概述
在armv8 架构中,它引入了更多的维度来描述内存模型,从而在此基础上进行硬件优化(但其中一些并未被主流的软件所接受),在此做一些简单的整理,更多信息请参考 Arm spec 以及 AMBA 协议。下文主要是对Memory 和 Device 两大类的模型进行解释,个人言论难免有误,如有谬误请不吝指正。
首先将物理地址空间映射分成两大类: Memory, Device。 两者最大的区别在于是否可以进cache,即Memory数据可以是 cacheable,也可以是non-cacheable,但是Device类型的一定是 non-cacheable 的。
Memory 的访存延迟使用cpu cycle来计量是非常大的, 所以为了弥补延迟差异,增加了cache,其中又为了速度和容量的权衡,cache通常又分为多级,所以 Memory cacheable是非常好理解的。对于 non-cacheable 的 memory 经常出现在boot阶段,cache 及相关管理单元还未初始化时,这时候使用 non-cacheable 来访问,不过这只是暂时的。软件中也有一句著名的话:没有什么是加一个中间层解决不了的,例如内核的page cache,memcache等,和这里原理是类似的,一切不过都是权衡。
Device 通常可以被外界改变,例如键盘输入、接收的网络包,Device状态改变时通常会有中断通知给cpu去重新访问它,所以cache Device状态通常是无意义的,并且因为会阻断访问真实的device而出错。Device 一般通过MMIO 或者 ioport等方式提供外界访问接口,而且外设的主频相对于cpu主频一般较低, 所以为了减少访问device操作的频率,除了普通的读写操作,经常还会伴随这Read Clear, Write Clear等操作,一般称之为副作用,所以Device一般是不能随意访问。
Memory 和 Device 的区别如上所属:
- Memory 在计算机的算作存储单元, 它不直接和外界进行交互,而是使用总线或类似的接口统一进行访问,不直接受外界影响。而Device在计算中算作输入和输出, 它直接和外界交互,其状态时刻在变化。
- Memory 可以随意的进行读操作,它并不会改变系统的正确性,所以经常会有投机读操作。而Device不能进行投机读操作,以防止错误地改变外设的状态。
下面我们以一张Armv8 N2的SoC框图来作为参考示例
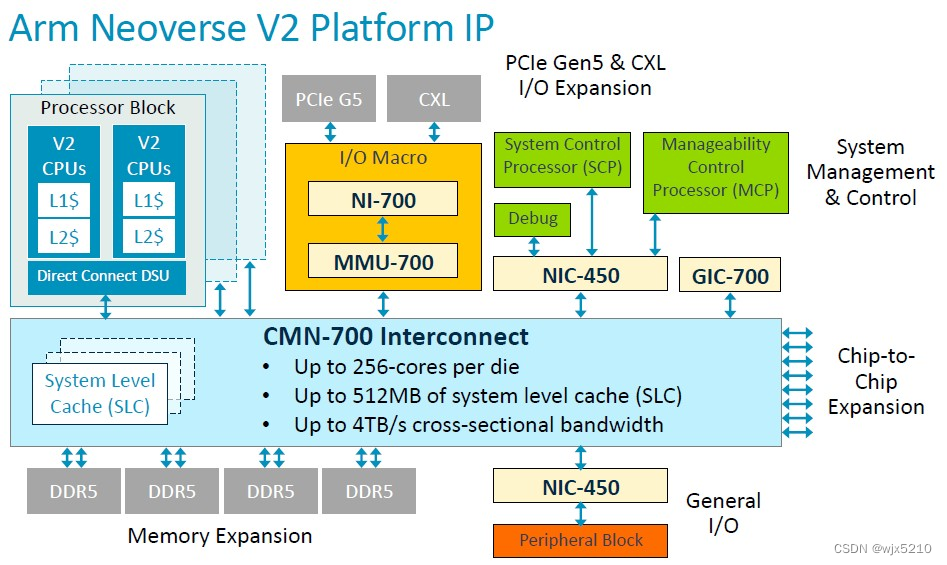
Memory 类型
先简要介绍一下cache以及cacheable属性,然后再说其他属性。
cache
首先说一下 cache 和 sram 的区别。
sram 是static ram,它是相对于dram,dram需要定时刷新来保持它内部的数据状态,而sram不需要定时刷新。sram 将一切都视作数据,并没有什么数据结构,它的接口一般都是地址、写数据、读数据,多个sram并联形成了我们通常说的多个way或者多bank的cache。但是cache并不仅仅是这些存储数据的单元,还包括sram的访问控制逻辑共同组成了cache,称之为cache controller可能更好。以L1 dcache 为例,它通常包括两种数据: tag 和 data,一般控制逻辑包括 dcache 的替换,miss时的重填,响应cache维护指令的请求等。
MESI概述
经典的cache coherence模型有MSI,MESI, MOESI,MESIF等,我们这里以使用较多的MESI为例简单介绍一下。在N2中有多个CPU,每个CPU有自己私有的cache,当两个cpu都要更新同一个cacheline时,如何处理?有两种基本模型:write-invalidate和write-update.
write-invalidate: core N要修改 X 地址时,它会将其他core X所属的cacheline全部invalidate掉,然后再更新。当其他core再次访问 X 时会发生cache miss,从而探测core N 的cache从而获取到最新数据。
write-update: core N要修改 X 地址时,它会更新自身时也会将其他core X所属的cacheline全部更新。当其他core再次访问 X 时不会发生cache miss而直接就能获得最新的数据。
因为其他core 立即访问X的几率并不大,write-update 所做的更新很可能是无用功,而且占用数据通道带宽较大,所以这种模型很少应用。而write-invalidate模型更像是一种lazy方式,需要时再获取最新数据,总体来说性能更好一下,应用广泛,MSI, MESI, MOESI, MESIF等都是基于这种模型来实现的。
MESI的状态:
- M:只有当前cache有该cacheline的数据并且是dirty状态,当invalidate或者进行其他操作时,需要将最新的数据回写到下级cache或者memory。
- E:只有当前cache有该cacheline的数据并且是clean状态。可以基于这种状态直接修改并且会变成M状态。可以自由的转变成S或I状态而无需回写操作
- S: cacheline属于share并且是clean状态(和memory中数据保持一致的说法并不确切),它此时是只读但是并不能基于这种状态进行修改,可以无条件无效掉。
- I: cacheline 处于无效状态。
下面是多个同级cache之间允许的合法状态组合:
| M | E | S | I | |
|---|---|---|---|---|
| M | x | x | x | √ |
| E | x | x | x | √ |
| S | x | x | √ | √ |
| I | √ | √ | √ | √ |
cache的基本操作以及状态转移将会放在后续的章节中详述。
多级cache概述
经典的 SoC cache一般有L1(I$, d$), L2, L3三级cache,目前高端的 SoC 配置的 cache已经超过了3级,以4级居多,在多Die互联的场景下还可能出现5级cache的情况。在4级 cache的场景中,已经不能使用L3来描述最后一级cache了,arm上称为SLC,intel称为LLC,下面我们统一以使用SLC术语。
一般 L1 cache 遵循哈弗结构,分为 L1 icache, L1 dcache,分别负责缓存指令和数据,其中 IFU(instruction fetch unit) 直接访问管理 icache , LSU (load store unit) 直接访问管理 dcache。其中 icache 和 dcache 中内部又包含元数据(tag 以及 cache状态) 和数据(sram),管理方式又有VIVT,VIPT,PIPT几种,其中 icache 以 VIPT 方式居多,dcache 以 VIPT 和 PIPT居多,暂不多展开。
从 L2 cache开始,它就是指令和数据统一可见的,arm为此引入了PoU概念。
PoU(Point of Unification):对于微架构中,它有不同的cache,通常是L1 Icache, L1 Dcache, TLB cache, 其中L1 Icache通常被实现成一个Clean的只读cache(当然会有Icache 的refill),它不需要接收snoop信息,有时候它也会包含过时的指令(self-modify),这时候一般会提供cache管理指令给软件来无效掉其中的cache数据。同理TLB也是一样的,当地址映射关系改变时,软件通过TLB管理指令来无效掉TLB cache。 Dcache是存储器读写的cache,所以它有dirty数据,那么就需要接收snoop并且在合适的时机写回到下级cache。这里有个问题,当TLB cache和Icache需要的最新数据在L1 Dcache中时怎么处理的问题,有两种做法: 1.Dcache中修改时主动invalidate Icache的数据,因为这两个都是以(va/pa)地址进行索引,但是TLB cache中是管理的va -> pa的映射关系,它必须通过va来进行索引,这就要求LSU在早期就通过va来投机无效TLB,但是TLB的修改较少,为了少数场景而频繁尝试invalidate TLB得不偿失。2. 通过软件维护Icache和TLB cache的有效性,当发生miss时,直接去L2请求数据,由L2选择是否snoop Dcache的数据。也就是在L2中做到了三种cache的数据一致性,L2就是完成PoU逻辑的部件。
之后的L3 cache 直到 SLC 的 上一级cache,他们都是中间层cache。作为中间层cache,一方面要接收来自更下层的cache 的snoop 请求,可能还需要向上转发下级的snoop。另一方面可能由于上层cache的请求引发向下的cache请求。
SLC作为最后一级cache,所有的cache对于他来说都是upper cache,它只需要响应上层cache的请求,并且snoop上层其他的cache。另一方面它读写DDR。在所有的cache miss时从DDR获取数据,在dirty数据无法在SLC中存储时写回到DDR中保存。
cache latency
另外比较关心的 L1 cache, L2 cache, L3 cache 的访问延迟,大致如下
L1 : 1-2 CPU clock cycle
L2: 10 CPU clock cycle
L3: 40 CPU clock cycle
计算时应该是end time - start time, 各级 cache 延迟差距这么大的原因并不是cache 容量导致的,这个说法应该是不准确的。
cache的容量反应在sram的容量上,容量的差异不会导致如此巨大的访问延迟,这里就需要将 cache 和 sram 分开来说了,cache 更准确的说是 cache controller,它更多的是体现为一个控制器,要完成复杂的功能控制。
以 L3 cache 的延迟举例, L2 miss 并访问 L3, 它的路径包括请求在interconnect上的延迟, L3 内部处理的延迟,数据在interconnect上的延迟。其中 L3 cache 不仅仅是管理 sram 数据, 它最重要的工作是管理 cache coherence问题,例如 snoop 其他处理器中的 cache 数据,中间又分为 snoop 在interconnect 上的延迟,处理器处理snoop 报文并且响应的延迟,snoop响应在 interconnect 上的延迟
cache 策略
在具体实现cache时,有很多细分的策略,具体包括多级cache之间的关系,读写时如何存放数据,SLC中采用snoopfilter、directory等。
首先是读写策略:
- read miss 时有两种策略 read-alloc 和 read-nonalloc。read alloc通常适用于普通的内存读,read-nonalloc通常适用于外设的读
- write miss 是也有两种对应的策略write-alloc 和non-write-alloc。write-alloc 是 write 时发生cache miss,先将整个cacheline数据填充到本地cache中,然后再写到cache中。write-nonalloc: write miss时,直接写到下层cache中,由下层cache来无效掉其他cache copy。
其次是cache的写回策略,它和上面的write miss策略有一些关系。
- writeback: write 时先将最新数据放在本地cache,在发生cache替换或者snoop时才将最新数据更新到存储中。这种在write-miss时就是write-alloc,这样才会有writeback操作。
- writethrough: write 时直接将最新数据更新到存储中,可能是cache不支持Dirty状态必须直接写到下级,代价就是写的延迟会比较大。
多级cache的互相包含关系:
- inclusive: 如果上级cache有该cacheline数据,那么本级cache一定有该cacheline数据。但是反之不成立。只有当本级cache容量远大于上级cache容量时才比较划算,否则冗余重复数据占比太会影响整体cache的性能。
- exclusive:如果上级cache有该cacheline数据,那么本级cache一定没有该cacheline数据。而且反之也成立。
- NINE(Non inclusive Non Exclusive):上级cache是否有该cacheline数据和本级是否有该cacheline数据没有任何关系。
不仅是在SLC中,在中间层的cache中也会有类似的部件来维护上层cache的状态:snoopfilter或者directory,其目标都是减少snoop来避免snoop风暴。
- directory: 维护上层cache的全部状态,SLC中知道上层cache的具体状态,这样可以精确的进行snoop或者cache状态转换
- snoopfilter: 只维护上层cache的大部分状态,对于不在snoopfilter中的cacheline状态可以进行广播或者无效掉上层对应的cacheline
cache的策略很大程度上影响整体的性能表现,但是在不同场景下cache策略有不同的表现,目前都是针对大部分场景进行的一种折中选择,应该根据自身的目标场景进行整体上的优化。
snoopable和shareable
对于Memory类型的,除了Cacheable之外它又引入了Snoopable, shareable,此外又允许配置readalloc, writealloc, writeback等属性,所以又引入了 alloc 属性。
正常情况下,上级cache miss或写权限不足时会向下级cache请求数据和权限,对于下级cache(这里我们以SLC为例)来说,如果它本身也miss时它有两种选择:
- 直接从DDR获取数据;
- 从其他处理器或者cluster的cache中获取数据。
直接从DDR获取数据的问题是,DDR中的数据并不一定是最新的,拿到一个过时的数据很显然会导致程序错误。所以此时SLC来说,它需要向上请求处理器内的cache数据,这个过程就称为snoop。之前的处理器之间互联一般使用ring结构总线,总线节点并不是很多,从一个节点到其他任意节点的时间都比较小,但是随着处理器核数越来越多,ring结构的带宽已经满足不了多核通信的需求,所以 Mesh 结构的 NoC (Network On Chip)应运而生。
首先说Snoopable属性, Snoopable描述的是下级cache miss时上层是否能提供可用的数据,所以对于Snoopable的数据就一定是cacheable属性。
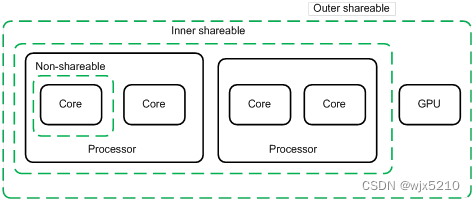
对于shareable的角度,它首先引入了domain的概念,根据不同domain间是否共享数据属性分成了三种: Non-Shareble(这种一般只出现在单核中,SMP一般是没有这种类型),inner-shareable, outer-shareable。对于inner-shareable,它一般指的是某个cluster内使用,但是其他cluster中不使用,这样在进行cache一致性同步时就可以忽略掉其他的cluster而不必snoop,但是linux中并不存在这种类型的存储,通常认为SMP之间是对等的,这个可以忽略的,否则要管理不一致的内存视图对于软件来说不要太痛苦。outer-shareable是指数据可以和domain外部的数据是共享的,这部分肯定要参与cache一致性。对于目前的架构来说通常不必要考虑inner-shareable的属性,可以将所有的cacheable & snoopable 都理解成 outer-shareable属性就好了。
alloc属性目前只是一种hint,它是上层cache建议是否在本级cache中存储,对于经常使用的数据但是由于容量问题被evict下来时通常可以建议本级cache存放该数据。当然也可以不接受这种建议,它在模型上并不影响cache coherence的正确性。
Device
对于Device, 它和Memory最主要的区别是
- 访问Device的寄存器可能会产生副作用,有些寄存器会有读清的效果,所以它并不能投机或者预读;
- Device通常是和外界交互,它不仅受到cpu的控制也会被外界的输入所影响,所以cache它的数据很多时候是没用的,并且获取到过时的数据时还可能导致程序行为错误。
所以访问Device时一般会比较严格,特别是多个arch平台上,为了保持驱动在所有arch上都能正常运行,又额外加了一些可能是冗余的屏障类指令。
C volatile 只是防止编译器优化外设读操作变成寄存器读,硬件需要保证外设范围的读操作不会经过cache,两者各有分工
首先Device进行大的分类, Device memory (例如GPU显存) 和 Device register,它们的处理稍有不同。首先是读操作,两种类别的读都必须等待Device当前的读状态返回才能继续下一步操作,但是对于Device Memory是可以进行prefetch类的预取操作,也就是投机读,这种不会引发副作用。对于写来说,Device memory可以进行两个优化,一个是写合并,将多笔写合并成一笔写入,另一个是提前返回,不需要真的写入到终端设备就可以返回,但是需要硬件保证其他任何对该该地址的读都能获取到写入的数据。
Arm提出了几种Device的类型,但是实际上允许乱序重拍的设备其实并不常见,并没有真的应用起来,一切还是以准确可用为先。
- Device nRnE: Non Reodrer, Non EarylWriteAck, 这种是最严格的序,即只有写到最终的设备并且接收到终端设备的响应才算结束
- Device nRE: No Reorder, Allow EarlyWriteAck, 这种允许不必写到终端设备,只要总线能够保证后续所有针对该地址的访问都能获取到最新数据即可。
- Device RE:Allow Reorder, Allow EarlyWriteAck
参考:
https://developer.arm.com/documentation/100941/0101/Memory-attributes
https://lkml.org/lkml/2020/3/23/598
https://stackoverflow.com/questions/60750340/how-is-cache-coherency-maintained-on-armv8-big-little-system













![World of Warcraft [CLASSIC][80][Shushia] [Obsidian Sanctum][Sartharion]](https://i-blog.csdnimg.cn/direct/2552154f28624745bcded7662cf2244b.jpeg)



