+N2+N3+...+Nr−r=N1+N2+N3+....+Nr+Ns−r−Ns=n−(r+Ns)=n−sets
s
e
t
s
sets
sets指的是并查集中的集合个数。
最终处理方法:
先对并查集初始化,有 n n n对情侣嘛,一开始都未入座时,情侣肯定是两两一对的,所以有n个集合。
void build(int n){
for(int i = 0 ; i < n;i++){ //情侣编号从0开始的
father[i] = i;
}
sets = n;
}
最终解决代码:
class Solution {
public:
std::vector<int> father; // 不直接初始化大小
int sets; // 表示并查集中集合个数
// 构造函数
Solution() {
father.resize(30); // 可以在构造函数中调整大小
}
void build(int N) {
for (int i = 0; i < N; i++) {
father[i] = i;
}
sets = N;
}
int find(int x) {
if (x != father[x]) {
father[x] = find(father[x]);
}
return father[x];
}
void Union(int x,
int y) { // 一张沙发上的两人不是情侣,则说明混在一起,将集合合并
int fx = find(x);
int fy = find(y);
if (fx != fy) {
father[fx] = fy;
sets--;
}
}
int minSwapsCouples(vector<int>& row) {
int N = row.size() / 2;
build(N);
for (int i = 0; i < N; i++) {
Union(row[2*i] / 2, row[2*i + 1] / 2);
}
return N - sets;
}
};
这道题的问题分析写得不是很好,同学们可以去看左程云老师的【并查集(上)】课程视频,看完视频后再看我的解析,应该就能明白我在讲什么了。
P
r
o
b
l
e
m
4
Problem4
Problem4 相似字符串组 LeetCode839
如果交换字符串 X 中的两个不同位置的字母,使得它和字符串 Y 相等,那么称 X 和 Y 两个字符串相似。如果这两个字符串本身是相等的,那它们也是相似的。
例如,"tars" 和 "rats" 是相似的 (交换 0 与 2 的位置); "rats" 和 "arts" 也是相似的,但是 "star" 不与 "tars","rats",或 "arts" 相似。
总之,它们通过相似性形成了两个关联组:{"tars", "rats", "arts"} 和 {"star"}。注意,"tars" 和 "arts" 是在同一组中,即使它们并不相似。形式上,对每个组而言,要确定一个单词在组中,只需要这个词和该组中至少一个单词相似。
给你一个字符串列表 strs。列表中的每个字符串都是 strs 中其它所有字符串的一个字母异位词。请问 strs 中有多少个相似字符串组?
示例 1:
输入:strs = ["tars","rats","arts","star"]
输出:2
示例 2:
输入:strs = ["omv","ovm"]
输出:1
问题分析:
这道题和** P r o b l e m 3 Problem3 Problem3 情侣牵手问题**很相似,都是先判断两个元素是否有一定关系,如果有关系,则将两个元素所在集合合并,如果没有关系,则不合并。
在 P r o b l e m 3 Problem3 Problem3中,同一张沙发上的两个人如果不是一对情侣,那么就将两个人分别所在的集合合并,表示 编号 A 编号A 编号A情侣两人和 编号 B 编号B 编号B情侣两人混坐在一起。如果是一对情侣,我们也做出了 将两人分别所在集合合并 操作,一对情侣中两人的情侣编号相同(假设为 K K K), K K K与 K K K合并之后还是 K K K,相当于 K K K所在集合中只有 K K K,类似于** K K K与其他集合不进行合并**。
回到 P r o b l e m 4 Problem4 Problem4,和 P r o b l e m 3 Problem3 Problem3一样,我们在初始状态把各个字符串都放在自己单独的集合里,如果两个字符串相似,再将两个字符串所在集合合并。有一点不同的是,如果字符串 s t r i n g A stringA stringA单独所在集合最终与集合 s e t A setA setA合并,只需要和 s e t A setA setA中的其中一个字符串相似即可,所以我们需要遍历集合 s e t A setA setA。所以我们可以按照数组顺序来合并集合。
解决代码:
int MAXN = 3000;
vector<int> father;
int sets;
Solution() { father.resize(MAXN); }
void build(int N) {
for (int i = 0; i < N; i++) {
father[i] = i;
}
sets = N;
}
int find(int x) {
if (x != father[x]) {
father[x] = find(father[x]);
}
return father[x];
}
void Union(int x, int y) {
int fx = find(x);
int fy = find(y);
if (fx != fy) {
father[fx] = fy;
sets--;
}
}
// 判断两个字符串是否相似,两处字符不同则为相似
bool isSimilar(string a, string b) {
int length = a.size();
int diff = 0;
for (int i = 0; i < length && diff < 3; i++) {
if (a[i] != b[i]) {
diff++;
}
}
return diff == 2 || diff == 0;
}
int numSimilarGroups(vector<string>& strs) {
int N = strs.size();
build(N);
// 对每个字符串进行遍历,并与排在它前面的字符串进行比较
for(int i = 1; i < N; i++){
for(int j = 0; j < i; j++){
if(isSimilar(strs[i],strs[j])){
Union(i,j);
}
}
}
return sets;
}
P
r
o
b
l
e
m
5
Problem5
Problem5 岛屿数量 LeetCode200
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1
问题分析:
这道题和前面几题一样,都是用并查集一直合并集合,最终拿到最后所剩的集合数,也就是岛屿的数量。
值得一提的是,我们对每个由单个字符串构成的集合的遍历是有顺序的,在第二题中,我们是对数组从左到右逐个遍历,只有按照顺序来,遍历过的字符串的最终集合才能确定下来。这道题同样如此,只有按照行从上到下,列从左到右的遍历顺序来,遍历过的节点才能确定最终在哪片岛屿中。
举个反例,如果不按照顺序来遍历,那要求某个节点究竟在哪片岛屿中,就要以此节点为中心,向上下左右四个方向搜索陆地节点并合并集合。这时又会出现一个问题,看下面这张图:

红色节点1最先会被划分到蓝色集合中,之后又和下面橙色节点1合并,划分到橙色集合中,但其实正确结果是红色节点1被划分到蓝色集合,并且下方的橙色节点1最终也是要被划分到蓝色集合的。为什么会出现这种结果呢?
究其原因是橙色节点1还是处于最开始(每个节点独自构成一个集合)的初始状态,也就是说橙色节点的最终归属集合还没有确定好,要想得到并查集的最终结果,我们在某一节点向四周搜索时必须搜索已经有归属集合的节点。
因为我们对数组遍历是从行从上到下,列从左到右的,所以遍历某个节点时只需要搜索其左边的节点和上边的节点。
解决代码:
最终代码如下:
int MAXN = 100001;
vector<int> father;
int sets;
Solution() { father.resize(MAXN); }
void build(vector<vector<char>>& grid) {
int rows = grid.size();
int columns = grid[0].size();
sets = 0;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < columns; j++) {
if (grid[i][j] == '1') {
int index = Index(i, j, columns);
father[index] = index;
sets++;
}
}
}
}
int Find(int i) {
// 利用堆栈进行扁平化处理
if (i != father[i]) {
father[i] = Find(father[i]);
}
return father[i];
}
void Union(int x1, int y1, int x2, int y2, int columns) {
int index1 = Index(x1, y1, columns);
int index2 = Index(x2, y2, columns);
int f1 = Find(index1);
int f2 = Find(index2);
if (f1 != f2) {
father[f1] = f2;
sets--;
}
}
int Index(int i, int j, int columns) { // 将二维坐标映射到一维
return i * columns + j;
}
int numIslands(vector<vector<char>>& grid) {
int rows = grid.size();
int columns = grid[0].size();
build(grid);
for (int i = 0; i < rows; i++) {
for (int j = 0; j < columns; j++) {
if (grid[i][j] == '1') {
// 尝试能否与左边节点所在集合合并
if (j > 0 && grid[i][j - 1] == '1') {
// 左边节点存在并且是陆地,则可以考虑合并
Union(i, j, i, j - 1, columns);
}
// 尝试能否与上边节点所在集合合并
if (i > 0 && grid[i - 1][j] == '1') {
// 右边节点存在并且是陆地,则可以考虑合并
Union(i, j, i - 1, j, columns);
}
}
}
}
return sets;
}