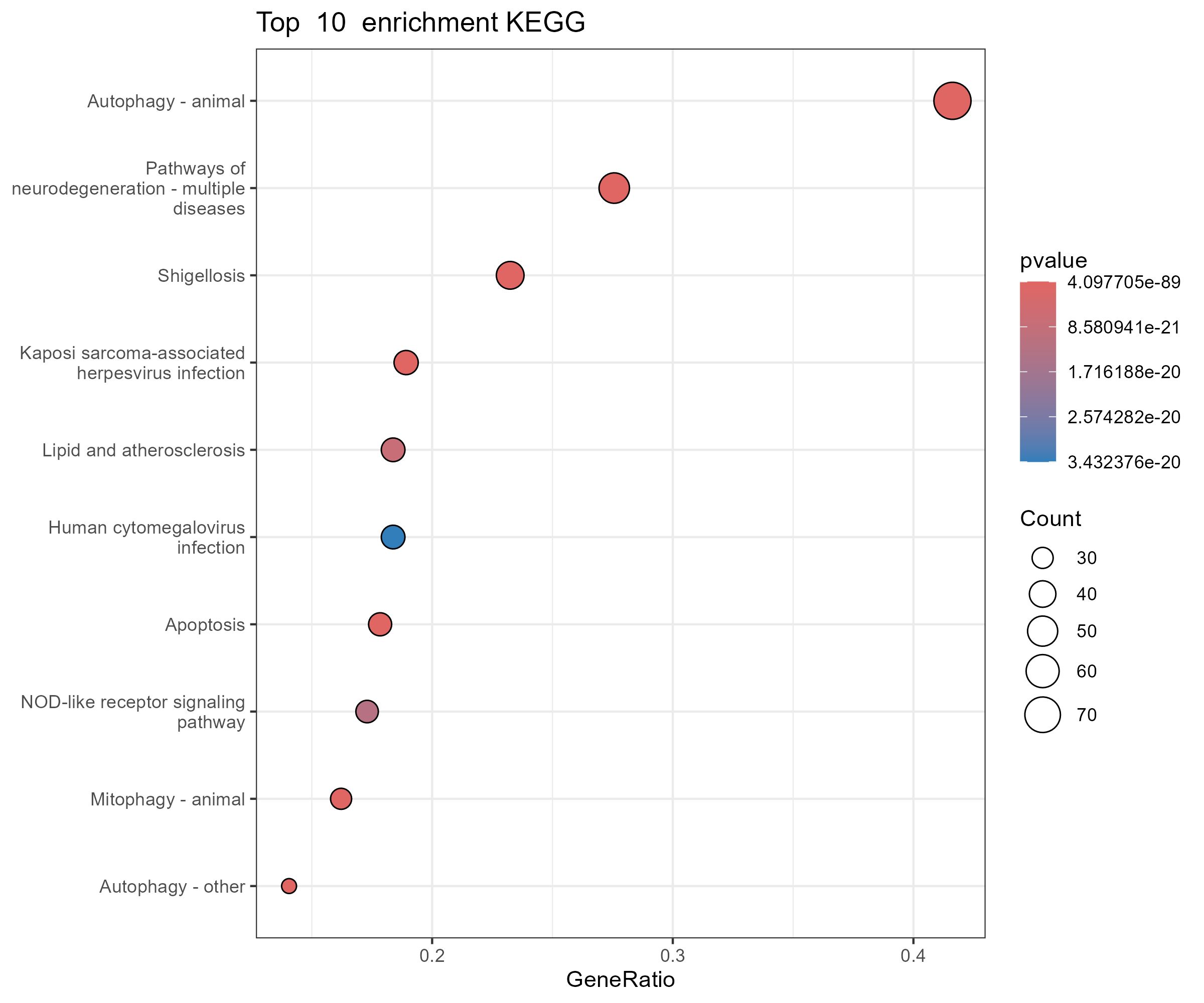
摘要
我们的无监督学习的动机是稳健的跟踪器应该在双向跟踪中有效。具体来说,跟踪器能够在连续帧中前向定位目标对象,并回溯到其在第一帧中的初始位置。基于这样的动机,在训练过程中,我们测量前向和后向轨迹之间的一致性,以便仅使用未标记的视频从头开始学习稳健的跟踪器。我们在 Siamese 相关滤波器网络上构建我们的框架,并提出了一种多帧验证方案和成本敏感损失来促进无监督学习。
介绍
最近,深度模型通过加强特征表示或端到端优化网络来提高跟踪精度,这些模型经过完全监督离线预训练,在训练阶段需要大量带注释的真实标签。手动注释总是昂贵且耗时的,而互联网上很容易获得大量未标记的视频。另一方面,视觉跟踪与其他识别任务(例如对象检测、图像分类)的不同之处在于对象标签根据第一帧上的目标初始化而变化。监督学习的广泛和不确定的标记过程引起了我们的兴趣,通过使用未标记的视频序列来开发替代学习方案。
在本文中,我们提出了一种用于视觉跟踪的无监督学习方法。我们没有使用现成的深度模型,而是从头开始训练视觉跟踪网络。无监督学习的直觉在于视频序列中的双向运动分析。跟踪对象可以以前向和后向方式执行。最初,给定第一帧中目标对象的边界框注释,我们可以在后续帧中向前跟踪目标对象。在向后跟踪时,我们使用最后一帧的预测位置作为初始目标边界框,并将其向后跟踪到第一帧。理想情况下,第一帧中估计的边界框位置与前向传递中的给定边界框位置相同。在这项工作中,我们测量前向和后向目标轨迹之间的差异并将其表述为损失函数。我们使用计算的损失以自我监督的方式训练我们的网络1,如图1所示。通过反复跟踪和向后跟踪,我们的模型学会了在没有任何监督的情况下在连续帧中定位目标对象。

通过监督学习和无监督学习进行视觉跟踪。监督学习需要训练视频中的各个帧的真实标签,而我们提出的无监督学习通过测量前向和后向跟踪之间的轨迹一致性没有任何标签。
所提出的无监督训练旨在学习一个通用的特征表示,而不是严格专注于跟踪完整的对象。在第一帧中,我们初始化了一个边界框,该边界框覆盖了具有高图像熵的信息局部区域。边界框可能包含任意图像内容,可能无法覆盖整个对象。然后,我们的跟踪网络学习跟踪训练视频序列中的边界框区域。我们的无监督注释与基于部分[36]和基于边缘的[34]跟踪方法有相似之处,后者跟踪目标对象的子区域。我们希望我们的跟踪器不仅专注于完整对象的形状,而且还能够跟踪它的任何部分。图像熵的边界框初始化摆脱了第一帧上的手动注释,从而保证了整个学习过程的无监督。
我们在 Siamese 相关滤波器框架下采用无监督学习。训练步骤包括前向跟踪和后向验证。前向和后向一致性测量的一个限制是前向传递中的目标轨迹可能与后向传递中的目标轨迹一致,尽管跟踪器丢失了目标。一致性损失函数无法惩罚这种情况,因为无论丢失目标如何,预测的目标区域仍然可以回溯到第一帧上的初始位置。此外,训练视频中严重遮挡或视野外等挑战会降低 CNN 特征表示能力。为了解决这些问题,我们引入了一种多帧验证方案和一个成本敏感的损失来促进无监督训练。如果跟踪器丢失目标,在训练阶段使用更多帧时,从前向和后向预测的轨迹就不太可能保持一致。此外,我们提出了一种新的成本敏感损失来缓解噪声样本在无监督学习过程中的影响。包含背景纹理的训练样本将被图像熵测量排除。基于上面讨论的多帧验证和样本选择策略,我们的网络训练是稳定的。
总之,这项工作的贡献有三个方面:
-我们在 Siamese 相关滤波器网络上提出了一种无监督学习方法。无监督学习由前向和后向跟踪组成,用于测量网络训练的轨迹一致性。
-我们提出了一种多帧验证方案,在跟踪器丢失目标时扩大轨迹不一致。此外,我们提出了一种成本敏感损失和熵选择度量来减少训练过程中简单样本的贡献。
-在七个标准基准上进行的大量实验证明了所提出的跟踪器的良好性能。我们对无监督表示进行了深入的分析,揭示了无监督学习在视觉跟踪方面的潜力。
相关工作
Wang 和 Gupta [66] 使用 KCF 跟踪器 [19] 对原始视频进行预处理,然后选择一对跟踪图像和另一个随机补丁来学习使用排名损失的 CNN。我们的方法从两个方面与[66]有很大的不同。首先,我们将跟踪算法集成到无监督训练中,而不是仅仅使用现成的跟踪器作为数据预处理工具。其次,我们的无监督框架与跟踪目标函数相结合,因此学习到的特征表示在表征通用目标对象方面是有效的。
方法
我们的无监督学习的动机如图2(a)所示。我们首先选择一个内容丰富的局部区域作为目标对象。给定这个初始化的边界框标签,我们向前跟踪以预测其在后续帧中的位置。然后,我们反转序列并将最后一帧的预测边界框作为伪标签进行反向验证。通过反向跟踪第一帧中的预测边界框理想地与原始边界框相同。我们使用一致性损失来衡量前向和后向轨迹之间的差异来训练网络。图2(b)显示了我们的无监督暹罗相关滤波器网络的概述。

我们在 (a) 中展示了跟踪前向和后向以计算网络训练的一致性损失的动机。详细的训练过程如 (b) 所示,其中无监督学习集成到 Siamese 相关滤波器网络中。在测试阶段,我们只向前跟踪以预测目标位置。
回顾相关跟踪
判别相关滤波器 (DCF) 将搜索补丁输入特征的循环移位版本回归到软目标响应图以进行目标定位。在训练 DCF 时,我们选择了一个带有相应真实标签 Y 的模板 patchX,它是高斯形的,峰值位于目标位置。模板补丁的大小通常大于目标的大小.图 2 显示了模板补丁的示例,其中既有目标内容,也有背景内容。通过求解以下岭回归问题,可以学习滤波器W.

其中 λ 是正则化参数,∗ 表示循环卷积。等式1 可以在傅里叶域中有效计算,DCF 可以计算为
其中点圈是逐元素乘积,F (·) 是离散傅里叶变换 (DFT),F -1(·) 是逆 DFT,并且星表示复共轭操作。在每个后续帧中,给定一个搜索补丁 Z,其对应的响应图 R 可以在傅里叶域中计算:

上述 DCF 框架从使用模板补丁学习目标模板的相关过滤器(即 W)开始,然后将其与搜索补丁 Z 进行卷积以生成响应。最近,Siamese相关滤波器网络将DCF嵌入到Siamese框架中,并构建两个共享权重分支来提取特征表示,如图2(b)所示。 第一个是模板分支,它以模板补丁 X 作为输入,并提取其特征,通过 DCF 进一步生成目标模板过滤器。第二个是搜索分支,它以搜索补丁 Z 作为输入进行特征提取。然后将模板过滤器与搜索补丁的 CNN 特征进行卷积以生成响应图。Siamese DCF 网络的优点是特征提取 CNN 和相关滤波器都被制定为端到端框架,因此学习到的特征与视觉跟踪场景更相关。
无监督学习原型
给定两个连续的帧P1和P2,我们分别裁剪模板和搜索补丁。通过前向跟踪和后向验证,所提出的框架不需要额外的监督。P1中初始边界框和预测边界框之间的位置差异将制定一致性损失。我们利用这种损失来训练没有真实注释的网络。
前向跟踪
按照之前的方法,我们构建了一个Siamese相关滤波器网络来跟踪帧P1中初始化的边界框区域。在从第一帧P1生成模板补丁T后,我们计算对应的模板滤波器WT如下:

其中 φθ (·) 表示具有可训练网络参数 θ 的 CNN 特征提取操作,YT 是模板补丁 T 的标签。这个标签是一个以初始化的边界框中心为中心的高斯响应。一旦我们获得了学习到的模板过滤器WT,从帧P2中搜索补丁S的响应图就可以由下式计算

如果补丁 S 的真实高斯标签可用,则可以通过计算 RS 和真实标签之间的 L2 距离来训练网络 φθ (·)。与监督框架不同,在下文中,我们展示了如何通过利用反向轨迹验证来训练网络,而不需要标签。
向后跟踪
在为帧P2生成响应图RS后,我们创建了一个以最大值为中心的伪高斯标签,用YS表示。在反向跟踪中,我们切换搜索补丁和模板补丁之间的角色。通过将 S 视为模板补丁,我们使用伪标签 YS 生成模板过滤器 WS。模板 filterWS 可以使用等式4学习 通过将 T 替换为 S 并用 YS 替换 YT,如下所示:

然后,我们通过等式生成模板补丁的响应图 RT。 5 通过将 WT 替换为 WS 并用 T 替换 S,如公式所示。

请注意,我们只使用一个 Siamese 相关滤波器网络来执行前向和后向跟踪。网络参数 θ 在跟踪步骤中是固定的。
一致性损失计算
在前向和后向跟踪之后,我们得到响应图 RT。理想情况下,RT 应该是高斯标签,峰值位于初始化目标位置。换句话说,RT 应该与最初给定的标签 YT 相似。因此,通过最小化重构误差,可以以无监督的方式训练表示网络 φθ (·),如下所示:


基于伪标记的自我训练的直觉。我们对前向和后向预测使用相同的网络。前向阶段为搜索补丁生成伪标签。后向阶段通过反向传播使用训练对更新跟踪网络。在训练期间,模板的响应图通过自我监督逐渐接近初始标签。
我们的无监督学习可以看作是一个增量的自我训练过程,它迭代地预测标签并更新模型以稳定地提高跟踪能力。图 3 显示了直觉,其中我们对前向和后向预测使用相同的网络。在前向跟踪中,我们为搜索补丁 S 生成一个伪标签 YS。然后我们将生成的 YS 视为 S 的标签并创建相应的样本。使用这些标记的训练对(即具有初始或伪标签),我们可以以与监督学习类似的方式更新 Siamese 相关滤波器网络。在损失反向传播期间,我们遵循 Siamese 相关滤波器方法来更新网络:

上述无监督训练过程基于两帧之间的前向后向一致性,由算法1总结。在下一节中,我们扩展了这个原型框架,以考虑多帧以获得更好的网络训练。

无监督学习的增强
所提出的无监督学习方法基于 RT 和 YT 之间的一致性构建目标函数。在实践中,跟踪器可能会在前向跟踪中偏离目标,但在后向过程中仍然返回到原始位置。然而,由于轨迹一致,所提出的损失函数不会惩罚这种偏差。同时,原始视频可能包含无纹理或遮挡的训练样本,从而恶化无监督学习过程。在本节中,我们提出了一种多帧验证方案和一个成本敏感的损失来解决这两个限制。
多帧验证
我们提出了一种多帧验证方法来扩大跟踪器丢失目标时的轨迹不一致。我们的直觉是在训练期间合并更多的帧,以减少后续帧中的错误定位成功回溯到第一帧中的初始位置的限制。这样,Eq. 8中的重构误差将有效地捕获不一致的轨迹。如图3所示,在前向阶段添加更多帧进一步挑战模型跟踪能力。
我们的无监督学习原型可以很容易地扩展到多帧。为了使用三帧构建轨迹周期,我们可以涉及另一个帧P3,它是P2之后的后续帧。我们从P2中裁剪一个搜索补丁S1,从P3中裁剪另一个搜索补丁S2。如果生成的响应图RS1与其对应的地真响应不同,则下一帧P3的差异趋于较大。因此,不一致性更有可能出现在反向跟踪中,生成的响应图RT更有可能与YT不同,如图4所示。通过在前向和后向跟踪过程中涉及更多的搜索补丁,所提出的一致性损失将更有效地惩罚不准确的定位。

单帧验证和多帧验证。单帧验证中不准确的定位可能无法捕获,如左侧所示。通过涉及更多帧,如右图所示,我们累积定位误差以打破前向和后向跟踪期间的预测一致性。
我们可以进一步扩展用于多帧验证的帧数量。轨迹的长度将增加,如图5所示。当目标丢失时,一致轨迹的局限性不太可能影响训练过程。令 R(Sk →T) 表示模板 T 的响应图,由使用第 k 个搜索补丁 Sk 训练的 DCF 生成(或跟踪)。对应的一致性损失函数可计算如下:
考虑到不同的轨迹周期,多帧一致性损失可以通过
其中 k 是搜索 parch 的索引。以图5(C)为例,最终的一致性目标包含三个损失(即公式11中的M=3),分别用图5(C)中的蓝色、绿色和红色周期表示。

多帧轨迹一致性概述。我们将 T 分别表示为模板,将 S 表示为搜索补丁。我们的无监督训练原型如 (a) 所示,其中只涉及两帧。使用更多帧,如 (b) 和 (c) 所示,我们可以在失去目标时逐步提高训练性能以克服一致的轨迹
成本敏感损失
我们在无监督训练期间将边界框区域初始化为第一帧中的训练样本。此边界框区域内的图像内容可能包含任意或部分对象。图 6 显示了这些区域的概述。为了缓解背景干扰,我们提出了一种代价敏感损失来有效地排除噪声样本进行网络训练。为简单起见,我们使用三个连续帧作为示例来说明样本选择,这可以自然地扩展到更多的帧。使用三帧的管道如图5(b)所示。

ILSVRC 2015[51]中裁剪图像补丁的示例。这些样本中的大多数都包含有意义的对象,而一些样本不太有意义(例如,最后一行)
在无监督学习过程中,我们从视频序列中构建多个训练三元组。对于包含三个帧的轨迹,每个训练三元组分别由帧P1中的一个初始化模板补丁T和后续帧P2和P3中的两个搜索补丁S1和S2组成。我们使用几个三元组来形成用于连体网络学习的训练批次。在实践中,我们发现一些损失极高的训练三元组可以防止网络训练收敛。为了减少基于伪标记的自我训练中的这些异常值效应,我们排除了包含最高损失值的整个训练三元组的 10%。它们的损失可以使用方程式计算。 10。为此,我们为每个训练三元组分配一个二进制权重 Aidrop。所有这些权重构成了一个向量 Adrop,其中其 10% 的元素为 0,其他元素为 1。
除了异常值训练对之外,原始视频还包括无意义的图像补丁,其中有无纹理的背景或静止的物体。在这些补丁中,对象(例如天空、草或树)不包含大动作。我们将运动权重向量 Amotion 分配给所有训练对,以增加网络学习的大运动效果。这个向量中的每个元素Aimotion可以通过以下方式计算。

其中 RiS1 和 RiS2 是第 i 个训练对中的响应图,YiT 和 YiS1 是对应的初始(或伪)标签。方程。 12 计算从帧 P1 到 P2 和 P2 到 P3 的目标运动差异。当Aimotion的值较大时,目标对象在该轨迹中经历快速运动。另一方面,Aimotion 的大值表示网络应该更加关注的硬训练对。我们将运动权重和二进制权重归一化如下:

其中 N 是小批量中的训练对的数量。样本权重 Ainorm 是一个标量,无需梯度反向传播即可重新加权训练数据。
小批量中图 5(b) 情况的最终无监督损失计算如下:

我们可以通过使用更多的帧来构造不同长度的轨迹,自然地将Eq. 14扩展到以下,如图5(c)的玩具示例所示。结合方程式。 11,我们使用 M 个后续帧计算最终的无监督损失函数为:

无监督训练细节
网络结构。我们遵循 DCFNet [64] 使用由两个卷积层组成的浅层连体网络进行跟踪。这种浅层结构在 CFNet [58] 中被证明是有效的,以集成 DCF 公式。这些卷积层的滤波器大小分别为 3×3×3×32 和 3×3 × 32 × 32。此外,在[64]之后的卷积层的末尾采用了局部响应归一化(LRN)层。这种轻量级结构为在线跟踪提供了有效的前向推理。
训练数据。我们选择 ILSVRC 2015 [51] 作为我们的训练数据,这是现有监督跟踪器使用的相同数据集。在数据预处理步骤中,监督方法 [1,58, 64] 需要每帧标签。此外,将删除帧,其中目标对象被遮挡、部分视图外或不规则形状(例如蛇)。监督方法的数据预处理是人类劳动耗时的。相比之下,我们的方法不依赖于手动注释的标签进行数据预处理。
在我们的方法中,对于原始视频中的第一帧,我们通过滑动窗口裁剪重叠的小块(总共5 × 5),如图7所示。然后,我们计算每个图像补丁的图像熵。图像熵有效地测量图像补丁的内容方差。当图像补丁只包含酉纹理(如天空)时,该补丁的熵接近0。当图像补丁包含纹理内容时,熵将变得更高。我们选择包含最高图像熵的裁剪图像补丁。该图像补丁初始化KCF[19]跟踪器,用于后续帧中的定位。然后,我们在DCFNet[64]之后裁剪出一个更大的图像补丁,填充目标大小的2倍,进一步调整为125×125作为网络的输入。图 6 显示了裁剪补丁的一些示例。我们从视频中的连续 10 帧中随机选择 4 个裁剪补丁来形成训练轨迹,其中一个定义为模板,其余定义为搜索补丁。这是基于这样一个假设,即中心定位的目标对象不太可能在短时间内从裁剪区域移出。我们跟踪图像补丁中的内容,而不考虑特定的对象类别。尽管这种基于熵的方法可能无法准确选择目标区域,并且 KCF 跟踪器不足以跟踪裁剪区域,但这种方法可以很好地缓解无意义的背景区域。

在线对象跟踪
在离线无监督学习之后,我们以前向跟踪的方式执行在线跟踪,如第 3.2 节所述。我们在线更新 DCF 以适应目标外观变化。DCF 更新遵循移动平均操作,如下所示:

其中 αt ∈ [0, 1] 是线性插值系数。目标尺度是通过比例因子为 {as|a = 1.015, s = {−1, 0, 1}} [12] 的补丁金字塔估计的。我们将跟踪器命名为 LUDT(即学习无监督深度跟踪)。此外,我们通过 αt 自适应地更新我们的模型,并遵循与 ECO [9] 中更好的 DCF 公式。我们将改进的跟踪器命名为 LUDT+。
我们在以下实验部分保留我们的初步跟踪器 UDT 和 UDT+ [61] 的符号。我们之前的 UDT 使用 3 帧周期(图 5(b)),并简单地裁剪原始视频中的中心补丁。LUDT从两个方面改进了UDT:(1)LUDT结合了不同的轨迹周期,如图5(c)所示;(2) LUDT利用图像熵来选择信息丰富的图像补丁,而不是中心裁剪。LUDT+ 和 UDT+ 分别通过采用 [9] 中提出的一些在线跟踪技术(例如自适应更新)来改进 LUDT 和 UDT。
实验
在本节中,我们首先分析我们的无监督训练框架的有效性并讨论我们的网络潜力。然后,我们将我们的跟踪器LUDT与最近发布的大型基准(包括OTB-2013[69]、OTB-2015[70]、Temple-Color[35]、VOT2016[25]、VOT2017/2018[24]、LaSOT[16]和TrackingNet[45])上的最先进的跟踪器进行比较。
在我们的实验中,我们使用动量为 0.9 的随机梯度下降 (SGD) 和 0.005 的权重衰减来训练我们的模型。我们的无监督网络训练了 50 个 epoch,学习率从 10-2 指数衰减到 10−5,小批量大小为 32。我们将轨迹长度设置为 4。所有实验均在具有 4.00GHz Intel Core I7-4790K 和 NVIDIA GTX 1080Ti GPU 的 PC 上执行。在单个 GPU 上,我们的 LUDT 和 LUDT+ 分别表现出大约 70 FPS 和 55 FPS2。所提出的方法在七个基准上进行了评估。在 OTB-2013/2015、TempleColor、LaSOT 和 TrackingNet 数据集上,我们使用带有距离和重叠精度指标的一次性评估 (OPE)。距离精度阈值设置为 20 像素。重叠成功图使用从 0 到 1 的阈值,并计算曲线下面积 (AUC) 来评估整体性能。在 VOT2016 和 VOT2017/2018 数据集上,我们使用预期平均重叠 (EAO) 来衡量性能
局限
图 16 显示了我们无监督学习的局限性。首先,与完全监督的学习相比,我们通过无监督学习训练的跟踪器在发生遮挡或剧烈外观变化时往往会漂移(例如,Skiing 和 Soccer 序列中的目标)。缺少真实注释带来的语义表示,缺少应付复杂场景的客观信息。其次,我们的无监督学习涉及前向和后向跟踪。训练阶段的计算负载是一个潜在的缺点,尽管学习过程是离线的。
总结
在本文中,我们展示了如何在野外使用未标记的视频训练视觉跟踪器,这在视觉跟踪中很少被研究。通过设计无监督的连体相关滤波器网络,我们验证了我们基于前向后向的无监督训练管道的可行性和有效性。为了进一步促进无监督训练,我们扩展了我们的框架以考虑多帧并采用成本敏感损失。大量实验表明,所提出的无监督跟踪器,没有铃铛和口哨,作为坚实的基线,并取得了与经典全监督跟踪器相当的结果。配备了额外的在线改进,例如复杂的更新方案,我们的 LUDT+ 跟踪器优于最先进的跟踪算法。此外,我们通过特征可视化和广泛的消融研究对我们的无监督表示进行了深入分析。我们的无监督框架在视觉跟踪方面显示出有希望的潜力,例如利用更多的未标记数据或弱标记数据来进一步提高跟踪精度。