本文介绍来自 Meta AI 的 LLaMa 模型,类似于 OPT,也是一种完全开源的大语言模型。LLaMa 的参数量级从 7B 到 65B 大小不等,是在数万亿个 token 上面训练得到。值得一提的是,LLaMa 虽然只使用公共的数据集,依然取得了强悍的性能。
本文目录
1 LLaMa:开源高效的大语言模型
(来自 Meta AI)
1.1 背景:模型参数量级的积累,或者训练数据的增加,哪个对性能提升帮助更大?
1.2 LLaMa 做到了什么
1.3 LLaMa 预训练数据
1.4 LLaMa 模型架构
1.5 LLaMa 的优化
1.6 LLaMa 的高效实现
1.7 LLaMa 实验结果
1.8 训练期间的性能变化
太长不看版
本文介绍来自 Meta AI 的 LLaMa 模型,类似于 OPT,也是一种完全开源的大语言模型。LLaMa 的参数量级从 7B 到 65B 大小不等,是在数万亿个 token 上面训练得到。值得一提的是,LLaMa 虽然只使用公共的数据集,依然取得了强悍的性能。LLaMA-13B 在大多数基准测试中都优于 GPT-3 (175B),LLaMA65B 与最佳模型 Chinchilla-70B 和 PaLM-540B 相比具有竞争力。
1 LLaMa:开源高效的大语言模型
论文名称:LLaMA: Open and Efficient Foundation Language Models
论文地址:
https://arxiv.org/pdf/2302.13971.pdf
代码链接:
https://github.com/facebookresearch/llama
1.1 背景:模型参数量级的积累,或者训练数据的增加,哪个对性能提升帮助更大?
以 GPT-3 为代表的大语言模型 (Large language models, LLMs) 在海量文本集合上训练,展示出了惊人的涌现能力以及零样本迁移和少样本学习能力。GPT-3 把模型的量级缩放到了 175B,也使得后面的研究工作继续去放大语言模型的量级。大家好像有一个共识,就是:模型参数量级的增加就会带来同样的性能提升。
但是事实确实如此吗?
最近的 “Training Compute-Optimal Large Language Models[1]” 这篇论文提出一种缩放定律 (Scaling Law):
训练大语言模型时,在计算成本达到最优情况下,模型大小和训练数据 (token) 的数量应该比例相等地缩放,即:如果模型的大小加倍,那么训练数据的数量也应该加倍。
翻译过来就是:当我们给定特定的计算成本预算的前提下,语言模型的最佳性能不仅仅可以通过设计较大的模型搭配小一点的数据集得到,也可以通过设计较小的模型配合大量的数据集得到。
那么,相似成本训练 LLM,是大 LLM 配小数据训练,还是小 LLM 配大数据训练更好?
缩放定律 (Scaling Law) 告诉我们对于给定的特定的计算成本预算,如何去匹配最优的模型和数据的大小。但是本文作者团队认为,这个功能只考虑了总体的计算成本,忽略了推理时候的成本。因为大部分社区用户其实没有训练 LLM 的资源,他们更多的是拿着训好的 LLM 来推理。在这种情况下,我们首选的模型应该不是训练最快的,而应该是推理最快的 LLM。呼应上题,本文认为答案就是:小 LLM 配大数据训练更好,因为小 LLM 推理更友好。
1.2 LLaMa 做到了什么
LLaMa 沿着小 LLM 配大数据训练的指导思想,训练了一系列性能强悍的语言模型,参数量从 7B 到 65B。例如,LLaMA-13B 比 GPT-3 小10倍,但是在大多数基准测试中都优于 GPT-3。大一点的 65B 的 LLaMa 模型也和 Chinchilla 或者 PaLM-540B 的性能相当。
同时,LLaMa 模型只使用了公开数据集,开源之后可以复现。但是大多数现有的模型都依赖于不公开或未记录的数据完成训练。
1.3 LLaMa 预训练数据
LLaMa 预训练数据大约包含 1.4T tokens,对于绝大部分的训练数据,在训练期间模型只见到过1次,Wikipedia 和 Books 这两个数据集见过2次。
如下图1所示是 LLaMa 预训练数据的含量和分布,其中包含了 CommonCrawl 和 Books 等不同域的数据。
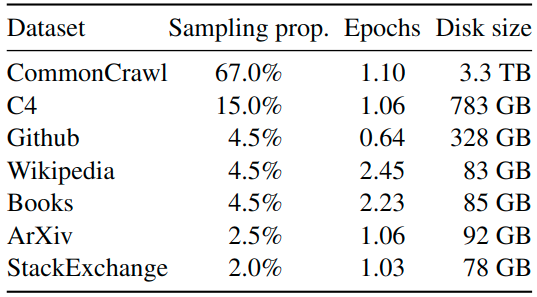
图1:LLaMa 预训练数据的含量和分布
CommonCrawl (占 67%): 包含 2017 到 2020 的5个版本,预处理部分包含:删除重复数据,去除掉非英文的数据,并通过一个 n-gram 语言模型过滤掉低质量内容。
C4 (占 15%): 在探索性实验中,作者观察到使用不同的预处理 CommonCrawl 数据集可以提高性能,因此在预训练数据集中加了 C4。预处理部分包含:删除重复数据,过滤的方法有一些不同,主要依赖于启发式方法,例如标点符号的存在或网页中的单词和句子的数量。
Github (占 4.5%): 在 Github 中,作者只保留在 Apache、BSD 和 MIT 许可下的项目。此外,作者使用基于行长或字母数字字符比例的启发式方法过滤低质量文件,并使用正则表达式删除标题。最后使用重复数据删除。
Wikipedia (占 4.5%): 作者添加了 2022 年 6-8 月的 Wikipedia 数据集,包括 20 种语言,作者处理数据以删除超链接、评论和其他格式样板。
Gutenberg and Books3 (占 4.5%): 作者添加了两个书的数据集,分别是 Gutenberg 以及 ThePile (训练 LLM 的常用公开数据集) 中的 Book3 部分。处理数据时作者执行重复数据删除,删除内容重叠超过 90% 的书籍。
ArXiv (占 2.5%): 为了添加一些科学数据集,作者处理了 arXiv Latex 文件。作者删除了第一部分之前的所有内容,以及参考文献。还删除了 .tex 文件的评论,以及用户编写的内联扩展定义和宏,以增加论文之间的一致性。
Stack Exchange (占 2%): 作者添加了 Stack Exchange,这是一个涵盖各种领域的高质量问题和答案网站,范围从计算机科学到化学。作者从 28 个最大的网站保留数据,从文本中删除 HTML 标签并按分数对答案进行排序。
Tokenizer 的做法基于 SentencePieceProcessor[2],使用 bytepair encoding (BPE) 算法。
LLaMa 的 PyTorch 代码如下,用到了 sentencepiece 这个库。
class Tokenizer:
def __init__(self, model_path: str):
# reload tokenizer
assert os.path.isfile(model_path), model_path
self.sp_model = SentencePieceProcessor(model_file=model_path)
logger.info(f"Reloaded SentencePiece model from {model_path}")
# BOS / EOS token IDs
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.pad_id()
logger.info(
f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}"
)
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
def encode(self, s: str, bos: bool, eos: bool) -> List[int]:
assert type(s) is str
t = self.sp_model.encode(s)
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
def decode(self, t: List[int]) -> str:
return self.sp_model.decode(t)
1.4 LLaMa 模型架构
Pre-normalization [受 GPT3 的启发]:
为了提高训练稳定性,LLaMa 对每个 Transformer 的子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm[3] 归一化函数。
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
常规的 Layer Normalization:
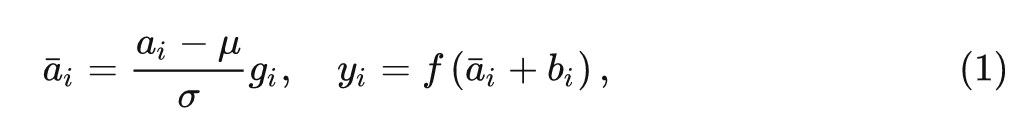
式中, 和 是 LN 的 scale 和 shift 参数, 和 的计算如下式所示:
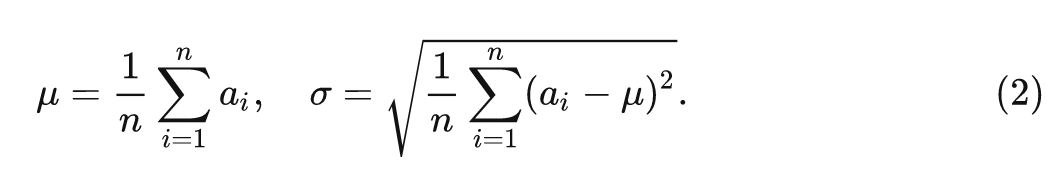
RMSNorm:
相当于是去掉了 这一项。
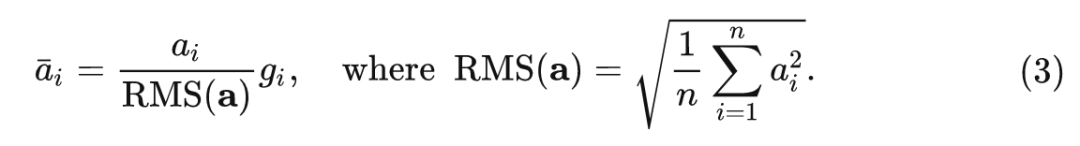
看上去就这一点小小的改动,有什么作用呢?RMSNorm 的原始论文进行了一些不变性的分析和梯度上的分析。
SwiGLU 激活函数 [受 PaLM 的启发]:
LLaMa 使用 SwiGLU 激活函数[4]替换 ReLU 非线性以提高性能,维度从 变为 。
Rotary Embeddings [受 GPTNeo 的启发]:
LLaMa 去掉了绝对位置编码,使用旋转位置编码 (Rotary Positional Embeddings, RoPE)[5],这里的 RoPE 来自苏剑林老师,其原理略微复杂,感兴趣的读者可以参考苏神的原始论文和官方博客介绍:
https://spaces.ac.cn/archives/8265
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

Self-Attention 的 PyTorch 代码:
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size()
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.cache_v = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
xq = xq.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, slen, cache_len + slen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, slen, head_dim)
output = output.transpose(
1, 2
).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
这里有几个地方值得注意一下:
首先是 model.py 文件里面从 fairscale 中 import 了3个类,分别是:ParallelEmbedding,RowParallelLinear,和 ColumnParallelLinear。
Fairscale 链接如下,是一个用于高性能大规模预训练的库,LLaMa 使用了其 ParallelEmbedding 去替换 Embedding, 使用了其 RowParallelLinear 和 ColumnParallelLinear 去替换 nn.Linear,猜测可能是为了加速吧。
https://github.com/facebookresearch/fairscale
另一个需要注意的点是:cache 的缓存机制,可以看到在构造函数里面定义了下面两个东西:
self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)).cuda()
self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)).cuda()关键其实就是这几行代码:
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]在训练的时候,因为每次都是输入完整的一句话,所以 cache 机制其实是不发挥作用的。
在推理的时候,比如要生成 “I have a cat”,过程是:
1 输入,生成I。
2 输入I,生成I have。
3 输入I have,生成I have a。
4 输入I have a,生成I have a cat。在执行3这一步时,计算 “a” 的信息时,还要计算
I have 的 Attention 信息,比较复杂。因此,cache 的作用就是在执行2这一步时,提前把I have 的 keys 和 values 算好,并保存在 self.cache_k 和 self.cache_v 中。在执行3这一步时,计算 Attention 所需的 keys 和 values 是直接从这里面取出来的:
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
只需要额外地计算 “a” 的 keys 和 values 即可,这对模型的快速推理是至关重要的。还有一个值得注意的点:self.cache_k = self.cache_k.to(xq)
这里使用的是 to() 函数的一种不太常见的用法:torch.to(other, non_blocking=False, copy=False)→Tensor
Returns a Tensor with same torch.dtype and torch.device as the Tensor other.
FFN 的 PyTorch 代码:
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
这里需要注意的点是:
激活函数用的是 F.silu(),也就是 Swish 激活函数。
self.w2(F.silu(self.w1(x)) * self.w3(x)) 的实现也就是 SwiGLU 激活函数。

图2:silu 激活函数
Transformer Block 的 PyTorch 代码:
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
Transformer 的 PyTorch 代码:
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h[:, -1, :]) # only compute last logits
return output.float()
self.tok_embeddings 用的是 ParallelEmbedding 这个函数,把 ids 变为词向量。
mask 部分通过 torch.full() 函数和 torch.triu() 函数得到一个上三角矩阵,用于注意力的计算。
通过 torch.nn.ModuleList() 函数定义所有的 Transformer Block。
所有的 norm 函数都使用 RMSNorm 去定义。
生成过程的 PyTorch 代码:
class LLaMA:
def __init__(self, model: Transformer, tokenizer: Tokenizer):
self.model = model
self.tokenizer = tokenizer
def generate(
self,
prompts: List[str],
max_gen_len: int,
temperature: float = 0.8,
top_p: float = 0.95,
) -> List[str]:
bsz = len(prompts)
params = self.model.params
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
prompt_tokens = [self.tokenizer.encode(x, bos=True, eos=False) for x in prompts]
min_prompt_size = min([len(t) for t in prompt_tokens])
max_prompt_size = max([len(t) for t in prompt_tokens])
total_len = min(params.max_seq_len, max_gen_len + max_prompt_size)
tokens = torch.full((bsz, total_len), self.tokenizer.pad_id).cuda().long()
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t).long()
input_text_mask = tokens != self.tokenizer.pad_id
start_pos = min_prompt_size
prev_pos = 0
for cur_pos in range(start_pos, total_len):
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if temperature > 0:
probs = torch.softmax(logits / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits, dim=-1)
next_token = next_token.reshape(-1)
# only replace token if prompt has already been generated
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
prev_pos = cur_pos
decoded = []
for i, t in enumerate(tokens.tolist()):
# cut to max gen len
t = t[: len(prompt_tokens[i]) + max_gen_len]
# cut to eos tok if any
try:
t = t[: t.index(self.tokenizer.eos_id)]
except ValueError:
pass
decoded.append(self.tokenizer.decode(t))
return decoded
def sample_top_p(probs, p):
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
return next_token
这里需要注意的是:
torch.multinomial() 函数用于按照一定的概率 (probs_sort) 采样一定数量 (num_samples) 的 Tensor。
torch.gather() 函数是一个抽数据的函数,按照 probs_idx 的索引和 dim=-1 的维度。
1.5 LLaMa 的优化
AdamW, , 使用 cosine 学习率衰减策略, 2000 步的 warm-up, 最终学习率等于最大学习率的 , 使用 0.1 的权重衰减和 1.0 的梯度裁剪。
1.6 LLaMa 的高效实现
快速的注意力机制: LLaMa 采用了高效的 causal multi-head attention (基于 xformers[6]),不存储注意力权重,且不计算 mask 掉的 query 和 key 的值。
手动实现反向传播过程,不使用 PyTorch autograd: 使用 checkpointing 技术减少反向传播中的激活值的计算,更准确地说,LLaMa 保存计算代价较高的激活值,例如线性层的输出。
通过使用模型和序列并行减少模型的内存使用。此外,LLaMa 还尽可能多地重叠激活的计算和网络上的 GPU 之间的通信。
LLaMa-65B 的模型使用 2048 块 80G 的 A100 GPU,在 1.4T token 的数据集上训练 21 天。
1.7 LLaMa 实验结果
LLaMa 在 20 个标准的 Zero-Shot 和 Few-Shot 任务上面做了评测。在评测时的任务包括自由形式的生成任务和多项选择任务。多项选择任务的目标是根据提供的上下文在一组给定选项中选择最合适的答案。
Zero-Shot 在评测时,作者提供了任务和测试示例的文本描述。LLaMa 要么使用开放式生成提供答案,要么对给定的答案进行排名。Few-Shot 在评测时,作者提供了任务的几个示例 (在 1 到 64 之间) 和一个测试示例。LLaMa 将此文本作为输入并生成答案或者排名不同的选项。
1.7.1 常识推理实验结果
作者考虑了8个标准的常识推理基准:BoolQ, PIQA, SIQA, WinoGrande 等,采用标准的 Zero-Shot 的设定进行评估。结果如图3所示,LLaMA-65B 在除了 BoolQ 的所有基准测试中都优于 Chinchilla-70B,在除了 BoolQ 和 WinoGrande 的任何地方都超过了 PaLM540B。LLAMA-13B 模型在大多数基准测试中也优于 GPT-3。
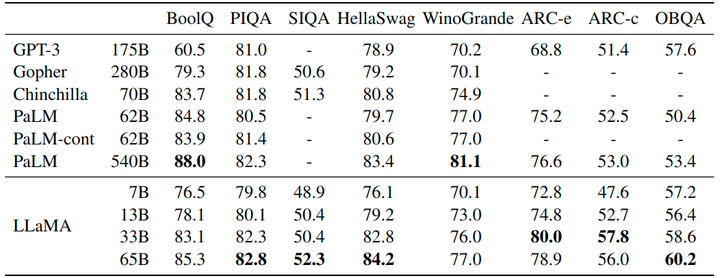
图3:常识推理实验结果
1.7.2 封闭式问答实验结果
如下图3和4所示是封闭式问答实验结果,图4是 Natural Questions 数据集,图5是 TriviaQA 数据集,报告的是报告精确匹配性能,即:模型无法访问包含回答问题证据的文档。在这两个基准测试中,LLaMA-65B 在零样本和少样本设置中实现了最先进的性能,而且 LLaMa-13B 的性能也同样具备竞争力。
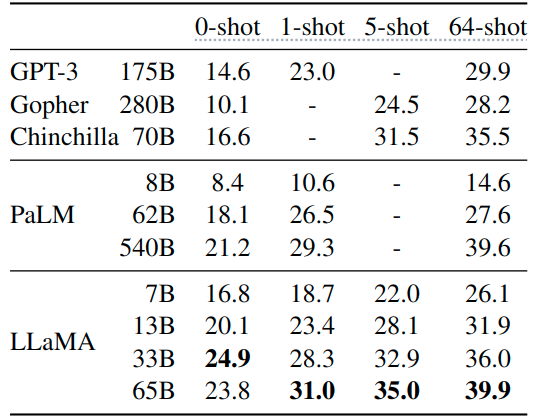
图4:Natural Questions 封闭式问答实验结果
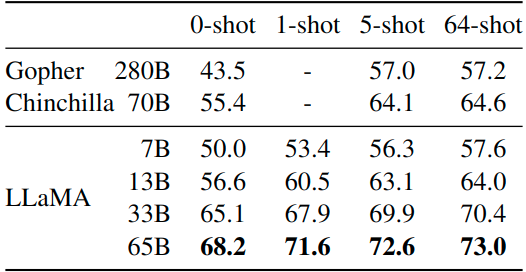
图5:TriviaQA 封闭式问答实验结果
1.7.3 阅读理解实验结果
阅读理解任务在 RACE 数据集上做评测,结果如图6所示。LLaMA-65B 与 PaLM-540B 具有竞争力,LLaMA-13B 的性能比 GPT-3 好几个百分点。
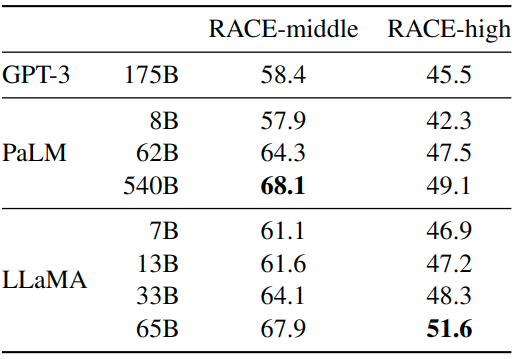
图6:阅读理解实验结果
1.7.4 数学推理实验结果
作者在 MATH 和 GSM8k 两个任务上面做数学推理任务,MATH 是一个 12K 中学和高中数学问题的数据集,用 LaTeX 编写。GSM8k 是一组中学数学问题。在 GSM8k 上,尽管 LLaMA-65B 从没在数学数据上进行微调,但可以观察到 LLaMA-65B 优于 Minerva-62B。
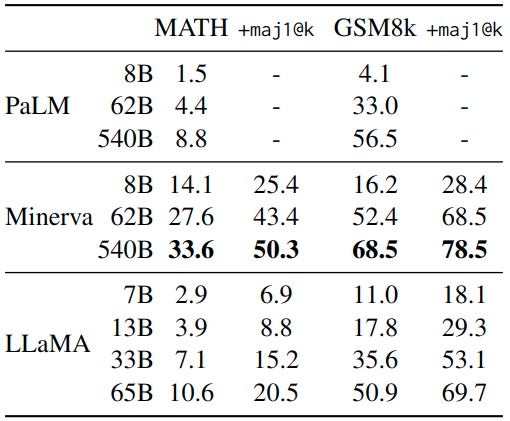
图7:数学推理实验结果
1.7.5 代码生成实验结果
作者在 HumanEval 和 MBPP 两个任务上面做代码生成任务,对于这两个任务,模型接收几个句子中的程序描述,以及一些输入输出示例。模型需要生成一个符合描述并满足测试用例的 Python 程序。图7将 LLaMa 与尚未在代码上微调的现有语言模型 (PaLM 和 LaMDA) 进行比较,PaLM 和 LLAMA 在包含相似数量代码标记的数据集上进行训练。对于相似数量的参数,LLaMa 优于其他通用模型,例如 LaMDA 和 PaLM,这些模型没有专门针对代码进行训练或微调。具有 13B 参数的 LLAMA,在 HumanEval 和 MBPP 上都优于 LaMDA 137B。LLaMA 65B 也超过了训练时间更长的 PaLM 62B。
1.7.6 大规模多任务语言理解实验结果
MMLU 大规模多任务语言理解基准由涵盖各种知识领域的多项选择题组成,包括人文、STEM 和社会科学。作者使用基准提供的示例在 5-shot 设置中评估我们的模型,结果如图7所示。可以观察到 LLaMa-65B 在大多数领域平均落后于 Chinchilla70B 和 PaLM-540B 几个百分点。一个潜在的解释是,LLaMa 在预训练数据中只使用了有限数量的书籍和学术论文,即 ArXiv、Gutenberg 和 Books3,总计只有 177GB,而其他的模型训练了多达 2TB 的书籍。
作者还发现加入一些微调指令也能够提升 大规模多任务语言理解的性能。尽管 LLaMA-65B 的非微调版本已经能够遵循基本指令,但可以观察到非常少量的微调提高了 MMLU 的性能,并进一步提高了模型遵循指令的能力。
如下图8所示,尽管这里使用的指令微调方法很简单,但在 MMLU 上达到了 68.9%。LLAMA-I (65B) 优于 MMLU 现有中等大小的指令微调模型,但仍远未达到最先进的水平。
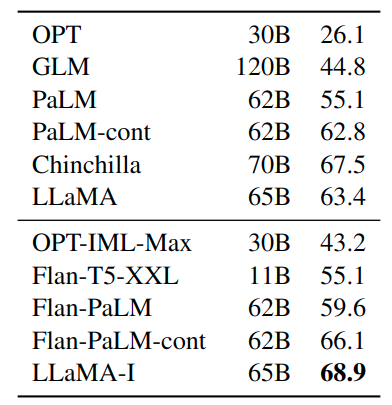
图8:大规模多任务语言理解实验结果
1.8 训练期间的性能变化
如下图9所示是 7B、13B、33B 和 65B 这几个模型在一些问答和常识基准的表现随着 training token 的变化,图10是 7B、13B、33B 和 65B 这几个模型的 training loss 随着 training token 的变化。在大多数基准测试中,性能稳步提高,并且与模型的训练困惑度相关。

图9:7B、13B、33B 和 65B 这几个模型在一些问答和常识基准的表现随着 training token 的变化
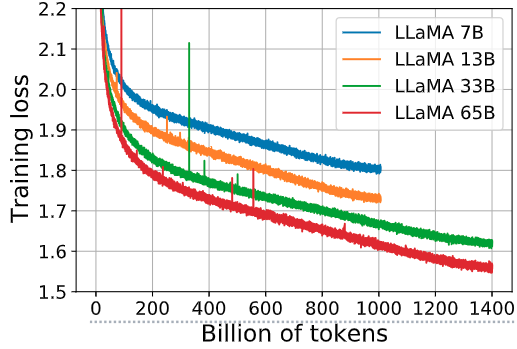
图10:7B、13B、33B 和 65B 这几个模型的 training loss 随着 training token 的变化
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓