- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
- GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。
- 作者: 如常
Debezium Incremental snapshotting
Introduction
CDC(Change-Data-Capture)正被广泛应用于数据缓存、更新查询索引、创建派生视图、异构数据同步等场景,Debezium 作为 CDC 的代表项目之一,它收集数据库中的事务日志(变化事件)并以统一的事件流格式输出(支持「Kafka Connect」及「内嵌到程序中」两种应用形式)。
数据库的事务日志往往会进行定期清理,这就导致了仅使用事务日志无法涵盖所有的历史数据信息,因此 Debezium 在进行事件流捕获前通常会执行 consistent snapshot(一致性快照) 以获取当前数据库中的完整数据。默认情况下,事件流的捕获会在 consistent snapshot 完成之后 开启,不同数据量情况下,这个过程可能会耗费数小时乃至数天,并且一旦这个过程由于某些异常因素停止,那重新开启后,它将从头开始执行。
为了解决一致性快照的这些痛点问题,Debezium 提出了一个新的设计方案,并在 DDD-3 中详细介绍了该方案的核心理论,借鉴了 DBLog 中的思想,使用一种基于 Watermark 的框架,实现了 Incremental snapshotting。
Incremental snapshotting 的优势
- 在任何时间都可以触发快照的动作,除了在捕获事件流前进行一次完整的快照外,在下游数据备份、丢失、恢复的场景中,往往也需要进行快照操作;
- 快照可在执行过程中「挂起」和「恢复」,并且恢复执行后可定位到挂起前的位置,无需再从头开始;
- 在执行快照时,不需要暂停事件流的捕获,也就是说快照可以和事件捕获同时执行,互不影响,保证了事件流的低延迟性;
- 无锁,保证了在快照的同时数据库依然能够写入。
下面详细介绍 DBLog 论文中的方案。
DBLog
- DBLog 使用基于 Watermark 的方法,它能在直接使用
select from对数据库进行快照的同时捕获数据库的变化事件流,并使用相同的格式对select快照和事务日志捕捉进行输出。这意味着 DBLog 可选择在任意时刻开始执行快照,而不仅限于事件日志捕获开始前。 - DBLog 同时支持快照的挂起和恢复,归功于它将数据按 chunk 进行划分,并且在外部系统(如 Zookeeper)中存储最近一次执行完成的 chunk。
- DBLog 的输出通常为 Kafka,支持将输出结果落库和使用 API 获取。
- DBLog 支持高可用,使用主备的方式保证同一时间会有一个活跃的实例处于正常工作状态,多个备用实例处于等待状态,一但工作中的实例发生异常,备用实例将会激活,替代原实例工作。
DBLog 的架构如下图所示:
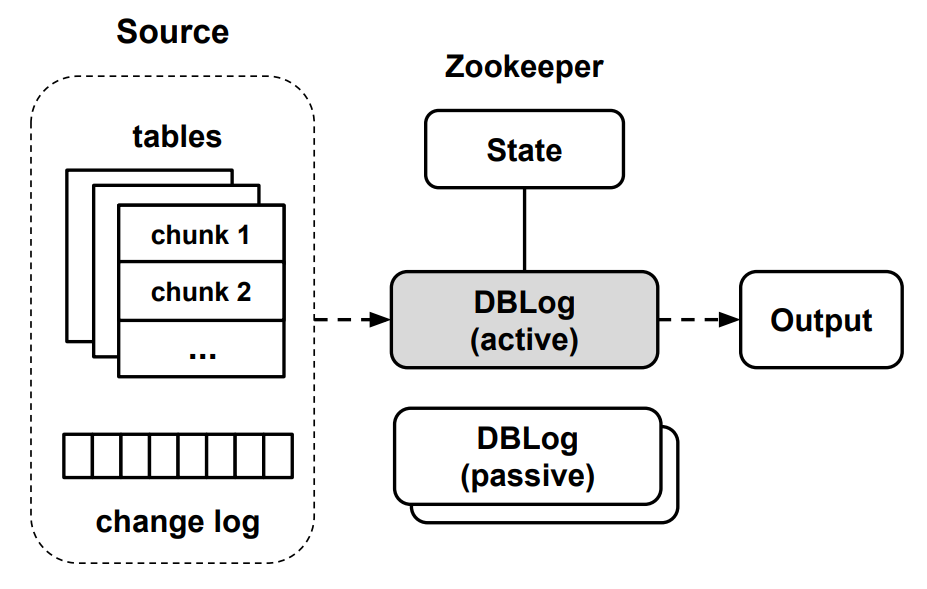
下面将详细介绍 DBLog 的事务日志捕获和快照机制。
事务日志捕获( Transaction log capture)
事务日志捕获依赖于数据库的支持,如 MySQL 和 PostgreSQL 都提供了 replication 协议,DBLog 将作为数据库主节点的一个从节点,数据库主节点在事务执行完成后会向 replication 从节点发送事务日志(经由 TCP)。通常的事务日志中包含 create、update 和 delete 类型的事件,DBLog 对这些事件进行处理,最终包装为一种统一的格式输出,输出的结果将包含各 column 在事务发生时的状态(事务发生前后的值),每个事件的包装都会以一个 8-byte 且严格单调递增的 LSN(Log Sequence Number)标识,该 LSN 表示该事件在事务日志中的偏移量。上述处理后的输出结果将会存储在 DBLog 进程的内存中,由另外的辅助线程将这些结果搬运到最终的目的地(如 Kafka、DB 等)。
事务日志中还包含了 schema 变化相关的事件,需要妥善处理,但不是本文讨论的重点,这里暂且忽略不提。
完整状态捕获(Full state capture)
事务日志由于定期清理等原因,通常无法保存当前数据库的所有历史状态,而在许多应用场景(如同步)中,都需要保证能完整重现源库的所有数据,这就需要提供一种扩展的 Full state capture 机制。一种较为直观的手段是对每个表建立相应的 copy 表,并将原表中的数据按批(Chunk)写入到 copy 表中,这些写入操作就会按照正确的顺序产生一系列的事务日志事件,在后续处理中就可以正确消费到这些事件(此时正常的事务事件可以同时生成)。这种方式的缺点在于需要消耗 IO 和磁盘空间,虽然可以使用诸如 MySQL bloackhole engine 规避,但实现方式依赖于数据库提供商的特性,没有泛用性。
DBLog 提供了一种更为通用且对源库影响较小策略,它无需将所有的源表中的数据写入到事务日志中,而是采用分批处理的方式,以 Chunk 为单位将源表中的数据查询出来(严格要求每次查询都以主键排序),将这些数据处理成为 DBLog 中的事件结果,并添加到该过程中产生的正常事务事件结果之后。执行过程中需要在外部存储(如 Zookerper)中存储上一个已完成的 Chunk 的最后一行的主键值,这样当这个过程被挂起后,就可以根据这个主键值恢复定位到最近一次执行成功的位置。
下图为 Chunk 的示例,该表中的主键为 c1,且查询时按 c1 进行排序,Chunk size 为 3。当执行 Chunk2 的查询时,会从存储中取出一个表示 Chunk1 最后一行数据的主键 4,而后执行的 Chunk2 查询就会增加条件 c1 > 4。
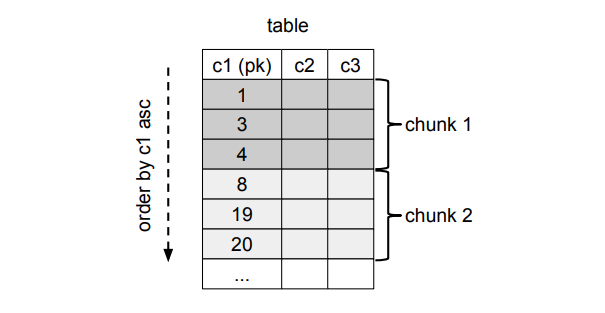
由于在查询 Chunk 过程中,正常的事务事件仍然同时在产生和执行,为了保证这个过程中不会发生「新数据」被「旧数据」覆盖的情况,每个 Chunk 在与正常事件合并前需要进行特殊处理。核心算法就是在正常的事务事件流中人为插入 Watermark 事件以标记 Chunk 的起止位置,Watermark 就是我们在源端库中创建的一张特殊的表,它由唯一的名称标识,保证不与现有的任何表名冲突,这个表中仅存储 一行一列 的数据,该记录中的数据为一个永不重复的 UUID,这样每当对这个记录进行 update 时,就会在事务日志中产生一条有 UUID 标识的事件,这个事件就称为 watermark event。
下面算法就是整个 Full state capture 的核心步骤:
Algorithm: Watermark-based Chunk Selection
Input: table
(1) pause log event processing
lw := uuid(), hw := uuid()
(2) update watermark table set value = lw
(3) chunk := select next chunk from table
(4) update watermark table set value = hw
(5) resume log event processing
inwindow := false
// other steps of event processing loop
while true do
e := next event from changelog
if not inwindow then
if e is not watermark then
append e to outputbuffer
else if e is watermark with value lw then
inwindow := true
else
if e is not watermark then
(6) if chunk contains e.key then
remove e.key from chunk
append e to outputbuffer
else if e is watermark with value hw then
(7) for each row in chunk do
append row to outputbuffer
// other steps of event processing loop
...
该算法流程会一直循环,直至表中的所有数据都被处理完成。
- 步骤 1 暂停当前的正常事件日志捕获并生成两个 UUID:
lw、hw。注意这里是暂停 DBLog 对事件的捕获,而不是暂停源端数据库的日志写入,这个暂停过程中仍然可以有很多的写入事件发生,这个暂停的过程较为短暂,在步骤 5 中会恢复; - 步骤 2 和步骤 4 分别使用步骤 1 中生成
lw和hw去修改 Watermark 表中的记录,这将会在事务日志中记录两个 update 事件; - 步骤 3 查询某一个 Chunk 中的所有记录,并将查询的结果 chunk 保存在内存中,这个操作被夹在两个 watermark 的更新操作之间,后续的处理流程就可以以这两个位置为依据标识出哪些事件是在这次 Chunk 查询过程中发生的;
- 步骤 5 开始,恢复正常的事件日志捕获,并循环遍历每个按顺序捕获到的事件,如果事件发生在
lw前,则直接添加到输出结果的内存中; - 如果事件
e进入到了lw和hw的区间中,则会在步骤 3 中的结果 chunk 中剔除与e具有相同主键的记录,lw和hw窗口内到达的事件表示在查询 Chunk 过程中有更「新」的数据达到,因此剔除掉 chunk 结果中的「旧数据」,保证「新数据」能够被最终结果应用; - 如果事件
e已经超过了hw,则直接将 chunk 结果中剩余的所有记录附加到输出结果末尾。
下面以一个具体的例子来演示一下算法的过程:
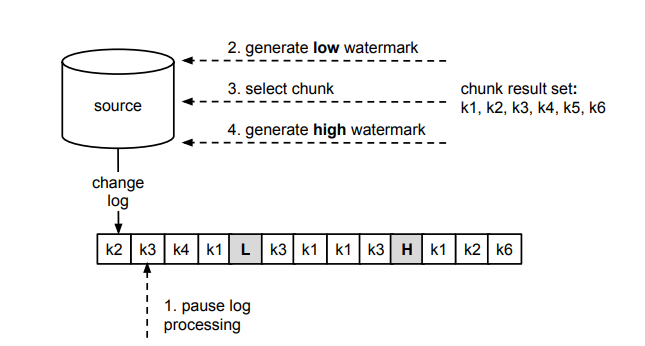
上图中以 k1-k6 表示一张表中的主键值,change log 中的每个事务日志事件也以主键标识为对该行数据的修改,步骤 1-4 与算法中的步骤编号相对应。图中表示了某次 Chunk 的查询过程,暂停事件日志捕获后,先后执行了步骤 2-4,在内存中产生了一个 chunk 结果,并在源数据库的事务日志中记录了两条 watermark。

上图中是步骤 5-7 的过程,我们以主键作为依据,从 chunk 结果中剔除了 L 和 H 窗口中修改数据事件对应的相关记录。
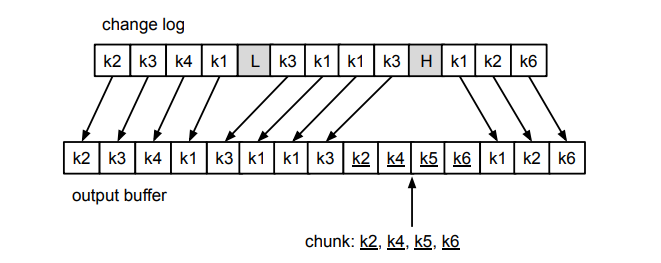
最终,将剩余的 chunk 结果附加到 H 之后,就完成了一个 Chunk 的选择过程。
总结
本文详细介绍了 Debezium 的 Incremental snapshot 的实现基础——DBLog,它在原有的 CDC 基础上使用一种基于 Watermark 的框架,扩展了 Full state capture 的功能,能够在事务日志事件捕获开启的同时执行快照,支持挂起和恢复操作,且用户能在任何时间点开启该快照操作。
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
捉虫活动详情:https://greatsql.cn/thread-97-1-1.html
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html




![[附源码]java毕业设计网上书店系统](https://img-blog.csdnimg.cn/683583f907194d3e8953113b5338fa74.png)