推荐参考:李沐的B站视频《GPT,GPT-2,GPT-3 论文精读》https://www.bilibili.com/video/BV1AF411b7xQ
一点记忆:
-
GPT1参数量:大概1亿参数
- 12层decoder(维度768,12个注意力头)
-
训练集:7000本书籍(8亿个单词)
文章目录
- 1 总结
- 1.1 GPT 1 想干什么?怎么干的?
- 1.2 为什么GPT1只使用transformer中的解码器,而不用编码器?
- 1. **自回归语言模型的需求**(最重要,权重:0.5)
- 2. **生成式任务的本质**(权重:0.3)
- 3. **减少复杂度和计算成本**(权重:0.2)
- 总结:
- 1.3 GPT1的模型结构图,以及如何应对不同的NLP任务数据输入的?
- 模型架构:
- 输入数据的编码:
- 任务特定的输入处理:
- 总结
- 1.4 GPT1模型超参数设置、训练技巧、具体效果
- 1. 实验设置(Setup)
- 2. 监督微调(Supervised Fine-tuning)
- 3. 主要实验结果
- 2 部分专业术语的解释
- 1. **无监督预训练(Unsupervised Pre-training)**
- 2. **有监督微调(Supervised Fine-tuning)**
- 3. **生成式预训练模型(Generative Pre-Training Model, GPT)**
- 4. **Transformer**
- 5. **自注意力机制(Self-Attention Mechanism)**
- 6. **掩码自注意力机制(Masked Self-Attention)**
- 7. **语言模型(Language Model, LM)**
- 8. **文本嵌入(Text Embedding)**
- 9. **位置嵌入(Position Embedding)**
- 10. **线性层(Linear Layer)**
- 11. **微调(Fine-tuning)**
- 3 原论文各章节概述
- 1. **研究背景与动机**
- 2. **方法论**
- 3. **模型架构**
- 4. **实验与结果**
- 5. **分析**
- 6. **结论**
1 总结
1.1 GPT 1 想干什么?怎么干的?
背景:在自然语言处理领域,带标注的数据较为稀缺,而无标注的数据则非常庞大。
目的:作者希望利用大量无标注的文本数据,通过无监督训练生成一个预训练模型,随后该模型可以通过少量的标注数据进行微调,从而在多种自然语言处理任务(如文本分类、问答、推理、相似度检测等)中表现出色。
方法:
- 先使用大规模未标注的文本语料库,对Transformer模型的【解码器部分】进行无监督训练,使其学会捕捉上下文和语言结构的深层语义信息。【备注:之所以能进行无监督训练,是因为transformer的解码器是个生成器,你可以训练它根据前面的单词来一个个预测后面的单词,这种数据不需要标注】
- 然后,将预训练的模型在特定任务的有标注数据上进行微调,通过少量的有监督样本调整模型参数,以适应具体的下游任务需求。
效果:
- 该预训练模型在多个自然语言处理任务上表现优异,超越了当时的最优方法,并展现了强大的迁移学习和泛化能力。模型在9个任务中刷新了SOTA(最先进技术)的结果。
1.2 为什么GPT1只使用transformer中的解码器,而不用编码器?
1. 自回归语言模型的需求(最重要,权重:0.5)
- 语言模型的任务是根据已有的词预测下一个词,这是一种自回归任务。也就是说,模型在生成下一个词时,只能依赖之前生成的词,而不能看到未来的词。
- 解码器部分的特点是它可以通过**掩码自注意力机制(Masked Self-Attention)**来实现这种自回归过程。掩码确保模型在预测当前词时,只能看到当前词之前的上下文,而不能看到未来的词。这非常适合生成语言模型任务。
- 编码器部分则设计用于处理双向上下文,它可以同时看到句子中的所有词(包括当前词之前和之后的词),这更适合于需要全局上下文的任务(如文本分类或句子嵌入),而不是语言生成任务。
2. 生成式任务的本质(权重:0.3)
- 预训练模型的主要任务是生成语言,即给定一部分文本生成下一个词,这是典型的生成式任务。
- Transformer解码器天然适合生成任务,因为它可以逐步生成词并动态调整注意力机制,使得生成的词能够很好地适应上下文。
- 使用完整的Transformer结构(即同时包含编码器和解码器)并不适用于这个生成任务,因为编码器用于处理输入序列的全局表示,而解码器负责逐步生成输出。因此,直接使用解码器更简洁高效。
3. 减少复杂度和计算成本(权重:0.2)
- 完整的Transformer结构包含编码器和解码器两部分,虽然在一些任务中(如机器翻译)它们协同工作,但对于单一的生成任务来说,只使用解码器部分可以减少模型的复杂性和计算成本。
- 使用解码器模型已经能够有效处理语言生成任务,而加入编码器可能带来额外的计算负担,并且在这个生成任务中并不必要。
总结:
- 核心原因是:解码器的自回归特性非常适合语言模型的生成任务,可以逐词预测下一个词,而编码器并不适合这种任务。
- 使用完整的Transformer结构反而会引入不必要的复杂度,增加计算成本,且对语言生成任务没有明显的性能提升。
因此,选择解码器部分是一种更加合理且高效的设计。
1.3 GPT1的模型结构图,以及如何应对不同的NLP任务数据输入的?

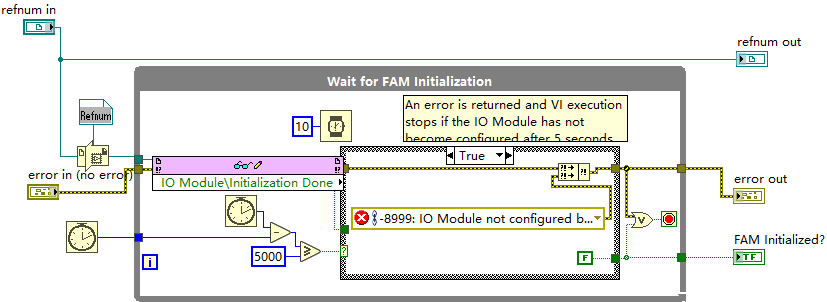
备注:上图右边黄色的linear层,是相对于左边transformer结构新增的,目的是为了能在不同的NLP任务中进行应用。
模型架构:
左侧是Transformer的结构,它由12层堆叠的解码器块组成。每个解码器块包含以下组件:
- Masked Multi Self-Attention(掩码自注意力机制):它负责捕捉输入序列中词与词之间的依赖关系。由于语言模型是自回归的,掩码机制确保模型只能看到之前的词,不能看到未来的词。
- Layer Norm(层归一化):用于对每一层的输出进行标准化,帮助模型更好地训练和收敛。
- Feed Forward(前馈神经网络):在每一层中用来进一步处理和调整特征表示。
右侧则展示了模型在不同任务中的输入处理流程和如何应用预训练模型。
输入数据的编码:
输入数据首先通过Text & Position Embedding模块进行编码。该模块包含两个部分:
- 文本嵌入(Text Embedding):将每个输入词映射到一个向量表示,捕捉词的语义信息。
- 位置嵌入(Position Embedding):由于Transformer模型没有像RNN那样的顺序感,位置嵌入用于向模型提供词在句子中的相对位置信息,帮助模型理解词之间的顺序关系。
这些经过编码的输入数据会送入Transformer解码器进行进一步的处理。因此,图中的输入数据已经过嵌入层的编码,然后在不同任务下通过变换结构输入到模型中。
任务特定的输入处理:
右侧展示了模型在不同任务上的输入如何变换为Token序列,供预训练的模型处理。
- 文本分类任务(Classification):
-
输入包括起始标记(Start)、文本内容(Text)和结束标记(Extract)。
-
这些输入直接进入预训练的Transformer模型,然后通过线性层进行分类预测。
-
文本蕴含任务(Entailment):
- 输入由前提句(Premise)和假设句(Hypothesis)组成,二者中间通过一个分隔符(Delim)分隔,代表两个句子的逻辑关系。
- 该输入经过Transformer处理,最后通过线性层来进行推理判断。
-
语义相似性任务(Similarity):
- 输入是两个文本(Text 1和Text 2),中间通过分隔符分隔。
- 模型会分别处理两种文本顺序(Text 1在前,Text 2在后,和Text 2在前,Text 1在后)【因为文本顺序调换计算结果不一样,但是顺序调换不能影响相似度结果,所以一起累加一下进行训练和应用 】,最后将两次的输出逐元素相加,再通过线性层计算相似性。
-
多项选择任务(Multiple Choice):
- 输入包括上下文(Context)和多个答案(Answer 1、Answer 2、Answer N),每个答案都与上下文拼接并通过分隔符隔开。
- 每个上下文-答案对独立进入Transformer模型处理,最后通过线性层和softmax层选择最可能的正确答案。
总结
图中展示的Transformer模型架构和输入变换策略,旨在说明如何通过最少的架构调整,使预训练的模型适应不同的任务。每个任务的输入都被转换成一个连贯的Token序列,然后通过Transformer和线性分类层进行预测。
1.4 GPT1模型超参数设置、训练技巧、具体效果
在论文的4 Experiments章节中,作者详细描述了实验的设置、训练方法以及各类任务上的表现。
1. 实验设置(Setup)
- 无监督预训练:为了训练语言模型,作者使用了BooksCorpus数据集。该数据集包含7000多本不同类型的未出版书籍,涉及冒险、奇幻、浪漫等不同的主题。该数据集的长文本连续性特点使得模型能够学习到长距离的上下文信息。相比之下,像1B Word Benchmark等数据集由于打乱了句子的顺序,丧失了长距离的依赖结构。因此,BooksCorpus更适合训练生成语言模型。
- 模型结构:使用12层的解码器仅有的Transformer结构,每层有768维的隐藏状态和12个注意力头。前馈网络的内层维度为3072。模型使用Adam优化器进行训练,最大学习率为2.5e-4,前2000步线性上升,然后使用余弦调度器将学习率逐步衰减。模型训练了100个epoch,每次使用随机采样的64个512-token的连续序列作为mini-batch。为正则化目的,使用了0.1的dropout率,并且在非偏置权重上加了L2正则化。
- 微调细节:在微调阶段,大部分超参数沿用无监督预训练阶段的设置,但在分类器中加入了0.1的dropout。大多数任务中,学习率设定为6.25e-5,batch size为32。模型通常只需要3个epoch的微调训练即可达到理想效果。
2. 监督微调(Supervised Fine-tuning)
作者在多种监督任务上进行了微调实验,包括自然语言推理(NLI)、问答、语义相似性检测、文本分类等任务。这些任务中的一些来自GLUE多任务基准测试平台。具体任务的概述如下:
- 自然语言推理:NLI任务要求模型读取两个句子并判断它们之间的逻辑关系(蕴含、矛盾或中立)。作者在五个不同的数据集上进行了测试,包括SNLI、MultiNLI、SciTail、QNLI等。实验结果表明,预训练的模型在大多数数据集上优于现有的SOTA模型。
- 问答任务:在问答任务中,模型需要根据给定的上下文回答问题,作者使用了RACE数据集和Story Cloze Test进行测试,RACE数据集包含来自初高中英语考试的段落和问题,模型在这类推理任务中表现优异,超越了之前的SOTA。
- 语义相似性:模型需要判断两个句子是否表达了相同的语义。作者在MSR Paraphrase Corpus、Quora Question Pairs和STS Benchmark等数据集上进行了测试,模型在大多数任务中都刷新了SOTA。
- 文本分类:使用了CoLA和SST-2两个数据集进行分类任务评估。CoLA用于判断句子是否符合语言学规则,SST-2用于二分类情感分析。模型在这两个任务上表现出色,尤其是在CoLA任务上显著超越了之前的最好结果。
3. 主要实验结果
- 预训练的Transformer模型在多个自然语言任务上显著超越了当时的SOTA,在9个任务上取得了最优成绩。
- 自然语言推理:在MNLI、SciTail、QNLI等数据集上,模型比现有方法最高提高了5%。
- 问答任务:在RACE和Story Cloze Test任务上,分别有5.7%和8.9%的提升。
- 语义相似性和文本分类:模型在STS-B上有1%的提升,在SST-2上获得91.3%的准确率。
总之,4 Experiments章节展示了通过生成预训练的Transformer模型能够很好地适应多个任务,展现出强大的迁移学习能力和优异的任务表现。
2 部分专业术语的解释
以下是论文中出现的一些核心专业术语及其通俗解释:
1. 无监督预训练(Unsupervised Pre-training)
- 专业解释:使用未标注的数据来训练模型,不依赖于标注的任务标签。预训练阶段,模型通过预测词语来学习语言的语法和语义结构。
- 通俗解释:给模型大量的文本,让它自己学习语言规律,比如如何根据前面的词猜测下一个词,而不需要告诉它具体的任务目标。
2. 有监督微调(Supervised Fine-tuning)
- 专业解释:在预训练完成后,使用有标注的任务数据对模型进行调整,使其适应具体的下游任务。
- 通俗解释:在模型已经学会了基本语言规则之后,给它一些带有正确答案的数据,帮助它针对具体问题(如分类或问答)变得更聪明。
3. 生成式预训练模型(Generative Pre-Training Model, GPT)
- 专业解释:一种通过生成式任务(如语言建模)进行预训练的模型,旨在让模型通过上下文预测下一个词,学习语言表示。
- 通俗解释:一个通过大量文本训练出来的模型,能够根据前面的内容生成合理的下一个词,就像接龙一样。
4. Transformer
- 专业解释:一种基于自注意力机制的神经网络架构,擅长处理序列数据,尤其在自然语言处理任务中表现出色。它由编码器和解码器组成,或仅使用其中一部分。
- 通俗解释:一种非常聪明的模型架构,可以很好地理解句子中词语之间的关系,并且能处理很长的文本。
5. 自注意力机制(Self-Attention Mechanism)
- 专业解释:一种计算方法,允许模型根据序列中的每个词与其他词的关联,自动决定哪个词在当前任务中最重要。
- 通俗解释:一种让模型“自己注意”句子中哪些词最相关的机制,帮助它理解词语之间的关系。
6. 掩码自注意力机制(Masked Self-Attention)
- 专业解释:在生成任务中,模型只能看到当前词前面的词,而不能看到未来的词。掩码用于隐藏未来的词,防止模型泄露信息。
- 通俗解释:模型在猜下一个词时,只能根据前面的词来猜,不能偷看后面的词。
7. 语言模型(Language Model, LM)
- 专业解释:一种通过预测文本序列中下一个词或字符来建模语言结构的模型。
- 通俗解释:让模型通过前面的词猜测接下来会是什么词,帮助它学习语言的规律。
8. 文本嵌入(Text Embedding)
- 专业解释:将文本中的词或句子转换为固定长度的向量,使得模型能够理解和处理文本中的语义信息。
- 通俗解释:把每个词变成一个可以让模型理解的“数字编码”,这个编码包含词的意思。
9. 位置嵌入(Position Embedding)
- 专业解释:在Transformer模型中,词的顺序信息是通过位置嵌入来引入的,使模型能够感知序列中的词语位置。
- 通俗解释:在模型中加入“位置信息”,让它知道每个词在句子中的具体顺序。
10. 线性层(Linear Layer)
- 专业解释:一种简单的神经网络层,将输入进行线性变换(如加权求和),通常用于最后的输出阶段。
- 通俗解释:模型处理完信息后,用这层做个简单的计算,最终得到预测结果。
11. 微调(Fine-tuning)
- 专业解释:对一个已经训练过的模型进行小范围的调整,以适应新的任务或数据。
- 通俗解释:模型已经学会了基础知识,接下来给它一些特定任务的训练数据,再做些小调整,让它在具体任务上表现更好。
3 原论文各章节概述
这篇文章题为《Improving Language Understanding by Generative Pre-Training》,由OpenAI的Alec Radford、Karthik Narasimhan、Tim Salimans和Ilya Sutskever撰写,介绍了一种通过生成预训练(Generative Pre-Training, GPT)提高自然语言理解的半监督学习方法。以下是文章的详细介绍:
1. 研究背景与动机
- 问题背景:自然语言理解任务(如文本蕴含、问答、语义相似性评估和文档分类)需要大量的标注数据。然而,标注数据相对稀缺,尤其是在特定任务中,这使得依赖监督学习的模型表现不理想。而未标注的大规模文本数据相对丰富,因此开发一种可以充分利用未标注数据进行预训练的模型成为一项重要任务。
- 动机:通过生成模型预训练,模型可以从未标注数据中学习广泛的语言特征,并通过少量的有监督数据进行微调,能够显著提高模型在各种自然语言理解任务中的表现。
2. 方法论
这篇论文提出了一种两阶段的训练框架,包括无监督预训练和有监督微调。
- 无监督预训练:使用一个大规模未标注的文本语料库,通过语言建模任务对模型进行预训练。模型目标是预测给定上下文中下一个词的概率。具体做法是使用Transformer模型(自注意力机制),通过连续的文本序列学习语言的长程依赖关系。预训练后的模型可以捕捉到文本的丰富语义信息。
- 有监督微调:在预训练的基础上,针对特定的下游任务(如文本分类、问答等)进行有监督微调。通过任务相关的标注数据集,调整预训练模型的参数,以优化任务的具体目标。模型在微调时会在结构化输入上进行一些转换,使得Transformer可以处理不同任务中的输入形式。
任务输入转换:
- 文本蕴含:将前提和假设拼接为一个连续的token序列,并通过Transformer进行处理。
- 问答:将文档、问题和答案拼接为一个序列,每个序列通过模型独立处理,并通过softmax层选择最优答案。
- 语义相似性:处理两个句子的不同顺序,获得两个句子表征后再进行逐元素加和。
3. 模型架构
文章使用了基于Transformer的架构。该架构具有多头自注意力机制,能够处理文本中的长程依赖问题。Transformer模型较传统的RNN和LSTM等网络在语言理解任务上有显著优势,尤其是长文本处理能力更强。
- 模型参数:该模型包含12层的Transformer解码器,每层有768维的隐藏状态和12个注意力头,内部的前馈网络有3072个维度。
- 优化策略:使用Adam优化器,学习率从初始的小值逐渐上升,之后再通过cosine调度器逐渐下降。为了防止过拟合,使用了多种正则化技术,如dropout和权重衰减等。
4. 实验与结果
文章在多个自然语言理解任务上进行了评估,包括:
- 自然语言推理(SNLI、MultiNLI、QNLI等数据集)
- 问答任务(RACE、Story Cloze)
- 语义相似性任务(Quora、MRPC等)
- 文本分类任务(Stanford Sentiment Treebank-2, SST-2)
在这些任务中,预训练的GPT模型显著优于其他基于监督学习的模型,并且在9个任务中刷新了当时的最先进技术的表现。例如:
- 在自然语言推理任务上,模型在SNLI上达到了89.9%的准确率,在MultiNLI上达到了82.1%。
- 在问答任务RACE上,比之前的最好结果高出5.7%。
主要实验结果:
- 预训练的模型在未标注文本上学到了一些有用的语言知识,这些知识在微调时能够有效地转移到下游任务。
- 使用预训练模型进行的少量有监督微调可以显著提高模型的表现,特别是在数据稀缺的任务中。
- 预训练Transformer比使用LSTM架构的模型在各种任务上表现更好,尤其在长文本处理任务上。
5. 分析
文章还对模型的效果进行了深入分析:
- 层数的影响:随着预训练模型中层数的增加,任务性能逐渐提升,特别是在MultiNLI和RACE任务中,层数对模型的表现有显著影响。
- 零样本行为:研究表明,经过生成预训练的Transformer模型在处理一些任务时表现出良好的零样本学习能力,即使没有任务特定的微调,模型也能在某些任务上取得不错的效果。
- 消融实验:文章还进行了消融实验,展示了预训练过程和使用Transformer架构的重要性。没有预训练的模型在所有任务上的表现都大幅下降。
6. 结论
文章总结道,生成预训练是一种非常有效的提高自然语言理解任务性能的方法。通过在未标注数据上的预训练,模型能够学习到强大的语义表示,并且在有监督的微调过程中能够很好地适应不同的任务。文章还指出,使用Transformer架构对处理长程依赖关系和捕捉语言结构起到了至关重要的作用。
主要贡献:
- 提出了基于生成预训练的框架,能够在多个自然语言理解任务上实现优异的性能。
- 证明了预训练Transformer在处理长程依赖和任务迁移上的强大能力,为自然语言处理领域带来了显著的进展。
这篇文章是GPT模型的开创性工作之一,对后续的GPT-2和GPT-3的开发奠定了基础,也为NLP领域的预训练方法和Transformer架构的应用提供了重要的参考。