概述

Decoder也是N=6层堆叠的结构,每层被分3层: 两个注意力层和前馈网络层,同Encoder一样在主层后都加有Add&Norm,负责残差连接和归一化操作。
Encoder与Decoder有三大主要的不同:
- 第一层 Masked Multi-Head Attention: 采用Masked操作
- 第二层 Multi-Head Attention: K, V矩阵是使用Encoder编码信息矩阵C进行计算,而Q使用上一个Decoder的输出计算。
- 概率计算输出: Linear和Softmax作用于前向网络层的输出后面,来预测对应的word的probabilities
Encoder的输入矩阵用X表示,输出矩阵用C表示
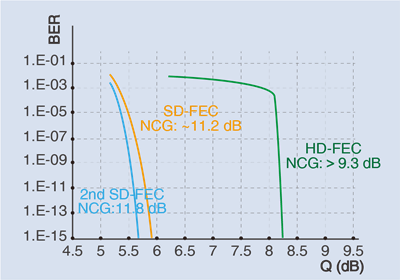
流程图表示如下:

分析如下:
- 我们将 输入转换为嵌入矩阵,再加上位置编码,输入解码器
- 解码器收到输入,将其发送给带掩码的多头注意力层,生成注意力矩阵M
- 将注意力矩阵M和Encoder输出的特征值R作为多头注意力层的输入,输出第二层注意力矩阵
- 从第二层的多头注意力层得到注意力矩阵,送入前馈网络层,后者将解码后的特征作为输出
- 前馈网络层的输出经过Add&Norm后,做linear及Softmax回归,并输出目标句子的特征
Decoder 的输入
Decoder的输入结构与encoder的一样。
见Transformer模型-4-Inputs-笔记
Masked Multi-Head Attention
输入组成
由如下几个部分组成
1.初始输入:前一时刻Decoder输入+前一时刻Decoder的预测结果 + Positional Encoding
3.中间输入:Encoder Embedding
4.Shifted Right:在输出前添加 起始符(Begin),方便预测第一个Token
Shifted Right是在起始位添加起始符(Begin),让整个输入向后移一位,是为了在T-1时刻需要预测T时刻的输出。
举例: I like eat hamburg
正常的输出序列位置关系如下:
1 0:"I"
2 1:"like"
3 2:"eat"
4 3: "hamburg"
在执行的过程中,我们在初始输出中添加了起始符,相当于将输出整体右移一位(Shifted Right),所以输出序列如下:
1 0: </s> #起始符
2 1: "I"
3 2: "like"
4 3: "eat"
5 4: "hamburg"
这样我们就可以通过起始符预测“I”,也就是通过起始符预测实际的第一个输出。
具体步骤
Time Step 1
- 初始输入: 起始符 + Positional Encoding
- 中间输入:(我爱吃汉堡)Encoder Embedding
- Decoder: 产生预测I
Time Step 2
- 初始输入:起始符 + I + Positonal Encoding
- 中间输入:(我爱吃汉堡)Encoder Embedding
- Decoder:产生预测like
Time Step 3
- 初始输入:起始符 + I + like + Positonal Encoding
- 中间输入:(我爱吃汉堡) Encoder Embedding
- Decoder:产生预测eat
Time Step 4
- 初始输入:起始符 + I + like + eat + Positonal Encoding
- 中间输入:(我爱吃汉堡) Encoder Embedding
- Decoder:产生预测hamburg
Masked
主要用途
- 引入类对焦矩阵,实现并行解码加速整个训练过程;
- 在生成attention时保存信息不泄露(没有生成不该生成的数据)
Masked的工作方式: 以"I like eat hamburg"说明
- 在Masked Multi-Head Attention层:在生成I时不能看到Like、eat、hambugers更不能生成他们之间的相关度信息,解码时只能看到自己或<起始符>,后面的信息都隐掉,即masked

上图表示:输入矩阵 + Mask = Mask矩阵
图中黑色框表示被Mask的部分
- 在Multi-Head Attention则是把Encoder信息与Decoder信息进行整合

并行化处理-原因分析
早在Seq2Seq模型采用的是逐步Decoder,在Encoder时一次性输入全部数据,生成第一个字时,会先结合 <起始符> ,再生成;然后用生成第二个字符时 由第一个字符再结合起始符达成,以此类推,整个过程是串行化的过程。
而在大规模的模型训练过程中,解决效率的的关键就是把串行计算改为计算(并行解码) ,即一次性输入,一次性解码。当一次性将信息全部输入,模型一次计算可能会计算所有数据。但并行会影响到结果输出 —— 因为计算时如数据全可见,会对预测会有影响,而加入了Masked是可以避免数据泄露的。我们输入时还是一次性输入全部数据,在Attention时追加一个Masked保证一个字符只能看到前一个字或起始符。
公式推导
1.得到Q,K,V: 输入数据:I like eat hamburg,进行三次线性变化,得到Q,K,V。

2.Masked计算:当Q∗K=QKTQ∗K=QKT得到相当度信息后,再和Masked矩阵做按位相乘得到masked QKTQKT 。Masked保存此次解码只看到该看到的,隐去看不到的或不应该看到的。

3.得到Attention(Q,K,V)公式:拿到softmax(QKTdk)softmax(dkQKT) 结果后再和 V(value) 做一次 Attention计算得到Attention(Q,K,V)
i
公式:

Multi-Head Attention
也称 Cross Multi-Head Attention 即是结合Encoder与Encoder而得到的信息,获取整合的Attention(Q,K,V),其中数据获取来源分为:
Q: 由masked Multi-head Attention输出,再经过Add&Norm后得到的数据
K\V: 是Encoder输入出经过两次线性变化的而得数据,其中的3/4分给了Multi-Head Attention
最后 将所有的Q (Decoder端所有的 token) 去和encoder的输出的数据一起计算,来衡量他们之间的相关度,最后结合Value生成Attention。
Decoder -输出
transformer的output probabilities,从字面上我们即可理解transformer的输出token是由各个词的概率计算而得。
原理: 数据经过 (cross) multi-head Attention及线性变化之后,输出softmax,最后输出数据,输出则是每个位置上单词的概率分布
结构分析

用softmax预测输出单词
用Softmax来预测下一个单词,通过之前的各种操作后得到一个最终输出Z来预测单词:

又因为Mask,使得单词的输出Z0只包含<起始符>的信息,如下:
起止符这里用begin表示

先贴个图,后面随着笔者对其学习研究的加强会补充更多的内容,现在主要是想强调输出是由概率计算而得,加深印象。
如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉如何学习AI大模型?👈
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。