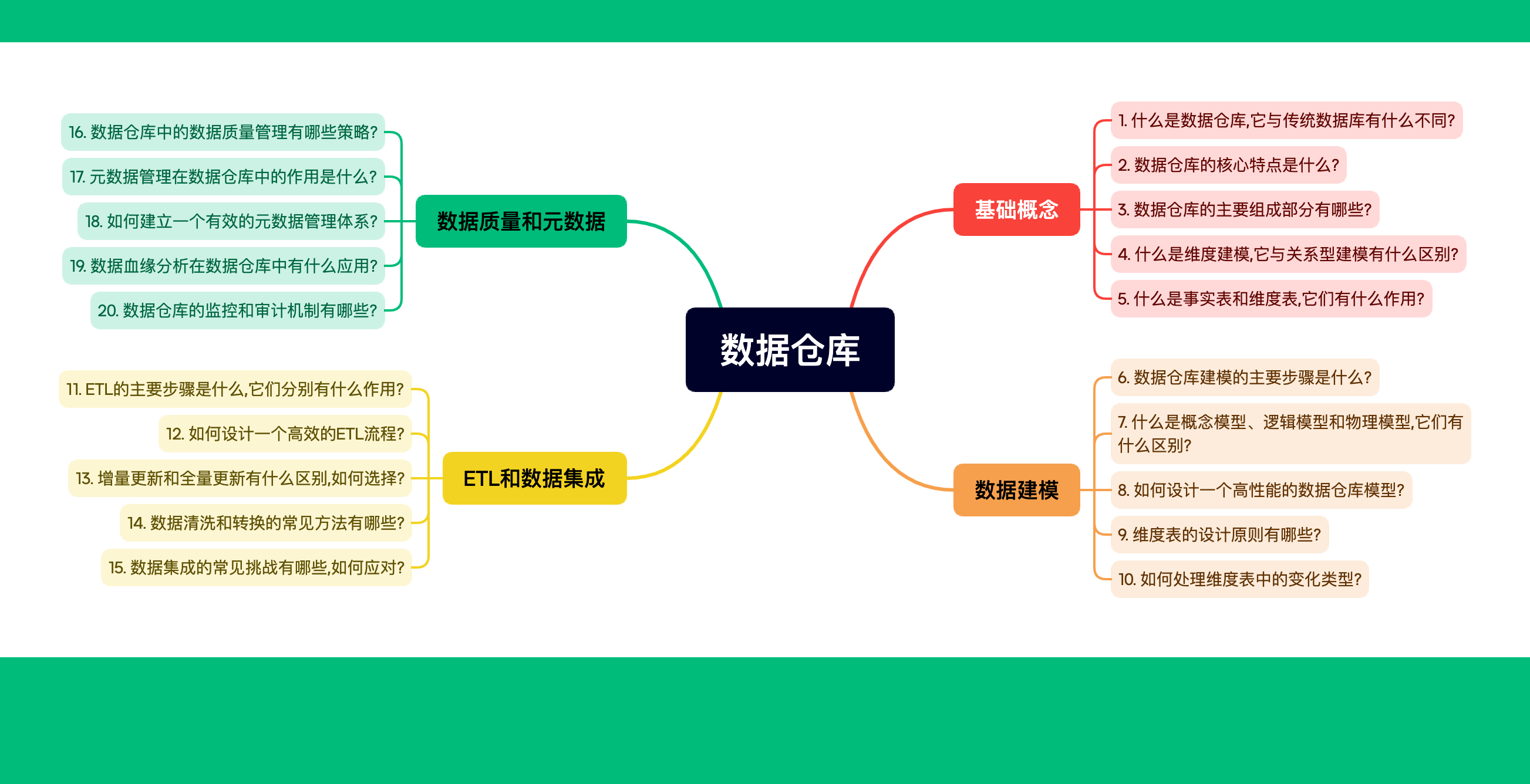
目录
1、异常概念
2、异常的捕获方法
3、异常的传递
4、python模块
4.1、模块的导入
4.2、自定义模块
5、python包
5.1、自定义python包
5.2、安装第三方包
1、异常概念
当检测到一个错误时,python解释器会无法执行,反而出现一些错误的提示,这就是所谓的“异常”,也就是BUG。
BUG就是异常的意思,因为历史上因为小虫子导致计算机失灵的案例,所以延续至今,bug就代表软件出现错误。
比如:打开一个不存在的文件
f=open("www.txt","r",encoding="utf-8")
# FileNotFoundError: [Errno 2] No such file or directory: 'www.txt'2、异常的捕获方法
在力所能及的范围内,对可能出现的bug,进行提前准备、提前处理的行为,称之为异常处理(捕获异常)
捕获异常的原因:
一、增强程序稳定性。避免程序因错误突然崩溃,如在线购物系统中可防止购物流程中断和数据丢失,采取适当措施使程序继续运行。
二、便于错误处理和调试。能获取异常详细信息,帮助开发者快速定位问题;还可根据不同异常类型进行特定处理。
三、提高程序可维护性。分离错误处理代码与业务逻辑代码,使程序结构更清晰;可在不同层次捕获异常,实现分层错误处理。
当我们的程序遇到了bug,会有两种情况:
1、整个程序因为一个BUG停止运行
2、对BUG进行提醒,整个程序继续运行
在程序运行时,往往会因为一个BUG而停止运行,也就是程序崩溃。但是在实际工作中,我们肯定不能因为一个小的BUG就让整个程序崩溃,而是对BUG进行提醒,整个程序继续运行,这时候就要用到捕获异常。
捕获异常的作用:提前假设某处会出现异常,提前做好准备,当真的出现异常,会有后续手段。
捕获常规异常基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码
需求:尝试以“r”模式打开文件,如果文件不存在,则以“w”方式打开
try:
f=open("www.txt","r",encoding="utf-8")
except:
f = open("www.txt", "w", encoding="utf-8")捕获指定异常基本语法:
try:
print(name)
except NameError as e:
print("name变量名称未定义错误")
# e指的是异常对象
注意事项:
1、如果尝试执行的代码的异常类型和要捕获的与异常类型不一致,则无法捕获异常。
2、一般try下方只放一行尝试执行的代码
捕获多个异常:
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except后,并使用元组的方式进行书写。
try:
print(1/0)
except (NameError,ZeroDivisionError):
print("ZeroDivisionError")
捕获所有异常:
try:
可能发生错误的异常代码
except Exception as e:
如果出现异常执行的代码
效果等同于常规异常捕获
异常else:else表示的是如果没有异常时执行的代码
try:
print(1)
except Exception as e:
print(e)
else:
print("我是else,是没有异常时执行的代码")
# 异常else
try:
print(1)
except Exception as e:
print(e)
else:
print("无异常")异常的finally:finally表示的是无论是否异常都要执行的代码。例如关闭文件
# 异常finally
try:
f=open("test.txt","r",encoding="utf-8")
except Exception as e:
print(e)
f = open("test.txt", "w", encoding="utf-8")
else:
print("无异常")
finally:
f.close()3、异常的传递
def func1():
print("函数1的开始")
print(1/0)
print("函数1的结束")
def func2():
print("函数2的开始")
func1()
print("函数2的结束")
def main():
try:
func2()
except Exception as e:
print(e)
main()
# 函数2的开始
# 函数1的开始
# division by zero异常是具有传递性的。当函数func1中发生异常,并且没有捕获处理这个异常的时候,异常会传递到函数func2中,当func2也没有捕获处理这个异常的时候,main函数会捕获这个异常,这就是异常的传递性。
当所有函数都没有捕获异常的时候,程序就会报错。
4、python模块
python模块(module),是一个python文件,以.py结尾。模块能定义函数,类和变量,模块也能包含可执行的代码。
模块的作用:python中有许多不同的模块,每一个模块都可以帮助我们快速的实现一些功能,比如实现和时间相关的功能就可以使用time模块,我们可以认为模块就是一个工具包,每一个工具包都有各种不同的工具供我们使用进而实现各种不同的功能
实际上模块就是一个python文件,里面有类、函数、变量等,导入模块以使用。
4.1、模块的导入
模块在使用前要先导入,导入语法:
[from 模块名] import [模块 | 类 | 变量 | 函数 | *] [as 别名]
常用的组合形式:
· import 模块名
· from 模块名 import 类、变量、方法等
· from 模块名 import *
· import 模块名 as 别名
· from 模块名 import 功能名 as 别名
案例:导入time模块
#导入时间模块
import time
print("开始")
#让程序睡眠1s(阻塞)
time.sleep(1)
print("结束")
# from time import sleep
# print("开始")
# sleep(1)
# print("结束")
# 使用*导入time模块的全部功能
from time import *
sleep(1)as定义别名:
import 模块名 as别名
from 模块名 import 功能 as 别名
import time as t
t.sleep(2)
print("haha")
from time import sleep as sl
sl(2)
print("hehe")4.2、自定义模块
python中已经帮我们实现了很多模块,不过有时候我们需要一些个性化的模块,这里就可以通过自定义模块实现,也就是自己制作模块。
案例:新建一个python文件,命名为my_module.py并定义test函数

注意:每个python文件都可以作为一个模块,模块的名字就是文件的名字,也就是说自定义模块必须要符合标识符命名规则。
# 模块1代码
def my_test(a,b):
print(a+b)
# 模块2代码
def my_test(a,b):
print(a-b)
# 导入模块并调用功能
from my_module1 import my_test
from my_module2 import my_test
# my_test函数是模块2中的函数
my_test(1,2)当导入多个模块的时候,且模块内有同名功能,当调用这个同名功能的时候,调用到的是后面导入的模块的功能。
测试模块:在实际开发中,当一个开发人员编写完一个模块后,为了模块能在项目中达到想要的效果,开发人员会自行在py文件中添加一些测试信息,例如,在my_module1.py中加入测试代码test(1,1)
def test(a,b):
print(a+b)
if __name__ == '__main__':
# 只在当前文件中调用该函数,其他导入的文件不符合该条件,不执行test函数调用
test(1,2)如果一个模块文件中有“__all__”变量,当使用“from 模块名 import *”导入时,只能导入这个列表中的元素。

5、python包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个__init__.py文件,该文件夹可用于包含多个模块文件。从逻辑上看,包的本质依然是模块。

包的作用:当我们的模块文件越来越多时,包可以帮助我们管理这些模块,包的作用就是包含多个模块,但本质依然是模块。
5.1、自定义python包
步骤:
1、新建包“my_package”
2、新建包内模块:“my_module1”和“my_module2”
2、模块内代码如下
 注意:新建包后,包内部会自动创建“__init__.py”文件,这个文件控制着包的导入行为。
注意:新建包后,包内部会自动创建“__init__.py”文件,这个文件控制着包的导入行为。
使用方式1:
import 包名.模块名
包名.模块名.目标
使用方式2:
from 包名 import *
模块名.目标
注意:必须在“__init__.py”文件中添加“__all_=[ ]”,控制允许导入的模块列表
5.2、安装第三方包
我们知道,可以包含一堆的python模块,而每个模块又包含许多的功能。所以,我们可以认为:一个包,就是一堆同类型功能的集合体。
在python程序的生态中,有许多非常多的第三方包(非python官方),可以极大的帮助我们提高开发效率,如:
· 科学计算常用的:numpy
· 数据分析中常用的:pandas
· 大数据计算中常用的:pyspark、apache-flink包
· 图形可视化常用的:matplotlib、pyecharts包
· 人工智能常用的:tensortflow
等等
这些第三方的包,极大的丰富python的生态,提高了开发效率。但是由于是第三方,所以python没有内置,所以手动安装才可导入使用。
第三方包的安装非常简单,我们只需要使用非python内置的pip程序即可。通过alt+F12打开本地终端,输入指令:
pip install 第三方包名称
但是因为pip默认链接的是国外网站,所以下载速度很慢,只需要加上以下命令,使其连接国内的网站;
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
创建一个自定义包,名称为:my_utils(我的工具)在包内提供2个模块
• str_util.py(字符串相关工具,内含:)
•函数:str_reverse(s),接受传入字符串,将字符串反转返回
• 函数:substr (s,x,y),按照下标x和y,对字符串进行切片
• file_util.py(文件处理相关工具,内含:)
• 函数:Print_file_info(file_name),接收传入文件的路径,打印文件的全部内容,如文件不存在则捕获异常,输出提示信息,通过finally关闭文件对象
• 函数:append_to_file(file_name, data),接收文件路径以及传入数据,将数据追加写入到文件中
# 模块str_util.py
def str_reverse(s):
s =s[::-1]
return s
def substr(s,x,y):
index_x=s.index(x)
index_y=s.index(y)
s = s[index_x:index_y]
print(s)
if __name__ == '__main__':
substr("itheima","t","m")
# 模块file_util.py
def print_file_info(file_name):
f=None
try:
f=open(file_name,'r')
content=f.read()
print(content)
except Exception as e:
print(e)
else:
if f:
f.close()
def append_file_info(file_name,data):
f=open(file_name,'a')
f.write(data)
f.write("\n")
f.close()