文章目录
- 论文实验总览
- 1. 任务设置与测试策略
- 2. 任务类别
- 3. 关键实验结果
- 4. 数据污染与实验局限性
- 5. 总结与贡献
- Abstract
- 1. 概括
- 2. 具体分析
- 3. 摘要全文翻译
- 4. 为什么不需要梯度更新或微调⭐
- Introduction
- 1. 概括
- 2. 具体分析
- 3. 进一步分析
- Approach
- 1. 概括
- 2. 具体分析
- 3. 进一步分析
- Results
- 1. 概括
- 2. 具体分析
- 2.1 语言模型任务
- LAMBADA任务
- HellaSwag任务
- StoryCloze
- 2.2 闭卷问答任务
- 总结:
- 2.3 翻译任务
- 2.4 Winograd风格任务
- 2.5 常识推理任务
- 2.6 阅读理解
- 3. 分析与总结
- Measuring and Preventing Memorization Of Benchmarks
- 1. 概括
- 2. 具体分析
- 3. 分析与总结
- Limitations
- 1. 概括
- 2. 具体分析
- GPT-3 在文本生成中的局限性
- 常识推理任务的挑战
- NLP 任务的表现差异
- 结构与算法局限
- 3. 未来改进方向
- Broader Impacts
- 1. 概括
- 2. 具体分析
- Misuse of Language Models(语言模型的滥用风险)
- Threat Actor Analysis(威胁行为者分析)
- Fairness, Bias, and Representation(公平性、偏见与代表性问题)
- Energy Usage(能源使用)
- 3. 总结
- Related Work
- 1. 概括
- 2. 具体分析
- 扩展语言模型的研究
- 小规模模型的优化
- 构建更加困难的基准任务
- 3. 小结
- Conclusion
- 1. 概括
- 2. 具体分析
- GPT-3 的性能总结
- 模型扩展的可预测趋势
- 社会影响讨论
- 局限性与未来展望
- 3. 小结
- Contributions
- 1. 概括
- 2. 具体分析
- 模型实现与训练基础设施
- 预训练实验
- 数据准备
- 下游任务的实现
- 缩放定律与模型规模预测
- 3. 总结
- end:三代GPT对比
- 各方面对比
- 1. GPT(Generative Pre-Training)
- 2. GPT-2
- 3. GPT-3
- 总结与对比
- 三代GPT的数据集
- 1. 《Language Models are Few-Shot Learners》
- 2. 《Language Models are Unsupervised Multitask Learners》
- 3. 《Improving Language Understanding by Generative Pre-Training》
🍃作者介绍:双非本科大四网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发,目前开始人工智能领域相关知识的学习
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
论文实验总览
在论文中作者对GPT-3模型进行了广泛的实验,评估其在零样本、单样本、少样本任务中的表现。
以下是对实验部分的详细讲解,以帮助快速理解其核心思想和贡献。
1. 任务设置与测试策略
在实验部分,作者明确指出,GPT-3被测试在三种主要的任务场景中:零样本(zero-shot)、单样本(one-shot)和少样本(few-shot)。
- 零样本学习(Zero-shot learning):在零样本设置中,模型没有接受任何与测试任务相关的训练示例。它只接收任务的自然语言描述,直接推断答案。这是一种极具挑战性的任务,因为模型完全依赖于其预训练过程中获得的广泛知识和语境理解能力。
原文:
“Zero-Shot (0S) is the same as one-shot except that no demonstrations are allowed, and the model is only given a natural language instruction describing the task. This method provides maximum convenience, potential for robustness, and avoidance of spurious correlations”
- 单样本学习(One-shot learning):相比之下,单样本学习允许模型接受一个示例,并根据示例进行推理。这种方法与零样本类似,但多了一个具体的示例来帮助模型理解任务。
- 少样本学习(Few-shot learning):少样本学习中,模型接受多个示例,通常在10到100个示例之间。少样本的优势在于它减少了对大规模任务特定数据的依赖,同时也减少了模型对狭窄分布的依赖,从而提升泛化能力。
原文:
“Few-Shot (FS) is the term we will use in this work to refer to the setting where the model is given a few demonstrations of the task at inference time as conditioning”
few - shot (FS)是我们在这项工作中使用的术语,指的是在推理时给模型一些任务演示作为条件反射的设置
“for a typical dataset an example has a context and a desired completionn (for example
an English sentence and the French translation), and few-shot works by giving K examples of context and completion, and then one final example of context, with the model expected to provide the completion.”
对于典型的数据集,示例具有上下文和期望的补全(例如一个英语句子和法语翻译),通过给出K个上下文和补全的例子,然后给出一个上下文的最后一个例子,期望模型提供补全。
2. 任务类别
实验评估涵盖了多个任务类别,作者对GPT-3在自然语言理解、生成、推理等任务中的表现进行了测试。以下是具体的任务类别:
- 语言建模与Cloze(完形)任务:GPT-3在Penn Tree Bank(PTB)数据集上的测试表现出色。作者指出,GPT-3在传统语言建模任务上取得了显著进步,达到了新的零样本学习的最优表现(SOTA)。在LAMBADA数据集上,GPT-3的表现尤为突出,尤其是在少样本设置下,它的准确率提高了18%。
原文:
“LAMBADA is also a demonstration of the flexibility of few-shot learning as it provides a way to address a problem that classically occurs with this dataset”
“GPT-3 achieves 86.4% accuracy in the few-shot setting, an increase of over 18% from the previous state-of-the-art.”
达到了86.4%的精度,比之前的最先进技术提高了18%以上
- 封闭书籍式问答任务(Closed-Book QA):此类任务评估了GPT-3在无需外部文本帮助下回答知识性问题的能力。在TriviaQA上,GPT-3的表现非常接近或超越了之前的精调模型,特别是在少样本学习设置中,它的准确率达到了71.2%。
原文:
“GPT-3 achieves 64.3% accuracy on TriviaQA in the zero-shot setting, 68.0% in the one-shot setting, and 71.2% in the few-shot setting, the last of which is state-of-the-art relative to fine-tuned models operating in the same closed-book setting.”
- 翻译任务:虽然GPT-3的主要训练数据集以英语为主(93%),但它在多语言翻译任务中的表现也得到了测试。在少样本情况下,GPT-3的表现接近无监督机器翻译(NMT)模型,尤其在法语到英语和德语到英语的翻译中表现突出。
原文:
“Zero-shot GPT-3, which only receives on a natural language description of the task, still underperforms recent unsupervised NMT results. However, providing only a single example demonstration for each translation task improves performance by over 7 BLEU.”
Zero-shot GPT-3只接收任务的自然语言描述,仍然不如最近的无监督NMT结果。
然而,为每个翻译任务只提供一个示例演示可以将性能提高7个BLEU以上。
(这段在论文当中因为中间有表格,所以是"断开的")
这段话的意思是:
在没有任何示例的情况下,GPT-3 只能通过自然语言描述任务来完成翻译任务(这就是所谓的 “zero-shot”)。也就是说,GPT-3 只接收到任务的文字描述,而没有任何具体的翻译示例。在这种情况下,GPT-3 的表现比最新的无监督机器翻译(NMT,Neural Machine Translation)结果要差。
然而,如果给 GPT-3 提供一个示例(即 “one-shot”,只给出一个翻译任务的例子),GPT-3 的翻译表现会明显提高,BLEU 分数(用于评估翻译质量的标准)提高了超过 7 分。
- Winograd Schema Challenge(WSC)任务:WSC任务是评估模型理解自然语言中的指代关系能力。GPT-3在Winograd和Winogrande数据集上表现较好,少样本学习下的准确率达到77.7%,接近精调模型的表现。
原文:
“On the more difficult Winogrande dataset, we do find gains to in-context learning: GPT-3 achieves 70.2% in the zero-shot setting, 73.2% in the one-shot setting, and 77.7% in the few-shot setting.”
在更困难的Winogrande数据集上,我们确实发现了上下文学习的收益:GPT-3在zero-shot设置中达到70.2%,在one-shot设置中达到73.2%,在few-shot设置中达到77.7%。
- 常识推理(Common Sense Reasoning):GPT-3在常识推理任务中表现参差不齐。在PIQA物理推理任务中,它在少样本条件下表现超过了最优的精调模型,但在一些其他任务(如ARC挑战数据集)上的表现还不够理想。
原文:
“GPT-3 achieves 81.0% accuracy zero-shot, 80.5% accuracy one-shot, and 82.8% accuracy few-shot (the last measured on PIQA’s test server).”
GPT-3在零样本学习(Zero-shot)情况下的准确率为81.0%,在一样本学习(0ne-shot)情况下的准确率为80.5%,在少数样本学习(Few-shot)情况下的准确率为82.8%(最后一次是在PIQA的测试服务器上测量的)
3. 关键实验结果
GPT-3在多个任务中表现出了显著的优势,尤其是在少样本学习环境下,它的性能在许多情况下接近甚至超过了现有的最优精调模型。以下是一些显著的实验结果:
- 语言建模与Cloze任务:在LAMBADA数据集上,GPT-3在少样本设置下的表现达到了86.4%的准确率,明显超越了之前的最优模型。
原文:
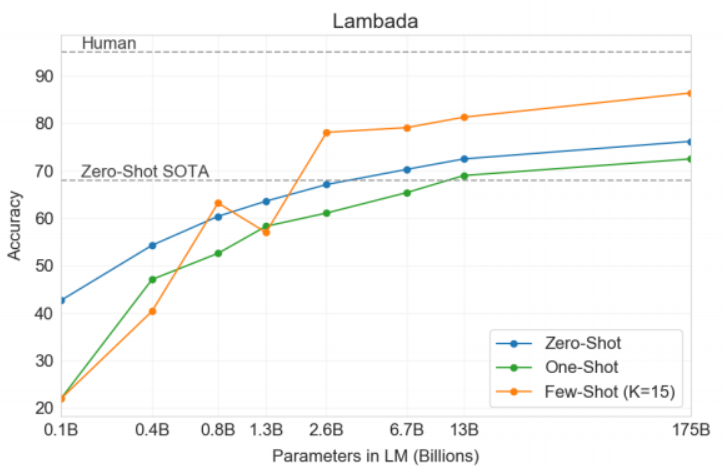
“On LAMBADA, the few-shot capability of language models results in a strong boost to accuracy.GPT-3 achieves 86.4% accuracy in the few-shot setting, an increase of over 18% from the previous state-of-the-art.”
在LAMBADA上,语言模型的少射能力大大提高了准确性。GPT-3在few-shot设置中达到86.4%的精度,比之前的最先进技术提高了18%以上。
- 阅读理解任务:在CoQA(Conversational Question Answering)数据集中,GPT-3在少样本学习设置下的F1分数达到了85.0,接近现有的最优精调模型的水平。
原文:
“GPT-3 achieves 81.5 F1 on CoQA in the zero-shot setting, 84.0 F1 on CoQA in the one-shot setting, 85.0 F1 in the few-shot setting.”
- 翻译任务:在少样本条件下,GPT-3的表现优于现有的无监督机器翻译模型,并且在法语到英语和德语到英语的翻译任务中达到了接近有监督模型的表现。
原文:
“For both Fr-En and De-En, few shot GPT-3 outperforms the best supervised result we could find but due to our unfamiliarity with the literature and the appearance that these are un-competitive benchmarks we do not suspect those results represent true state of the art.”
对于Fr-En和De-En两种语言对,我们发现极少数的GPT-3模型在性能上超过了我们能找到的最好的监督学习结果。但由于我们对相关文献不熟悉,而且这些基准测试似乎不具竞争力,所以我们并不认为这些结果代表了当前的最佳水平。
这段话的意思是:
对于法语到英语(Fr-En)和德语到英语(De-En)的翻译任务,在“few-shot”条件下,GPT-3 的表现超过了他们找到的最佳监督学习结果(supervised result)。但是,作者对相关文献(翻译领域的研究)并不太熟悉,同时他们也注意到这些基准测试(benchmarks)似乎并不是当前最具竞争力的。因此,他们不认为 GPT-3 的这些结果是真正的“最先进水平”(state of the art)。
简单来说,尽管 GPT-3 在法语到英语和德语到英语的翻译任务上表现很好,但作者对相关领域的研究了解有限,所以无法确定这些结果是否代表真正的最优水平。
4. 数据污染与实验局限性
作者也详细探讨了在训练大规模模型时可能遇到的“数据污染”问题,即模型在训练数据中可能会看到测试集中的某些数据。这种问题可能会导致实验结果偏高,因此,作者在实验中采取了多种措施来检测和减少数据污染的影响。尽管如此,作者仍然发现某些数据集中存在重叠的情况,并且对这些结果进行了标记。
原文:
“We develop systematic tools to measure data contamination and quantify its distorting effects. Although we find that data contamination has a minimal effect on GPT-3’s performance on most datasets, we do identify a few datasets where it could be inflating results, and we either do not report results on these datasets or we note them with an asterisk, depending on the severity.”
我们开发了系统的工具来测量数据污染并量化其扭曲效应。虽然我们发现数据污染对GPT-3在大多数数据集上的性能影响很小,但我们确实确定了一些可能会夸大结果的数据集,我们要么不报告这些数据集的结果,要么根据严重程度用星号标记它们。
5. 总结与贡献
通过对GPT-3模型的详细实验,作者展示了少样本学习在语言模型中的潜力,尤其是在任务不可精调或训练数据不足的情况下,GPT-3能够表现出良好的泛化能力。这为未来更大规模的模型开发提供了重要的启示,尤其是在跨领域任务的快速适应方面。
这篇论文的核心贡献在于展示了GPT-3的规模效应,并表明随着模型参数的增加,它能够在零样本、单样本和少样本学习中表现出色,甚至在某些任务上超越了现有的精调模型。
这使得语言模型在不需要任务特定数据的情况下,能够快速泛化到新的任务,从而推动了无监督学习领域的发展。
下面进入论文每一章节的学习,我会先讲这个章节的"概括",再对主要内容进行讲述,同时关键地方会附上论文原文,方便定位查找。 同时下面内容的标题均与论文内容标题对应。
先说结论:我认为GPT-3用一句话可以概括,那就是大力出奇迹“!
Abstract
1. 概括
在论文的摘要部分,作者讨论了自然语言处理(NLP)领域的一个趋势:通过大规模预训练语言模型来提升多项任务的表现。
传统的方法是先在大规模文本上进行预训练,再通过针对特定任务的数据进行微调。
然而,这种方法依然依赖于大量的任务特定数据,现有的NLP系统通常无法像人类一样,通过少量的例子或简单的指令完成新任务。
为此,作者展示了通过扩大语言模型的规模(例如GPT-3,具有1750亿参数),可以显著提高在“少样本学习”(few-shot learning)环境下的任务表现,甚至在某些任务上可以与微调的最先进模型相媲美。
论文指出,GPT-3在没有进行梯度更新或微调的情况下,通过文本交互即可执行任务。
此外,GPT-3在生成新闻文章方面表现出色,人类评估者难以区分其生成的内容与人类写作的文章。
2. 具体分析
- 现有问题:当前的NLP模型依赖于任务特定的数据集进行微调,虽然模型架构是通用的,但仍然需要数千到数万条样本才能达到较好的性能。
原文:
“While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples.”
- 人类能力的对比:人类能够通过少量例子或简单指令来完成新的语言任务,但现有的NLP系统在这方面仍存在很大差距。
原文:
“By contrast, humans can generally perform a new language task from only a few examples or from simple instructions – something which current NLP systems still largely struggle to do.”
- GPT-3的优势:GPT-3通过 扩大模型规模(1750亿参数),在无需梯度更新或微调的情况下,通过文本交互来处理任务。在多个NLP数据集上,GPT-3表现出色,包括翻译、问答和拼字任务等。此外,它在需要即兴推理或领域适应的任务(例如解词、三位数算术等)中也有优异表现。
原文:
“Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting.”
具体来说,我们训练了GPT-3,一个具有1750亿个参数的自回归语言模型,比以往任何非稀疏语言模型都多10倍,并在few-shot设置中测试了它的性能。
- 不足与局限:GPT-3在某些数据集上的表现依然有限,特别是在使用大规模网络语料训练时,它也面临一些方法上的问题。
原文:
“At the same time, we also identify some datasets where GPT-3’s few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora.”
- 社会影响:GPT-3可以生成高质量的新闻文章,且人类评估者难以区分其与人类写作的区别,作者还探讨了这一现象及其对社会的潜在影响。
原文:
“Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general.”
总结来说,论文的摘要部分介绍了GPT-3模型的主要创新点——通过大规模预训练,无需微调即可在多个任务上取得较好的表现,尤其在少样本学习情境中表现优异。论文还提到了一些挑战与社会影响。
3. 摘要全文翻译
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task.
最近的工作表明,通过在大量文本语料库上进行预训练,然后在特定任务上进行微调,在许多NLP任务和基准上取得了实质性的进展。
While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples.
虽然在体系结构中通常与任务无关,但这种方法仍然需要特定于任务的数千或数万个示例的微调数据集。
By contrast, humans can generally perform a new language task from only a few examples or from simple instructions – something which current NLP systems still largely struggle to do.
相比之下,人类通常只需要几个例子或简单的指令就能完成一个新的语言任务——这是目前NLP系统在很大程度上仍然难以做到的。
Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art finetuning approaches.
在这里,我们表明,扩展语言模型极大地提高了任务不可知的、少数镜头的性能,有时甚至达到了与先前最先进的微调方法的竞争力。
Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting.
具体来说,我们训练了GPT-3,一个具有1750亿个参数的自回归语言模型,比以往任何非稀疏语言模型都多10倍,并在few-shot设置中测试了它的性能。
For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
对于所有任务,GPT-3的应用没有任何梯度更新或微调,任务和少数镜头演示完全通过与模型的文本交互指定。
GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
GPT-3在许多NLP数据集上都有很强的表现,包括翻译、问答和完形填空任务,以及一些需要实时推理或领域适应的任务,如解乱单词、在句子中使用新单词或执行3位数算术。
At the same time, we also identify some datasets where GPT-3’s few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora.
与此同时,我们也发现了一些GPT-3的少数镜头学习仍然挣扎的数据集,以及一些GPT-3面临与大型网络语料库训练相关的方法问题的数据集。
Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans.
最后,我们发现GPT-3可以生成新闻文章的样本,人类评估者很难将其与人类撰写的文章区分开来。
We discuss broader societal impacts of this finding and of GPT-3 in general.
我们讨论了这一发现和GPT-3的更广泛的社会影响。
4. 为什么不需要梯度更新或微调⭐
全文翻译摘要有利于更清晰的知道这篇论文干了什么事情;
看了上面的摘要,我有一个问题,那就是:为什么不需要梯度更新或微调
论文当中提到:
'Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting.",
这段话的意思是:
作者训练了 GPT-3,这是一种自回归语言模型(autoregressive language model),拥有 1750 亿 个参数。这个模型的参数数量是之前任何非稀疏语言模型的 10 倍。接着,作者测试了 GPT-3 在 few-shot 学习环境下的表现,也就是说,模型在不进行梯度更新和微调的情况下,仅通过提供少量示例来完成任务。
GPT-3 的设计使得它在执行任务时,不需要像传统方法那样进行 梯度更新(gradient updates) 和 微调(fine-tuning)。这个特性在论文中被称为 “in-context learning”。也就是说,GPT-3 只需要通过上下文信息(在推理时的文本输入)来学习和完成任务,而不是通过修改模型参数(即梯度更新)的方式。
论文对这一点的解释如下:
原文引用:
“For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.”
解释:
对于所有任务,GPT-3 在不进行任何梯度更新或微调的情况下使用,仅通过文本交互(即通过自然语言任务描述和少量示例)来指定任务和演示。这意味着,GPT-3 能够通过给定的文本信息直接完成任务,而不需要修改其内部的参数。
为什么 GPT-3 能做到不需要梯度更新:
- 原因在于 GPT-3 是通过 大量预训练 实现的。
- 在预训练阶段,它接触了大量的文本数据,学会了大量的语言模式和任务结构。
- 因此,在实际推理时,GPT-3 不需要像传统的机器学习模型那样对特定任务进行再训练或微调,它可以通过上下文中的少量示例来推断出任务的要求。这种能力与其庞大的参数量(1750 亿参数)直接相关,这使得它能够泛化并在多个任务中表现良好。
- 这在论文中被称为 “meta-learning” 或 “in-context learning”,即模型在预训练过程中已经学到了大量的任务模式,推理时无需再修改模型的权重就能执行不同的任务。
Introduction
1. 概括
"Introduction"部分主要介绍了当前自然语言处理(NLP)领域的预训练模型方法及其局限性,尤其是如何通过扩展模型规模来应对这些问题。
论文详细讨论了GPT-3模型的发展背景、任务无关(task-agnostic)的预训练模型如何应用于少样本学习(few-shot learning),并且展望了少样本学习在消除对大规模数据集依赖方面的潜力。
作者还讨论了近年来模型规模扩展带来的性能提升,并引入了“元学习”(meta-learning)与“in-context learning”作为重要概念。
2. 具体分析
- 当前预训练模型的进展与局限性:
在NLP中,语言模型的预训练架构经历了几个发展阶段。从早期的单层词向量模型,到后来具有上下文表示的循环神经网络(RNNs),再到近年来大规模Transformer模型的引入,这些技术在多个NLP任务上取得了巨大进展。特别是,预训练Transformer模型通过微调,可以在阅读理解、问答等任务上获得极佳的表现。
论文原文提到:
“Recent years have featured a trend towards pre-trained language representations in NLP systems, applied in increasingly flexible and task-agnostic ways for downstream transfer.”
近年来,在NLP系统中出现了一种预训练语言表示的趋势,以越来越灵活和任务不可知的方式应用于下游迁移。
这句话的意思是:
近年来,自然语言处理(NLP)系统中出现了一个趋势,那就是预训练的语言表示(pre-trained language representations)得到了广泛应用。预训练的语言表示是指在大型数据集上预先训练的语言模型,这些模型能够学习到丰富的语言知识。
这些预训练模型可以灵活地用于不同的任务,而不需要为每个具体任务专门设计架构。这种方法是任务无关的(task-agnostic),意味着一个模型可以通过简单的调整或微调,适应不同的下游任务,而不需要为每个任务重新训练一个新模型。
换句话说,这种趋势使得研究人员可以通过一个预先训练好的通用模型,在许多不同的自然语言处理任务中进行应用,从而提高了效率和灵活性。
那么什么叫下游任务:
下游任务(downstream tasks)是指在机器学习,尤其是自然语言处理(NLP)中,使用预训练模型完成的具体任务。预训练模型首先在大量数据上进行训练,学习通用的语言表示和特征,然后这些通用模型会被用于处理特定的实际应用任务,这些任务就是“下游任务”。
典型的 NLP 下游任务包括:
- 文本分类:将一段文本归类到特定类别,如垃圾邮件检测、情感分析。
- 机器翻译:将一种语言的文本翻译成另一种语言。
- 问答系统:根据一段文本回答问题,如基于文本的信息提取和回答问题。
- 命名实体识别(NER):从文本中识别出人名、地名、公司名等实体。
- 句子生成:生成自然流畅的句子,如文章续写。
- 阅读理解:模型从一段文本中理解并提取关键信息。
预训练模型通过在大规模数据集上学习语言的通用特征,之后应用到这些下游任务时,不需要从头开始训练,只需稍微调整(微调)模型就可以获得良好的效果。这使得下游任务的开发更加高效。
然而,尽管这些模型架构在任务上是任务无关的,但它们的实际应用依然受到两个关键问题的限制:
①任务特定数据的依赖:
模型在每个新任务上仍然需要大量的标注数据,这使得它们的适用性受限。例如,在实际应用中,为每个新任务准备成千上万的标注数据集是很困难的。
论文指出:
“There exists a very wide range of possible useful language tasks, … it is difficult to collect a large supervised training dataset, especially when the process must be repeated for every new task.”
②泛化能力不足:
预训练模型往往过于专注于训练数据的分布,而在遇到分布外(out-of-distribution)的数据时表现较差。即使模型规模越来越大,仍然可能无法很好地泛化到与训练数据不同的任务上。
论文进一步说明:
“There is evidence that suggests that the generalization achieved under this paradigm can be poor because the model is overly specific to the training distribution and does not generalize well outside it.”
- 与人类学习的差距:
人类在执行语言任务时,通常只需要少量的指令或示例就能理解任务并完成。而目前的语言模型依赖于大量的标注数据,并需要通过微调来获得好的表现。作者希望通过减少对大数据集的依赖,使语言模型能够更像人类一样高效地学习语言任务。论文通过举例描述了人类如何通过简单的指令快速掌握任务:
“Humans do not require large supervised datasets to learn most language tasks – a brief directive in natural language (e.g. “please tell me if this sentence describes something happy or something sad”) or at most a tiny number of demonstrations (e.g. “here are two examples of people acting brave; please give a third example of bravery”) is often sufficient to enable a human to perform a new task.”
人类不需要大型监督数据集来学习大多数语言任务-自然语言的简短指令(例如“请告诉我这句话描述的是快乐还是悲伤”)或最多少量的演示(例如“这里有两个表现勇敢的人的例子;请再举个勇敢的例子”),这通常足以让一个人完成一项新任务。
- 元学习(Meta-learning)与in-context learning:
为了缩小当前模型与人类学习方式的差距,作者提出了元学习的概念。元学习意味着模型在训练时学会了一组广泛的技能和模式识别能力,并在推理时通过少量的任务示例或文本指令来快速适应新的任务。作者提出的“in-context learning”方法正是通过这种方式实现的,即模型在推理时通过输入上下文来识别任务,并预测接下来的任务需求,而无需进行权重更新。
论文解释了这一过程:
"We use the term “in-context learning” to describe the inner loop of this process, which occurs within the forward-pass upon each sequence. "
- 模型规模扩展与性能提升:
随着Transformer模型规模的不断扩展,语言模型的能力显著提高。例如,最早的$ 100 亿参数模型发展到 G P T − 3 的 亿参数模型发展到GPT-3的 亿参数模型发展到GPT−3的 1750 $亿参数,每次模型扩展都显著提高了其在语言生成和下游NLP任务中的表现。作者强调,模型的扩展不仅仅提升了模型的文本生成能力,还改善了其在各种NLP任务中的泛化性能。
论文特别指出:
“Each increase has brought improvements in text synthesis and/or downstream NLP tasks, and there is evidence suggesting that log loss, which correlates well with many downstream tasks, follows a smooth trend of improvement with scale”
每次提升都带来了文本合成 and/or 下游自然语言处理任务的改进,有证据表明,与许多下游任务高度相关的对数损失函数(log loss)随着规模的增大呈现出平稳的改进趋势。
- 图表讲解:
- 图1.1: “Language model meta-learning”
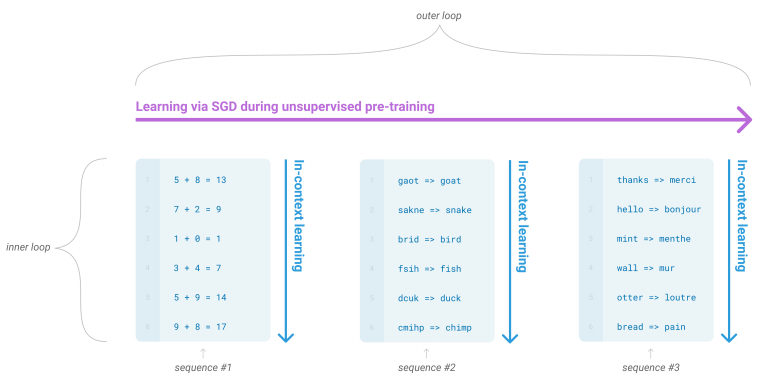
这一图表展示了语言模型通过无监督预训练开发出的广泛技能,如何在推理时迅速适应任务。图中展示了任务的内循环过程,称为“in-context learning”,这是一种利用上下文信息推理的过程。模型在推理阶段,利用文本输入作为任务的说明,然后基于输入进行预测。这张图通过多个子任务嵌入的序列展示了这个内循环过程,尽管这些序列并不代表模型在预训练期间所看到的数据,而是说明了模型如何在任务中进行适应。
原文描述:
“The sequences in this diagram are not intended to be representative of the data a model would see during pre-training, but are intended to show that there are sometimes repeated sub-tasks embedded within a single sequence.”
该图中的序列并非旨在代表模型在预训练期间可能看到的数据,而是旨在说明有时在一个序列中会嵌入重复的子任务。
图1.2: “Larger models make increasingly efficient use of in-context information”
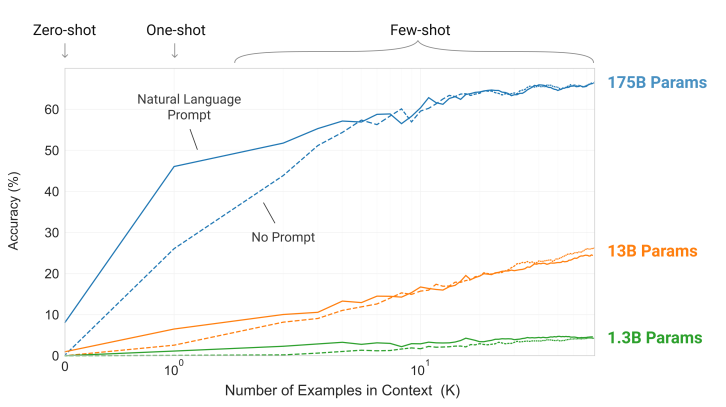 这张图展示了大规模模型在少样本学习中的显著提升。作者测试了不同规模模型在简单任务中的in-context学习表现,任务要求模型去掉单词中的随机符号。随着模型规模的增加,模型利用上下文信息完成任务的能力显著增强。该图表明,较大规模的模型在in-context learning任务中表现出更陡峭的学习曲线,这意味着它们能更高效地从上下文中获取信息。
这张图展示了大规模模型在少样本学习中的显著提升。作者测试了不同规模模型在简单任务中的in-context学习表现,任务要求模型去掉单词中的随机符号。随着模型规模的增加,模型利用上下文信息完成任务的能力显著增强。该图表明,较大规模的模型在in-context learning任务中表现出更陡峭的学习曲线,这意味着它们能更高效地从上下文中获取信息。
原文解释:
"The steeper “in-context learning curves” for large models demonstrate improved ability to learn a task from contextual information. We see qualitatively similar behavior across a wide range
of tasks."
图1.3: “Aggregate performance for all 42 accuracy-denominated benchmarks”
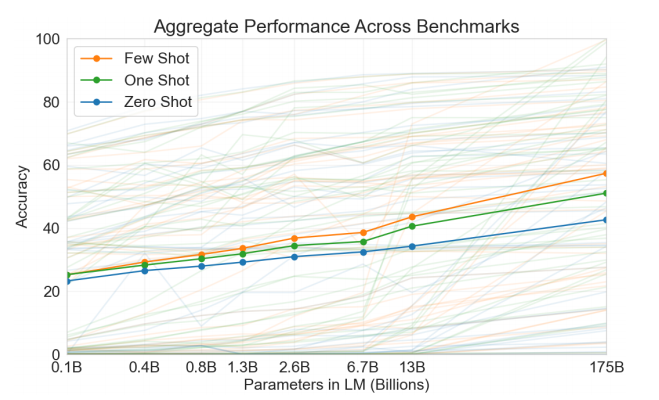
该图展示了不同规模模型在$ 42 $个基准测试上的整体表现。图表显示,随着模型规模的扩大,零样本和少样本学习的性能提升较为显著,尤其是少样本学习(few-shot learning)的表现,随着模型规模的增加,提升速度更快。作者通过这一图表强调了大模型在处理in-context信息时的优势。
论文指出:
“Few-shot performance increases more rapidly, demonstrating that larger models are more proficient at in-context learning.”
3. 进一步分析
在"Introduction"部分,作者提出了基于in-context learning的元学习方法,试图解决现有方法中对大数据集和任务特定数据的依赖问题。通过扩展模型规模,GPT-3在多个任务中的表现显著提升。最重要的是,GPT-3不仅在预训练和微调阶段表现出色,还在零样本和少样本学习环境中表现突出,展现了其无需微调即可适应新任务的潜力。
这部分内容不仅奠定了论文的基础,还为后续的研究方向提出了新的可能性。
Approach
1. 概括
在"Approach(方法)"部分,作者详细描述了GPT-3的模型架构、训练方法以及不同学习设置的对比。
GPT-3通过扩展模型规模、数据集和训练时间,显著提高了语言任务中的表现,特别是在少样本学习(Few-Shot Learning)方面表现出色。作者在这一部分讨论了几种不同的学习设置,包括零样本、单样本和少样本,并展示了GPT-3如何通过上下文信息完成任务,而无需更新模型权重。
2. 具体分析
- 模型训练基础:
GPT-3的预训练方法与之前的GPT-2方法类似,主要通过扩展模型规模和数据集来提升性能。模型在大量未标注的文本数据上进行训练,形成了广泛的语言技能和模式识别能力,这些能力使得模型能够在推理阶段通过上下文信息执行任务,而无需进一步微调。
“Our basic pre-training approach, including model, data, and training, is similar to the process described in [RWC+19], with relatively straightforward scaling up of the model size, dataset size and diversity, and length of training. Our use of in-context learning is also similar to [RWC+19], but in this work we systematically explore different settings for learning within the context.”
我们的基本预训练方法,包括模型、数据和训练,与[RWC+19]中描述的过程类似,模型大小、数据集大小和多样性以及训练长度的缩放相对简单。我们对情境学习的使用也类似于[RWC+19],但在这项工作中,我们系统地探索了在情境中学习的不同设置。
- 四种学习设置对比:
论文讨论了GPT-3在四种不同的学习环境中的表现,这些环境可以根据对任务特定数据的依赖程度来进行区分。
- 微调(Fine-Tuning, FT):这是过去几年来最常见的方法,模型通过一个特定任务的数据集对预训练模型的权重进行更新。这个过程通常使用成千上万个标注示例。微调的主要优点是能够在许多基准测试上表现优异,但缺点是每个任务都需要一个新的大规模数据集,并且模型可能无法很好地泛化到分布外数据。
“Fine-Tuning (FT) has been the most common approach in recent years, and involves updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task. Typically thousands to hundreds of thousands of labeled examples are used. The main advantage of fine-tuning is strong performance on many benchmarks. The main disadvantages are the need for a new large dataset for every task, the potential for poor generalization out-of-distribution [MPL19], and the potential to exploit spurious features of the training data [GSL+18, NK19], potentially resulting in an unfair comparison with human performance.”
- 少样本学习(Few-Shot, FS):在这种情况下,模型在推理时会通过上下文给定少量示例进行推理,但不允许更新权重。少样本学习的主要优点是显著减少了任务特定数据的需求,并降低了从大规模但狭窄的微调数据集中学习到过于狭窄分布的可能性。
"Few-Shot (FS) is the term we will use in this work to refer to the setting where the model is given a few demonstrations of the task at inference time as conditioning [RWC+19], but no weight updates are allowed. As shown in Figure 2.1, for a typical dataset an example has a context and a desired completion (for example an English sentence and the French translation), and few-shot works by giving K examples of context and completion, and then one final example of context, with the model expected to provide the completion. We typically set K in the range of 10 to 100 as this is how many examples can fit in the model’s context window (nctx = 2048). The main advantages of few-shot are a major reduction in the need for task-specific data and reduced potential to learn an overly narrow distribution from a large but narrow fine-tuning dataset. "
Few-Shot (FS)是我们在这项工作中使用的术语,指的是在推理时给模型一些任务的演示作为条件[RWC+19],但不允许权重更新的设置。如图2.1所示,对于一个典型的数据集,一个例子有一个上下文和一个期望的补全(例如一个英语句子和一个法语翻译),通过给出K个上下文和补全的例子,然后给出一个上下文的最后一个例子,用预期的模型提供补全。我们通常将K设置在10到100的范围内,因为这是模型上下文窗口中可以容纳的示例数(nctx = 2048)。few-shot的主要优点是大大减少了对特定任务数据的需求,并且减少了从大而窄的微调数据集中学习过于狭窄的分布的可能性。
- 单样本学习(One-Shot, 1S):这与少样本学习类似,但模型只接受一个任务示例以及任务的自然语言描述。该方法与人类通常在实际任务中接收到的指令更为接近。
“One-Shot (1S) is the same as few-shot except that only one demonstration is allowed, in addition to a natural language description of the task, as shown in Figure 1. The reason to distinguish one-shot from few-shot and zero-shot (below) is that it most closely matches the way in which some tasks are communicated to humans. For example, when asking humans to generate a dataset on a human worker service (for example Mechanical Turk), it is common to give one demonstration of the task.”
- 零样本学习(Zero-Shot, ZS):在这种设置下,模型只接受任务的自然语言描述,没有任何示例。这种方法提供了最大的便利性和鲁棒性,但也是最具挑战的,因为模型必须完全依赖任务说明进行推理。
“Zero-Shot (0S) is the same as one-shot except that no demonstrations are allowed, and the model is only given a natural language instruction describing the task. This method provides maximum convenience, potential for robustness, and avoidance of spurious correlations (unless they occur very broadly across the large corpus of pre-training data), but is also the most challenging setting.”
- 训练数据集
GPT-3的训练数据包括多个来源,其中最大的贡献者是Common Crawl数据集,此外还包括WebText2、Books1、Books2和English Wikipedia等。整个训练数据集的大小达到了45TB的未压缩文本数据。为了确保数据集的多样性和广泛性,作者还对这些数据集进行了额外的清理和过滤,以确保训练数据的高质量。

- 训练过程
GPT-3的训练过程采取了混合并行策略,结合模型并行和数据并行来处理大规模的模型和数据。
在训练过程中,作者调整了学习率和批量大小,以最大限度地提高训练效率。为了应对计算资源的挑战,训练使用了微软提供的高带宽GPU集群。
“To train the larger models without running out of memory, we use a mixture of model parallelism within each matrix multiply and model parallelism across the layers of the network.”
为了在不耗尽内存的情况下训练更大的模型,我们在每个矩阵乘法中混合使用模型并行性和跨网络层的模型并行性。
- 评估方法
GPT-3的评估主要基于少样本学习(few-shot learning)场景,模型通过提供少量示例来完成推理任务。每个任务的上下文窗口(nctx = 2048)可以容纳10到100个示例。
作者为每个任务设计了相应的评估流程,允许在推理时为模型提供任务示例,同时限制模型权重的更新。
“For few-shot learning, we evaluate each example in the evaluation set by randomly drawing K examples from that task’s training set as conditioning,”
- 图表讲解:
- 图2.1: “Zero-shot, one-shot and few-shot, contrasted with traditional fine-tuning”:
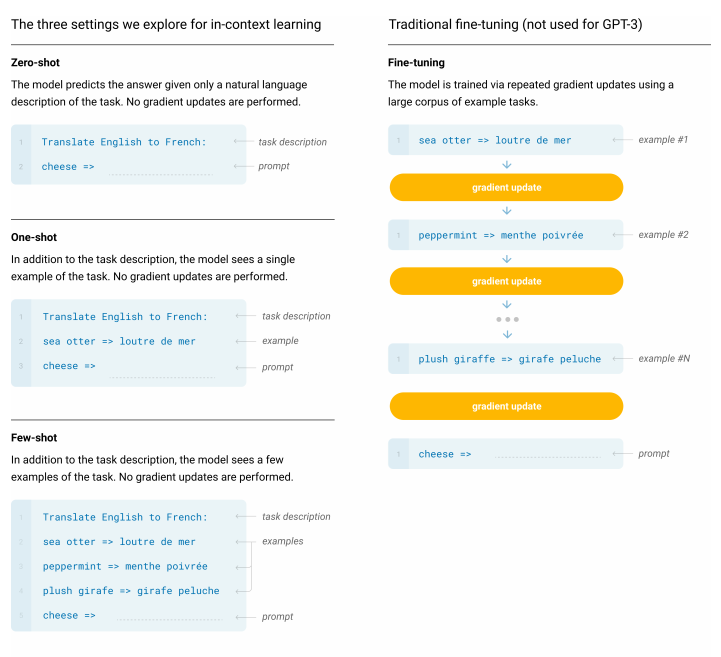
这一图表展示了四种不同的任务执行方式,分别是微调、零样本、单样本和少样本。微调涉及在训练时更新模型权重,而零样本、单样本和少样本则依赖于推理时的上下文输入,而不涉及权重更新。图2.1通过具体的任务示例展示了这些不同方法的实现方式。
“The panels above show four methods for performing a task with a language model – fine-tuning is the traditional method, whereas zero-, one-, and few-shot, which we study in this work, require the model to perform the task with only forward passes at test time. We typically present the model with a few dozen examples in the few shot setting. Exact phrasings for all task descriptions, examples and prompts can be found in Appendix G.”
我们通常在几个镜头设置中用几十个例子来呈现模型。所有任务描述、示例和提示的确切措辞都可以在附录G中找到。

3. 进一步分析
在“Approach”部分,作者明确展示了GPT-3如何在不同的学习设置下表现出色,特别是在少样本学习中。通过大规模预训练,GPT-3能够在不更新权重的情况下,通过上下文示例迅速适应任务需求。相比之下,传统的微调方法虽然性能强大,但其需要大量任务特定数据,泛化能力有限。而零样本和单样本学习则通过最大限度地减少对任务特定数据的依赖,展现了未来模型在更广泛任务中的潜力。
通过扩展模型规模和数据集,GPT-3展示了在少样本学习中的巨大优势,尤其是在推理时模型可以利用上下文信息进行高效的任务执行。
Results
1. 概括
在"Results"部分,作者评估了GPT-3在各种任务中的表现,涵盖了从传统语言建模、完形填空、问答到翻译和常识推理的多种任务。作者通过少样本学习(Few-Shot)、单样本学习(One-Shot)和零样本学习(Zero-Shot)模式,对GPT-3的性能进行了深入的分析和比较。
2. 具体分析
2.1 语言模型任务
GPT-3在语言建模任务上的表现尤为出色。通过对Penn Tree Bank (PTB) 数据集的评估,GPT-3打破了之前的最佳记录,达到了新的状态-of-the-art (SOTA)。由于PTB是一个传统的语言建模数据集,它没有明确区分用于单样本或少样本评估的示例,因此此处仅进行了零样本评估。
“We calculate zero-shot perplexity on the Penn Tree Bank (PTB) [MKM+94] dataset measured in [RWC+19]. We omit the 4 Wikipedia-related tasks in that work because they are entirely contained in our training data, and we also omit the one-billion word benchmark due to a high fraction of the dataset being contained in our training set. PTB escapes these issues due to predating the modern internet. Our largest model sets a new SOTA on PTB by a substantial margin of 15 points, achieving a perplexity of 20.50.”
我们在[RWC+19]中测量的Penn Tree Bank (PTB) [MKM+94]数据集上计算了零射击困惑度。我们在这项工作中省略了4个与维基百科相关的任务,因为它们完全包含在我们的训练数据中,我们也省略了10亿单词的基准测试,因为我们的训练集中包含了很大一部分数据集。由于早于现代互联网,PTB逃避了这些问题。我们最大的模型将PTB上的新SOTA设置为15点,达到20.50的困惑度。
LAMBADA任务
LAMBADA任务是一种需要模型预测句子最后一个单词的完形填空任务,GPT-3在少样本学习场景下显著提高了任务的准确率,达到了86.4%的准确率,比之前的SOTA提升了18%。这表明GPT-3的少样本学习能力极为强大。
“When presented with examples formatted this way, GPT-3 achieves 86.4% accuracy in the few-shot setting, an increase of over 18% from the previous state-of-the-art.”
HellaSwag任务
HellaSwag任务旨在通过从给定的叙事或指令中选择最佳结尾来测试模型的推理能力。这个任务对语言模型极具挑战性,但GPT-3在少样本和单样本场景下分别达到了79.3%和78.1%的准确率,尽管仍然低于目前的SOTA(85.6%)。
“GPT-3 achieves 78.1% accuracy in the one-shot setting and 79.3% accuracy in the few-shot setting, outperforming the 75.4% accuracy of a fine-tuned 1.5B parameter language model [ZHR+19] but still a fair amount lower than the overall SOTA of 85.6% achieved by the fine-tuned multi-task model ALUM.”
StoryCloze
论文如下:
We next evaluate GPT-3 on the StoryCloze 2016 dataset [MCH+16], which involves selecting the correct ending sentence for five-sentence long stories. Here GPT-3 achieves 83.2% in the zero-shot setting and 87.7% in the few-shot setting (with K = 70). This is still 4.1% lower than the fine-tuned SOTA using a BERT based model [LDL19] but improves over previous zero-shot results by roughly 10%.
接下来,我们在StoryCloze 2016数据集[MCH+16]上评估GPT-3,其中包括为五句长故事选择正确的结尾句。其中,GPT-3在零发情况下达到83.2%,在少发情况下达到87.7% (K = 70)。这仍然比使用基于BERT模型的微调SOTA低4.1% [LDL19],但比以前的零射击结果提高了大约10%。

这段内容描述了 GPT-3 在 StoryCloze 2016 数据集上的表现,该数据集的任务是给出一个五句长的故事,并要求模型选择一个正确的句子作为故事的结尾。
下面是对这段的详细解读:
StoryCloze 任务介绍
StoryCloze 数据集用于测试模型在故事理解和情节预测方面的能力。具体任务是,给定一个包含四句的故事,模型需要从两个备选的结尾中选择一个正确的句子,以合理地结束故事。这个任务考察模型的常识推理能力和语言理解能力。GPT-3 在 Zero-shot 和 Few-shot 环境下的表现
GPT-3 在这个任务中分别在 zero-shot 和 few-shot 环境下进行了评估:
- Zero-shot 环境:GPT-3 没有被提供任何示例,只有任务的描述。即使没有示例,GPT-3 的表现依然不错,取得了 83.2% 的准确率。
- Few-shot 环境:在 few-shot 设置下,GPT-3 被提供了 70 个示例(即 K=70K = 70K=70),并在此基础上完成任务。在这种情况下,GPT-3 的表现有所提高,达到了 87.7% 的准确率。
与最先进的微调模型对比
虽然 GPT-3 表现出色,但它仍然比最先进的微调模型(基于 BERT 的模型)低 4.1%。BERT 模型在经过微调后,在这项任务上达到了更高的准确率。相对于以前的 Zero-shot 结果的进步
虽然 GPT-3 的表现未能超越微调的 BERT 模型,但它的 zero-shot 结果相比之前的最佳 zero-shot 模型结果提升了大约 10%。这意味着,在没有提供任何示例的情况下,GPT-3 相对于先前的模型在这类任务上的表现有了显著提升。总结
- 任务:让模型为四句故事选择正确的结尾。
- Zero-shot:GPT-3 在没有示例的情况下取得了 83.2% 的准确率。
- Few-shot:GPT-3 在提供 70 个示例的情况下,取得了 87.7% 的准确率。
- 对比:GPT-3 的 few-shot 结果比微调后的 BERT 模型低 4.1%,但其 zero-shot 结果比先前的最佳 zero-shot 模型提升了约 10%。
通过这段内容,可以看到 GPT-3 在理解故事和选择合理结尾的任务上表现优异,尤其是在 zero-shot 场景下,相比其他模型有了显著提升。
2.2 闭卷问答任务
在闭卷问答(Closed-Book QA)任务中,GPT-3表现出了强大的知识储备能力。
通过对Natural Questions、WebQuestions和TriviaQA数据集的评估,GPT-3在少样本学习场景下分别达到了29.9%、41.5%和71.2%的准确率。
“On TriviaQA, we achieve 64.3% in the zero-shot setting, 68.0% in the one-shot setting, and 71.2% in the few-shot setting. The zero-shot result already outperforms the fine-tuned T5-11B by 14.2%, and also outperforms a version with Q&A tailored span prediction during pre-training by 3.8%. The one-shot result improves by 3.7% and matches the SOTA for an open-domain QA system which not only fine-tunes but also makes use of a learned retrieval mechanism over a 15.3B parameter dense vector index of 21M documents [LPP+20].GPT-3’s few-shot result further improves performance another 3.2% beyond this.”
这段话的意思是描述 GPT-3 在 TriviaQA 数据集上的表现,并且将其与其他模型的结果进行了对比。让我们逐步解析:
- GPT-3 在 TriviaQA 数据集上的结果:
- Zero-shot 设置:GPT-3 在没有任何示例的情况下(zero-shot),取得了 64.3% 的准确率。
- One-shot 设置:当 GPT-3 仅提供一个示例(one-shot)时,准确率提升到了 68.0%。
- Few-shot 设置:当 GPT-3 提供了多个示例(few-shot),准确率进一步提升到了 71.2%。
- 与其他模型对比:
- Zero-shot vs. T5-11B:在 zero-shot 设置下,GPT-3 的 64.3% 准确率比经过微调的 T5-11B 模型(这是一个拥有 110 亿参数的模型)高出了 14.2%。也就是说,GPT-3 在没有任何示例的情况下,表现比 T5-11B 模型要好得多。
- Zero-shot vs. 定制 Q&A 模型:GPT-3 的 zero-shot 准确率 64.3% 也比一种专门为问答任务设计的模型高了 3.8%。这个定制的模型在预训练阶段进行了针对性调整,以适应 Q&A 任务。
- One-shot 表现与最先进模型(SOTA)的对比:
- 当 GPT-3 提供一个示例时(one-shot),它的准确率提高了 3.7%,达到了 68.0%。这个结果相当于当前最先进的开放域问答系统的表现。该系统不仅进行了微调,还使用了一个专门的 检索机制,这个机制在一个拥有 153 亿参数的密集向量索引上检索了 2100 万篇文档来帮助回答问题【参考文献 LPP+20】。
- Few-shot 的进一步提升:
- 在 few-shot 设置下,GPT-3 通过提供多个示例,准确率进一步提高了 3.2%,达到了 71.2%,比 one-shot 表现更好。
总结:
- GPT-3 在 TriviaQA 数据集上的表现非常出色,尤其是在 zero-shot 设置下,它比 T5-11B 和其他定制问答模型有显著提升。
- 在 one-shot 设置下,GPT-3 的表现与当前最先进的开放域问答系统相当,而这种系统不仅微调了模型,还使用了复杂的检索机制。
- 最后,在 few-shot 设置下,GPT-3 的表现进一步提升了 3.2%,展现出极强的问答能力。
这段话的核心是,GPT-3 即使在只提供少量示例的情况下,也能超越现有的许多先进系统,这证明了其强大的通用性和适应性。
2.3 翻译任务
在翻译任务中,GPT-3的表现随着模型规模的扩大而显著提高。尤其是在少样本学习模式下,GPT-3在翻译成英文时表现较为突出,但翻译出英文的效果则略显不足。
“For both Fr-En and De-En, few shot GPT-3 outperforms the best supervised result we could find but due to our unfamiliarity with the literature and the appearance that these are un-competitive benchmarks we do not suspect those results represent true state of the art. For Ro-En, few shot GPT-3 performs within 0.5 BLEU of the overall SOTA which is achieved by a combination of unsupervised pretraining, supervised finetuning on 608K labeled examples, and backtranslation [LHCG19b].”
2.4 Winograd风格任务
Winograd Schema挑战是一项经典的自然语言推理任务,要求模型通过上下文推断指代的含义。GPT-3在少样本学习场景中取得了77.7%的准确率,接近于经过微调的RoBERTa-large模型。
“Scaling is relatively smooth with the gains to few-shot learning increasing with model size, and few-shot GPT-3 175B is competitive with a fine-tuned RoBERTA-large.”
2.5 常识推理任务
在常识推理任务中,GPT-3的表现并不一致。尽管在OpenBookQA任务中有显著提升,但在其他任务如ARC (Challenge) 和PIQA中的表现仍然低于现有的SOTA。
“GPT-3’s few-shot performance is similar to a fine-tuned BERT Large baseline on the leaderboard.”
2.6 阅读理解
论文原文:

这段内容描述了 GPT-3 在 阅读理解(Reading Comprehension) 任务上的表现,使用了五个不同的数据集来评估模型在各种回答格式下的能力。以下是对这部分的详细解释:
- 评估任务和数据集
GPT-3 在五个阅读理解数据集上进行了评估,这些数据集包括抽象性问题、多项选择题和基于跨度(span-based)的回答形式,涉及对话和单一问题场景。模型在不同数据集上的表现差异很大,反映出 GPT-3 在面对不同类型问题时有不同的处理能力。
总体上,GPT-3 的表现与基线模型和使用上下文表示训练的早期结果相当。
- 各数据集上的表现
- CoQA 数据集: GPT-3 在 CoQA(Conversational Question Answering)数据集上表现最好,接近人类基线,准确率只差 3 个点。CoQA 是一个自由对话形式的数据集,要求模型在对话上下文中生成答案。
- QuAC 数据集: 在 QuAC(Question Answering in Context)数据集上,GPT-3 表现最差,比 ELMo 基线低了 13 个 F1 分数。这个数据集需要建模结构化对话行为和师生互动的回答选择,这对 GPT-3 来说是个难点。
- DROP 数据集: 在 DROP(Discrete Reasoning Over Paragraphs)数据集中,测试离散推理和阅读理解中的算术推理能力。GPT-3 在 few-shot 设置下,超过了论文中的 微调 BERT 基线,但仍然远远落后于人类表现和一些使用符号系统增强神经网络的最先进方法。
- SQuAD 2.0 数据集: GPT-3 在 SQuAD 2.0 数据集上的表现展示了其 few-shot 学习能力,在 few-shot 设置下提高了 10 个 F1 分数,从 零样本的 59.1 提升到 69.8,略微超过了原论文中的最佳微调结果。
- RACE 数据集: 在 RACE(ReAding Comprehension from Examinations)数据集中,这个数据集包括中学和高中的英语考试。GPT-3 的表现相对较弱,仅能与早期使用上下文表示的基线模型相媲美,且比最先进模型的表现落后 45%。
- 总结
这部分显示了 GPT-3 在阅读理解任务上的广泛能力,但在某些数据集上存在显著差异:
- 强点:GPT-3 在 CoQA 和 SQuAD 2.0 数据集上展示了较强的 few-shot 学习能力,并且表现超出了部分微调模型。
- 弱点:GPT-3 在 QuAC 和 RACE 数据集上的表现相对较差,特别是在需要复杂推理和对话建模的任务中。
3. 分析与总结
在"Results"部分中,GPT-3在多个任务中的表现进一步展示了其大规模模型的强大能力,尤其是在少样本学习模式下。然而,尽管GPT-3在一些任务上表现优异,它在某些复杂推理任务中仍然面临挑战。这一部分结果也揭示了GPT-3在语言理解和生成任务上的潜力,同时也展示了未来在改进模型能力方面的挑战。
Measuring and Preventing Memorization Of Benchmarks
基准的测量与防止记忆
1. 概括
在这一部分,作者重点探讨了GPT-3模型在训练过程中可能存在的数据泄漏(data contamination)和记忆化现象(memorization)。由于GPT-3的训练数据集庞大且来源广泛(包括Common Crawl等互联网上的数据),训练集中可能包含了一些与测试基准数据集重复的内容。
作者通过设计和执行一系列的实验来衡量这种“泄漏”对测试结果的影响,并提出了一些措施来减轻这种影响,确保模型的评估结果准确无误。
2. 具体分析
- 数据泄漏的检测与影响:
作者首先指出,随着训练数据集规模的扩展和模型能力的增强,模型可能在训练集中见过部分测试数据。这种现象尤其在使用互联网数据时容易发生,因为互联网数据本身可能已经包含了部分测试集的内容。
“Since our training dataset is sourced from the internet, it is possible that our model was trained on some of our benchmark test sets. Accurately detecting test contamination from internet-scale datasets is a new area of research without established best practices.”
由于我们的训练数据集来自互联网,所以我们的模型可能是在我们的一些基准测试集上训练的。从互联网规模的数据集中准确检测测试污染是一个新的研究领域,没有既定的最佳实践。
- 模型训练和评估中的挑战:
尽管先前的GPT-2模型已经进行了数据泄漏的分析,但由于GPT-3的规模和数据集的复杂性,评估这种泄漏变得更加复杂。作者指出,他们发现GPT-3的训练数据中确实包含了一些基准测试集的内容,但对测试结果的影响并不显著。
“GPT-3 operates in a somewhat different regime”
“we expect that contamination is likely to be frequent, but that its effects may not be as large as feared.”
GPT-3的运作方式有些不同。
我们预计污染可能会频繁发生,但其影响可能不会像担心的那么大。
- 清理基准测试集:
为了评估数据泄漏的影响,作者创建了“清理版本”的基准数据集,并比较了GPT-3在“原始数据集”和“清理数据集”上的表现。作者通过移除那些与训练集中有重叠的例子,重新评估模型的表现。如果模型在“清理数据集”上的表现与原始数据集相似,那么可以认为数据泄漏对结果的影响较小。
“We then evaluate GPT-3 on these clean benchmarks, and compare to the original score. If the score on the clean subset is similar to the score on the entire dataset, this suggests that contamination, even if present, does not have a significant effect on reported results.”

- 图4.2: 基准测试污染分析:
图4.2展示了不同数据集的污染情况以及污染对模型表现的影响。纵轴显示了在清理后的数据集上的表现变化,横轴则是保留的“干净”数据的百分比。结果表明,尽管某些基准测试集的潜在污染率较高,但对大多数数据集的性能变化几乎可以忽略不计。
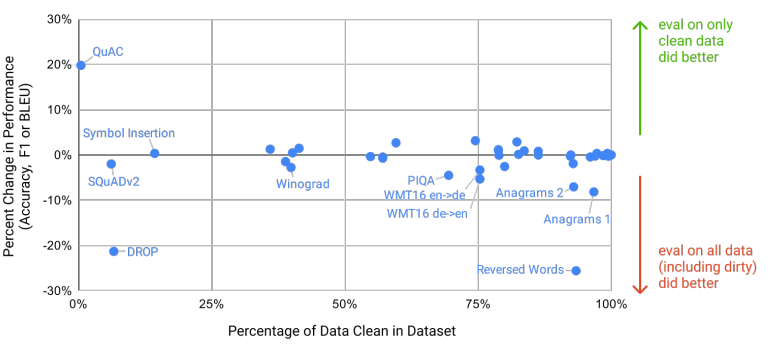
"Performance on most benchmarks changed negligibly, but some were flagged for
further review. On inspection we find some evidence for contamination of the PIQA and Winograd results"
大多数基准测试的性能变化很小,但有些会被标记为进一步审查。
在检查中,我们发现了一些PIQA和Winograd结果被污染的证据。
- 少数例外:
尽管大部分数据集的污染影响较小,但在某些数据集上,模型在“清理数据集”上的表现明显下降,表明可能存在由于数据泄漏导致的结果偏差。例如,PIQA任务中约29%的测试数据被标记为污染,导致模型在清理数据集上的表现下降了3个百分点。
“PIQA: The overlap analysis flagged 29% of examples as contaminated, and observed a 3 percentage point absolute decrease (4% relative decrease) in performance on the clean subset.”
- 总评:
总体来看,GPT-3的表现显示出即便在存在少量数据泄漏的情况下,模型的总体结果仍然保持稳定。然而,作者指出数据泄漏问题仍然是大规模模型和开放网络数据训练的关键挑战之一。未来研究需要开发更为严格的检测和防范机制,以确保模型的泛化能力不受泄漏的影响。
3. 分析与总结
在这一部分,作者系统地分析了GPT-3在数据泄漏问题上的表现,并通过创建清理数据集来衡量泄漏对测试结果的影响。尽管某些任务表现出潜在的污染迹象,但大多数任务的数据泄漏对模型的整体表现影响不大。通过这种细致的分析,作者展示了处理这种大规模模型的复杂挑战,并提出了未来研究可能的改进方向。
Limitations
1. 概括
在 “Limitations” 这一部分,作者讨论了 GPT-3 模型的局限性,主要集中在生成的文本质量、处理常识推理任务的能力、NLP 任务的表现差异、以及模型的结构性和算法性限制。
这些局限性表明,尽管 GPT-3 展现了强大的 few-shot 学习能力,但仍然存在很多需要改进的地方,特别是在长文本生成的连贯性、常识推理、自然语言推理任务的表现等方面。
2. 具体分析
GPT-3 在文本生成中的局限性
虽然 GPT-3 在文本生成任务上表现出色,但在生成长文本时,它仍然会出现重复性、连贯性下降、前后矛盾以及生成无关句子的情况。
特别是对于较长的段落,GPT-3 生成的内容可能会失去连贯性或变得不合逻辑。
原文引用:
"GPT-3 samples still sometimes repeat themselves semantically at the document level, start to lose coherence over sufficiently long passages, contradict themselves, and occasionally contain non-sequitur sentences or paragraphs. "GPT-3样本有时在文档层面上仍然在语义上重复自己,在足够长的段落中开始失去连贯性,相互矛盾,偶尔包含非推论的句子或段落。
常识推理任务的挑战
GPT-3 在涉及常识推理的任务上表现不佳,尤其是在需要对物理常识进行推断的任务中,它往往会生成不符合现实情况的答案。例如,在涉及物理常识的推理问题上,GPT-3 可能会产生明显不正确的答案。即使在特定数据集(如 PIQA 数据集)上表现良好,但总体上 GPT-3 在处理物理常识推理时仍显不足。
原文引用:
"Within the domain of discrete language tasks, we have noticed informally that GPT-3 seems to have special difficulty with “common sense physics”, despite doing well on some datasets (such as PIQA [BZB+19]) that test this domain. Specifically GPT-3 has difficulty with questions of the type “If I put cheese into the fridge, will it melt?”. "在离散语言任务领域,我们非正式地注意到,尽管GPT-3在测试该领域的一些数据集(如PIQA [BZB+19])上做得很好,但它似乎在“常识物理”方面有特殊的困难。
特别是GPT-3很难回答“如果我把奶酪放进冰箱,它会融化吗?”这类问题。
NLP 任务的表现差异
在一些 NLP 任务中,特别是涉及语义比较和推理的任务上,GPT-3 的表现不尽如人意。
例如,GPT-3 在 “Word-in-Context” (WiC) 和 “Adversarial Natural Language Inference” (ANLI) 任务中的表现几乎与随机猜测无异。
在这些需要对比文本或推断语义关系的任务上,GPT-3 的 few-shot 表现非常有限。
原文引用:
“GPT-3’s in-context learning performance has some notable gaps on our suite of benchmarks, as described in Section 3, and in particular it does little better than chance when evaluated one-shot or even few-shot on some “comparison” tasks, such as determining if two words are used the same way in a sentence, or if one sentence implies another (WIC and ANLI respectively),”这段话指出,GPT-3 在 WiC 和 ANLI 任务中,特别是在 one-shot 或 few-shot 设置下,表现接近随机猜测的水平,反映了它在这些需要比较两个句子或推理句子之间关系的任务中的弱点。
结构与算法局限
- 自回归架构的局限性
GPT-3 使用的是自回归语言模型(autoregressive model),这种架构的优势在于它能够方便地进行采样和计算似然性。然而,这种架构相对于双向模型(如 BERT 或使用去噪训练目标的模型)在某些任务上表现较弱,尤其是在需要比较两个段落或重新审视较长文本并生成简短回答的任务中,即需要 对比或回顾内容的任务。
作者提到,GPT-3 的设计决策使其在一些依赖于双向性的任务上表现较差。
原文引用:
“GPT-3 has several structural and algorithmic limitations, which could account for some of the issues above. We focused on exploring in-context learning behavior in autoregressive language models because it is straightforward to both sample and compute likelihoods with this model class. As a result our experiments do not include any bidirectional architectures or other training objectives such as denoising. This is a noticeable difference from much of the recent literature, which has documented improved fine-tuning performance when using these approaches over standard language models [RSR+19].”GPT-3有几个结构和算法限制,这可以解释上面的一些问题。我们专注于探索自回归语言模型中的上下文学习行为,因为使用该模型类进行采样和计算可能性都很简单。因此,我们的实验不包括任何双向架构或其他训练目标,如去噪。这与最近的许多文献有明显的不同,这些文献记录了在标准语言模型上使用这些方法可以提高微调性能[RSR+19]。
"Thus our design decision comes at the cost of potentially worse performance on tasks which empirically benefit from bidirectionality. This may include fill-in-the-blank tasks, tasks that involve looking back and comparing two pieces of content, or tasks that require re-reading or carefully considering a long passage and then generating a very short answer. "
因此,我们的设计决策是以潜在的更糟糕的任务性能为代价的,而这些任务从经验上受益于双向性。这可能包括填空任务,回顾和比较两段内容的任务,或者需要重读或仔细考虑一篇长文章,然后生成一个非常简短的答案的任务。
- 与双向模型的对比
与双向模型相比,GPT-3 在需要比较两个句子、段落或重新审视信息的任务中表现相对较弱,尤其是在 WiC(Word-in-Context)和 ANLI(Adversarial NLI)等任务中,GPT-3 的 few-shot 学习表现并不理想。这种弱点主要是因为 GPT-3 使用自回归结构,缺少了能够同时前后处理信息的能力。
论文原文:
"This could be a possible explanation for GPT-3’s lagging few-shot performance on a few of the tasks, such as WIC (which involves comparing the use of a word in two sentences), ANLI (which involves comparing two sentences to see if one implies the other), and several reading comprehension tasks (e.g. QuAC and RACE). "
这可能是GPT-3在一些任务上表现滞后的一个可能的解释,比如WIC(比较一个词在两个句子中的使用),ANLI(比较两个句子看一个是否暗示另一个),以及一些阅读理解任务(例如QuAC和RACE)。
这说明,GPT-3 在某些需要进行上下文比较和推理的任务上表现不佳,而这与其架构设计有很大关系.
3. 未来改进方向
未来的改进方向包括使用双向模型、基于人类学习的目标进行训练、或通过强化学习进行优化。此外,GPT-3 在预训练阶段消耗了大量的数据和计算资源,这也限制了其在任务效率上的表现。提高预训练效率和结合多模态(如图像和语言)的模型设计是未来研究的关键。
- 使用双向模型和其他架构改进性能
原文引用:
“We also conjecture, based on past literature, that a large bidirectional model would be stronger at fine-tuning than GPT-3. Making a bidirectional model at the scale of GPT-3, and/or trying to make bidirectional models work with few- or zero-shot learning, is a promising direction for future research, and could help achieve the “best of both worlds”.”
我们还推测,基于过去的文献,一个大的双向模型将在微调比GPT-3更强。在GPT-3的规模上制作一个双向模型,或者尝试使双向模型在很少或零学习的情况下工作,是未来研究的一个有希望的方向,并且可以帮助实现“两全其美”。
- 改进预训练目标
目前 GPT-3 的训练目标是基于自监督的预测任务,所有词在预测中被平等对待。论文指出,这种训练目标没有考虑到哪些词在预测任务中更为重要。未来的研究方向之一是引入更加个性化的预测目标,甚至结合多模态的信息(如图像和视频),以增强模型对世界的理解。
论文原文:
Our current objective weights every token equally and lacks a notion of what is most important to predict and what is less important.
我们目前的目标是平等地对每个标记进行加权,并且缺乏预测哪些是最重要的,哪些是不重要的概念。
scaling pure self-supervised prediction is likely to hit limits, and augmentation with a different approach is likely to be necessary. Promising future directions in this vein might include learning the objective function from humans [ZSW+19a], fine-tuning with reinforcement learning, or adding additional modalities such as images to provide grounding and a better model of the world [CLY+19].
扩展纯粹的自我监督预测可能会达到极限,并且可能需要使用不同的方法进行增强。
在这方面有希望的未来方向可能包括从人类那里学习目标函数[ZSW+19a],通过强化学习进行微调,或者添加额外的模式,如图像,以提供基础和更好的世界模型[CLY+19]。
总结来说,GPT-3 尽管在 many-shot 任务上取得了显著的进展,但在长文本生成、常识推理和自然语言推理任务上仍存在明显的局限性。同时,GPT-3 的结构性问题和预训练效率也是需要未来研究解决的方向。
Broader Impacts
更广泛的影响
1. 概括
“Broader Impacts” 部分讨论了 GPT-3 语言模型对社会的 潜在影响,既包括正面影响,也包括潜在的负面风险。
作者探讨了 GPT-3 在生成文本能力提升方面的应用可能,包括代码自动完成、写作辅助、改进搜索引擎等。
但更重要的是,作者详细分析了 GPT-3 可能导致的 滥用行为以及模型的公平性和偏见问题。
此外,还讨论了大规模模型的 能源使用问题。
2. 具体分析
Misuse of Language Models(语言模型的滥用风险)
GPT-3 生成的高质量文本可能会被恶意使用。作者提到了几个潜在的滥用场景,例如虚假信息传播、网络钓鱼、滥用法律和政府流程、欺诈性学术论文写作等。高质量文本生成降低了这些行为的实施难度,增加了其有效性。随着 GPT-3 等模型生成文本质量的提升,滥用的可能性也随之增加。
原文引用:
“Any socially harmful activity that relies on generating text could be augmented by powerful language models. Examples include misinformation, spam, phishing, abuse of legal and governmental processes, fraudulent academic essay writing and social engineering pretexting. Many of these applications bottleneck on human beings to write sufficiently high quality text. Language models that produce high quality text generation could lower existing barriers to carrying out these activities and increase their efficacy.”
任何依赖于生成文本的社会有害活动都可以通过强大的语言模型来增强。例子包括错误信息、垃圾邮件、网络钓鱼、滥用法律和政府程序、欺诈性学术论文写作和社会工程借口。许多这样的应用程序在编写足够高质量的文本时遇到了瓶颈。产生高质量文本生成的语言模型可以降低执行这些活动的现有障碍并提高其效率。
此外,GPT-3 能够生成人类难以区分的长段文本,进一步增加了滥用的风险。
原文引用:
“The misuse potential of language models increases as the quality of text synthesis improves. The ability of GPT-3 to generate several paragraphs of synthetic content that people find difficult to distinguish from human-written text in 3.9.4 represents a concerning milestone in this regard.”
随着文本合成质量的提高,语言模型的误用可能性也在增加。GPT-3能够生成几个段落的合成内容,人们很难将其与3.9.4中的人工文本区分开来,这是这方面的一个重要里程碑。
Threat Actor Analysis(威胁行为者分析)
威胁行为者可以根据技能和资源进行分类,包括低技能、中等资源的个人和高技能、资源充足的高级持续威胁(APT)组织。
虽然在 GPT-2 发布后讨论了这些技术的滥用可能性,但作者指出这些行为并没有大规模发生。然而,未来的改进可能会吸引更多恶意行为者。
Fairness, Bias, and Representation(公平性、偏见与代表性问题)
GPT-3 从互联网上的大量数据中进行训练,因此它不可避免地会反映出数据中的偏见。模型可能生成带有性别、种族、宗教等方面的刻板印象或歧视内容。作者提供了对性别、种族和宗教偏见的初步分析,并指出 GPT-3 的输出常常反映出训练数据中的这些偏见。
Energy Usage(能源使用)
GPT-3 的训练和推理需要消耗大量的计算资源,预训练 GPT-3 175B 参数模型需要几千 PetaFLOP/s-天的计算能力。这种大规模模型的高能耗问题引发了对其效率的关注。未来研究应致力于提高预训练效率以及减少模型的能耗。
3. 总结
在 “Broader Impacts” 部分,作者探讨了 GPT-3 的广泛影响,特别是滥用的可能性、模型偏见和能耗问题。作者呼吁更多的研究来应对这些问题,并希望通过模型的改进来减轻这些潜在风险。
Related Work
相关工作
1. 概括
在"Related Work"这一部分,作者回顾了与他们工作相关的现有研究,主要集中在三个方面:
- 语言模型的扩展研究
- 小规模模型优化
- 标准基准任务的发展
通过回顾与GPT-3模型相关的文献,作者展示了他们的研究如何与现有工作相联系,同时说明了GPT-3相对于前人的进步之处。
2. 具体分析
扩展语言模型的研究
多项研究已经系统地研究了语言模型规模对性能的影响。
研究显示,随着自回归语言模型规模的增加,模型的损失 以幂律趋势平滑下降。
这些研究表明,幂律关系在扩展到更大模型时仍然有效,尽管从某些曲线中可以看出轻微的弯曲。作者同样观察到,在许多任务中,随着模型规模的增加,性能平滑上升。
幂律可以用一个公式来表示:
y = k ⋅ x − α y = k \cdot x^{-\alpha} y=k⋅x−α
● y 和 x 是两个相关联的变量;
● k 是常数;
● α 是幂律的指数,通常为正数。
幂律关系说明随着某个变量(如模型规模 x x x)增加,另一个变量(如模型的损失值 y y y)会以非线性但可预测的方式变化。

原文引用:
“Several efforts have also systematically studied the effect of scale on language model performance. [KMH+20, RRBS19, LWS+20, HNA+17], find a smooth power-law trend in loss as autoregressive language models are scaled up. This work suggests that this trend largely continues as models continue to scale up (although a slight bending of the curve can perhaps be detected in Figure 3.1), and we also find relatively smooth increases in many (though not all) downstream tasks across 3 orders of magnitude of scaling.”
一些研究也系统地研究了尺度对语言模型性能的影响。[KMH+20, RRBS19, LWS+20, HNA+17],发现随着自回归语言模型的放大,损失呈平滑的幂律趋势。
这项工作表明,随着模型继续扩大规模,这种趋势在很大程度上仍在继续(尽管在图3.1中可以检测到曲线的轻微弯曲),我们还发现许多(尽管不是全部)下游任务在3个数量级的规模上相对平稳地增长。
小规模模型的优化
相较于单纯的扩展语言模型的规模,另一方向的研究则是如何在保持强大性能的前提下,尽可能减少模型的参数量。
这类方法包括ALBERT等模型的蒸馏方法以及任务特定的蒸馏技术。
这些技术可以用于减少大模型的延迟和内存占用,与本研究中的大规模GPT-3模型是互补的,未来可以用于进一步优化大模型的使用效率。
原文引用:
“Another line of work goes in the opposite direction from scaling, attempting to preserve strong performance in language models that are as small as possible. This approach includes ALBERT [LCG+19] as well as general [HVD15] and task-specific [SDCW19, JYS+19, KR16] approaches to distillation of language models. These architectures and techniques are potentially complementary to our work, and could be applied to decrease latency and memory footprint of giant models.”
另一项工作与扩展方向相反,试图在尽可能小的语言模型中保持强大的性能。
该方法包括ALBERT [LCG+19]以及通用[HVD15]和特定任务[SDCW19, JYS+19, KR16]方法来蒸馏语言模型。
这些架构和技术对我们的工作是潜在的补充,可以用于减少大型模型的延迟和内存占用。
构建更加困难的基准任务
随着微调后的语言模型在许多基准任务中接近人类的表现,研究人员开始致力于设计更困难或更开放式的任务。这些任务包括更复杂的问题回答、阅读理解以及一些专门针对语言模型弱点构建的对抗性数据集。作者在他们的研究中测试了GPT-3在这些基准任务上的表现。
原文引用:
“As fine-tuned language models have neared human performance on many standard benchmark tasks, considerable effort has been devoted to constructing more difficult or open-ended tasks, including question answering [KPR+19, IBGC+14, CCE+18, MCKS18], reading comprehension [CHI+18, RCM19], and adversarially constructed datasets designed to be difficult for existing language models [SBBC19, NWD+19]. In this work we test our models on many of these datasets.”
由于精细的语言模型在许多标准基准任务上的表现接近人类,因此人们投入了大量精力来构建更困难或开放式的任务,包括问答[KPR+19, IBGC+14, CCE+18, MCKS18],阅读理解[CHI+18, RCM19],以及设计为现有语言模型难以构建的对抗性构建数据集[SBBC19, NWD+19]。在这项工作中,我们在许多这些数据集上测试了我们的模型。
3. 小结
在"Related Work"部分,作者探讨了语言模型扩展的趋势,指出了随着模型规模的增加性能的提升。与之形成对比的是,研究者也在探索如何在较小的模型中实现强大的性能,同时构建了更具挑战性的基准任务来测试模型的鲁棒性。这些工作为GPT-3的研究奠定了基础,同时也展示了GPT-3相对于前人的进步。
Conclusion
1. 概括
在 “Conclusion”(结论)部分,作者总结了他们在研究中所取得的成果,提出了他们的 1750 亿参数语言模型(GPT-3)的显著表现,并指出 GPT-3 在多个 NLP 任务和基准测试中的出色性能,尤其是在零样本、单样本和小样本学习环境下。
尽管 GPT-3 存在一定的局限性和弱点,但研究结果表明,超大规模语言模型可能是未来开发具有更强适应性、广泛应用的通用语言系统的关键因素。
2. 具体分析
GPT-3 的性能总结
在结论部分,作者强调 GPT-3 是一个拥有 1750 亿参数的语言模型,展示了其在许多 NLP 任务和基准测试中的强劲表现。
GPT-3 不仅在零样本、单样本和小样本学习环境下表现良好,甚至在某些情况下接近或超过了现有的最先进的微调系统。
此外,GPT-3 在很多即席定义的任务中也能够生成高质量的样本并表现出较强的定性性能。
原文引用:
“We presented a 175 billion parameter language model which shows strong performance on many NLP tasks and benchmarks in the zero-shot, one-shot, and few-shot settings, in some cases nearly matching the performance of state-of-the-art fine-tuned systems, as well as generating high-quality samples and strong qualitative performance at tasks defined on-the-fly.”
模型扩展的可预测趋势
通过对模型扩展的详细分析,作者记录了在不进行微调的情况下,GPT-3 的性能与规模呈现出可预测的趋势。随着模型的扩展,其在多个下游任务中的表现得到了显著的提升。这一观察表明,GPT-3 的扩展规律不仅可以预测,还可能对进一步开发具有通用适应能力的语言系统至关重要。
原文引用:
“We documented roughly predictable trends of scaling in performance without using fine-tuning.”
社会影响讨论
尽管 GPT-3 表现出色,作者也意识到这种大规模语言模型的潜在社会影响。特别是这些模型带来的伦理和公平性问题,可能会对社会产生深远的影响。这些潜在的负面影响与模型的滥用、偏见以及资源消耗有关。
原文引用:
“We also discussed the social impacts of this class of model.”
局限性与未来展望
尽管 GPT-3 取得了令人印象深刻的成果,作者也指出了模型存在的许多局限性和不足。例如,GPT-3 在某些任务中仍然表现欠佳,尤其是需要细粒度推理和常识推理的任务。尽管如此,作者认为,这种超大规模的语言模型可能是开发具有适应性、通用性语言系统的重要组成部分。
原文引用:
“Despite many limitations and weaknesses, these results suggest that very large language models may be an important ingredient in the development of adaptable, general language systems.”
3. 小结
在 “Conclusion” 部分,作者总结了 GPT-3 的优异表现,强调了模型扩展对性能提升的可预测性以及它在多个任务上的适应性。同时,尽管模型仍然存在局限性,但其潜力让作者相信,超大规模语言模型可能是构建更通用语言系统的关键路径。
Contributions
1. 概括
在“Contributions”部分,作者详细列举了每位团队成员在项目中的具体贡献。整体工作主要分为模型开发、数据准备、任务实现与实验、预训练实验和研究指导等几个方面。通过展示不同研究人员的贡献,明确了整个 GPT-3 项目是如何通过多方协作完成的。
2. 具体分析
模型实现与训练基础设施
Tom Brown, Ben Mann, Prafulla Dhariwal, Dario Amodei, Nick Ryder, Daniel M Ziegler 和 Jeffrey Wu 实现了大规模模型、训练基础设施和模型并行策略。这表明,他们负责了 GPT-3 的核心基础设施,确保了如此大规模模型的训练可行。
原文引用:
“Tom Brown, Ben Mann, Prafulla Dhariwal, Dario Amodei, Nick Ryder, Daniel M Ziegler, and Jeffrey Wu implemented the large-scale models, training infrastructure, and model-parallel strategies.”
预训练实验
Tom Brown, Dario Amodei, Ben Mann 和 Nick Ryder 负责了 GPT-3 的预训练实验,他们的工作确保了模型在大规模数据集上的有效训练。
原文引用:
“Tom Brown, Dario Amodei, Ben Mann, and Nick Ryder conducted pre-training experiments.”
数据准备
Ben Mann 和 Alec Radford 负责了 GPT-3 的数据集的收集、过滤和去重工作,并进行了重叠分析,确保训练数据集的质量和多样性。
原文引用:
“Ben Mann and Alec Radford collected, filtered, deduplicated, and conducted overlap analysis on the training data.”
下游任务的实现
Melanie Subbiah, Ben Mann, Dario Amodei, Jared Kaplan, Sam McCandlish, Tom Brown, Tom Henighan 和 Girish Sastry 实现了下游任务和用于支持它们的软件框架,包括创建合成任务。这些下游任务是评估 GPT-3 性能的重要部分,确保了它在各种任务中的表现。
原文引用:
“Melanie Subbiah, Ben Mann, Dario Amodei, Jared Kaplan, Sam McCandlish, Tom Brown, Tom Henighan, and Girish Sastry implemented the downstream tasks and the software framework for supporting them, including creation of synthetic tasks.”
缩放定律与模型规模预测
Jared Kaplan 和 Sam McCandlish 首先预测了超大规模语言模型应该会继续提高性能,并应用缩放定律来预测和指导模型和数据的扩展决策。
原文引用:
“Jared Kaplan and Sam McCandlish initially predicted that a giant language model should show continued gains, and applied scaling laws to help predict and guide model and data scaling decisions for the research.”
3. 总结
在"Contributions"部分,作者清晰地展示了整个研究团队的贡献,涵盖了从模型开发到数据准备,再到实验分析的每个重要环节。通过详细列举各自的工作,作者展现了GPT-3项目的多维合作,使得这一超大规模模型的训练与评估成为可能。
end:三代GPT对比
文末附上关于GPT、GPT2、GPT3的简单对比分析。
这三篇论文分别介绍了OpenAI开发的不同版本的生成预训练模型(GPT、GPT-2 和 GPT-3)。以下是这三个版本之间的主要区别
各方面对比
1. GPT(Generative Pre-Training)
- 论文: Improving Language Understanding by Generative Pre-Training
- 模型架构: 基于Transformer的语言模型。
- 训练方法: 采用无监督的预训练方法,使用大规模的未标注文本数据对模型进行预训练,然后通过有监督的微调来适应特定的NLP任务。
- 创新点: 提出了通过无监督预训练和有监督微调相结合的方法来提升自然语言理解任务的表现。该方法在多个NLP任务中实现了显著的性能提升,并且展示了较好的迁移学习能力。
- 模型规模: GPT使用的是一个12层的Transformer模型,模型规模较小。
2. GPT-2
- 论文: Language Models are Unsupervised Multitask Learners
- 模型架构: 与GPT类似,GPT-2也基于Transformer架构,但它是一个更大的版本。
- 训练方法: 同样使用无监督预训练,GPT-2可以通过大量的未标注文本来学习多种任务,显示出强大的零样本和小样本学习能力。
- 创新点: GPT-2的主要改进在于模型的规模显著扩大,并且展示了更强的生成能力和任务泛化能力,甚至能够在没有明确训练目标的情况下完成复杂的语言任务。
- 模型规模: GPT-2包含了1.5亿到15亿的参数,远超GPT的规模,这使得它能够在更广泛的任务上表现优异。
3. GPT-3
- 论文: Language Models are Few-Shot Learners
- 模型架构: 依然基于Transformer架构,但GPT-3是目前为止规模最大的模型。
- 训练方法: GPT-3的训练方法与GPT-2类似,但它能够在极少量的示例(few-shot learning)下执行新任务,表现出卓越的零样本和小样本学习能力。
- 创新点: GPT-3的主要创新在于其规模巨大,参数数量达到了1750亿,使其能够以极少的任务示例进行任务适应。此外,GPT-3能够执行更复杂的推理任务,并且在多任务学习中表现优异,进一步减少了任务特定调整的需要。
- 模型规模: GPT-3显著扩展了参数规模,达到了1750亿个参数,这使得它成为当时规模最大的语言模型,展示了前所未有的语言生成和理解能力。
总结与对比
- 模型规模: GPT < GPT-2 < GPT-3。每个版本的模型规模都显著扩大,参数数量从最初的数亿扩展到数千亿。
- 能力提升: 随着模型规模的增加,GPT-2和GPT-3在零样本学习、小样本学习、多任务学习以及生成文本的质量和连贯性方面都有显著提升。
- 应用场景: GPT主要用于自然语言理解任务的改进,而GPT-2和GPT-3由于其增强的生成能力,被广泛应用于更多复杂的NLP任务,包括自动写作、对话系统等。
每个版本的GPT模型在前一代的基础上进行了规模和能力上的扩展,使得这些模型在处理自然语言任务时表现出更强的泛化能力和更高的任务性能。
三代GPT的数据集
1. 《Language Models are Few-Shot Learners》
- 使用的数据集:
- Common Crawl(4100亿个标记,占训练数据的60%)
- WebText2(190亿个标记,占22%)
- Books1(120亿个标记,占8%)
- Books2(550亿个标记,占8%)
- Wikipedia(30亿个标记,占3%)
论文原文描述:
“We used the following datasets to train our models: a version of the Common Crawl dataset that was filtered to improve quality, which we refer to as CC, WebText2, Books1, Books2, and Wikipedia.”
数据集的使用方式: 这些数据集被混合使用,但并不是按大小的比例进行采样。质量较高的数据集被更频繁地采样,以提高训练效率。例如,Common Crawl 和 Books2 的采样频率较低,而 Wikipedia 则被多次采样。
论文原文描述:
“The datasets are not sampled in proportion to their size, with higher-quality datasets being sampled more frequently, and lower-quality datasets less frequently.”
数据污染问题: 论文也提到了可能存在数据污染的风险。 由于模型在网络数据上大规模训练,存在训练数据和测试数据重叠的风险,因此模型可能在训练过程中接触到测试数据。
论文原文描述:
“Since the training data is collected from a wide variety of sources, including publicly available internet corpora, there is some risk of contamination, where the model has seen the test set during training.”
2. 《Language Models are Unsupervised Multitask Learners》
- 使用的数据集:
- WebText:该数据集是从 Reddit 链接的网页中收集的,筛选出至少有3个赞的页面。最终得到4500万个链接,并过滤成约800万个文档(约40 GB 文本)。
- 其他数据集:PTB、WikiText-2、WikiText103、enwik8、text8(用于评估)。
论文原文描述:
“We train on the WebText dataset, which we created by scraping web pages that were linked to from Reddit posts with a score of at least 3. This resulted in a dataset of over 8 million documents.”
数据集的使用方式: 模型在 WebText 上进行无监督训练,并在多个任务上评估模型的零样本性能。WebText 是经过严格过滤的数据集,删除了重复内容和像 Wikipedia 这样的来源,以确保数据集的质量。WebText 用于训练,其他数据集则用于测试模型的泛化能力和零样本表现。
论文原文描述:
“We evaluate our model’s zero-shot performance on a wide range of datasets, including PTB, WikiText-2, WikiText103, enwik8, and text8.”
3. 《Improving Language Understanding by Generative Pre-Training》
- 使用的数据集:
- BooksCorpus:包含7000多本未发表的书籍,来自不同类型,如冒险、幻想和浪漫小说。这些书籍的长文本段落使其适合用于预训练。
- 监督数据集(用于特定任务的微调):SNLI、MultiNLI、RACE、Quora 问题对等。这些数据集用于将预训练的模型微调到具体任务,如自然语言推理、问答和文本分类。
论文原文描述:
“We use the BooksCorpus dataset for training the language model. It contains over 7,000 unique unpublished books from a variety of genres including Adventure, Fantasy, and Romance.”
监督微调使用了 SNLI、MultiNLI、RACE、Quora 问题对等数据集。
论文原文描述:
“We fine-tune our model on various supervised datasets such as SNLI, MultiNLI, and RACE to adapt it to specific tasks like natural language inference and question answering.”
数据集的使用方式: 论文详细描述了无监督预训练与监督微调的结合使用方式,首先在无标注的文本数据上预训练,然后在标注数据上进行微调以适应特定任务。
论文原文描述:
“Our training procedure consists of two stages. The first stage is learning a high-capacity language model on a large corpus of text. This is followed by a fine-tuning stage, where we adapt the model to a discriminative task with labeled data.”