文章目录
目录
文章目录
1 . 前置内容
1.1 基本全局命令
KEYS
EXISTS
编辑
DEL
EXPIRE
TTL
TYPE
1.2 数据结构和内部编码
2. String类型
SET
GET
MGET
MSET
SETNX
INCR
INCRBY
DECR
DECYBY
INCRBYFLOAT
命令小结
内部编码
3 . Hash 哈希类型
HSET
HGET
HEXISTS
HDEL
HKEYS
HVALS
HGETALL
HMGET
HLEN
HSETNX
HINCRBY
HINCRBYFLOAT
命令小结
内部编码
4 . List列表
LPUSH
LPUSHX
RPUSH
RPUSHX
LRANGE
LPOP
RPOP
LINDEX
LLEN
BLPOP
BRPOP
命令小结
内部编码
5 . Set 集合
SADD
SMEMBERS
SISMEMBER
SCARD
SPOP
SMOVE
SREM
SINTER
SINTERSTORE
SUNION
SUNIONSTORE
SDIFF
SDIFFSTORE
命令小结
内部编码
6 . Zset 有序集合
ZADD
ZCARD
ZCOUNT
ZRANGE
ZREVRANGE
ZPOPMAX
BZPOPMAX
ZPOPMIN
BZPOPMIN
ZRANK
ZREVRANK
ZSCORE
ZREM
ZINCRBY
ZINTERSTORE
ZUNIONSTORE
命令小结
内部编码
7. 渐进式遍历
8. 数据库命令
总结
1 . 前置内容
1.1 基本全局命令
KEYS
语法
KEYS pattern
用于匹配所有符合模版条件的key
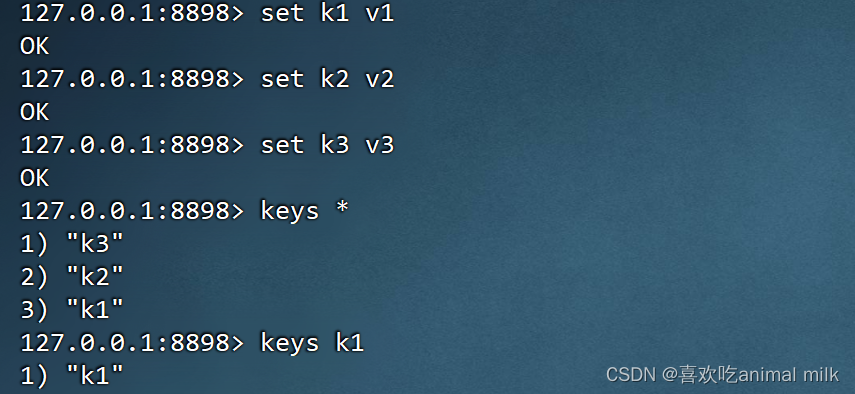
EXISTS
EXISTS key [key ...]
判断某个 key 是否存在。
上面我们添加了三个key 分别是 k1 k2 k3 我们用存在的key和不存在的key来进行测试,看看结果如何

DEL
DEL key [key ...]
删除指定的key

返回值: 删除掉key的个数
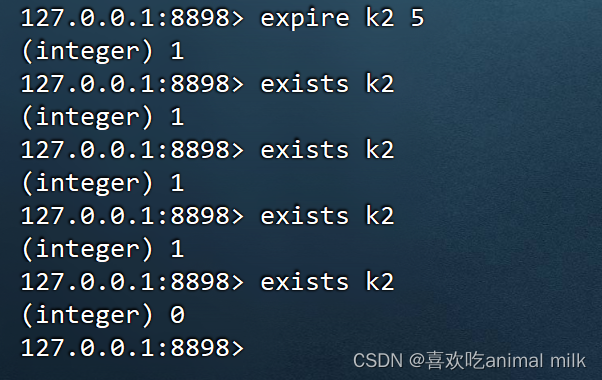
EXPIRE
EXPIRE key seconds
为指定的 key 添加秒级的过期时间(Time To Live TTL)
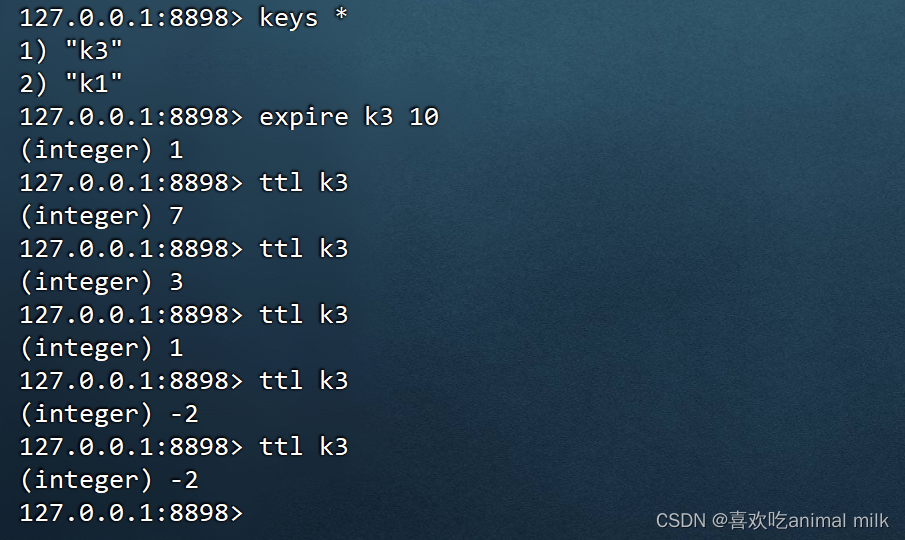
TTL
TTL key
获取指定 key 的过期时间,秒级。
返回值:剩余过期时间。-1 表示没有关联过期时间,-2 表示 key 不存在。
TYPE
TYPE key
返回 key 对应的数据类型。

1.2 数据结构和内部编码
type 命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)、list(列 表)、hash(哈希)、set(集合)、zset(有序集合),但这些只是 Redis 对外的数据结构,实际上 Redis 针对每种数据结构都有自己的底层内部编码实现,而且是多种实现,这样 Redis 会 在合适的场景选择合适的内部编码。
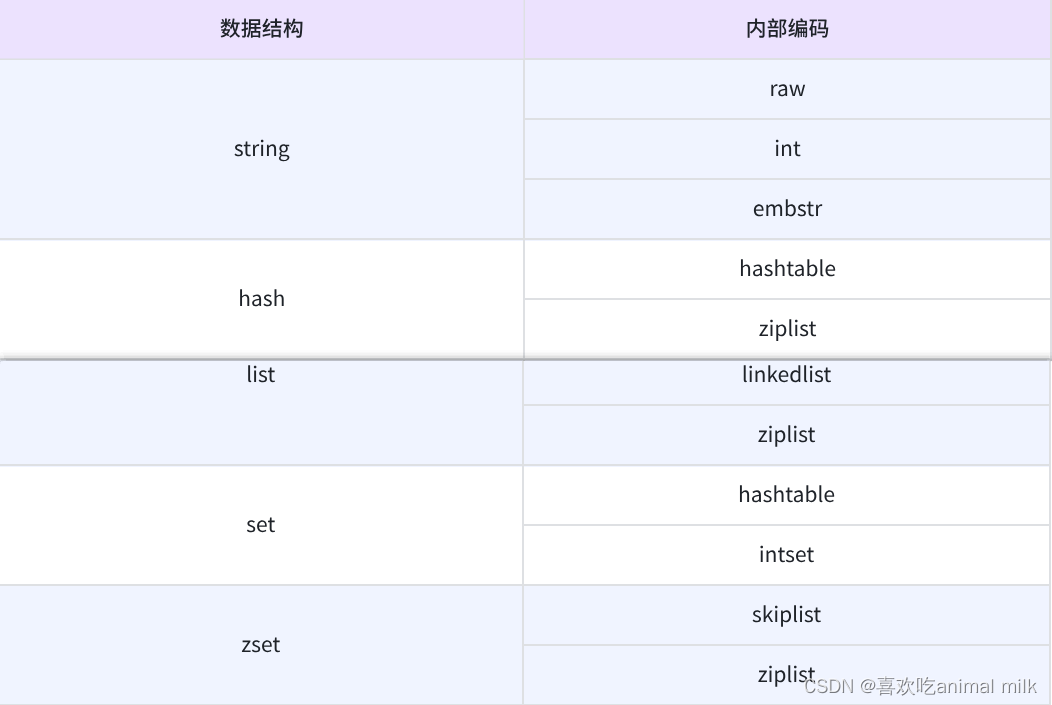
-
字符串(String):Redis 使用简单动态字符串(SDS)来存储字符串数据。SDS 是一种结构化的字符串表示,可以动态调整大小,并且可以在 O(1) 时间内获取字符串长度。
-
列表(List):Redis 使用压缩列表(ziplist)或双向循环链表(linkedlist)来存储列表数据。压缩列表是一种紧凑的数据结构,可以在一定程度上节省内存空间。双向循环链表则提供了更好的性能,但会消耗更多的内存。
-
哈希表(Hash):Redis 使用压缩列表或哈希表(hashtable)来存储哈希数据。压缩列表适用于小规模的哈希数据,而哈希表则适用于大规模的哈希数据。
-
集合(Set):Redis 使用整数集合(intset)或哈希表来存储集合数据。整数集合适用于存储整数类型的数据,而哈希表适用于存储任意类型的数据。
-
有序集合(Sorted Set):Redis 使用跳跃表(skiplist)和哈希表来存储有序集合数据。跳跃表提供了快速的查找和插入操作,而哈希表则提供了快速的范围查询操作。
2. String类型
SET
将 string 类型的 value 设置到 key 中。如果 key 之前存在,则覆盖,无论原来的数据类型是什么。之前关于此 key 的 TTL 也全部失效。
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]
EX seconds⸺使用秒作为单位设置 key 的过期时间。
PX milliseconds⸺使用毫秒作为单位设置 key 的过期时间。
NX ⸺只在 key 不存在时才进行设置,即如果 key 之前已经存在,设置不执行。
XX ⸺只在 key 存在时才进行设置,即如果 key 之前不存在,设置不执行。
GET
获取 key 对应的 value。如果 key 不存在,返回 nil。如果 value 的数据类型不是 string,会报错。
GET key
MGET
⼀次性获取多个 key 的值。如果对应的 key 不存在或者对应的数据类型不是 string,返回 nil。
MGET key [key ...]
MSET
⼀次性设置多个 key 的值。
MSET key value [key value ...]
SETNX
设置 key-value 但只允许在 key 之前不存在的情况下。
SETNX key value
INCR
将 key 对应的 string 表示的数字加1。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是⼀个整型或者范围超过了 64 位有符号整型,则报错。
INCR key
INCRBY
Increment the integer value of a key by the given amount
增加指定的数字为指定的value
DECR
将 key 对应的 string 表示的数字减⼀。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对 应的 string 不是⼀个整型或者范围超过了 64 位有符号整型,则报错
DECYBY
将 key 对应的 string 表示的数字减去对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如 果 key 对应的 string 不是⼀个整型或者范围超过了 64 位有符号整型,则报错。
INCRBYFLOAT
将 key 对应的 string 表示的浮点数加上对应的值。如果对应的值是负数,则视为减去对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的不是 string,或者不是⼀个浮点数,则报 错。允许采用科学计数法表示浮点数。
命令小结
| 命令 | 执行效果 | 时间复杂度 |
| set key value [key value...] | 设置key的值为value | O(N) N是键的个数 |
| get key | 得到key对应的value的值 | O(1) |
| del key [key...] | 删除指定的key | O(N) N是键的个数 |
| mset key value[key value...] | 批量设置指定的key和value | O(N) N是键的个数 |
| mget key | 批量获取 key 的值 | O(N) N是键的个数 |
| incr key | 指定的key + 1 | O(1) |
| decr key | 指定的key - 1 | O(1) |
| incrby key n | 指定的key + n | O(1) |
| decrby key n | 指定的key - n | O(1) |
| incrbyfloat key n | 指定的key + n | O(1) |
| append key value | 指定的key追加value | O(1) |
| strlen key | 获取指定的key的值的长度 | O(1) |
| setrange key offset value | 覆盖指定的key从offset开始的部分值 | O(1) |
| getrange key start end | 获取指定的key从start 到end部分的值 | O(1) |
内部编码
字符串类型的内部编码有 3 种:
- int: 8 个字节的长整型。
- embstr: 小于等于39个字节的字符串
- raw: 大于等于39个字节的字符串

3 . Hash 哈希类型

哈希类型中的映射关系通常称为 field-value,用于区分 Redis 整体的键值对(key-value), 注意这里的 value 是指 field 对应的值,不是键(key)对应的值,请注意 value 在不同上下 文的作用。
HSET
设置 hash 中指定的字段(field)的值(value)。
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HGET myhash field1
"HelloHGET
获取 hash 中指定字段的值。
redis> HSET myhash field1 "foo"
(integer) 1
redis> HGET myhash field1
"foo"
redis> HGET myhash field2
(nil)HEXISTS
判断 hash 中是否有指定的字段。
redis> HSET myhash field1 "foo"
(integer) 1
redis> HEXISTS myhash field1
(integer) 1
redis> HEXISTS myhash field2
(integer) 0HDEL
删除 hash 中指定的字段。
redis> HSET myhash field1 "foo"
(integer) 1
redis> HDEL myhash field1
(integer) 1
redis> HDEL myhash field2
(integer) 0
HKEYS
获取 hash 中的所有字段。
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HKEYS myhash
1) "field1"
2) "field2"HVALS
获取 hash 中的所有的值。
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HVALS myhash
1) "Hello"
2) "World"
HGETALL
获取 hash 中的所有字段以及对应的值。
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
HMGET
⼀次获取 hash 中多个字段的值
redis> HSET myhash field1 "Hello"
比特就业课
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HMGET myhash field1 field2 nofield
1) "Hello"
2) "World"
3) (nil)
HLEN
获取 hash 中的所有字段的个数。
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HLEN myhash
(integer) 2
HSETNX
在字段不存在的情况下,设置 hash 中的字段和值。
redis> HSETNX myhash field "Hello"
(integer) 1
redis> HSETNX myhash field "World"
(integer) 0
redis> HGET myhash field
"Hello"
HINCRBY
将 hash 中字段对应的数值添加指定的值。
redis> HSET myhash field 5
(integer) 1
redis> HINCRBY myhash field 1
(integer) 6
redis> HINCRBY myhash field -1
(integer) 5
redis> HINCRBY myhash field -10
(integer) -5HINCRBYFLOAT
HINCRBY 的浮点数版本。
redis> HSET mykey field 10.50
(integer) 1
redis> HINCRBYFLOAT mykey field 0.1
"10.6"
redis> HINCRBYFLOAT mykey field -5
"5.6"
redis> HSET mykey field 5.0e3
(integer) 0
redis> HINCRBYFLOAT mykey field 2.0e2
"5200"
命令小结
| 命令 | 执行效果 | 时间复杂度 |
| hset key field value | 设置值 | O(1) |
| hget key fileld | 获取值 | O(1) |
| hdel key field[field ...] | 删除field | O(k) k是field的个数 |
| hlen key | 计算field的个数 | O(1) |
| hgetall key | 获取所有的field-value | O(k) k是field的个数 |
| hmget field [field ...] | 批量获取field-value | O(k) k是field的个数 |
| hmset field value[field value ...] | 批量设置field-value | O(k) k是field的个数 |
| hexists key field | 判断field是否存在 | O(1) |
| hkeys key | 获取所有的field | O(k) k是field的个数 |
| hvals key | 获取所有的value | O(k) k是field的个数 |
| hsetnx key field value | 设置key 如果field不存在 | O(1) |
| hincrby key field n | 对应的field-value + n | O(1) |
| hincrbyfloat key field n | 对应的field-value + n | O(1) |
| hstrlen key field | 计算value的字符串长度 | O(1) |
内部编码
ziplist(压缩列表):当哈希类型元素个数小于 hash-max-ziplist-entries 配置(默认 512 个)、 同时所有值都小于 hash-max-ziplist-value 配置(默认 64 字节)时,Redis 会使用 ziplist 作为哈 希的内部实现,ziplist 使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比 hashtable 更加优秀。
hashtable(哈希表):当哈希类型无法满足 ziplist 的条件时,Redis 会使用hashtable 作为哈希 的内部实现,因为此时 ziplist 的读写效率会下降,而hashtable 的读写时间复杂度为 O(1)。
4 . List列表
列表(List)是一种简单的、可变长度的字符串序列,支持在两端进行插入和删除操作。

LPUSH
将一个或者多个元素从左侧放入(头插)到 list 中
redis> LPUSH mylist "world"
(integer) 1
redis> LPUSH mylist "hello"
(integer) 2
redis> LRANGE mylist 0 -1
1) "hello"
2) "world"
LPUSHX
在 key 存在时,将一个或者多个元素从左侧放入(头插)到 list 中。不存在,直接返回
redis> LPUSH mylist "World"
(integer) 1
redis> LPUSHX mylist "Hello"
(integer) 2
redis> LPUSHX myotherlist "Hello"
(integer) 0
redis> LRANGE mylist 0 -1
1) "Hello"
2) "World"
redis> LRANGE myotherlist 0 -1
(empty array)RPUSH
将一个或者多个元素从右侧放入(尾插)到 list 中
redis> RPUSH mylist "world"
(integer) 1
redis> RPUSH mylist "hello"
(integer) 2
redis> LRANGE mylist 0 -1
1) "world"
2) "hello"RPUSHX
在 key 存在时,将⼀个或者多个元素从右侧放⼊(尾插)到 list 中。
redis> RPUSH mylist "World"
(integer) 1
redis> RPUSHX mylist "Hello"
(integer) 2
redis> RPUSHX myotherlist "Hello"
(integer) 0
redis> LRANGE mylist 0 -1
1) "World"
2) "Hello"
redis> LRANGE myotherlist 0 -1
(empty array)LRANGE
获取从 start 到 end 区间的所有元素,左闭右闭
redis> RPUSH mylist "one"
(integer) 1
redis> RPUSH mylist "two"
(integer) 2
redis> RPUSH mylist "three"
(integer) 3
redis> LRANGE mylist 0 0
1) "one"
redis> LRANGE mylist -3 2
1) "one"
2) "two"
3) "three"
redis> LRANGE mylist -100 100
1) "one"
2) "two"
3) "three"
redis> LRANGE mylist 5 10
(empty array)LPOP
从 list 左侧取出元素(即头删)。
redis> RPUSH mylist "one" "two" "three" "four" "five"
(integer) 5
redis> LPOP mylist
"one"
redis> LPOP mylist
"two"
redis> LPOP mylist
"three"
redis> LRANGE mylist 0 -1
1) "four"
2) "five"RPOP
从 list 右侧取出元素(即尾删)。
redis> RPUSH mylist "one" "two" "three" "four" "five"
(integer) 5
redis> RPOP mylist
"five"
redis> LRANGE mylist 0 -1
1) "one"
2) "two"
3) "three"
4) "four"LINDEX
获取从左数第 index 位置的元素
redis> LPUSH mylist "World"
(integer) 1
redis> LPUSH mylist "Hello"
(integer) 2
redis> LINDEX mylist 0
"Hello"
redis> LINDEX mylist -1
"World"
redis> LINDEX mylist 3
(nil)LLEN
获取 list ⻓度。
redis> LPUSH mylist "World"
(integer) 1
redis> LPUSH mylist "Hello"
(integer) 2
redis> LLEN mylist
(integer) 2BLPOP
阻塞版本
BRPOP
阻塞版本
命令小结
| 操作类型 | 命令 | 时间复杂度 |
| 添加 | rpush key value [value...] | O(K), K是元素个数 |
| lpush key value [value ...] | O(K), K是元素个数 | |
| linsert key before | after pivot value | O(n), n是pivot距离头尾的距离 | |
| 查找 | lrange key start end | O(s+n),s 是 start 偏移量,n 是 start 到 end 的范 围 |
| lindex key index | O(n),n 是索引的偏移量 | |
| llen key | O(1) | |
| 删除 | lpop key | O(1) |
| rpop key | O(1) | |
| lrem key count value | O(K), K是元素个数 | |
| ltrim key dtart end | O(K), K是元素个数 | |
| 修改 | lset key index value | O(n) , n是索引的偏移量 |
| 阻塞操作 | blpop brpop | O(1) |
内部编码
Ziplist:
- 当列表的元素数量较少且每个元素的长度较短时,Redis会使用Ziplist编码。
- Ziplist是一种紧凑的内存表示方式,可以有效地存储小型列表。
- 优点:节省内存,适合小型列表。
- 缺点:在进行插入和删除操作时,性能较低。
Linked List:
- 当列表的元素数量增加到一定阈值时,Redis会将其转换为双向链表。
- 链表允许在两端快速插入和删除操作。
- 优点:支持快速的插入和删除操作。
- 缺点:相对于Ziplist,内存占用更高。
Quicklist:
- Redis 3.2引入了Quicklist作为列表的默认实现。
- Quicklist结合了Ziplist和链表的优点,使用多个Ziplist块来存储元素,并通过链表连接这些块。
- 优点:在内存使用和性能之间取得了良好的平衡,适合大多数使用场景。
5 . Set 集合
集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中
1)元素之间是无序的
2)元素不允许重复。
一个集合中最多可以存储 个元素。Redis 除了支持集合内的增删查改操作,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多问题。

SADD
将⼀个或者多个元素添加到 set 中。注意,重复的元素无法添加到 set 中
redis> SADD myset "Hello"
(integer) 1
redis> SADD myset "World"
(integer) 1
redis> SADD myset "World"
(integer) 0
redis> SMEMBERS myset
1) "Hello"
2) "World"SMEMBERS
获取⼀个 set 中的所有元素,注意,元素间的顺序是无序的。
redis> SADD myset "Hello"
(integer) 1
redis> SADD myset "World"
(integer) 1
redis> SMEMBERS myset
1) "Hello"
2) "World"SISMEMBER
判断⼀个元素在不在 set 中。
redis> SADD myset "one"
(integer) 1
redis> SISMEMBER myset "one"
(integer) 1
redis> SISMEMBER myset "two"
(integer) 0SCARD
获取⼀个 set 的基数(cardinality),即 set 中的元素个数。
redis> SADD myset "Hello"
(integer) 1
redis> SADD myset "World"
(integer) 1
redis> SCARD myset
(integer) 2
SPOP
从 set 中删除并返回⼀个或者多个元素。注意,由于 set 内的元素是无序的,所以取出哪个元素实际是未定义行为,即可以看作随机的。
SMOVE
将一个元素从源 set 取出并放入目标 set 中。
redis> SADD myset "one"
(integer) 1
redis> SADD myset "two"
(integer) 1
redis> SADD myotherset "three"
(integer) 1
redis> SMOVE myset myotherset "two"
(integer) 1
redis> SMEMBERS myset
1) "one"
redis> SMEMBERS myotherset
1) "three"
2) "two"
SREM
将指定的元素从 set 中删除。
redis> SADD myset "one"
(integer) 1
redis> SADD myset "two"
(integer) 1
redis> SADD myset "three"
(integer) 1
redis> SREM myset "one"
(integer) 1
redis> SREM myset "four"
(integer) 0
redis> SMEMBERS myset
1) "three"
2) "two"
SINTER
获取给定 set 的交集中的元素。
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SINTER key1 key2
1) "c"SINTERSTORE
获取给定 set 的交集中的元素并保存到目标 set 中。
SINTERSTORE destination key [key ...]redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SINTERSTORE key key1 key2
(integer) 1
redis> SMEMBERS key
1) "c"
SUNION
获取给定 set 的并集中的元素
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SUNION key1 key2
1) "a"
2) "c"
3) "e"
4) "b"
5) "d"SUNIONSTORE
获取给定 set 的并集中的元素并保存到目标 set 中。
SUNIONSTORE destination key [key ...]redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SUNIONSTORE key key1 key2
(integer) 5
redis> SMEMBERS key
1) "a"
2) "c"
3) "e"
4) "b"
5) "d"
SDIFF
获取给定 set 的差集中的元素
SDIFF key [key ...]redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SDIFF key1 key2
1) "a"
2) "b"SDIFFSTORE
获取给定 set 的差集中的元素并保存到目标 set 中
SDIFFSTORE destination key [key ...]redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SDIFFSTORE key key1 key2
(integer) 2
redis> SMEMBERS key
1) "a"
2) "b"
命令小结
| 命令 | 时间复杂度 |
| sadd key element[element ...] | O(K), K是元素个数 |
| srem key element [element ...] | O(K), K是元素个数 |
| scard key | O(1) |
| sismember key element | O(1) |
| spop key [count] | O(n), n是count |
| smemebers key | O(K), K是元素个数 |
| sinter key [key...] siterstore | O(m*k) , k十几个集合中元素最小的个数, m是键个数 |
| sunion key[key ...] sunionstore | O(K), K是多个集合元素个数总和 |
| sdiff key [key ...] sdiffstore | O(K), K是多个集合元素个数总和 |
内部编码
集合类型的内部编码有两种:
intset(整数集合):当集合中的元素都是整数并且元素的个数小于 set-max-intset-entries 配置 (默认 512 个)时,Redis 会选用intset 来作为集合的内部实现,从而减少内存的使用。 • hashtable(哈希表):当集合类型无法满足 intset 的条件时,Redis 会使用 hashtable 作为集合 的内部实现。
6 . Zset 有序集合
有序集合相对于字符串、列表、哈希、集合来说会有⼀些陌生。它保留了集合不能有重复成员的 特点,但与集合不同的是,有序集合中的每个元素都有⼀个唯⼀的浮点类型的分数(score)与之关联,着使得有序集合中的元素是可以维护有序性的,但这个有序不是用下标作为排序依据而是用这个分数。
ZADD
添加或者更新指定的元素以及关联的分数到 zset 中,分数应该符合 double 类型,+inf/-inf 作为正负极限也是合法的。
XX:仅仅⽤于更新已经存在的元素,不会添加新元素。
NX:仅⽤于添加新元素,不会更新已经存在的元素。
CH:默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更 新的元素的个数。
INCR:此时命令类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定⼀个元素和 分数。
ZCARD
获取⼀个 zset 的基数(cardinality),即 zset 中的元素个数。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZCARD myzset
(integer) 2ZCOUNT
返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的
ZCOUNT key min maxredis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZCOUNT myzset -inf +inf
(integer) 3
redis> ZCOUNT myzset 1 3
(integer) 3
redis> ZCOUNT myzset (1 3
(integer) 2
redis> ZCOUNT myzset (1 (3
(integer) 1ZRANGE
返回指定区间⾥的元素,分数按照升序。带上 WITHSCORES 可以把分数也返回。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
redis> ZRANGE myzset 0 -1
1) "one"
2) "two"
3) "three"
redis> ZRANGE myzset 2 3
1) "three"
redis> ZRANGE myzset -2 -1
1) "two"
2) "three"
ZREVRANGE
返回指定区间里的元素,分数按照降序。带上 WITHSCORES 可以把分数也返回。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREVRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3"
3) "two"
4) "2"
5) "one"
6) "1"
redis> ZREVRANGE myzset 0 -1
1) "three"
2) "two"
3) "one"
redis> ZREVRANGE myzset 2 3
1) "one"
redis> ZREVRANGE myzset -2 -1
1) "two"
2) "one"
ZPOPMAX
删除并返回分数最高的 count 个元素
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZPOPMAX myzset
1) "three"
2) "3"BZPOPMAX
ZPOPMAX 的阻塞版本。
ZPOPMIN
删除并返回分数最低的 count 个元素
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZPOPMIN myzset
1) "one"
2) "1"BZPOPMIN
ZPOPMIN 的阻塞版本。
ZRANK
返回指定元素的排名,升序。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANK myzset "three"
(integer) 2
redis> ZRANK myzset "four"
(nil)ZREVRANK
返回指定元素的排名,降序。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREVRANK myzset "one"
(integer) 2
redis> ZREVRANK myzset "four"
(nil)ZSCORE
返回指定元素的分数。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZSCORE myzset "one"
"1"ZREM
删除指定的元素。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREM myzset "two"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "three"
4) "3"
ZINCRBY
为指定的元素的关联分数添加指定的分数值
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZINCRBY myzset 2 "one"
"3"
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "two"
2) "2"
3) "one"
4) "3"
ZINTERSTORE
求出给定有序集合中元素的交集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元 素对应的分数按照不同的聚合方式和权重得到新的分数。
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight
[weight ...]] [AGGREGATE <SUM | MIN | MAX>]redis> ZADD zset1 1 "one"
(integer) 1
redis> ZADD zset1 2 "two"
(integer) 1
redis> ZADD zset2 1 "one"
(integer) 1
redis> ZADD zset2 2 "two"
(integer) 1
redis> ZADD zset2 3 "three"
(integer) 1
redis> ZINTERSTORE out 2 zset1 zset2 WEIGHTS 2 3
(integer) 2
redis> ZRANGE out 0 -1 WITHSCORES
1) "one"
2) "5"
3) "two"
4) "10"ZUNIONSTORE
求出给定有序集合中元素的并集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元 素对应的分数按照不同的聚合方式和权重得到新的分数。
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight
[weight ...]] [AGGREGATE <SUM | MIN | MAX>]redis> ZADD zset1 1 "one"
(integer) 1
redis> ZADD zset1 2 "two"
(integer) 1
redis> ZADD zset2 1 "one"
(integer) 1
redis> ZADD zset2 2 "two"
(integer) 1
redis> ZADD zset2 3 "three"
(integer) 1
redis> ZUNIONSTORE out 2 zset1 zset2 WEIGHTS 2 3
(integer) 3
redis> ZRANGE out 0 -1 WITHSCORES
1) "one"
2) "5"
3) "three"
4) "9"
5) "two"
命令小结
| 命令 | 作用 | 时间复杂度 |
| zadd key score member[score member ...] | 给集合中添加成员 | O(K*log(n)),K是添加成员的个数, n是当前有序集合的元素个数 |
| zcard key | 获取集合中成员个数 | O(1) |
| zscore key member | 返回指定成员的分数 | O(1) |
| zrank key member[member...] | 返回指定元素的排名,升序 | O(log(n)), n是当前有序集合的元素个数 |
| zrem key member [member ...] | 移除成员 | O(k * log(n)),k 是删除成员的个数,n 是当前有序集合的元 素个数 |
| zincrby key increment member | 增加指定值 | O(log(n)),n 是当前有序集合的元素个数 |
| zrange key start end [withscores] zrevrange key start end [withscores] | 获取分数在start和end范围类的成员 | O(k + log(n)),k 是获取成员的个数,n 是当前有序集合的元 素个数 |
| zcount | 获取集合中成员的数量 | O(log(n)),n 是当前有序集合的元素个数 |
| zinterstore destination numkeys key [key ...] | 将指定集合取并集并将结果保存入新的集合中 | O(n * k) + O(m * log(m)),n 是输⼊的集合最⼩的元素个数, k 是集合个数, m 是⽬标集合元素个数 |
| zunionstore destination numkeys key [key ...] | 将指定集合取交集并奖结果保存入新的集合中 | O(n) + O(m * log(m)),n 是输⼊集合总元素个数,m 是⽬标 集合元素个数 |
内部编码
ziplist(压缩列表):当有序集合的元素个数小于 zset-max-ziplist-entries 配置(默认 128 个), 同时每个元素的值都小于 zset-max-ziplist-value 配置(默认 64 字节)时,Redis 会用 ziplist 来作 为有序集合的内部实现,ziplist 可以有效减少内存的使用。
skiplist(跳表):当 ziplist 条件不满足时,有序集合会使⽤ skiplist 作为内部实现,因为此时 ziplist 的操作效率会下降
7. 渐进式遍历
渐进式遍历(Incremental Traversal)是一种在数据结构中逐步访问元素的方法,通常用于处理大型数据集或流式数据,以避免一次性加载所有数据而导致的内存消耗。
关键概念:
-
分批处理:数据被分成多个小批次进行处理,而不是一次性加载所有数据。这种方法可以减少内存使用并提高响应速度。
-
懒加载:仅在需要时加载数据,而不是预先加载所有数据。这种方式可以提高性能,尤其是在处理大数据集时。
-
迭代器模式:使用迭代器来逐步访问数据结构中的元素。迭代器可以提供一种统一的方式来遍历不同类型的数据结构。

redis 127.0.0.1:6379> scan 0
1) "17"
2) 1) "key:12"
2) "key:8"
3) "key:4"
4) "key:14"
5) "key:16"
6) "key:17"
7) "key:15"
8) "key:10"
9) "key:3"
10) "key:7"
11) "key:1"
redis 127.0.0.1:6379> scan 17
1) "0"
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"
6) "key:13"
7) "key:6"
8) "key:9"
9) "key:11"
8. 数据库命令
切换数据库
select dbIndex
清除数据库
flushdb / flushall # flushdb 只清除当前数据库,flushall 会清楚所有数
据库。总结
以上就是这篇博客的主要内容了,大家多多理解,下一篇博客见!



















