前言
随着互联网的发展,IP地址定位成为了诸多应用中的重要一环。然而,现有的许多定位库在面对大规模数据时,往往会遇到查询速度慢、内存消耗大等问题。有没有一款工具能够处理这些问题,为开发者提供一个更为高效、灵活的定位库呢?
Ip2region 正是为此而生。它是一个离线IP数据管理框架和定位库,支持亿级别的数据段,提供了10微秒级别的查询性能,同时支持多种主流编程语言的数据管理引擎实现。
介绍
Ip2region (2.0 - xdb) 是一个离线IP数据管理框架和定位库,支持亿级别的数据段,拥有卓越的查询性能。它不仅能够高-效地管理和查询IP数据,还提供了多种方式来加速查询过程。
主要功能
-
支持亿级别数据段:即使是在处理大量IP数据时也能保持高-效。
-
10微秒级别的查询性能:确保了查询的快速响应。
-
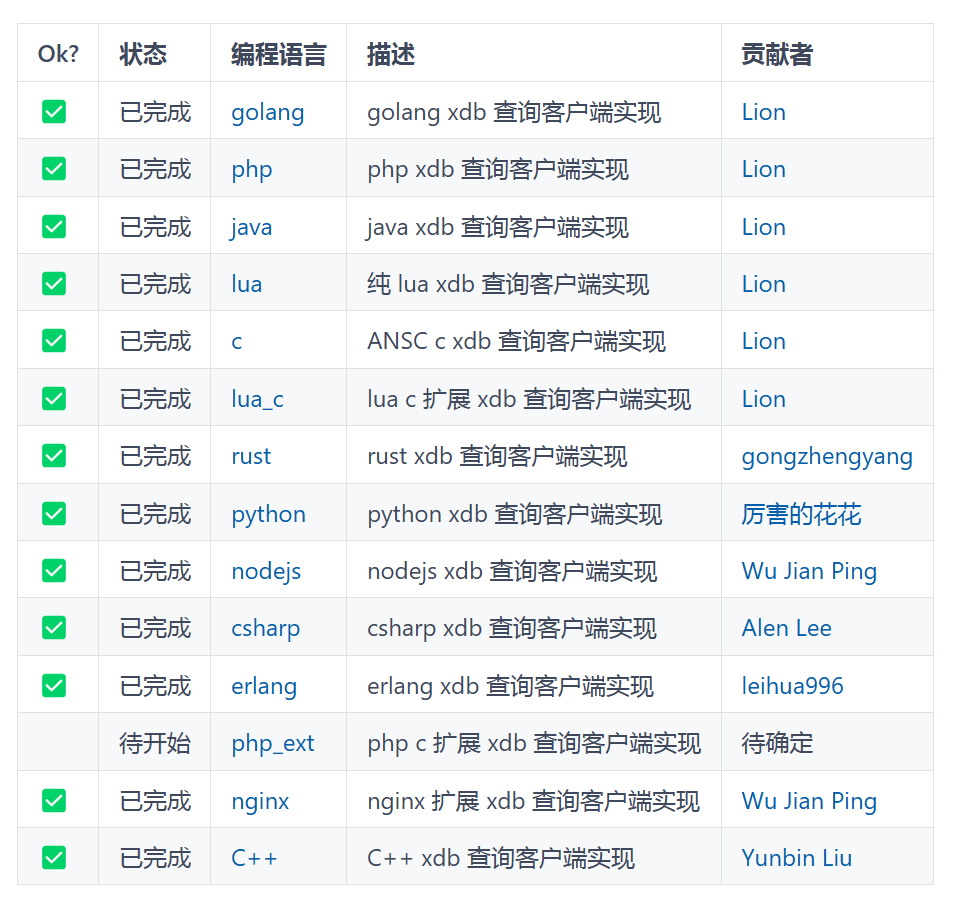
多种语言支持:提供了多种主流编程语言的数据管理引擎实现,方便集成到不同的应用中。
特点
Ip2region 的特点在于:
-
IP数据管理框架:支持亿级别的IP数据段,region信息支持完全自定义,可以根据业务需求追加特定数据。
-
数据去重和压缩:自动去重和压缩数据,生成的xdb数据库体积小,随着数据详细度增加而适度增长。
-
极速查询响应:支持vIndex索引缓存和xdb文件缓存,保持微秒级别的查询效率。
技术特性
-
IP数据管理框架
-
xdb支持亿级别的IP数据段行数。
-
region信息支持完全自定义,可以包含额外业务数据。
-
-
数据去重和压缩
-
自动生成的xdb数据库体积控制在合理范围内。
-
-
极速查询响应
-
支持两种内存加速查询方式:vIndex索引缓存和xdb文件缓存。
-
使用案例
Maven依赖
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>2.7.0</version>
</dependency>
完全基于文件的查询
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
String dbPath = "path/to/ip2region.xdb";
Searcher searcher = null;
try {
searcher = Searcher.newWithFileOnly(dbPath);
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros(System.nanoTime() - sTime);
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("Error: %s\n", e);
} finally {
if (searcher != null) searcher.close();
}
}
}
开源协议
Ip2region 是一个开源项目,遵循Apache License Version 2.0协议,对商用友好,拿来即用。
结语
Ip2region 以其强大的功能和灵活的设计理念,为IP地址定位带来了全新的体验。无论是对于新手开发者还是经验丰富的工程师,都能从中找到适合自己的工具和方法。
如果你也希望能够在处理大规模IP数据时保持高-效,简化工作流程,那么Ip2region 将是一个不错的选择。
应用业务场景:
1、数据统计分析:对于需要根据用户地理位置进行数据汇总分析的应用,如市场调研、受众分析等,IP定位可以帮助更好地理解用户分布情况。
2、内容定制:根据用户所在的地区提供定制化的内容或语言版本,比如网站、视频流服务等。
源码:https://gitee.com/lionsoul/ip2region