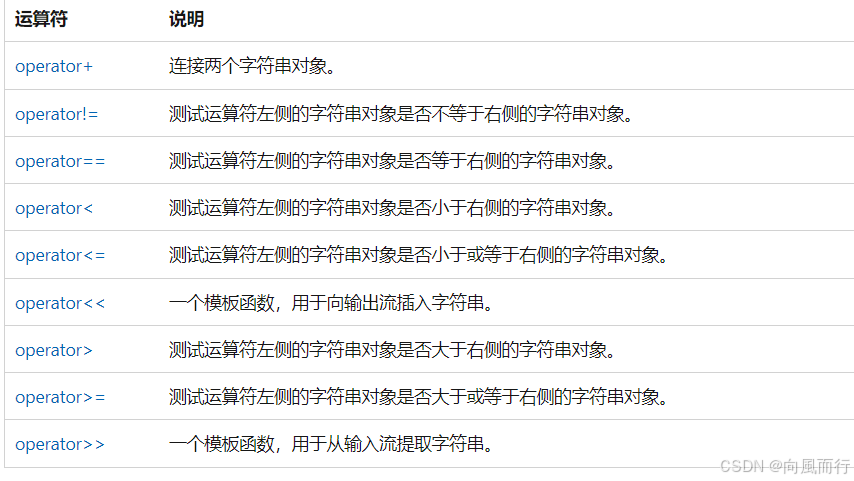
在 C# 中,内存中的所有字符串都是按 Unicode (UTF-16) 编码的。将数据从存储器移动到 string 对象中后,数据将自动转换为 UTF-16。如果数据仅包含从 0 到 127 的 ASCII 值,则此转换无需您执行任何额外的工作。但若源文本包含扩展的 ASCII 字节值(128 到 255),则默认情况下,将根据当前代码页解释扩展字符。若要指定应该根据其他某个代码页解释源文本,请使用 System.Text..::.Encoding 类,如下面的示例所示。
下面的示例演示如何转换按 8 位 ASCII 编码的文本文件

using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
//yngqq@2024年9月3日15:22:45
namespace ConsoleApp1
{
class ANSIToUnicode
{
static void Main()
{
// Create a file that contains the Greek work ψυχή (psyche) when interpreted by using
// code page 737 ((DOS) Greek). You can also create the file by using Character Map
// to paste the characters into Microsoft Word and then "Save As" by using the DOS
// (Greek) encoding. (Word will actually create a six-byte file by appending "\r\n" at the end.)
//桌面自动生成一个txt文件,写入字节。
string mypath = @"C:\Users\Administrator\Desktop\greek.txt";
System.IO.File.WriteAllBytes(mypath, new byte[] { 0xAF, 0xAC, 0xAE, 0x9E });
// Specify the code page to correctly interpret byte values
//此外,对于一些常用的字符编码(如UTF-8、Unicode等),C#还提供了更直接的获取方式,
如 Encoding.UTF8 或 Encoding.Unicode。
然而,对于特定语言或地区的字符编码,如希腊语(代码页737),
/则需要使用 GetEncoding 方法指定代码页编号来获取。
Encoding encoding = Encoding.GetEncoding(737); //(DOS) Greek code page
// Encoding encoding = Encoding.ASCII ; //也可以用其他编码方式读取
string mypath1 = @"C:\Users\Administrator\Desktop\1.txt";
//读取字节文件
byte[] codePageValues = System.IO.File.ReadAllBytes(mypath);//byte[] codePageValues = System.IO.File.ReadAllBytes(mypath);
// Same content is now encoded as UTF-16
//用希腊编码737方式读取文本
string unicodeValues = encoding.GetString(codePageValues);
// Show that the text content is still intact in Unicode string
// (Add a reference to System.Windows.Forms.dll)
Console.WriteLine(unicodeValues);
// Same content "ψυχή" is stored as UTF-8
//转换编码后输出到1.txt
System.IO.File.WriteAllText(mypath1, unicodeValues);
// Conversion is complete. Show the bytes to prove the conversion.
Console.WriteLine("8-bit encoding byte values:");
foreach (byte b in codePageValues)
Console.Write("{0:X}-", b);
Console.WriteLine("\n");
Console.WriteLine("Unicode values:");
//需要在桌面建一个2.txt文件
string mypath2 = @"C:\Users\Administrator\Desktop\2.txt";
string mypath3 = @"C:\Users\Administrator\Desktop\3.txt";
string mypath4 = @"C:\Users\Administrator\Desktop\4.txt";
//读取桌面的已有文件2.txt
string unicodeString2 = System.IO.File.ReadAllText(mypath2);
byte[] code4 = System.IO.File.ReadAllBytes(mypath2);
string unicode4 = encoding.GetString(code4);
System.IO.File.WriteAllText(mypath4, unicode4);
System.Globalization.TextElementEnumerator enumerator =
System.Globalization.StringInfo.GetTextElementEnumerator(unicodeString2);
//另一种转换方法
while (enumerator.MoveNext())
{
string s = enumerator.GetTextElement();
//转换编码方式
int i = Char.ConvertToUtf32(s, 0);
Console.Write("{0:X}-", i);
}
Console.WriteLine();
System.IO.File.WriteAllText(mypath3, unicodeValues);
// Keep the console window open in debug mode.
Console.Write("Press any key to exit.");
Console.ReadKey();
}
}
}