其实现在的OpenAI挺烦人的,和之前Ilya在的时候就不太一样了,Schulman也走了, 尤其Schulman走了是真的可惜,因为他是整个后训练,包括微调尤其是RLHF的真正操盘手
Altman发草莓然后又没下文,挺败好感的,大家最近也总被草莓这个事刷屏,估计很多同学想理解一下草莓到底是啥?
Strawberry 其实就是最早的Q*,其实可以理解为强化学习算法又一次证明自己的地方,现在堆语料玩pretrain基本上已经玩到头了
而合成数据这个领域呢,我是不支持不反对的那波人,可是合成数据会有很大的继承问题,我的微博,朋友圈也都发过,如下:
一大堆拿着gpt和llama3做合成数据的模型,目前面对了一个比较严重的问题(llama自己都受到了合成数据的一定范围的困扰),前代大模型的一些错误认知,都遗传并且污染了训练集,后面的模型把错误也不可逆的继承了,而且随着迭代轮次的加深,越来越被强化。目前的语言模型本质上还是概率统计,既然是统计概率,从数学的角度上看 :那么就会有统计近似误差,大概率的知识就永远被强化,小概率就越来越被忽略了。还有函数近似误差,比如量化,比如取近似导致的误差,一代一代就被保留了下来
所以Schlman他们对齐组的,就要从RLHF上下功夫,诞生了Q*和草莓这些相对玩的很新的RL算法来提升模型的能力,当然最终目标都是AGI,可是AGI如果面对的全是幻觉,它必然不是AGI,我可以给出结论,Q*和草莓,不是AGI路上的唯一需要解决问题的办法,但肯定是必要的那个。
我们知道传统的模型训练,包括Pratrain,Finetune,RLHF这些步骤,如果这些不懂的,建议先看我以前文章,否则一会读起来可能会有点吃力
链接:
从词表到RLHF一镜到底训练一个大模型 (qq.com)
RLHF这块
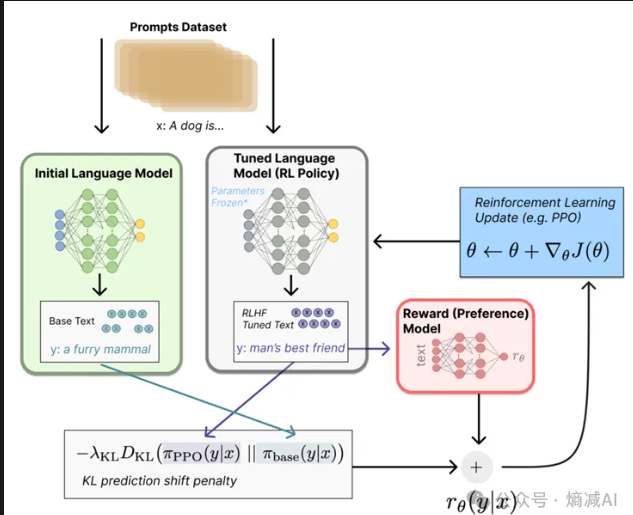
以前就很多人问我,你训练就训练为啥还要摆个基准模型在那搞KL散度,这个我以前讲过你不放个基准模型的答案一起比较KL,RL是真的给你往舔狗了回啊,往往人类越喜欢什么样的答题风格,它就往那个答案上盯着,那么为什么,说白了,为了得到更高的分数,这是这个系统就这样的设定的。所以KL散度能一定程度上防止它过于舔狗,但是能不能彻底解决,那必然是不能的,GPT4o之前你们没发现过吗?大模型明明回答你的问题肯呢个是对的,但是你要说,我以前认为的不是这样的,它整不好就告诉你,那是我记错了,应该是这样回答的,然后巴拉巴拉,按着你的错误答案给一顿云回答。
这东西怎么AGI啊,所以我一个哥们一直说LLM是傻子,也不是没道理。
那Q* 或者草莓解决了什么问题呢?
就解决这个问题,学术一点的说法叫做
“从结果监督的RL到对过程监督的RL的实现”不用搜,网上没有这话,这都我总结的,你要是此刻看到了,就偷着乐吧

上图说明的舔狗强化学习RL,就是唯结果论,这种东西在解数学题和代码上尤其没法弄,这两种行为它往往上多段式推理,同时问题的语义相近,但是里面的一些entity的参数不一样,那结果是完全不一样的。所以你们以前看到过好多LLM的数学和代码笑话,原因就在这
OAI自己出了一片论文 step by step,其中有作者就是Schulman...
2305.20050 (arxiv.org)
这个论文把写的其实很含蓄,GPT-3之后OAI自己就不太认真对外发表算法啥的了,都是实验性的东西
和这个道理基本一样的是STAR既“ Self-Taught Reasoner”,斯坦福的一篇论文,也不算新
2203.14465 (arxiv.org) 有兴趣的可以看一下这个
这个其实就是过程监督RL的一个体现,不过这个论文的问题是写的列子都比较浅层
我这里随便挑一个讲吧
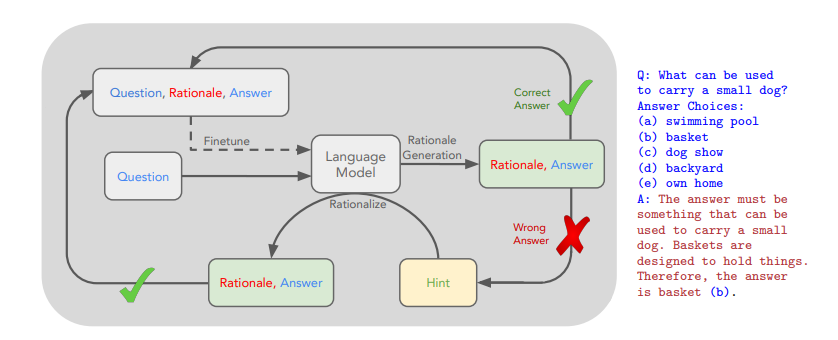
如图所示,在你给到模型一个问题和数据答案的时候,比如用什么东西装小狗,出了b,以外,你要告诉模型,这个答案那必须是basket,因为它就是被设计出来拎东西的,诸如此类
这其实是一步推理,如果把步骤拆开,比如解数学论证,道理是一样的
这个红色的东西它稳中叫做rationalization,也就是合理性,你的每一步的推理到你的最终答案,出了给我中间的每部解乏的中间答案以外(COT),你要把你的合理性给我做出来。
用数学来设计和理解,就是这样的:
给定一个预训练好的LLM “M” 和一个带有答案的问题数据集 "D"
![]()
我们的方法从一个小的示例集合 “P” 开始,这些示例包含中间推理
![]()
|P|《 |D|,将提示和这些推理由ri链接到每个问题xi,,我就让模型来学习生成的推理步骤(rationalization)和答案yi, 然后每次生成的合理性推理步骤和答案我都验证,反复的循环来扩充我的数据集
解释:一开始P很小,但是P让模型学到了过程(过程监督吗)。然后拿P对模型RLHF,模型牛B了一些,继续来做D里的其他的数据集,让原来没有rationalization,只有答案的数据集D,变为两者间距的D', 然后再回来搞模型下一轮的RL.模型越来越牛B,还可以搞别的数据集去了。。。。
当然整个RL的损失函数和后面训练的梯度也都变了,可以理解成这样
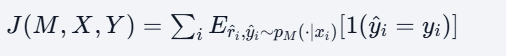
J是奖励函数,描述了模型M在给定输入x和然后回答y,就这么个动作,来得到的总奖励期望
它的梯度就得为

这快没啥讲的,就是上一步的指式函数么1(^yi=yi),要是就是1不是就是0,然后算一个对数概率梯度。
我的文章一般写算法读的人都比较少,为了增大阅读量,我再通俗一点。
比如是你让机器看你打一局农药
可能机器看你赢了,但是真说学到啥了,那不一定
因为关联性对战局影响太大了
比如
-
兵线
-
你的队友级别
-
你的队友出装
-
是不是抢大龙了
-
两边人员配置
而且每个变更(例如你3杀)都应该有实时反馈,正向负向
原来的RL,它不是一点也学不到,但是它无法对每一步都研究的特透,有人可能拿围棋的AlphaGO跟我抬杠,这个例子其实不错,但是首先围棋它和你解决AGI这种通用问题不一样,第一它有严格的规则,而且理论上来讲就那么个棋牌,是有固定的讨论,所以你只要给它足够的把数,让它硬搞,它是能学到某些隐空间里定义的套路,但是对于NLP这种动辄就把人类社会的所有知识点都拿来pretrain的业务,你让它像Alpha Go这样死命练是不够的,更别提好多数据集了的答案甚至都是错的。
还是回答打农药的这个问题
正因为它分析了每一步对战局的影响,然后它有个整体的期望E,它要想赢就可以找以前训练里面的那些后续步骤会对赢这个事情有更好的反馈,然后一步一步的往赢了去搞,理论上和解数学题也是一样的。
对这种数据构成比较感兴趣的,可以去看看OpenAI开放的数据集PRM800K
当然Q*和草莓肯定不止于此,但是多少能让你理解到什么是step by step,什么是star
另外一个值得关注的就是TOT替换COT
COT的一大问题就是容易跑偏,LLM毕竟是概率模型,plan太多生成就跑题了也正常
用TOT如果不考虑算力的情况下(他家正常训练也用不到那么多卡),在思考反省回退的过程中不断迭代。也会对产出最终答案的正确性起到非常大的作用
好,做个总结就是OpenAI 的草莓,就是强化学习的一个enhancement,但是绝对是立竿见影,再加上TOT,就能产生牛B的数据集(带合理性推理的),对,这玩意是造数据的,也是Reward,反正都在RL那块,但是它可不是主模型
然后给下一代大模型Orion来用,其实Orion好像应该是GPT-6了,那可能GPT-5就不会发售了把,或者给个阉割版本的,在秋天发售也说不好。
本文完



















