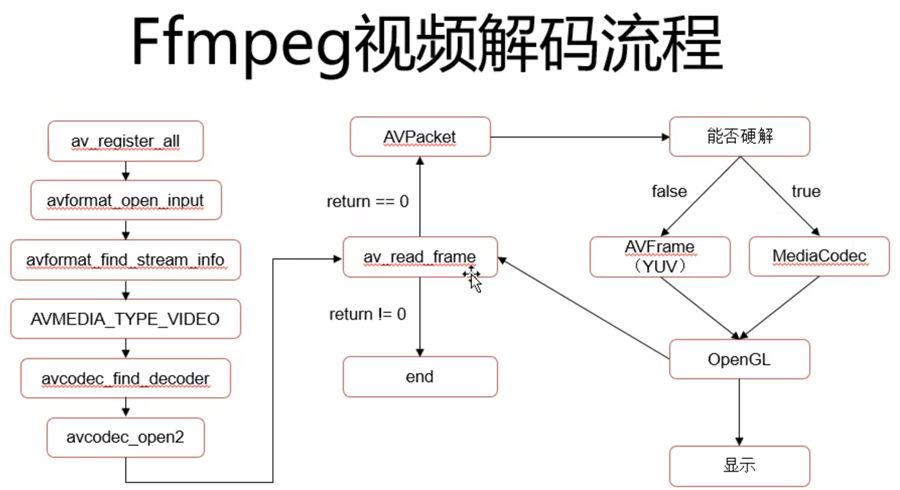
前言:
在本章中,我们开始编写面向用户的界面,其中只涉及简单的HTML结构,不会做太多美化,目的就是把后台创建的数据展示到前台。
从技术上来讲,这一节将涉及Django 中function view和 class-based view 的用法,它们本身没有优劣之分,也不是说用class-based view就是高级技术。场景不同,需要用到的技术也不同,仅此而已。
本章中,我们先使用function view来完成前台逻辑的编写,最后演化到class-based view,这样能够对这两个方法或者技术有更直观的认识。另外需要意识到的一件事是,这些Django 提供的接口或者方法都是Python代码写出来的,所以它们本身都是为了符合某种场景而抽象出来的东西,就像Django一样。
好了,我们开始吧。
第四章:开发面向用户的界面
4.1 搭建基础结构与展示文章数据
在开发面向用户的界面时,首先要整理出需要多少种URL,即存在多少种页面(每种页面对应一类URL),然后再来编写View的代码,这种方式的好处是可以去掉重复的逻辑。
接着要分析页面上需要呈现的数据,不同的数据意味着要用到不同的模型或者字段。在整个梳理的过程中,可能会突然意识到我们缺了某个字段,不过没关系,开发阶段还是可以即时调整字段的。因为目前并没有正式数据,调整字段不会有什么影响,但如果上线之后有字段调整的需求,就需要考虑一下新增字段对现有业务的影响了。
4.1.1 分析URL和页面数据
我们在第1章中做需求分析时也整理过了,对于这个需求,需要有这几个页面:
- 博客首页
- 博文详情页
- 分类列表页
- 标签列表页
- 友链展示页
我们可以先定义好URL,假设最终的网址是https://www.buranshifei.com,那么对应的页面如下所示。
- 博客首页:https://www.buranshifei.com/
- 博文详情页:https://www.buranshifei.com/post/<post_id>.html
- 分类列表页:https://www.buranshifei.com/category/<category_id>/
- 标签列表页:https://www.buranshifei.com/tag/<tag_id>/
- 友链展示页:https://www.buranshifei.com/links/
页面如何布局呢?我们可以自己构思一下,通常的博客布局如下图所示。

通过布局和URL,我们可以得出页面中的大部分数据是共用的。比如说博客首页、分类列表页和标签列表页,本质上都是文章列表页,只是其他信息稍有差别。因此,View 的逻辑可以划分为两类:
- 根据不同的查询条件展示列表页
- 展示博文详情页
不过,友链展示页是独立的逻辑。
所以,View只需要三个即可。
- 列表页View:根据不同的查询条件分别展示博客首页、分类列表页和标签列表页。
- 文章页View:展示博文详情页。
- 友链页View:展示所有友情链接。
4.1.2 编写URL代码
有了上面的分析,我们开始编写URL的代码:
# typeidea/urls.py
from django.contrib import admin
from django.urls import path
from blog.views import post_list, post_detail
from config.views import links
from typeidea.custom_site import custom_site
urlpatterns = [
path('', post_list, name='post-list'),
path('category/<int:category_id>/', post_list, name='category-list'),
path('tag/<int:tag_id>/', post_list, name='tag-list'),
path('post/<int:post_id>/', post_detail, name='post-detail'),
path('links/', links, name='links'),
path('super_admin/', admin.site.urls, name='super-admin'),
path('admin/', custom_site.urls, name='admin'),
]
这里定义了三个View——post_list、post_detail和 links,从命名上就能看到它们要处理的逻辑。在编写对应的View之前,先来解释一下上面的定义。
我们可以将URL的定义理解为是一个路径(正则字符串)对应一个函数的映射,比如path('', post_list, name='post_list')意味着如果用户访问博客首页,就把请求传递到post_list这个函数中,该函数的参数下面会介绍。在URL的定义中,还有其他参数。完整的URL参数解释如下:
path(<URL的路径模式>, < view function> , [kwargs=[额外的关键字参数]], <URL名称>)
下面来看一个完整的例子。这里还是以post_list为例,可以这么定义URL:
path('category/<int:category_id>/', post_list, {'example':'nop'}, name='category_list')
这里首先定义了一个URL路径模式,它通过定义<int:category_id>把URL这个位置的字符作为名为category_id的参数传递给post_list函数。第二个参数定义用来处理请求的函数。第三个参数定义默认传递过去的参数,也就是无论什么请求过来,都会传递(‘example’:‘nop’)到post_list 中。第四个参数是这个URL的名称。
接着,再来编写View的代码,各项参数你需要能对上号。
4.1.3 编写View代码
先来搭一个简单的架子,让用户访问URL之后出现定义的内容。在blog/views.py中先添加如下代码:
# blog/views.py
from django.http import HttpResponse
def post_list(request, category_id=None, tag_id=None):
content = 'post_list category_id=(category_id), tag_id=(tag_id)'.format(
category_id=category_id,
tag_id=tag_id,
)
return HttpResponse(content)
def post_detail(request, post_id):
return HttpResponse('detail')
这两个函数仅仅是通过HttpResponse返回了简单的字符串,函数定义中的参数是从URL中传递过来的。其实从定义上也能看出 Django的处理逻辑——从正则表达式中解析要匹配的关键字,比如说 < int:category_id >,然后将其作为参数传递到函数中。
根据这一逻辑,可以处理不同的URL匹配到同一个函数的逻辑。我们可以通过不同的参数来区分当前请求是来自博客首页,还是来自分类列表页,或者是来自标签列表页。
接着可以编写友链(links)的处理逻辑,config/views.py中相关代码如下:
# config/views.py
from django.http import HttpResponse
def links(request):
return HttpResponse('links')
这里只返回简单的字符串。因为在 links的URL定义中没有参数,所以这里也不需要定义除request之外的参数。
此时可以运行一下代码。启动Django程序,然后依次访问以下地址,看看页面结果:
- http://127.0.0.1:8000/
- http://127.0.0.1:8000/category/1/
- http://127.0.0.1:8000/tag/1/
- http://127.0.0.1:8000/post/2
- http://127.0.0.1:8000/links/
你可以尝试对views.py中的代码做些修改,然后观察结果。我们可以通过不断修改代码来理解View 的作用。
上面只是简单实现了从URL到View的数据映射,接着来增加对模板的处理,我们依然只是填充简单的内容。
根据下面的代码来修改blog/views.py中的代码:
# blog/views.py
from django.shortcuts import render
def post_list(request, category_id=None, tag_id=None):
return render(request, 'blog/list.html', context={'name': 'post_list'})
def post_detail(request, post_id=None):
return render(request, 'blog/detail.html', context={'name': 'post_detail'})
这里需要稍稍介绍一下render方法,它接收的参数如下:
render(request, template_name, context=None, content_type=None,
status=None,using=None)
其中各参数的意义如下。
- request:封装了HTTP请求的request 对象。
- template_name: 模板名称,可以像前面的代码那样带上路径。
- context:字典数据,它会传递到模板中。
- content_type:页面编码类型,默认值是text/html。
- status:状态码,默认值是200。
- using:使用哪种模板引擎解析,这可以在settings中配置,默认使用Django自带的模板。
了解了render的基本用法之后,需要编写模板代码。
4.1.4 配置模板
在日常开发中,创建模板常用的方法有两种:一种是每个 App各自创建自己的模板;另外一种是统一放到项目同名的App中,也就是typeidea中。
我们考虑到后期可能需要配置多个模板,因此就放在一起,都放到typeidea/typeidea/目录下。
首先进入对应目录,创建templates、templates/blog/和templates/config/目录。
创建完之后,目前typeidea 的完整结构如下,其中去掉了各 App的文件夹下内容的展示:

先在templates/blog/目录下创建 list.html和detail.html文件。
list.html文件如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>list</h1> <!-- 新增 -->
{{ name }}
</body>
</html>
detail.html文件如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>detail</h1> <!-- 新增 -->
{{ name }}
</body>
</html>
这里只输出一个名字。
现在可以运行项目,访问首页http://127.0.0.1:8000,观察一下提示了什么?如果报错,仔细看一下出错提示。我建议你完整阅读错误提示,因为学会看错误也是技能之一。
4.1.5 模板找不到的错误处理
可能你会看到这样的提示:
TemplateDoesNotExist at blog/list.html
下面还有 Template-loader postmortem 字样,你可以看看它提示的路径是什么。新手程序员看到错误经常会恐慌,其实不必如此。程序出错一般会给出明确的提示,给你一些线索,帮助你定位错误。Django这么完善的框架也是如此。
针对这个错误,其大致意思是:“我找了多少个目录,都没找到你说的资源。”
这时候就要去看看它有没有去查找模板目录,如果没有,那说明模板不在它的查找范围,你需要去配置 INSTALLED_APPS。如果它列出了你放置模板的 App,但是提示未找到,那么应该检查一下模板名称是不是有写错的情况。
针对这个错误,因为我们的模板目录在typeidea 下面,所以需要把它加到settings配置的INSTALLED_APPS 中。
加入之后的INSTALLED_APPS 如下:
INSTALLED_APPS = [
'typeidea', # 增加这个App
'blog.apps.BlogConfig',
'config.apps.ConfigConfig',
'comment.apps.CommentConfig',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
再次刷新页面,看到正常输出了。
好了,如果你是自己解决这个问题的,那么恭喜你,你已经具有基本的分析异常并解决问题的能力了。
4.1.6 编写正式的View代码
通过上面的内容,你已经理清了URL到View,View到模板的逻辑了。理解了这个流程,这个架子就算搭好了。接着,需要填充内容了。
这里需要做的就是通过Model层把数据从数据库中读取出来,然后展示到页面上。在前面的章节中,我们已经学习了Model部分的操作,你可以根据自己的理解尝试独立完成内容的获取。
我们先来完成post_list 和post_detail的逻辑,后面再来完成其他部分的代码。先来梳理一下这两个部分的逻辑。
post_list 的逻辑是:使用Model从数据库中批量拿取数据,然后把标题和摘要展示到页面上。
post_detail的逻辑也一样,只不过是只展示一条数据。
我们来编写具体代码:
# blog/views.py
from django.shortcuts import render
from .models import Post, Tag
def post_list(request, category_id=None, tag_id=None):
if tag_id:
try:
tag = Tag.objects.get(id=tag_id)
except Tag.DoesNotExist:
post_list = []
else:
post_list = tag.post_set.filter(status=Post.STATUS_NORMAL)
else:
post_list = Post.objects.filter(status=Post.STATUS_NORMAL)
if category_id:
post_list = post_list.filter(category=category_id)
return render(request, 'blog/list.html', context={'post_list': post_list})
def post_detail(request, post_id=None):
try:
post = Post.objects.get(id=post_id)
except Post.DoesNotExist:
post = None
return render(request, 'blog/detail.html', context={'post': post})
先来解释一下上面的代码。post_detail很简单,这里不做解释。
post_list 中的逻辑看似有些复杂,其主要复杂之处在于同一个函数中处理了多种请求,就是前面说的博客首页、分类列表页和标签列表页。我们可以通过判断不同的参数来处理不同的逻辑。
其中需要解释的有两个位置:第一个是如果查询到不存在的对象,需要通过try…except…来捕获并处理异常,避免当数据不存在时出现错误;第二个是tag与post 是多对多的关系,因此需要先获取 tag 对象,接着通过该对象来获取对应的文章列表。
最终传递到模板中的数据分别为post_list 和post。下面配置模板来展示这些数据。
4.1.7 配置模板数据
在模板中,我们只需要根据View传递的数据展示即可,这里先配置与文章相关的数据。
template/blog/list.html的代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<ul>
{% for post in post_list %}
<li>
<a href="/post/{{ post.id }}">{{ post.title }}</a>
<div>
<span>作者:{{ post.owner.username }}</span>
<span>分类:{{ post.category.name }}</span>
</div>
<p>{{ post.desc }}</p>
</li>
{% endfor %}
</ul>
</body>
</html>
template/blog/detail.html的代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{% if post %}
<h1>{{ post.title }}</h1>
<div>
<span>分类:{{ post.category.name }}</span>
<span>作者:{{ post.owner.username }}</span>
</div>
<hr/>
<p>
{{ post.content }}
</p>
{% endif %}
</body>
</html>
它们其实是简单的模板语法,里面用到了for循环、if 条件判断以及变量获取。这跟Python语法类似。
需要注意的是,我们在detail.html中需要判断post 是否存在,以免在对象未获取到(即post=None)时出错。
另外一点就是外键内容的获取,比如post.category.name和 post.owner.username.这个代码理解起来并不困难,不过这里的问题需要重视。因为是外键查询,所以每一条记录的请求都需要对应查询一次数据库来获取关联外键的数据。即列表页要展示10条文章数据,每一个关联外键的查询都会产生一次数据库请求,这就是我们前面提到的N+1问题。
也就是一次文章列表页的查询会对应着N次相关查询,这是非常损耗性能的事。我们将在后面的代码中解决这个问题,你也可以根据前面讲过的方法自行处理。
编写好上述代码后,运行程序,打开浏览器,分别访问博客首页和博文详情页,应该能得到与下图中类似的页面效果。


4.1.8 总结
在这一节中,我们通过编写function view代码,把数据从数据库中取出,并放到模板中展示。
在下一节中,我们将完善页面结构,展示更多信息。另外,我们将补充通用的页面配置,比如对分类、标签、最新文章、最热文章等的展示。
4.1.9 参考资料
Django render的用法:
https://docs.djangoproject.com/zh-hans/4.2/topics/http/shortcuts/
4.2 配置页面通用数据
上一节中,我们简单处理了与文章相关的数据。如果你手动编写了代码并且能成功运行,那么你应该知道如何通过function view来完成需求。这一节中,我们来完善页面信息,然后把通用的数据都拿出来塞到页面上。
4.2.1 完善模板信息
首先说博客首页、分类列表页、标签列表页的数据,这三个页面目前都是一样的,只是内容不同,因此我们需要做一下区分。另外,目前的 HTML 结构并不完整,我们需要根据 HTML5标准来组织页面。
先完成列表页的信息展示,主要是增加不同页面的信息展示。这里先修改 post_list里的逻辑,改后的代码如下:
# blog/views.py
from django.shortcuts import render
from .models import Post, Tag, Category
def post_list(request, category_id=None, tag_id=None):
tag = None
category = None
if tag_id:
try:
tag = Tag.objects.get(id=tag_id)
except Tag.DoesNotExist:
post_list = []
else:
post_list = tag.post_set.filter(status=Post.STATUS_NORMAL)
else:
post_list = Post.objects.filter(status=Post.STATUS_NORMAL)
if category_id:
try:
category = Category.objects.get(id=category_id)
except Category.DoesNotExist:
category = None
else:
post_list = post_list.filter(category_id=category_id)
context = {
'category': category,
'tag': tag,
'post_list': post_list,
}
return render(request, 'blog/list.html', context=context)
# 省略其他代码
相应的list.html模板改为
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>typeidea 博客系统</title> <!-- 标题也进行修改 -->
</head>
<body>
<!-- 新增代码 -->
{% if tag %}
标签页: {{ tag.name }}
{% endif %}
{% if category %}
分类页: {{ category.name }}
{% endif %}
<!-- -->
<ul>
{% for post in post_list %}
<li>
<a href="/post/{{ post.id }}">{{ post.title }}</a>
<div>
<span>作者:{{ post.owner.username }}</span>
<span>分类:{{ post.category.name }}</span>
</div>
<p>{{ post.desc }}</p>
</li>
{% endfor %}
</ul>
</body>
</html>
这样在观察不同的页面时,就能看到不同的信息提示。现在你可以运行代码看看效果。不得不说,现在View部分的代码有点复杂,因为我们在一个函数中处理了过多的业务,所以也就出现很多条件分支。这样的代码已经存在“坏味道”了,后面可以稍微做一些重构。
4.2.2 重构post_list视图
上面说到,post_list 函数的代码到目前已经出现“坏味道”了,我们需要避免它继续变坏,因此先对其进行重构。这里先来了解一下重构的思路,这个代码有两个逻辑。
第一,我们可以把复杂的部分抽取成为单独的函数,比如通过tag 来获取文章列表。其实对于我们的主函数post_list 来说,只需要通过tag_id拿到文章列表和tag 对象就行,因此可以把这个逻辑抽出去作为独立的函数。分类的处理也一样。
第二,从根源上来分析。造成post_list 函数复杂的原因是我们把多个URL的处理逻辑都放到一个函数中,这个函数不得不通过各种条件语句来处理多种业务逻辑。
关于第二个逻辑,后面会通过另外的方式来解决。这里我们对第一个逻辑进行重构。
首先,抽取两个函数分别来处理标签和分类。因为这两个函数用于处理 Post 相关的数据,所以我们把它们定义到Model层,同时处理上一节留下的问题,把获取最新文章数据的操作放到Model 层中。我们来修改 Post 模型(文件 blog/models.py)的定义:
# blog/models.py
# 省略其他代码
class Post(models.Model):
STATUS_NORMAL = 1
STATUS_DELETE = 0
STATUS_DRAFT = 2
STATUS_ITEMS = (
(STATUS_NORMAL, '正常'),
(STATUS_DELETE, '删除'),
(STATUS_DRAFT, '草稿')
)
title = models.CharField(max_length=255, verbose_name='标题')
desc = models.CharField(max_length=1024, blank=True, verbose_name='摘要')
content = models.TextField(verbose_name='正文', help_text="正文必须为MarkDown格式")
status = models.PositiveIntegerField(choices=STATUS_ITEMS, default=STATUS_NORMAL, verbose_name='状态')
category = models.ForeignKey(Category, verbose_name='分类', on_delete=models.CASCADE)
tag = models.ManyToManyField(Tag, verbose_name='标签')
owner = models.ForeignKey(User, verbose_name='作者', on_delete=models.CASCADE)
created_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
def __str__(self):
return self.title
class Meta:
verbose_name = verbose_name_plural = '文章'
ordering = ['-id'] # 根据id进行降序排序
# 新增如下代码!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
@staticmethod
def get_by_tag(tag_id):
try:
tag = Tag.objects.get(id=tag_id)
except Tag.DoesNotExist:
tag = None
post_list = []
else:
post_list = tag.post_set.filter(status=Post.STATUS_NORMAL).select_related('owner', 'category')
return post_list, tag
@staticmethod
def get_by_category(category_id):
try:
category = Category.objects.get(id=category_id)
except Category.DoesNotExist:
category = None
post_list = []
else:
post_list = category.post_set.filter(category=category_id).select_related('owner', 'category')
return post_list, category
@classmethod
def latest_posts(cls):
queryset = cls.objects.filter(status=cls.STATUS_NORMAL)
return queryset
接着修改blog/views.py中的代码,修改之后的post_list 代码如下:
# blog/views.py
from django.shortcuts import render
from .models import Post
def post_list(request, category_id=None, tag_id=None):
tag = None
category = None
# 修改部分!!!!!!!!!!!!!!
if tag_id:
post_list, tag = Post.get_by_tag(tag_id)
elif category_id:
post_list, category = Post.get_by_category(category_id)
else:
post_list = Post.latest_posts()
context = {
'category': category,
'tag': tag,
'post_list': post_list,
}
return render(request, 'blog/list.html', context=context)
# 省略其他代码
这样View中的逻辑看起来就清晰多了。另外,在上面的重构中,我们也通过select_related方式解决了上一节提到的部分N+1问题。
4.2.3 分类信息
接下来,需要做的是把导航信息展示到页面上。我们把分类作为一个导航来展示给访客或读者,在分类的设计上,我们也定义了is_nav字段,作者可以确定将哪些分类放到导航上。
我们来编写获取分类的代码。需要注意的是,我们需要一个独立的函数,然后在post_list和post_detail中使用该函数获取基础数据。
我们既可以考虑在View层来编写这个函数,也可以在Model层来完成,不过数据操作的部分建议放到Model层。
我们在blog/models.py中编写下面的代码:
# blog/models.py
class Category(models.Model):
STATUS_NORMAL = 1
STATUS_DELETE = 0
STATUS_ITEMS = (
(STATUS_NORMAL, '正常'),
(STATUS_DELETE, '删除'),
)
name = models.CharField(max_length=50, verbose_name='名称')
status = models.PositiveIntegerField(choices=STATUS_ITEMS, default=STATUS_NORMAL, verbose_name='状态')
is_nav = models.BooleanField(default=False, verbose_name='是否为导航')
owner = models.ForeignKey(User, verbose_name='作者', on_delete=models.CASCADE)
created_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
def __str__(self):
return self.name
class Meta:
verbose_name = verbose_name_plural = '分类'
# 新增如下代码!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
@classmethod
def get_navs(cls):
categories = cls.objects.filter(status=cls.STATUS_NORMAL)
nav_categories = categories.filter(is_nav=True)
normal_categories = categories.filter(is_nav=False)
return {
'navs': nav_categories,
'categories': normal_categories,
}
# 省略其他代码
这个函数用来获取所有的分类,并且区分是否为导航。但是这种写法存在一个问题,那就是它会产生两次数据库请求。我们在模型优化的部分讲过QuerySet 的懒惰特性。第一个 filter 函数在被调用时并不会产生数据库访问,因为返回的对象还未被使用。但我们返回的是nav_categories 和normal_categories 这两个QuerySet 对象,它们会被用在其他地方。在使用时,它们会分别产生自己的查询语句。对系统来说,就是两次I/O操作。
考虑到在数据量小的情况下,我们可以通过简单的if判断来处理是否为导航的逻辑,那就没必要产生一次额外的 I/O操作了。要知道,在生产环境中每一次 I/O操作的代价是相对较高的。但这并非绝对,具体需要考虑业务场景。
因此,我们可以将上面的代码重构为:
# blog/models.py
class Category(models.Model):
STATUS_NORMAL = 1
STATUS_DELETE = 0
STATUS_ITEMS = (
(STATUS_NORMAL, '正常'),
(STATUS_DELETE, '删除'),
)
name = models.CharField(max_length=50, verbose_name='名称')
status = models.PositiveIntegerField(choices=STATUS_ITEMS, default=STATUS_NORMAL, verbose_name='状态')
is_nav = models.BooleanField(default=False, verbose_name='是否为导航')
owner = models.ForeignKey(User, verbose_name='作者', on_delete=models.CASCADE)
created_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
def __str__(self):
return self.name
class Meta:
verbose_name = verbose_name_plural = '分类'
# 修改如下代码!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
@classmethod
def get_navs(cls):
categories = Category.objects.filter(status=cls.STATUS_NORMAL)
nav_categories = []
normal_categories = []
for cate in categories:
if cate.is_nav:
nav_categories.append(cate)
else:
normal_categories.append(cate)
return {
'navs': nav_categories,
'categories': normal_categories,
}
# 省略其他代码
这样只需要一次数据库查询,即可拿到所有数据,然后在内存中进行数据处理。
接着,需要修改post_list中context 部分的代码,增加上述分类数据:
# blog/views.py
def post_list(request, category_id=None, tag_id=None):
# 省略其他代码
context = {
'category': category,
'tag': tag,
'post_list': post_list,
}
context.update(Category.get_navs())
return render(request, 'blog/list.html', context=context)
根据同样的方式修改post_detail的代码:
# blog/views.py
def post_detail(request, post_id=None):
try:
post = Post.objects.get(id=post_id)
except Post.DoesNotExist:
post = None
context = {
'post': post,
}
context.update(Category.get_navs())
return render(request, 'blog/detail.html', context=context)
现在我们已经把分类的数据塞到模板中了,接下来需要在模板中展示出这些信息了。
我们在之前list.html 中进行修改:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>typeidea 博客系统</title>
</head>
<body>
<!-- 修改部分开始 -->
<div>顶部分类:
{% for cate in navs %}
<a href="/category/{{ cate.id }}/">{{ cate.name }}</a>
{% endfor %}
</div>
<hr/>
<!-- 修改部分结束 -->
{% if tag %}
标签页: {{ tag.name }}
{% endif %}
{% if category %}
分类页: {{ category.name }}
{% endif %}
<ul>
{% for post in post_list %}
<li>
<a href="/post/{{ post.id }}">{{ post.title }}</a>
<div>
<span>作者:{{ post.owner.username }}</span>
<span>分类:{{ post.category.name }}</span>
</div>
<p>{{ post.desc }}</p>
</li>
{% endfor %}
</ul>
<!-- 修改部分开始 -->
<hr/>
<div>底部分类:
{% for cate in categories %}
<a href="/category/{{ cate.id }}/">{{ cate.name }}</a>
{% endfor %}
</div>
<!-- 修改部分结束 -->
</body>
</html>
这样就把分类数据也展示到页面上了,你可以到后台增加数据,看看展示结果。这里需要注意的是,目前在页面上写的URL地址依然是硬编码上去的,后面我们会通过reverse方式来解耦。

4.2.4 侧边栏配置
根据布局规划,每个页面都会有侧边栏数据,因此还需要增加侧边栏数据。同上面一样,我们需要新增一个函数来获取侧边栏数据,以便它们在post_list和post_detail中都能够使用。
直接在config/models.py中定义的SideBar 中新增类函数 get_all:
# config/models.py
class SideBar(models.Model):
# 省略其他代码
@classmethod
def get_all(cls):
return cls.objects.filter(status=cls.STATUS_SHOW)
接着,修改post_list和post_detial中的context代码:
# blog/views.py
# 省略其他代码
context = {
# 省略其他代码
'sidebars': SideBar.objects.all(), # (两个context中都要增加'sidebars': SideBar.objects.all(),)
}
View中的代码编写好了,接着来修改template。在list.html和detail.html的最下面(的上面)新增代码:
<div>侧边栏展示:
{% for sidebar in sidebars %}
<h4>{{ sidebar.title }}</h4>
{{ sidebar.content }}
{% endfor %}
</div>
这里先忽略sidebar类型的处理,下一节会单独处理这个逻辑。

4.2.5 总结
到此为止,我们已经把通用数据都放到页面上了。目前,还有两个瑕疵:一个是样式确实比较丑,当前的重点在数据展示上,后面再来处理美化问题;另一个是现在的侧边栏只能展示类型为HTML的内容,无法展示之前设计的最近文章、最热文章等数据。
下一节中,我们来单独处理侧边栏的展示。
4.3 封装侧边栏逻辑
因为侧边栏的逻辑比较复杂,所以专门用一节来处理。这里主要处理两个问题:一个是把复杂的逻辑封装起来,在模板中只需要使用sidebar.content 即可;另一个是调整Post 模型,以满足我们获取最热文章的逻辑
4.3.1 调整模型
我们需要给Post 增加两个字段,分别为pv和uv,它们用来统计每篇文章的访问量。同时,也需要把最新文章和最热文章包装到Post的方法上,便于其他业务进行语义化调用。
修改Post 模型的定义,在其中增加字段和方法:
# blog/models.py
class Post (models.Model):
#省略其他已有字段
pv = models.PositiveIntegerField(default=1)
uv = models.PositiveIntegerField(default=1)
#省略其他代码
@classmethod
def hot_posts(cls):
return cls.objects.filter(status=cls.STATUS_NORMAL).order_by('-pv')
修改完字段后,需要做一下迁移:
python manage.py makemigrations
python manage.py migrate

这样 Post 模型的调整就算完成了。其实可以更进一步处理,根据在模板中需要用到的字段,通过only方法进行优化,比如在侧边栏展示热门文章时,只需要用到title和id这两个字段。关于only的用法,详见2.4节。
作为扩展练习,你可以自己处理这个优化。如果遇到无法解决的问题,欢迎联系我。
4.3.2 封装好 SideBar
接着,需要封装SideBar。在上一节中,我们在模板中使用了sidebar.content 来展示数据。对于类型为HTML的数据,可以直接展示,但对于其他类型的数据,就会有问题。
因为SideBar 中不同类型对应着不同的数据源,所以一般有两种方式来处理:第一种是把数据获取的逻辑放到Model层,直接从 Model层渲染数据到模板上,然后拿到渲染好的HTML数据并将其放到上一节写的SideBar 部分;第二种是在模板中抽取 SideBar 为独立的block,不同的数据源需要在不同页面对应的View层来获取。
这里我们采用第一种方案,把数据的获取封装到Model层,这样可以有更好的通用性,同时也能避免View层的逻辑过多。从经验上来说,大部分业务的调整都发生在View层,因此在起初的结构中,我们应该尽量保证View层足够“瘦”,避免后期维护麻烦。
不过即便把数据封装到Model层,也需要定义单独的模板block来渲染SideBar的数据。
先来整理一下思路:根据需要展示的类型,在Model层直接对数据做渲染,最终返回渲染好的数据。因为有几种类型,不同类型的数据展示不一样,所以需要处理不同的数据源。
首先,在Model中处理数据源。在这里处理的好处是,除了语义上更加明确外,还可以避免冗余。
我们在 SideBar 模型中增加一个方法,同时修改之前 SIDE_TYPE 中用到的数字,通过变量替代,避免代码中出现Magic Number(魔术数字)的问题:
# config/models.py
class SideBar(models.Model):
DISPLAY_HTML = 1
DISPLAY_LATEST = 2
DISPLAY_HOT = 3
DISPLAY_COMMENT = 4
SIDE_TYPE = (
(DISPLAY_HTML, 'HTML'),
(DISPLAY_LATEST, '最新文章'),
(DISPLAY_HOT, '最热文章'),
(DISPLAY_COMMENT, '最近评论'),
)
# 省略其他代码
@property
def content_html(self):
""" 直接渲染模板 """
from blog.models import Post
from comment.models import Comment
result = ''
if self.display_type == self.DISPLAY_HTML:
result = self.content
elif self.display_type == self.DISPLAY_LATEST:
context = {
'posts': Post.latest_posts()
}
result = render_to_string('config/sidebar_posts.html', context)
elif self.display_type == self.DISPLAY_HOT:
context = {
'posts': Post.hot_posts()
}
result = render_to_string('config/sidebar_posts.html', context)
elif self.display_type == self.DISPLAY_COMMENT:
context = {
'comments': Comment.objects.filter(status=Comment.STATUS_NORMAL)
}
result = render_to_string('config/sidebar_comments.html', context)
return result
在整个模块(config/models.py)的最上方增加render_to_string的引用:
from django.template.loader import render_to_string
在content_html方法中,我们用到了两个模板:sidebar_posts.html 和sidebar_comments.html分别来实现一下,模板位置在typeidea/templates/config/下。
sidebar_posts.html的代码如下:
<ul>
{% for post in posts %}
<li><a href="/post/{{ post.id }}/">{{ post.title }}</a>
{% endfor %}
</ul>
sidebar_comments.html 的代码如下:
<ul>
{% for comment in comments %}
<li><a href="/post/{{ comment.target_id }}/">{{ comment.target.title }}</a> | {{ comment.nickname }} : {{ comment.content }}
{% endfor %}
</ul>
这样我们就完成了SideBar 的封装。在之前的 list.html中,我们需要把sidebar.content 修改为sidebar.content_html。

4.3.3 总结
稍稍总结一下,其实你应该也能体验出来,拆分之后,每部分的逻辑都比较明确。如果需要修改样式,那就修改模板。而数据源是按需加载的,比方说只有你选择展示最新文章时,才会去加载对应数据。
另外,建议你考虑一下另外一种实现方案。如果要在View层做处理的话,怎么做?别偷懒,需要再次强调的是,单纯地读完本书,对你来说可能只是涨了些知识而已,这些东西需要在实践后才能转换成经验。
到此为止,我们就完成了数据的封装。接下来,对模板进行抽象和优化。
4.4 整理模板代码
这部分主要有两块内容:一是抽象出基础模板,因为有通用的数据,所以可以通过基类的方式实现;二是去掉模板中不合理的硬编码。
4.4.1 抽象基础模板
在前两节中,我们在 list.html中处理侧边栏数据的展示。对于页面结构来说,也需要在文章详情页展示侧边栏数据,那么要怎么处理呢?复制代码,然后粘贴过去吗?显然这是不合理的。
因为除了这一部分之外,还有其他代码(比如频道导航和页脚)也需要共用,如果直接复制过去,那么有新的需求时,就要修改两个地方。这是复制代码最大的危害,提高了代码的维护成本。
这一节中,我们先来抽象基础模板。首先,在 list.html同级目录下创建base.html,然后把通用代码从list.html中剪切过去。
base.html的代码如下:
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf-8"/>
<title>{% block title %}首页{% endblock %}- typeidea博客系统</title>
</head>
<body>
<div>顶部分类:
{% for cate in navs %}
<a href="/category/{{ cate.id }}">{{ cate.name }}</a>
{% endfor %}
</div>
<hr/>
{% block main %}
{% endblock %}
<hr/>
<div>底部分类:
{% for cate in categories %}
<a href="/category/{{ cate.id }}">{{ cate.name }}</a>
{% endfor %}
</div>
<hr/>
<div>侧边栏展示:
{% for sidebar in sidebars %}
<h4>{{ sidebar.title }}</h4>
{{ sidebar.content_html }}
{% endfor %}
</div>
</body>
</html>
在上面的代码中,我们定义了几个block,方便重写子模板。
- block title:页面标题。
- block main: 页面主内容区。
这样的话,子模板中只需要分别实现这两个block即可。接着,来看下 list.html和detail.html 的代码。
list.html的代码如下:
{% extends "blog/base.html" %}
{% block title %}
{% if tag %}
标签页: {{ tag.name }}
{% elif category %}
分类页: {{ category.name }}
{% else %}
首页
{% endif %}
{% endblock %}
{% block main %}
<ul>
{% for post in post_list %}
<li>
<a href="/post/{{ post.id }}">{{ post.title }}</a>
<div>
<span>作者:{{ post.owner.username }}</span>
<span>分类:{{ post.category.name }}</span>
</div>
<p>{{ post.desc }}</p>
</li>
{% endfor %}
</ul>
{% endblock %}
detail.html的代码如下:
{% extends "blog/base.html" %}
{% block title %}
{{ post.title }}
{% endblock %}
{% block main %}
{% if post %}
<h1>{{ post.title }}</h1>
<div>
<span>分类:{{ post.category.name }}</span>
<span>作者:{{ post.owner.username }}</span>
</div>
<hr/>
<p>
{{ post.content }}
</p>
{% endif %}
{% endblock %}
可以发现,list.html和detail.html中的代码都比之前简洁很多。其实模板的继承跟类的继承一样,如果能够定义一个合适的基类,那么子类中只需针对自己的特性或者场景来实现,整个逻辑会变得非常简单,同时后期的维护成本也会很低。
你可能会有疑问,什么情况下需要抽象出子类,什么情况下不抽取子类。其实设计模式中有一个原则很重要,叫开-闭原则,意思是对扩展开放,对修改关闭。通俗点说就是,如果你发现每次实现新需求时,都需要去修改定义好的代码结构,那么你的逻辑是不合理的。合理的方式是,通过继承原有的类(即扩展)来实现新需求。如何识别哪些代码需要抽取到父类中呢?从经验上来说,把在各个地方都会用到但不经常发生变动的代码抽取到父类中。
4.4.2 解耦硬编码
接着,我们来处理硬编码的问题。什么样的代码算是硬编码呢?在代码评审时或者你在读别人代码时,如果发现在逻辑运算中存在无意义的数字(即Magic Number),就可以给出这个建议:是否可以通过定义更加语义化的变量来取代毫无意义的数字,降低代码维护时的心智负担(也就是需要查询好多其他代码才能搞明白这个数字的含义)?
数字只是其中一种,我们在模板中遇到的问题是写了很多固定的 URL的定义。比如,在list.html代码中配置的URL:
<a href="/post/{{ post.id }}">{{ post.title }}</a>
文章详情页的URL定义是path('post/<int:post_id>/', post_detail, name='post_detail'),上面的写法没问题,但是问题在于这两部分代码是紧耦合在一起的,就像前面说到的复制+粘贴的后果一样。假如需要变更URL地址,此时就需要去修改所有根据这个定义写死的代码,可能不仅仅是list.html中。
那么,怎么处理呢?前面也提到过 reverse 这个函数。Django 给我们提供了URL 反向解析的函数,但是需要在定义URL时加上name参数。reverse的作用就是通过name反向解析成URL我们先来修改 urls.py中的定义代码:
这里跟大家道个歉,在之前的代码中这里就已经添加过name属性了,只不过在这里才开始详细介绍添加name属性的作用。
# 没有任何修改
from django.contrib import admin
from django.urls import path
from blog.views import post_list, post_detail
from config.views import links
from typeidea.custom_site import custom_site
urlpatterns = [
path('', post_list, name='post-list'),
path('category/<int:category_id>/', post_list, name='category-list'),
path('tag/<int:tag_id>/', post_list, name='tag-list'),
path('post/<int:post_id>/', post_detail, name='post-detail'),
path('links/', links, name='links'),
path('super_admin/', admin.site.urls, name='super-admin'),
path('admin/', custom_site.urls, name='admin'),
]
在上面的URL定义中,我们都添加了name,接着需要对模板代码中URL硬编码的部分进行修改。下面是对 list.html文件的修改,你需要根据示例去修改其他页面的URL(在下面同样会给出):
<li>
<a href="{% url 'post-detail' post.id %}">{{ post.title }}</a> <!-- 改动地方 -->
<div>
<span>作者:{{ post.owner.username }}</span>
<span>分类:{{ post.category.name }}</span>
</div>
<p>{{ post.desc }}</p>
</li>
对base.html进行修改:
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf-8"/>
<title>{% block title %}首页{% endblock %}- typeidea博客系统</title>
</head>
<body>
<div>顶部分类:
{% for cate in navs %}
<a href="{% url 'category-list' cate.id %}">{{ cate.name }}</a> <!-- 改动地方 -->
{% endfor %}
</div>
<hr/>
{% block main %}
{% endblock %}
<hr/>
<div>底部分类:
{% for cate in categories %}
<a href="{% url 'category-list' cate.id %}">{{ cate.name }}</a> <!-- 改动地方 -->
{% endfor %}
</div>
<hr/>
<div>侧边栏展示:
{% for sidebar in sidebars %}
<h4>{{ sidebar.title }}</h4>
{{ sidebar.content_html }}
{% endfor %}
</div>
</body>
</html>
对sidebar_comments.html进行修改:
<ul>
{% for comment in comments %}
<li><a href="{% url 'post-detail' comment.target_id %}">{{ comment.target.title }}</a> | {{ comment.nickname }} : {{ comment.content }}
{% endfor %}
</ul>
对sidebar_posts.html进行修改:
<ul>
{% for post in posts %}
<li><a href="{% url 'post-detail' post.id %}">{{ post.title }}</a>
{% endfor %}
</ul>
需要注意的是,如果你自己定义的URL中有多个参数,那么在模板中使用时也可以传递多个参数:{% url 'name' arg1 arg2 %}。如果是定义的关键字参数,可以这么写:{% url 'name' arg1=arg1 arg2=arg2 %}。
4.4.3 总结
在开发中,解耦是非常重要的概念,如果有两部分代码是相互耦合的,那意味着每次这部分代码的调整都需要考虑其耦合方。不过需要提醒的是,也不能一味追求解耦,有时候适当的耦合是必要的。这里可以考虑一下组件的概念以及设计模式中常说的“高内聚,低耦合”。
4.5 升级至class-based view
在前面几节中,我们完成了 View 层和 Model层数据的传递,也把数据展示到页面上了。虽然整个流程有一些粗糙,但是数据没问题了。接下来,需要做的就是使用class-based view(类视图)进行重构。
单纯从技术上来说,function view(函数视图)和class-based view并没有高低之分,有的仅仅是对场景的适用性。
4.5.1 函数与类
首先,需要对比的一个概念是函数和类。
什么情况下需要使用函数,什么情况下需要封装出一个类呢?简单来说,只要代码的逻辑被重复使用,同时有需要共享的数据,就可以考虑封装出一个类。这样就可以享用类提供的好处了——继承和复用。
而如果这种情况下依然使用函数的话,就需要定义多个子函数,通过函数级别的复用来达到目的。但问题在于不够结构化,无法通过继承一个结构(类),然后修改其中某个配置,或者重写某个方法达到复用的目的。
4.5.2 理解 class-based view
上面简单说明了函数和类的区别,接着看看 Django给我们提供的class-based view都有哪些.以及它们的作用分别是什么。
先看一下Django文档中class-based view的具体解释:
View 就是一个能够接受请求并且返回响应的可调用对象,它不仅仅是一个函数。同时Django提供了一些类作为View的示例。这样就允许我们结构化 View并且通过继承和混入(mixin)的方式来复用代码。
接着,来看一下 Django 提供了多少种class-based view。我们尝试总结一下需要这种class-based view 的场景,以及相对于function view的优缺点。
Django 提供了下面几个class-based view。
- View: 基础的View,它实现了基于HTTP方法的分发(dispatch)逻辑,比如GET请求会调用对应的get方法,POST请求会调用对应的post方法。但它自己没有实现具体的get或者post方法。
- Templateview:继承自View,可以直接用来返回指定的模板。它实现了get方法,可以传递变量到模板中来进行数据展示。
- Detailview:继承自View,实现了get方法,并且可以绑定某一个模板,用来获取单个实例的数据。
- Listview:继承自View,实现了get方法,可以通过绑定模板来批量获取数据。
上面的简单解释看起来比较抽象,下面还是通过代码实际体验一番。
在function view的情况下,view函数是这么写的:
# 演示无需编写
from django.http import HttpResponse
def my_view(request):
if request.method == 'GET':
# <view logic>
return HttpResponse('result')
在class-based view的情况下,可以这么写:
# 演示无需编写
from django.http import HttpResponse
from django.views import View
class MyView(View):
def get (self, request):
# <view logic>
return HttpResponse('result')
这有一个明显的好处就是,解耦了HTTPGET请求、HTTPPOST请求以及其他请求。前面提到过开一闭原则,在这种情况下,如果需要增加处理 POST请求的逻辑,我们不需要去修改原有函数,只需要新增函数def post(self,request)即可,完全不用触及已有的逻辑。
这点想必你能够体会到。其他的View也类似,从本质上来讲,我们的View无论是函数形式还是类形式,都是用来处理HTTP请求的。因此,对于同一个URL需要处理多种请求的情况,class-based view 显然更加合适,因为可以避免写很多分支语句。这是其中的一个优势。
那么,定义好的class-based view 怎么使用呢?如果使用了class-based view,那么URL的定义如下:
# 演示无需编写
from django.urls import path
from myapp.views import MyView
urlpatterns = [
path('about/', MyView.as_view()),
]
通过 as_view 函数来接受请求以及返回响应。你可能会好奇这是怎么实现的。其原理其实很简单,就是把 function view里面的分支语句抽出来放到独立的函数as_view中,通过动态获取当前请求HTTP Method对应的方法(如GET请求对应get方法)来处理对应请求。
具体代码会比较复杂,这里用伪代码简单模拟一下其中的逻辑,如果有兴趣的话,可以深入研究:
# 伪代码,只做参考
class View:
@classmethod
def as_view(cls, **initkwargs):
def view(request,*args, **kwargs):
self = cls(**initkwargs)
handler = getattr(self, request.mothod.lower())
if handler:
return handler(request)
else:
raise Exception("Method Not Allow!")
return view
大概就这么一个逻辑,里面涉及闭包和getattr 的用法。如果你目前不熟悉的话,建议抽空补上这部分知识。
上面是对View的解释,其他的View类似,只是增加了额外的功能。比如,TemplateView增加了指定模板的功能,它既可以用来返回某个模板,也可以直接写到URL上:
# 演示无需编写
from django.urls import path
from django.views.generic import TemplateView
urlpatterns = [
path('about/', TemplateView.as_view(template_name="about.html")
]
这只是简单用法,用来返回静态页面,你还可以通过继承 TemplateView,然后实现它的get_context_data 方法来将要展示的数据传递到模板中。
接着,再来说DetailView。上面我们说它也继承自View,但其实是间接继承自View的。另外,它也间接继承自 TemplateView 所继承的另外一个父类TemplateResponseMixin(当然,这个类只做了解即可,它是提供了TemplateView功能的主要父类)。
我们可以简单理解为DetailView 也拥有 TemplateView的能力。除此之外,多余的能力就是上面说到的,可以通过绑定一个模板来指定数据源。下面通过简单的示例来有一个感性的认识,该代码基于我们已经定义好的模板。
首先,定义 PostDetailView,用它来替换之前在blog/views.py 中定义的 post_detail方法:
# blog/views.py
from django.views.generic import DetailView
# 省略其他代码
class PostDetailView(DetailView):
model = Post
template_name = 'blog/detail.html'
如果只是简单地展示Post的内容,上面的定义已经足够。接着就是模板了,我们把blog/detail.html的代码改为:
{% if post %}
<h1>{{ post.title }}</h1>
<div>
<span>分类:{{ post.category.name }}</span>
<span>作者:{{ post.owner.username }}</span>
</div>
<hr/>
<p>
{{ post.content }}
</p>
{% endif %}
这里去掉了公共部分的数据,因为在Detailview 里面只需要处理与当前 Model相关的数据。这个Model就是我们指定的model=Post 属性,那么应该依据什么来拿到具体数据呢(也就是filter部分的过滤逻辑)?
下面需要修改URL的定义,因为最终需要获取哪条数据还要通过URL来知晓:
from django.urls import path
from blog.views import PostDetailView
urlpatterns = [
path('post/<int:post_id>/', PostDetailView.as_view(), name='post-detail'),
]
在上面的URL定义中,指定了要匹配的参数post_id来作为过滤Post 数据的参数,从而产生这样的请求:Post.objects.filter(post_id=post_id),以拿到指定文章的实例。
对于上面的整个示例,可能你看起来会有一些疑惑,比如为什么URL中配置了<int:post_id>这样的规则,就可以拿到对应的文章实例了?我们只是继承了DetailView,配置了 model=Post 以及template_name =‘blog/detail.html’,就能渲染数据了?
其实关键点在于,对于单个数据的请求,Django帮我们封装好了数据获取的逻辑,我们只需要配置一下就可以得到最终结果。其实,起作用的代码并不比你写function view的代码少,只是大部分代码Django都已经编写好了,我们只需要配置。
只需要配置,我认为这是一个很高的境界,这意味着你可以构建一个足够通用的基础结构,个性化的业务需求只要通过配置就可以满足。
对于Detailview,我们不得不像官方文档那样,罗列出一些属性和方法,因为它做了很多封装。如果你只是了解上面的用法,不知道它提供了哪些接口,可能无法高效地完成自己的需求。
DetailView 提供了如下属性和接口。
- model 属性:指定当前View 要使用的Model。
- queryset 属性: 跟Model一样,二选一。设定基础的数据集,ModeI的设定没有过滤的功能,可以通过queryset=Post.objects.filter(status=Post.STATUS_NORMAL)进行过滤。
- template_name 属性: 模板名称。
- get_queryset 接口: 同前面介绍过的所有get_queryset方法一样,用来获取数据。如果设定了queryset,则会直接返回queryset。
- get_object 接口:根据URL参数,从queryset 上获取到对应的实例。
- get_context_data 接口: 获取渲染到模板中的所有上下文,如果有新增数据需要传递到模板中,可以重写该方法来完成。
这些基本上就是常用的属性和方法了。通过上面的描述,可以简单理解其作用,并在合适的时候使用。
说完 DetailView,再来看ListView。它跟DetailView类似,只不过后者只获取一条数据,而ListView获取多条数据。而且因为是列表数据,如果数据量过大,就没法一次都返回,因此它还需要完成分页功能。
下面通过一个简单的示例体验一下。在我们的项目中,首页本身就是一个从新到旧排序的文章列表。在不考虑其他数据的情况下,可以使用ListView来处理。
首先,还是来编写blog/views.py代码:
# blog/views.py
from django.views.generic import DetailView, ListView
# 省略其他代码
class PostListView(ListView):
queryset = Post.latest_posts()
paginate_by = 1
context_object_name = 'post_list' # 如果不设置此项,在模板中需要使用 object_list 变量
template_name = 'blog/list.html'
这样列表页的代码就写好了,并且自带分页功能。为了演示,这里把每页的数量设置为1,也就是paginate_by = 1,这个你可以自行调整。
然后编写 list.html的代码,其代码跟我们已经写好的类似,只需要替换掉blockmain中的代码即可:
{% extends "blog/base.html" %}
{% block title %}
{% if tag %}
标签页: {{ tag.name }}
{% elif category %}
分类页: {{ category.name }}
{% else %}
首页
{% endif %}
{% endblock %}
{% block main %}
<ul>
{% for post in post_list %}
<li>
<a href="{% url 'post-detail' post.id %}">{{ post.title }}</a>
<div>
<span>作者:{{ post.owner.username }}</span>
<span>分类:{{ post.category.name }}</span>
</div>
<p>{{ post.desc }}</p>
</li>
{% endfor %}
{% if page_obj %}
{% if page_obj.has_previous %}
<a href="?page={{ page_obj.previous_page_number }}">上一页</a>
{% endif %}
Page {{ page_obj.number }} of {{ paginator.num_pages }}.
{% if page_obj.has_next %}
<a href="?page={{ page_obj.next_page_number }}">下一页</a>
{% endif %}
{% endif %}
</ul>
{% endblock %}
这样的话,一个带分页的模板就弄好了。之前我们在function view的逻辑中并没有处理分页的情况,你可以对比一下,如果使用paginator 组件编写分页逻辑,会多出多少行代码。这其实是class-based view 的好处。我们可以直接利用Django已经封装好的逻辑,通过简单配置来使用。
好了,接着根据已经掌握的内容来改造一下我们编写完的代码。
4.5.3 改造代码
前面我们知道了 finction view和 class-based view 的差别,说白了还是要归结到函数和类的差别。如果只是单纯地来讲 class-based view 的用法以及它所提供的方法和属性配置,那没有太大意义,因为文档上都能够查到。
如果不能从本质上理解这个东西产生的原因,就无法更好地在适当的时候使用合适的技术。
好了,有了上面的示例代码,我们来把已存在的function view的代码重构为class-based view的代码。首先是views.py中的代码,主要的View有两个,分别为post_list和post_detail。其中post_list 处理了多个URL的逻辑,在改造为class-based view之后,我们可以通过继承的方式来复用代码,因此可以拆开。
首先,处理一下首页的代码,blog/views.py下方新增如下代码:(这里可以把之前的代码清空了,最后我会给出完整代码)
# blog/views.py
class IndexView(ListView):
queryset = Post.latest_posts()
paginate_by = 2
context_object_name = 'post_list'
template_name = 'blog/list.html'
对于首页来说,这些代码还不够,需要增加通用数据,比如分类导航、侧边栏和底部导航。但是这些数据是基础数据,因此最好独立成一个类来写,然后通过组合的方式复用。我们在Indexview 上面增加CommonviewMixin类来处理通用的数据:
# blog/views.py
class CommonViewMixin:
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context.update({
'sidebars': SideBar.objects.all()
})
context.update(Category.get_navs())
return context
class IndexView(CommonViewMixin, ListView):
# 省略代码
这里面的代码都不陌生,都是我们之前写的基础函数,只不过把它们都封装到CommonViewMixin中了。这样,我们就有了进行通用数据处理和首页处理的类。接着,来写分类列表页和标签列表页的处理逻辑。
首先,需要分析一下,相对首页来说,这两个页面的差别有哪些?
主要有以下两个。
- QuerySet 中的数据需要根据当前选择的分类或者标签进行过滤。
- 渲染到模板中的数据需要加上当前选择的分类的数据。
好了,理解了这些差异,就知道该如何做了。有两个方法需要重写:一个是get_context_data方法,用来获取上下文数据并最终将其传入模板;另外一个是get_queryset方法,用来获取指定Model或QuerySet 的数据。
我们继续在blog/views.py中添加代码:
# blog/views.py
from django.shortcuts import get_object_or_404
# 省略代码
class CategoryView(IndexView):
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
category_id = self.kwargs.get('category_id')
category = get_object_or_404(Category, id=category_id)
context.update({
'category': category,
})
return context
def get_queryset(self):
""" 重写 queryset, 根据标签过滤 """
queryset = super().get_queryset()
category_id = self.kwargs.get('category_id')
return queryset.filter(category_id=category_id)
class TagView(IndexView):
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
tag_id = self.kwargs.get('tag_id')
tag = get_object_or_404(Tag, id=tag_id)
context.update({
'tag': tag,
})
return context
def get_queryset(self):
""" 重写 queryset, 根据标签过滤 """
queryset = super().get_queryset()
tag_id = self.kwargs.get('tag_id')
return queryset.filter(tag_id=tag_id)
其中有几个地方需要单独说一下。
- get_object_or_404是一个快捷方式,用来获取一个对象的实例。如果获取到,就返回实例对象;如果不存在,直接抛出404错误。
- 在tag_id=self.kwargs.get(‘tag_id’)里面,self.kwargs中的数据其实是从我们的URL定义中拿到的,你可以对比一下。
到目前为止,首页、分类列表页、标签列表页的View都已经编写好了,我们继续完成博文详情页的代码。根据上面的示例代码,很容易编写。在blog/views.py中继续增加代码:
# blog/views.py
class PostDetailView(CommonViewMixin, DetailView):
queryset = Post.objects.filter(status=Post.STATUS_NORMAL)
template_name = 'blog/detail.html'
context_object_name = 'post'
pk_url_kwarg = 'post_id'
对比一下示例代码,你会发现,我们只是多了CommonViewMixin组合类而已。
这样View 层的代码就编写完了,读者可能会有疑问,为什么代码看起来比之前多了很多?确实如此,但是你也会发现,条理更清晰了。比方说,之前post_list中的条件判断没有了。另外,对于目前的代码结构,如果需要新增其他类型的页面,也很容易处理。
这里给出blog/views.py的完整代码:
# blog/views.py
from django.shortcuts import get_object_or_404
from django.views.generic import DetailView, ListView
from config.models import SideBar
from .models import Post, Category, Tag
# def post_list(request, category_id=None, tag_id=None):
# tag = None
# category = None
#
# if tag_id:
# post_list, tag = Post.get_by_tag(tag_id)
# elif category_id:
# post_list, category = Post.get_by_category(category_id)
# else:
# post_list = Post.latest_posts()
#
# context = {
# 'category': category,
# 'tag': tag,
# 'post_list': post_list,
# 'sidebars': SideBar.objects.all(),
# }
#
# context.update(Category.get_navs())
# return render(request, 'blog/list.html', context=context)
#
#
# def post_detail(request, post_id=None):
# try:
# post = Post.objects.get(id=post_id)
# except Post.DoesNotExist:
# post = None
#
# context = {
# 'post': post,
# 'sidebars': SideBar.objects.all(),
# }
#
# context.update(Category.get_navs())
# return render(request, 'blog/detail.html', context=context)
#
#
# class PostListView(ListView):
# queryset = Post.latest_posts()
# paginate_by = 2
# context_object_name = 'post_list' # 如果不设置此项,在模板中需要使用 object_list 变量
# template_name = 'blog/list.html'
class CommonViewMixin:
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context.update({
'sidebars': SideBar.objects.all()
})
context.update(Category.get_navs())
return context
class IndexView(CommonViewMixin, ListView):
queryset = Post.latest_posts()
paginate_by = 2
context_object_name = 'post_list'
template_name = 'blog/list.html'
class CategoryView(IndexView):
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
category_id = self.kwargs.get('category_id')
category = get_object_or_404(Category, id=category_id)
context.update({
'category': category,
})
return context
def get_queryset(self):
""" 重写 queryset, 根据标签过滤 """
queryset = super().get_queryset()
category_id = self.kwargs.get('category_id')
return queryset.filter(category_id=category_id)
class TagView(IndexView):
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
tag_id = self.kwargs.get('tag_id')
tag = get_object_or_404(Tag, id=tag_id)
context.update({
'tag': tag,
})
return context
def get_queryset(self):
""" 重写 queryset, 根据标签过滤 """
queryset = super().get_queryset()
tag_id = self.kwargs.get('tag_id')
return queryset.filter(tag_id=tag_id)
class PostDetailView(CommonViewMixin, DetailView):
queryset = Post.objects.filter(status=Post.STATUS_NORMAL)
template_name = 'blog/detail.html'
context_object_name = 'post'
pk_url_kwarg = 'post_id'
接着,我们来编写URL的代码。只需要把之前的func_view 改为<基于类的View>.as_view:
from django.contrib import admin
from django.urls import path
from config.views import links
from .custom_site import custom_site
from blog.views import IndexView, CategoryView, TagView, PostDetailView
urlpatterns = [
path('', IndexView.as_view(), name='index'),
path('category/<int:category_id>/', CategoryView.as_view(), name='category-list'),
path('tag/<int:tag_id>/', TagView.as_view(), name='tag-list'),
path('post/<int:post_id>/', PostDetailView.as_view(), name='post-detail'),
path('links/', links, name='links'),
path('super_admin/', admin.site.urls, name='super-admin'),
path('admin/', custom_site.urls, name='admin'),
]
4.5.4 总结
好了,到此为止,function view就改造为class-based view了。你可以通过实践上述代码和流程来体验其中差别。接下来,我们来总结一下Django处理请求的逻辑。
页面结果图:

4.5.5 参考资料
ListView 获取 URL参数:
https://docs.djangoproject.com/zh-hans/4.2/topics/class-based-views/generic-display/#dynamic-filteringo
ListView 详细介绍:
https:/docs.djangoproject.com/zh-hans/4.2/ref/class-based-views/generic-display#django.views.generic.list.ListView
View源码:
https://github.com/django/django/blob/4.2/django/views/generic/base.py#L28
4.6 Django的View是如何处理请求的
在前面几节中,我们分别编写了function view 和 class-based view:既知道了如何定义URL.把请求转发到对应的 View 上,也知道了如何在 View 中获取请求数据,然后操作 Model 层拿到数据,最后渲染模板并返回。
这一节中,我们来简单总结这两种方式处理请求的差别。
当Django接受一个请求之后(严格来说是HTTP请求,只不过HTTP请求会被Django转化为request对象),请求会先经过所有 middleware的process_request 方法,然后解析 URL,接着根据配置的URL和View的映射,把request对象传递到View中。
这里的View有两类,就是我们前面讲到的 function view 和class-based view。
function view的处理逻辑比较好理解,就是简单的函数,流程就是函数的执行流程,只是第一个参数是request对象。关于class-based view,我们需要详细解释一下。
4.6.1 class-based view的处理流程
class-based view 对外暴露的接口其实是as_view,这在上一节中已经说过。现在我们需要梳理一下as_view做了哪些事,以及在请求到达之后,它的处理流程是什么样的。
-
as_view的逻辑
as_view 其实只做了一件事,那就是返回一个闭包。这个闭包会在Django解析完请求之后调用,而闭包中的逻辑是这样的。-
给class(也就是我们定义的view类)赋值—-request、args 和kwargs。
-
根据 HTTP方法分发请求。比如HTTPGET请求会调用class.get 方法,POST请求会调用class.post方法。
-
-
请求到达之后的完整逻辑
我们知道as_view 做了什么事,也知道了as_view返回的闭包是如何处理后续请求的。假设现在有一个GET请求,我们来具体看一下ListView的流程,其他的View大同小异。
(1)请求到达之后,首先会调用dispatch进行分发。
(2)接着会调用get方法。
① 在GET请求中,首先会调用get_queryset方法,拿到数据源。
② 接着调用get_context_data方法,拿到需要渲染到模板中的数据。
1)在get_context_data中,首先会调用get_paginate_by拿到每页数据。
2)接着调用get_context_object_name拿到要渲染到模板中的这个queryset名称。
3)然后调用paginate_queryset 进行分页处理。
4)最后拿到的数据转为dict并返回。
③调用render_to_response渲染数据到页面中。
1)在render_to_response 中调用get_tempalte_names拿到模板名。
2)然后把request、context、template_name等传递到模板中。
到此为止,关于View 的编写已经完成。
4.6.2 总结
理解View的处理逻辑,有助于我们在编写View层代码时更合理地组织代码。
4.7 本章总结
到目前为止,我们完成了主体的业务流程,数据已经能够完整地展示到页面上了,只是还有点丑陋,毕竟我们还没做任何页面上的设计。下一章中,我们就来介绍前端框架Bootstrap的用法,以及如何用它来美化页面。
本章中,你需要掌握的是如何把Django的Model、View和Template连起来。