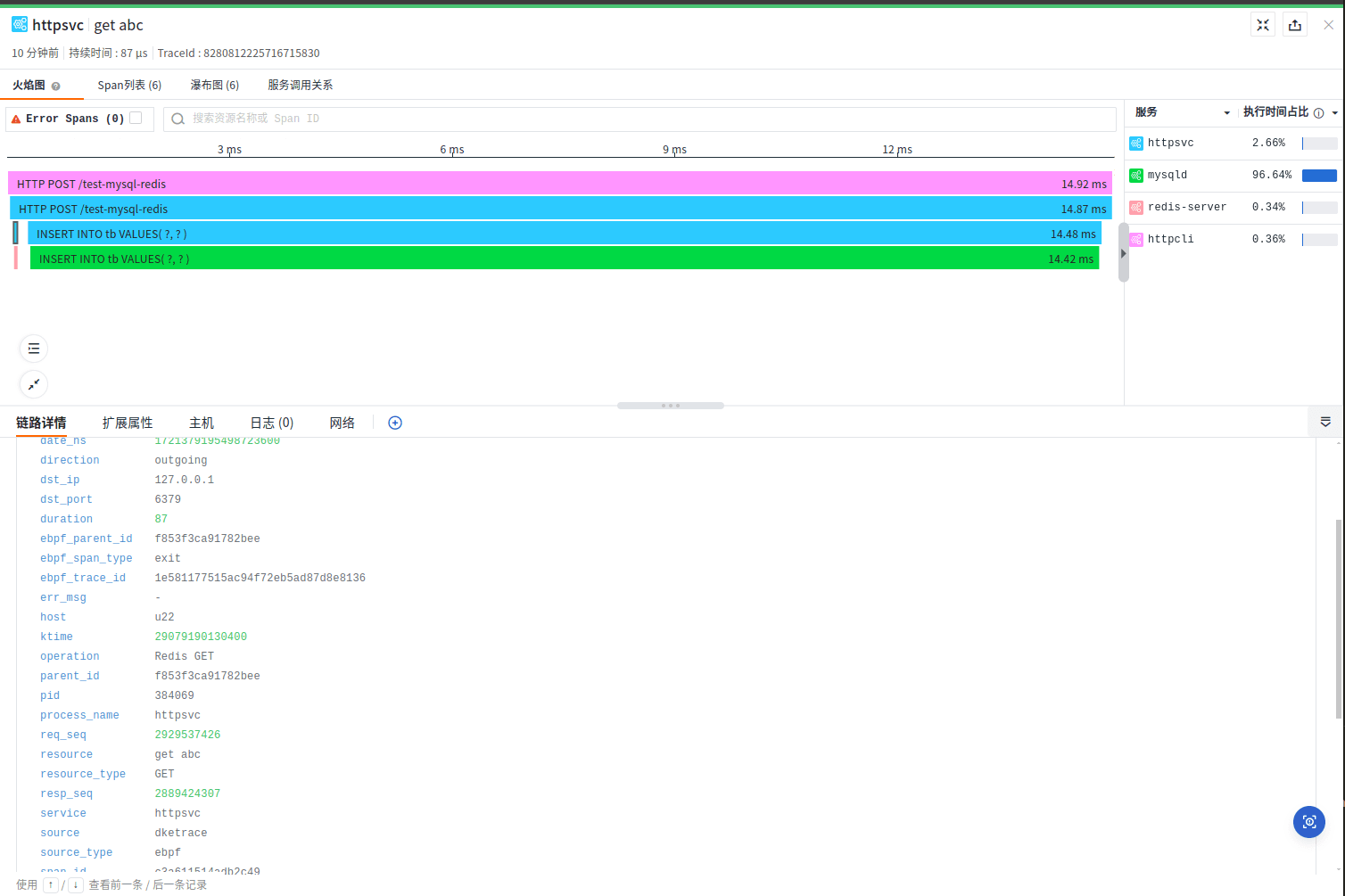
SkipList
SkipList(跳表)是一种有序链表加多级索引数据结构,基于有序的单链表,类似于平衡二叉树,但其查找、插入和删除操作的时间复杂度都是 O(logN),并且不需要进行旋转平衡等复杂操作。
跳表利用二分查找的思想,通过添加多层索引来加速查找的过程,因此可以有效地支持高效的插入、删除和查找操作。
Redis 中的 有序集合 sorted set 就是用跳表实现的
实现原理
跳表的基本结构包含多个层级,每个层级都是一个有序链表。最底层是最完整的有序链表,每个节点都包含一个值和一个指向下一个节点的指针。其他层级通过连接部分节点来实现跨级访问,即跳跃查找。
构建跳表
-
建立一级索引
为了提高查找效率,使用 二分查找 的思想,对有序链表建立一级“索引”。 每两个节点提取一个节点到索引层。 索引层中的每个节点 都包含两个指针,一个
next指针,指向下一个节点,一个down指针,指向下一级节点。 -
建立二级索引
与建立一级索引的方式类似,在第一级索引的基础上,每两个节点抽出一个节点到第二级索引
![![[SkipList.png]]](https://i-blog.csdnimg.cn/direct/99d012c3afdf402aad30aedecc8b42a2.png)
通过建立索引的方式,对于数据量越大的有序链表,通过建立多级索引,查找效率提升会非常明显。
基本操作
跳表的插入、删除和查找操作都从最顶层开始,逐层向下进行。
查找操作从最顶层的头节点开始,根据节点值的大小与目标值进行比较:
-
如果小于目标值,继续移动到当前层级的下一个节点
-
如果大于目标值,则将层级降低到下一层级,继续比较。直到找到目标值或者无法继续降低层级,查找结束。
插入和删除操作类似于查找操作,也是从最顶层开始,按照相同的方式进行查找,找到对应位置后进行插入或删除节点,并调整层级索引。
优点
跳表的优势在于简单、高效,并且不需要进行复杂的平衡操作。其时间复杂度与平衡二叉树相当,但实现起来更简单。然而,跳表相对于平衡二叉树的空间复杂度稍高,因为需要维护多层索引。
跳表在实际应用中广泛用于需要高效的有序查找的场景,特别是在并发环境下,因为跳表的结构对并发操作友好,可以提供较好的并发性能。
ConcurrentSkipListSet
ConcurrentSkipListSet 是 Java 中的一个线程安全集合类,实现了SortedSet 接口,并基于跳表数据结构进行实现。它支持高效的插入、删除和查找操作,并提供了强一致性、线程安全的操作保证。
ConcurrentSkipListSet 底层基于跳表,每个节点包含一个值和多个指向下一个节点的指针。
在插入、删除、查找元素时,ConcurrentSkipListSet 会从节点的最高层级开始查找,并逐层降低层级,直到找到对应的节点或无法继续降低层级。
ConcurrentSkipListSet (Java SE 11 & JDK 11 ) (oracle.com)
应用场景
- 高并发访问的有序集合:在需要频繁插入、删除和查找有序元素的多线程环境中,
ConcurrentSkipListSet是一个理想的选择。 - 排行榜系统:如电商系统中的热门商品排行榜,可以根据销量、评分等因素实时更新排名。
- 任务调度系统:根据任务的优先级进行排序,并允许动态添加或取消任务。
特点
ConcurrentSkipListSet 的特性如下:
-
线程安全:ConcurrentSkipListSet 支持多线程的并发访问,保证了线程安全性。
-
有序集合:ConcurrentSkipListSet 继承了
SortedSet接口,保证了有序的元素集合。 -
可能存在重复元素:ConcurrentSkipListSet 可以存在相同的元素,因此在插入元素时需要注意。
-
高效的插入、删除和查找操作:ConcurrentSkipListSet 采用跳表的数据结构,在高度平衡与高效性之间取得了一个良好的平衡,具有较高的速度。
常用方法
-
add(E e):将指定的元素添加到集合中,如果已存在则不进行添加。 -
remove(Object o):从集合中移除指定的元素,如果不存在则不进行移除。 -
contains(Object o):判断集合是否包含指定的元素,返回布尔值。 -
isEmpty():判断集合是否为空,如果为空则返回true,否则返回false。 -
size():返回集合中元素的数量。 -
first():获取集合中的第一个元素。 -
last():获取集合中的最后一个元素。 -
headSet(E toElement):返回一个子集合,包含所有小于给定元素的元素。 -
tailSet(E fromElement):返回一个子集合,包含所有大于等于给定元素的元素。 -
subSet(E fromElement, E toElement):返回一个子集合,包含所有在给定范围之内的元素。 -
iterator():返回集合的迭代器,用于遍历集合的元素。
构造方法
- 创建一个空的
ConcurrentSkipListSet,使用元素的自然顺序进行排序。
ConcurrentSkipSet()
- 创建一个空的
ConcurrentSkipListSet,使用指定的比较器对元素进行排序。
ConcurrentSkipListSet(Comparator<? super E> comparator)
- 创建一个包含指定集合的元素的
ConcurrentSkipListSet。
ConcurrentSkipListSet(Collection<? extends E> collection)
- 创建一个包含指定排序集合的元素的
ConcurrentSkipListSet。
ConcurrentSkipListSet(SortedSet<E> set)
使用示例
以下是一个使用 ConcurrentSkipListSet 基本操作的简单示例
import java.util.concurrent.ConcurrentSkipListSet;
public class ConcurrentSkipListSetExample {
public static void main(String[] args) {
// 创建一个 ConcurrentSkipListSet 实例
ConcurrentSkipListSet<Integer> skipListSet = new ConcurrentSkipListSet<>();
// 插入元素
skipListSet.add(3);
skipListSet.add(1);
skipListSet.add(4);
skipListSet.add(2);
// 输出集合
System.out.println("Initial Set: " + skipListSet);
// 判断是否存在元素
boolean contains = skipListSet.contains(5);
System.out.println("Contains '5': " + contains);
// 添加重复元素
boolean added = skipListSet.add(1);
System.out.println("Added '1' again: " + added);
// 删除元素
boolean removed = skipListSet.remove(3);
System.out.println("Removed '3': " + removed);
// 使用 headSet 和 tailSet
System.out.println("Head Set (up to 3): " + skipListSet.headSet(3));
System.out.println("Tail Set (from 3): " + skipListSet.tailSet(3));
// 使用 subSet
System.out.println("Sub Set (from 2 to 4): " + skipListSet.subSet(2, 4));
// 遍历所有元素
skipListSet.forEach(item -> System.out.println("Item: " + item));
// 清空集合
skipListSet.clear();
}
}