github:diffusers/examples/instruct_pix2pix/train_instruct_pix2pix_sdxl.py at main · huggingface/diffusers · GitHub
论文:https://arxiv.org/pdf/2211.09800
摘要
我们提出了一种从人类指令编辑图像的方法:给定一个输入图像和告诉模型做什么的书面指令,我们的模型遵循这些指令来编辑图像。为了获得这个问题的训练数据,我们结合了两个大型预训练模型(语言模型 (GPT-3) 和文本到图像模型 (Stable Diffusion))的知识,以生成大量图像编辑示例数据集。我们的条件扩散模型 InstructPix2Pix 在我们生成的数据上进行了训练,并在推理时推广到真实图像和用户编写的指令。由于它在前向传递中执行编辑,并且不需要每个示例的微调或反转,因此我们的模型在几秒钟内快速编辑图像。我们展示了对不同集合输入图像和书面指令的令人信服的编辑结果。
介绍
我们提出了一种教学生成模型的方法,以遵循人工编写的指令进行图像编辑。由于此任务的训练数据难以大规模获取,我们提出了一种生成成对数据集的方法,该数据集结合了在不同模态上预训练的多个大型模型:大型语言模型 (GPT-3 [7]) 和文本到图像模型 (Stable Diffusion [52])。这两个模型捕获了有关语言和图像的补充知识,这些知识可以结合起来为跨越两种模态的任务创建成对的训练数据。
使用我们生成的成对数据,我们训练了一个条件扩散模型,该模型给定输入图像和文本指令如何编辑它,生成编辑后的图像。我们的模型直接在前向传递中执行图像编辑,不需要任何额外的示例图像、输入/输出图像的完整描述或每个示例微调。尽管完全接受了合成示例的训练(即生成的书面说明和生成的图像),我们的模型实现了对任意真实图像和自然人工编写的指令的零样本泛化。我们的模型实现了直观的图像编辑,可以遵循人类指令来执行多样化的编辑集合:替换对象、更改图像的样式、更改设置、艺术媒介等。选定的示例可以在图 1 中找到。
方法
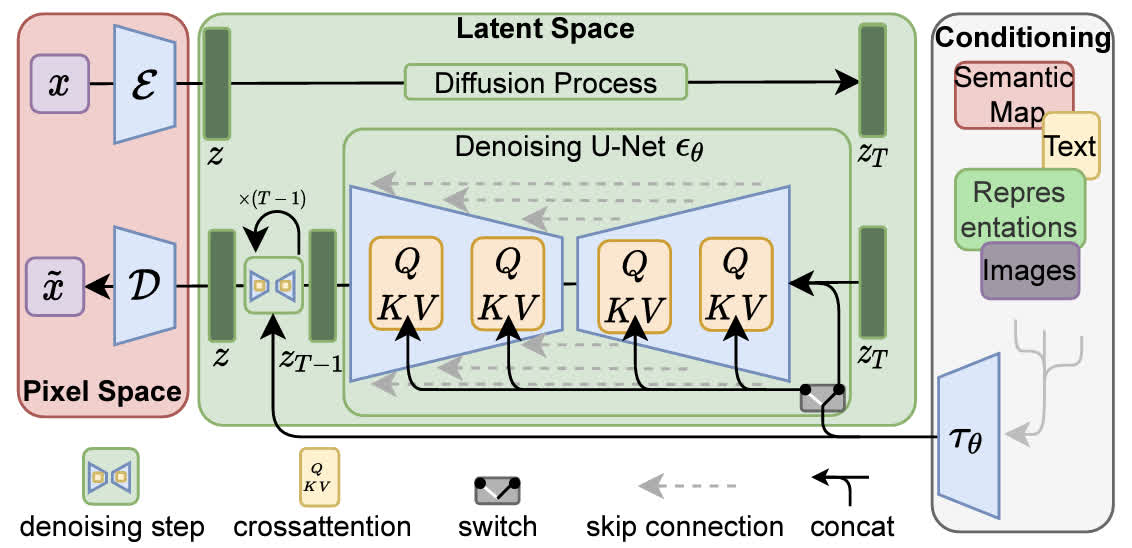
我们将基于指令的图像编辑视为监督学习问题:(1)首先,我们在编辑前后生成文本编辑指令和图像的配对训练数据集(第 3.1 节,图 2a-c),然后(2)我们在这个生成的数据集上训练图像编辑扩散模型(第 3.2 节,图 2d)。尽管是用生成的图像和可编辑指令,我们的模型能够泛化到使用任意人工编写的指令编辑真实图像。有关我们方法的概述,请参见下图2。

我们的方法由两部分组成:生成图像编辑数据集,并在该数据集上训练扩散模型。(a) 我们首先使用微调的 GPT-3 来生成指令和编辑的标题。(b) 然后,我们使用 StableDiffusion [52] 结合 Prompt-to-Prompt [17] 从字幕对生成图像对。我们使用此过程来创建超过 450,000 个训练示例的数据集 (c)。(d) 最后,我们在生成的数据上训练我们的 InstructPix2Pix 扩散模型,以从指令编辑图像。在推理时,我们的模型可以推广到从人工编写的指令中编辑真实图像
生成多模态训练数据集
我们结合了两种在不同模态上运行的大规模预训练模型的能力——大型语言模型 [7] 和文本到图像模型 [52]——以生成包含文本编辑指令的多模式训练数据集以及编辑前后的相应图像。在接下来的两节中,我们将详细描述此过程的两个步骤。在第 3.1.1 节中,我们描述了微调 GPT-3 [7] 以生成文本编辑集合的过程:给定一个描述图像的提示,生成一个描述要进行更改的文本指令,以及一个描述该更改后图像的提示(图 2a)。然后,在第 3.1.2 节中,我们描述了使用文本到图像模型 [52] 将两个文本提示(即编辑前后的)转换为一对对应图像的过程(图 2b)。
生成指令和配对提示词
我们首先完全在文本领域进行操作,我们利用一个大型语言模型来获取图像标题,并在编辑后生成编辑说明和最终的文本标题。例如,如图2a所示,提供“一个女孩骑马的照片”的输入标题,我们的语言模型既可以生成一个合理的编辑指令“让她骑马”,也可以生成一个适当修改的输出标题“一个女孩骑马的照片”。在文本域中操作使我们能够生成大量不同的编辑集合,同时保持图像更改和文本指令之间的对应关系。我们的模型是通过在一个相对人工编写的编辑三元组小数据集:(1)输入标题,(2)编辑指令,(3)输出标题。为了生成微调数据集,我们从LAION-Aesthetics V2 6.5+[57]数据集中采样了700个输入标题,并手动编写指令和输出标题。关于我们的书面指令和输出标题的示例,请参见表1a。使用这些数据,我们使用默认训练参数对GPT-3达芬奇模型进行了单个epoch的微调。
得益于GPT-3的丰富知识和泛化能力,我们的微调模型能够生成创造性但明智的说明和说明。例如GPT-3生成的数据见表1b。我们的数据集是通过使用此训练模型生成大量编辑和输出标题来创建的,其中输入标题是来自LAION-Aesthetics的真实图像标题(不包括具有重复标题或重复图像url的样本)。我们之所以选择LAION数据集,是因为它的大小、内容的多样性(包括对专有名词和流行文化的引用)和媒介的多样性(照片、绘画、数字艺术品)。LAION的一个潜在缺点是它非常嘈杂,并且包含许多无意义或描述性的标题——然而,我们发现通过数据集过滤(第3.1.2节)和无分类器指导(第3.2.1节)的组合可以减轻数据集噪声。我们生成的指令和标题的最终语料库由454,445个示例组成。

表1。我们标记了一个小型文本数据集,微调GPT-3,并使用该微调模型生成一个大型文本三元组数据集。作为标记示例和生成示例的输入标题,我们使用来自LAION的真实图像标题。高亮显示的文本是由GPT-3生成的。
从配对字幕生成配对图像
接下来,我们使用预训练的文本到图像模型将一对字幕(参考编辑前后的图像)转换为一对图像。将一对字幕转换为一对相应的图像的一个挑战是,文本-图像模型不能保证图像的一致性,即使在条件的非常微小的变化下也是如此提示。例如,两个非常相似的提示:“一只猫的图片”和“一只黑猫的图片”可能会产生截然不同的猫的图像。这并不适合我们的目的,我们打算使用这些配对数据作为监督来训练模型来编辑图像(而不是产生不同的随机图像)。因此,我们使用了Prompt-to-Prompt[17],这是一种最近的方法,旨在鼓励文本到图像扩散模型的多代相似。这是通过在一些去噪步骤中借用交叉注意权重来完成的。图3显示了使用和不使用Prompt-to-Prompt的采样图像的比较。

图3。使用StableDiffusion[52]和不使用Prompt-to-Prompt[17]生成的一对图像。两者对应的标题都是“女孩骑马的照片”和“女孩骑马的照片”。
虽然这极大地有助于吸收生成的图像,但不同的编辑可能需要对图像空间进行不同程度的更改。例如,较大幅度的变化,例如那些改变大规模图像结构的变化(例如,四处移动物体,用不同形状的物体替换),可能对生成的图像对的相似性要求较低。幸运的是,Prompt-to-Prompt有一个参数可以控制两个图像之间的相似性:具有共享注意力权重的去噪步骤p的比例。不幸的是,仅从标题和编辑文本中识别p的最佳值是很困难的。因此,我们为每个标题对生成100个样本对图像,每个图像具有随机的p ~ U(0.1, 0.9),并对这些图像进行过滤 使用基于CLIP的度量:Gal等人[14]引入的CLIP空间中的方向相似性。该度量度量两个图像(在CLIP空间中)之间的变化与两个图像标题之间的变化的一致性。执行这种过滤不仅有助于最大限度地提高图像对的多样性和质量,而且还使我们的数据生成对提示到提示和稳定扩散的失败更加健壮。
InstructPix2Pix
我们使用生成的训练数据来训练一个条件扩散模型,该模型可以根据书面指令编辑图像。我们的模型基于稳定扩散,这是一种大规模文本到图像的潜在扩散模型。
扩散模型[60]学习通过一系列去噪自编码器来生成数据样本,这些自编码器估计数据分布的分数[23](指向更高密度数据的方向)。潜伏扩散[52]通过在预训练的具有编码器E和解码器d的变分自编码器[30]的潜伏空间中运行,提高了扩散模型的效率和质量。对于图像,扩散过程在编码的潜伏z = E(x)中添加噪声,产生噪声潜伏zt,其中噪声水平随着时间步长t∈t而增加。我们学习了一个网络θ,在给定图像条件cI和文本指令条件cT的情况下,该网络可以预测添加到噪声潜在zt中的噪声。我们最小化以下潜在扩散目标:

两种条件下的无分类器引导
无分类器扩散指导[20]是一种权衡扩散模型生成的样本质量和多样性的方法。它通常用于类条件图像和文本条件图像生成,以提高生成图像的视觉质量,并使采样图像更好地与其条件相对应。无分类器引导有效地将概率质量向数据转移,其中隐式分类器pθ(c|zt)将高似然性分配给条件c。无分类器引导的实现包括联合训练扩散模型进行条件和无条件去噪,并在推理时组合两个得分估计。无条件去噪的训练是通过在训练期间简单地将条件设置为某个频率下的固定零值c=∅来完成的。在推理时,当引导量表s≥1时,在di中外推修正的得分估计值eθ(zt,c)-朝向条件eθ(zt,c),远离无条件eθ。
![]()
对于我们的任务,分数网络eθ(zt,cI,cT)有两个条件:输入图像cI和文本指令cT。我们发现,在两种条件下利用无分类器指导是否有益。Liu等人[38]证明,条件扩散模型可以从多个不同的条件值中组合分数估计。我们将相同的概念应用于具有两个单独条件输入的模型。在训练过程中,我们随机设置5%的样本只有cI=∅I,5%的样本只有cT=⇼T,5%的示例同时有cI=?I和cT=?T。因此,我们的模型能够对两个或两个条件输入进行条件或无条件的去噪。我们引入了两个指导量表,sI和sT,可以调整它们来权衡生成的样本与输入图像的对应程度和它们与编辑指令的对应程度。我们修改后的分数估计如下:

在图4中,我们显示了这两个参数对生成样本的影响。关于我们的无分类器引导公式的详细信息,请参见附录B

结果
我们在一组不同的真实照片和艺术品上展示了基于指令的图像编辑结果,用于各种类型的编辑和指令文字。所选结果见图1、5、6、7、11、12、15、16、17、18和19。我们的模型成功地执行了许多具有挑战性的编辑,包括替换对象、更改季节和天气、替换背景、修改材质属性、转换艺术媒介等。
我们将我们的方法与最近的几部作品SDEdit[39]和Text2Live[6]进行了定性比较。我们的模型遵循如何编辑图像的说明,但之前的工作(包括这些基线方法)需要对图像(或编辑层)进行描述。因此,我们为他们提供了“编辑后”的文字说明,而不是编辑说明。我们还将我们的方法与SDEdit进行了定量比较,使用了两个衡量图像一致性和编辑质量的指标,如第4.1节所述。最后,我们在第4.2节中展示了生成的训练数据的大小和质量如何影响我们模型的性能。
 图5。蒙娜丽莎变成了各种艺术媒介。
图5。蒙娜丽莎变成了各种艺术媒介。

图6。亚当的创造与新的背景和主题(以768分辨率生成)。

图7。披头士乐队标志性的专辑《艾比路》封面以各种方式发生了变化。
训练配置
我们在8×40GB NVIDIA A100 GPU上训练我们的图像编辑模型,在25.5小时内完成10000步。我们以256×256的分辨率进行训练,总批量大小为1024。我们应用随机水平翻转增强和裁剪增强,其中图像首先在256和288像素之间随机调整大小,然后裁剪到256。我们使用10−4的学习率(没有任何学习率预热)。从Stable Diffusion v1.5检查点的EMA权重初始化我们的模型,并采用公共Stable Diffusion代码库中的其他训练设置。虽然我们的模型是在256×256分辨率下训练的,但我们发现它在推理时很好地推广到512×512分辨率,并在本文中使用Kerras等人提出的具有去噪方差调度的Euler祖先采样器在512分辨率下生成了100个去噪步骤的结果[25]。在A100 GPU上使用我们的模型编辑图像大约需要9秒。