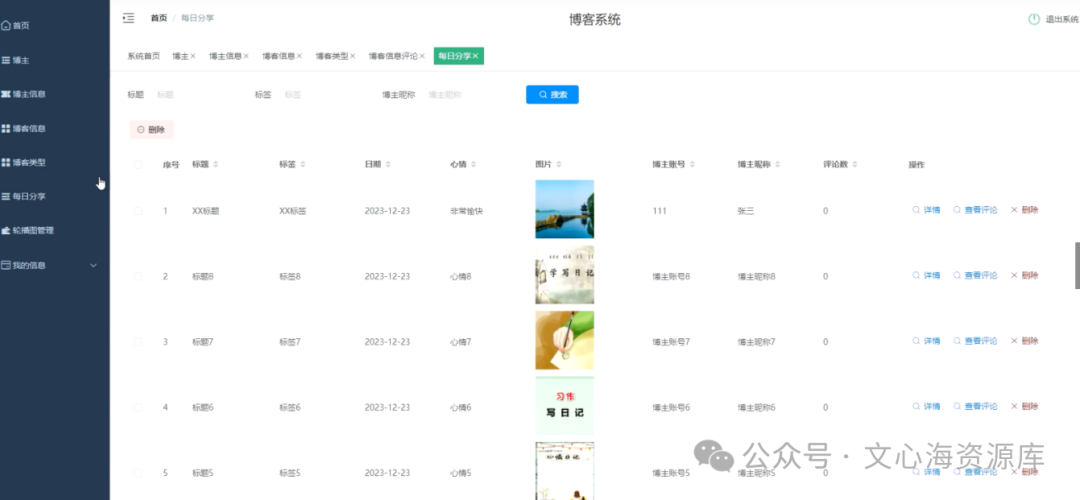
一、保险项目的基本介绍
一、保险项目的基本介绍
项目名称:富华阳光人寿保险
1. 行业背景介绍
在保险行业中,最为核心技术就是精算,精算简单来说就是根据人的年龄来计算应交保费问题,通过精算,让整个保险行业更加专业化,精细化 从而取代之间依靠经验判断的方式
精算到目前为止,并不仅仅计算保费,主要包含:
确定保险费率、应付意外损失的准备金、自留限额、未到期责任准备金和未决赔款准备金等方面,都力求采用更精确的方式取代以前的经验判断
保险精算学主要研究事故的出险规律、损失的分布规律、保费的厘定、保险产品的设计、准备金的提取、偿付能力等保险具体问题。
2 行业相关的术语
在保险行业中,以人的生命作为标的,可以划分为两大类保险:人寿保险 和 非人寿保险.
非寿险:
- 财产保险:对家庭财产进行投保的保险种类
- 责任保险:比如汽车的第三责任险
- 健康保险: 重大疾病的保险
- 意外伤害保险: 保障意外伤害保险种类
精算师:最为抢手的金领中的钻石领
保险行业全栈性人才
投保人: 指的 申购或者缴费保险的人
被保人: 以 谁的生命为标的
受益人: 当进行理赔的时候, 获得理赔金的人
保险人: 指的就是保险公司
保险准备金: 保险准备金是值保险人为保证其如约履行保险赔付和给付的义务,根据政府有关法律规定或者业务需要,从收取的保费或者从投资盈余 中 提取与其承担的保险责任相对应的一定数量的基金
生命表: 根据以往一定时期内各种年龄死亡率统计编写的一种统计表保费:投保人向保险公司缴纳的费用
责任: 一个保险产品是由多个责任组成的,比如医疗门诊责任,医疗住院责任,自然死亡责任,意外死亡责任,残疾责任,重疾赔付责任,住院津贴责任等等。

3 保险行业特点
整个保险行业的特点:交易频次比较低,数据量巨大(人均保单5张以上)大多数的需求对实时性要求不高 主要以离线需求为主
但是对于其他行业,比如证券,比如银行,交易频次比较高,尤其证券,他们的相关的需求对实时性要求比较高大多数需求都是以实时为主
在目前整个所有行业发展,每个行业都是有实时需求和离线需求,目前来看大多数的行业都是离线需求大于实时需求(离线需求占比70%以上)

3.1 用户投保流程


3.2 保险分类
- 风险转移类保险:
- 寿险
- 定期寿险
- 两全寿险
- 终身寿险
- 健康险 (性价比最高)
- 重疾险
- 医疗险
- 理财型保险:
- 年金保险
- 万能险
- 投资连结险
3.3 数据介绍
理赔数据Oracle数据源
介绍:记录客户出现死亡,医疗意外等,保险公司需要赔付的信息,该数据库记录出险时间、详情等,赔付金额等。
精算数据MySQL数据源
介绍:存储保单的现金价值,准备金,生存金,婚假金,教育金,理财收益等结果数据以及保费的确定,需要精算师的参与,大数据工程师跟精算师沟通。
保单数据PostqreSQL数据源
介绍:保单数据存储具体客户保单的详情,比如投保时间,地点,产品以及缴费时长等信志。
说明: 该项目拥有多种数据源,教学项目中仅使用MySQL存储理赔、精算、核保和保单数据源方便开发使用。
4. 项目背景
产生大数据保险项目的原因:
- 早期精算师主要采用Excel或者 专业的精算软件来计算各项费用
- 弊端:Excel计算比较慢,而且一次性只能计算一种情况 容易损坏,专业软件收费昂贵(年年收费),单机计算,效率低
- 还可以使用Oracle来计算
- 弊端:收费昂贵,单机计算,效率低
- 可以引入大数据来解决:
- 更简单, 更容易上手数据角度:需要解决 迭代计算问题,以及计算效率的问题,优先产生有spark来解决,其中spark SQL 计算
- spark支持分布式计算,支持内存计算 效率更高,spark出现的主要原因支持更加高效的迭代计算操作
尝试使用sparkSQL来解决问题
二、项目业务需求与架构介绍
1. 本次项目七大业务需求
- 1-计算所有性别,所有缴费期,所有投保年龄,在未来每个保单年度的保费参数因子相关指标: 23个 保单参数指标,合并情况组合方式有19338种情况 保存到 prem-src 表
- 比如:
- 情况一: 性别 男,缴费期选择 10年 投保年龄 20岁 在第一年度(20~105岁)计算器 23个保费因子
- 情况二:性别 男,缴费期选择 10年 投保年龄 20岁 在第二年度 计算器 23个保费因子
- 2-计算所有性别,所有缴费期,所有投保年龄的每年的应交保费,此表的计算需要依赖于第一个表 参数因子表聚合统计,保存到:prem-std 表
- 比如:这种情况共计有 274组不同组合
- 情况一:性别男,缴费期为 10年,投保年龄为 20岁,其需要缴纳保费为: xxx
- 情况二:性别女,缴费期为 15年,投保年龄为 40岁,其需要缴纳保费为: xxx
- 3-计算所有性别,所有缴费期,所有的投保年龄,在未来每个保单年度(共计有19338种情况)跟现金价值有关的37个指标,结果保存 cy_src(现金价值表)
- 比如:情况方式有19338种
- 情况一: 性别 男,缴费期选择 10年 投保年龄 20岁 在第一年度(20~105岁)计算 37个现金价值指标
- 情况二:性别 男,缴费期选择 10年 投保年龄 20岁 在第二年度 计算 37个现金价值指标
- 4-计算所有性别, 所有缴费期, 所有投保年龄,在未来每个保单年度(共计有19338种情况)跟准备金相关的33个指标, 保存到 rsv src (准备金表)表中
- 比如:情况方式有19338种
- 情况一: 性别 男,缴费期选择 10年 投保年龄 20岁 在第一年度(20~105岁)计算 33个准备金指标
- 情况二:性别 男,缴费期选择 10年 投保年龄 20岁 在第二年度 计算 33个准备金指标
- 5-需要依据 ç_src (现金价值表),rsv_src (准备金表) 关联 计算后续的 产品精算结果表(policy_actuary)主要包含信息:现金价值,生存金,保费信息 ….
- 此表作用:
- 作用一:后续向银保监会批准售卖保险,必须提交资料
- 作用二:公司要计算准备金负债 也是需要的
- 6-需要依据上面的产品精算结果表 关联到具体客户表,得到对应客户的精算结果表,体现客户当前和未来的现金价值和生存金信息,此表是给用户看的
- 7-依据保单详情表,汇总统计得到保监会规定的指标,同样此指标用于给公司决策使用 (用来实现最终的图表展
2. 项目架构

项目架构:
cloudera manager
HDFS
YANR
zookeeper
HIVE
SPARK
SQOOP
DS:任务调度
Spring boot:web框架
基于cloudera manager 平台构建的大数据分析平台,在此平台基础上,搭建有 HDFS YARN、zookeeper....相关软件
整个数据流转流程大致如下:
- 首先通过sqoop来对接,将数据源的数据导入到HIVE中,在HIVE构建数仓体系,
- 整个体系大致分为有三层(ODS DW 以及 APP层),基于数仓进行数据统计分析操作,
- 将统计分析的结果数据导出到MYSQL,
- 最后使用springboot来完成最终BI图表展示工作,
- 于整个统计分析需要周而复始进行,所以引入DS 完成 定时调度工作
2.1 项目技术版本

3. 项目基本情况
3.1 正式环境

3.2 人员配比

3.3 开发周期

3.4 技术亮点

三、数仓建模
1.数据仓库的基本介绍
- 什么是数据仓库?
存储数据的仓库,主要是用于存储过去已经既定发生过的数据(历史数据),对这些数据进行统计分析操作,从而能够对未来提供决策支持
- 数据仓库最大的特征是什么呢?
既不生产数据,也不消耗数据,数据来源于各个数据源
- 数据仓库的四大特点
- 面向主题的: 基于主题的统计分析操作,比如说对订单进行分析 那么订单就是主题
- 集成性: 数据来源于各个数据源的,每个数据源的结构什么都不一致需要将这些数据全部汇聚在一起
- 非易失性(稳定性): 存储的都是过去历史数据,这些数据一般不会发生变化
- 时变性: 随着时间的推移,数据可能会进行新增操作,以及分析数据也会发生一定的变化
- OLAP 和 OLTP的区别:
OLTP: 联机事务处理
1-面向业务的,支持事务操作
2-用于捕获数据,存储最近一段时间的内数据
3-延迟低,交互性强
OLAP: 联机分析处理1-面向主题的,不支持事务操作
2-用于分析数据,存储历史数据
3-延迟低
- ETL
ETL: 抽取转换加载
狭义上的ETL:
将数据从ODS层抽取出来,对数据进行清洗转换处理的操作,将清洗转换后的数据,加载到Dw层过程宽泛的ETL:
指的是整个数仓操作的全过程
- 数据仓库 和 数据集市
数据仓库包含数据集市的,在一个数据仓库中,可以有多个数据集市
数据仓库:更加的构建数仓平台
数据集市:更加以某一个主题构建
2.维度分析
- 维度
什么是维度?分析问题的时候,可以从不同的角度来看待,此时这些角度指的就是维度
比如说,分析过去10年的订单的数据,此时可以基于 时间,用户,商品,店铺,渠道..
维度的分类:
定性维度:维度主要是以每个各个这样维度
在编写SQL的时候,一般这样的维度都是放置SQL的 group by中定量维度: 指的计算某一个范围,或者某一个具体的值的维度
在编写SQL的时候 一般这样的维度都是放置SQL的where中
维度的分层和分级:
例如:比如按照地区进行统计分析,可以将地区划分为各省份各市各县区维度的上卷和下钻:一定要有衡量标准比如说:默认按照天统计操作,上卷统计 周
- 指标
什么是指标? 衡量事务发展的标准 也叫度量值
常见的度量值: sum() count() max() min()指标分类:
相对指标:不需要计算出具体的值,只需要计算出一个比例即可,比如 转化率 流失率 同比增长..绝对指标:需要计算出具体的某一个结果,比如说销售额 订单量
3.数仓建模
何为数仓建模:规范应该如何在数据仓库中构建表的一套理论
常见的数仓建模的理论:
1-三范式建模:
主要是应用在 关系型数据库中,主要是面向于业务来使用,要求在构建表的时候,表必须要有主键,而且表中数据尽可能避免数据冗余的发生,尽可能进行分表操作.....
2-维度建模:主要是应用于面向主题的数据仓库中,主要是用于进行分析操作,要求 所有的建表以利于分析的方案来建表,允许数据冗余

3.1 维度建模
在维度建模的理论中,规定有二种类型的表:
事实表:
什么是事实表:一般事实表都是一坨主键 (其他的表,在当前表称为外键) 的聚集,以及事实表一般是可以反应出用户具体行为
事实表分类:
事务事实表: 最初始的事实表
周期快照事实表 :指的对事实表进行了一定的提前聚合 所形成的表,比如 按照天形成日统计宽表累计快照事实表 :反应一个事件从开始到结束完整周期的事实表
维度表:
什么是维度表:在对事实表进行统计分析的时候,需要关联到其他表才能得到结果,此时其他的表就是维度表,以及维度表一般提前构建好,不会反映用户的行为
维度表分类:
数据量一般比较大,比如商品表高基数维度表:
数据量一般比较小,或者数据比较稳定比如地区表时间表低基数维度表:
3.2 数仓模型
维度建模中数仓模型(反应数仓发展的阶段):

4. 缓慢渐变维:
缓慢渐变维主要的作用:解决历史数据变化是否需要存储的问题
SCD1:不维护历史变化的行为,直接将历史数据覆盖即可
常用于: 对错误数据的处理
SCD2(拉链表): 会维护历史变化,在构建表时候,会增加两个字段,一个起始时间(开链时间) 一个结束时间(封链时间),当数据有变化的时候,将之前的数据的结束时间设置为上一天的日期即可,当新的数据作为新的开链即可
好处: 可以保存大量的历史版本,实现比较简单利于维护
弊端:会存在大量的冗余情况
SCD3:会维护历史变化,当数据发生变更的时候,通过扩展表的列,记录新的变更的值即可
好处:不存在大量的冗余情况,可以保存历史变化
弊端: 仅能保存少量的历史版本适用于 空间不足,仅需要维护少量版本的情况
5. 数据仓库的分层架构
- 数据仓库的分层架构
- 通过分层,规定每个层次作用 不同层次完成不同功能
- 利用维护
ODS层: 数据源层(贴源层)
对接数据源,一般和数据源的数据保持一致 将数据源的数据完整的导入到ODS层
DW层: 数据仓库层
数据来源于与 ODS层,主要将ODS层数据进行抽取,对数据进行转换处理的工作,最后将数据加载到Dw层在Dw层进行数据的统计分析处理操作
app(rpt,ads, da)层:
准备好用于存储指标分析的结果 此层主要是用于对接后纹的应用,后续的应用需要什么数据,需要在APP层将相关的数据

注意:
在整个保险项目中,对数仓分层并没有进行太细粒度的分层,仅进行简单三层划分
主要原因:
1-整个涉及表并不是特别多
2-整个项目中,进行指标计算的,是严重依赖于迭代计算操作,可能通过一个spark程序,就将所有的需求全部计算完成了,自然也不需要什么分层,此处的分主要也是便于大家理解
6. 项目目录

7. 完成基础数据集的导入操作



7.1 表说明

四、HIVE构建库和表 (ODS层)
1. HIVE构建库和表
ODS: 源数据层(贴源层)
作用: 对接数据源,用于和数据源保持相同的粒度,说白了就是将数据源中数据完整的拷贝到ODS层,数据源中有那些表,那么我们在ODS层就构建那些表,字段与之一致
在HIVE中构建的表的时候,需要考虑那些问题呢?
- 1- 需要考虑表使用内部表还是外部表?
是否对当前这个表有绝对的控制权,如果有控制权,一般构建都是内部表否则构建都是外部表
在当前项目中,对于ODS层,建表以及采集数据都是由自己来工作,对表有控制权的,所以ODS层构建内部表
什么情况下可能会构建外部表?例子:数据源的数据,在一开始的时候,就已经放置在HDFS中,对于我们只需要在HIVE中建表,将HDFS的数据映射上,此时仅仅只是建表,并没有处理数据,此时没有对数据的控制权,所以构建外部表了
- 2- 需要考虑在建表的时候,使用分区表还是分桶表?
分区表: 表数据比较多,表数据存在定时增量操作,以及后续在统计的时候也是针对某个时间段内数据进行统计,此时需要构建分区表
分桶表:需要对表进行数据采样的操作或者 后续需要使用SMB 或者 bucket Map join 来进行优化操作,此时 我们可以构建分桶表
在实际工作中 大多数的表都是可以满足分区表的要求,一般建表的时候都是分区表,分区字段大多数都是以日期作为分区字段
在当前项目中,除了与客户相关的表,需要构建为分区表以外,对于项目中其他表的构建的都是普通表
- 3- 需要考虑在建表的时候,表使用何种存储方式以及 压缩方案 ?
存储方式:textFile ORC sequenceFile parquet
压缩方案:gz zip lzo snappy
常用存储方式:textFile 和ORC
什么时候需要使用textFile:
一般textFile主要应用ODS层中
如果数据需要加载外部的文本文件的数据时候,必须构建为textFile
如果使用sqoop的方式来导入,不采用hcatalog形式,构建也是textFile
其他情况下,如果可以使用ORC,建议优先采用ORC方式
什么时候需要使用 ORC ?其他层次结构,建议都是采用ORC方式,有一些特殊优化,
必须建立在ORC存储格式上
压缩方式:一般选择都是 snappy
其中 ODS层可以选择使用 gz或者 zlib 压缩方案
如果空间充足,建议全部采用snappy

2. 基于SQOOP完成数据采集操作
2.1 ods建表
-- 构建库
drop database if exists insurance_ods cascade ;
create database if not exists insurance_ods location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db';
use insurance_ods;
-- 构建表
drop table if exists insurance_ods.mort_10_13;
create table if not exists insurance_ods.mort_10_13(
age smallint comment '年龄',
cl1 decimal(10, 8) comment '非养老类业务一表,男(CL1)',
cl2 decimal(10, 8) comment '非养老类业务一表,女(CL2)',
cl3 decimal(10, 8) comment '非养老类业务二表,男(CL3)',
cl4 decimal(10, 8) comment '非养老类业务二表,女(CL4)',
cl5 decimal(10, 8) comment '养老类业务表,男(CL5)',
cl6 decimal(10, 8) comment '养老类业务表,女(CL6)'
) comment '中国人身保险业经验生命表(2010-2013)'
row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/mort_10_13';
drop table if exists insurance_ods.dd_table;
create table if not exists insurance_ods.dd_table(
age smallint comment '年龄',
male decimal(10, 8) comment '男性的重疾发生率',
female decimal(10, 8) comment '女性的重疾发生率',
k_male decimal(10, 8) comment '男性的K值',
k_female decimal(10, 8) comment '女性的K值'
) comment '行业25种重疾发生率'
row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/dd_table';
--ASSUMPTION 预定附加费用率 pre_add_exp_ratio
drop table if exists insurance_ods.pre_add_exp_ratio;
create table if not exists insurance_ods.pre_add_exp_ratio (
PPP smallint comment '缴费期',
r1 decimal(10,8) comment '如果保单年度=1',
r2 decimal(10,8) comment '如果保单年度=2',
r3 decimal(10,8) comment '如果保单年度=3',
r4 decimal(10,8) comment '如果保单年度=4',
r5 decimal(10,8) comment '如果保单年度=5',
r6_ decimal(10,8) comment '如果保单年度>=6',
r_avg decimal(10,8) comment 'Avg',
r_max decimal(10,8) comment '上限'
) comment '预定附加费用率'
row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/pre_add_exp_ratio';
drop table if exists insurance_ods.prem_std_real;
create table if not exists insurance_ods.prem_std_real
(
age_buy smallint comment '年投保龄',
sex string comment '性别',
ppp smallint comment '缴费期',
bpp string comment '保障期',
prem decimal(14, 6) comment '每期交的保费',
nbev decimal(10,8) comment '新业务价值率(NBEV,New Business Embed Value)'
)comment '标准保费真实参照表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/prem_std_real';
drop table if exists insurance_ods.prem_cv_real;
create table if not exists insurance_ods.prem_cv_real
(
age_buy smallint comment '年投保龄',
sex string comment '性别',
ppp smallint comment '缴费期间',
prem_cv decimal(15, 7) comment '保单价值准备金毛保险费(Premuim)'
)comment '保单价值准备金毛保险费,真实参照表'
row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/prem_cv_real';
drop table if exists insurance_ods.area;
create table if not exists insurance_ods.area
(
id smallint comment '编号',
province string comment '省份',
city string comment '城市',
direction String comment '大区域'
) comment '中国省市区域表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/area';
drop table if exists insurance_ods.policy_client;
CREATE TABLE if not exists insurance_ods.policy_client(
user_id STRING COMMENT '用户号',
name STRING COMMENT '姓名',
id_card STRING COMMENT '身份证号',
phone STRING COMMENT '手机号',
sex STRING COMMENT '性别',
birthday STRING COMMENT '出生日期',
province STRING COMMENT '省份',
city STRING COMMENT '城市',
direction STRING COMMENT '区域',
income INT COMMENT '收入'
)
comment '客户信息表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/policy_client';
drop table if exists insurance_ods.policy_benefit;
CREATE TABLE if not exists insurance_ods.policy_benefit( pol_no STRING COMMENT '保单号',
user_id STRING COMMENT '用户号',
ppp STRING COMMENT '缴费期',
age_buy BIGINT COMMENT '投保年龄',
buy_datetime STRING COMMENT '购买日期',
insur_name STRING COMMENT '保险名称',
insur_code STRING COMMENT '保险代码',
pol_flag smallint COMMENT '保单状态,1有效,0失效',
elapse_date STRING COMMENT '保单失效时间')
comment '客户投保详情表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/policy_benefit';
drop table if exists insurance_ods.claim_info;
create table if not exists insurance_ods.claim_info
(
pol_no string comment '保单号',
user_id string comment '用户号',
buy_datetime string comment '购买日期',
insur_code string comment '保险代码',
claim_date string comment '理赔日期',
claim_item string comment '理赔责任',
claim_mnt decimal(35,6) comment '理赔金额'
) comment '理赔信息表'
row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/claim_info';
drop table if exists insurance_ods.policy_surrender;
create table if not exists insurance_ods.policy_surrender
(
pol_no string comment '保单号',
user_id string comment '用户号',
buy_datetime string comment '投保日期',
keep_days smallint comment '退保前的保单持有天数',
elapse_date string comment '保单失效日期'
) comment '退保记录表'
row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_ods.db/policy_surrender';

出现原因:
在启动spark的thrift服务的时候,并没有指定默认加载数据的路径,导致其选择了spark SQL默认的位置:$SPARK HoME/bin/spark-warehouse/
解决方式:1-在启动thrift服务的时候,指定默认加载路径
2-在建表和建库的时候,在SQL的后面手动指定加载数据的路径

2.2 sqoop
sqoop是apache旗下一款用于进行RDBMS和hadoop生态圈之间的顶级数据导入导出的工具
Sqoop可以埋解为: SQL到Hadoop 和Hadoop 到SQL"


查看所有库
sqoop list-databases --connect jdbc:mysql://node1:3306/ --username root --password 123456
查看某个数据库所有表
sqoop list-tables --connect jdbc:mysql://node1:3306/insurance --username root --password 123456
执行数据导入操作
将mysql中某一个表 导入到HDFS中:
思考:需要传递什么参数?
sqoop import--connect jdbc:mysql://node1:3306/insurance (数据库)
--username root--password 123456
--table area (表名)
--target-din xxxx (HDFS路径)
--fields-terminated-by ',' (分隔符)
2.2.1 相关参数
1) 公用参数:数据库连接
| *参数* | *说明* |
|---|---|
| --connect | 连接关系型数据库的URL |
| --help | 打印帮助信息 |
| --driver | JDBC的driver class |
| --password | 连接数据库的密码 |
| --username | 连接数据库的用户名 |
| --verbose | 在控制台打印出详细信息 |
2) 公用参数:import
| *参数* | *说明* |
|---|---|
| --enclosed-by <char> | 给字段值前加上指定的字符 |
| --escaped-by <char> | 对字段中的双引号加转义符 |
| --fields-terminated-by <char> | 设定每个字段是以什么符号作为结束,默认为逗号 |
| --lines-terminated-by <char> | 设定每行记录之间的分隔符,默认是\n |
| --mysql-delimiters | Mysql默认的分隔符设置,字段之间以逗号分隔,行之间以\n分隔,默认转义符是\,字段值以单引号包裹。 |
| --optionally-enclosed-by <char> | 给带有双引号或单引号的字段值前后加上指定字符。 |
| -m | 指定并行处理的MapReduce任务数量。 -m不为1时,需要用split-by指定分片字段进行并行导入,尽量指定int型。 |
| --split-by id | 如果指定-split by, 必须使用$CONDITIONS关键字, 双引号的查询语句还要加\ |
| --query或--e <statement> | 将查询结果的数据导入,使用时必须伴随参--target-dir,--hcatalog-table,如果查询中有where条件,则条件后必须加上CONDITIONS关键字。 如果使用双引号包含sql,则CONDITIONS前要加上\以完成转义:$CONDITIONS |
3 公用参数:export (基本都不怎么用)
| 参数 | 说明 |
|---|---|
| --input-enclosed-by <char> | 对字段值前后加上指定字符 |
| --input-escaped-by <char> | 对含有转移符的字段做转义处理 |
| --input-fields-terminated-by <char> | 字段之间的分隔符 |
| --input-lines-terminated-by <char> | 行之间的分隔符 |
| --input-optionally-enclosed-by <char> | 给带有双引号或单引号的字段前后加上指定字符 |
公用参数:hive
| *参数* | *说明* |
|---|---|
| --hive-delims-replacement <arg> | 用自定义的字符串替换掉数据中的\r\n和\013 \010等字符 |
| --hive-drop-import-delims | 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符 |
| --map-column-hive <arg> | 生成hive表时,可以更改生成字段的数据类型 |
| --hive-partition-key | 创建分区,后面直接跟分区名,分区字段的默认类型为string |
| --hive-partition-value <v> | 导入数据时,指定某个分区的值 |
| --hive-home <dir> | hive的安装目录,可以通过该参数覆盖之前默认配置的目录 |
| --hive-import | 将数据从关系数据库中导入到hive表中 |
| --hive-overwrite | 覆盖掉在hive表中已经存在的数据 |
| --create-hive-table | 默认是false,即,如果目标表已经存在了,那么创建任务失败。 |
| --hive-table | 后面接要创建的hive表,默认使用MySQL的表名 |
| --table | 指定关系数据库的表名 |
| --hive-database | 指定导入到那个hive库中 |
2.3 ods数据采集
以其中一个表为例:
area 行政区域表:

后续需要将sqoop命令通过DS完成定时调度操作,此时需要将这个命令保存起来,放置成一个shell脚本,后续让DS直接调度这个脚本即可
#!/bin/bash
/export/server/sqoop/bin/sqoop import \
--connect jdbc:mysql://node1:3306/insurance \
--username root \
--password 123456 \
--table area \
--hive-import \
--hive-overwrite \
--hive-database insurance_ods \
--hive-table area \
--fields-terminated-by '\t' \
-m 1
for file in ./02_sh_sqoop/*.sh; do
sh "$file"
done
3. Dolphinscheduler任务调度
3.1 DS基本介绍
DolphinScheduler是apache旗下一款顶级的工作流调度系统, 早期是由国内易观公司开发,在2019年贡献给apache,并成为apache旗下顶级项目,主要作用: 实现工作流的调度操作 与 oozie是同类型的软件,只不过比ooize提供了更加友好的操作界面,可以直接通过界面对工作流进行完整的配置 启动 监控等相关的工作
3.2 安装DS
将提供的DS的安装包拷贝到项目环境的_04_software 目录下
添加mysql的驱动包到 DS的lib目录下

修改DS的初始数据源的配置文件

# 此部分添加 # 注释
# postgresql
#spring.datasource.driver-class-name=org.postgresql.Driver
#spring.datasource.url=jdbc:postgresql://localhost:5432/dolphinscheduler
#spring.datasource.username=test
#spring.datasource.password=test# 新增的内容
# mysql
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.88.161:3306/dolphinscheduler?characterEncoding=UTF-8&allowMultiQueries=true
spring.datasource.username=root
spring.datasource.password=123456
说明:
请注意, 在复制的时候能不能不把中文复制进去?
进入mysql的客户端, 执行以下代码:
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
初始化元数据表:
cd /export/server/dolphinscheduler
sh script/create-dolphinscheduler.sh

修改 conf/env/dolphinscheduler_env.sh 环境变量

export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
export SPARK_HOME1=/export/server/spark
#export SPARK_HOME2=/opt/soft/spark2
export PYTHON_HOME=/root/anaconda3/bin/python
export JAVA_HOME=/export/server/jdk1.8.0_241
export HIVE_HOME=/export/server/hive
#export FLINK_HOME=/opt/soft/flink
#export DATAX_HOME=/opt/soft/datax/bin/datax.py
export SQOOP_HOME=/export/server/sqoopexport PATH=$HADOOP_HOME/bin:$HADOOP_CONF_DIR:$PYTHON_HOME:$SPARK_HOME1/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$SQOOP_HOME/bin:$PATH
修改 conf/config/install_config.conf (安装配置文件)
说明: 将配置文件对应配置信息, 改为一下的内容, 与以下内容一定一定要保持一致
dbhost="192.168.88.161:3306"
username="root"
password="123456"
zkQuorum="192.168.88.161:2181,192.168.88.162:2181,192.168.88.163:2181"
installPath="/export/server/dolphinscheduler_install"
deployUser="root"
#mailServerHost="smtp.exmail.qq.com"
#mailServerPort="25"
#mailSender="xxxxxxxxxx"
#mailUser="xxxxxxxxxx"
#mailPassword="xxxxxxxxxx"
#starttlsEnable="true"
#sslEnable="false"
#sslTrust="smtp.exmail.qq.com"
resourceStorageType="HDFS"
defaultFS="hdfs://192.168.88.161:8020"
#yarnHaIps="192.168.xx.xx,192.168.xx.xx"
singleYarnIp="192.168.88.161"
#hdfsRootUser="hdfs"
ips="192.168.88.161,192.168.88.162,192.168.88.163"
masters="192.168.88.161,192.168.88.162"
workers="192.168.88.161,192.168.88.162,192.168.88.163"
alertServer="192.168.88.163"
apiServers="192.168.88.161"
启动 zookeeper集群:
注意: 三个节点都要执行
cd /export/server/zookeeper/bin/
./zkServer.sh start
三个节点启动后, 需要查看zk的状态:
./zkServer.sh status必须看到: 两个follower 和 一个 leader

触发安装并启动
cd /export/server/dolphinscheduler
sh install.sh
注意:
此操作, 会进行DS的安装操作, 安装完成后, 自动将DS进行启动
此操作, 仅需要第一次执行一次即可, 后续启动DS会有专门的命令的
安装后, 需要查看各个节点:


访问DS
后续的启动, 是专门有命令来处理的:
cd /export/server/dolphinscheduler_install
一键停止集群所有服务
sh ./bin/stop-all.sh
一键开启集群所有服务
sh ./bin/start-all.sh单独停止和启动命令:
sh ./bin/dolphinscheduler-daemon.sh start master-server
sh ./bin/dolphinscheduler-daemon.sh stop master-serversh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-serversh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-serversh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-serversh ./bin/dolphinscheduler-daemon.sh start alert-server
sh ./bin/dolphinscheduler-daemon.sh stop alert-server
访问DS: http://192.168.88.161:12345/dolphinscheduler
用户名: admin
密码: dolphinscheduler123

3.3 DS的架构说明

说明:
首先由用户在web uI界面上配置工作流,配置完成后,启动工作流,启动后,启动工作流请求就会发生给 API服务,API服务接收到请求,会随机的选择一台Master节点 负责这个任务的处理,Master收到任务后,开始形成DAG执行流程图,进行任务分配,确定任务应该交给那个或者那些worker节点来负责,分配完成后,将任务信息发送给对应worker节点,由worker节点来负责最终任务的执行
同时告警服务也在时刻监控着工作流的执行状态,一旦发现工作流存在问题,就会实施告警工作,同时worker节点还附带一个logger日志服务,此服务也会实时记录这个各个节点的工作日志,方面用户进行实时查看执行日志
注意:
目前配置DS的高可用集群方案的状态,当用户提交一个工作流后,这个工作流最终被那个或那些worker执行是不确定的,所以后续在执行shell脚本的时候,由于shell脚本存储在本地的,需要将shell脚本分发给 node2和node3,以及sqoop也需要在node2和node3都要安装好
3.4 DS的基本使用
3.4.1 队列
后续在提交工作流的时候, 可以将工作流提交到指定的队列中, 后续基于队列进行资源化管理

3.4.2 租户
建议配置为root, 避免后续有一些权限问题

3.4.3 用户
此部分可以创建全新的用户, 可以使用这个用户登录DS, 进行相关的操作

3.4.4 告警组
说明: 可以配置告警信息, 后续在使用工作流的时候, 就可以配置告警组, 配置后, 对应告警组的用户就会受到告警邮件或者短信

3.4.5 Worker分组管理
此组主要是用于后续在进行工作流执行的时候, 可以指定worker分组, 这样master在进行任务分配的时候,会从对应worker分组中选择一个worker节点来运行, 在实际生产环境中, 此分组可能会很多个, 根据任务的大小来选择对应的分组执行

3.4.6 创建项目编写工作流

点击进入拖动脚本




3.5.基于DS实现ODS任务工作流配置
-
1- 将 node1中10个采集的shell脚本拷贝到node2和node3: 统一放置位置 /export/data/insurance_collect_sh
node1:
mkdir -p /export/data/insurance_collect_sh
cd /export/data/workspace/itcast_insurance/_02_sh_sqoop/
cp _* /export/data/insurance_collect_sh/
将数据发送给node2和node3:
cd /export/data/
scp -r insurance_collect_sh/ node2:$PWD
scp -r insurance_collect_sh/ node3:$PWD
注意:
拷贝完成后 记得到node2和node3校验一下
-
2- 将sqoop在node2和node3也进行一下安装操作:
node1:
cd /export/server/
scp -r sqoop-1.4.7.bin__hadoop-2.6.0/ node2:$PWD
scp -r sqoop-1.4.7.bin__hadoop-2.6.0/ node3:$PWD
在node2和node3中配置软连接以及配置环境变量
cd /export/server/
ln -s sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop
vim /etc/profile
添加以下内容:
#SQOOP_HOME
export SQOOP_HOME=/export/server/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
记得: source /etc/profile
-
3- 在node2和node3中安装 dos2unix
yum -y install dos2unix
-
4- 在DS上进行工作流的配置操作
脚本设置内容如下
dos2unix /export/data/insurance_collect_sh/_01_insurance_mort_10_13_import.sh
sh /export/data/insurance_collect_sh/_01_insurance_mort_10_13_import.sh

五、项目分析
1. 寿险定价规则
1.1 定价精算控制循环流程
整个保险产品,在定价的时候,并不是一次性成型,精算师需要将各种情况全部的考虑进去,然后得出一个保费的结果,然后根据保费在进行利润测试,如果没有达标 需要重新计算 直到可以满足利润目标以及在市场上存在一定竞争力

1.2 寿险定价原则
1.2.1 充足性原则
费率充足,指保险费率足够用于保单所承诺的赔付或给付、退保金、费用、税金、红利等各项支出,同时保险公司还要获取合理的利润。
1.2.2 合理性原则
费率合理,指保险费率不能过高。
如果保险费率过高,会损害被保险人的利益,保险人会获得太多的非正常经营性利润。
1.2.3 公平性原则
保险人对被保险人所承担的责任与投保人交纳的保费对等,对出险概率高、赔付成本高的被保险人收取更多的保险费,反之亦然。
1.3 寿险定价假设
- 死亡率:一般来说,死亡率随着年龄而提高,同一年龄上男性的死亡率高于女性 ,一般女性的死亡率为设置为男性死亡率的50%~80%。
- 失效率:指各种原因导致的保单不再有效、自愿退保、中途中止等情况。
- 保单年度。对均衡保费保单,最初几年,失效率随着保单年度的增加而迅速降低,5~10年后,失效率降低的速度变得非常缓慢,基本呈现平衡状态
- 投保年龄。十几到二十几岁的投保保单失效率较高,30岁以上的被保险人随年龄增加,保单率会降低。
- 利率:利率假设可以看做是保单持有人未来的收益率。寿险公司假设的利率能否实现,要看其未来投资收益为谨慎起见,利率假设一般较为保守。
- 费用:保单从出售到全部赔付、满期、退保或失效,要经历核保、出单、保单维持、理赔等环节,每一环节都需要消耗成本,这些成本源于保险人从投保人那里收取的保费和公司累积资产的投资收益。
1.4 传统的定价方法的介绍

2. 窗口函数补充知识
https://spark.apache.org/docs/3.1.2/api/sql/index.html
SparkSQL支持的所有函数
2.1 如何生成多行序列
-- 需求: 请生成一列数据, 内容为 1,2,3,4,5
select array(1,2,3,4,5,6);
select explode(array(1,2,3,4,5,6));
-- 需求2: 请生成一列数据,内容为 1~100:
select explode(sequence(1,100));说明:
explode的参数只能是列表或者 字典类型,主要用于爆炸操作,将一列数据转换为 多行的数据
2.2 如何快速生成一张表数据
-- 如何快速生成一张表数据 stack()
-- 例如:生成两行两列的数据
--——————————
--| 男 | M |
--——————————
--| 女 | F |
--—————————
-- 快速生成表数据的函数:stack(N,数据列表)
-- N 表示生成几行数
-- 数据列表:用于放置每一行的数据,函数内部会自动列表平均分为N分,放置到每一行中
select stack(2,'男','M','女','F');
-- 如何将这个表结果保存起来呢?共后续使用呢?
-- 可以通过子查询的方式,将SQL作为一个临时结果集使用
select
*
from(select stack(2,'男''M''女''F'))as t1;
-- 通过构建表的方式:
create table if not exists t3 as select stack(2,'男','M''女''F');
2.3 回顾窗口函数
-- 窗口函数: over(partition by xxx order by xxx [desc asc] [rows betweenxx and xxx ]
-- 1- row_number() rank() dense_rank() ntile()
-- 2- 与聚合函数配合使用: sum() avg() max() min() count()
-- 3- lag() lead() first_value() last_value()
--测试数据
create or replace temporary view t1 (id,name,score)as
values (1,'张三',90),
(1,'李四',80),
(1,'玉五',85),
(1,'赵六',80),
(1,'田七',76),
(2,'周八',90),
(2,'李九',80),
(2,'老王',60);
select * from t1;
-- 1- rownumber rank dense_rank ntile
select
id,
name,
score,
row_number() over (partition by id order by score) as rank1,
rank() over (partition by id order by score) as rank2,
dense_rank() over (partition by id order by score) as rank3,
ntile(3) over (partition by id order by score) as rank4
from t1;
select
id,
name,
score,
sum(score) over (partition by id order by score) as rank1,
sum(score) over (partition by id order by score rows between unbounded preceding and current row ) as rank2,
sum(score) over (partition by id) as rank3,
sum(score) over (partition by id order by score rows between unbounded preceding and unbounded following ) as rank4
from t1;
/*
lag(字段,N,默认值): 将当前行和之前第N行放置一行中
lead(字段,N,默认值): 将当前行和之后第N行放置一行中
first_value(字段): 将当前行和第一行放置在一行中
将当前行和最后一行放置在一行中,但是不能添加排序操作,否则只能和当前行处理了
既想排序 又想和最后一行比较,请使用rows between条 所有整个组的全范围即可:
rows between unbounded preceding and current row
*/
select
id,
name,
score,
lag(score,2,100) over (partition by id order by score) as rank1,
lead(score,2,100) over (partition by id order by score) as rank2,
first_value(score) over (partition by id order by score) as rank3,
last_value(score) over (partition by id) as rank4
from t1;3. 迭代计算
3.1 横向迭代计算
-- 演示 如何进行 横向迭代计算操仵:
-- 需求:已知 c1列数锯,计算岀 c2 和 c3列数据
-- c1 有1,2,3 c2: c1+2 c3: c1*(c2+3)
-- 初始化数据
create or replace temporary view t1 as
select explode(`array`(1,2,3)) as c1;
--计算c2
with t2 as (
select
c1,
c1+2 as c2
from t1
)
--计算c2
select
c1,
c2,
c1*(c2+3) as c3
from t2;说明:
如果进行横向迭代计算操作,方案就是一列一列的进行计算即可,计算完成一列后,将结果临时保存一下,然后基于这个结果计算下列的数据
3. 纵向迭代计算
-- 需求: 计算 c4:
-- 计算逻辑:当c2=1,则 c4=1;否则 c4=(上一个c4 + 当前的c3)/2
--测试数据
create or replace view t2 (c1,c2,c3) as values
(1,1,6),
(1,2,23),
(1,3,8),
(1,4,4),
(1,5,10),
(1,1,23),
(1,2,14),
(1,3,17),
(1,4,20);
-- 计算逻辑:当c2=1,则 c4=1
with t3 as (
select
c1,
c2,
c3,
`if`(c2 = 1,1,null) as c4
from t2
)
-- 否则 c4=(上一个c4 + 当前的c3)/2
select
c1,
c2,
c3,
`if`(c2 = 1,1,(lag(c4,1) over(partition by c1 order by c2) + c3)/2 ) as c4
from t3;发现,通过不断的一条SQL一条SQL的进行迭代计算,最终是可以完成计算操作,但是如果一个组内有 更多行的数据,此时, 此种操作就并不合适了…..
思考: 如何解决呢? 可以采用 自定义UDAF函数的操作
import os import pandas as pd from pyspark import SparkContext, SparkConf import pyspark.sql.functions as F from pyspark.sql import SparkSession os.environ['SPARK_HOME'] = '/export/server/spark' os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3' os.environ['PYSPARK_DIRVER_PYTHON'] = '/root/anaconda3/bin/python3' if __name__ == '__main__': print('自定义UDAF函数解决纵向迭代') spark = SparkSession.builder.master('local[*]').appName('create_udaf').getOrCreate() # 开启arrow框架 spark.conf.set('spark.sql.execution.arrow.pyspark.enabled',True) # 初始化数据 df = spark.sql(""" create or replace temporary view t2 (c1,c2,c3,c4) as values (1,1,6,1), (1,2,23,null), (1,3,8,null), (1,4,4,null), (1,5,10,null), (1,1,23,1), (1,2,14,null), (1,3,17,null), (1,4,20,null) """) @F.pandas_udf('float') def udaf_fun(c3:pd.Series,c4:pd.Series) -> float: tt = 0 for i in range(0,len(c3)): if i == 0: tt = c4[i] else: tt = ( tt + c3[i] ) / 2 return tt # 注册函数 spark.udf.register('udaf_fun',udaf_fun) spark.sql(""" select c1, c2, c3, udaf_fun(c3,c4) over(partition by c1 order by c2) as c4 from t2 """).show()
六、 计算保费参数因子
1. 需求说明
需求: 计算所有性别,所有缴费期,所有投保年龄,在未来每个保单年度的保费参数因子相关指标: 23个 保单参数指标,合并情况组合方式有19338种情况 保存到 prem-src表

以死亡率指标为例,讲解如何将其翻译为可以理解的内容:
公式:=IF(J14<=105,VLOOKUP(J14,MORT_10_13,IF(Sex="M",2,3)),0)*MortRatio_Prem_0*(I14<=BPP)


整个结果表: 共计 33个字段: 其中10个字段为维度,23字段为指标
DW层保费因子表建表
-
1- 在项目中创建一个SQL的脚本:
名字为: _02_insurance_create_dw_table.sql
-
2- 在SQL脚本中, 放置以下内容:
drop database if exists insurance_dw; create database if not exists insurance_dw location 'hdfs://node1:8020/user/hive/warehouse/insurance_dw.db'; drop table if exists insurance_dw.prem_src; create table if not exists insurance_dw.prem_src ( age_buy smallint comment '投保年龄', nursing_age smallint comment '长期护理保险金给付期满年龄', sex string comment '性别', t_age smallint comment '满期年龄(Terminate Age)', ppp smallint comment '交费期间(Premuim Payment Period PPP)', bpp smallint comment '保险期间(BPP)', interest_rate decimal(6, 4) comment '预定利息率(Interest Rate PREM&RSV)', sa decimal(12, 2) comment '基本保险金额(Baisc Sum Assured)', policy_year smallint comment '保单年度', age smallint comment '保单年度对应的年龄', qx decimal(17, 12) comment '死亡率', kx decimal(17, 12) comment '残疾死亡占死亡的比例', qx_d decimal(17, 12) comment '扣除残疾的死亡率', qx_ci decimal(17, 12) comment '残疾率', dx_d decimal(17, 12) comment '', dx_ci decimal(17, 12) comment '', lx decimal(17, 12) comment '有效保单数', lx_d decimal(17, 12) comment '健康人数', cx decimal(17, 12) comment '当期发生该事件的概率,如下指的是死亡发生概率', cx_ decimal(17, 12) comment '对Cx做调整,不精确的话,可以不做', ci_cx decimal(17, 12) comment '当期发生重疾的概率', ci_cx_ decimal(17, 12) comment '当期发生重疾的概率,调整', dx decimal(17, 12) comment '有效保单生存因子', dx_d_ decimal(17, 12) comment '健康人数生存因子', ppp_ smallint comment '是否在缴费期间,1-是,0-否', bpp_ smallint comment '是否在保险期间,1-是,0-否', expense decimal(17, 12) comment '附加费用率', db1 decimal(17, 12) comment '残疾给付', db2_factor decimal(17, 12) comment '长期护理保险金给付因子', db2 decimal(17, 12) comment '长期护理保险金', db3 decimal(17, 12) comment '养老关爱金', db4 decimal(5, 2) comment '身故给付保险金', db5 decimal(17, 12) comment '豁免保费因子' ) comment '保费因子表(到每个保单年度)' row format delimited fields terminated by '\t' location 'hdfs://node1:8020/user/hive/warehouse/insurance_dw.db/prem_src'; -
3- 执行SQL脚本, 创建表
| 保险名词 | 描述解释 | 字段名 |
|---|---|---|
| 缴费期 | 客户要交多少年保费 | ppp |
| 保险费 | 客户每年交多少钱的保费 | prem |
| 投保年龄(购买年龄) | 购买保险时的年龄。最低购买年龄18岁。70岁以后不能购买,70岁后也不能缴费。比如缴费期10年,那么最大购买年龄是60岁。不能在61岁时购买,否则导致71岁还在缴费。所以缴费期与投保年龄的关系如下图: | age_buy |
| 保单年度 | 自投保之日起,第1年是第1个保单年度,第2年是第二保单年度.。。以此类推。 | policy_year |
| 满期年龄 | 一直保障至多少岁。如果是终身则是106岁。 | t_age |
| 保险期间 | 自投保之日起,至满期年龄,之间的年数。比如18岁投保,满期年龄106岁,保障至106岁,保险期间=106-18=88年。 | bpp |
2. 准备构建起始维度表
1- 在项目中创建一个计算保费的SQL脚本文件: _04_insurance_dw_prem_std.sql
2- 编写SQL:
-- 此脚本用于计算保费信息:
-- 1- 先生成维度表信息(19338种)
-- 性别:
create or replace view insurance_dw.prem_src0_sex as
select stack(2,'M','F') as sex;
-- 缴费期: 10 15 20 30
create or replace view insurance_dw.prem_src0_ppp as
select stack(4,10,15,20,30) as ppp;
-- 投保年龄: 18~60
create or replace view insurance_dw.prem_src0_age_buy as
select explode(sequence(18,60)) as age_buy;
-- 保单年度:
create or replace view insurance_dw.prem_src0_policy_year as
select explode(sequence(1,88)) as policy_year;
-- 构建一个常量标准数据表:
create or replace view insurance_dw.input as
select 0.035 interest_rate, --预定利息率(Interest Rate PREM&RSV)
0.055 interest_rate_cv,--现金价值预定利息率(Interest Rate CV)
0.0004 acci_qx,--意外身故死亡发生率(Accident_qx)
0.115 rdr,--风险贴现率(Risk Discount Rate)
10000 sa,--基本保险金额(Baisc Sum Assured)
1 average_size,--平均规模(Average Size)
1 MortRatio_Prem_0,--Mort Ratio(PREM)
1 MortRatio_RSV_0,--Mort Ratio(RSV)
1 MortRatio_CV_0,--Mort Ratio(CV)
1 CI_RATIO,--CI Ratio
6 B_time1_B,--生存金给付时间(1)—begain
59 B_time1_T,--生存金给付时间(1)-terminate
0.1 B_ratio_1,--生存金给付比例(1)
60 B_time2_B,--生存金给付时间(2)-begain
106 B_time2_T,--生存金给付时间(2)-terminate
0.1 B_ratio_2,--生存金给付比例(2)
70 MB_TIME,--祝寿金给付时间
0.2 MB_Ration,--祝寿金给付比例
0.7 RB_Per,--可分配盈余分配给客户的比例
0.7 TB_Per,--未分配盈余分配给客户的比例
1 Disability_Ratio,--残疾给付保险金保额倍数
0.1 Nursing_Ratio,--长期护理保险金保额倍数
75 Nursing_Age--长期护理保险金给付期满年龄
;
-- 组装四个维度:
create or replace view insurance_dw.prem_src0 as
select
t3.age_buy,
t5.Nursing_Age,
t1.sex,
t5.B_time2_T as t_age,
t2.ppp,
t5.B_time2_T - t3.age_buy as bpp,
t5.interest_rate,
t5.sa,
t4.policy_year,
(t3.age_buy + t4.policy_year) - 1 as age
from insurance_dw.prem_src0_sex t1 join insurance_dw.prem_src0_ppp t2 on 1=1
join insurance_dw.prem_src0_age_buy t3 on t3.age_buy >= 18 and t3.age_buy <= 70 - t2.ppp
join insurance_dw.prem_src0_policy_year t4 on t4.policy_year >=1 and t4.policy_year <= 106 - t3.age_buy
join insurance_dw.input as t5 on 1=1;
-- 校验维度表
select * from insurance_dw.prem_src0;3. 保费参数因子表计算
开启精度保护
--开启spark精度保护
set spark.sql.decimal0perations.allowPrecisionLoss=false;
3.1 完成步骤一

-- 步骤一:计算 ppp_ 和 bpp_
create or replace view insurance_dw.prem_src1 as
select *,
if(policy_year <= ppp, 1, 0) as ppp_,
if(policy_year <= bpp, 1, 0) as bpp_
from insurance_dw.prem_src0;
--校验
select *
from insurance_dw.prem_src1
where age_buy = 45
and sex = 'F'
and ppp = 15;4.3.2 完成步骤二

--步骤二:qx kx 和 qx_ci
create or replace view insurance_dw.prem_src2 as
select t1.*,
cast((
if(
t1.age <= 105,
if(t1.sex = 'M', t3.cl1, t3.cl3),
0)
) * t2.MortRatio_Prem_0 * t1.bpp_ as decimal(17, 8)) as qx,
(
if(
t1.age <= 105,
if(t1.sex = 'M', t4.k_male, t4.k_female),
0)
) * t1.bpp_ as kx,
(
if(
t1.sex = 'M',
t4.male,
t4.female)
) * t1.bpp_ as qx_ci
from insurance_dw.prem_src1 t1
join insurance_dw.input t2 on 1 = 1
join insurance_ods.mort_10_13 t3 on t1.age = t3.age
join insurance_ods.dd_table t4 on t1.age = t4.age;
--校验
select *
from insurance_dw.prem_src2
where age_buy = 45
and sex = 'F'
and ppp = 15;
4.3.3 完成步骤三

select
t1.*,
(
if(t1.age >= 105, t1.qx - t1.qx_ci, t1.qx*(1-t1.kx))
) * t1.bpp_ as qx_d
from insurance_dw.prem_src2 t1;使用spark程序读取SQL脚本执行
import os
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DIRVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 工具函数(方法) :
def executeSQLFile(filename):
with open(r'../sparksql_script/' + filename, 'r') as f:
read_data = f.readlines()
# 将列表的一行一行拼接成一个长文本,就是SQL文件的内容
read_data = ''.join(read_data)
# 将文本内容按分号切割得到数组,每个元素预计是一个完整语句
arr = read_data.split(";")
# 对每个SQL,如果是空字符串或空文本,则剔除掉
# 注意,你可能认为空字符串''也算是空白字符,但其实空字符串‘’不是空白字符 ,即''.isspace()返回的是False
arr2 = list(filter(lambda x: not x.isspace() and not x == "", arr))
# 对每个SQL语句进行迭代
for sql in arr2:
# 先打印完整的SQL语句。
print(sql, ";")
# 由于SQL语句不一定有意义,比如全是--注释;,他也以分号结束,但是没有意义不用执行。
# 对每个SQL语句,他由多行组成,sql.splitlines()数组中是每行,挑选出不是空白字符的,也不是空字符串''的,也不是--注释的。
# 即保留有效的语句。
filtered = filter(lambda x: (not x.lstrip().startswith("--")) and (not x.isspace()) and (not x.strip() == ''),
sql.splitlines())
# 下面数组的元素是SQL语句有效的行
filtered = list(filtered)
# 有效的行数>0,才执行
if len(filtered) > 0:
df = spark.sql(sql)
# 如果有效的SQL语句是select开头的,则打印数据。
if filtered[0].lstrip().startswith("select"):
df.show(100)
if __name__ == '__main__':
print("保险项目的spark程序的入口:")
# 1- 创建 SparkSession对象: 支持与HIVE的集成
spark = SparkSession \
.builder \
.master("local[*]") \
.appName("insurance_main") \
.config("spark.sql.shuffle.partitions", 4) \
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse") \
.config("hive.metastore.uris", "thrift://node1:9083") \
.enableHiveSupport() \
.getOrCreate()
# 2) 编写SQL执行:
executeSQLFile('04_insurance_dw_prem_std.sql')4.3.4 完成步骤四

# 定义lx的函数 udaf_lx
@F.pandas_udf('decimal(17,12)')
def udaf_lx(lx:pd.Series,qx:pd.Series) -> decimal :
tmp_lx = decimal.Decimal(0)
tmp_qx = decimal.Decimal(0)
for i in range(len(lx)):
if i == 0:
tmp_lx = decimal.Decimal(lx[0])
tmp_qx = decimal.Decimal(qx[0])
else:
tmp_lx = (tmp_lx * (1- tmp_qx)).quantize(decimal.Decimal('0.000000000000'))
tmp_qx = decimal.Decimal(qx[0])
return tmp_lx
spark.udf.register('udaf_lx',udaf_lx)--步骤四:lx
create or replace view insurance_dw.prem_src4_1 as
select
t1.*,
if(policy_year = 1,1,null) as lx
from insurance_dw.prem_src3 t1;
--步骤4_2:lx
-- 通过对 ppp(缴费期)sex age_buy(投保年龄) 分组,即可将每组中对应的保单年度放置在一组内,进行计算操作
drop table if exists insurance_dw.prem_src4;
create table if not exists insurance_dw.prem_src4 as
select
*,
udaf_lx(lx,qx) over(partition by ppp,sex,age_buy order by policy_year) as lx
from insurance_dw.prem_src4_1;4.3.5 完成步骤五


# 定义lx_d,dx_,dx_ci的函数 udaf_lx
@F.pandas_udf('string')
def udaf_3col(lx_d:pd.Series, qx_d:pd.Series, qx_ci:pd.Series) -> str:
tmp_lx_d = decimal.Decimal(0)
tmp_dx_d = decimal.Decimal(0)
tmp_dx_ci = decimal.Decimal(0)
for i in range(len(lx_d)):
if i == 0 :
tmp_lx_d = decimal.Decimal(lx_d[i])
tmp_dx_d = decimal.Decimal(qx_d[i])
tmp_dx_ci = decimal.Decimal(qx_ci[i])
else:
tmp_lx_d =(tmp_lx_d - tmp_dx_d - tmp_dx_ci).quantize(decimal.Decimal('0.000000000000'))
tmp_dx_d = (tmp_lx_d * qx_d[i]).quantize(decimal.Decimal('0.000000000000'))
tmp_dx_ci = (tmp_lx_d * qx_ci[i]).quantize(decimal.Decimal('0.000000000000'))
return str(tmp_lx_d)+','+str(tmp_dx_d)+','+str(tmp_dx_ci)
spark.udf.register('udaf_3col', udaf_3col)
--步骤五:lx_d dx_d dx_ci
--5_1
create or replace view insurance_dw.prem_src5_1 as
select *,
if(policy_year = 1, 1, null) as lx_d,
if(policy_year = 1, qx_d, null) as dx_d,
if(policy_year = 1, qx_ci, null) as dx_ci
from insurance_dw.prem_src4_2;
--5_2
drop table if exists insurance_dw.prem_src5_2;
create table if not exists insurance_dw.prem_src5_2 as
select age_buy,
Nursing_Age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
ppp_,
bpp_,
qx,
kx,
qx_ci,
qx_d,
lx,
udaf_3col(lx_d, qx_d, qx_ci) over (partition by ppp,sex,age_buy order by policy_year) as 3col
from insurance_dw.prem_src5_1;
-- 5_3最后:将三列合并数据切割开,,形成三列结果数热
create or replace view insurance_dw.prem_src5_3 as
select age_buy,
Nursing_Age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
ppp_,
bpp_,
qx,
kx,
qx_ci,
qx_d,
lx,
cast(split(3col,',')[0] as decimal(17,12)) as lx_d,
cast(split(3col,',')[0] as decimal(17,12)) as dx_d,
cast(split(3col,',')[0] as decimal(17,12)) as dx_ci
from insurance_dw.prem_src5_2;4.3.6 完成步骤六

--步骤六:cx
-- pow()幂次方计算
-- pow((1+interest_rate),(age+1) ) => 1+interest_rate)^(age+1)
create or replace view insurance_dw.prem_src6 as
select
*,
dx_d / pow((1+interest_rate),(age+1) ) as cx
from insurance_dw.prem_src5_3;4.3.7 完成步骤七

--步骤七:cx_ ci_cx
create or replace view insurance_dw.prem_src7 as
select
*,
cx * pow((1+interest_rate),0.5) as cx_,
dx_ci / pow((1+interest_rate),(age+1)) as ci_cx
from insurance_dw.prem_src6;4.3.8 完成步骤八

--步骤八:ci_cx_ dx dx_d_
create or replace view insurance_dw.prem_src8 as
select
*,
ci_cx * pow((1+interest_rate),0.5) as ci_cx_,
lx / pow((1+interest_rate),age) as dx,
lx_d / pow((1+interest_rate),age) as dx_d_
from insurance_dw.prem_src7;4.3.9 完成步骤九

--步骤九:expense DB1 db2_factor
create or replace view insurance_dw.prem_src9 as
select t1.*,
(
case
when t1.policy_year = 1 then t2.r1
when t1.policy_year = 2 then t2.r2
when t1.policy_year = 3 then t2.r3
when t1.policy_year = 4 then t2.r4
when t1.policy_year = 5 then t2.r5
else t2.r6_
end
) * t1.ppp_ as expense,
t3.Disability_Ratio * t1.bpp_ as db1,
(
if(t1.age < t1.Nursing_Age, 1, 0)
) * t3.Nursing_Ratio as db2_factor
from insurance_dw.prem_src8 t1
join insurance_ods.pre_add_exp_ratio t2 on t1.ppp = t2.PPP
join insurance_dw.input t3 on 1 = 1;4.3.10 完成步骤十

--步骤十:db2 db3 db4 db5
-- least() 即在多列中取最小值
--least() => if( t1.ppp > t1.policy_year, t1.policy_year ,t1.ppp)
create or replace view insurance_dw.prem_src10 as
select t1.*,
(
sum(t1.dx * t1.db2_factor)
over (partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between current row and unbounded following)
) / t1.dx as db2,
(
if(t1.age >= t1.Nursing_Age, 1, 0)
) * t2.Nursing_Ratio as db3,
least(t1.ppp, t1.policy_year) as db4,
(
ifnull(sum(t1.dx * t1.ppp_)
over (partition by ppp,sex,age_buy order by policy_year rows between 1 following and unbounded following),
0)
/ t1.dx
) * pow((1 + t1.interest_rate), 0.5) as db5
from insurance_dw.prem_src9 t1
join insurance_dw.input t2 on 1 = 1;保存至目标表
--将保费参数因于的数灌入到目标表
insert overwrite table insurance_dw.prem_src
select age_buy,
nursing_age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
qx,
kx,
qx_d,
qx_ci,
dx_d,
dx_ci,
lx,
lx_d,
cx,
cx_,
ci_cx,
ci_cx_,
dx,
dx_d_,
ppp_,
bpp_,
expense,
db1,
db2_factor,
db2,
db3,
db4,
db5
from insurance_dw.prem_src10;
select count(1) from insurance_dw.prem_src;4.4 计算保费
4.4.1 完成步骤十一
1-在DW层创建用于保存最终保费的结果表:
思考: 保费结果表,应该有那些字段呢?投保年龄,性别,缴费期,保费
-- 创建保费的结果表 drop table if exists insurance_dw.prem_std; create table if not exists insurance_dw.prem_std( age_buy smallint comment '年投保龄', sex string comment '性别', ppp smallint comment '缴费期', bpp string comment '保障期', prem decimal(14, 6) comment '每期交的保费' ) comment '标准保费结果表' row format delimited fields terminated by '\t' location 'hdfs://node1:8020/user/hive/warehouse/insurance_dw.db/prem_std';注意: 建表语句放置在 _02_insurance_create_dw_table.sql 建表SQL脚本中
-- 步骤 11: 计算保费前的中间结果值: 先分组, 然后进行统计
create or replace view insurance_dw.prem_std_src11 as
select
ppp, sex, age_buy,
sum(
if(policy_year = 1, 0.5 * ci_cx_ * db1 * pow((1 + interest_rate), -0.25),
ci_cx_ * db1)
) as t11,
sum(
if(policy_year = 1, 0.5 * ci_cx_ * db2 * pow((1 + interest_rate), -0.25),
ci_cx_ * db2)
) as v11,
sum(dx * db3) as w11,
sum(dx * ppp_) as q11,
sum(
if(policy_year = 1, 0.5 * ci_cx_ * pow((1 + interest_rate), 0.25), 0)
) as t9,
sum(
if(policy_year = 1, 0.5 * ci_cx_ * pow((1 + interest_rate), 0.25), 0)
) as v9,
sum(dx * expense) as s11,
sum(cx_ * db4) as x11,
sum(ci_cx_ * db5) as y11
from insurance_dw.prem_src
group by ppp, sex, age_buy;
4.4.2 完成步骤十二
-- 步骤十二: 核算保费:
create or replace view insurance_dw.prem_std_src12 as
select
t1.age_buy,
t1.sex,
t1.ppp,
106-t1.age_buy as bpp,
input.sa * (t1.t11 + t1.v11 + t1.w11) / (t1.q11 -t1.t9 - t1.v9 -t1.s11 - t1.x11 - t1.y11) as prem
from insurance_dw.prem_std_src11 t1 join insurance_dw.input on 1=1 ;
-- 校验:
select * from insurance_dw.prem_std_src12 where age_buy = 50 and sex = 'M' and ppp = 20;4.4.3 将保费信息数据保存目标表
insert overwrite table insurance_dw.prem_std
select
age_buy,
sex,
ppp,
bpp,
prem
from insurance_dw.prem_std_src12;
-- 校验数据
select count(1) from insurance_dw.prem_std;
select * from insurance_dw.prem_std where age_buy = 50 and sex = 'M' and ppp = 20;4.5 示例代码
insurance_main.py
import decimal
import os
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import pandas as pd
import pyspark.sql.functions as F
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DIRVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 工具函数(方法) :
def executeSQLFile(filename):
with open(r'../sparksql_script/' + filename, 'r') as f:
read_data = f.readlines()
# 将列表的一行一行拼接成一个长文本,就是SQL文件的内容
read_data = ''.join(read_data)
# print(read_data)
# 将文本内容按分号切割得到数组,每个元素预计是一个完整语句
arr = read_data.split(";")
# 对每个SQL,如果是空字符串或空文本,则剔除掉
# 注意,你可能认为空字符串''也算是空白字符,但其实空字符串‘’不是空白字符 ,即''.isspace()返回的是False
arr2 = list(filter(lambda x: not x.isspace() and not x == "", arr))
# print(arr2)
# 对每个SQL语句进行迭代
for sql in arr2:
# 先打印完整的SQL语句。
print(sql, ";")
# 由于SQL语句不一定有意义,比如全是--注释;,他也以分号结束,但是没有意义不用执行。
# 对每个SQL语句,他由多行组成,sql.splitlines()数组中是每行,挑选出不是空白字符的,也不是空字符串''的,也不是--注释的。
# 即保留有效的语句。
filtered = filter(lambda x: (not x.lstrip().startswith("--")) and (not x.isspace()) and (not x.strip() == ''),
sql.splitlines())
# 下面数组的元素是SQL语句有效的行
filtered = list(filtered)
# 有效的行数>0,才执行
if len(filtered) > 0:
df = spark.sql(sql)
# 如果有效的SQL语句是select开头的,则打印数据。
if filtered[0].lstrip().startswith("select"):
df.show(100)
if __name__ == '__main__':
print("保险项目的spark程序的入口:")
# 1- 创建 SparkSession对象: 支持与HIVE的集成
spark = SparkSession \
.builder \
.master("local[*]") \
.appName("insurance_main") \
.config("spark.sql.shuffle.partitions", 4) \
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse") \
.config("hive.metastore.uris", "thrift://node1:9083") \
.enableHiveSupport() \
.getOrCreate()
# 定义lx的函数 udaf_lx
@F.pandas_udf('decimal(17,12)')
def udaf_lx(lx:pd.Series,qx:pd.Series) -> decimal :
tmp_lx = decimal.Decimal(0)
tmp_qx = decimal.Decimal(0)
for i in range(len(lx)):
if i == 0:
tmp_lx = decimal.Decimal(lx[0])
tmp_qx = decimal.Decimal(qx[0])
else:
tmp_lx = (tmp_lx * (1- tmp_qx)).quantize(decimal.Decimal('0.000000000000'))
tmp_qx = decimal.Decimal(qx[0])
return tmp_lx
spark.udf.register('udaf_lx',udaf_lx)
# 定义lx_d,dx_,dx_ci的函数 udaf_lx
@F.pandas_udf('string')
def udaf_3col(lx_d:pd.Series, qx_d:pd.Series, qx_ci:pd.Series) -> str:
tmp_lx_d = decimal.Decimal(0)
tmp_dx_d = decimal.Decimal(0)
tmp_dx_ci = decimal.Decimal(0)
for i in range(0, len(lx_d)):
if i == 0:
tmp_lx_d = decimal.Decimal(lx_d[i])
tmp_dx_d = decimal.Decimal(qx_d[i])
tmp_dx_ci = decimal.Decimal(qx_ci[i])
else:
tmp_lx_d = (tmp_lx_d - tmp_dx_d - tmp_dx_ci).quantize(decimal.Decimal('0.000000000000'))
tmp_dx_d = (tmp_lx_d * qx_d[i]).quantize(decimal.Decimal('0.000000000000'))
tmp_dx_ci = (tmp_lx_d * qx_ci[i]).quantize(decimal.Decimal('0.000000000000'))
return str(tmp_lx_d) + ',' + str(tmp_dx_d) + ',' + str(tmp_dx_ci)
spark.udf.register('udaf_3col', udaf_3col)
# 2) 编写SQL执行:
executeSQLFile('04_insurance_dw_prem_std.sql')
04_insurance_dw_prem_std.sql
--开启spark精度保护
set spark.sql.decimal0perations.allowPrecisionLoss=false;
-- 此脚本用于计算保费信息:
-- 1- 先生成维度表信息(19338种)
-- 性别:
create or replace view insurance_dw.prem_src0_sex as
select stack(2, 'M', 'F') as sex;
-- 缴费期: 10 15 20 30
create or replace view insurance_dw.prem_src0_ppp as
select stack(4, 10, 15, 20, 30) as ppp;
-- 投保年龄: 18~60
create or replace view insurance_dw.prem_src0_age_buy as
select explode(sequence(18, 60)) as age_buy;
-- 保单年度:
create or replace view insurance_dw.prem_src0_policy_year as
select explode(sequence(1, 88)) as policy_year;
-- 构建一个常量标准数据表:
create or replace view insurance_dw.input as
select 0.035 interest_rate, --预定利息率(Interest Rate PREM&RSV)
0.055 interest_rate_cv,--现金价值预定利息率(Interest Rate CV)
0.0004 acci_qx,--意外身故死亡发生率(Accident_qx)
0.115 rdr,--风险贴现率(Risk Discount Rate)
10000 sa,--基本保险金额(Baisc Sum Assured)
1 average_size,--平均规模(Average Size)
1 MortRatio_Prem_0,--Mort Ratio(PREM)
1 MortRatio_RSV_0,--Mort Ratio(RSV)
1 MortRatio_CV_0,--Mort Ratio(CV)
1 CI_RATIO,--CI Ratio
6 B_time1_B,--生存金给付时间(1)—begain
59 B_time1_T,--生存金给付时间(1)-terminate
0.1 B_ratio_1,--生存金给付比例(1)
60 B_time2_B,--生存金给付时间(2)-begain
106 B_time2_T,--生存金给付时间(2)-terminate
0.1 B_ratio_2,--生存金给付比例(2)
70 MB_TIME,--祝寿金给付时间
0.2 MB_Ration,--祝寿金给付比例
0.7 RB_Per,--可分配盈余分配给客户的比例
0.7 TB_Per,--未分配盈余分配给客户的比例
1 Disability_Ratio,--残疾给付保险金保额倍数
0.1 Nursing_Ratio,--长期护理保险金保额倍数
75 Nursing_Age--长期护理保险金给付期满年龄
;
-- 组装四个维度:
create or replace view insurance_dw.prem_src0 as
select t3.age_buy,
t5.Nursing_Age,
t1.sex,
t5.B_time2_T as t_age,
t2.ppp,
t5.B_time2_T - t3.age_buy as bpp,
t5.interest_rate,
t5.sa,
t4.policy_year,
(t3.age_buy + t4.policy_year) - 1 as age
from insurance_dw.prem_src0_sex t1
join insurance_dw.prem_src0_ppp t2 on 1 = 1
join insurance_dw.prem_src0_age_buy t3 on t3.age_buy >= 18 and t3.age_buy <= 70 - t2.ppp
join insurance_dw.prem_src0_policy_year t4 on t4.policy_year >= 1 and t4.policy_year <= 106 - t3.age_buy
join insurance_dw.input as t5 on 1 = 1;
-- 校验维度表
select count(1)
from insurance_dw.prem_src0;
--====================================计算指标===================================================
-- 步骤一:计算 ppp_ 和 bpp_
create or replace view insurance_dw.prem_src1 as
select *,
if(policy_year <= ppp, 1, 0) as ppp_,
if(policy_year <= bpp, 1, 0) as bpp_
from insurance_dw.prem_src0;
--校验
select *
from insurance_dw.prem_src1
where age_buy = 45
and sex = 'F'
and ppp = 15;
--步骤二:qx kx 和 qx_ci
create or replace view insurance_dw.prem_src2 as
select t1.*,
cast((
if(
t1.age <= 105,
if(t1.sex = 'M', t3.cl1, t3.cl3),
0)
) * t2.MortRatio_Prem_0 * t1.bpp_ as decimal(17, 12)) as qx,
(
if(
t1.age <= 105,
if(t1.sex = 'M', t4.k_male, t4.k_female),
0)
) * t1.bpp_ as kx,
(
if(
t1.sex = 'M',
t4.male,
t4.female)
) * t1.bpp_ as qx_ci
from insurance_dw.prem_src1 t1
join insurance_dw.input t2 on 1 = 1
join insurance_ods.mort_10_13 t3 on t1.age = t3.age
join insurance_ods.dd_table t4 on t1.age = t4.age;
--校验
select *
from insurance_dw.prem_src2
where age_buy = 45
and sex = 'F'
and ppp = 15;
--步骤三:qx_d
create or replace view insurance_dw.prem_src3 as
select t1.*,
cast(
(
if(t1.age >= 105, t1.qx - t1.qx_ci, cast(t1.qx * (1 - t1.kx) as decimal(17, 12)))
) * t1.bpp_
as decimal(17, 12)) as qx_d
from insurance_dw.prem_src2 t1;
--校验
select *
from insurance_dw.prem_src3
where age_buy = 25
and sex = 'M'
and ppp = 20;
--步骤四:lx
create or replace view insurance_dw.prem_src4_1 as
select t1.*,
if(policy_year = 1, 1, null) as lx
from insurance_dw.prem_src3 t1;
--步骤4_2:lx
-- 通过对 ppp(缴费期)sex age_buy(投保年龄) 分组,即可将每组中对应的保单年度放置在一组内,进行计算操作
drop table if exists insurance_dw.prem_src4_2;
create table if not exists insurance_dw.prem_src4_2 as
select age_buy,
Nursing_Age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
ppp_,
bpp_,
qx,
kx,
qx_ci,
qx_d,
udaf_lx(lx, qx) over (partition by ppp,sex,age_buy order by policy_year) as lx
from insurance_dw.prem_src4_1;
--校验
select *
from insurance_dw.prem_src4_2
where age_buy = 25
and sex = 'M'
and ppp = 20;
--步骤五:lx_d dx_d dx_ci
--5_1
create or replace view insurance_dw.prem_src5_1 as
select *,
if(policy_year = 1, 1, null) as lx_d,
if(policy_year = 1, qx_d, null) as dx_d,
if(policy_year = 1, qx_ci, null) as dx_ci
from insurance_dw.prem_src4_2;
--5_2
drop table if exists insurance_dw.prem_src5_2;
create table if not exists insurance_dw.prem_src5_2 as
select age_buy,
Nursing_Age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
ppp_,
bpp_,
qx,
kx,
qx_ci,
qx_d,
lx,
udaf_3col(lx_d, qx_d, qx_ci) over (partition by ppp,sex,age_buy order by policy_year) as 3col
from insurance_dw.prem_src5_1;
-- 5_3最后:将三列合并数据切割开,,形成三列结果数热
create or replace view insurance_dw.prem_src5_3 as
select age_buy,
Nursing_Age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
ppp_,
bpp_,
qx,
kx,
qx_ci,
qx_d,
lx,
cast(split(3col, ',')[0] as decimal(17, 12)) as lx_d,
cast(split(3col, ',')[1] as decimal(17, 12)) as dx_d,
cast(split(3col, ',')[2] as decimal(17, 12)) as dx_ci
from insurance_dw.prem_src5_2;
--校验
select *
from insurance_dw.prem_src5_3
where age_buy = 25
and sex = 'M'
and ppp = 20;
--步骤六:cx
-- pow()幂次方计算
-- pow((1+interest_rate),(age+1) ) => 1+interest_rate)^(age+1)
create or replace view insurance_dw.prem_src6 as
select *,
dx_d / pow((1 + interest_rate), (age + 1)) as cx
from insurance_dw.prem_src5_3;
--校验
select *
from insurance_dw.prem_src6
where age_buy = 25
and sex = 'M'
and ppp = 20;
--步骤七:cx_ ci_cx
create or replace view insurance_dw.prem_src7 as
select *,
cx * pow((1 + interest_rate), 0.5) as cx_,
dx_ci / pow((1 + interest_rate), (age + 1)) as ci_cx
from insurance_dw.prem_src6;
--校验
select *
from insurance_dw.prem_src7
where age_buy = 25
and sex = 'M'
and ppp = 20;
--步骤八:ci_cx_ dx dx_d_
create or replace view insurance_dw.prem_src8 as
select *,
ci_cx * pow((1 + interest_rate), 0.5) as ci_cx_,
lx / pow((1 + interest_rate), age) as dx,
lx_d / pow((1 + interest_rate), age) as dx_d_
from insurance_dw.prem_src7;
--校验
select *
from insurance_dw.prem_src8
where age_buy = 25
and sex = 'M'
and ppp = 20;
--步骤九:expense DB1 db2_factor
create or replace view insurance_dw.prem_src9 as
select t1.*,
(
case
when t1.policy_year = 1 then t2.r1
when t1.policy_year = 2 then t2.r2
when t1.policy_year = 3 then t2.r3
when t1.policy_year = 4 then t2.r4
when t1.policy_year = 5 then t2.r5
else t2.r6_
end
) * t1.ppp_ as expense,
t3.Disability_Ratio * t1.bpp_ as db1,
(
if(t1.age < t1.Nursing_Age, 1, 0)
) * t3.Nursing_Ratio as db2_factor
from insurance_dw.prem_src8 t1
join insurance_ods.pre_add_exp_ratio t2 on t1.ppp = t2.PPP
join insurance_dw.input t3 on 1 = 1;
--校验
select *
from insurance_dw.prem_src9
where age_buy = 25
and sex = 'M'
and ppp = 20;
--步骤十:db2 db3 db4 db5
-- least() 即在多列中取最小值
--least() => if( t1.ppp > t1.policy_year, t1.policy_year ,t1.ppp)
create or replace view insurance_dw.prem_src10 as
select t1.*,
(
sum(t1.dx * t1.db2_factor)
over (partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between current row and unbounded following)
) / t1.dx as db2,
(
if(t1.age >= t1.Nursing_Age, 1, 0)
) * t2.Nursing_Ratio as db3,
least(t1.ppp, t1.policy_year) as db4,
(
ifnull(sum(t1.dx * t1.ppp_)
over (partition by ppp,sex,age_buy order by policy_year rows between 1 following and unbounded following),
0)
/ t1.dx
) * pow((1 + t1.interest_rate), 0.5) as db5
from insurance_dw.prem_src9 t1
join insurance_dw.input t2 on 1 = 1;
--校验
select *
from insurance_dw.prem_src10
where age_buy = 25
and sex = 'M'
and ppp = 20;
--将保费参数因于的数灌入到目标表
insert overwrite table insurance_dw.prem_src
select age_buy,
nursing_age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
qx,
kx,
qx_d,
qx_ci,
dx_d,
dx_ci,
lx,
lx_d,
cx,
cx_,
ci_cx,
ci_cx_,
dx,
dx_d_,
ppp_,
bpp_,
expense,
db1,
db2_factor,
db2,
db3,
db4,
db5
from insurance_dw.prem_src10;
select count(1)
from insurance_dw.prem_src;
-- 步骤 11: 计算保费前的中间结果值: 先分组, 然后进行统计
create or replace view insurance_dw.prem_std_src11 as
select
ppp, sex, age_buy,
sum(
if(policy_year = 1, 0.5 * ci_cx_ * db1 * pow((1 + interest_rate), -0.25),
ci_cx_ * db1)
) as t11,
sum(
if(policy_year = 1, 0.5 * ci_cx_ * db2 * pow((1 + interest_rate), -0.25),
ci_cx_ * db2)
) as v11,
sum(dx * db3) as w11,
sum(dx * ppp_) as q11,
sum(
if(policy_year = 1, 0.5 * ci_cx_ * pow((1 + interest_rate), 0.25), 0)
) as t9,
sum(
if(policy_year = 1, 0.5 * ci_cx_ * pow((1 + interest_rate), 0.25), 0)
) as v9,
sum(dx * expense) as s11,
sum(cx_ * db4) as x11,
sum(ci_cx_ * db5) as y11
from insurance_dw.prem_src
group by ppp, sex, age_buy;
select *
from insurance_dw.prem_std_src11
where age_buy = 25
and sex = 'M'
and ppp = 20;
-- 步骤十二: 核算保费:
create or replace view insurance_dw.prem_std_src12 as
select
t1.age_buy,
t1.sex,
t1.ppp,
106-t1.age_buy as bpp,
input.sa * (t1.t11 + t1.v11 + t1.w11) / (t1.q11 -t1.t9 - t1.v9 -t1.s11 - t1.x11 - t1.y11) as prem
from insurance_dw.prem_std_src11 t1 join insurance_dw.input on 1=1 ;
-- 校验:
select * from insurance_dw.prem_std_src12 where age_buy = 50 and sex = 'M' and ppp = 20;
-- 保存到目标表
insert overwrite table insurance_dw.prem_std
select
age_buy,
sex,
ppp,
bpp,
prem
from insurance_dw.prem_std_src12;
-- 校验数据
select count(1) from insurance_dw.prem_std;
select * from insurance_dw.prem_std where age_buy = 50 and sex = 'M' and ppp = 20;七、现金价值计算
1. 寿险业务简介
1.1 保单的现金价值
是保单的一种带有【储蓄】性质的价值
保险人为履行合同责任通常提存责任准备金,以备投保人中途【退保】或【解约】时,能退换给他一笔现金。
可以依据现金价值,进行保单贷款,一般是现金价值的70%
1.2 保险准备金
保险准备金(reserve)是指保险人为保证其如约履行保险【赔偿】或【给付】义务,根据政府有关法律规定或业务特定需要,从【保费】或【盈余】中提取的与其所承担的保险责任相对应的一定数量的基金。
寿险准备金是计提的保费,用来作为未来赔付的保证。准备金是衡量保险公司【偿付能力】的重要指标,偿付能力越强,保险公司信用评级越【高】。
2. 业务:计算现金价值表
-
基于 投保年龄, 性别, 缴费期 以及保单年度 来分别计算现金价值 (总条数为: 19338) 共有37个指标
需求说明 : 1- 通过对测试模板进行分析发现, 整个现金价值结果表共计有47字段(10个维度字段 + 37个指标字段) 2- 其中10个维度字段, 除了利率维度以外, 其他的维度与保费参数因子表的维度信息完全一致, 直接读取保费因子表维度数据即可(19338条) 3- 在现金价值表中, 当保单年度为0的时候, 是有意义的, 所以需要在现金价值结果表, 将保单年度为0的数据也要生成, 此数据共计有 274条, 所以总计条数为: (19338+274 = 19612) 4- 剩余的37个指标中, 有15个字段可以直接从保费参数因子表读取, 只需要计算剩余22个字段即可 操作步骤: 1- 首先在DW层构建现金价值结果表 2- 读取保费参数因子表, 从当中把所有维度以及不需要计算的指标, 全部提取出来 3- 基于提取后的结果数据, 进行横向迭代计算, 将剩余的22个指标全部计算完成 4- 将整个计算结果保存到现金价值结果表中
-
1- 创建现金价值结果表:
drop table if exists insurance_dw.cv_src;
create table if not exists insurance_dw.cv_src(
age_buy smallint comment '投保年龄',
nursing_age smallint comment '长期护理保险金给付期满年龄',
sex string comment '性别',
t_age smallint comment '满期年龄(Terminate Age)',
ppp smallint comment '交费期间(Premuim Payment Period PPP)',
bpp smallint comment '保险期间(BPP)',
interest_rate_cv decimal(6, 4) comment '现金价值预定利息率(Interest Rate CV)',
sa decimal(12, 2) comment '基本保险金额(Baisc Sum Assured)',
policy_year smallint comment '保单年度',
age smallint comment '保单年度对应的年龄',
qx decimal(8, 7) comment '死亡率',
kx decimal(8, 7) comment '残疾死亡占死亡的比例',
qx_d decimal(8, 7) comment '扣除残疾的死亡率',
qx_ci decimal(8, 7) comment '残疾率',
dx_d decimal(8, 7) comment '',
dx_ci decimal(8, 7) comment '',
lx decimal(8, 7) comment '有效保单数',
lx_d decimal(8, 7) comment '健康人数',
cx decimal(8, 7) comment '当期发生该事件的概率,如下指的是死亡发生概率',
cx_ decimal(8, 7) comment '对Cx做调整,不精确的话,可以不做',
ci_cx decimal(8, 7) comment '当期发生重疾的概率',
ci_cx_ decimal(8, 7) comment '当期发生重疾的概率,调整',
dx decimal(8, 7) comment '有效保单生存因子',
dx_d_ decimal(8, 7) comment '健康人数生存因子',
ppp_ smallint comment '是否在缴费期间,1-是,0-否',
bpp_ smallint comment '是否在保险期间,1-是,0-否',
expense decimal(8, 7) comment '附加费用率',
db1 decimal(12, 2) comment '残疾给付',
db2_factor decimal(8, 7) comment '长期护理保险金给付因子',
db2 decimal(12, 2) comment '长期护理保险金',
db3 decimal(12, 2) comment '养老关爱金',
db4 decimal(12, 2) comment '身故给付保险金',
db5 decimal(12, 2) comment '豁免保费因子',
np_ DECIMAL(12, 2) comment '净保费',
pvnp DECIMAL(17, 7) comment '净保费现值',
pvdb1 DECIMAL(17, 7) comment '',
pvdb2 DECIMAL(17, 7) comment '',
pvdb3 DECIMAL(17, 7) comment '',
pvdb4 DECIMAL(17, 7) comment '',
pvdb5 DECIMAL(17, 7) comment '',
pvr DECIMAL(17, 7) comment '保单价值准备金',
rt DECIMAL(6, 3) comment '',
np DECIMAL(17, 7) comment '修匀净保费',
sur_ben DECIMAL(17, 7) comment '生存金',
cv_1a DECIMAL(17, 7) comment '现金价值年末(生存给付前)',
cv_1b DECIMAL(17, 7) comment '现金价值年末(生存给付后)',
cv_2 DECIMAL(17, 7) comment '现金价值年中'
)comment '现金价值表(到每个保单年度)' row format delimited
fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_dw.db/cv_src';-
2- 创建 现金价值准备金 毛保费的结果表(中间临时表):
drop table if exists insurance_dw.prem_cv;
create table if not exists insurance_dw.prem_cv
(
age_buy smallint comment '年投保龄',
sex string comment '性别',
ppp smallint comment '缴费期间',
prem_cv decimal(15, 7) comment '保单价值准备金毛保险费(Preuim)'
)comment '保单价值准备金毛保险费表' row format delimited
fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_dw.db/prem_cv';2.1 步骤13~16: 价值准备金基础指标
-
步骤13:
-- 计算现金价值准备金表:
-- 1- 读取保费参数因子表, 从当中把所有维度以及不需要计算的指标, 全部提取出来
create or replace view insurance_dw.cv_src13 as
select
t1.age_buy,
t1.Nursing_Age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
t2.interest_rate_cv ,
t1.sa,
t1.policy_year,
t1.age,
t1.qx,
t1.kx,
t1.qx_d,
t1.qx_ci,
t1.dx_d,
t1.dx_ci,
t1.lx,
t1.lx_d,
t1.dx_d / pow((1+ t2.interest_rate_cv),(age+1)) as cx,
t1.ppp_,
t1.bpp_,
t1.expense,
t1.db1,
t1.db2_factor,
t1.db3,
t1.db4
from insurance_dw.prem_src10 t1
join insurance_dw.input as t2 on 1 = 1
union all
select distinct
t1.age_buy,
t1.Nursing_Age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
t2.interest_rate_cv,
t1.sa,
0 as policy_year,
NULL AS age,
NULL AS qx,
NULL AS kx,
NULL AS qx_d,
NULL AS qx_ci,
NULL AS dx_d,
NULL AS dx_ci,
NULL AS lx,
NULL AS lx_d,
NULL AS cx,
NULL AS ppp_,
NULL AS bpp_,
NULL AS expense,
NULL AS db1,
NULL AS db2_factor,
NULL AS db3,
NULL AS db4
from insurance_dw.prem_src10 t1 join insurance_dw.input as t2;
-- 校验:
select count(1) from insurance_dw.cv_src13;
select * from insurance_dw.cv_src13 where age_buy = 50 and sex = 'M' and ppp = 20 order by policy_year ;完整代码: 13~16步骤:
-- 计算现金价值准备金表:
-- 1- 读取保费参数因子表, 从当中把所有维度以及不需要计算的指标, 全部提取出来
create or replace view insurance_dw.cv_src16 as
with cv_src13 as (
select
t1.age_buy,
t1.Nursing_Age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
t2.interest_rate_cv ,
t1.sa,
t1.policy_year,
t1.age,
t1.qx,
t1.kx,
t1.qx_d,
t1.qx_ci,
t1.dx_d,
t1.dx_ci,
t1.lx,
t1.lx_d,
t1.dx_d / pow((1+ t2.interest_rate_cv),(age+1)) as cx,
t1.ppp_,
t1.bpp_,
t1.expense,
t1.db1,
t1.db2_factor,
t1.db3,
t1.db4
from insurance_dw.prem_src10 t1
join insurance_dw.input as t2 on 1 = 1
union all
select distinct
t1.age_buy,
t1.Nursing_Age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
t2.interest_rate_cv,
t1.sa,
0 as policy_year,
NULL AS age,
NULL AS qx,
NULL AS kx,
NULL AS qx_d,
NULL AS qx_ci,
NULL AS dx_d,
NULL AS dx_ci,
NULL AS lx,
NULL AS lx_d,
NULL AS cx,
NULL AS ppp_,
NULL AS bpp_,
NULL AS expense,
NULL AS db1,
NULL AS db2_factor,
NULL AS db3,
NULL AS db4
from insurance_dw.prem_src10 t1 join insurance_dw.input as t2
),
cv_src14 as (
select
*,
cx * pow((1+interest_rate_cv),0.5) as cx_,
dx_ci / pow((1+interest_rate_cv),(age+1)) as ci_cx
from cv_src13
),
cv_src15 as (
select
*,
ci_cx * pow((1+interest_rate_cv),0.5) as ci_cx_,
lx / pow((1+interest_rate_cv),age) as dx,
lx_d / pow((1+interest_rate_cv),age) as dx_d_
from cv_src14
)
select
*,
sum(dx * db2_factor) over (partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/ dx as db2 ,
(
ifnull(sum(dx * ppp_) over (partition by ppp,sex,age_buy order by policy_year rows between 1 following and unbounded following) ,0)
/ dx
) * pow((1+interest_rate_cv),0.5) as db5
from cv_src15;2.2 步骤 17~18: 计算现金价值准备金毛保费
with cv_src17 as (
select
ppp,sex,age_buy,
sum(
if(
policy_year = 1,
0.5 *ci_cx_ * db1 * pow((1+interest_rate_cv),-0.25),
ci_cx_ * db1
)
) as t11,
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * db2 * pow((1+interest_rate_cv),-0.25),
ci_cx_ * db2
)
) as v11,
sum(dx * db3) as w11,
sum(dx * ppp_) as q11,
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * pow((1+interest_rate_cv),0.25),
0
)
) as t9,
sum(
if(
policy_year = 1,
0.5 * ci_cx_ * pow((1+interest_rate_cv),0.25),
0
)
) as v9,
sum(dx * expense) as s11,
sum(cx_ * db4) as x11,
sum(ci_cx_ * db5) as y11
from insurance_dw.cv_src16
group by ppp,sex,age_buy
),
cv_src18 as (
select
t1.ppp,t1.sex,t1.age_buy,
(t2.sa *(t1.t11 + t1.v11 + t1.w11) + t3.prem * (t1.t9 + t1.v9 +t1.x11 +t1.y11)) /(t1.q11 - t1.s11) as prem_cv
from cv_src17 t1 join insurance_dw.input t2 on 1 = 1
join insurance_ods.prem_std_real t3 on t1.ppp = t3.ppp and t1.sex = t3.sex and t1.age_buy = t3.age_buy
)
-- 将毛保费结果保存到结果表中: prem_cv
insert overwrite table insurance_dw.prem_cv
select
age_buy,sex,ppp,prem_cv
from cv_src18;2.3 步骤19~23: 计算各保单年度现金价值
-- 步骤19
create or replace view insurance_dw.cv_src23 as
with cv_src19 as (
select
t1.*,
(t1.ppp_ - t1.expense) * t2.prem_cv as np_,
t2.prem_cv * sum(t1.dx *(t1.ppp_ -t1.expense)) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between current row and unbounded following)
/ t1.dx as pvnp,
if(
t1.policy_year = 1,
(
t1.sa
*
ifnull(sum(t1.ci_cx_ * t1.db1) over (partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between 1 following and unbounded following) ,0)
+
0.5 *(
(t3.prem * t1.ci_cx_ *pow((1+t1.interest_rate_cv),0.25))
+
(t1.sa * t1.db1 * t1.ci_cx_ * pow((1+t1.interest_rate_cv),-0.25))
)) / t1.dx,
t1.sa
*
sum(t1.ci_cx_ * t1.db1) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between current row and unbounded following)
/
t1.dx
) as pvdb1,
if(
t1.policy_year = 1,
(
t1.sa
*
ifnull(sum(t1.ci_cx_ * t1.db2) over (partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between 1 following and unbounded following) ,0)
+
0.5 *(
(t3.prem * t1.ci_cx_ *pow((1+t1.interest_rate_cv),0.25))
+
(t1.sa * t1.db2 * t1.ci_cx_ * pow((1+t1.interest_rate_cv),-0.25))
)) / t1.dx,
t1.sa
*
sum(t1.ci_cx_ * t1.db2) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between current row and unbounded following)
/
t1.dx
) as pvdb2,
t1.sa
*
sum(t1.dx * t1.db3) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between current row and unbounded following)
/
dx as pvdb3,
t3.prem
*
sum(t1.cx_ * t1.db4) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between current row and unbounded following)
/
dx as pvdb4,
t3.prem
*
sum(t1.ci_cx_ * t1.db5) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year rows between current row and unbounded following)
/
dx as pvdb5
from insurance_dw.cv_src16 t1 join insurance_dw.prem_cv t2 on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.age_buy = t2.age_buy
join insurance_ods.prem_std_real t3 on t1.ppp = t3.ppp and t1.sex = t3.sex and t1.age_buy = t3.age_buy
),
-- 步骤20:
cv_src20 as (
select
*,
if(
policy_year = 0 ,
null,
lead( (pvdb1 + pvdb2 +pvdb3 +pvdb4 +pvdb5 -pvnp),1,0) over(partition by ppp,sex,age_buy order by policy_year)
) as pvr,
if(
ppp = 1 ,
1,
if(
policy_year >= least(20,ppp) ,
1,
0.8 + policy_year * 0.8 / least(20,ppp)
)
) as rt
from cv_src19
),
-- 步骤21:
cv_src21 as (
select
*,
np_ * lag(rt,1,0) over (partition by ppp,sex,age_buy order by policy_year) as np,
db3 * sa as sur_ben,
rt * greatest( (pvr - lead((db3 * sa)) over (partition by ppp,sex,age_buy order by policy_year)) , 0) as cv_1b
from cv_src20
),
-- 步骤22:
cv_src22 as (
select
*,
cv_1b + lead(sur_ben,1,0) over (partition by ppp,sex,age_buy order by policy_year) as cv_1a
from cv_src21
)
-- 步骤23:
select
*,
(np + lag(cv_1b) over (partition by ppp,sex,age_buy order by policy_year) + cv_1a) /2 as cv_2
from cv_src22;
-- 校验:
select * from insurance_dw.cv_src23 where age_buy = 45 and sex = 'F' and ppp = 10;2.4 将结果灌入到目标表:
-- 将现金价值结果数据, 灌入到目标表:
insert overwrite table insurance_dw.cv_src
select
age_buy,
nursing_age,
sex,
t_age,
ppp,
bpp,
interest_rate_cv,
sa,
policy_year,
age,
qx,
kx,
qx_d,
qx_ci,
dx_d,
dx_ci,
lx,
lx_d,
cx,
cx_,
ci_cx,
ci_cx_,
dx,
dx_d_,
ppp_,
bpp_,
expense,
db1,
db2_factor,
db2,
db3,
db4,
db5,
np_,
pvnp,
pvdb1,
pvdb2,
pvdb3,
pvdb4,
pvdb5,
pvr,
rt,
np,
sur_ben,
cv_1a,
cv_1b,
cv_2
from insurance_dw.cv_src23;
-- 校验:
select * from insurance_dw.cv_src where age_buy = 45 and sex = 'F' and ppp = 10;八、保险准备金计算
保险准备金: 为了能够满足投保人的赔付或者给付义务, 需要将投保人的缴纳保费一部分, 以及投资所产生受益的一部分放入到银保监会指定的基金账户中, 用于进行对未来需要赔付或者给付提供的资金保证, 此部分资金属于保险负债
需求说明:
1- 保险准备金对于保险公司来说, 每个用户每一个投保年度对应准备金都是不一致的
2- 对于保险准备金的计算, 需要结合年龄 性别 缴费期以及投保年度 来计算每一个保单年度的准备金信息, 共计19338条数据信息
3- 保险准备金中10个维度信息数据与 保费参数因子表中维度完全一致
4- 整个保险准备金中共有33个指标需要计算:
其中可以直接从保费因子表获取的字段: qx,kx,qx_d,qx_ci,dx_d.dx_ci,lx,lx_d,CX,cx_,ci_cx ,ci_cx_,dx,dx_d,ppp_,bpp_, db2_factor
需要计算:
DB1, DB2,DB3,DB4,DB5,np_,pvnp,pvdb1,pvdb2,pvdb3,pvdb4,pvdb5,rsv1,rsv2,
rsv1_re,rsv2_re
5- 额外增加了三个字段: prem_rsv alpha beta
这三个字段在每一个保单年度的值都是一模一样的
-
1- 在DW层构建目标表: 字段数量为 43个
drop table if exists insurance_dw.rsv_src;
create table if not exists insurance_dw.rsv_src
(
age_buy smallint comment '投保年龄',
nursing_age smallint comment '长期护理保险金给付期满年龄',
sex string comment '性别',
t_age smallint comment '满期年龄(Terminate Age)',
ppp smallint comment '交费期间(Premuim Payment Period PPP)',
bpp smallint comment '保险期间(BPP)',
interest_rate decimal(6, 4) comment '预定利息率(Interest Rate PREM&RSV)',
sa decimal(12, 2) comment '基本保险金额(Baisc Sum Assured)',
policy_year smallint comment '保单年度',
age smallint comment '保单年度对应的年龄',
qx decimal(8,7) comment '死亡率',
kx decimal(8,7) comment '残疾死亡占死亡的比例',
qx_d decimal(8,7) comment '扣除残疾的死亡率',
qx_ci decimal(8,7) comment '残疾率',
dx_d decimal(8,7) comment '',
dx_ci decimal(8,7) comment '',
lx decimal(8,7) comment '有效保单数',
lx_d decimal(8,7) comment '健康人数',
cx decimal(8,7) comment '当期发生该事件的概率,如下指的是死亡发生概率',
cx_ decimal(8,7) comment '对Cx做调整,不精确的话,可以不做',
ci_cx decimal(8,7) comment '当期发生重疾的概率',
ci_cx_ decimal(8,7) comment '当期发生重疾的概率,调整',
dx decimal(8,7) comment '有效保单生存因子',
dx_d_ decimal(8,7) comment '健康人数生存因子',
ppp_ smallint comment '是否在缴费期间,1-是,0-否',
bpp_ smallint comment '是否在保险期间,1-是,0-否',
db1 decimal(12, 2) comment '残疾给付',
db2_factor decimal(8, 7) comment '长期护理保险金给付因子',
db2 decimal(12, 2) comment '长期护理保险金',
db3 decimal(12, 2) comment '养老关爱金',
db4 decimal(12, 2) comment '身故给付保险金',
db5 decimal(12, 2) comment '豁免保费因子',
np_ decimal(12, 2) comment '修正纯保费',
pvnp decimal(17, 7) comment '修正纯保费现值',
pvdb1 decimal(17, 7) comment '',
pvdb2 decimal(17, 7) comment '',
pvdb3 decimal(17, 7) comment '',
pvdb4 decimal(17, 7) comment '',
pvdb5 decimal(17, 7) comment '',
prem_rsv decimal(17, 7) comment '保险费(Preuim)',
alpha decimal(17, 7) comment '修正纯保费首年',
beta decimal(17, 7) comment '修正纯保费续年',
rsv1 decimal(17, 7) comment '准备金年末',
rsv2 decimal(17, 7) comment '准备金年初(未加当年初纯保费)',
rsv1_re decimal(17, 7) comment '修正责任准备金年末',
rsv2_re decimal(17, 7) comment '修正责任准备金年初(未加当年初纯保费)'
)comment '准备金表(到每个保单年度)' row format delimited
fields terminated by ','
location 'hdfs://node1:8020/user/hive/warehouse/insurance_dw.db/rsv_src';
完成计算操作: 基于分组的方案实现
-- 用于计算保险准备金:
-- 开启spark的精度保护:
set spark.sql.decimalOperations.allowPrecisionLoss=false;
-- 步骤24: 读取保费参数因子表, 从中将所有维度以及不需要计算的指标全部抽取出来
with rsv_src24 as (
select
t1.age_buy,
t1.nursing_age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
t1.interest_rate,
t1.sa,
t1.policy_year,
t1.age,
t1.qx,
t1.kx,
t1.qx_d,
t1.qx_ci,
t1.dx_d,
t1.dx_ci,
t1.lx,
t1.lx_d,
t1.cx,
t1.cx_,
t1.ci_cx,
t1.ci_cx_,
t1.dx,
t1.dx_d_,
t1.ppp_,
t1.bpp_,
t1.db2_factor,
if(
t1.policy_year = 1,
0.5 * (t1.sa * t1.db1 * pow((1 + t1.interest_rate),-0.25) + t2.prem * pow((1+t1.interest_rate),0.25) ),
t1.sa * t1.db1
) as db1,
if(
t1.policy_year = 1,
0.5 * (t1.sa * t1.db2 * pow((1 + t1.interest_rate),-0.25) + t2.prem * pow((1+t1.interest_rate),0.25) ),
t1.sa * t1.db2
) as db2,
t1.sa * t1.db3 as db3,
t2.prem * t1.db4 as db4,
t2.prem * t1.db5 as db5,
t2.prem
from insurance_dw.prem_src10 t1
join insurance_ods.prem_std_real t2 on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.age_buy = t2.age_buy
),
rsv_src25 as (
select
*,
sum(ci_cx_ * db1) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb1,
sum(ci_cx_ * db2) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb2,
sum(dx * db3) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb3,
sum(cx_ * db4) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb4,
sum(ci_cx_ * db5) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb5
from rsv_src24
),
rsv_src26 as (
select
ppp,sex,age_buy,
sum(
if( policy_year = 1 , pvdb1 + pvdb2 +pvdb3 +pvdb4 +pvdb5 , 0)
)
/
sum(dx * ppp_)
*
sum(
if(policy_year =1 ,dx , 0)
) as prem_rsv
from rsv_src25
group by ppp,sex,age_buy
),
rsv_src27 as (
select
t1.ppp,t1.sex,t1.age_buy,t2.prem_rsv,
sum(
if(
t1.ppp = 1 ,
t2.prem_rsv,
if(
policy_year = 1,
((t1.db1 + t1.db2 + t1.db5) * t1.ci_cx_ + t1.db3 * t1.dx + t1.cx_ * t1.db4) / t1.dx,
0
)
)
) as alpha
from rsv_src25 t1 join rsv_src26 t2 on t1.age_buy = t2.age_buy and t1.sex =t2.sex and t1.ppp = t2.ppp
group by t1.ppp,t1.sex,t1.age_buy,t2.prem_rsv
),
rsv_src28 as (
select
t1.ppp,t1.sex,t1.age_buy,t2.prem_rsv,t2.alpha,
if(
t1.ppp = 1,
0,
t2.prem_rsv
+
(t2.prem_rsv - t2.alpha)
/
sum(
if(
t1.policy_year >= 2,
t1.dx * ppp_,
0
)
)
*
sum(
if(policy_year = 1 ,dx,0)
)
) as beta
from rsv_src25 t1 join rsv_src27 t2 on t1.age_buy = t2.age_buy and t1.sex =t2.sex and t1.ppp = t2.ppp
group by t1.ppp,t1.sex,t1.age_buy,t2.prem_rsv,t2.alpha
),
rsv_src29 as (
select
t1.*,
t2.prem_rsv,
t2.alpha,
t2.beta,
if(
t1.policy_year = 1,
t2.alpha,
least(t1.prem,t2.beta)
) * t1.ppp_ as np_
from rsv_src25 t1 join rsv_src28 t2 on t1.age_buy = t2.age_buy and t1.sex =t2.sex and t1.ppp = t2.ppp
),
rsv_src30 as (
select
*,
sum(dx * np_) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvnp
from rsv_src29
),
rsv_src31 as (
select
*,
lead((pvdb1+pvdb2+pvdb3+pvdb4+pvdb5-pvnp),1,0) over (partition by ppp,sex,age_buy order by policy_year ) as rsv1
from rsv_src30
),
rsv_src32 as (
select
*,
lag(rsv1,1,0) over (partition by ppp,sex,age_buy order by policy_year ) - db3 as rsv2
from rsv_src31
),
rsv_src33 as (
select
t1.*,
greatest(t1.rsv1, t2.cv_1a ) as rsv1_re,
greatest(
t1.rsv2,
lag(t2.cv_1b,1,0) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year)
) as rsv2_re
from rsv_src32 t1 join insurance_dw.cv_src t2
on t1.age_buy = t2.age_buy and t1.ppp = t2.ppp and t1.sex =t2.sex and t1.policy_year = t2.policy_year
)
insert overwrite table insurance_dw.rsv_src
select
age_buy,
nursing_age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
qx,
kx,
qx_d,
qx_ci,
dx_d,
dx_ci,
lx,
lx_d,
cx,
cx_,
ci_cx,
ci_cx_,
dx,
dx_d_,
ppp_,
bpp_,
db1,
db2_factor,
db2,
db3,
db4,
db5,
np_,
pvnp,
pvdb1,
pvdb2,
pvdb3,
pvdb4,
pvdb5,
prem_rsv,
alpha,
beta,
rsv1,
rsv2,
rsv1_re,
rsv2_re
from rsv_src33;
-- 校验:
select count(1) from insurance_dw.rsv_src;
select * from insurance_dw.rsv_src where ppp = 20 and sex = 'F' and age_buy = 30;基于窗口函数实现: 第二种方式
-- 用于计算保险准备金:
-- 开启spark的精度保护:
set spark.sql.decimalOperations.allowPrecisionLoss=false;
-- 步骤24: 读取保费参数因子表, 从中将所有维度以及不需要计算的指标全部抽取出来
with rsv_src24 as (
select
t1.age_buy,
t1.nursing_age,
t1.sex,
t1.t_age,
t1.ppp,
t1.bpp,
t1.interest_rate,
t1.sa,
t1.policy_year,
t1.age,
t1.qx,
t1.kx,
t1.qx_d,
t1.qx_ci,
t1.dx_d,
t1.dx_ci,
t1.lx,
t1.lx_d,
t1.cx,
t1.cx_,
t1.ci_cx,
t1.ci_cx_,
t1.dx,
t1.dx_d_,
t1.ppp_,
t1.bpp_,
t1.db2_factor,
if(
t1.policy_year = 1,
0.5 * (t1.sa * t1.db1 * pow((1 + t1.interest_rate),-0.25) + t2.prem * pow((1+t1.interest_rate),0.25) ),
t1.sa * t1.db1
) as db1,
if(
t1.policy_year = 1,
0.5 * (t1.sa * t1.db2 * pow((1 + t1.interest_rate),-0.25) + t2.prem * pow((1+t1.interest_rate),0.25) ),
t1.sa * t1.db2
) as db2,
t1.sa * t1.db3 as db3,
t2.prem * t1.db4 as db4,
t2.prem * t1.db5 as db5,
t2.prem
from insurance_dw.prem_src10 t1
join insurance_ods.prem_std_real t2 on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.age_buy = t2.age_buy
),
rsv_src25 as (
select
*,
sum(ci_cx_ * db1) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb1,
sum(ci_cx_ * db2) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb2,
sum(dx * db3) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb3,
sum(cx_ * db4) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb4,
sum(ci_cx_ * db5) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvdb5
from rsv_src24
),
rsv_src26 as (
select
*,
sum(
if(
policy_year = 1 ,
pvdb1 + pvdb2 + pvdb3 +pvdb4 + pvdb5,
0
)
) over (partition by ppp,sex,age_buy)
/
sum(dx * ppp_) over (partition by ppp,sex,age_buy)
*
sum(
if(policy_year = 1 ,dx,0)
) over (partition by ppp,sex,age_buy) AS prem_rsv
from rsv_src25
),
rsv_src27 as (
select
*,
sum(
if(
ppp = 1 ,
prem_rsv,
if(
policy_year = 1,
((db1 + db2 + db5) * ci_cx_ + db3 * dx + cx_ * db4) / dx,
0
)
)
) over(partition by ppp,sex,age_buy ) as alpha
from rsv_src26
),
rsv_src28 as (
select
*,
if(
ppp = 1,
0,
prem_rsv
+
(prem_rsv - alpha)
/
sum(
if(
policy_year >= 2,
dx * ppp_,
0
)
) over (partition by ppp,sex,age_buy )
*
sum(
if(policy_year = 1 ,dx,0)
) over (partition by ppp,sex,age_buy )
) as beta
from rsv_src27
),
rsv_src29 as (
select
*,
if(
policy_year = 1,
alpha,
least(prem,beta)
) * ppp_ as np_
from rsv_src28
),
rsv_src30 as (
select
*,
sum(dx * np_) over(partition by ppp,sex,age_buy order by policy_year rows between current row and unbounded following)
/
dx as pvnp
from rsv_src29
),
rsv_src31 as (
select
*,
lead((pvdb1+pvdb2+pvdb3+pvdb4+pvdb5-pvnp),1,0) over (partition by ppp,sex,age_buy order by policy_year ) as rsv1
from rsv_src30
),
rsv_src32 as (
select
*,
lag(rsv1,1,0) over (partition by ppp,sex,age_buy order by policy_year ) - db3 as rsv2
from rsv_src31
),
rsv_src33 as (
select
t1.*,
greatest(t1.rsv1, t2.cv_1a ) as rsv1_re,
greatest(
t1.rsv2,
lag(t2.cv_1b,1,0) over(partition by t1.ppp,t1.sex,t1.age_buy order by t1.policy_year)
) as rsv2_re
from rsv_src32 t1 join insurance_dw.cv_src t2
on t1.age_buy = t2.age_buy and t1.ppp = t2.ppp and t1.sex =t2.sex and t1.policy_year = t2.policy_year
)
insert overwrite table insurance_dw.rsv_src
select
age_buy,
nursing_age,
sex,
t_age,
ppp,
bpp,
interest_rate,
sa,
policy_year,
age,
qx,
kx,
qx_d,
qx_ci,
dx_d,
dx_ci,
lx,
lx_d,
cx,
cx_,
ci_cx,
ci_cx_,
dx,
dx_d_,
ppp_,
bpp_,
db1,
db2_factor,
db2,
db3,
db4,
db5,
np_,
pvnp,
pvdb1,
pvdb2,
pvdb3,
pvdb4,
pvdb5,
prem_rsv,
alpha,
beta,
rsv1,
rsv2,
rsv1_re,
rsv2_re
from rsv_src33;
-- 校验:
select count(1) from insurance_dw.rsv_src;
select * from insurance_dw.rsv_src where ppp = 20 and sex = 'F' and age_buy = 30;此种操作:利用 当窗口函数 和 聚合函数进行组合使用的时候, 如果窗口函数中没有书写order by, 相当于将整个窗口全部打开, 整对个分组数据进行聚合统计操作, 每一行的结果都是整个组的聚合结果
九、App层计算操作
1. 保险精算表生成

整个保险精算表大致有以下几个字段:
年龄 age_buy 性别 sex 缴费期 ppp 保障期 bpp 保单年度 policy year 保单年度基本保额 sa 现金价值给付前cv_1a -- 来源于 现金价值表 cv_src表 现金价值给付后cv_1b -- 来源于 现金价值表 cv_src表 生存给付金sur_ben -- 来源于 现金价值表 cv_src表 纯保费(NP)CV.NP -- 来源于 现金价值表 cv_src表 年初责任准备金rsv2_re -- 来源于 保险准备金表 rsv_src表 年末责任准备金rsv1_re -- 来源于 保险准备金表 rsv_src表 纯保费(RSV) RSV.np_ -- 来源于 保险准备金表 rsv_src表
构建保险精算表:
drop database if exists insurance_app;
create database if not exists insurance_app location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db';
drop table if exists insurance_app.policy_actuary;
create table if not exists insurance_app.policy_actuary(
age_buy smallint comment '投保年龄',
sex string comment '性别',
ppp smallint comment '交费期间(Premuim Payment Period PPP)',
bpp smallint comment '保险期间(BPP)',
policy_year smallint comment '保单年度',
sa decimal(12, 2) comment '基本保险金额(Baisc Sum Assured)',
cv_1a decimal(17, 7) comment '现金价值年末(生存给付前)',
cv_1b decimal(17, 7) comment '现金价值年末(生存给付后)',
sur_ben decimal(17, 7) comment '生存金',
np decimal(17, 7) comment '修匀净保费',
rsv2_re decimal(17, 7) comment '修正责任准备金年初(未加当年初纯保费)',
rsv1_re decimal(17) comment '修正责任准备金年末',
np_ decimal(12) comment '修正纯保费'
) comment '产品精算数据表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db/policy_actuary';将数据导入到保险精算表中:
-- 1- 计算 保险精算结果表:
insert overwrite table insurance_app.policy_actuary
select
t1.age_buy,
t1.sex,
t1.ppp,
t1.bpp,
t1.policy_year,
t1.sa,
t1.cv_1a,
t1.cv_1b,
t1.sur_ben,
t1.np,
t2.rsv2_re,
t2.rsv1_re,
t2.np_
from insurance_dw.cv_src t1 join insurance_dw.rsv_src t2
on t1.age_buy = t2.age_buy and t1.ppp = t2.ppp and t1.sex = t2.sex and t1.policy_year = t2.policy_year;
-- 校验:
select count(1) from insurance_app.policy_actuary;2. 如何将数据导出到MySQL中
导出的方案:
-
1- 通过 sqoop完成数据导出
-
2- 通过Spark SQL 完成数据导出
基本格式:
df
.write
.mode('append|overwrite|ignore|error')
.format('csv|json|orc|parquet|jdbc')
.option()
.save()
导出到MySQL:
df
.write
.mode('overwrite')
.format('jdbc')
.option('url','jdbc:mysql://node1:3306/xxx')
.option('dbtable','目标表')
.option('user','用户名')
.option('password','密码')
.save()
-
1- 现在Mysql中创建库和表:
create database if not exists insurance_app character set utf8 ;
drop table if exists insurance_app.policy_actuary;
create table if not exists insurance_app.policy_actuary(
age_buy smallint comment '投保年龄',
sex varchar(10) comment '性别',
ppp smallint comment '交费期间(Premuim Payment Period PPP)',
bpp smallint comment '保险期间(BPP)',
policy_year smallint comment '保单年度',
sa decimal(12, 2) comment '基本保险金额(Baisc Sum Assured)',
cv_1a decimal(17, 7) comment '现金价值年末(生存给付前)',
cv_1b decimal(17, 7) comment '现金价值年末(生存给付后)',
sur_ben decimal(17, 7) comment '生存金',
np decimal(17, 7) comment '修匀净保费',
rsv2_re decimal(17, 7) comment '修正责任准备金年初(未加当年初纯保费)',
rsv1_re decimal(17) comment '修正责任准备金年末',
np_ decimal(12) comment '修正纯保费'
) comment '产品精算数据表';-
通过spark SQL完成数据导出:
# 3) 将保险精算结果表导出到MYSQL中:
df = spark.sql("""
select
t1.age_buy,
t1.sex,
t1.ppp,
t1.bpp,
t1.policy_year,
t1.sa,
t1.cv_1a,
t1.cv_1b,
t1.sur_ben,
t1.np,
t2.rsv2_re,
t2.rsv1_re,
t2.np_
from insurance_dw.cv_src t1 join insurance_dw.rsv_src t2
on t1.age_buy = t2.age_buy and t1.ppp = t2.ppp and t1.sex = t2.sex and t1.policy_year = t2.policy_year;
""")
# 设置缓存, 将其缓存到内存中, 如果内存放不下, 放置到磁盘上
df.persist(storageLevel=StorageLevel.MEMORY_AND_DISK).count()
df.createTempView('t1')
# 3.1 将这个结果灌入到 HIVE的APP层库中
spark.sql("""
insert overwrite table insurance_app.policy_actuary
select * from t1
""")
# 3.2 将这个结果灌入到 mysql的APP层库中
df.write.jdbc(
"jdbc:mysql://node1:3306/insurance_app?createDatabaseIfNotExist=true&serverTimezone=UTC&characterEncoding=utf8&useUnicode=true",
'policy_actuary',
'overwrite',
{'user': 'root', 'password': '123456'}
)3.指标计算
3.1 计算某个月份各个客户应交保费
需求:
1、 请结合客户投保详情表,计算当月客户的精算现金价值、准备金信息和现在的应交保费。
2、 每月统计一次
3、 结果按月分区
4、 各字段的取数或计算逻辑如下


-
1- 将目标表创建:
drop table if exists insurance_app.policy_result;
create table if not exists insurance_app.policy_result
(
pol_no STRING COMMENT '保单号',
user_id string comment '客户id',
name string comment '姓名',
sex string comment '性别',
birthday string comment '出生日期',
ppp string comment '缴费期',
age_buy bigint comment '投保年龄',
buy_datetime string comment '投保日期',
insur_name STRING COMMENT '保险名称',
insur_code STRING COMMENT '保险代码',
province string comment '所在省份',
city string comment '所在城市',
direction String comment '所在区域',
bpp smallint comment '保险期间,保障期',
policy_year smallint comment '保单年度',
sa decimal(12, 2) comment '保单年度基本保额',
cv_1a decimal(17, 7) comment '现金价值给付前',
cv_1b decimal(17, 7) comment '现金价值给付后',
sur_ben decimal(17, 7) comment '生存给付金',
np decimal(17, 7) comment '纯保费(CV.NP)',
rsv2_re decimal(17, 7) comment '年初责任准备金',
rsv1_re decimal(17, 7) comment '年末责任准备金',
np_ decimal(12, 2) comment '纯保费(RSV.np_) ',
prem_std decimal(14, 6) comment '每期交保费',
prem_thismonth decimal(14, 6) comment '本月应交保费'
) partitioned by (month string)
comment '客户保单精算结果表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db/policy_result';-- 思考: 如果计算用户购买的这个保单, 截止到 2021-03月份 已经到了第几个保单年度了呢?
-- 计算规则: 向下取整[(当前时间月份 - 用户投保日期月份 ) / 12 ]+ 1 = 投保年度
-- 2021-04 计算日期 2022-04月 / 12 = 1
-- 如何进行日期之间计算呢?
-- 向上取整: ceil()
-- 向下取整: floor()
select floor(months_between('2022-04','2021-04-15') / 12) + 1 ;-- 思考 如何从日期中获取月份信息:
select month('1942-02-27');
select substr('1942-02-27',6,2);
-- 计算某个月 客户的投保详细信息: 2021-03 动态分区 SET hive.exec.dynamic.partition.mode=nonstrict; insert overwrite table insurance_app.policy_result partition (month) -- create or replace view insurance_app.policy_result1 as select t1.pol_no, t1.user_id, t2.name, t2.sex, t2.birthday, t1.ppp, t1.age_buy, t1.buy_datetime, t1.insur_name, t1.insur_code, t2.province, t2.city, t2.direction, t3.bpp, t3.policy_year, t3.sa, t3.cv_1a, t3.cv_1b, t3.sur_ben, t3.np, t3.rsv2_re, t3.rsv1_re, t3.np_, t4.prem, if( t1.ppp = 1, 0, if( t1.ppp < t3.policy_year , 0, if( substr( t1.buy_datetime,6,2) = substr('2021-04',6,2), t4.prem, 0 ) ) ) as prem_thismonth, substr('2021-04',6,2) as month from insurance_ods.policy_benefit t1 join insurance_ods.policy_client t2 on t1.user_id = t2.user_id join insurance_app.policy_actuary t3 on t2.sex = t3.sex and t1.ppp = t3.ppp and t1.age_buy = t3.age_buy and t3.policy_year = floor(months_between('2021-04',t1.buy_datetime) / 12) + 1 join insurance_ods.prem_std_real t4 on t4.sex = t2.sex and t4.age_buy = t1.age_buy and t4.ppp = t1.ppp; -- 校验; select * from insurance_app.policy_result where prem_thismonth >0;
3.2 计算保费收入增长率
1、每月计算一次。下月初计算上月的数据。
2、当月保费收入增长率prem_incre_rate= (当月末保费收入-上月末保费收入)/上月末保费收入
3、例:2021年1月31日,个险渠道保费收入为100元, 2021年2月28日,个险保费收入为110元,则,个险保费收入增长率 = 110/100 -1 = 10
-
1- 创建目标表:
drop table if exists insurance_app.app_agg_month_incre_rate;
CREATE TABLE if not exists insurance_app.app_agg_month_incre_rate
(
prem DECIMAL(24, 6) comment '本月保费收入',
last_prem DECIMAL(24, 6) comment '上月保费收入',
prem_incre_rate DECIMAL(6, 4)comment '保费收入增长率'
) partitioned by (month string comment '月份')
comment '保费收入增长率表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db/app_agg_month_incre_rate';-
2- 编写SQL:
-- 计算保费收入增长率
-- 计算当月的保费收入:
with this_month as(
select
sum(prem_thismonth) as prem
from insurance_app.policy_result where month = '2021-04'
),
-- 计算上个月的保费收入:
last_month as(
select
sum(prem_thismonth) as last_prem
from insurance_app.policy_result where month = '2021-03'
)
insert overwrite table insurance_app.app_agg_month_incre_rate partition (month)
select
prem,
last_prem,
cast((prem - last_prem) / last_prem as decimal(12,4)) as prem_incre_rate,
'2021-04' as month
from this_month join last_month on 1 =1 ;
3.3 计算首年保费与保费收入比
1、每月计算一次。下月初计算上月的数据。
2、first_of_total_prem= 首年保费收入/保费收入
drop TABLE if exists insurance_app.app_agg_month_first_of_total_prem;
CREATE TABLE if not exists insurance_app.app_agg_month_first_of_total_prem
(
first_prem DECIMAL(24, 6),
total_prem DECIMAL(24, 6),
first_of_total_prem DECIMAL(8, 6)
) partitioned by (month string comment '月份')
comment '首年保费与保费收入比表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db/app_agg_month_first_of_total_prem';-- 计算首年保费与保费收入比:
-- 思考 首年保费如何计算: 有多少张保单, 那么将每一张保单的保费累加在一起就可以得到首年总保费
-- 思考: 总保费如何计算: 保费 * 缴费年限
-- 如何确定缴费年限: 这三种情况 谁小 选择 谁
-- 1- 保单年度 > 缴费期 , 缴费年限 = 缴费期
-- 2- 保单年度 <= 缴费期 , 缴费年限 = 保单年度
-- 3- 退保日期 < 缴费期, 缴费年限 = 截止到退保日期的保单年度
with t1 as (
select
t1.prem_std,
least(
t1.policy_year,
cast(t1.ppp as int),
floor(months_between(t2.elapse_date,t1.buy_datetime) / 12) + 1
) as ppp_year
from insurance_app.policy_result t1
left join insurance_ods.policy_surrender t2 on t1.pol_no = t2.pol_no and t1.month = '2021-04'
)
insert overwrite table insurance_app.app_agg_month_first_of_total_prem partition (month='2021-04')
select
sum(prem_std) as first_prem ,
sum(prem_std * ppp_year) as total_prem,
sum(prem_std) / sum(prem_std * ppp_year) as first_of_total_prem
from t1;
3.4 个人营销渠道的件均保费
1、每月计算一次。下月初计算上月的数据。
2、个人营销渠道的件均保费 premium per policy of individual marketing channel
个人营销渠道的件均保费=(本月的)个人营销渠道的首年原保费收入÷(本月的)个人营销渠道的新单件数
解释:个人营销渠道的件均保费是指个人营销渠道的首年原保费收入与新单件数的比值。
大白话:
计算: 当月产生新单的总保费 和 当月产生新单数量 计算 平均每笔保单的保费
drop TABLE if exists insurance_app.app_agg_month_premperpol;CREATE TABLE if not exists insurance_app.app_agg_month_premperpol( insur_code string comment '保险代码', insur_name string comment '保险名称', prem_per_pol DECIMAL(38, 2) comment '个人营销渠道的件均保费') partitioned by (month string comment '月份') comment '个人营销渠道的件均保费' row format delimited fields terminated by '\t'location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db/app_agg_month_premperpol';insert overwrite table insurance_app.app_agg_month_premperpol partition (month)
select
insur_code,insur_name,
cast(sum(prem_thismonth) / count( if(prem_thismonth >0, pol_no,NULL)) as decimal(38,2) ) as prem_per_pol,
'2021-04' as month
from insurance_app.policy_result where month = '2021-04'
group by insur_code,insur_name;
3.5 死亡发生率和残疾发生率
DROP TABLE if exists insurance_app.app_agg_month_mort_dis_rate;CREATE TABLE if not exists insurance_app.app_agg_month_mort_dis_rate( insur_code string comment '保险代码', insur_name string comment '保险名称', age int, sg_rate decimal(8,6), sc_rate decimal(8,6) ) partitioned by (month string comment '月份') comment '死亡发生率和残疾发生率表' row format delimited fields terminated by '\t'location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db/app_agg_month_mort_dis_rate';-- 计算 死亡发生率 =在月末时点,统计每个年龄的人群,按一岁一组,计算其中历史所有发生过死亡的保单数/所有的有效保单
-- 残疾发生率 =在月末时点,统计每个年龄的人群,按一岁一组,计算其中历史所有发生过残疾的保单数/所有的有效保单
-- 分组中年龄: 以实际发生赔付年龄为分组条件, 而不是投保年龄
with t1 as(
select
t1.insur_code,
t1.insur_name,
floor(months_between(t3.claim_date,t1.buy_datetime)/12) + t1.age_buy as age,
count( if(t3.claim_item like 'sg%',t3.pol_no,NULL) ) as sg_cnt,
count( if(t3.claim_item like 'sc%',t3.pol_no,NULL) ) as sc_cnt,
count( t1.pol_no) as total_cnt
from insurance_app.policy_result t1
left join insurance_ods.claim_info t3 on t1.pol_no = t3.pol_no
group by t1.insur_name,t1.insur_code, floor(months_between(t3.claim_date,t1.buy_datetime)/12) + t1.age_buy
),
t2 as(
select
insur_code,
insur_name,
age,
sg_cnt,
sc_cnt,
sum(total_cnt) over(partition by insur_code,insur_name)as total_cnt
from t1
)
insert overwrite table insurance_app.app_agg_month_mort_dis_rate partition (month)
select
insur_code,
insur_name,
age,
sg_cnt / total_cnt as sg_rate,
sc_cnt / total_cnt as sc_rate,
'2021-04' as month
from t2;3.6 新业务价值率
1、每月计算一次。下月初计算上月的数据。
2、新业务价值率(NBEV,New Business Embed Value)= PV(预期各年利润) / 首年保费收入
3、对一个产品的一个保单的业务价值率而言,它存在prem_std_real表中。
4、对一个产品的多张保单而言,
第1张单,期交保费100元,新业务价值率是10%
第2张单,期交保费是200元,新业务价值率是20%
则新业务价值率 = (100*10% + 200* 20%) / 300 = 16.67%
--新业务价值率
drop table if exists insurance_app.app_agg_month_nbev;
create table if not exists insurance_app.app_agg_month_nbev
(
insur_code string comment '保险代码',
insur_name string comment '保险名称',
nbev decimal(38,11) comment '新业务价值率'
) partitioned by (month string comment '月份')
comment '新业务价值率表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db/app_agg_month_nbev';
-- 计算新业务价值率:
insert overwrite table insurance_app.app_agg_month_nbev partition(month)
select
t1.insur_code,t1.insur_name,
sum(t1.prem_std * t2.nbev) / sum(t1.prem_std) as nbev,
'2021-04' as month
from insurance_app.policy_result t1 join insurance_ods.prem_std_real t2
on t1.ppp = t2.ppp and t1.sex = t2.sex and t1.age_buy = t2.age_buy
where t1.month = '2021-04'
group by t1.insur_code,t1.insur_name;3.7 高净值客户比例
1、每月计算一次。下月初计算上月的数据。
2、高净值客户,指填写的信息里,年收入超过1000万的客户
3、高净值客户比例= 高净值客户 / 总客户。例如100个客户,高净值客户10个,则高净值客户比例 = 10/100 = 10%
drop table if exists insurance_app.app_agg_month_high_net_rate;
create table if not exists insurance_app.app_agg_month_high_net_rate
(
high_net_rate decimal(8, 6) comment '高净值客户比例'
) partitioned by (month string comment '月份')
comment '高净值客户比例表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db/app_agg_month_high_net_rate';-- 高净值客户群体比例:
insert overwrite table insurance_app.app_agg_month_high_net_rate partition(month)
select
count( DISTINCT if(t1.income >= 10000000,t1.user_id,NULL) ) / count(distinct t1.user_id) as high_net_rate,
'2021-04' as month
from insurance_ods.policy_client t1 join insurance_app.policy_result t2
on t1.user_id = t2.user_id and t2.month = '2021-04';1.8 各地区的汇总保费
1、 每月计算一次。下月初计算上月的数据。
2、 依据精算数据表policy_result的当月数据,按区域分组,统计当月时刻的总投保人数,当月收取的保费汇总,当月时刻的总现金价值,总生存金,总准备金。
-
构建目标表:
drop table if exists insurance_app.app_agg_month_dir;
create table if not exists insurance_app.app_agg_month_dir
(
direction string comment '所在区域',
sum_users bigint comment '总投保人数',
sum_prem decimal(24) comment '当月保费汇总',
sum_cv_1b decimal(27,2) comment '总现金价值',
sum_sur_ben decimal(27) comment '总生存金',
sum_rsv2_re decimal(27,2) comment '总准备金'
) partitioned by (month string comment '月份')
comment '各地区的汇总保费表' row format delimited fields terminated by '\t'
location 'hdfs://node1:8020/user/hive/warehouse/insurance_app.db/app_agg_month_dir';
insert overwrite table insurance_app.app_agg_month_dir partition (month)
select
direction,
count(distinct user_id) as sum_users,
sum(prem_thismonth) as sum_prem,
sum(cv_1b) as sum_cv_1b,
sum(sur_ben) as sum_sur_ben,
sum(rsv2_re) as sum_rsv2_re,
'2021-04' as month
from insurance_app.policy_result where month = '2021-04'
group by direction;十、 项目上线至YARN平台
-
1- 需要调整python运行的脚本: 将 master参数删除即可, 或者修改为 yarn:

-
2- 删除代码中原有配置: spark.sql.shuffle.partitions 或许通过spark-submit方式来指定
-
3- 编写一个shell脚本, 在脚本中, 设置提交spark程序的脚本内容: _spark_insurance.sh
#!/bin/bash
# 如何向YARN 提交任务: spark-submit
/export/server/spark/bin/spark-submit \
--master YARN \
--deploy-mode client \
--conf 'spark.sql.shuffle.partitions'=8 \
--driver-memory 512m \
--driver-cores 1 \
--executor-memory 512m \
--executor-cores 2 \
--num-executors 2 \
--queue default \
/export/data/workspace/itcast_insurance/main/_insurance_main.py-
4- 测试脚本, 是否可以正常运行
-
5- 将需要定时的脚本, 放置到DS中, 进行定时运行即可 (app 层)
可以或出现的错误:

错误原因:
程序找不到mysql的驱动包
解决: 添加驱动包
1- 通过 spark-submit --jars jar包路径
2- 将jar包上传到HDFS的spark/jars目录中
十一、 项目相关面试题
1- 请简单介绍一下你最近做的这个项目 (请讲述你比较熟悉的项目...)如何介绍项目: 5分钟 1.1 描述项目基本情况(什么行业的项目, 项目的背景) 背景: 本次项目是一个重构项目, 之前整个项目是基于Oracle计算的, 后来管理这个项目的程序员离职了, 我们到了之后, 发现Oracle计算过程非常复杂的, 而且利用大量的存储过程, 导致我们维护非常麻烦的, 不好维度, 所以项目老大想更换一种新的方式完成整个精算计算操作, 所以后续采用spark SQL 来进行计算实现操作, 对计算流程进行了拆解, 简化难度, 提升维护性, 以及提升效率 1.2 描述出项目的架构: 技术架构 和 数据流转流程 (结合在一起来说) 1.3 描述出在本次项目, 我主要负责那一部分计算操作: 可选负责: 0- 基础数据采集操作 1- 负责保费参数因子计算 以及后续的保费计算 2- 负责现金价值指标计算 3- 负责保险准备金计算操作 4- 负责 行业业务指标统计分析 可组合: 0-1-2-4 : 适用于从0开始进入项目 0-1-3-4 : 适用于从0开始进入项目 0-1-4: 适用于从0开始进入项目, 中途接触了其他项目,后续又回来的 1-3-4 : 适合中期进入项目 1-2-4:适合中期进入项目 3-4 : 适合中期进入项目2- 结合着项目描述, 面试官会挑选它所感兴趣, 并且也是你所负责的点, 进行深入询问: 例如: 保费参数因子是什么呢? 如何完成保费参数因子计算 ? 1- 描述保费因子主要是做什么? 支撑后续的保费 保险准备金 以及现金价值计算的基础表 2- 计算流程: 详细描述出具体的操作流程 2.1 - 首先精算师提供了Excel测算模板 2.2 - 接着根据测试模板确定涉及到维度和指标 2.3 - 对指标进行分析发现, 各项指标计算存在互相依赖, 需要进行迭代计算 2.4 - 如果每个指标计算都是有比较负责的规则, 所以我先了解计算规则, 将规则形成计算流程图,在形成过程中, 与精算部分由比较深入沟通, 了解每一个指标计算方案 2.5 - 根据形成计算流程图, 开始进行指标计算, 整个计算采用横向迭代计算方案, 每一步计算操作, 都通过spark SQL 构建视图临时保存起来, 逐步往下进行, 同时在计算过程中, 使用自定义UDAF函数, 完成一些比较负责的迭代计算操作 2.6 最终完成保费参数因子表计算操作, 将结果灌入到目标表中, 共计涉及到23个指标3- 在整个计算过程中, 是否存在一些计算的难点, 或者 你认为整个计算操作, 你觉得最闪光在哪里? 经历最大挑战是什么? 可将难点: 展示能力地方 1- 自定义UDAF函数 : 遇到什么问题, 当时先采用什么方案解决的, 然后没解决掉, 有更换其他的方式, 怎么做的, 最后解决了 2- 数据量比较大, shuffle分区: 3- 精度问题4- 项目真实性的问题:5- 相关原理性问题: -- 有很多了 spark hadoop hive zookeeperpyspark的程序执行流程Driver的job的调度流程spark SQL的调度流程