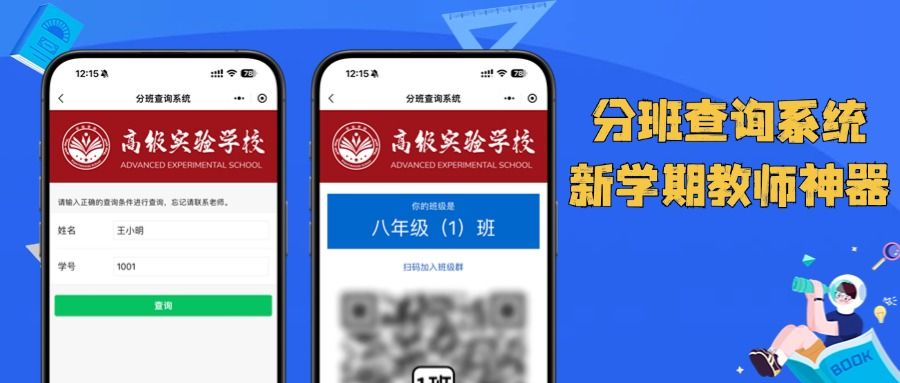
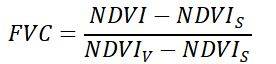某东东的jdgs算法分析
这个贴主要还是对算法本身结构部分描述会多点,憋问,问就是过去太久了,很多逆向过程不一定能还原(主要是懒,不想原路再走一遍),所以可能有部分跳跃的内容,会给具体代码,但对应的偏移地址和具体信息没有,给大家一个锻炼自己的机会 ( •_•)
继续观看前申明:本文涉及的内容是为给大家提供适合大家巩固基础及进阶更高的技术,别做不好的事情哦。
算法分析结构划分
1、查找java调用jdgs算法位置,frida主动调用获取参数;
2、unidbg模拟算法so执行;
3、枯燥的边调边复现算法;
java调用部分
这部分直接参考其他佬的,挺详细的[原创]某东 APP 逆向分析+ Unidbg 算法模拟 ;
unidbg模拟执行jdgs流程
jdgs算法的unidbg模拟执行上面链接里的结果出现以下情况问题解决:

看到java层和so层都对i2出现了不同参数对应不同功能的分支就要打起精神了,需要判断在走i2=101主体算法获取jdgs结果之前是否有走其他流程,明显是的,它执行了i2=103的init初始化部分,你在分析java层调用jdgs native算法的时候会看到init部分,so层分析时也能看到i2值会走不同的分支;
所以需要在unidbg里提前执行一步init:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
问题二:
jdgs算法过程会调用具体的两个资源文件,位置在解压文件夹assets里,后缀是.jdg.jpg和.jdg.xbt,通过unidbg自带的HookZz框架将这两个本地文件先入内存再写入到寄存器里(这部分我不贴代码了,新手可以练练手);
问题三:
这个问题就是需要你手动去利用unidbg调试算法过程,去查看控制台报红日志代码位置点在哪,追溯为什么会走这个报红日志,去手动修改这些点,这里我就直接贴代码给大家:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
这些问题主要还是动手能力的体现,就算天赋异禀,也要老老实实的动手;
最终会看到满意的结果:

jdgs算法分析
首先看下jdgs的结果
| 1 2 3 4 5 6 7 8 |
|
通过重复抓包和执行,确定固定值b1(.jdg.xbt文件名)、b2、b3、b7(时间戳,分析过程通过hook固定),
需要分析b4、b5、b6,其实实际走完算法,主要是考验你对标准算法的熟悉程度(ida脚本Findcrypt),因为并没有出现魔改算法,自定义算法也没混淆,难度不大,但详细写篇幅有点大了,适合新手进阶,所以我说下算法具体实现,就不参照ida和unidbg调试过程手摸手复现;
分析前固定时间戳
经验之谈,分析算法过程,时间戳一般都是在算法中主要变动参数之一,为了减小分析影响,我们可以选择固定时间戳值:
so直接搜索获取时间戳的常见函数名进行回溯找到时间戳生成位置:
然后通过unidbg的HookZz实现固定
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
b4
首先传参拼接一串json:e1:参数三eid,e2:参数二finger和一些常量,e3:时间戳
这一串json会进行压缩操作,返回值:comp_json
| 1 2 3 4 5 6 7 8 |
|
接下来是获取一块0x100自定义加密数据:buf_sf_0x100
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
然后将buf_sf_0x100和comp_json进行处理获得新的:comp_json
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
|
最后对comp_json进行base64即可获得b4
| 1 2 3 4 |
|
b5
首先对b1进行计算
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
|
然后对参数一的comm_body也进行同样处理,
| 1 2 |
|
然后对body_eny 进行md5得到md5_text
| 1 2 3 4 5 6 |
|
然后通过Findcrpy知道md5_text要进行aes加密得到aes_text,key和iv是内存值,不难找
| 1 2 3 4 5 6 7 8 9 |
|
接下来是sha1加密算法,明文comm_body+" "+aes_text
| 1 2 3 4 5 6 |
|
结果就是b5
b6
b6的参数是拼接值
| 1 |
|
然后和b5相同的算法结构,得到b6
结尾
这个算法过程其实非常适合新手进阶,并没有混淆和魔改,但遇到的问题都非常典型,文章的本身也是抱着锻炼的想法写的,不喜勿喷,希望大家可以互相交流,一起进步。