图像分割是将一幅图像分割成有意义区域的过程。区域可以是图像的前景与背景或图像中一些单独的对象。这些区域可以利用一些诸如颜色、边界或近邻相似性等特征进行构建。本章中,我们将看到一些不同的分割技术。
9.1 图割(Graph Cut)
图论中的图(graph)是由若干节点(有时也称顶点)和连接节点的边构成的集合。图 9-1 给出了一个示例 1 。边可以是有向的(图 9-1 中用箭头示出)或无向的,并且这些可能有与它们相关联的权重。
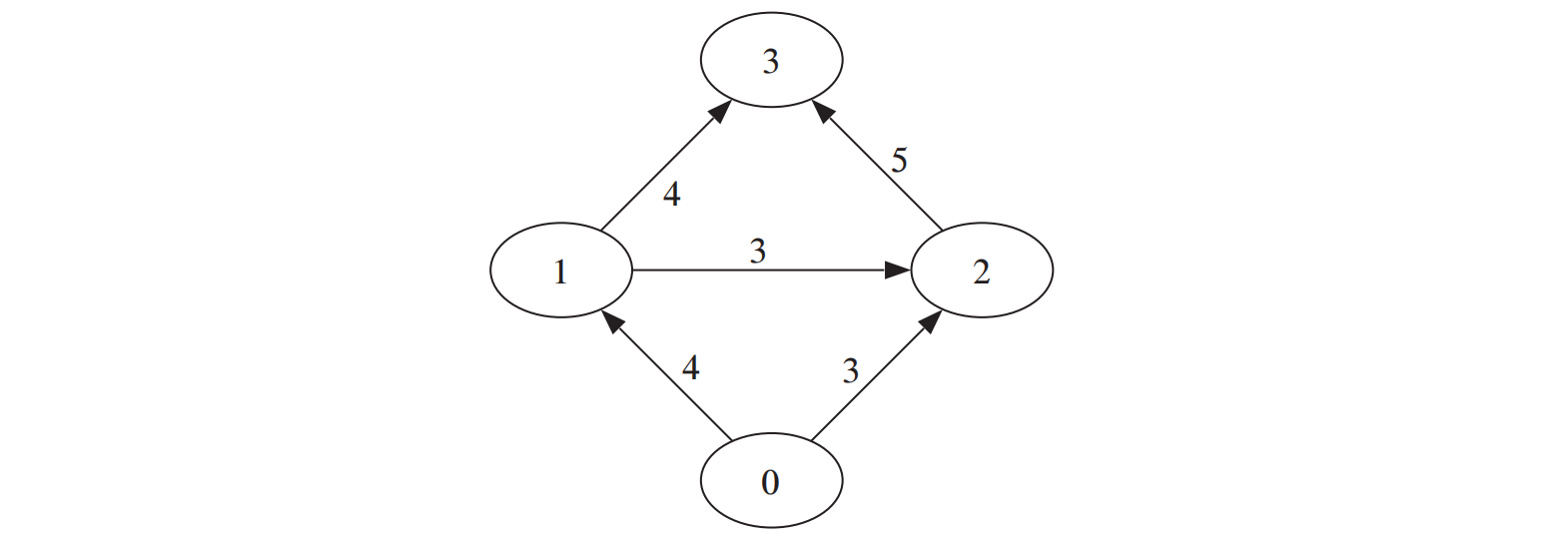
图 9-1:用 python-graph 工具包创建的一个简单有向图
图割是将一个有向图分割成两个互不相交的集合,可以用来解决很多计算机视觉方面的问题,诸如立体深度重建、图像拼接和图像分割等计算机视觉方面的不同问题。从图像像素和像素的近邻创建一个图并引入一个能量或“代价”函数,我们有可能利用图割方法将图像分割成两个或多个区域。图割的基本思想是,相似且彼此相近的像素应该划分到同一区域。
图割 C(C 是图中所有边的集合)的“代价”函数定义为所有割的边的权重求合相加:

寻找最小割(minimum cut 或 min cut)等同于在源点和汇点间寻找最大流(maximum flow 或 max flow)。此外,很多有效的算法都可以解决这些最大流 /最小割问题。我们在图割例子中将采用 python-graph 工具包,该工具包包含了许多非常有用的图算法,你可以在 http://code.google.com/p/python-graph/ 下载该工具包并查看文档。随后的例子里,我们要用到 maximum_flow() 函数,该函数用 Edmonds-Karp 算法
(http://en.wikipedia.org/wiki/Edmonds-Karp_algorithm)计算最大流 / 最小割。采用一个完全用 Python 写成工具包的好处是安装容易且兼容性良好;不足是速度较慢。不过,对于小尺寸图像,该工具包的性能足以满足我们的需求,对于较大的图像,需要一个更快的实现。这里给出一个用 python-graph 工具包计算一幅较小的图 1 的最大流 / 最小割的简单例子:
from pygraph.classes.digraph import digraph
from pygraph.algorithms.minmax import maximum_flow
gr = digraph()
gr.add_nodes([0,1,2,3])
gr.add_edge((0,1), wt=4)
gr.add_edge((1,2), wt=3)
gr.add_edge((2,3), wt=5)
gr.add_edge((0,2), wt=3)
gr.add_edge((1,3), wt=4)
flows,cuts = maximum_flow(gr,0,3)
print 'flow is:', flows
print 'cut is:', cuts
首先,创建有 4 个节点的有向图,4 个节点的索引分别 0...3,然后用 add_edge() 增添边并为每条边指定特定的权重。边的权重用来衡量边的最大流容量。以节点 0 为源点、3 为汇点,计算最大流。打印出流和割结果:
flow is: {(0, 1): 4, (1, 2): 0, (1, 3): 4, (2, 3): 3, (0, 2): 3}
cut is: {0: 0, 1: 1, 2: 1, 3: 1}
上面两个 python 字典包含了流穿过每条边和每个节点的标记:0 是包含图源点的部分,1 是与汇点相连的节点。你可以手工验证这个割确实是最小的。参见图 9-1。
9.1.1 从图像创建图
给定一个邻域结构,我们可以利用图像像素作为节点定义一个图。这里我们将集中讨论最简单的像素四邻域和两个图像区域(前景和背景)情况。一个四邻域(4-neighborhood)指一个像素与其正上方、正下方、左边、右边的像素直接相连 1 。除了像素节点外,我们还需要两个特定的节点——“源”点和“汇”点,来分别代表图像的前景和背景。我们将利用一个简单的模型将所有像素与源点、汇点连接起来。下面给出创建这样一个图的步骤:
• 每个像素节点都有一个从源点的传入边;
• 每个像素节点都有一个到汇点的传出边;
• 每个像素节点都有一条传入边和传出边连接到它的近邻。


利用该模型,可以将每个像素和前景及背景(源点和汇点)连接起来,权重等于上面归一化后的概率。wij 描述了近邻间像素的相似性,相似像素权重趋近于 κ,不相似的趋近于 0。参数 σ 表征了随着不相似性的增加,指数次幂衰减到 0 的快慢。创建一个名为 graphcut.py 的文件,将下面从一幅图像创建图的函数写入该文件中:
from pygraph.classes.digraph import digraph
from pygraph.algorithms.minmax import maximum_flow
import bayes
def build_bayes_graph(im,labels,sigma=1e2,kappa=2):
""" 从像素四邻域建立一个图,前景和背景(前景用 1 标记,背景用 -1 标记,
其他的用 0 标记)由 labels 决定,并用朴素贝叶斯分类器建模 """
m,n = im.shape[:2]
# 每行是一个像素的 RGB 向量
vim = im.reshape((-1,3))
# 前景和背景(RGB)
foreground = im[labels==1].reshape((-1,3))
background = im[labels==-1].reshape((-1,3))
train_data = [foreground,background]
# 训练朴素贝叶斯分类器
bc = bayes.BayesClassifier()
bc.train(train_data)
# 获取所有像素的概率
bc_lables,prob = bc.classify(vim)
prob_fg = prob[0]
prob_bg = prob[1]
# 用m*n+2 个节点创建图
gr = digraph()
gr.add_nodes(range(m*n+2))
source = m*n # 倒数第二个是源点
sink = m*n+1 # 最后一个节点是汇点
# 归一化
for i in range(vim.shape[0]):
vim[i] = vim[i] / linalg.norm(vim[i])
# 遍历所有的节点,并添加边
for i in range(m*n):
# 从源点添加边
gr.add_edge((source,i), wt=(prob_fg[i]/(prob_fg[i]+prob_bg[i])))
# 向汇点添加边
gr.add_edge((i,sink), wt=(prob_bg[i]/(prob_fg[i]+prob_bg[i])))
# 向相邻节点添加边
if i%n != 0: # 左边存在
edge_wt = kappa*exp(-1.0*sum((vim[i]-vim[i-1])**2)/sigma)
gr.add_edge((i,i-1), wt=edge_wt)
if (i+1)%n != 0: # 如果右边存在
edge_wt = kappa*exp(-1.0*sum((vim[i]-vim[i+1])**2)/sigma)
gr.add_edge((i,i+1), wt=edge_wt)
if i//n != 0: 如果上方存在
edge_wt = kappa*exp(-1.0*sum((vim[i]-vim[i-n])**2)/sigma)
gr.add_edge((i,i-n), wt=edge_wt)
if i//n != m-1: # 如果下方存在
edge_wt = kappa*exp(-1.0*sum((vim[i]-vim[i+n])**2)/sigma)
gr.add_edge((i,i+n), wt=edge_wt)
return gr
这里我们用到了用 1 标记前景训练数据、用 -1 标记背景训练数据的一幅标记图像。基于这种标记,在 RGB 值上可以训练出一个朴素贝叶斯分类器,然后计算每一像素的分类概率,这些计算出的分类概率便是从源点出来和到汇点去的边的权重;由此可以创建一个节点为 n×m+2 的图。注意源点和汇点的索引;为了简化像素的索引,我们将最后的两个索引作为源点和汇点的索引。为了在图像上可视化覆盖的标记区域,我们可以利用 contourf() 函数填充图像(这里指带标记图像)等高线间的区域,参数 alpha 用于设置透明度。将下面函数增加到 graphcut.py 中:
def show_labeling(im,labels):
""" 显示图像的前景和背景区域。前景 labels=1, 背景 labels=-1,其他 labels = 0 """
imshow(im)
contour(labels,[-0.5,0.5])
contourf(labels,[-1,-0.5],colors='b',alpha=0.25)
contourf(labels,[0.5,1],colors='r',alpha=0.25)
axis('off')
图建立起来后便需要在最优位置对图进行分割。下面这个函数可以计算最小割并将输出结果重新格式化为一个带像素标记的二值图像:
def cut_graph(gr,imsize):
""" 用最大流对图 gr 进行分割,并返回分割结果的二值标记 """
m,n = imsize
source = m*n # 倒数第二个节点是源点
sink = m*n+1 # 倒数第一个是汇点
# 对图进行分割
flows,cuts = maximum_flow(gr,source,sink)
# 将图转为带有标记的图像
res = zeros(m*n)
for pos,label in cuts.items()[:-2]: # 不要添加源点 / 汇点
res[pos] = label
return res.reshape((m,n))
需要再次注意源点和汇点的索引;我们需要将图像的尺寸作为输入去计算这些索引,在返回分割结果之前要对输出结果进行 reshape() 操作。割以字典返回,需要将它复制到分割标记图像中,这通过返回列表(键,值)的 .item() 方法完成。这里我们再一次略过了列表中最后两个元素。
现在让我们看看怎样利用这些函数来分割一幅图像。下面这个例子会读取一幅图像,从图像的两个矩形区域估算出类概率,然后创建一个图:
from scipy.misc import imresize
import graphcut
im = array(Image.open('empire.jpg'))
im = imresize(im,0.07,interp='bilinear')
size = im.shape[:2]
# 添加两个矩形训练区域
labels = zeros(size)
labels[3:18,3:18] = -1
labels[-18:-3,-18:-3] = 1
# 创建图
g = graphcut.build_bayes_graph(im,labels,kappa=1)
# 对图进行分割
res = graphcut.cut_graph(g,size)
figure()
graphcut.show_labeling(im,labels)
figure()
imshow(res)
gray()
axis('off')
show()
我们利用了 imresize() 函数使图像小到适合我们的 Python graph 库;在该例中将图像统一缩放到原图像尺寸的 7%。图分割后将结果和训练区域一起画出来。图 9-2 中图像覆盖区域为训练区域并显示出了最终的分割结果。

图 9-2:利用贝叶斯概率模型进行图割分割。图像降采样(downsample)到 54×38 大小。用于模型训练的标记图像(左);在待分割图像上显示训练区域(中);分割的结果(右)
变量 kappa(方程中的 K)决定了近邻像素间边的相对权重。改变 K 值分割的效果如图 9-3 所示;随着 K 值增大,分割边界将变得更平滑,并且细节部分也逐步丢失。你可以根据自己应用的需要及想要获得的结果类型来选择合适的 K 值。
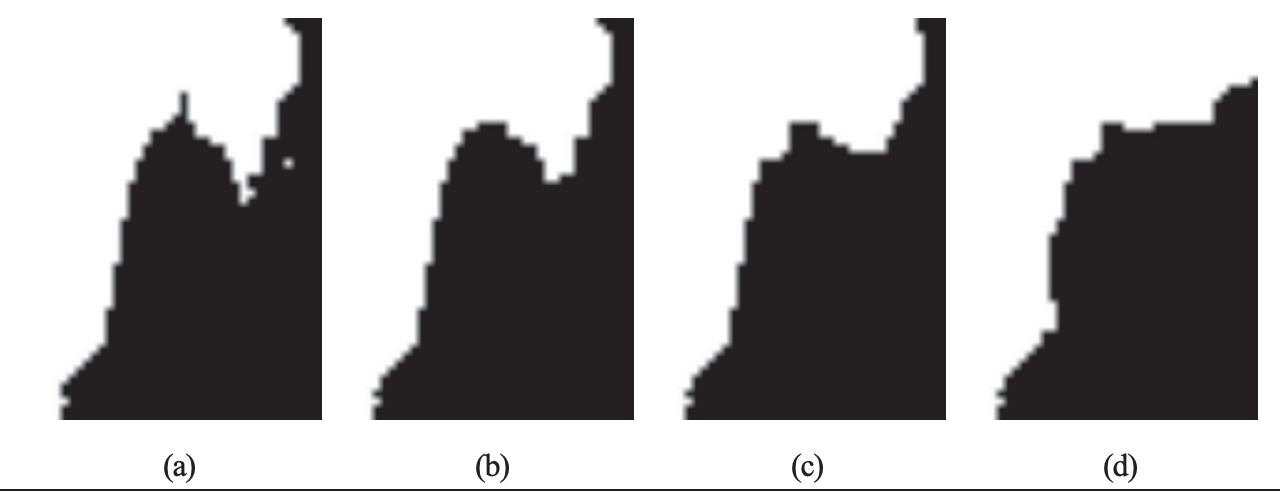
图 9-3:改变像素相似性和类概率之间相对权重对分割结果的影响,采用的分割方法与图 9-2相同:(a)k=1,(b)k=2,(c)k=5,(d)k=10
9.1.2 用户交互式分割
利用一些方法可以将图割分割与用户交互结合起来。例如,用户可以在一幅图像上为前景和背景提供一些标记。另一种方法是利用边界框(bounding box)或“lasso”工具选择一个包含前景的区域。
这些图像还提供了用来评价分割性能的真实标记,还有模拟用户选择矩形图像区域或用“lasso”之类的工具来标记前景和背景的标注信息。我们可以利用这些用户提供的输入来得到训练数据,并以用户输入为导向用切割对图像进行分割。
将用户输入编码成具有下面意义的位图图像:

这里给出一个完整的示例代码,它会载入一幅图像及对应的标注信息,然后将其传递到我们的图割分割路径中:
from scipy.misc import imresize
import graphcut
def create_msr_labels(m,lasso=False):
""" 从用户的注释中创建用于训练的标记矩阵 """
labels = zeros(im.shape[:2])
# 背景
labels[m==0] = -1
labels[m==64] = -1
# 前景
if lasso:
labels[m==255] = 1
else:
labels[m==128] = 1
return labels
# 载入图像和注释图
im = array(Image.open('376043.jpg'))
m = array(Image.open('376043.bmp'))
# 调整大小
scale = 0.1
im = imresize(im,scale,interp='bilinear')
m = imresize(m,scale,interp='nearest')
# 创建训练标记
labels = create_msr_labels(m,False)
# 用注释创建图
g = graphcut.build_bayes_graph(im,labels,kappa=2)
# 图割
res = graphcut.cut_graph(g,im.shape[:2])
# 去除背景部分
res[m==0] = 1
res[m==64] = 1
# 绘制分割结果
figure()
imshow(res)
gray()
xticks([])
yticks([])
savefig('labelplot.pdf')
首先,我们定义一个辅助函数用以读取这些标注图像,格式化这些标注图像便于将其传递给背景和前景训练模型函数,矩形框中只包含背景标记。在本例中,我们设置前景训练区域为整个“未知的”区域(矩形内部)。下一步我们创建图并分割。由于有用户输入,所以我们移除那些在标记背景区域里有任何前景的结果。最后,我们绘制出分割结果,并通过设置这些勾选标记到一个空列表来移去这些勾选标记。这样我们就可以得到一个很好的边框(否则,图像中的边界在黑白图中很难看到)。图 9-4 显示了利用 RGB 向量作为原始图像的特征进行分割的一些结果,一个下采样掩膜和下采样分割结果。右边的图像是通过上面的脚本生成的图线。

图 9-4:利用 Grab cut 数据集中的图像进行图割分割的结果:经过下采样后的原始图像(左);用于训练的掩膜(中间);(右)将用 RGB 像素值作为特征向量进行分割后的结果
9.2 利用聚类进行分割
上一节的图割问题通过在图像的图上利用最大流 / 最小割找到了一种离散解决方案。在本节,我们将看到另外一种分割图像图的方法,即基于谱图理论的归一化分割算法,它将像素相似和空间近似结合起来对图像进行分割。
该方法来自定义一个分割损失函数,该损失函数不仅考虑了组的大小而且还用划分的大小对该损失函数进行“归一化”。该归一化后的分割公式将方程(9.1)中分割损失函数修改为:



def ncut_graph_matrix(im,sigma_d=1e2,sigma_g=1e-2):
""" 创建用于归一化割的矩阵,其中 sigma_d 和 sigma_g 是像素距离和像素相似性的权重参数 """
m,n = im.shape[:2]
N = m*n
# 归一化,并创建 RGB 或灰度特征向量
if len(im.shape)==3:
for i in range(3):
im[:,:,i] = im[:,:,i] / im[:,:,i].max()
vim = im.reshape((-1,3))
else:
im = im / im.max()
vim = im.flatten()
# x,y 坐标用于距离计算
xx,yy = meshgrid(range(n),range(m))
x,y = xx.flatten(),yy.flatten()
# 创建边线权重矩阵
W = zeros((N,N),'f')
for i in range(N):
for j in range(i,N):
d = (x[i]-x[j])**2 + (y[i]-y[j])**2
W[i,j] = W[j,i] = exp(-1.0*sum((vim[i]-vim[j])**2)/sigma_g) * exp(-d/sigma_d)
return W
该函数获取图像数组,并利用输入的彩色图像 RGB 值或灰度图像的灰度值创建一个特征向量。由于边的权重包含了距离部件,对于每个像素的特征向量,我们利用meshgrid() 函数来获取 x 和 y 值,然后该函数会在 N 个像素上循环,并在 N×N 归一化割矩阵 W 中填充值。
我们可以顺序分割每个特征向量或获取一些特征向量对它们进行聚类来计算分割结果。这里选择第二种方法,它不需要修改任意分割数也能正常工作。将拉普拉斯矩阵进行特征分解后的前 ndim 个特征向量合并在一起构成矩阵 W,并对这些像素进行聚类。下面函数实现了该聚类过程,可以看到,它和 6.3 节的谱聚类例子几乎是一样的:
from scipy.cluster.vq import *
def cluster(S,k,ndim):
""" 从相似性矩阵进行谱聚类 """
# 检查对称性
if sum(abs(S-S.T)) > 1e-10:
print 'not symmetric'
# 创建拉普拉斯矩阵
rowsum = sum(abs(S),axis=0)
D = diag(1 / sqrt(rowsum + 1e-6))
L = dot(D,dot(S,D))
# 计算 L 的特征向量
U,sigma,V = linalg.svd(L)
# 从前 ndim 个特征向量创建特征向量
# 堆叠特征向量作为矩阵的列
features = array(V[:ndim]).T
# K-means 聚类
features = whiten(features)
centroids,distortion = kmeans(features,k)
code,distance = vq(features,centroids)
return code,V
这里我们采用基于特征向量图像值的 K-means 聚类算法(细节参见 6.1 节)对像素进行分组。如果你想对该结果进行实验,可以采用任一聚类算法或分组准则。
现在我们可以利用该算法在一些样本图像上进行测试。下面的脚本展示了一个完整的例子:
import ncut
from scipy.misc import imresize
im = array(Image.open('C-uniform03.ppm'))
m,n = im.shape[:2]
# 调整图像的尺寸大小为 (wid,wid)
wid = 50
rim = imresize(im,(wid,wid),interp='bilinear')
rim = array(rim,'f')
# 创建归一化割矩阵
A = ncut.ncut_graph_matrix(rim,sigma_d=1,sigma_g=1e-2)
# 聚类
code,V = ncut.cluster(A,k=3,ndim=3)
# 变换到原来的图像大小
codeim = imresize(code.reshape(wid,wid),(m,n),interp='nearest')
# 绘制分割结果
figure()
imshow(codeim)
gray()
show()
因为 Numpy 的 linanlg.svd() 函数在处理大型矩阵时的计算速度并不够快(有时对于太大的矩阵甚至会给出不准确的结果),所以这里我们重新设定图像为一固定尺寸(在该例中为 50×50),以便更快地计算特征向量。在重新设定图像大小的时候我们采用了双线性插值法;因为不想插入类标记,所以在重新调整分割结果标记图像的尺寸时我们采用近邻插值法。注意,重新调整到原图像尺寸大小后第一次利用reshape 方法将一维矩阵变换为(wid,wid)二维数组。在该例中,我们用到了静态手势(Static Hand Posture)数据库(详见 8.1 节)的某幅手势图像,并且聚类数 k 设置为 3。分割结果如图 9-5 所示,取前 4 个特征向量。

图 9-5:利用归一化分割算法分割图像:原始图像和三类分割结果(上);图相似矩阵的前 4个特征向量(下)
例子中的特征向量以数组 V 返回,可以通过下面的代码可视化为图像:
imshow(imresize(V[i].reshape(wid,wid),(m,n),interp=’bilinear’))
它以原图像尺寸将特征向量 i 显示为一幅图像。
图 9-6 是一些利用上面脚本进行分割的示例。飞机图像来源于 Caltech 101 数据库中的飞机类。在这些例子中,我们保持参数 σg 和 σd 与上面一致,改变这两个参数的值可以得到更平滑、更规则的结果和不同的特征向量图像。我们将这个实验留给你完成。

图 9-6:利用规范化分割算法对两类图像分割示例:原始图像(左边),分割结果(右边)
注意,即使对于这些相对简单的例子,对图像进行阈值处理不会给出相同的结果,对 RGB 值或灰度值进行聚类也一样;原因是它们都没有考虑像素的近邻。
9.3 变分法
在本书中有很多利用最小化代价函数或能量函数来求解计算机视觉问题的例子,如前面章节中在图中最小化割;我们同样可以看到诸如 ROF 降噪、K-means 和 SVM的例子,这些都是优化问题。
当优化的对象是函数时,该问题称为变分问题,解决这类问题的算法称为变分法。我们看一个简单而有效的变分模型。Chan-Vese 分割模型 [6] 对于待分割图像区域假定一个分片常数图像模型。这里我们集中关注两个区域的情形,比如前景和背景,不过这个模型也可以拓展到多区域,比如文献 [38] 中的例子。我们接下来对该模型进行描述。如果我们用一组曲线 Г 将图像分离成两个区域 Ω1 和 Ω2,如图 9-7 所示,分割是通过最小化 Chan-Vese 模型能量函数给出的:

图 9-7:分片常数 Chan-Vese 分割模型

如果用 λ|c1-c2| 替换 ROF 方程 (1.1) 中的 λ,则该方程与 ROF 方程 (1.1) 的形式一致;唯一的区别在于,我们 Chan-Vese 模型中在寻找一幅具有分片常数的图像 U。对ROF 方案进行阈值处理可以给出一个好的极小值,感兴趣的读者可以在文献中查阅细节。
最小化 Chan-Vese 模型现在转变成为设定阈值的 ROF 降噪问题:
import rof
im = array(Image.open('ceramic-houses_t0.png').convert("L"))
U,T = rof.denoise(im,im,tolerance=0.001)
t = 0.4 # 阈值
import scipy.misc
scipy.misc.imsave('result.pdf',U < t*U.max())
在该示例中,为确保得到足够的迭代次数,我们调低 ROF 迭代终止时的容忍阈值。图 9-8 显示了两幅难以分割图像的分割结果。

图 9-8:利用 ROF 降噪最小化 Chan-Vese 模型的一些图像分割示例:(a)为原始图像;(b)为经过 ROF 降噪后的图像;(c)为最终分割结果