
论文:Sirius: Contextual Sparsity with Correction for Efficient LLMs
地址:https://www.arxiv.org/abs/2409.03856
研究背景
研究问题:这篇文章要解决的问题是大型语言模型(LLMs)在推理效率上的挑战。随着LLMs的广泛应用,如何在保持模型性能的同时减少计算成本成为一个重要的研究方向。
研究难点:该问题的研究难点包括:如何在推理任务中保持稀疏模型的效率,以及如何纠正稀疏模型中的错误以提高其性能。
相关工作:该问题的研究相关工作包括上下文稀疏性(Contextual Sparsity, CS)方法,这种方法通过动态稀疏模式减少模型参数和计算成本,但在复杂推理任务中表现不佳。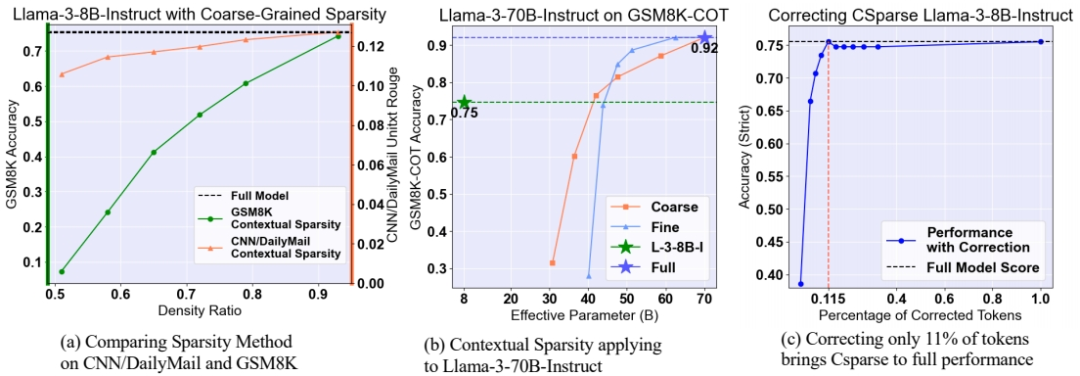
研究方法
这篇论文提出了Sirius机制,用于解决上下文稀疏模型在推理任务中性能下降的问题。具体来说:
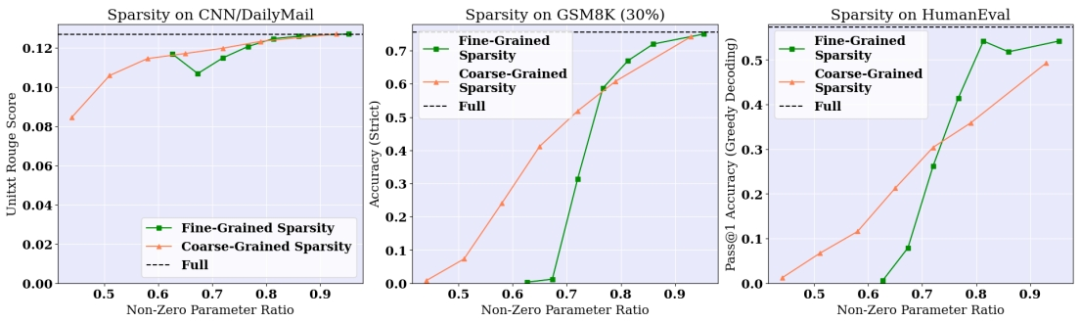
上下文稀疏性方法:首先,文章回顾了上下文稀疏性方法的两种主要类型:粗粒度稀疏性(CSparse)和细粒度稀疏性(FSparse)。粗粒度稀疏性在同一输入提示下固定稀疏模式,而细粒度稀疏性则利用每令牌的稀疏性来节省资源。
错误纠正机制:文章发现,尽管上下文稀疏模型在大多数任务中表现良好,但在需要高层次推理和理解的生成任务中表现较差。为了纠正这些错误,文章提出了一种高效的纠正机制,称为Sirius。
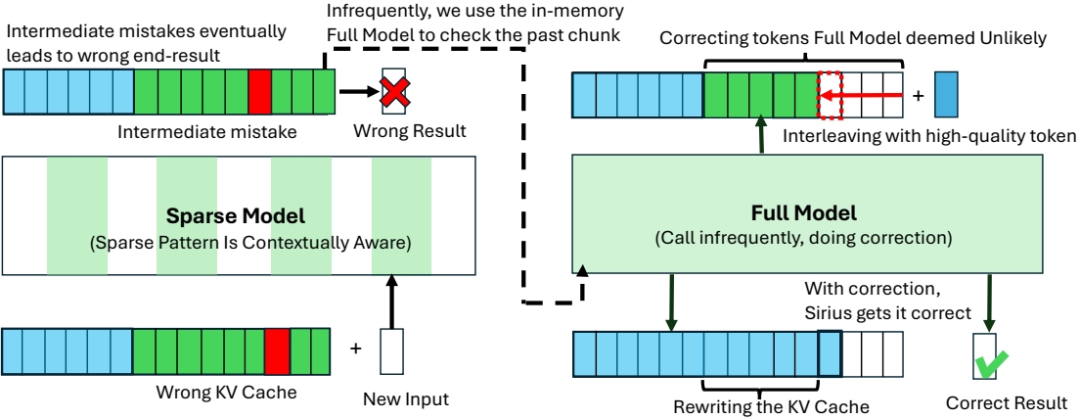
Sirius的设计
Sirius基于周期性的方法,通过设置一个超参数周期来控制全模型的正确次数。具体步骤如下:
KV缓存重写:在全模型运行期间,共享KV缓存,全模型生成的新KV直接写入共享缓存。
最小回滚:当全模型认为某个令牌极不可能时,进行回滚。
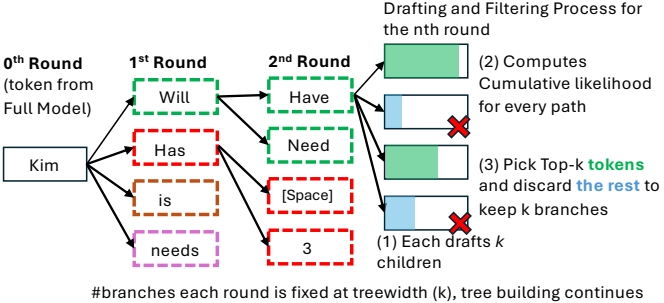
硬件高效树构建:在稀疏生成过程中构建树结构,以增加有效周期并提高纠正效率。
 公式解释:
公式解释:
平均参数使用量(APU):
其中, 是稀疏模型的参数数量, 是稀疏模型的参数密度, 是全模型的参数数量, 是平均前进长度。
有效密度:
其中, 是全局稀疏性。
实验设计
数据集选择:实验使用了六个主流LLMs,包括Llama-2-7B、Llama-3-8B和Llama-2-13B及其指令微调版本。推理任务包括算术推理(GSM8K、AQuA-RAT)、常识推理(CSQA、StrategyQA、Date、Sports)和编码任务(HumanEval、MBPP+)。
稀疏性设置:对于算术推理和编码任务,使用50%的神经元稀疏性;对于常识推理任务,使用40%的神经元稀疏性。
系统实现:实验在主流GPU(如Nvidia A40、L40、A100)上进行,评估了Sirius在片上和卸载设置下的延迟。
结果与分析
有效性:Sirius在各种任务和模型上均表现出显著的有效性,能够将细粒度和粗粒度稀疏模型的准确率从较低的稀疏性恢复到接近全模型的性能。
效率:Sirius在片上和卸载设置下均实现了显著的加速效果。例如,在A40 GPU上,Sirius将Llama-3-8B-Instruct模型的延迟减少了约20%。
组件分析:通过对Sirius组件的消融实验,发现回滚机制最有效,而KV缓存重写和树构建也对性能提升有显著贡献。
总体结论
这篇论文提出的Sirius机制有效地解决了上下文稀疏模型在推理任务中性能下降的问题。通过少量的全模型纠正,Sirius能够在保持稀疏模型效率的同时显著提高其性能。未来的研究方向包括探索更高效率的错误定位方法和进一步优化模型性能。
本文由AI辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















