前言:2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测2,GLM-130B 是亚洲唯一入选的大模型。GLM-130B 在准确性和恶意性指标上与 GPT-3 175B持平。chatglm1,2,3代在模型架构上基本一样,本文主要讲解模型结构。
目录
- 1. 大模型基础知识
- 1.1 主流预训练模型架构
- 1.2 文本生成评价指标
- 1.2.1 BLUE(Bilingual Evaluation Understudy)
- 1.2.2 ROUGE
- 1.3 Prefix Decoder-only
- 2. GLM
- 2.1 整体架构
- 2.2 预训练目标
- 2.3 自编码器
- 参考文献
1. 大模型基础知识
1.1 主流预训练模型架构

√是擅长,—是可以做,x是做不了。自编码是利用的上下文信息(双向注意力机制),自回归是从左到右的生成信息(单向注意力机制)。
1.2 文本生成评价指标
1.2.1 BLUE(Bilingual Evaluation Understudy)
- 应用:主要用于翻译系统,对比机器翻译输出与参考翻译之间的相似度。
- 原理:主要是对比n-gram,采用不同长度的n-gram加权和的方式计算得分,每一个n-gram得分包含精确匹配率(Precision)和修改程度惩罚(Brevity Penalty)。
- 精确匹配率(Precision):衡量生成翻译中的n-gram有多少出现在参考翻译中。精确匹配率的计算方法为:将生成翻译中的n-gram与参考翻译中的n-gram进行比较,统计匹配的数量。
- 修改程度惩罚(Brevity Penalty):为了惩罚生成翻译比参考翻译更短的情况,BLEU引入了修改程度惩罚项。它通过计算机器翻译与参考翻译之间的长度差异来调整BLEU的得分。
- 计算公式: s c o r e = B r e v i t y P e n a l t y ∗ ( ∑ ( P r e c i s i o n i ) / N ) {score = Brevity Penalty*(\sum(Precision_i)/N)} score=BrevityPenalty∗(∑(Precisioni)/N),N表示不同长度的n-gram数量。
1.2.2 ROUGE
- 应用:评估自动摘要系统生成的摘要质量的指标。主要目的是衡量自动摘要结果与参考摘要之间的相似程度,从而判断生成的摘要是否包含了关键信息并保持了原文的主旨
- 原理:
- 召回率(Recall):以相应的n-gram单位(例如单词或短语)为基准,计算生成摘要中有多少个n-gram出现在参考摘要中,并将其总数作为分子,参考摘要中所有的n-gram总数作为分母。
- 精确率(Precision):以相应的n-gram单位为基准,计算生成摘要中有多少个n-gram出现在参考摘要中,并将其总数作为分子,生成摘要中所有的n-gram总数作为分母。
- F1值:综合考虑召回率和精确率,计算出一个综合指标,即F1值。F1值是召回率和精确率的调和平均。
- 分类:
- ROUGE-N:衡量n-gram(通常是单词)的重叠率。其中,ROUGE-1表示单个词的重叠,ROUGE-2表示相邻两个词的重叠,以此类推。ROUGE-N主要用于评估生成摘要中与参考摘要中重要短语的重合度,判断摘要的概括能力。
- ROUGE-L:基于最长公共子序列(Longest Common Subsequence)计算两个摘要之间的相似度。它不仅考虑了重叠的单词和短语,还考虑了它们的顺序关系。ROUGE-L适用于评估生成摘要中保持参考摘要结构和重要信息的能力。
- ROUGE-S:用于评估生成和参考摘要之间连续子序列的重叠程度。它通过计算包含Skip-bigram的共同片段数来衡量。ROUGE-S在考虑长距离依赖和多样性方面比较有效。
- 案例:
原文:“AI机器人能够通过深度学习技术从海量数据中学习,并利用自然语言处理技术生成准确流畅的摘要。”
摘要生成:“AI机器人通过深度学习和自然语言处理技术生成摘要。”
参考摘要:“AI机器人通过深度学习技术从大量数据中学习,并生成准确流畅的摘要。”
计算:通过ROUGE-1来衡量召回率,我们可以计算出生成摘要与参考摘要的重叠词数为7,参考摘要中共有8个单词,因此ROUGE-1的召回率为7/8,精确率为7/7,F1值为1。这说明生成的摘要完全覆盖了参考摘要中的所有单词,质量较高。
1.3 Prefix Decoder-only
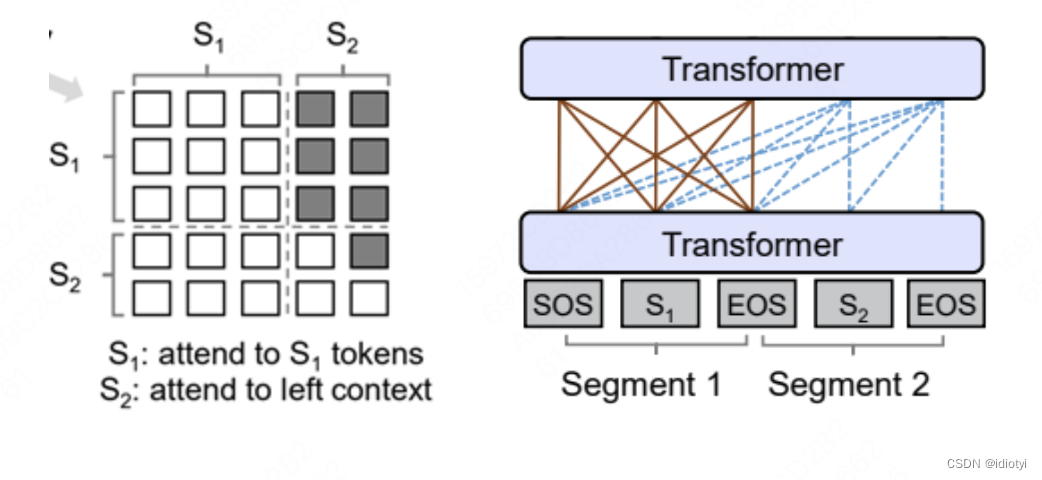
- Prefix LM
不同于标准的encoder-decoder模型,prefix LM中编码器会解码器共用一个transformer。Prefix LM在Encoder部分采用Auto Encoding (AE-自编码)模式,即前缀序列中任意两个token都相互可见,而Decoder部分采用Auto Regressive (AR-自回归)模式,即待生成的token可以看到Encoder侧所有token(包括上下文)和Decoder侧已经生成的token,但不能看未来尚未产生的token。
- Casual LM
只涉及到Encoder-Decoder中的Decoder部分,采用Auto Regressive模式。
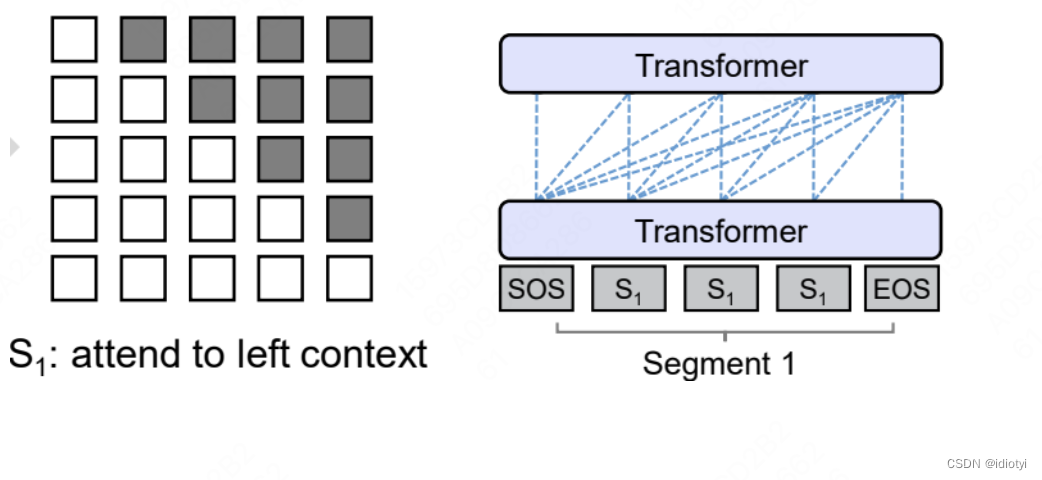
- decoder only
生成式架构。Decoder-Only 架构还有一个重要特点是可以进行无监督预训练。在预训练阶段,模型通过大量的无标注数据学习语言的统计模式和语义信息。OpenAI的GPT系列(如GPT-4)是Decoder-Only架构的经典例子。
2. GLM
2.1 整体架构

核心思想:GLM 通过添加二维位置编码和允许任意顺序预测空白区域,改进了空白填充预训练。随机mask一些词语(自编码),按照一定的顺序预测mask的词语(自回归),并且GLM打乱了空白区域的预测顺序
二维位置编码:第一个维度对span在原文本中的位置进行编码,第二个维度对token在span中的位置进行编码。
注意力矩阵:在步骤(d)中,Part A采用自编码的形式,但是只能看到A自己的K,V,而对于B,按照自回归的顺序看K,V
2.2 预训练目标
制定了三种针对自回归的预训练目标:
- token-level objective 单词级
- sentence-level objective 句子级
- document-level objective 文档级
2.3 自编码器
相较于transformer的编码器,做了如下改进:
- 调整了LN和残差连接的顺序
- 对于token的预测输出用的是单个的线性层
- 将激活函数由ReLU调整为了GeLUs
参考文献
[1]GLM: General Language Model Pretraining with Autoregressive Blank Infifilling
[2]文本生成评估指标:ROUGE、BLEU详谈