来源:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8461375 (这是一篇跟 X-vector 有关的论文)
这里有更适合初学者的两个资料:
1.https://www.youtube.com/watch?v=R3rzN6JYm38 (MIT教授的youtube视频)
2.https://people.csail.mit.edu/sshum/talks/ivector_tutorial_interspeech_27Aug2011.pdf (MIT教授的slides)
首先是摘要

在本文中,我们使用数据增强来提高深度神经网络(DNN)嵌入矢量在说话人识别中的性能。DNN经过训练以区分不同的说话人,将可变长度的语音片段映射为我们称之为x-vectors的固定维度嵌入(有点类似于 NLP 中的嵌入矢量)。先前的研究发现,嵌入在利用大规模训练数据集方面比i-vectors表现更佳。然而,收集大量标记数据进行训练可能具有挑战性。我们使用数据增强,包括添加噪声和混响,作为一种廉价的方法来增加训练数据量并提高鲁棒性。我们在“野外说话人”数据集和NIST SRE 2016粤语数据集上将x-vectors与i-vector基准进行了比较。结果发现,虽然数据增强对PLDA分类器有益,但对i-vector提取器并没有帮助。然而,x-vector DNN由于其监督训练,能够有效利用数据增强。因此,x-vectors在评估数据集上取得了更优的性能。
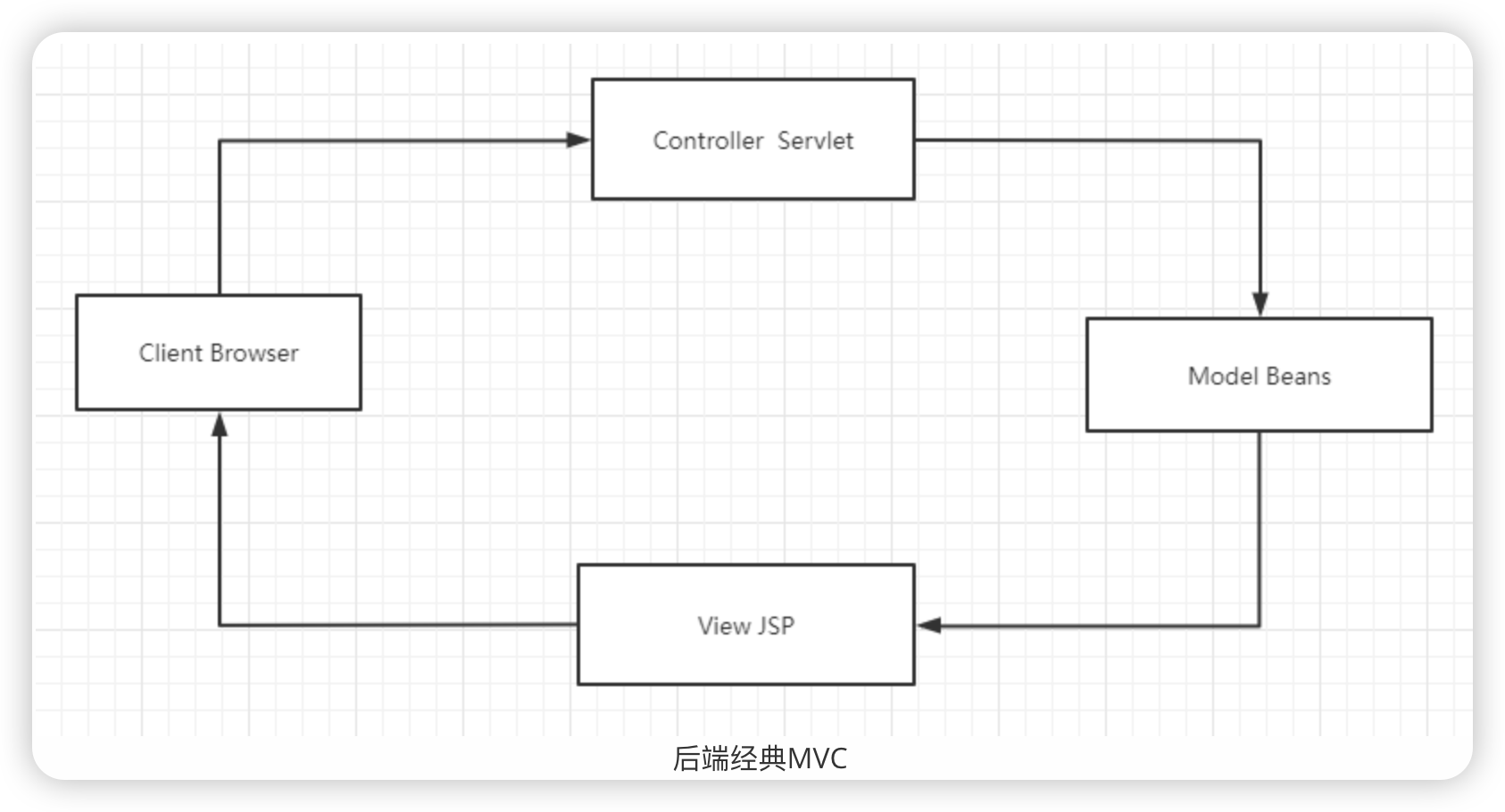
看完摘要,初步判断这是比较 x-vector 和 i-vector 的文章,我们来直接跳到第二节 SPEAKER RECOGNITION SYSTEMS,也是类似于其它文章的 BACKROUND

本节描述了为本研究开发的说话人识别系统,包括两个i-vector基准和DNN x-vector系统。所有系统均使用Kaldi语音识别工具包构建。

基于文献[11]中描述的GMM-UBM方法的传统i-vector系统作为我们的声学特征基准系统。特征为20个MFCC,帧长度为25毫秒,在最长为3秒的滑动窗口内进行均值归一化。增添了Delta和加速度,形成60维特征向量。基于能量的语音活动检测(SAD)系统选择与语音帧对应的特征。UBM为2048个成分的全协方差GMM。该系统使用600维的i-vector提取器,并采用PLDA进行评分(见第2.4节)。
(感觉似乎并没有讲述 i-vector 是个啥)
TODO: here