一 前言
相比xml.dom.minidom,lxml.etree具有高效的查找方法,更方便,直接;
二、知识点:查找感兴趣的元素
举例一:递归遍历其下的所有子树(包括子级,子级的子级,等等
import lxml.etree as LET
tree = LET.parse('country_data.xml')
root = tree.getroot()
for neighbor in root.iter('neighbor'):
... print(neighbor.attrib)
举例二:
#关键点:
# xpath() 通过使用xpath,可以更精确地指定要查找的元素。
#rank.getparent() 可跳转到父节点查找
#find() 在当前节点查找
"""
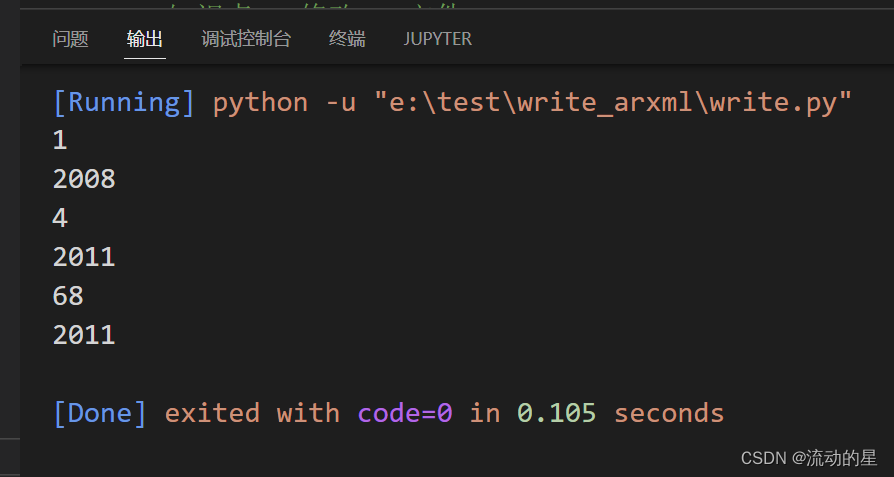
for rank in root.xpath('country/rank'):
print(rank.text)
text = rank.getparent().find('year').text
print(text)
"""
三、查找结果
四、测试用xml--country_data.xml
<?xml version='1.0' encoding='UTF-8'?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>