MySQL

mysql -u root -ply
MySQL的三层结构
1.安装MySQL数据库本质就是在主机安装一个数据库管理系统(DBMS),这个管理程序可以管理多个数据库.
2.一个数据库中可以创建多个表,以保存数据

SQL语句分类
1.DDL:数据定义语句[create 表,库]
2.DML:数据操作语句[增加insert,修改update,删除delete]
3.DQL:数据查询语句[select]
4.DCL:数据控制语句[管理数据库:比如用户权限 grant 撤回 revoke]
创建数据库

查看,删除数据库
显示数据库语句:SHOW DATABASE
显示数据库创建语句:SHOW CREATE DATABASE db_name
数据库删除语句:DROP DATABASE [IF EXISTS] db_name
创建数据库,表的时候,为了规避关键字,可以使用反引号解决
备份恢复数据库
备份数据库(注意: 在DOS执行)命令行
mysqldump -u 用户名(本机是root) -p -B数据库1 数据库2 数据库n>路径 文件名.sql (如 >d:\\bak.sql)
恢复数据库
在MySQL命令行在执行 source 文件名.sql
备份表
mysqldump -u 用户名-p 数据库 表1 表2 表n>路径 文件名.sql
恢复表
source 文件名.sql 也可以直接把备份文件复制到SQLyog执行
创建表

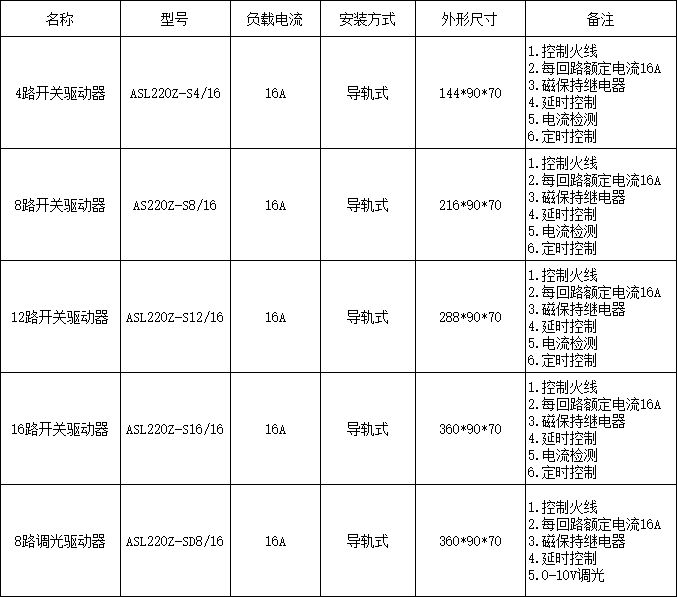
MySQL常用的数据类型

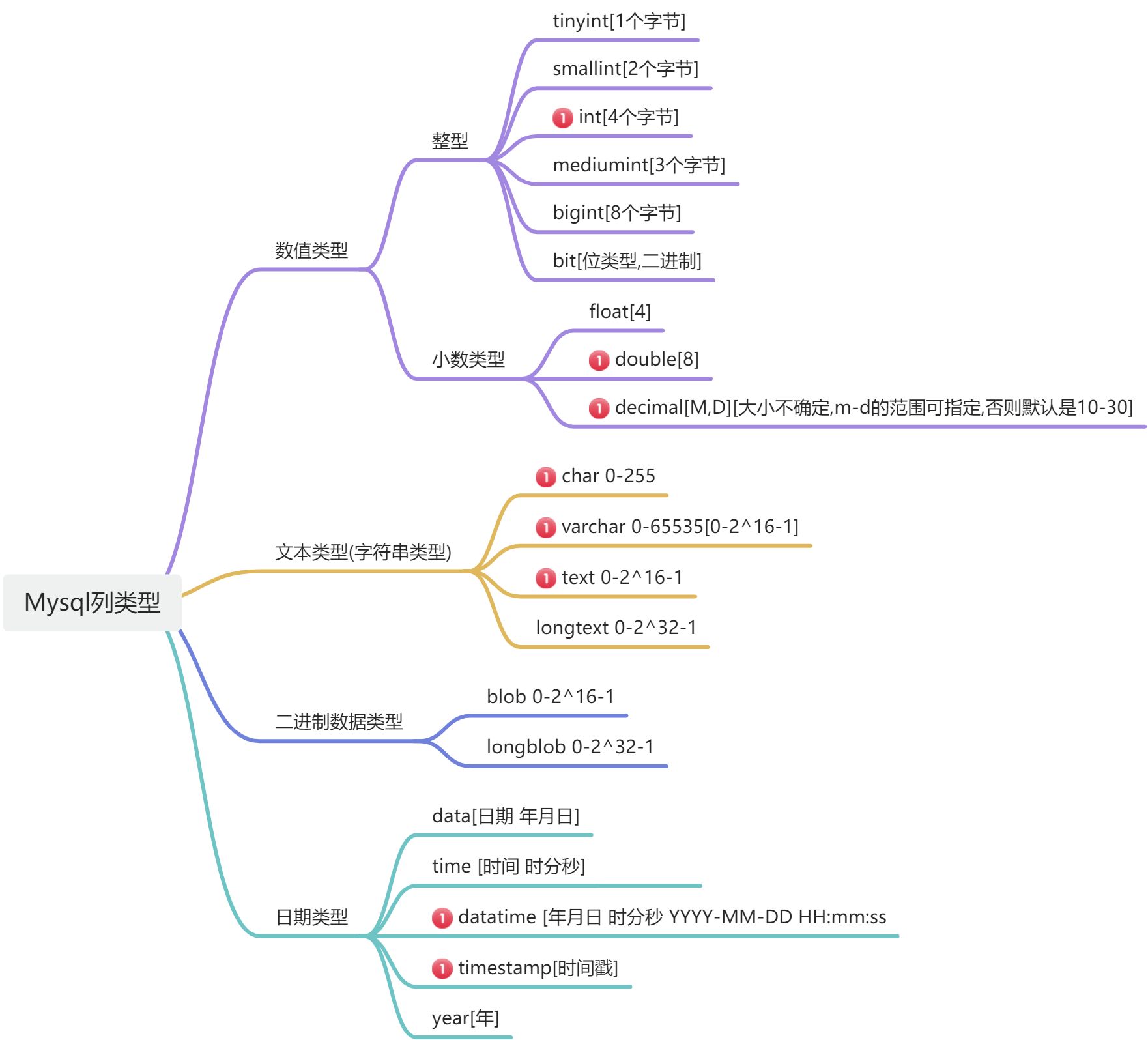
1.整型:如果没有指定unsinged,就是有符号,否则无.
2.字符串的基本使用:char最大255字符,可变长度字符串varchar最大65532字节,utf8最大21844字符,gbk最大32766个字符,1-3个字节用于记录大小
3.decimal[M,D][大小不确定,m-d的范围可指定,否则默认是10-30]
4.char(4)和varchar(4)区别在于,char不是字节数,不管是中文还是字母都放四个,即是定长(大小固定,占用分配四个字符的空间),varchar这个4表示字符数,不管是字母还是中文都以定义好的表的编码来存放数据(即变长.按实际占用空间分配)


修改表(添加修改删除)

-- 在emp表添加一个image列,varchar类型,要求在resume后面
ALTER TABLE emp
ADD COLUMN image VARCHAR(32) NOT NULL DEFAULT '' AFTER RESUME
-- 显示表结构(这通常是一个单独的命令,不是ALTER TABLE的一部分)
-- DESC emp; -- 可以在这里运行,但不在ALTER TABLE操作中
-- 修改job列,使其长度为60
ALTER TABLE emp
MODIFY COLUMN job VARCHAR(60) NOT NULL DEFAULT ''
-- 删除sex列
ALTER TABLE emp
DROP COLUMN sex
-- 表名修改为employee
RENAME TABLE emp TO employee
-- 修改表的字符集为utf8(建议使用utf8mb4以支持更广泛的Unicode字符)
ALTER TABLE employee CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
-- 列名name修改为user_name
ALTER TABLE employee
CHANGE COLUMN `name` `user_name` VARCHAR(64) NOT NULL DEFAULT ''
-- 显示修改后的表结构
DESC employee注意没加分号;一条一条的执行编辑语句
数据库的CRUD语句
insert(添加)
如:
-- 创建一张商品表的goods
CREATE TABLE `goods` (
id INT,
goods_name VARCHAR(10),
price DOUBLE);
-- 添加数据
INSERT INTO `goods`(id,goods_name,price)
VALUES(10,'华为手机',2000);insert细节
1.插入的数据应与字段的数据类型相同,且字段长度应在规定范围内
2.在values中列出的数据位置必须与被加入的列排列顺序相对应
3.字符和日期需要包含在单引号内
4.列可以插入控制[前提是该字段允许为空,看定义],insert into table value(null)
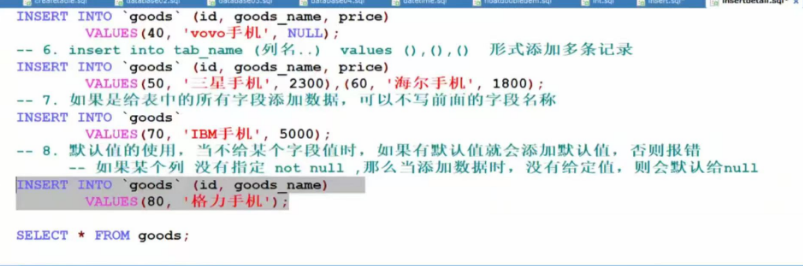
5.insert into 列名 values(),(),() 形式添加多条记录
6.如果是给表中的所有字段添加数据,可以不写前面的字段名称
7.默认值的使用,当不给某个字段值的时候,如果有默认值机会添加,否则报错.
可以指定,在创建表的时候指定,如 price DOUBLE NOT NULL DEFAULT 100
update(修改)
update细节
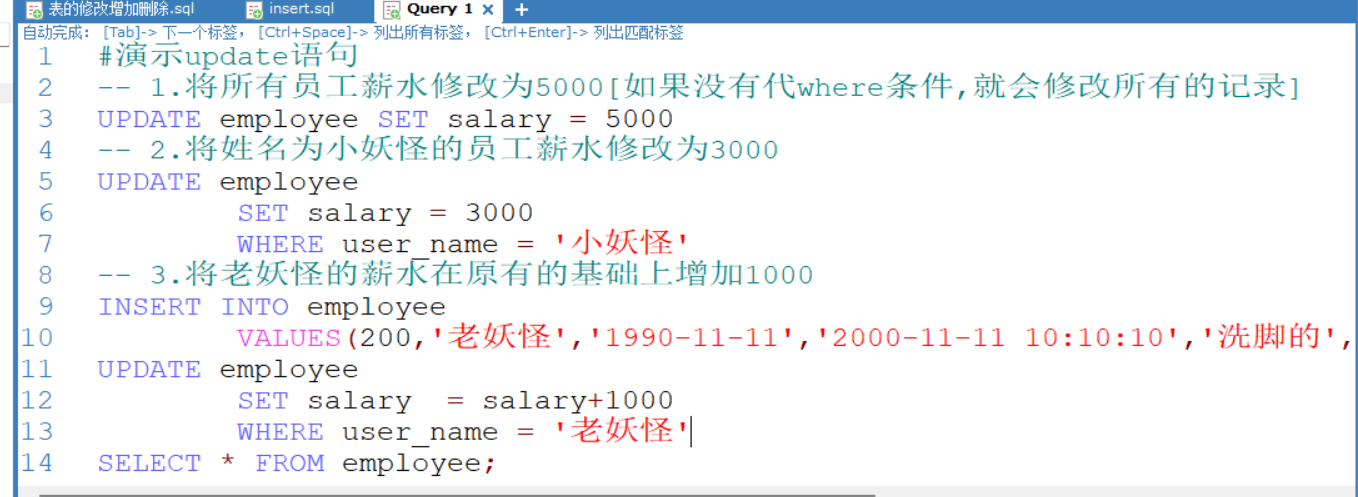
1.update语法可以用来更新原有表行中的列
2.set子句指示要修改哪些值和要给予哪些值
3.where子句指定应该更新哪些行.如果没有WHERE子句.则更新所有的行
4.如果要修改多个字段,可以通过 set 字段1=值1,字段2 = 值2.
delete语句

select语句**

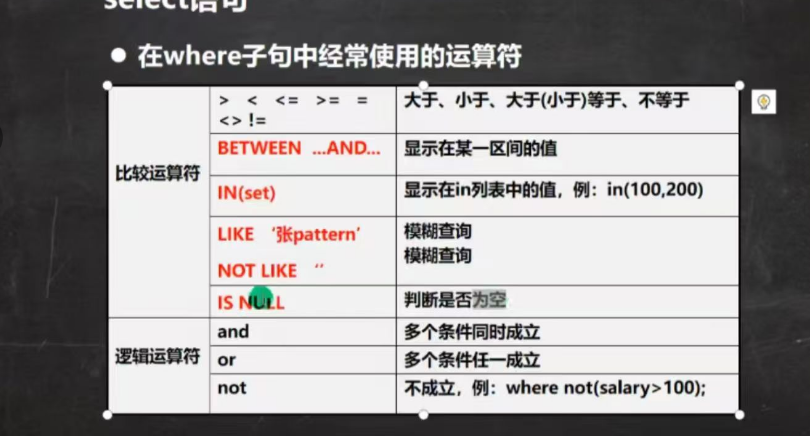
在where子句中经常用到的运算符
使用order by子句排序查询的结果


使用group by 和having子句

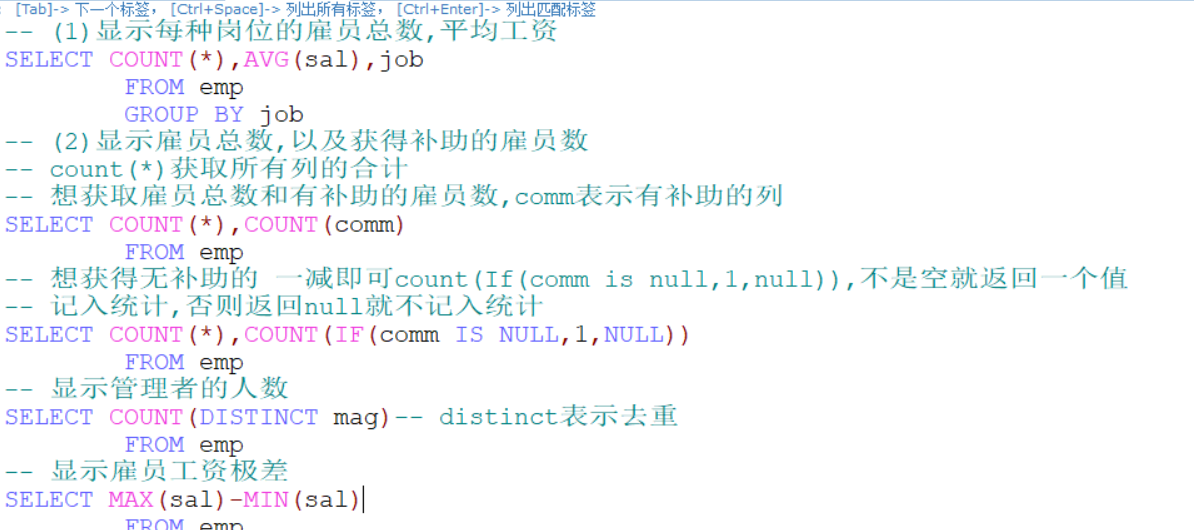
合计/统计函数
-- 1.演示mysql的统计函数count的使用
SELECT COUNT(*) FROM student
-- 统计总分大于300的人数
SELECT COUNT(*)FROM student
WHERE (math+english+chinese)>300
-- 解释:count(*)返回满足条件记录的行数
-- count(列): 统计满足条件的某列有多少个,会排除null
CREATE TABLE t2 (
`name` VARCHAR(20));
INSERT INTO t2 VALUES('tom');
INSERT INTO t2 VALUES('luo');
INSERT INTO t2 VALUES('tang');
INSERT INTO t2 VALUES(NULL);
SELECT * FROM t2;
SELECT COUNT(*)FROM t2 -- 4
SELECT COUNT(`name`)FROM t2 -- 3
-- 2.演示sum函数,仅对数值起作用
-- 统计一个班级数学总成绩
SELECT SUM(math)FROM student
-- 统计一个班级语文平均分
SELECT SUM(chinese)/COUNT(*)FROM student;
-- 3.演示avg的使用
SELECT AVG(math)FROM student
-- 4.演示max 和min
SELECT MAX(math+english+chinese),MIN(math+english+chinese)FROM student
SELECT MAX(math)AS math_high,MIN(math)FROM student字符串相关函数
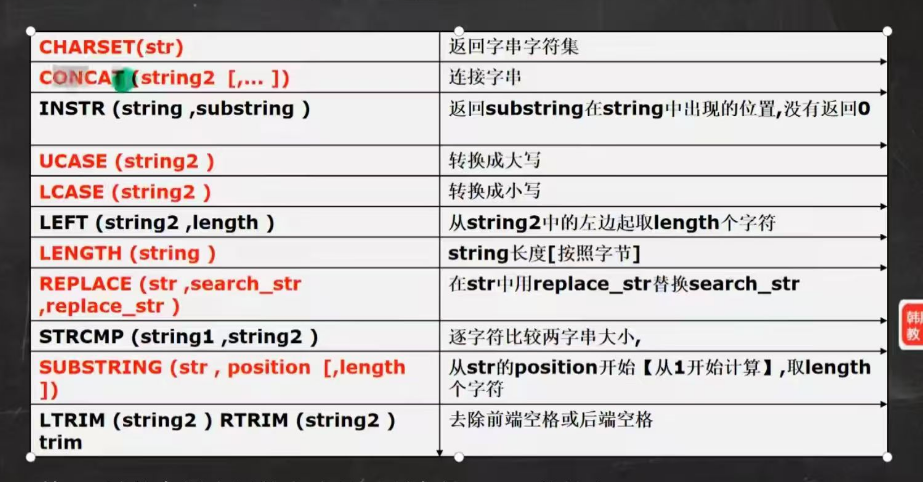
-- charset返回字串字符集
SELECT CHARSET(ename) FROM emp
-- concat,连接字符串
SELECT CONCAT(ename,'工作是',job)FROM emp
-- instr(str,substr)返回str中substr出现的位置,没有返回-1
-- dual 亚元表,可作为测试表使用,系统自带
SELECT INSTR('hangshunping','ping')FROM DUAL
-- ucase lcase 转大小写
-- left(str,length),right(str,length)从左从右返回该字符串的指定长度
-- replace(str,search_str,replace_str)
-- 从str中replace_str替换search_str
SELECT ename,REPLACE(job,'manager','经理') FROM emp
-- strcmp(string1,string2)逐字比较两字串大小
-- substring(str,position[,length])
-- 从str 指定位置开始取长度,length不指定就是全取
SELECT SUBSTRING(ename,1,2)FROM emp
-- ltrim(str) rhrim(str) trim去除左端/右端/全部空格练习,把ename的名字首字母小写后面全大写

数学相关函数
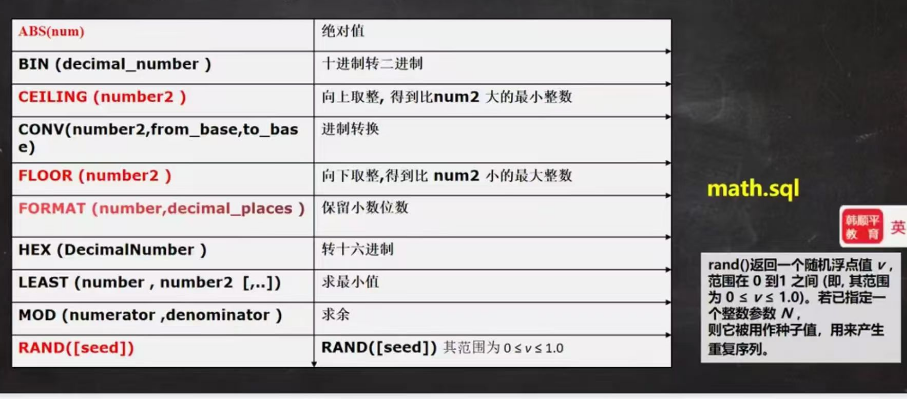
日期相关函数

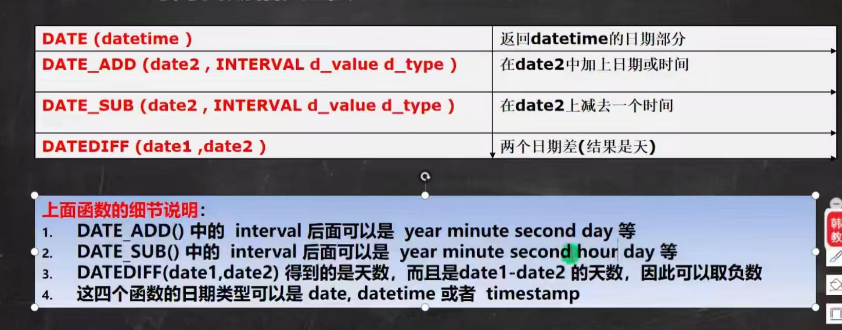
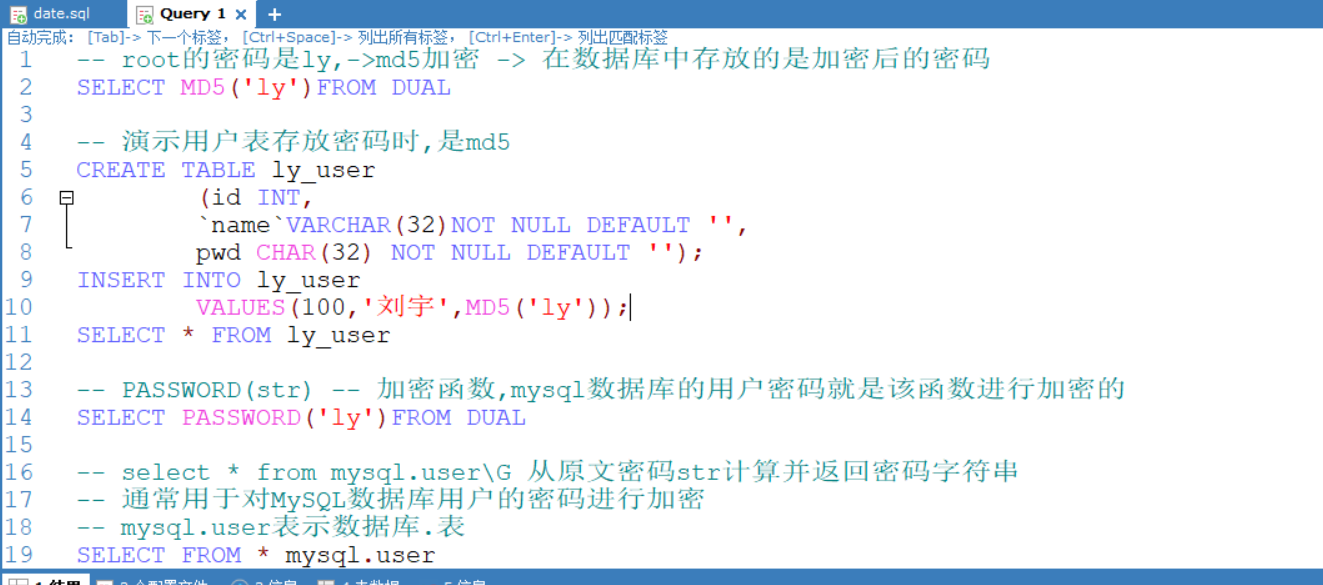
加密和系统函数
流程控制函数

查询增强
-- 查询增强
-- mysql中日期类型可直接比较,需要注意格式
-- 查询2012.1.1后入职的员工
SELECT * FROM emo
WHERE datehire>'2012.01.01'
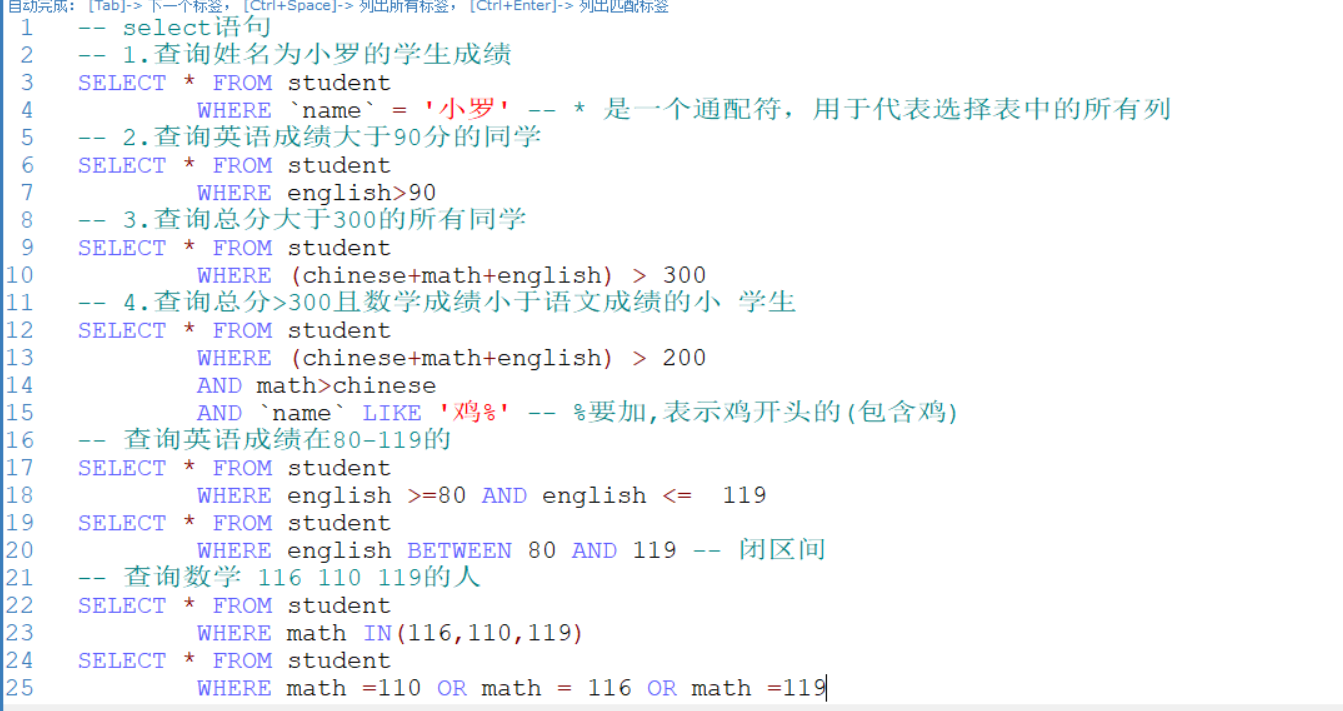
-- 使用like操作符(模糊)
-- %: 表示0到多个任意字符 _:表示任意单个字符
-- 如何显示是首字符为s的员工姓名和工资?
SELECT ename,sal FROM emp
WHERE ename LIKE 's%'
-- 如何显示第三个字符为大o的所有员工姓名和工资
SELECT ename,sal FROM emp
WHERE ename LIKE '__O%'-- --两个下划线
-- 判断某一列是否为null 用is
-- 使用order by子句 来一个升序排列
SELECT * FROM emp
ORDER BY sal ASC
-- 工资升序 部门降序排列
SELECT * FROM emp
ORDER BY sal ASC,dep DESC分页查询
select ... limit start,rows表示从start+1行开始取,取出rows行,start从0开始计算
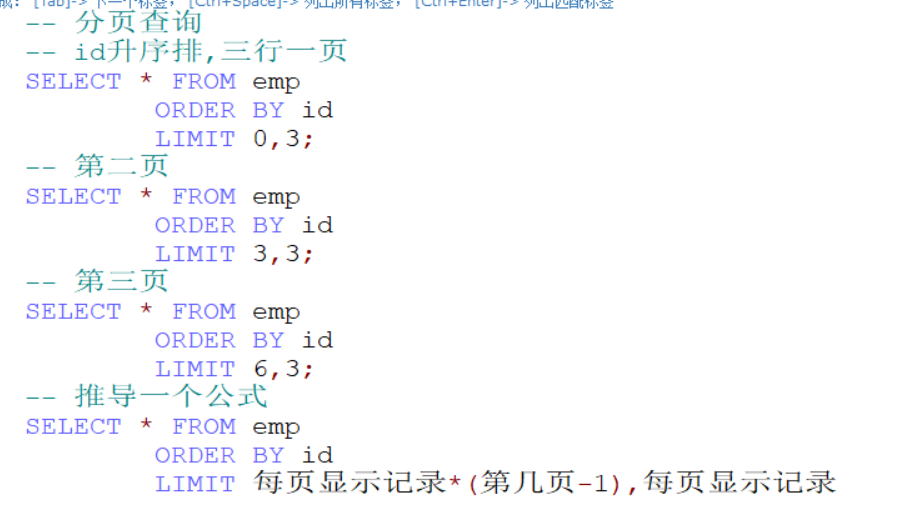
分组复习
多子句查询

顺序不能错
案例:
-- 顺序group by->having->order by->limit
SELECT dep ,AVG(sal)AS avg_sal
FROM emp
GROUP BY dep -- 分组
HAVING avg_sal>1000 -- 过滤
ORDER BY avg_sal DESC -- 排序
LIMIT 0,2 -- 分页
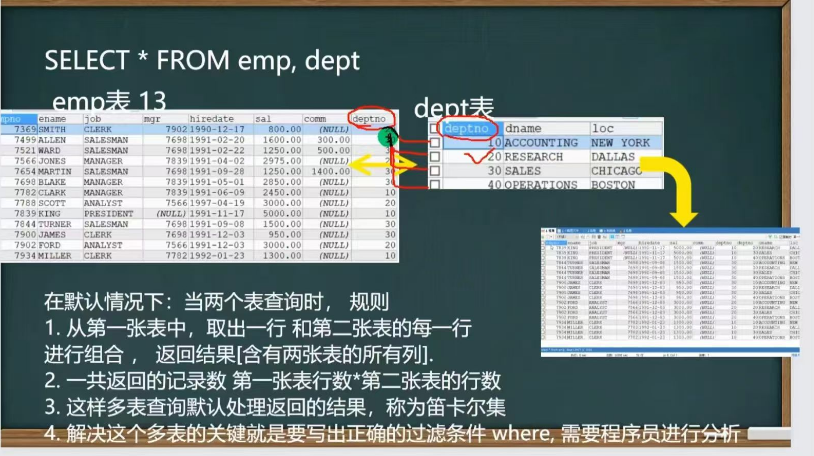
多表查询*
重复的如果想要指定显示某个表的列,需要 表.列表
找到两个表或多个表多余的列的共同点进行过滤
多表查询的过滤条件不能少于 表的个数-1
自连接
自连接是指在同一张表的连接查询[将同一张表看作两张表.这种查询方式在处理具有层级关系或递归关系的数据时非常有用,比如部门结构中的上下级关系、员工之间的管理关系等。
自连接的示例
假设我们有一个employees表,其中包含员工的ID、姓名以及他们上级的ID(作为外键指向同一张表中的某个员工ID)。表结构可能如下所示:
employees
+----+-----------+----------+
| id | name | manager_id|
+----+-----------+----------+
| 1 | John Doe | NULL |
| 2 | Jane Doe | 1 |
| 3 | Bob Smith | 1 |
| 4 | Alice | 2 |
+----+-----------+----------+在这个例子中,John Doe是CEO,没有上级(manager_id为NULL)。Jane Doe和Bob Smith都向John Doe报告,而Alice则向Jane Doe报告。
如果我们想查询每个员工及其直接上级的名字,我们可以使用自连接来实现这一点:
SELECT e1.name AS em_name, e2.name AS ma_name
FROM emp e1 ,emp e2
WHERE e1.id=e2.id多行子查询
-- 如何查询与smith同一部门的所有员工
-- 1.先查询到Smith的部门号
-- 2.把上面的select语句当作一个子查询来使用
SELECT *
FROM emp
WHERE deptno =(
SELECT deptno
FROM emp
WHERE ename = 'smith'
)
-- 课堂练习: 如何查询和部门10的工作相同的雇员的
-- 名字,岗位,工资,部门号,但不含10号部门自己的雇员
-- 查询十号部门有哪些工作
SELECT DISTINCT job -- distinct去重
FROM emp
WHERE deptno =10;
-- 把上面查询的结果当作子查询使用,完整语句
SELECT ename,job,sal,deptno
FROM emp
WHERE job IN(
SELECT DISTINCT job
FROM emp
WHERE deptno =10
)AND deptno!=10子查询临时表
把子查询当做一张临时表来使用,可以解决很多问题

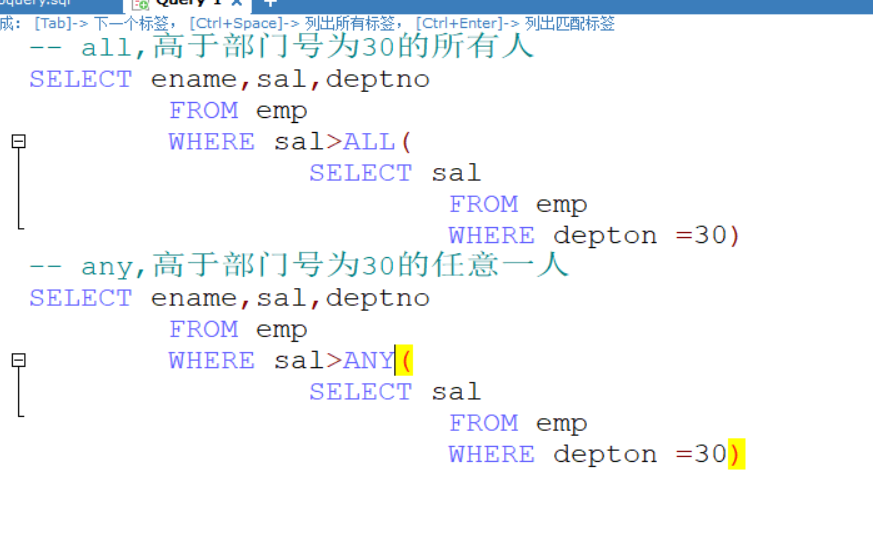
all和any
多列子查询
多列子查询是指查询返回多个列数据的子查询语句

表的复制和去重
-- 表的复制
--
CREATE TABLE ly_tab01
(id INT,
`name` VARCHAR(32),
sal DOUBLE,
job VARCHAR(32),
deptno INT;
DESC ly_tab01
SELECT * FROM ly_tab01
INSERT INTO ly_tab01
VALUES(1,'Yu',19999,'java开发工程师',99)
SELECT * FROM emp
-- 演示如何自我复制
RENAME TABLE employee TO emp
-- 1.把emp表的记录复制到 ly_tab01
INSERT INTO ly_tab01
(id,`name`,sal,job,deptno)
SELECT id,user_name,sal,job,deptno FROM emp;
-- 2.自我复制
INSERT INTO ly_tab01
SELECT * FROM ly_tab01
SELECT * FROM ly_tab01
-- 如何删除一张表的重复记录
-- 1.创建一张ly_tab02
-- 2. 让该表有重复的记录
CREATE TABLE ly_tab02 LIKE emp -- 这个语句把emp表的结构(列),复制到ly_tab02
DESC ly_tab02
INSERT INTO ly_tab02
SELECT * FROM emp
SELECT * FROM ly_tab02
/*
思路
(1)先创建一张临时表 my_tmp,该表结构和my_tab02一样
(2)把my_tmp的记录 通过distinct 关键字 处理后,把记录赋值到my_tmp
(3)清除掉my_tab02记录
(4)把my_tmp 表记录复制到ly_tab02
(5)drop掉 临时表my_tmp
*/
CREATE TABLE my_tmp LIKE ly_tab02
INSERT INTO my_tmp
SELECT DISTINCT * FROM ly_tab02;
DELETE FROM ly_tab02
INSERT INTO ly_tab02
SELECT * FROM my_tmp
DROP TABLE my_tmp;合并查询


mysql外连接
左外连接:(如果左侧的表完全显示我们就说是左外连接)
右外连接:(如果右侧的表完全显示我们就说是右外连接)
mysql约束
约束用于确保数据库满足特定的商业规则
包括not null ,unique,primary key,foreign key 和check五种
主键
primary key(主键)-基本使用
字段名 字段类型 primary key

-- 主键使用
-- id name,email
CREATE TABLE t13
(id INT PRIMARY KEY,-- 表示id 是主键
`name` VARCHAR(32),
email VARCHAR(32));
-- 1.主键列的值是不可以重复
INSERT INTO t13
VALUES(1,'jack','jack@sohu.com');
INSERT INTO t13
VALUES(3,'lans','lans@sohu.com');
-- 2.primary key不可以重复且不能为null
INSERT INTO t13
VALUES(NULL,'luo','luo@sohu.com');
-- 3.一张表最多只能有一个主键,但可以复合主键,把id name做成复合主键
CREATE TABLE t14
(id INT ,
`name` VARCHAR(32),
email VARCHAR(32),
PRIMARY KEY(id,`name`));-- 复合主键 需复合的都完全相同就无法添加
INSERT INTO t14
VALUES(3,'lans','lans@sohu.com');
INSERT INTO t14
VALUES(3,'lanss','lans@sohu.com');
SELECT * FROM t14
-- 使用desc表名,可以看到primary的情况
DESC t14 -- 查看 t14表的结果,显示约束的情况unique/not null
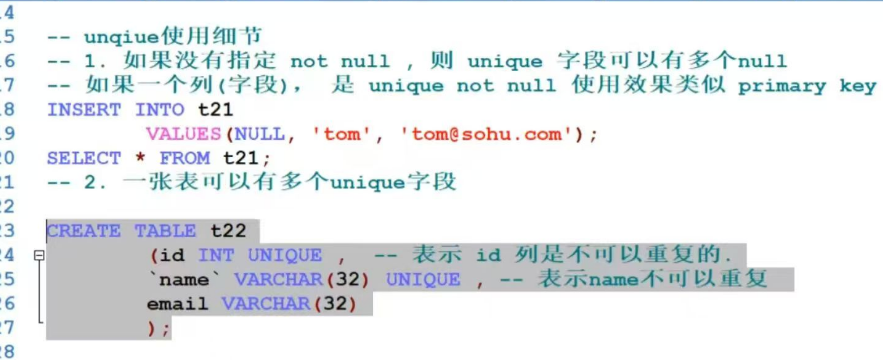
外键


-- 外键演示
-- 主表
CREATE TABLE my_class(
id INT PRIMARY KEY,
`name` VARCHAR(32)NOT NULL DEFAULT '');
-- 从表
CREATE TABLE my_stu(
id INT PRIMARY KEY,
`name` VARCHAR(32) NOT NULL DEFAULT '',
class_id INT,
-- 指定外键关系
FOREIGN KEY(class_id) REFERENCES my_class(id));
-- 测试数据
INSERT INTO my_class
VALUES(100,'java'),(200,'web');
INSERT INTO my_stu
VALUES(1,'tom',100);
INSERT INTO my_stu
VALUES(2,'jack',200);
INSERT INTO my_stu
VALUES(3,'lans',300); -- 失败,300班级不存在
SELECT * FROM my_stucheck

自增长
+AUTO_INCREMENT

索引**
大幅提高查询速度

创建索引,删除,改,查
索引的类型
1.主键索引,主键自动的为主索引(类型 Primary key)
2.唯一索引 (UNIQUE)
3.普通索引(INDEX)
4.全文索引(FULLTEXT)[适用MySAM]
开发中考虑使用全文搜索 Solr 和 ElasticSearch(ES)
-- 添加索引
-- 添加唯一索引
CREATE UNIQUE INDEX id_index ON t25(id);
-- 添加普通索引
CREATE INDEX id_index ON t25(id)
-- 想要优化速度但又不确定数据会不会重复就可以使用普通索引
-- 添加普通索引2
ALTER TABLE t25 ADD INDEX id_index(id)
-- 添加主键索引 可以在创建时添加
ALTER TABLE t25 ADD PRIMARY KEY(id)
-- 也可
-- 删除索引
SHOW INDEX FROM t25
DROP INDEX id_index ON t25
-- 删除主键索引
ALTER TABLE t25 DROP PRIMARY KEY
-- 修改索引 先删除 后重新添加
-- 查询索引
-- 1.方式
SHOW INDEX FROM t25
-- 2.方式
SHOW INDEXES FROM t25
-- 3.
SHOW KEYS FROM t25
-- 4 不建议
DESC t25小结: