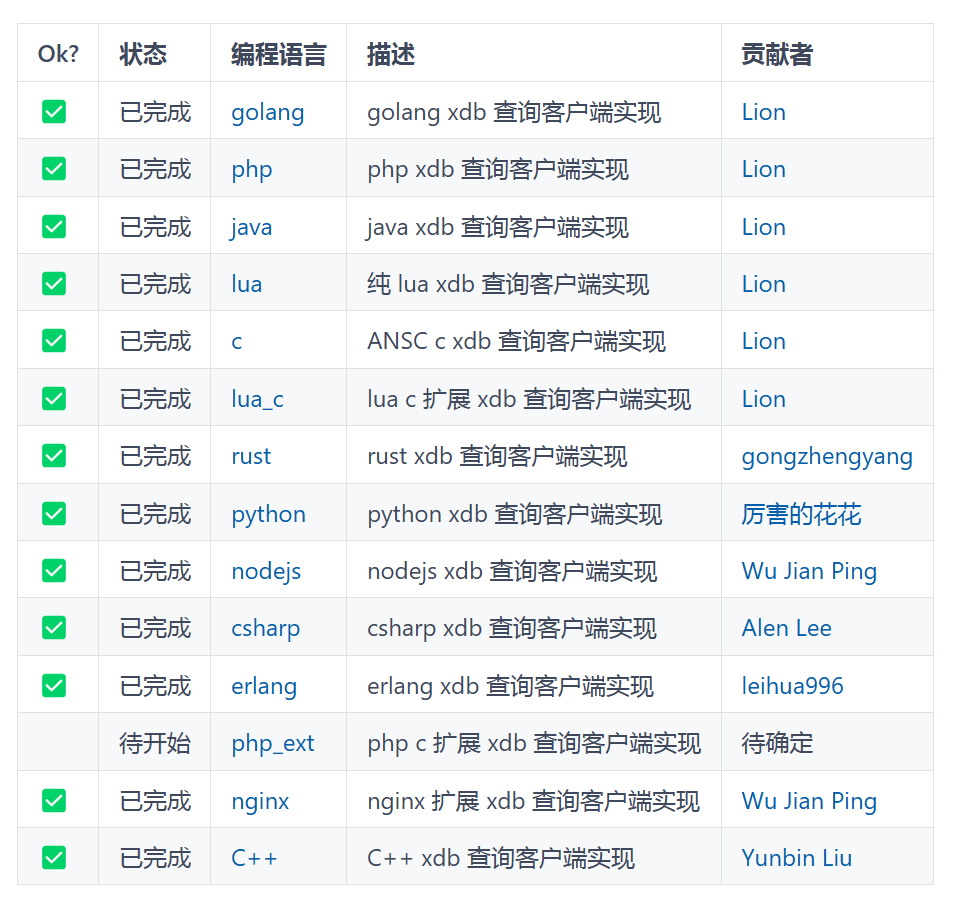
基于姿态估计的翻越动作识别系统是一个结合了计算机视觉、姿态估计技术和深度学习的项目,其目的是识别特定的动作,比如“翻越”动作。在这个项目中,我们使用MediaPipe姿态估计工具进行人体姿态估计,并结合深度学习模型来识别翻越动作。以下是对此项目的详细介绍及其实现的关键步骤。
项目介绍
本项目旨在开发一个能够自动识别“翻越”动作的系统。系统利用MediaPipe进行人体姿态估计,捕捉人体关键点,并通过深度学习模型对姿态序列进行分析,从而判断是否发生了翻越动作。此外,系统还包括一个简单的用户界面,用户可以上传视频或实时捕捉视频流,并查看识别结果。
关键功能
-
姿态估计:
- 使用MediaPipe Pose API进行人体姿态估计,获取人体关键点位置。
-
动作识别:
- 采集姿态估计结果作为特征输入到深度学习模型中。
- 利用深度学习模型(如LSTM、GRU或其他时序模型)识别特定的动作(如翻越)。
-
实时处理:
- 支持实时视频流处理,实时检测和识别翻越动作。
-
用户界面:
- 提供一个简单易用的用户界面,允许用户上传视频或开启摄像头进行实时检测。
- 显示识别结果,包括动作发生的时刻和概率。
技术栈
- 姿态估计:MediaPipe Pose API。
- 深度学习:TensorFlow或PyTorch框架。
- 编程语言:Python。
- 用户界面:Tkinter、PyQt或其他GUI库。
关键步骤
1. 姿态估计
使用MediaPipe Pose API进行姿态估计,获取人体关键点的位置信息。
1import cv2
2import mediapipe as mp
3mp_drawing = mp.solutions.drawing_utils
4mp_pose = mp.solutions.pose
5
6cap = cv2.VideoCapture(0) # 或者读取视频文件 cap = cv2.VideoCapture('path_to_video.mp4')
7
8with mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose:
9 while cap.isOpened():
10 success, image = cap.read()
11 if not success:
12 print("Ignoring empty camera frame.")
13 continue
14
15 # To improve performance, optionally mark the image as not writeable to pass by reference.
16 image.flags.writeable = False
17 image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
18 results = pose.process(image)
19
20 # Draw the pose annotation on the image.
21 image.flags.writeable = True
22 image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
23 mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
24
25 # 获取姿态关键点
26 landmarks = []
27 if results.pose_landmarks:
28 for landmark in results.pose_landmarks.landmark:
29 landmarks.append([landmark.x, landmark.y, landmark.z])
30
31 # 显示图像
32 cv2.imshow('MediaPipe Pose', image)
33 if cv2.waitKey(5) & 0xFF == 27:
34 break
35
36cap.release()2. 动作识别
将姿态估计的结果作为特征输入到深度学习模型中进行动作识别。
1import numpy as np
2from tensorflow.keras.models import Sequential
3from tensorflow.keras.layers import LSTM, Dense
4
5# 定义LSTM模型
6model = Sequential([
7 LSTM(64, return_sequences=True, input_shape=(30, len(landmarks))), # 假设每个姿态序列包含30帧
8 LSTM(128),
9 Dense(1, activation='sigmoid') # 输出层,二分类问题
10])
11
12# 编译模型
13model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
14
15# 加载预训练的模型权重
16model.load_weights('path_to_model_weights.h5')
17
18# 使用模型进行预测
19def predict_action(landmarks_sequence):
20 landmarks_sequence = np.array(landmarks_sequence)
21 landmarks_sequence = landmarks_sequence.reshape(1, 30, len(landmarks))
22 prediction = model.predict(landmarks_sequence)
23 return prediction[0][0] # 返回预测结果3. 用户界面
使用Python的GUI库(如Tkinter)构建一个简单的用户界面,允许用户上传视频或启动摄像头,并显示识别结果。
1import tkinter as tk
2from tkinter import filedialog
3
4def upload_video():
5 filepath = filedialog.askopenfilename(filetypes=[("Video files", "*.mp4")])
6 if filepath:
7 process_video(filepath)
8
9def process_video(filepath):
10 cap = cv2.VideoCapture(filepath)
11 with mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose:
12 while cap.isOpened():
13 success, image = cap.read()
14 if not success:
15 print("Video ended.")
16 break
17
18 # 进行情态估计
19 image.flags.writeable = False
20 image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
21 results = pose.process(image)
22
23 # 获取姿态关键点
24 landmarks = []
25 if results.pose_landmarks:
26 for landmark in results.pose_landmarks.landmark:
27 landmarks.append([landmark.x, landmark.y, landmark.z])
28
29 # 预测动作
30 if len(landmarks) >= 30: # 假设每30帧为一个姿态序列
31 prediction = predict_action(landmarks[-30:])
32 action_label.config(text=f"Action Probability: {prediction:.2f}")
33
34 cap.release()
35
36root = tk.Tk()
37root.title("Action Recognition")
38
39video_button = tk.Button(root, text="Upload Video", command=upload_video)
40video_button.pack(pady=20)
41
42action_label = tk.Label(root, text="", font=('Helvetica', 14))
43action_label.pack(pady=20)
44
45root.mainloop()应用场景
- 安全监控:用于识别非法翻越围墙的行为,提高安全防范水平。
- 体育训练:用于运动员训练过程中动作的识别和纠正。
- 智能家居:用于家庭环境中的行为识别,比如老人跌倒检测等。
结论
基于姿态估计的翻越动作识别系统通过结合MediaPipe姿态估计工具和深度学习模型,实现了对人体姿态的精确估计和翻越动作的自动识别。系统通过构建一个简单的用户界面,使用户能够方便地上传视频或开启摄像头进行实时检测,并查看识别结果。该系统可以应用于安全监控、体育训练、智能家居等多个领域,提高动作识别的准确性和实时性。随着技术的不断进步,此类系统将在实际应用中发挥更大的作用。






![[OpenCV] 数字图像处理 C++ 学习——14霍夫变换直线、圆检测 附完整代码](https://i-blog.csdnimg.cn/direct/9aedffeeba184527b0d66311fb989935.png)