1. 总结经验
redis主从:可实现高并发(读),典型部署方案:一主二从
redis哨兵:可实现高可用,典型部署方案:一主二从三哨兵
redis集群:可同时支持高可用(读与写)、高并发,典型部署方案:三主三从
2. 概述
Redis 支持三种集群模式,分别为主从模式、哨兵模式和Cluster模式。
最初,Redis采用主从模式构建集群。在这种模式下,如果主节点(master)出现故障,需要手动将从节点(slave)转换为主节点。然而,这种模式在故障恢复方面效率不高。
为了提高系统的可用性,Redis引入了哨兵模式。在哨兵模式中,一个哨兵集群负责监控主节点和从节点。如果检测到主节点故障,系统可以自动将从节点晋升为新的主节点。这提高了故障恢复的自动化程度。
尽管如此,哨兵模式仍然面临内存容量和写入性能的限制,因为这种模式的写入能力仍然局限于单个节点。为了解决这一问题,Redis在3.x版本之后推出了Cluster集群模式。Cluster模式通过数据分片和节点的水平扩展,实现了更高效的内存利用和写入性能。

3. 二、Redis 主从模式架构介绍
3.1. 概要
在Redis的主从复制架构中,系统通过定义主库(master)和从库(slave)的角色,实现数据的高效同步和备份。这一架构具体包含以下特点:
master的读写能力:master是系统中的数据中心,它不仅承担全部的写操作,还能处理读请求。当在master上执行任何改变数据的操作时,这些更改会自动且实时地同步到所有slave。
单向数据流:数据同步流是单向的,意味着数据只从master流向slave,确保了数据同步的一致性和可靠性。
slave的只读特性:slave通常被配置为只读模式,它们接收并存储从master传来的数据。这样设计主要是为了分散读取压力,从而提高系统的整体读取性能。
主slave的对应关系:一个master可以对应多个slave,形成一对多的关系。这种结构利于数据的冗余备份和读取负载的分散。相反,一个slave只能对应一个master,以保持数据同步的一致性。
slave的容错性:如果某个slave出现故障,它对系统其他部分的影响是最小的。即便在slave宕机的情况下,其它slave仍能继续提供读服务,master也能保持正常的读写操作。当故障的slave恢复后,它会自动从master同步缺失的数据。
master故障的影响:master的故障会导致Redis暂时无法处理新的写请求,但已连接的slave可以继续提供读服务。一旦master恢复,Redis会重新提供完整的读写服务。
master故障的应对机制:在当前的master发生故障时,系统不会自动在slave中选择一个新的master。这需要通过额外的高可用性解决方案来实现,例如使用Redis Sentinel或Redis Cluster来管理master的选举和故障转移。
在Redis主从复制架构,Redis能够有效地提供高可用性、数据冗余以及读写分离,从而在维持高性能的同时确保数据的安全和一致性。
3.2. Redis主从复制原理
在本文档中,我们将重点介绍Redis版本2.8及其后续版本的主从复制机制。
无是哪种场景,Redis 的主从复制机制均采用异步复制,也称为乐观复制,因此不能完全保证主从数据的一致性。
不论在什么场景下,Redis的主从复制机制都采用了所谓的“异步复制”或“乐观复制”。这种复制方式意味着不能完全保证主库和从库数据的实时一致性。
Redis的主从复制机制可以根据不同的运行场景和条件采取不同的实现方式。以下是一些主要场景及其对应的复制实现和说明:
第一次启动:在从库第一次连接到主库时,将采用psync复制方式进行全量复制。这意味着从库会从头开始复制主库中的全部数据。
正常运行期间:在正常运行状态下,从库通过读取主库的缓冲区来进行增量复制。这个过程涉及复制主库上发生的新的数据变更。
从库第二次启动(主库缓冲区未溢出):当从库重新启动且主库的缓冲区未溢出时,将通过读取主库的缓冲区进行部分复制。这种方式能够快速同步中断期间发生的数据变更,而不会对主库造成重大影响。
Redis 2.8及以上版本的从库第二次启动(针对主库):当从库第二次启动且系统版本为Redis 2.8或以上时,将采用psync复制进行全量复制。这种情况通常发生在主库的缓冲区数据无法满足从库需要同步的数据量时。
通过上述不同的复制策略,Redis能够在保证数据备份和减少系统负载的同时,灵活应对各种运行场景。尽管异步复制机制可能导致主从数据存在短暂的不一致,但这种设计在绝大多数应用场景中已被证明是既高效又可靠的。
PS:异步复制是Redis的复制方式,而psync是实现这种复制方式的具体命令。乐观复制或乐观并发控制则是另一种与Redis的异步复制机制不同的数据库事务处理概念。不少博客或说明介绍异步复制和乐观复制是同一个概念。
3.3. PSYNC 工作原理
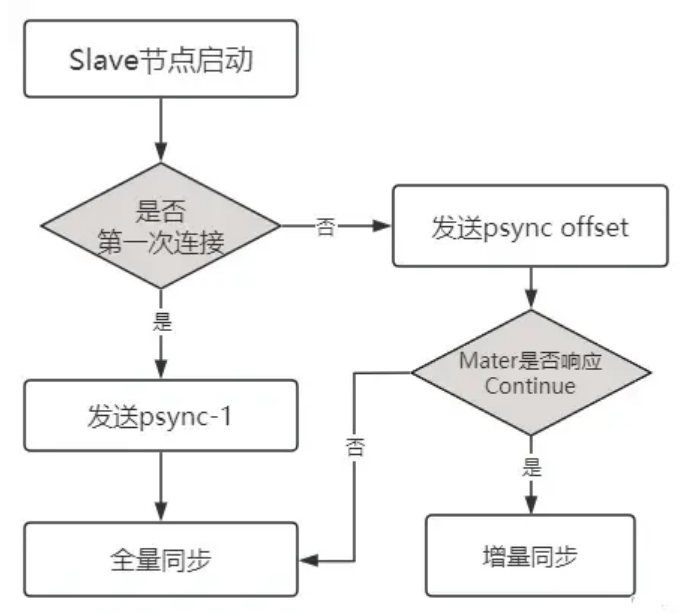
图2-3 Redis主从复制原理图解
PSYNC 命令是Redis中用于从节点与主节点之间数据同步的关键命令。它的工作原理包括以下几个步骤:
启动或重连判断:
当从节点(Slave)启动或与主节点(Master)的连接断开后重连时,从节点需要确定是否曾经同步过。
如果从节点没有保存任何主节点的运行ID(runid),它将视为第一次连接到主节点。
第一次同步处理:
在第一次同步的情况下,从节点会发送 PSYNC -1 命令给主节点,请求进行全量数据同步。
全量同步是指主节点将其所有数据完整地复制一份给从节点。
断线重连处理:
对于之前已经同步过的从节点,它会发送 PSYNC runid offset 命令,其中runid是主节点的唯一标识符,offset是从节点上次同步数据的偏移量。
主节点的响应:
主节点接收到PSYNC命令后,会检查runid是否匹配,以及offset是否在复制积压缓冲区的范围内。
如果匹配且offset有效,主节点将回复CONTINUE,并发送自从节点上次断开连接以来的所有写命令。
全量同步触发条件:
如果runid不匹配,或offset超出了积压缓冲区的范围,主节点将通知从节点执行全量同步,回复FULLRESYNC runid offset。
复制积压缓冲区的作用:
主节点会在处理写命令的同时,将这些命令存入复制积压队列,同时记录队列中存放命令的全局offset。
当从节点断线重连,且条件允许时,它可以通过offset从积压队列中进行增量复制,而不是全量复制。
数据一致性保障:
PSYNC机制允许从节点在网络不稳定或其他意外断开连接的情况下,能够以增量方式重新同步数据,保持主从节点数据的一致性。
PS:判断是否进行全量同步,需要考虑两个关键因素:首先,确认这是否是第一次进行数据同步;其次,检查缓存区是否已经达到或超过其容量上限。只有在是第一次同步,或者缓存区已溢出的情况下,才会执行全量同步。
4. Redis 主从模式环境搭建
在Redis的主从架构中,主节点的数据更新会自动被复制到从节点,确保数据的一致性。这种设置既是一种数据备份策略——从节点存储了主节点的数据备份,也提高了数据安全性。此外,通过主从架构实现读写分离,主节点负责处理写请求,而读请求可以分散到一个或多个从节点,这样既提高了系统的处理能力,又优化了资源的利用。

4.1. redis配置
4.1.1. 主库配置
该配置示例适用于Redis 2.6及更高版本
此操作在10.0.0.231机器上操作
mkdir -p /data/redis/{data,conf} && cd /data/redis/conf
cat > redis.conf << 'EOF'
# 设置Redis监听的IP地址和端口号,默认监听所有IP地址和6379端口
bind 0.0.0.0
#replicaof 10.0.0.231 6379
# docker方式运行,此值必须为no
daemonize no
# 是否启用保护模式,允许远程访问
protected-mode no
# 指定Redis监听的端口号
port 6379
# 配置TCP连接的最大等待队列长度 增加此值以处理更多的等待连接
tcp-backlog 2048
# 配置客户端连接超时时间
timeout 0
# 配置TCP keepalive参数 减少此值以更快检测和断开空闲连接
tcp-keepalive 60
# 关闭对后台任务的通知
notify-keyspace-events ""
# 配置最大客户端连接数 确保您的操作系统支持这么多文件描述符
maxclients 1000000
###################################日志级别及目录###################################
# 日志级别,info表示记录大部分有用的信息,适合生产环境
loglevel notice
# 日志存储目录
#logfile /data/redis.log
###################################客户端连接口令,主从口令######################
# 设置客户端连接服务端的验证口令
requirepass 123
# 设置主从服务器之间通信时的密码
masterauth 123
###################################配置RDB持久化###################################
#通过快照的形式,将某一时刻的数据集保存到磁盘上的二进制文件中
#适用于定时备份,以及灾难恢复。
# 在900s内,如果至少有1个key进行了修改,就进行持久化操作
save 900 1
# 在300s内,如果至少有10个key进行了修改,就进行持久化操作
save 300 10
# 在60s内,如果至少有10000个key进行了修改,就进行持久化操作
save 60 10000
# 配置如果持久化出错,Redis是否禁止写入命令 yes:禁止写入命令,no:允许写入命令(存在数据丢失风险)
stop-writes-on-bgsave-error yes
# 配置是否压缩rdb文件。[开启(yes)的话,会消耗一定的cpu资源]
rdbcompression yes
# 保存rdb文件的时候,进行错误的检查校验
rdbchecksum yes
# 默认持久化保存后的文件名
dbfilename dump.rdb
# rdb文件保存的目录,目录需存在
dir /data
###################################配置AOF持久化###################################
#记录服务器接收到的每一个写操作命令,并将这些命令追加到文件的末尾。
#通过重放这些命令来恢复数据,适用于需要高数据完整性的场景。
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
# always 每次修改都进行持久化操作
# everysec 每秒执行一次持久化操作
# no 不执行持久化操作,相当于未开启aof持久化策略
# 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no,建议yes
no-appendfsync-on-rewrite no
# AOF文件自动重写的触发条件,表示当AOF文件大小是上一次重写后的AOF文件大小的100%时,触发重写
auto-aof-rewrite-percentage 100
# 设置触发AOF重写的最小文件大小,避免AOF文件很小的时候触发重写,减少不必要的重写操作
auto-aof-rewrite-min-size 64mb
# 配置在启动加载AOF文件时对不完整文件的处理,设置为yes,允许加载不完整的AOF文件,提高数据恢复的灵活性
aof-load-truncated yes
# 启用增量式fsync,减少磁盘I/O操作
aof-rewrite-incremental-fsync yes
# 在AOF重写期间,使用备用的子进程进行写操作,减少对主进程的影响
#aof-rewrite-use-rdb-preamble yes
#——————————————————————————————————————————————
# 配置Lua脚本执行时间限制
# 调整阈值
lua-time-limit 5000
# 调整慢查询日志配置
slowlog-log-slower-than 10000
slowlog-max-len 128
# 配置事件通知
notify-keyspace-events ""
###################################内存相关设置###################################
# 增加Redis的最大内存限制,以容纳更多数据
#增加内存限制,根据您的服务器实际内存调整
#maxmemory 16GB
maxmemory 30720mb
# 设置在达到最大内存后的处理策略为LRU算法
maxmemory-policy allkeys-lru
# 调整数据结构的配置以优化内存使用
hash-max-ziplist-entries 1024
hash-max-ziplist-value 128
set-max-intset-entries 1024
list-max-ziplist-size -2
zset-max-ziplist-entries 128
zset-max-ziplist-value 128
# 配置HyperLogLog数据结构的最大内存使用
hll-sparse-max-bytes 3000
EOFconf]# docker run -p 6379:6379 --name redis --restart=always \
-v /data/redis/conf/redis.conf:/etc/redis/redis.conf \
-v /data/redis/data:/data \
-d redis redis-server /etc/redis/redis.conf
conf]# docker ps|grep redis|column -t
3f7e89055dbe redis "docker-entrypoint.s…" 2 minutes ago Up 2 minutes 0.0.0.0:6379->6379/tcp, :::6379->6379/tcp redis4.1.2. 从库配置
此操作在10.0.0.232,10.0.0.233机器上操作,
mkdir -p /data/redis/{data,conf} && cd /data/redis/conf
cat > redis.conf << 'EOF'
# 设置Redis监听的IP地址和端口号,默认监听所有IP地址和6379端口
bind 0.0.0.0
replicaof 10.0.0.231 6379
# docker方式运行,此值必须为no
daemonize no
# 是否启用保护模式,允许远程访问
protected-mode no
# 指定Redis监听的端口号
port 6379
# 配置TCP连接的最大等待队列长度 增加此值以处理更多的等待连接
tcp-backlog 2048
# 配置客户端连接超时时间
timeout 0
# 配置TCP keepalive参数 减少此值以更快检测和断开空闲连接
tcp-keepalive 60
# 关闭对后台任务的通知
notify-keyspace-events ""
# 配置最大客户端连接数 确保您的操作系统支持这么多文件描述符
maxclients 1000000
###################################日志级别及目录###################################
# 日志级别,info表示记录大部分有用的信息,适合生产环境
loglevel notice
# 日志存储目录
#logfile /data/redis.log
###################################客户端连接口令,主从口令######################
# 设置客户端连接服务端的验证口令
requirepass 123
# 设置主从服务器之间通信时的密码
masterauth 123
###################################配置RDB持久化###################################
#通过快照的形式,将某一时刻的数据集保存到磁盘上的二进制文件中
#适用于定时备份,以及灾难恢复。
# 在900s内,如果至少有1个key进行了修改,就进行持久化操作
save 900 1
# 在300s内,如果至少有10个key进行了修改,就进行持久化操作
save 300 10
# 在60s内,如果至少有10000个key进行了修改,就进行持久化操作
save 60 10000
# 配置如果持久化出错,Redis是否禁止写入命令 yes:禁止写入命令,no:允许写入命令(存在数据丢失风险)
stop-writes-on-bgsave-error yes
# 配置是否压缩rdb文件。[开启(yes)的话,会消耗一定的cpu资源]
rdbcompression yes
# 保存rdb文件的时候,进行错误的检查校验
rdbchecksum yes
# 默认持久化保存后的文件名
dbfilename dump.rdb
# rdb文件保存的目录,目录需存在
dir /data
# 配置Lua脚本执行时间限制
# 调整阈值
lua-time-limit 5000
# 调整慢查询日志配置
slowlog-log-slower-than 10000
slowlog-max-len 128
# 配置事件通知
notify-keyspace-events ""
###################################内存相关设置###################################
# 增加Redis的最大内存限制,以容纳更多数据
#增加内存限制,根据您的服务器实际内存调整
#maxmemory 16GB
maxmemory 30720mb
# 设置在达到最大内存后的处理策略为LRU算法
maxmemory-policy allkeys-lru
# 调整数据结构的配置以优化内存使用
hash-max-ziplist-entries 1024
hash-max-ziplist-value 128
set-max-intset-entries 1024
list-max-ziplist-size -2
zset-max-ziplist-entries 128
zset-max-ziplist-value 128
# 配置HyperLogLog数据结构的最大内存使用
hll-sparse-max-bytes 3000
EOFconf]# docker run -p 6379:6379 --name redis --restart=always \
-v /data/redis/conf/redis.conf:/etc/redis/redis.conf \
-v /data/redis/data:/data \
-d redis redis-server /etc/redis/redis.conf
conf]# docker ps|grep redis|column -t
3f7e89055dbe redis "docker-entrypoint.s…" 2 minutes ago Up 2 minutes 0.0.0.0:6379->6379/tcp, :::6379->6379/tcp redis4.2. springboot配置(开发配置)
|
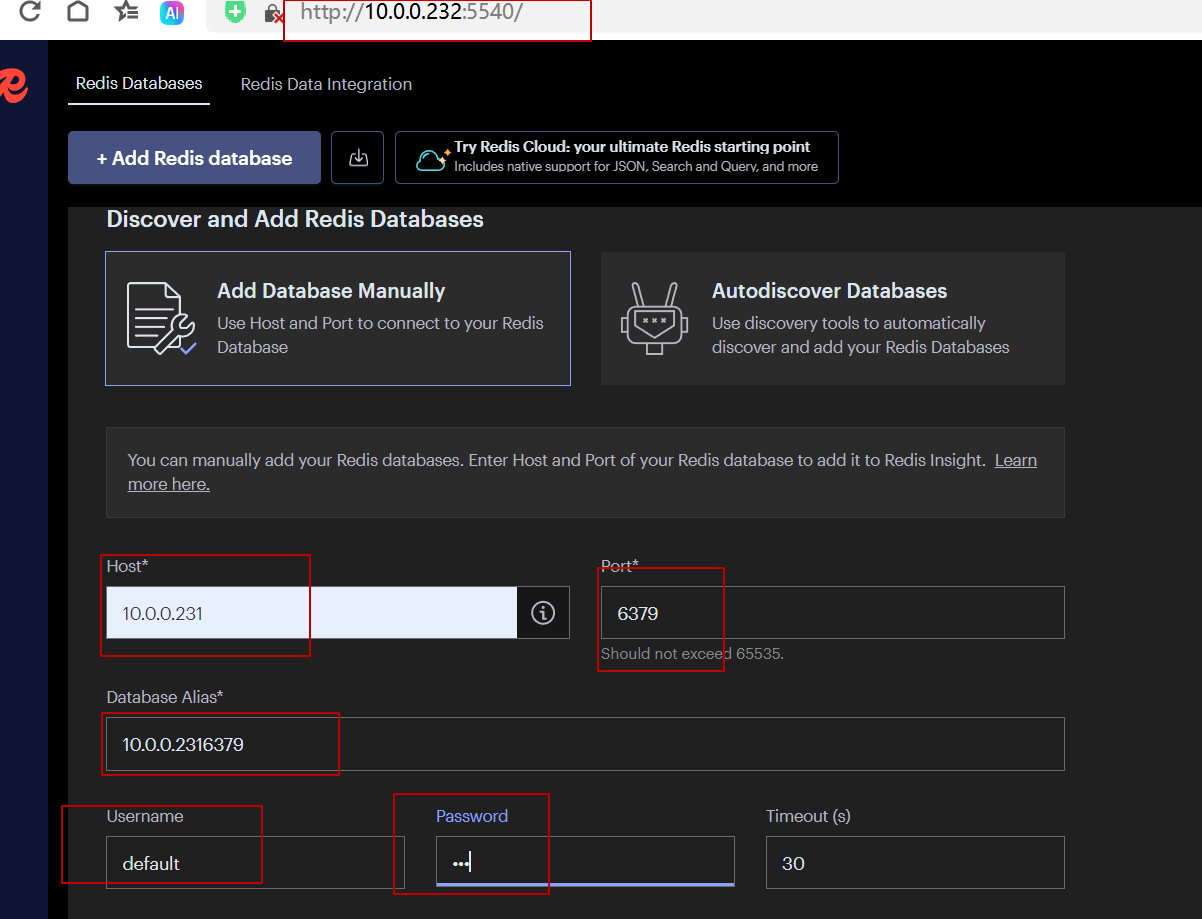
4.3. redisinsight安装
https://hub.docker.com/r/redis/redisinsight
mkdir -p /data/redisinsight/ && chown -R 1000.1000 /data/redisinsight/
docker run -d --name redisinsight -p 5540:5540 -v /data/redisinsight:/data redis/redisinsight:latest这里有坑,最新版本的redisinsight的端口已经是5540了,以前的版本端口是8081,网上很多人的文档都是8081启动命令,导致无法访问页面,另外页面上面有个用户名,如果没设置密码的话,用户名和密码都不用填,如果用requirepass设置了密码的话,这里用户名就是default,如果是用acl设置的用户那就是那个用户名和密码
4.4. 主从关系验证
231主库执行命令后,看到role为master
docker exec -it redis redis-cli -a 123 info replication

232从库执行命令后,看到role为master
docker exec -it redis redis-cli -a 123 info replication
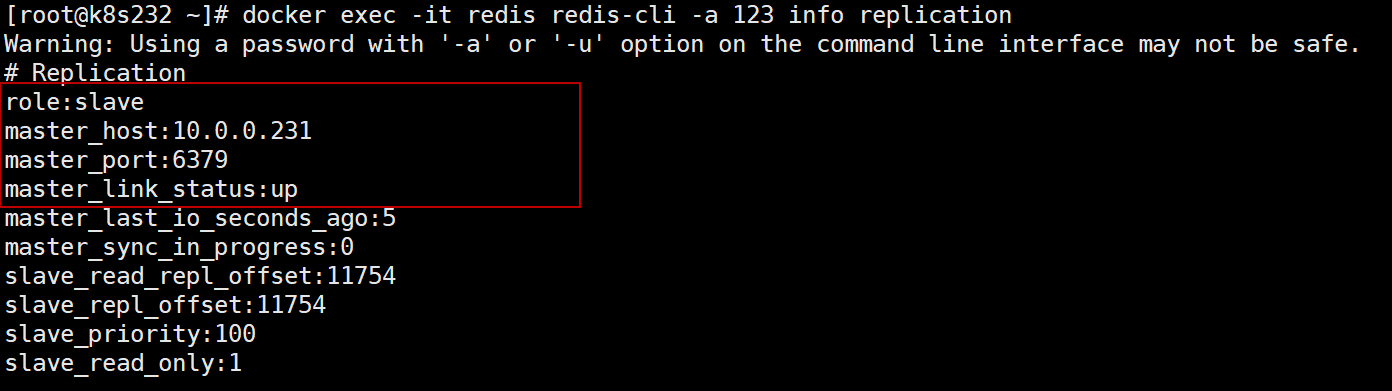
233从库执行命令后,看到role为master
docker exec -it redis redis-cli -a 123 info replication

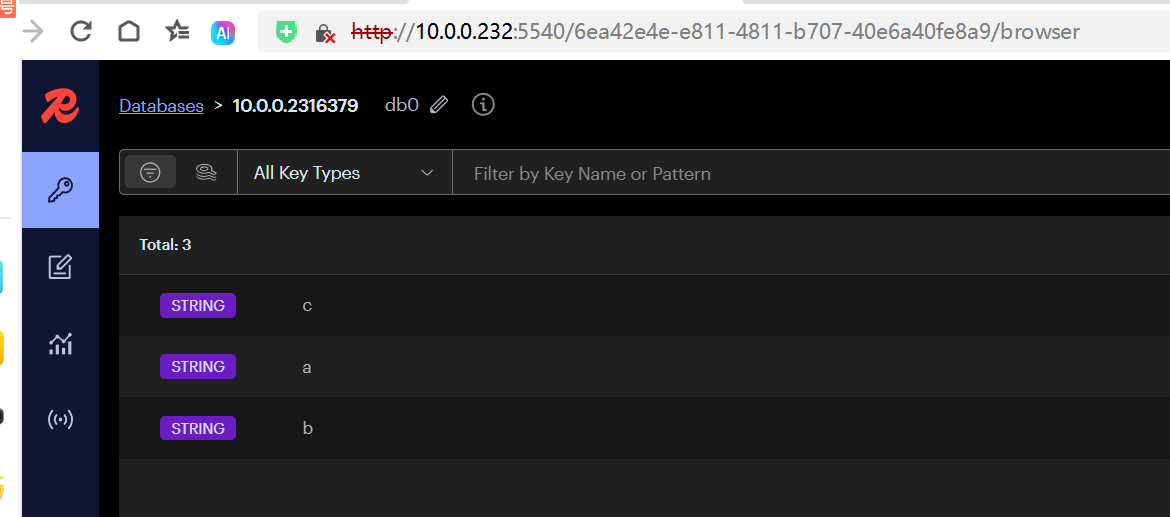
#231主节点写入数据
[root@k8s231.tom.com conf]# docker exec -it redis redis-cli -a 123
127.0.0.1:6379> set c 1
OK
#232从节点可以获取到数据
[root@k8s232 conf]# docker exec -it redis redis-cli -a 123 get c
"1"
#233从节点可以获取到数据
[root@k8s233.tom.com conf]# docker exec -it redis redis-cli -a 123 get c
"1"5. Redis 哨兵模式
5.1. Redis哨兵原理
自Redis 2.8版本起,官方引入了Sentinel(哨兵)架构,旨在提升系统的高可用性。哨兵模式主要通过后台监控机制来确保Redis服务的稳定性。在这一模式中,哨兵负责实时监控主节点的运行状况。一旦主节点出现故障,哨兵将基于预设的投票机制,自动将某个从节点晋升为新的主节点,以保持服务的连续性和数据的可用性。
哨兵本身是一个独立的进程,运行在Redis本身进程之外。它通过周期性地向Redis节点发送命令,并等待节点的响应,来判断被监控的Redis实例是否正常运行。通过这种方式,哨兵能够监控和管理一个或多个Redis实例,确保整个Redis服务的高可用性和稳定性。

基于上面的实验已经搭建了231节点的主库,232,233的从库,我们直接在每台机器上面部署一个sentinel
5.2. 231,232,233 都是同样的sentinel配置
cd /data/redis/conf
cat > sentinel.conf <<EOF
#指定16379哨兵节点的工作端口
port 16379
#指定master为监控目标名称,后面跟上监控的ip 端口,至少需要2台哨兵节点认可才能认定该主服务器失效
sentinel monitor master 10.0.0.231 6379 2
#连接master的密码
sentinel auth-pass master 123
dir /
logfile "sentinel.log"
EOF
docker run -itd --privileged=true --name redis-sentinel \
-v /data/redis/conf/sentinel.conf:/usr/local/etc/redis/sentinel.conf \
-p 16379:16379 redis:latest redis-sentinel /usr/local/etc/redis/sentinel.conf
docker exec -it redis-sentinel redis-cli -p 16379 info sentinel

5.3. 宕机测试
关闭主库redis,重新查看哨兵状态
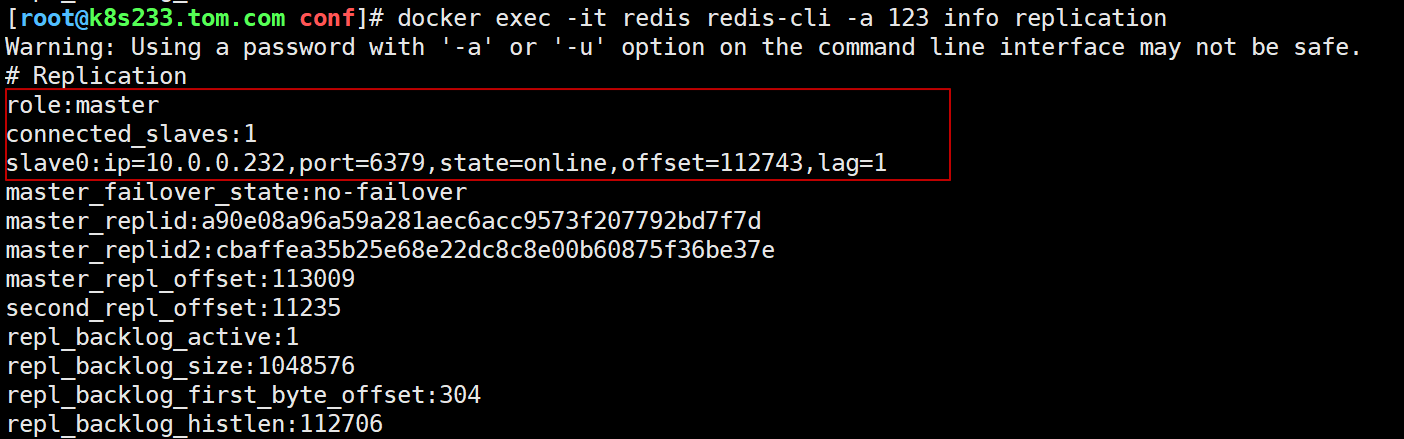
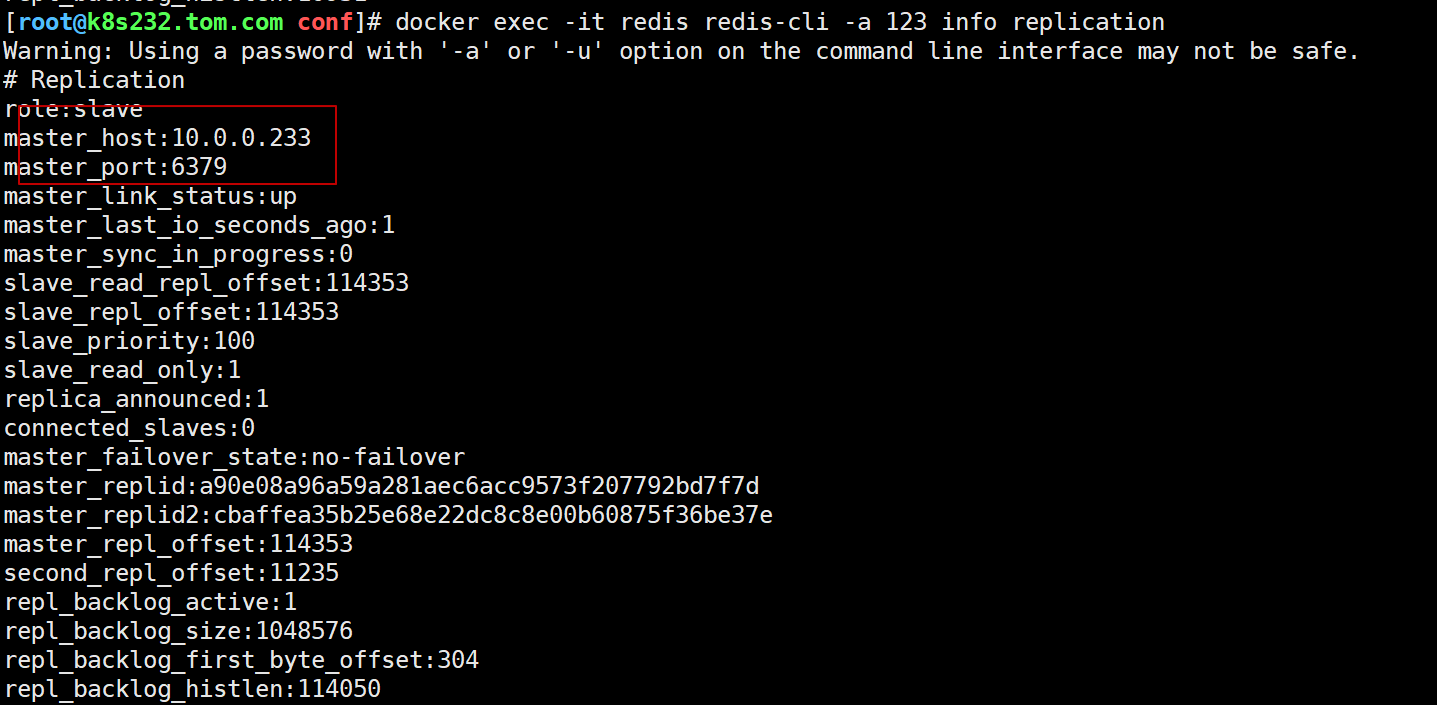
将主节点231 redis关闭,模拟宕机的情况。 哨兵投票选举出新的从节点119升为主节点。
231执行 docker stop redis
然后1分钟左右可以看到233从库变为主库了

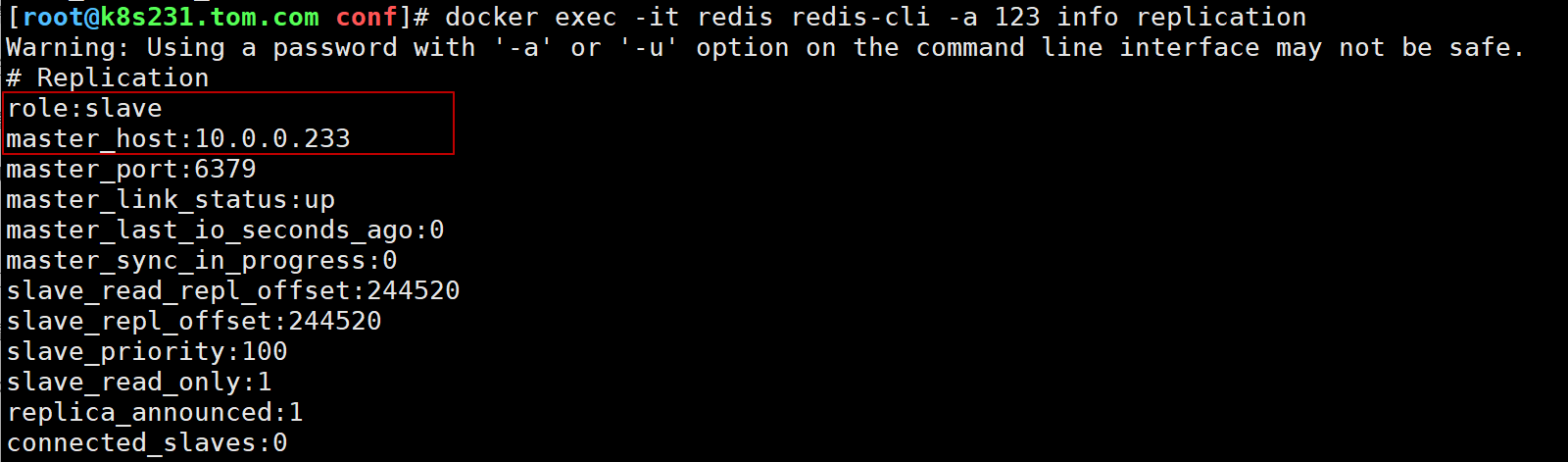
当节点231 重新启动之后,从未出故障前的主库变为了现在233的从库
6. Redis Cluster模式
6.1. cluster原理
Redis Cluster 通过高效的节点分配和稳健的主从模式,确保了数据的高可用性和稳定性。以下是对其核心机制的详细解释:
6.1.1. Redis Cluster 节点分配
6.1.1.1. 节点间的哈希槽分配
Redis Cluster 使用哈希槽(hash slot)机制来分配数据。假设我们有三个主节点:A、B、C,它们可以部署在同一台机器的不同端口上,或分布在三台不同的服务器上。在这种设置下,16384个哈希槽将被如下分配:
节点A负责管理0至5460号槽;
节点B负责管理5461至10922号槽;
节点C负责管理10923至16383号槽。
6.1.1.2. 数据的保存和获取
存入数据:例如,存储一个键值对,键名为“key”,其哈希值按照 CRC16(‘key’) % 16384 = 6782 计算。根据这个哈希槽号,数据将被存储在节点B上。
获取数据:无论连接哪个节点(A、B、C),获取键名为“key”的数据时,都会根据同样的哈希算法路由到节点B上提取数据。
6.1.1.3. 新增或删除主节点
新增节点:假设新增一个节点D,Redis Cluster 会将部分哈希槽从其他节点迁移至D节点。这可能导致哈希槽分布如下调整:
节点A:1365-5460
节点B:6827-10922
节点C:12288-16383
节点D:0-1364,5461-6826,10923-12287
删除节点:删除节点时,其管理的哈希槽会被迁移到其他节点上。迁移完成后,该节点即可被安全移除。
6.1.2. Redis Cluster主从模式
主从的重要性:为了保障数据的高可用性,Redis Cluster 引入了主从模式。在这种模式下,每个主节点都有一个或多个从节点。主节点处理所有的读写操作,而从节点主要负责数据备份。如果主节点发生故障,从节点中的一个将被提升为新的主节点,以确保集群的稳定运行。
未设置从节点的风险:以ABC三个主节点的集群为例,如果这些主节点都没有配置从节点,当其中一个(如B)发生故障时,整个集群的可用性将受到影响。A和C节点的哈希槽也将无法访问。
实例说明
在建立集群时,为每个主节点配置从节点是非常重要的。例如,集群包含主节点A、B、C,及其对应的从节点A1、B1、C1。这样,即使B节点出现故障,B1节点可以被提升为新的主节点,保证集群的持续运行。当B节点恢复时,它将成为B1的从节点。然而,需要注意的是,如果B节点和其对应的从节点B1同时出现故障,Redis Cluster 将无法提供服务。
注意事项
在Redis Cluster模式下,集群只支持一个数据库,即默认的数据库0。
由于集群不支持多数据库,后台代码配置时无法选择Redis库,所有操作均默认针对数据库0进行。
6.2. cluster模式环境部署

Redis Cluster被配置为三主三从模式。服务器ip 10.0.0.11-16
6.2.1. 所有节点都要优化的内核参数
cat >> /etc/sysctl.conf << EOF
net.core.somaxconn=2048
vm.overcommit_memory=1
EOF
sysctl -p
docker network create redis-net6.2.2. 11-16节点都操作以下内容,启动redis
#创建工作目录
mkdir -p /redis-cluster/data && cd /redis-cluster
#编写docker-compose文件
cat > /redis-cluster/docker-compose.yml <<EOF
version: '3'
services:
redis-cluster:
image: redis:7.2.5
container_name: redis
ports:
- "6379:6379"
- "16379:16379"
volumes:
- ./data:/data
restart: always
command: redis-server /data/redis.conf
EOF
#redis配置文件
cat > /redis-cluster/data/redis.conf <<EOF
# 设置Redis监听的IP地址和端口号,默认监听所有IP地址和6379端口
bind 0.0.0.0
#禁用危险命令
rename-command keys ""
rename-command flushdb ""
rename-command FLUSHALL ""
#被设置为 "no" 时,每次删除操作都会尽可能地立即释放被删除键所占用的内存。
#被设置为 "yes" 时,Redis 会将删除操作的内存释放延迟到后续时刻,避免在删除短时间大量键时产生过多的内存回收操作,从而提高删除操作的性能。
lazyfree-lazy-server-del yes
#no时,当 Redis 收到一个 DEL 命令请求删除一个键时,它会立即同步地从数据库中删除这个键,并释放其占用的内存资源。这种操作可能会引起阻塞,特别是当删除大对象(比如包含大量元素的集合或哈希表)时,释放内存的过程可能会消耗较长时间,影响服务其他客户端请求的性能。
#yes时,Redis 在接收到 DEL 命令时并不会立即删除并释放内存,而是将删除任务放入后台线程中异步执行。这样做的好处在于,主线程可以快速返回继续处理其他客户端请求,从而提高 Redis 对高并发场景的响应速度和整体性能。
lazyfree-lazy-user-del yes
#被设置为 "no" 时,主节点在向从节点同步数据时会尽可能快地将所有数据刷新到从节点上,从而确保快速的数据同步,但会增加网络流量和主节点的负载。
#被设置为 "yes" 时,主节点将采用一种“懒惰”策略,在一定程度上延迟将数据刷新到从节点上,以减少网络流量和主节点的负载。这意味着主节点会在一段时间内收集多个命令,然后一次性地发送给从节点,从而减少数据同步的频率。
replica-lazy-flush yes
#replicaof 10.0.0.231 6379
# docker方式运行,此值必须为no
daemonize no
# 是否启用保护模式,允许远程访问
protected-mode no
# 指定Redis监听的端口号
port 6379
# 开启集群模式
cluster-enabled yes
# 集群节点超时时间
cluster-node-timeout 5000
# 集群配置文件
cluster-config-file redis-cluster.conf
#这个IP地址将被用来通知其他节点如何访问到当前节点
cluster-announce-ip $(hostname -I|awk '{print $1}')
# 激活重哈希
activerehashing yes
# 不使用监管模式
supervised no
# 从节点为只读模式
replica-serve-stale-data yes
replica-read-only yes
# 关闭无盘复制模式
repl-diskless-sync no
# 无盘复制模式的延迟时间
repl-diskless-sync-delay 5
# 开启TCP_NODELAY
repl-disable-tcp-nodelay no
# 从节点的优先级
replica-priority 100
# 配置TCP连接的最大等待队列长度 增加此值以处理更多的等待连接
tcp-backlog 2048
# 配置客户端连接超时时间,0表示无超时时间
timeout 0
# 配置TCP keepalive参数 减少此值以更快检测和断开空闲连接
tcp-keepalive 60
# 关闭对后台任务的通知
notify-keyspace-events ""
# 配置最大客户端连接数 确保您的操作系统支持这么多文件描述符
maxclients 1000000
###################################日志级别及目录###################################
# 日志级别,info表示记录大部分有用的信息,适合生产环境
loglevel notice
# 日志存储目录
#logfile /data/redis.log
###################################客户端连接口令,主从口令######################
# 设置客户端连接服务端的验证口令
requirepass 123
# 设置主从服务器之间通信时的密码
masterauth 123
###################################配置RDB持久化###################################
#通过快照的形式,将某一时刻的数据集保存到磁盘上的二进制文件中
#适用于定时备份,以及灾难恢复。
# 在900s内,如果至少有1个key进行了修改,就进行持久化操作
save 900 1
# 在300s内,如果至少有10个key进行了修改,就进行持久化操作
save 300 10
# 在60s内,如果至少有10000个key进行了修改,就进行持久化操作
save 60 10000
# 配置如果持久化出错,Redis是否禁止写入命令 yes:禁止写入命令,no:允许写入命令(存在数据丢失风险)
stop-writes-on-bgsave-error yes
# 配置是否压缩rdb文件。[开启(yes)的话,会消耗一定的cpu资源]
rdbcompression yes
# 保存rdb文件的时候,进行错误的检查校验
rdbchecksum yes
# 默认持久化保存后的文件名
dbfilename dump.rdb
# rdb文件保存的目录,目录需存在
dir /data
# 如果后台保存错误则停止写入
stop-writes-on-bgsave-error yes
###################################配置AOF持久化###################################
#记录服务器接收到的每一个写操作命令,并将这些命令追加到文件的末尾。
#通过重放这些命令来恢复数据,适用于需要高数据完整性的场景。
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
# always 每次修改都进行持久化操作
# everysec 每秒执行一次持久化操作
# no 不执行持久化操作,相当于未开启aof持久化策略
# 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no(rewrite期间可以fsync),建议yes
no-appendfsync-on-rewrite yes
# AOF文件自动重写的触发条件,表示当AOF文件大小是上一次重写后的AOF文件大小的100%时,触发重写
auto-aof-rewrite-percentage 100
# 设置触发AOF重写的最小文件大小,避免AOF文件很小的时候触发重写,减少不必要的重写操作
auto-aof-rewrite-min-size 64mb
# 配置在启动加载AOF文件时对不完整文件的处理,设置为yes,允许加载不完整的AOF文件,提高数据恢复的灵活性
aof-load-truncated yes
# 启用增量式fsync,减少磁盘I/O操作
aof-rewrite-incremental-fsync yes
# 在AOF重写期间,使用备用的子进程进行写操作,减少对主进程的影响
#aof-rewrite-use-rdb-preamble yes
#——————————————————————————————————————————————
# 配置Lua脚本执行时间限制
# 调整阈值
lua-time-limit 5000
# 调整慢查询日志配置
slowlog-log-slower-than 10000
slowlog-max-len 128
# 配置事件通知
notify-keyspace-events ""
###################################内存相关设置###################################
# 增加Redis的最大内存限制,以容纳更多数据
#增加内存限制,根据您的服务器实际内存调整
maxmemory 40G
# 设置在达到最大内存后的处理策略为LRU算法
maxmemory-policy allkeys-lru
# 调整数据结构的配置以优化内存使用
hash-max-ziplist-entries 1024
hash-max-ziplist-value 128
set-max-intset-entries 1024
list-max-ziplist-size -2
zset-max-ziplist-entries 128
zset-max-ziplist-value 128
# 配置HyperLogLog数据结构的最大内存使用
hll-sparse-max-bytes 3000
EOF
docker-compose up -d
docker ps|grep redis6.2.3. 创建集群
只需要进入某一个节点的容器执行命令即可
#进入redis容器
docker exec -it redis bash
#进入容器后执行下面这条命令,前面三个ip表示主库,后面三个ip表示从库
#--cluster-replicas 1 表示创建自动创建并给每个 master 节点分配一个 slave 节点,
#共6节点,也就是三主三从模式;
redis-cli -a 123 --cluster create \
10.0.0.11:6379 \
10.0.0.12:6379 \
10.0.0.13:6379 \
10.0.0.14:6379 \
10.0.0.15:6379 \
10.0.0.16:6379 \
--cluster-replicas 1
6.2.4. --cluster命令管理集群(只能在容器上面使用)
redis-trib.rb是官方提供的Redis Cluster的管理工具,它提供了集群创建、检查、修复、均衡等命令行工具。Redis Cluster 在5.0之后取消了ruby脚本的支持,而是直接集合到redis-cli里,避免了再安装ruby的相关环境。现在通过--cluster命令调用即可,只能在容器上面使用
写法1:docker exec -it redis redis-cli -a 123 --cluster 命令
写法2:docker exec -it redis bash ,进入容器后,再执行redis-cli -a 123 --cluster 命令
[root@m01 redis-cluster]# docker exec -it redis /bin/bash -c 'redis-cli -a 123 --cluster help'
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
Cluster Manager Commands:
create host1:port1 ... hostN:portN
--cluster-replicas <arg>
check <host:port> or <host> <port> - separated by either colon or space
--cluster-search-multiple-owners
info <host:port> or <host> <port> - separated by either colon or space
fix <host:port> or <host> <port> - separated by either colon or space
--cluster-search-multiple-owners
--cluster-fix-with-unreachable-masters
reshard <host:port> or <host> <port> - separated by either colon or space
--cluster-from <arg>
--cluster-to <arg>
--cluster-slots <arg>
--cluster-yes
--cluster-timeout <arg>
--cluster-pipeline <arg>
--cluster-replace
rebalance <host:port> or <host> <port> - separated by either colon or space
--cluster-weight <node1=w1...nodeN=wN>
--cluster-use-empty-masters
--cluster-timeout <arg>
--cluster-simulate
--cluster-pipeline <arg>
--cluster-threshold <arg>
--cluster-replace
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id <arg>
del-node host:port node_id
call host:port command arg arg .. arg
--cluster-only-masters
--cluster-only-replicas
set-timeout host:port milliseconds
import host:port
--cluster-from <arg>
--cluster-from-user <arg>
--cluster-from-pass <arg>
--cluster-from-askpass
--cluster-copy
--cluster-replace
backup host:port backup_directory
help
For check, fix, reshard, del-node, set-timeout, info, rebalance, call, import, backup you can specify the host and port of any working node in the cluster.
Cluster Manager Options:
--cluster-yes Automatic yes to cluster commands prompts1、 --cluster create 创建集群
2、--cluster check 检查集群
3、--cluster info 查看集群
4、--cluster fix 修复集群
5、--cluster rehard 迁移槽位
6、 --cluster rebalance 平衡集群
7、 --cluster add-node 集群扩容
8、--cluster del-node 集群缩容
9、 --cluster call 在集群中执行命令
10、--cluster set-timeout 整个集群的cluster-node-timeout时间
11、--cluster import 导入数据至集群
12、--cluster backup 备份集群rdb文件6.2.4.1. --cluster create 创建集群
create host1:port1 ... hostN:portN
--cluster-replicas <arg>
该命令用来创建集群,假设我现在想搭建三主三从的集群127.0.0.1:7001~7006
启动所有节点后,可通过如下命令进行搭建:
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
--cluster-replicas 1 :表示每个主节点需要1个从节点。
这里随机分配主从关系,如果需要定制,则可以不加该参数,使用add-node来定制,查看第7节6.2.4.2. --cluster check 检查集群
check host:port
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
该命令经常使用,需要拥有槽位的所有节点为启动状态,用于检查集群状态是否正常,只有当所有的槽位正常时,集群状态才OKdocker exec -it redis redis-cli -a 123 --cluster check 10.0.0.11:6379
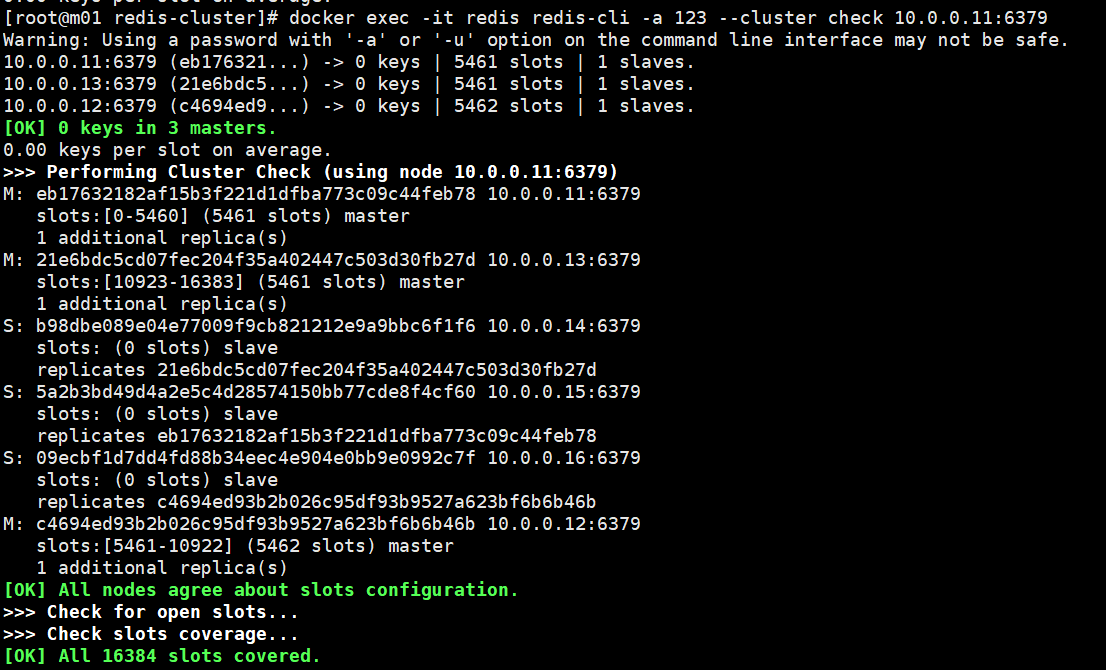
6.2.4.3. --cluster info 查看集群
用于查看集群的简易信息
docker exec -it redis redis-cli -a 123 --cluster info 10.0.0.11:6379

6.2.4.4. --cluster fix 修复集群
fix host:port
--cluster-search-multiple-owners
--cluster-fix-with-unreachable-masters
该命令十分有用,说明如下:
--cluster-search-multiple-owners : 是否修复多个拥有者的槽位。当集群中的槽位在迁移过程中,
出现意外时,使用fix可使用该参数。fix功能,
redis内部在槽位的某些异常情况下会交互式的询问操作者是否同意它的修复策略,一般情况下,默认即可。
--cluster-fix-with-unreachable-masters : 是否修复不可达的主节点上的槽位。
例如,集群中某个主节点就是坏掉了,也没有故障转移成功。此时如何恢复该主节点上的所有槽位呢,
这时就可以使用该参数,会将处于该主节点上的所有槽位恢复到存活的主节点上(之前的数据会丢失,仅仅是恢复了槽位)。6.2.4.5. --cluster rehard 迁移槽位
reshard host:port
--cluster-from <arg> #槽位来源的节点运行id,多个用,分割,all表示全部节点
--cluster-to <arg> #目标节点的运行id,只允一个
--cluster-slots <arg> #迁移的槽位数
--cluster-yes #是否默认同意集群内部的迁移计划(默认同意就可以)
--cluster-timeout <arg> #迁移命令(migrate)的超时时间
--cluster-pipeline <arg> #迁移key时,一次取出 的key数量,默认10
--cluster-replace #是否直接replace到目标节点
迁移一个或者多个(--cluster-from)节点上的--cluster-slots个槽位至一个目标节点(--cluster-to)上。
--cluster-from 的值不为all的情况下, --cluster-from不能包含--cluster-to6.2.4.6. --cluster rebalance 平衡集群
rebalance host:port
--cluster-weight <node1=w1...nodeN=wN>
--cluster-use-empty-masters
--cluster-timeout <arg> #迁移命令(migrate)的超时时间
--cluster-simulate # 模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline <arg> #定义 getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold <arg>
--cluster-replace #是否直接replace到目标节点
--cluster-weight: 槽位权重(浮点型)比值,
例如(这里使用端口号代替运行id): 7001=1.0,7002=1.0,7003=2.0
则表示,总权重为4.0, 7001和7002将分配到 (16384/4)*1 个槽位,7003则是(16384/4)*2个槽位。
--cluster-threshold: 平衡触发的阈值条件,默认为2.00%。
例如上一步,7001和7002应该有4096个槽位,如果7001的槽位数不够4096个,
且超过 (4096*0.02 约等于)82个及以上;或者7001的槽位数比4096少于82个及以上,则会触发自平衡。6.2.4.7. --cluster add-node 集群扩容
add-node new_host:new_port #新加入集群的ip和port
existing_host:existing_port #集群中任一节点的ip和port
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id <arg> #给新节点指定主节点,值为节点的运行id
可用于向集群中添加主、从节点(即扩容)
假设我现在集群中有7001 7002 7003三个主节点了,想为7001添加一个从节点127.0.0.1:7006,则可执行如下命令:
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7001 --cluster-slave --cluster-master-id 30c69d9e408015082c1a2145875cd1ec0c7a41ea
不传入--cluster-slave --cluster-master-id 参数,表示添加一个主节点。
当添加的是一个主节点时,此时,该主节点没有任何槽位,可以使用rebalance或者reshard来迁移槽位给它6.2.4.8. --cluster del-node 集群缩容
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
也就是缩容。
删除一个主节点要求先迁移走改主节点上的槽位(数据),这时就可以使用reshard命令了。
[root@localhost bin]# ./redis-cli --cluster del-node 192.168.84.1:7002 10a4381d9869e293cad95bf75482f506de9f43fe
>>> Removing node 10a4381d9869e293cad95bf75482f506de9f43fe from cluster 192.168.84.1:7002
[ERR] Node 192.168.84.1:7002 is not empty! Reshard data away and try again.6.2.4.9. --cluster call 在集群中执行命令
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
--cluster-only-masters #是否只在主节点上执行
--cluster-only-replicas #是否只在从节点上执行
docker exec -it redis redis-cli -a 123 --cluster call 10.0.0.11:6379 ping
docker exec -it redis redis-cli -a 123 --cluster call 10.0.0.11:6379 set name tom
docker exec -it redis redis-cli -a 123 --cluster call 10.0.0.11:6379 get name
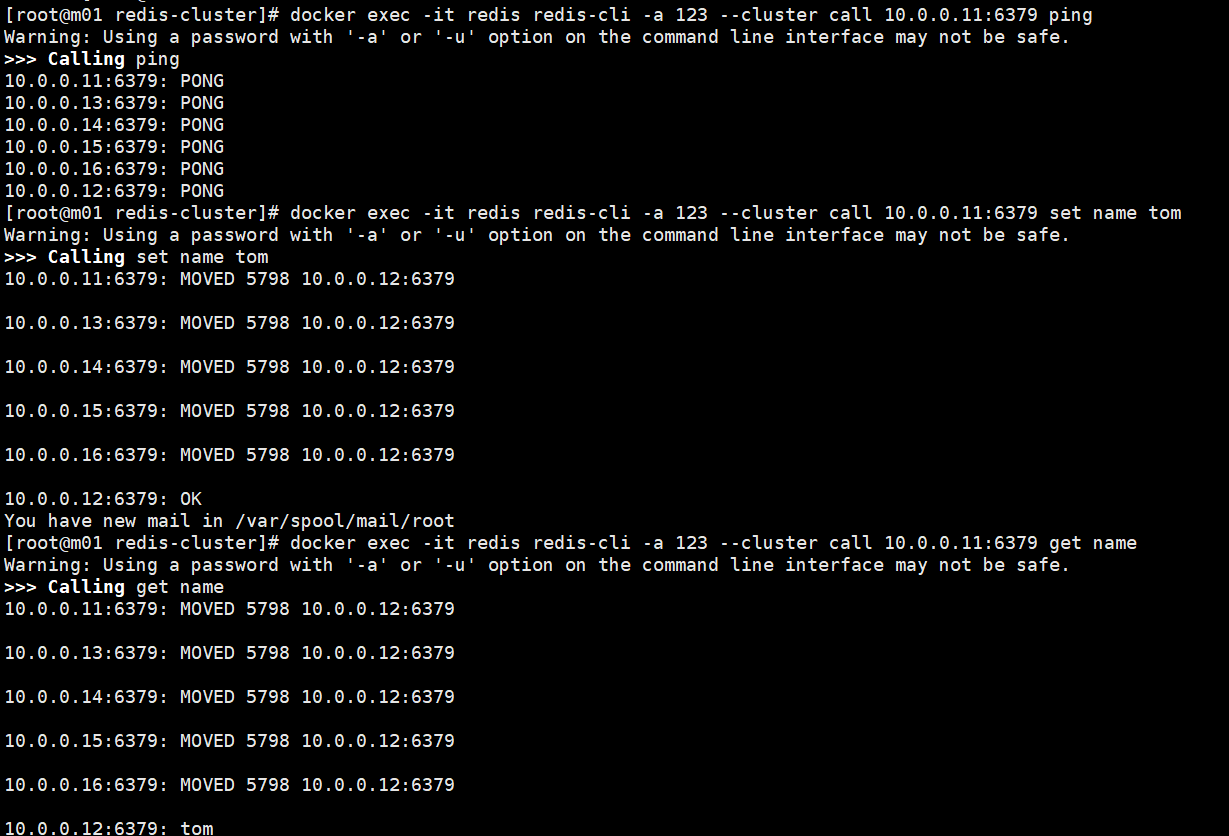
6.2.4.10. --cluster set-timeout 整个集群的cluster-node-timeout时间
set-timeout host:port milliseconds
设置整个集群的cluster-node-timeout时间6.2.4.11. --cluster import 导入数据至集群
import host:port
--cluster-from <arg>
--cluster-from-user <arg>
--cluster-from-pass <arg>
--cluster-from-askpass
--cluster-copy #migrate时指定类型为copy
--cluster-replace #migrate时指定类型为replace
将外部redis的数据导入集群
redis-cli --cluster import 127.0.01:6379 --cluster-from 127.0.0.2:6379 --cluster-replace --cluster-copy
说明:外部Redis实例(127.0.0.2:6379)导入到集群中的任意一节点,导入之后,
原来集群的key变为空,导入到新集群的key会自动分片到各个mater节点的slot
--cluster-replace 如果集群(127.0.01:6379)中存在外部redis实例(127.0.0.2:6379)的key,则会覆盖掉(10.35.2.68:6379)的value
--cluster-copy 默认情况下,import 命令在向集群导入数据的同时,还会删除单机服务器中源数据。
如果用户想要保留单机服务器中的数据,那么可以在执行命令的同时给定 –cluster-copy 选项
该命令将正在运行的实例的所有键(从源实例中删除键)移动到指定的预先存在的 Redis 集群。
实际项目上,数据导入应该用redis-shake工具的比较多。6.2.4.12. --cluster backup 备份集群rdb文件
backup host:port backup_directory
备份主节点上的数据值RDB文件
#进入容器操作
docker exec -it redis bash
root@daa16c5f98a5:/data# mkdir backup
root@daa16c5f98a5:/data# redis-cli -a 123 --cluster backup 10.0.0.11:6379 ./backup
#容器外查看
[root@m01 redis-cluster]# tree data/backup/
data/backup/
├── nodes.json
├── redis-node-10.0.0.11-6379-eb17632182af15b3f221d1dfba773c09c44feb78.rdb
├── redis-node-10.0.0.12-6379-c4694ed93b2b026c95df93b9527a623bf6b6b46b.rdb
└── redis-node-10.0.0.13-6379-21e6bdc5cd07fec204f35a402447c503d30fb27d.rdb6.3. 连接集群后,可执行命令(任意客户端都可使用命令)
客户端连接redis集群命令,-c 表示集群支持
redis-cli -h 10.0.0.11 -a 123 -c-c连接集群后,可执行命令写法
写法1:redis-cli -h 10.0.0.11 -a 123 -c 命令
写法2:redis-cli -h 10.0.0.11 -a 123 -c ,连接建立后,再写命令
127.0.0.1:6379> cluster help
1) CLUSTER <subcommand> [<arg> [value] [opt] ...]. Subcommands are:
2) ADDSLOTS <slot> [<slot> ...]
3) Assign slots to current node.
4) ADDSLOTSRANGE <start slot> <end slot> [<start slot> <end slot> ...]
5) Assign slots which are between <start-slot> and <end-slot> to current node.
6) BUMPEPOCH
7) Advance the cluster config epoch.
8) COUNT-FAILURE-REPORTS <node-id>
9) Return number of failure reports for <node-id>.
10) COUNTKEYSINSLOT <slot>
11) Return the number of keys in <slot>.
12) DELSLOTS <slot> [<slot> ...]
13) Delete slots information from current node.
14) DELSLOTSRANGE <start slot> <end slot> [<start slot> <end slot> ...]
15) Delete slots information which are between <start-slot> and <end-slot> from current node.
16) FAILOVER [FORCE|TAKEOVER]
17) Promote current replica node to being a master.
18) FORGET <node-id>
19) Remove a node from the cluster.
20) GETKEYSINSLOT <slot> <count>
21) Return key names stored by current node in a slot.
22) FLUSHSLOTS
23) Delete current node own slots information.
24) INFO
25) Return information about the cluster.
26) KEYSLOT <key>
27) Return the hash slot for <key>.
28) MEET <ip> <port> [<bus-port>]
29) Connect nodes into a working cluster.
30) MYID
31) Return the node id.
32) MYSHARDID
33) Return the node's shard id.
34) NODES
35) Return cluster configuration seen by node. Output format:
36) <id> <ip:port@bus-port[,hostname]> <flags> <master> <pings> <pongs> <epoch> <link> <slot> ...
37) REPLICATE <node-id>
38) Configure current node as replica to <node-id>.
39) RESET [HARD|SOFT]
40) Reset current node (default: soft).
41) SET-CONFIG-EPOCH <epoch>
42) Set config epoch of current node.
43) SETSLOT <slot> (IMPORTING <node-id>|MIGRATING <node-id>|STABLE|NODE <node-id>)
44) Set slot state.
45) REPLICAS <node-id>
46) Return <node-id> replicas.
47) SAVECONFIG
48) Force saving cluster configuration on disk.
49) SLOTS
50) Return information about slots range mappings. Each range is made of:
51) start, end, master and replicas IP addresses, ports and ids
52) SHARDS
53) Return information about slot range mappings and the nodes associated with them.
54) LINKS
55) Return information about all network links between this node and its peers.
56) Output format is an array where each array element is a map containing attributes of a link
57) HELP
58) Print this help.
127.0.0.1:6379>
//集群(cluster)
CLUSTER INFO 打印集群的信息
CLUSTER NODES 列出集群当前已知的所有节点(node),以及这些节点的相关信息。
//节点(node)
CLUSTER MEET <ip> <port> 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
CLUSTER FORGET <node_id> 从集群中移除 node_id 指定的节点。
CLUSTER REPLICATE <node_id> 将当前节点设置为 node_id 指定的节点的从节点。
CLUSTER SAVECONFIG 将节点的配置文件保存到硬盘里面。
//槽(slot)
CLUSTER ADDSLOTS <slot> [slot ...] 将一个或多个槽(slot)指派(assign)给当前节点。
CLUSTER DELSLOTS <slot> [slot ...] 移除一个或多个槽对当前节点的指派。
CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
CLUSTER SETSLOT <slot> NODE <node_id> 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
CLUSTER SETSLOT <slot> MIGRATING <node_id> 将本节点的槽 slot 迁移到 node_id 指定的节点中。
CLUSTER SETSLOT <slot> IMPORTING <node_id> 从 node_id 指定的节点中导入槽 slot 到本节点。
CLUSTER SETSLOT <slot> STABLE 取消对槽 slot 的导入(import)或者迁移(migrate)。
//键 (key)
CLUSTER KEYSLOT <key> 计算键 key 应该被放置在哪个槽上。
CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot 目前包含的键值对数量。
CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 个 slot 槽中的键。6.3.1.1. 集群(cluster) 命令
6.3.1.1.1. cluster info 查看集群状态
#查看集群状态
10.0.0.11:6379> cluster info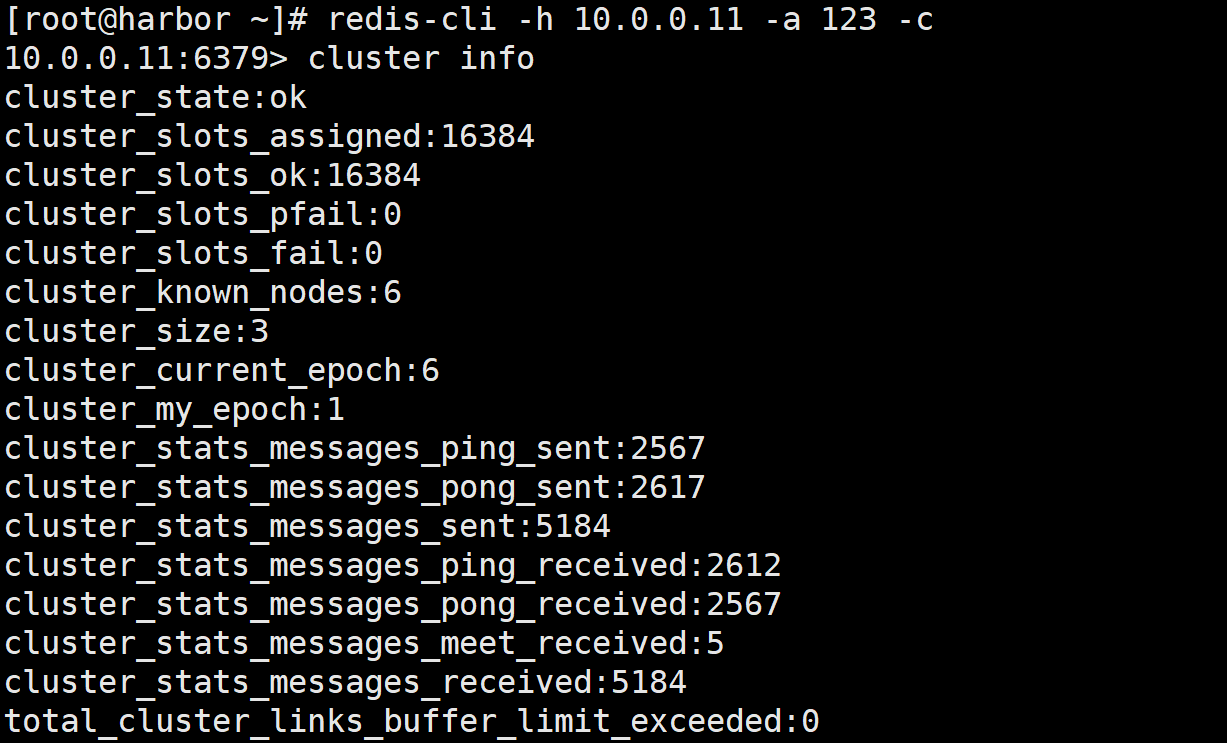
6.3.1.1.2. cluster nodes 查看集群节点信息
#查看集群节点信息
10.0.0.11:6379> cluster nodes
6.3.1.2. 节点(node)相关命令
节点(node)相关命令:
CLUSTER MEET IP PORT 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子
CLUSTER FORGET <node_id> 从集群中移除 node_id 指定的节点
CLUSTER REPLICATE <node_id> 将当前节点设置为 node_id 指定的节点的从节点
CLUSTER SAVECONFIG 将节点的配置文件保存到硬盘里面#获取节点信息,复制10.0.0.15的node_id
[root@harbor ~]# redis-cli -h 10.0.0.11 -a 123 -c cluster nodes
#从集群中移除 node_id 指定的节点10.0.0.15
[root@harbor ~]# redis-cli -h 10.0.0.11 -a 123 -c cluster forget 5a2b3bd49d4a2e5c4d28574150bb77cde8f4cf60
#查看节点信息发现节点已经删除了
[root@harbor ~]# redis-cli -h 10.0.0.11 -a 123 -c cluster nodes
#把10.0.0.15加入集群
[root@harbor ~]# redis-cli -h 10.0.0.11 -a 123 -c cluster meet 10.0.0.15 6379
#查看集群节点信息,因为之前15就是从,所以一加进来就成为了别人的从节点
[root@harbor ~]# redis-cli -h 10.0.0.11 -a 123 -c cluster nodes
#10.0.0.19是一个新的redis节点,查看集群只有自己
[root@harbor ~]# redis-cli -h 10.0.0.19 -a 123 cluster nodes
f43b57e4a3b7ab647e2db070b1793580cf7b7d95 10.0.0.19:6379@16379 myself,master - 0 0 0 connected
#查看已经存在的集群信息
[root@harbor ~]# redis-cli -h 10.0.0.15 -a 123 cluster nodes
eb17632182af15b3f221d1dfba773c09c44feb78 10.0.0.11:6379@16379 master - 0 1725022165179 1 connected 0-5460
b98dbe089e04e77009f9cb821212e9a9bbc6f1f6 10.0.0.14:6379@16379 slave 21e6bdc5cd07fec204f35a402447c503d30fb27d 0 1725022165608 3 connected
21e6bdc5cd07fec204f35a402447c503d30fb27d 10.0.0.13:6379@16379 master - 0 1725022164536 3 connected 10923-16383
5a2b3bd49d4a2e5c4d28574150bb77cde8f4cf60 10.0.0.15:6379@16379 myself,slave c4694ed93b2b026c95df93b9527a623bf6b6b46b 0 1725022164000 2 connected
c4694ed93b2b026c95df93b9527a623bf6b6b46b 10.0.0.12:6379@16379 master - 0 1725022164105 2 connected 5461-10922
#把10.0.0.19设置为10.0.0.12的从节点,这里失败了,因为还没有加入集群,要先meet
[root@harbor ~]# redis-cli -h 10.0.0.19 -a 123 cluster replicate c4694ed93b2b026c95df93b9527a623bf6b6b46b
(error) ERR Unknown node c4694ed93b2b026c95df93b9527a623bf6b6b46b
#执行meet,把10.0.0.19加入集群
[root@harbor ~]# redis-cli -h 10.0.0.15 -a 123 cluster meet 10.0.0.19 6379
OK
#把10.0.0.19设置为10.0.0.12的从节点
[root@harbor ~]# redis-cli -h 10.0.0.19 -a 123 cluster replicate c4694ed93b2b026c95df93b9527a623bf6b6b46b
OK
#查看10.0.0.19已经是10.0.0.12的从节点
[root@harbor ~]# redis-cli -h 10.0.0.15 -a 123 cluster nodes
eb17632182af15b3f221d1dfba773c09c44feb78 10.0.0.11:6379@16379 master - 0 1725022242217 1 connected 0-5460
b98dbe089e04e77009f9cb821212e9a9bbc6f1f6 10.0.0.14:6379@16379 slave 21e6bdc5cd07fec204f35a402447c503d30fb27d 0 1725022241148 3 connected
21e6bdc5cd07fec204f35a402447c503d30fb27d 10.0.0.13:6379@16379 master - 0 1725022240075 3 connected 10923-16383
5a2b3bd49d4a2e5c4d28574150bb77cde8f4cf60 10.0.0.15:6379@16379 myself,slave c4694ed93b2b026c95df93b9527a623bf6b6b46b 0 1725022241000 2 connected
f43b57e4a3b7ab647e2db070b1793580cf7b7d95 10.0.0.19:6379@16379 slave c4694ed93b2b026c95df93b9527a623bf6b6b46b 0 1725022240000 2 connected
c4694ed93b2b026c95df93b9527a623bf6b6b46b 10.0.0.12:6379@16379 master - 0 1725022240504 2 connected 5461-10922
6.4. 案例:
6.4.1. 案例1:给集群添加一个主节点步骤
#1.新节点10.0.0.20 按照上面的部署步骤里的第一步安装redis
#2.用--cluster命令把新节点加入集群,并作为主节点
[root@m10 redis-cluster]# docker exec -it redis bash
root@61cf976fdfe9:/data# redis-cli -a 123 --cluster add-node 10.0.0.20:6379 10.0.0.11:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Adding node 10.0.0.20:6379 to cluster 10.0.0.11:6379
>>> Performing Cluster Check (using node 10.0.0.11:6379)
M: eb17632182af15b3f221d1dfba773c09c44feb78 10.0.0.11:6379
slots:[0-5460] (5461 slots) master
S: f43b57e4a3b7ab647e2db070b1793580cf7b7d95 10.0.0.19:6379
slots: (0 slots) slave
replicates c4694ed93b2b026c95df93b9527a623bf6b6b46b
S: 5a2b3bd49d4a2e5c4d28574150bb77cde8f4cf60 10.0.0.15:6379
slots: (0 slots) slave
replicates c4694ed93b2b026c95df93b9527a623bf6b6b46b
M: 21e6bdc5cd07fec204f35a402447c503d30fb27d 10.0.0.13:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: b98dbe089e04e77009f9cb821212e9a9bbc6f1f6 10.0.0.14:6379
slots: (0 slots) slave
replicates 21e6bdc5cd07fec204f35a402447c503d30fb27d
M: c4694ed93b2b026c95df93b9527a623bf6b6b46b 10.0.0.12:6379
slots:[5461-10922] (5462 slots) master
2 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Getting functions from cluster
>>> Send FUNCTION LIST to 10.0.0.20:6379 to verify there is no functions in it
>>> Send FUNCTION RESTORE to 10.0.0.20:6379
>>> Send CLUSTER MEET to node 10.0.0.20:6379 to make it join the cluster.
[OK] New node added correctly.
#3. 检查集群,发现新添加的节点是没有哈希槽的
root@61cf976fdfe9:/data# redis-cli -a 123 --cluster info 10.0.0.11 6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.11:6379 (eb176321...) -> 0 keys | 5461 slots | 0 slaves.
10.0.0.13:6379 (21e6bdc5...) -> 0 keys | 5461 slots | 1 slaves.
10.0.0.12:6379 (c4694ed9...) -> 1 keys | 5462 slots | 2 slaves.
10.0.0.20:6379 (dd94c96c...) -> 0 keys | 0 slots | 0 slaves.
#4. 为新节点分配哈希槽,手动计算16383/4=4096,所以要给新节点分配4096个hash槽,第二个选择项选all
root@61cf976fdfe9:/data# redis-cli -a 123 --cluster reshard 10.0.0.20:6379
......
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? dd94c96c771f8cf58590ccf6ffe7f1967c27209e
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all
Ready to move 4096 slots.
......
#检查发现新节点已经有了hash槽
root@61cf976fdfe9:/data# redis-cli -a 123 --cluster info 10.0.0.11 6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.11:6379 (eb176321...) -> 0 keys | 4096 slots | 0 slaves.
10.0.0.13:6379 (21e6bdc5...) -> 0 keys | 4096 slots | 1 slaves.
10.0.0.12:6379 (c4694ed9...) -> 0 keys | 4096 slots | 1 slaves.
10.0.0.20:6379 (dd94c96c...) -> 1 keys | 4096 slots | 1 slaves.
[OK] 1 keys in 4 masters.6.4.2. 案例2:集群下线一个主节点步骤
下线主节点步骤:
- 检查集群信息,如果这个主节点上有从节点,从节点需要下线或者转为别的主节点的从节点
- 主节点的从节点不存在后,转移主节点上的槽到别的主节点
- 下线主节点
注意事项:
- 如果主节点上有从节点,主直接下线,从节点将变为主节点
- 在移除某个节点之前,首先不能在登入该节点当中,否则不能正常移除该节点
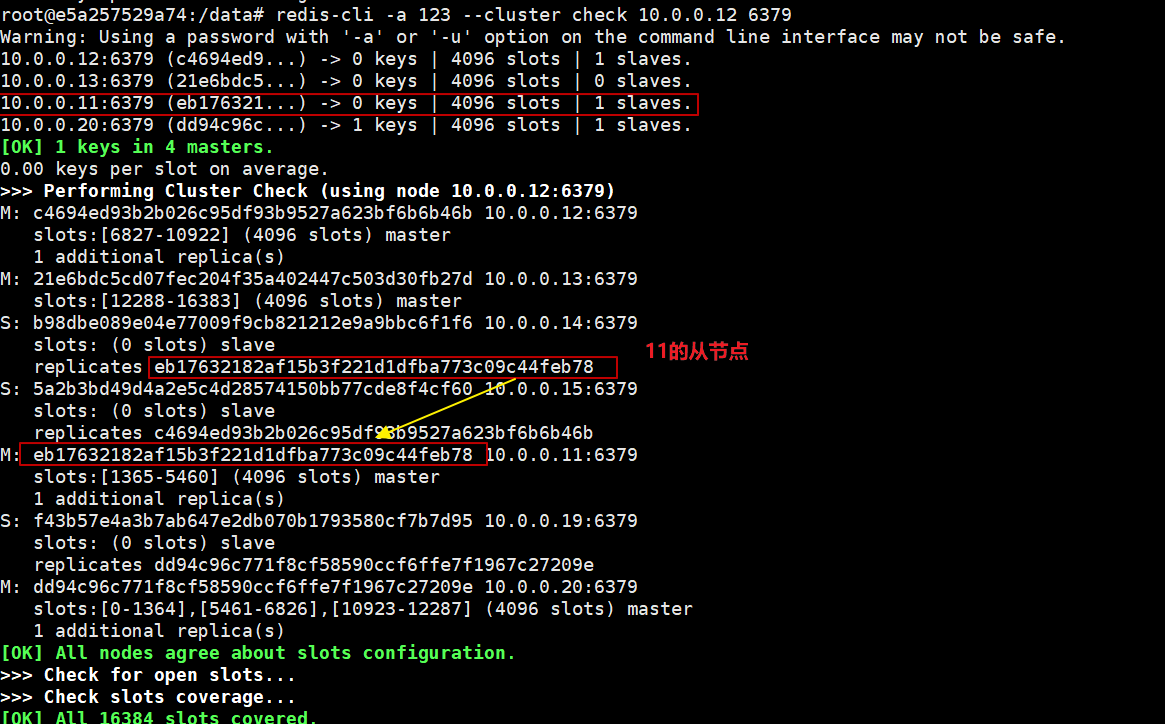
1. #检查集群信息,看10.0.0.11的从节点是10.0.0.14
root@e5a257529a74:/data# redis-cli -a 123 --cluster check 10.0.0.12 6379
#2 移除从节点
root@e5a257529a74:/data# redis-cli -a 123 --cluster del-node 10.0.0.14:6379 b98dbe089e04e77009f9cb821212e9a9bbc6f1f6
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Removing node b98dbe089e04e77009f9cb821212e9a9bbc6f1f6 from cluster 10.0.0.14:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
#3 迁移主节点数据,共4096个槽位在10.0.0.11上面,所以要手动计算下如何分配到其他3个主节点上,这里是1364+1364+1368
redis-cli -a 123 --cluster reshard 10.0.0.11:6379 --cluster-from eb17632182af15b3f221d1dfba773c09c44feb78 --cluster-to c4694ed93b2b026c95df93b9527a623bf6b6b46b --cluster-slots 1364 --cluster-yes
redis-cli -a 123 --cluster reshard 10.0.0.11:6379 --cluster-from eb17632182af15b3f221d1dfba773c09c44feb78 --cluster-to 21e6bdc5cd07fec204f35a402447c503d30fb27d --cluster-slots 1364 --cluster-yes
redis-cli -a 123 --cluster reshard 10.0.0.11:6379 --cluster-from eb17632182af15b3f221d1dfba773c09c44feb78 --cluster-to dd94c96c771f8cf58590ccf6ffe7f1967c27209e --cluster-slots 1368 --cluster-yes
#4 下线主节点
redis-cli -a 123 --cluster del-node 10.0.0.11:6379 eb17632182af15b3f221d1dfba773c09c44feb786.4.3. 案例3:cluster重新创建
- 关闭所有已启动的redis节点
- 删除集群相关文件(在设置数据存储目录dir目录下) 删除每个节点下的appendonlydir 、dump.rdb和nodes.conf文件
- 启动所有Redis节点
- 重新创建cluster集群
|









![洛谷 P3183 [HAOI2016]食物链(记忆化搜索/拓扑排序)](https://i-blog.csdnimg.cn/direct/6c26222b73d54a8f90c38253737473ae.jpeg)