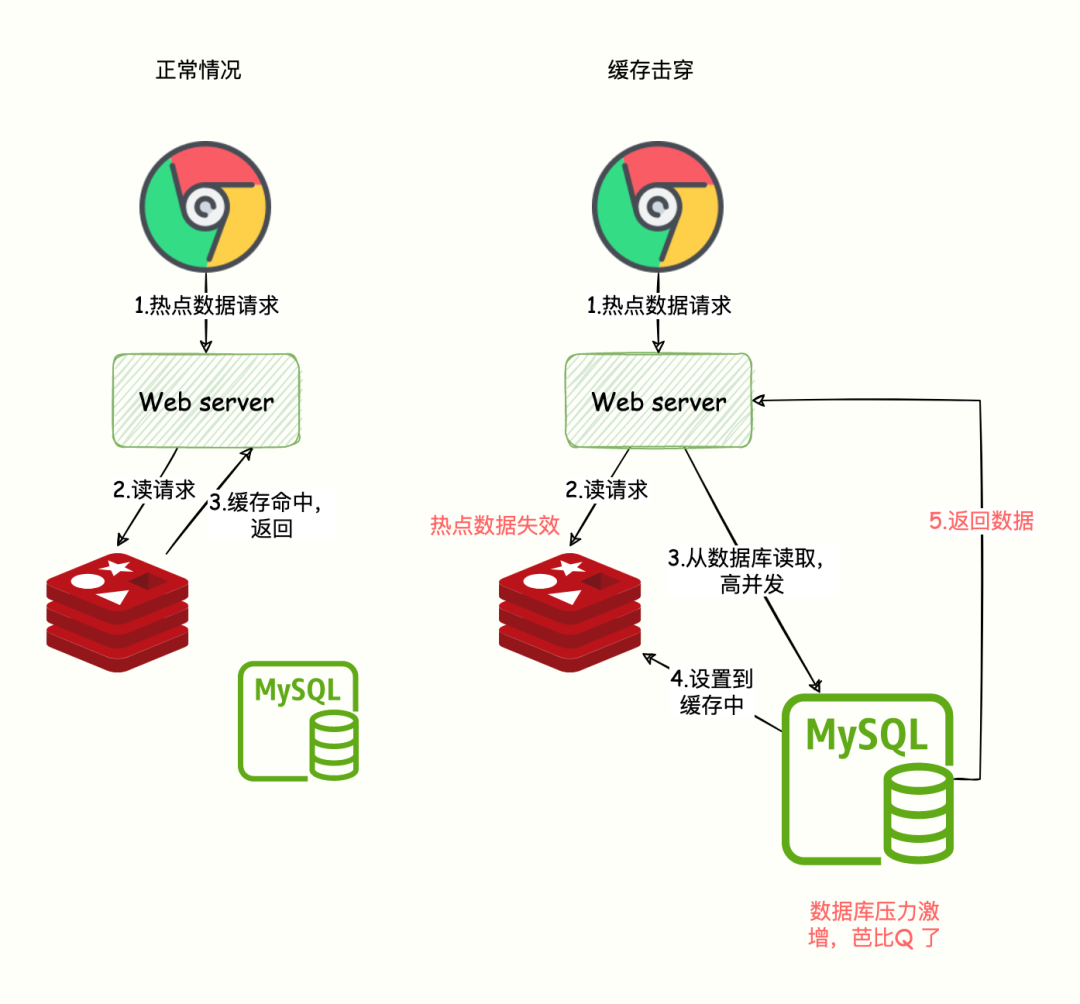
一、缓存穿透(失效)问题
缓存穿透是指查询一个一定不存在的数据,由于缓存中没有命中,会去数据库中查询,而数据库中也没有该数据,并且每次查询都不会命中缓存,从而每次请求都直接打到了数据库上,这会给数据库带来巨大压力。
二、布隆过滤器原理
布隆过滤器(Bloom Filter)是一种空间效率很高的随机数据结构,它利用多个不同的哈希函数将一个元素映射到一个位数组中的多个位置,并将这些位置的值置为 1。
当查询一个元素时,同样使用这些哈希函数计算出多个位置,如果这些位置上的值都为 1,那么这个元素可能存在;如果有任何一个位置上的值为 0,那么这个元素一定不存在。
布隆过滤器存在一定的误判概率,即可能会把不存在的元素判断为存在,但不会把存在的元素判断为不存在。
三、使用 Redis 中的布隆过滤器解决缓存穿透问题的代码
- 引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.21.1</version>
</dependency>
- 代码实现
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
public class BloomFilterCache {
private final RedissonClient redissonClient;
private final RBloomFilter<String> bloomFilter;
public BloomFilterCache() {
redissonClient = Redisson.create();
// 创建布隆过滤器,预计插入 10000 个元素,误判率为 0.01
bloomFilter = redissonClient.getBloomFilter("myBloomFilter");
bloomFilter.tryInit(10000, 0.01);
}
public boolean mightContain(String key) {
return bloomFilter.contains(key);
}
public void add(String key) {
bloomFilter.add(key);
}
public void close() {
redissonClient.shutdown();
}
public static void main(String[] args) {
BloomFilterCache bloomFilterCache = new BloomFilterCache();
// 添加一些可能存在的键
bloomFilterCache.add("key1");
bloomFilterCache.add("key2");
// 查询键是否可能存在
System.out.println(bloomFilterCache.mightContain("key1")); // true
System.out.println(bloomFilterCache.mightContain("key3")); // false
bloomFilterCache.close();
}
}
在上述代码中,首先创建了一个 Redisson 客户端,并初始化了一个布隆过滤器。mightContain方法用于判断一个键是否可能存在于布隆过滤器中,add方法用于向布隆过滤器中添加一个键。
使用布隆过滤器可以在缓存之前进行快速判断,减少对数据库的不必要查询,从而有效地解决缓存穿透问题。
获取到缓存失效后改怎么处理?
- 返回异常信息,业务流程往下走
- 记录对应的日志信息
- 异步缓存key到redis
- 当使用布隆过滤器判断某个 key 不存在时,触发一个异步任务。
- 异步任务从可能的数据来源(如数据库、外部 API 等)获取该 key 对应的数据。
- 如果获取到数据,将其存入缓存(Redis 或其他缓存系统),以便下次查询时能够快速响应。

![[环境配置]ubuntu20.04安装后wifi有图标但是搜不到热点解决方法](https://i-blog.csdnimg.cn/blog_migrate/c40e82403b25f0299fe82b03f60cabcb.png)