目录
前言
一、什么是MindSpore Hub
1.简单介绍
2.MindSpore Hub包含功能
3.MindSpore Hub使用场景
二、安装MindSpore Hub
1.确认系统环境信息
2.安装
3.下载源码
4.进行验证
三、加载模型
1.介绍
2.推理验证
3.迁移学习
四、模型发布
前言
MindSpore着重提升易用性并降低AI开发者的开发门槛,MindSpore原生适应每个场景包括端、边缘和云,并能够在按需协同的基础上,通过实现AI算法即代码,使开发态变得更加友好,显著减少模型开发时间,降低模型开发门槛。通过MindSpore自身的技术创新及MindSpore与华为昇腾AI处理器的协同优化,实现了运行态的高效,大大提高了计算性能;MindSpore也支持GPU、CPU等其它处理器。
一、什么是MindSpore Hub
1.简单介绍
官方版本的预训练模型中心库---MindSpore Hub
mindspore_hub 是一个Python库
下载网址:点击跳转
2.MindSpore Hub包含功能
-
即插即用的模型加载
-
简单易用的迁移学习
import mindspore
import mindspore_hub as mshub
from mindspore import set_context, GRAPH_MODE
set_context(mode=GRAPH_MODE,
device_target="Ascend",
device_id=0)
model = "mindspore/1.6/googlenet_cifar10"
# Initialize the number of classes based on the pre-trained model.
network = mshub.load(model, num_classes=10)
network.set_train(False)
# ...
3.MindSpore Hub使用场景
· 推理验证:mindspore_hub.load用于加载预训练模型,可以实现一行代码完成模型的加载。
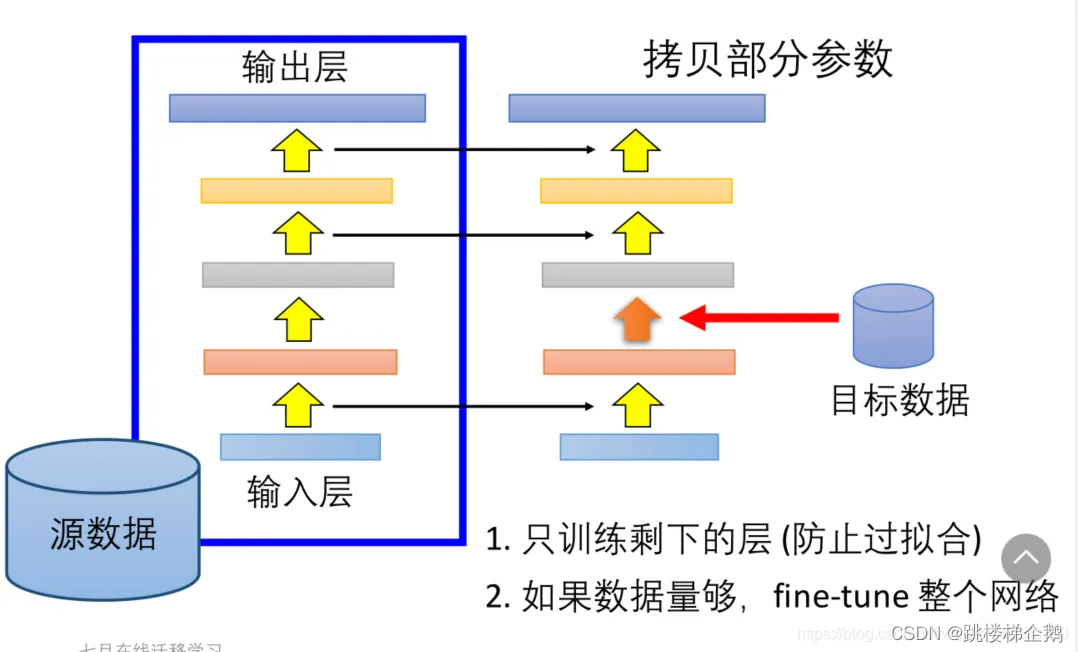
· 迁移学习:通过mindspore_hub.load完成模型加载后,可以增加一个额外的参数项只加载神经网络的特征提取部分,这样就能很容易地在之后增加一些新的层进行迁移学习。
· 发布模型:可以将自己训练好的模型按照指定的步骤发布到MindSpore Hub中,以供其他用户进行下载和使用。
二、安装MindSpore Hub
1.确认系统环境信息
硬件平台支持Ascend、GPU和CPU。
确认安装Python 3.7.5版本。
MindSpore Hub与MindSpore的版本需保持一致。
MindSpore Hub支持使用x86 64位或ARM 64位架构的Linux发行版系统。
在联网状态下,安装whl包时会自动下载
setup.py中的依赖项,其余情况需自行安装。
2.安装
在命令行中输入下面代码进行下载MindSpore Hub whl包
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/{version}/Hub/any/mindspore_hub-{version}-py3-none-any.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
3.下载源码

从Gitee下载源码。
git clone https://gitee.com/mindspore/hub.git -b r1.9
编译安装MindSpore Hub。
cd hub ##切换到hub文件下
python setup.py install ## 下载4.进行验证
在能联网的环境中执行以下命令,验证安装结果。
import mindspore_hub as mshub
model = mshub.load("mindspore/1.6/lenet_mnist", num_class=10)
如果出现下列提示,说明安装成功:
Downloading data from url https://gitee.com/mindspore/hub/raw/r1.9/mshub_res/assets/mindspore/1.6/lenet_mnist.md
Download finished!
File size = 0.00 Mb
Checking /home/ma-user/.mscache/mindspore/1.6/lenet_mnist.md...Passed!三、加载模型
1.介绍
于个人开发者来说,从零开始训练一个较好模型,需要大量的标注完备的数据、足够的计算资源和大量训练调试时间。使得模型训练非常消耗资源,提升了AI开发的门槛,针对以上问题,MindSpore Hub提供了很多训练完成的模型权重文件,可以使得开发者在拥有少量数据的情况下,只需要花费少量训练时间,即可快速训练出一个较好的模型。
2.推理验证

##使用url完成模型的加载
import mindspore_hub as mshub
import mindspore
from mindspore import Tensor, nn, Model, set_context, GRAPH_MODE
from mindspore import dtype as mstype
import mindspore.dataset.vision as vision
set_context(mode=GRAPH_MODE,
device_target="Ascend",
device_id=0)
model = "mindspore/1.6/googlenet_cifar10"
# Initialize the number of classes based on the pre-trained model.
network = mshub.load(model, num_classes=10)
network.set_train(False)
最后使用MindSpore进行推理
3.迁移学习
#使用url进行MindSpore Hub模型的加载,注意:include_top参数需要模型开发者提供。
import os
import mindspore_hub as mshub
import mindspore
from mindspore import Tensor, nn, set_context, GRAPH_MODE
from mindspore.nn import Momentum
from mindspore import save_checkpoint, load_checkpoint,load_param_into_net
from mindspore import ops
import mindspore.dataset as ds
import mindspore.dataset.transforms as transforms
import mindspore.dataset.vision as vision
from mindspore import dtype as mstype
from mindspore import Model
set_context(mode=GRAPH_MODE, device_target="Ascend", device_id=0)
model = "mindspore/1.6/mobilenetv2_imagenet2012"
network = mshub.load(model, num_classes=500, include_top=False, activation="Sigmoid")
network.set_train(False)
#在现有模型结构基础上,增加一个与新任务相关的分类层。
class ReduceMeanFlatten(nn.Cell):
def __init__(self):
super(ReduceMeanFlatten, self).__init__()
self.mean = ops.ReduceMean(keep_dims=True)
self.flatten = nn.Flatten()
def construct(self, x):
x = self.mean(x, (2, 3))
x = self.flatten(x)
return x
# Check MindSpore Hub website to conclude that the last output shape is 1280.
last_channel = 1280
# The number of classes in target task is 10.
num_classes = 10
reducemean_flatten = ReduceMeanFlatten()
classification_layer = nn.Dense(last_channel, num_classes)
classification_layer.set_train(True)
train_network = nn.SequentialCell([network, reducemean_flatten, classification_layer])
#定义数据集加载函数。
def create_cifar10dataset(dataset_path, batch_size, usage='train', shuffle=True):
data_set = ds.Cifar10Dataset(dataset_dir=dataset_path, usage=usage, shuffle=shuffle)
# define map operations
trans = [
vision.Resize((256, 256)),
vision.RandomHorizontalFlip(prob=0.5),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
vision.HWC2CHW()
]
type_cast_op = transforms.TypeCast(mstype.int32)
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=8)
data_set = data_set.map(operations=trans, input_columns="image", num_parallel_workers=8)
# apply batch operations
data_set = data_set.batch(batch_size, drop_remainder=True)
return data_set
# Create Dataset
dataset_path = "/path_to_dataset/cifar-10-batches-bin"
dataset = create_cifar10dataset(dataset_path, batch_size=32, usage='train', shuffle=True)
#为模型训练选择损失函数、优化器和学习率。
def generate_steps_lr(lr_init, steps_per_epoch, total_epochs):
total_steps = total_epochs * steps_per_epoch
decay_epoch_index = [0.3*total_steps, 0.6*total_steps, 0.8*total_steps]
lr_each_step = []
for i in range(total_steps):
if i < decay_epoch_index[0]:
lr = lr_init
elif i < decay_epoch_index[1]:
lr = lr_init * 0.1
elif i < decay_epoch_index[2]:
lr = lr_init * 0.01
else:
lr = lr_init * 0.001
lr_each_step.append(lr)
return lr_each_step
# Set epoch size
epoch_size = 60
# Wrap the backbone network with loss.
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
loss_net = nn.WithLossCell(train_network, loss_fn)
steps_per_epoch = dataset.get_dataset_size()
lr = generate_steps_lr(lr_init=0.01, steps_per_epoch=steps_per_epoch, total_epochs=epoch_size)
# Create an optimizer.
optim = Momentum(filter(lambda x: x.requires_grad, classification_layer.get_parameters()), Tensor(lr, mindspore.float32), 0.9, 4e-5)
train_net = nn.TrainOneStepCell(loss_net, optim)
#开始重训练。
for epoch in range(epoch_size):
for i, items in enumerate(dataset):
data, label = items
data = mindspore.Tensor(data)
label = mindspore.Tensor(label)
loss = train_net(data, label)
print(f"epoch: {epoch}/{epoch_size}, loss: {loss}")
# Save the ckpt file for each epoch.
if not os.path.exists('ckpt'):
os.mkdir('ckpt')
ckpt_path = f"./ckpt/cifar10_finetune_epoch{epoch}.ckpt"
save_checkpoint(train_network, ckpt_path)
#在测试集上测试模型精度。
model = "mindspore/1.6/mobilenetv2_imagenet2012"
network = mshub.load(model, num_classes=500, pretrained=True, include_top=False, activation="Sigmoid")
network.set_train(False)
reducemean_flatten = ReduceMeanFlatten()
classification_layer = nn.Dense(last_channel, num_classes)
classification_layer.set_train(False)
softmax = nn.Softmax()
network = nn.SequentialCell([network, reducemean_flatten, classification_layer, softmax])
# Load a pre-trained ckpt file.
ckpt_path = "./ckpt/cifar10_finetune_epoch59.ckpt"
trained_ckpt = load_checkpoint(ckpt_path)
load_param_into_net(classification_layer, trained_ckpt)
loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
# Define loss and create model.
eval_dataset = create_cifar10dataset(dataset_path, batch_size=32, do_train=False)
eval_metrics = {'Loss': nn.Loss(),
'Top1-Acc': nn.Top1CategoricalAccuracy(),
'Top5-Acc': nn.Top5CategoricalAccuracy()}
model = Model(network, loss_fn=loss, optimizer=None, metrics=eval_metrics)
metrics = model.eval(eval_dataset)
print("metric: ", metrics)四、模型发布

#将你的预训练模型托管在可以访问的存储位置。参照模板,在你自己的代码仓中添加模型生成文件mindspore_hub_conf.py,文件放置的位置如下:
googlenet
├── src
│ ├── googlenet.py
├── script
│ ├── run_train.sh
├── train.py
├── test.py
├── mindspore_hub_conf.py
#参照模板,在hub/mshub_res/assets/mindspore/1.6文件夹下创建{model_name}_{dataset}.md文件,其中1.6为MindSpore的版本号,hub/mshub_res的目录结构为:
hub
├── mshub_res
│ ├── assets
│ ├── mindspore
│ ├── 1.6
│ ├── googlenet_cifar10.md
│ ├── tools
│ ├── get_sha256.py
│ ├── load_markdown.py
│ └── md_validator.py本次分享完