RASA 学习笔记整理
一 安装
在虚拟环境中安装,进入python3版本的环境
conda activate python3 ai04机器
旧版本:rasa-nlu和rasa-core是分开安装的
最新版本:rasa 将二者做了合并
直接安装
pip3 install rasa
在安装到如下步骤时候会报网络错误
Downloading tensorflow-2.8.4-cp37-cp37m-macosx_10_14_x86_64.whl (217.8 MB)
━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 10.4/217.8 MB 5.6 kB/s eta 10:21:12
raise ReadTimeoutError(self._pool, None, "Read timed out.")
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out.
解决:换安装源
pip3 install rasa -i https://pypi.mirrors.ustc.edu.cn/simple/
速度嗖嗖快
如下安装源都可以试试
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
环境安装版本对比
rasa 3.4.2
rasa-sdk 3.4.0
tensorflow 2.8.4
安装rasa1
直接安装总是不成功,参考 https://blog.csdn.net/weixin_35757704/article/details/122269142
pip3 install -U --user pip && pip3 install rasa==1.10.18 -i https://pypi.org/simple
或者参考 https://zhuanlan.zhihu.com/p/439666645?utm_id=0
二 使用rasa
安装完rasa后
进入工程,确定里面含有三个文件
外层 domain.yml config.yml 以及data目录,内含 nlu.md stories.md
domain.yml 定义意图和实体等
config.yml 定义nlu和core的组件
storieds.md 定义了用户和助手之间的真实会话过程。rasa core可以以strories数据来训练模型
endpoints.yml 定义rasa core和其他服务连接的信息,比如url服务端口
1)开始训练 模型
rasa train --domain domain.yml --data data --config config.yml --out models
-
可以用 rasa train nlu 或者 rasa train core 来区分训练哪一部分模型
-
可以用 rasa train --finetune来从已经存在的一个模型中初始化,再在新数据上额外训练,这可以减少训练次数
同理可以用 rasa train nlu --finetune 和 rasa train core --finetune
2)基于RASA sdk启动一个action 服务
rasa run actions
3)启动会话
rasa shell -m models --endpoints configs/endpoints.yml
rasa shell 此命令会加载最新训练的模型,然后开始一个会话
rasa shell nlu 此命令会显示会话句子被模型抽取出来的nlu结构:实体和意图是什么
4)也可以直接启动训练和交互
rasa interactive 此命令会先训练一个模型,再启动一个会话交互
ras interactive --model 此命令会跳过训练,从model路径中download一个模型
也可以用postman进行交互 rasa run --enable-api
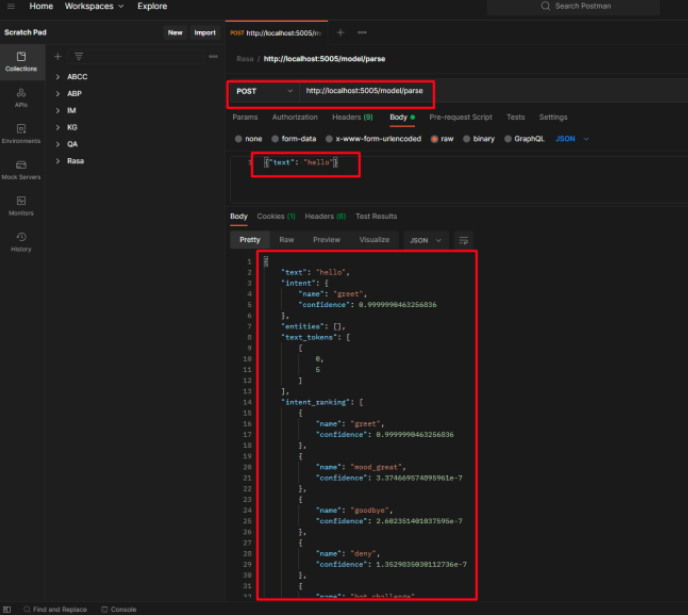
常见可用的rasa命令
rasa -h 查看所有命令参数
rasa init:创建一个新的项目,包含示例训练数据,actions和配置文件。
rasa run:使用训练模型开启一个Rasa服务。
rasa shell:通过命令行的方式加载训练模型,然后同聊天机器人进行对话。
rasa train:使用NLU数据和stories训练模型,模型保存在./models中。
rasa interactive:开启一个交互式的学习会话,通过会话的方式,为Rasa模型创建一个新的训练数据。
telemetry:Configuration of Rasa Open Source telemetry reporting.
rasa test:使用测试NLU数据和stories来测试Rasa模型。
rasa visualize:可视化stories。
rasa data:训练数据的工具。
rasa export:通过一个event broker导出会话。
rasa evaluate:评估模型的工具。
-h, --help:帮助命令。
--version:查看Rasa版本信息。
rasa run actions:使用Rasa SDK开启action服务器。
rasa x:在本地启动Rasa X。
三 RASA的系统架构
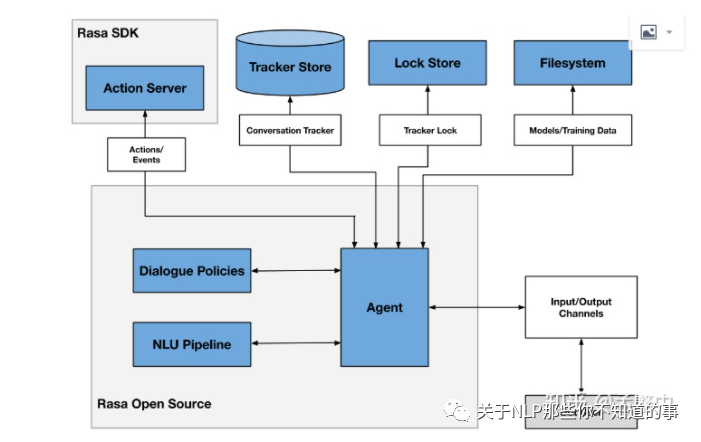
rasa包含nlu和core两个组件。NLU是pipline的方式处理意图分类,实体提取,响应检索。dp是对话策略组件。
Action是一个总控单元,连接NLU和DP,返回回答。
Tracker Store是存储对话的单元,存储了机器人和用户的对话的历史信息。

Lock Store,是ID产生器,用来锁定一个会话,保证消息的顺序处理。
Filesystem,提供文件存储服务
四 RASA的NLU
pipline模式训练做nlu,依次执行如下组件
The configuration for pipeline and policies was chosen automatically. It was written into the config file at 'config.yml'.
rasa.engine.training.hooks - Starting to train component 'RegexFeaturizer'.
2023-02-08 15:07:24 INFO rasa.engine.training.hooks - Finished training component 'RegexFeaturizer'.
2023-02-08 15:07:26 INFO rasa.engine.training.hooks - Starting to train component 'LexicalSyntacticFeaturizer'.
2023-02-08 15:07:26 INFO rasa.engine.training.hooks - Finished training component 'LexicalSyntacticFeaturizer'.
2023-02-08 15:07:27 INFO rasa.engine.training.hooks - Starting to train component 'CountVectorsFeaturizer'.
2023-02-08 15:07:27 INFO rasa.nlu.featurizers.sparse_featurizer.count_vectors_featurizer - 2353 vocabulary items were created for text attribute.
2023-02-08 15:07:31 INFO rasa.engine.training.hooks - Finished training component 'CountVectorsFeaturizer'.
2023-02-08 15:07:35 INFO rasa.engine.training.hooks - Starting to train component 'DIETClassifier'.
代码位置:
ai04机器 /data/jqli02/rasa
rasa-main/rasa/nlu
-
RASA-NLU的实现方法(中文为例)
以组件的形式对输入句子做处理,包含语言模型、分词器、特征提取、实体识别、意图分类、结构化输出。
1)加载预训练的词向量模型
该模型文件叫MITIE模型,可以用MITIE库训练。结构类似word2vec
pipeline: - name: "MitieNLP" model: "data/total_word_feature_extractor.dat" #可以直接下载,也可以自己训练,自己训练慢2**)初始化spacy结构,使用spacyNLP**
pipeline: - name: "SpacyNLP" # 加载语言模型 model: "en_core_web_md" # 当检索单词向量时,这将决定单词的大小写是否相关。' False'则是忽略大小写。 case_sensitive: FalsespacyNLP是什么?
一个开源的NLP库,可以做各种实用的句子分析功能,包括分词、词性分析,也可以做命令体识别和文本分类等,还支持最新神经网络模型,BERT等。以及系统打包,部署等。3)定义分词器
4)其他一堆提特征过程 featurizer
详细如下:
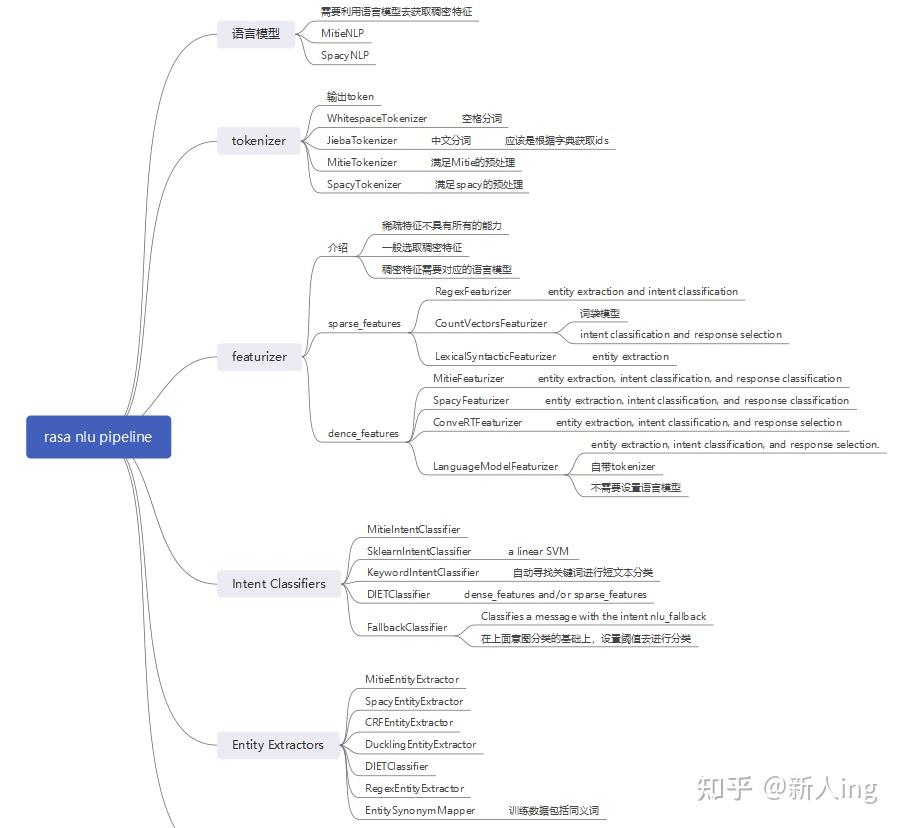
重点:
LanguageModelFeaturizer,需要指定加载的语言模型,可以支持的模型有 BERT/GPT/GPT-2/XLNet/RoBERTa
DIETClassifier 可以同时做意图识别和实体提取,使用transformer模型
可以自己自定义一些NLU的模型,需要自己写组件代码,并加入component.py中,再执行一下注册,详情参考[6]
五 RASA-core的组件
代码位置:
rasa-main/rasa/core/policies
分为 基于机器学习的策略和基于规则的策略,
机器学习策略:TEDPolicy,UnexpecTED Intent Policy,Memoization Policy,Augmented Memoization Policy
包括机器学习和深度学习训练得到的策略模型。如sklearn_policy,keras_policy
基于规则策略:Rule Policy,

重点:
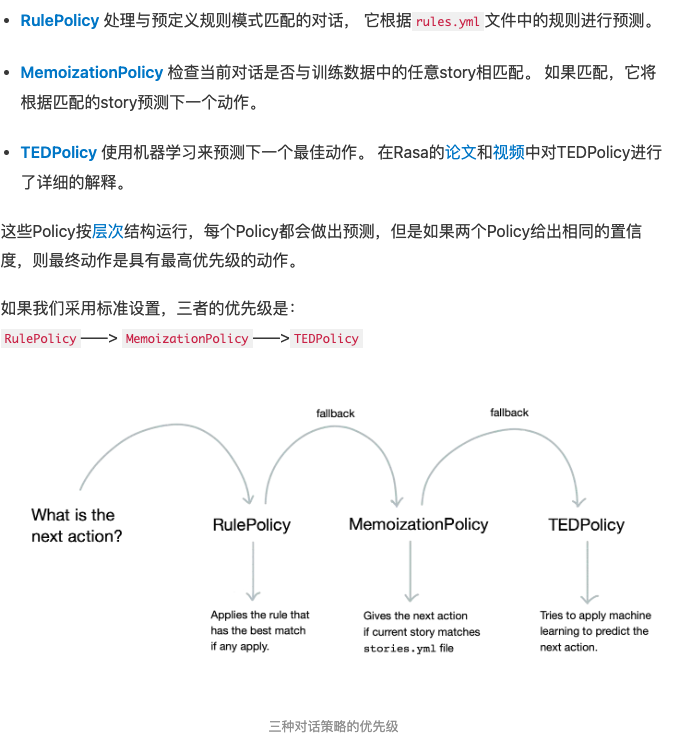
TEDPolicy包含了下一步动作预测和实体识别两个目标的多任务架构。两个任务共享transformer encoder,实体识别用CRF预测输出,下一个动作预测,作为分类任务输出。参数:max_history,查看多少条历史对话来决定下一个动作。
如下是优先级

RASA-CORE的源码解读
地址:
rasa-main/rasa/core
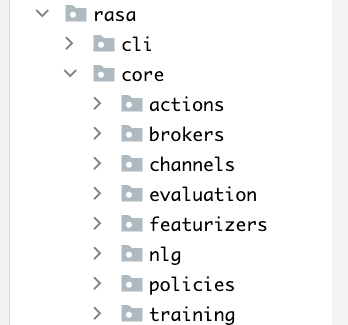
actions:bot执行的一些动作
channels:与前端对接的接口
nlg:rasa的回答生成模块,支持两种:模板生成话术,以及模型训练做NLG
policies:对话管理模块。依据策略执行不同的actions。策略包括人工策略+模型训练策略
schemas:指domain.yml, 这个配置文件定义了槽位,实体定义,intent,话术模板
training:如何将准备的数据转化为可训练的转化方法
featurizers:将对话数据特征化的方法
六 RASA中配置文件的编写
内容包括:
* greet 用户输入(相应的意图和实体)
- utter_answer_greet 助手相应(相应的action,指rasa nlu识别到该意图后RASA core能执行的action)
*开头代表用户的输入,使用NLU的输出的intent和entity来表示可能的输入
-开头的句子代表要执行的动作。分为utterance actions 和 custom actions。前者是机器人的回复,后者是自定义的动作。
* request_weather 识别意图为查天气
- weather_form 系统相应的动作 action
- form{"name": "weather_form"} 需要获取所有实体信息,
- form{"name": null} 然后把name置为null,返回查询天气的结果。
*inform{"date_time": "大后天"} 表示输入包含entity的情况后的响应
- weather_form
-
如何设计一个story
参考例子:https://www.cnblogs.com/hq0803/p/15214597.html
需要考虑两组路径:快乐路径 和 不快乐路径。
快乐路径:用户按照预期遵循对话流流程,再出现提示时候始终提供必要信息,叫做happy path
不快乐路径:用户因为问题,闲聊,或者其他问题,偏离愉快路径的流程。叫做unhappy path
例子
stories:
- story: Welcome message, premium user
steps: #story的步骤
- intent: greet 用户的intent
- action: action_check_profile 机器响应:检查profile
- slot_was_set:
- premium_account: true 高级账户,机器响应:欢迎账户
- action: utter_welcome_premium
- story: Welcome message, basic user
steps:
- intent: greet
- action: action_check_profile
- slot_was_set:
- premium_account: false 非高级账户
- action: utter_welcome_basic 机器响应:欢迎账户,询问是否需要升级
- action: utter_ask_upgrade
-
使用OR语句
合并两个intent可以用or语句
- or: 代表如下两个intent出现的时候,响应都是一种 - intent: affirm - intent: thanks - action: action_signup_newsletter -
检查点 checkpoint
使用检查点来模块化经常重复使用的单元。
- story: user provides feedback steps: - checkpoint: ask_feedback - action: utter_ask_feedback
nlu和story定义中一些关键词的含义
-
slot_was_set 设定slot必须满足某值,才能走下面的流程
stories: - story: It's raining now steps: - intent: check_for_rain - action: action_check_for_rain - slot_was_set: - raining: true - action: utter_is_raining - action: utter_bring_umbrella - story: It isn't raining now steps: - intent: check_for_rain - action: action_check_for_rain - slot_was_set: - raining: false - action: utter_not_raining - action: utter_no_umbrella_needed -
type: slot的type
type设置为unfeaturized:该插槽不会具有任何特征,因此其值不会影响对话流程,在预测机器人应执行的下一个动作时会被忽略。
slots: name: type: unfeaturized -
action_loop 激活form表单的意思
如果用了form,激活form并使用的过程必须为
action: ticket_form action_loop: ticker_formform的使用方法
- action: form_xxx # 启动form - active_loop: form_xxx # 在故事或rules中增加ActiveLoop event,表示启动 - active_loop: null # 在故事或rules中增加ActiveLoop event,表示停止 - action: action_submit # form获取信息后,完成后续动作steps: - intent: book_ticket #用户回答 - action: ticket_form #启动表单,准备挨个填充表单必须的槽位 #当用form的action的时候,就需要active_loop, #active_loop代表激活form填充的action,根据接下来定义的slot_was_set挨个填充form - active_loop: ticket_form #启动form # slot_was_set并不是动作,不会完成赋值操作,而是检查变量是否被赋予指定的值,满足条件才能会话进行下去 - slot_was_set: - city_arrive: 上海 - city_depart: 北京 # - departure_date: 明天下午 - active_loop: null #停止form -
rasa数据格式检查
rasa data validate 检查数据格式对domain文件,如果报错,找不到domainfile,大多是yaml文件格式有问题,一般是要求缩进的格子,缩进不够
检查yaml文件格式
pip install yamllint yamllint domain.yml -
rasa的rule和story的冲突
运行rasa数据验证不会测试您的规则是否与您的故事一致。但是,在训练期间,RulePolicy会检查规则和故事之间的冲突。任何此类冲突都将中止训练。 然后报错
- the prediction of the action 'action_extract_slots' in story 'happy_path_1' is contradicting with rule(s) 'Activate ticket_form' which predicted action 'ticket_form'. - the prediction of the action 'utter_ask_departure_date' in story 'happy_path_1' is contradicting with rule(s) 'Submit ticket_form' which predicted action 'action_buy_ticket'.解决:根据rules的定义,分析rule中流程,一般是同样的输入,同样的step,最终结果如果不一致,就会报冲突错误
-
rule和story的区别
-
Rule: 规则是一种简单而有限制的方式来定义对话流程。它们通常用于处理简单的用户请求,例如回答一个固定的问题或者执行某些操作。规则只能捕获单个意图(intent)并且不能处理槽位填充或多轮对话。该方法适用于简单的场景下。
-
rule用于单轮对话的固定规则,core部分训练会校验是否只有一个user_uttered… 如果rule中定义了有多处(>=2)个需要用户输入intent的地方,就会报错如下

-
rule是固定规则(整合了原来的trigger intent),如果需要根据前文灵活设置对话线,还是要用story
-
Story: story可用于更复杂的对话流程。故事中可以包含多个意图、槽位填充以及多轮对话。在故事中,您可以定义特定的对话场景,并为机器人提供处理这些场景的指导。此外,故事还允许您使用Rasa的核心功能,例如对话管理器(Dialogue Management)和策略(Policies)
-
执行action的时候,policy中的选用,MemoizationPolicy 执行的是story中定义的流程。RulePolicy执行的是rule中定义的规则,TedPolicy是根据机器学习,训练并预测下一个动作
总结:
-
当处理简单的确定的用户请求时,应该使用规则。一个intent对应一个确定的action,就用rule
例如:greet -> utter_greet goodbye->utter_goodbye
-
如果需要处理更复杂的对话场景,则应该使用story。
-
story中可以拆解,一个多流程的故事为多个子流程的故事。注意:每个story都需要从intent开始开启,如果从action中开启,发现衔接不上。
- story: start_ticket steps: - intent: start_ticket #子流程,从intent开启 - action: utter_ask_city_depart_arrive #助手询问出发和到达城市 ========================================= - story: 核实用户订单信息,用户确认并下单 steps: - action: utter_confirm_info #子流程,从action开启,则上文必须有从此action结束的步骤 - intent: confirm_info #下单购买 - action: utter_action_book_ticket - action: utter_ask_other_question -
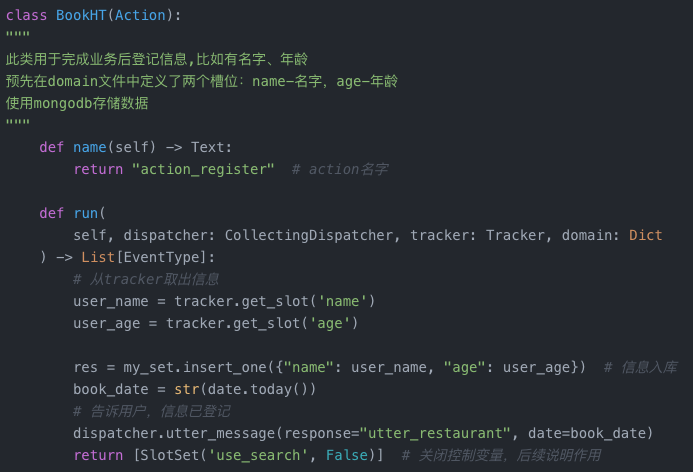
action的编写
action.py中,定义类,函数 name指向domain中的form名称


七 当前可用工程介绍
实践
工程是基于rasa1的。安装好rasa1
ai04机器 rasa1环境。
安装rasa1 pip3 install -U --user pip && pip3 install rasa==1.10.18 -i https://pypi.org/simple
-
rasa-demo-main
一个简单英文助手demo,包含了简单意图,打招呼,确认,再见 -
rasa_nlu_chi
一个中文项目,可以参考 -
rasa_chatbot_cn-master
中文项目 -
rasa_chatbot
一个旧版本,rasa-nlu和rasa-core分离的实现的英文系统,包含了办理套餐,查询话费,案件查询等场景。 rasa版本比较低,rasa-nlu使用了crf模型。 -
rasa-chatbot-templates-master
包含多个例子的配置文件。可以直接进入该目录,训练模型并测试效果。有简单聊天,酒店预定,车票预定等场景,都是英文
rasa train --domain domain.yml --data data --config config.yml --out models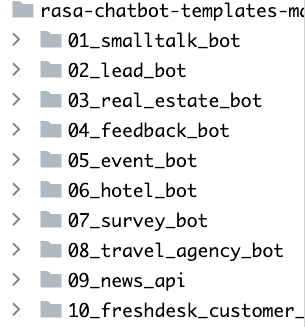
-
rasa_nlu_gq-master
包含了一些新增特性的代码。 比如实体识别模型bilstm+crf,bert模型提取词向量,结合rasa_chatbot_cn 可以实现一些中文的定制化特征提取需求 -
rasa-main
rasa源码,版本3.1 rasa/nlu rasa/core中分别是两部分源码 examples中包含一些demo例子,都是英文 -
rasa_shopping_bot-master
一个关于买东西的例子,包含了尺码选择等多轮对话使用过程
ubuntu 安装 rasa-x pip3 install rasa-x --extra-index-url https://pypi.rasa.com/simple 报错: Failed to build xmlsec ERROR: Could not build wheels for xmlsec, which is required to install pyproject.toml-based projects 解决办法: Note: There is no required version of LibXML2 for Ubuntu Precise, so you need to download and install it manually. wget http://xmlsoft.org/sources/libxml2-2.9.1.tar.gz tar -xvf libxml2-2.9.1.tar.gz cd libxml2-2.9.1 ./configure && make && make install
RASA比TCP的对比
1.RASA也有tracker来存储历史信息
2.RASA也有policy来做对话管理。RASA包含模型和规则两种方式,TCP只有规则
3.RASA是个整体的NLP系统,包含NLU,DM,NLG全部分,TCP只做DM部分,需要衔接NLU
4.RASA是全python,可读性好。
八 Rasa如何在pycharm中调试
修改了配置文件的代码在这里
/work/myCode/ContextDialog/rasa3test
直接执行使用:
rasa shell --debug 可以看到阶段一些打印点的信息
rasa interactive 可以看到每次预测的intent和action的信息
可是如果还想知道更多变量的信息,参数是如何流转的,就需要自己debug了。
方法1:
在源码中加print,然后用上面命令来打印看输出
方法2:
直接把源码加入pycharm中,开始debug
步骤如下
一) rasa的源码在哪里?
conda env list
然后进入对应环境目录的如下目录,就是rasa代码
lib/python3.8/site-packages/rasa
整体目录为:
miniconda3/envs/rasa3/lib/python3.8/site-packages
也可以在action.py中埋入一个bug后,用rasa shell --debug来执行,就会在log中显示源码路径
二) 拷贝rasa的源码到外面,加载到pycharm中
这里注意,在外部建立同名目录并修改部分代码调试后,会发现运行的时候,依然跳转到site-packages目录中。你修改的部分和设置的断点压根不起作用。
解决办法:将site-packages中的目录改名。让其不再跳转
将rasa 目录 改为 rasa_code
在pycharm中调试配置如下:
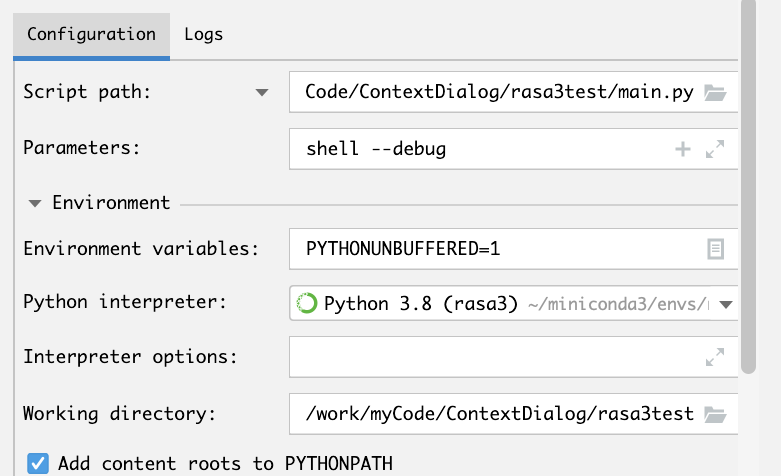
如此,现在,不再跳转到根目录中去了。
注意:修改了名称后,命令行中又不能执行rasa了。这是因为在site-packages目录下找不到该目录了。所以不能删除,只能改名,pycharm环境中调试完成后,再更新代码到site-packages中,并把目录名改回去。
Rasa中policy是如何竞争的
参考:https://www.jianshu.com/p/a96a17af201a
发现一个问题,story中定的流程总是不走下去,详细看rasa shell debug的日志,发现ted_policy预测的next action是对的,然后又走了一下rule_policy,变成别的了。
要点:story和rule中不需要定相同的流程。如果定了,按照优先级执行,rule的优先级高于ted
九 RASA使用中一些踩坑要点
-
要点:每次修改完配置文件,不论是data目录中的,还是config.yml,都需要重新训练使之生效:rasa train
-
要点:如果使用了form,必须要使用rule,并且rule中定义填form的流程。否则不生效
如下,分别在domain.yml rules.yml, story.yml, config.yml中定义如下
=========domain.yml========== forms: ticket_form: required_slots: - city_arrive - city_depart ===========rule.yml============ - rule: Activate ticket_form steps: - intent: book_ticket - action: action_extract_slots - action: ticket_form - active_loop: ticket_form - slot_was_set: - requested_slot: city_arrive - requested_slot: city_depart - active_loop: null - action: utter_ask_departure_date ===============story.yml中定义rule中的后文======= - story: happy path1 steps: - action: utter_ask_departure_date - intent: request_departure_date #用户输入出发日期 - slot_was_set: - departure_date: 明天 - action: utter_action_book_ticket - action: utter_ask_other_question ================config.yml=============== policies: #如下三者的次序,那个在前那个在后不要紧,最终还是按优先级 rule>memoiza>ted - name: MemoizationPolicy - name: RulePolicy - name: TEDPolicy -
使用了form,定义了form表单内容后,必须action中定义一个填form的函数。否则能执行,但是会报错。
-
要点:每个story都不能以intent结尾,以intent结尾就会默认后面是action_listen。结果就不可控,必须是action结尾
-
- story: start_ticket steps: - intent: start_ticket - action: utter_ask_city_depart_arrive #助手询问出发和到达城市 -
不要随便用rasa init,会把修改后的data目录,actions.py都给用初始文件覆盖掉
-
rasa train --force,用来强制让模型重新训练,使得改动生效
有时候修改后,rasa train执行后,发现还是没有生效。这可能是改动没有被rasa识别到,它没有重新训练模型,所以需要加上 force 参数。
rasa train --force
十 一些诡异bug
bug1:story中定义了东方航空,经济舱等,但是执行的时候总是不生效。查看rasa train的过程,发现在这些句子地方都报了warning,warning如下
More info at https://rasa.com/docs/rasa/training-data-format#nlu-training-data
/data2/conda/envs/rasa3/lib/python3.7/site-packages/rasa/shared/utils/io.py:99: UserWarning: Misaligned entity annotation in message '大前天中午的' with intent 'request_departure_date'. Make sure the start and end values of entities ([(0, 5, '大前天中午')]) in the training data match the token boundaries ([(0, 6, '大前天中午的')]). Common causes:
1) entities include trailing whitespaces or punctuation
2) the tokenizer gives an unexpected result, due to languages such as Chinese that don't use whitespace for word separation
More info at https://rasa.com/docs/rasa/training-data-format#nlu-training-data
/data2/conda/envs/rasa3/lib/python3.7/site-packages/rasa/shared/utils/io.py:99: UserWarning: Misaligned entity annotation in message '只查找10点之后的' with intent 'request_departure_date'. Make sure the start and end values of entities ([(3, 8, '10点之后')]) in the training data match the token boundaries ([(0, 9, '只查找10点之后的')]). Common causes:
1) entities include trailing whitespaces or punctuation
2) the tokenizer gives an unexpected result, due to languages such as Chinese that don't use whitespace for word separation
More info at https://rasa.com/docs/rasa/training-data-format#nlu-training-data
/data2/conda/envs/rasa3/lib/python3.7/site-packages/rasa/shared/utils/io.py:99: UserWarning: Misaligned entity annotation in message '2号的航班' with intent 'request_departure_date'. Make sure the start and end values of entities ([(0, 2, '2号')]) in the training data match the token boundaries ([(0, 5, '2号的航班')]). Common causes:
1) entities include trailing whitespaces or punctuation
2) the tokenizer gives an unexpected result, due to languages such as Chinese that don't use whitespace for word separation
找到如下解决方法
https://forum.rasa.com/t/misaligned-entity-annotation/3768/4

分析如上说明,感觉是有道理的。我的数据中标记的,将 “东方航空” “经济舱”这些当做一个实体标记出来,但是结巴分词的时候,没法把它们分成一个整体,就可能报如上的warning,所以训练的时候没有训练到model中,导致最终不生效。
解决:把这些词加入结巴自定义词典中。
根据config.yml中定义
- name: JiebaTokenizer
dictionary_path: data (注意,此处要求写的是path,写清楚path,并且该path里不能有和dict名字容易混淆的文件存在。
最好路径中是 dict_4s/dict.txt
搜索jieba_tokenizer.py代码,查到如下
dictionary_path = config["dictionary_path"]
if dictionary_path is not None: #当config中词典目录不为空的时候,从该目录中load词典,否则就从默认安装路径中load词典
cls._load_custom_dictionary(dictionary_path)
解决,将conda环境中,jieba目录下的dict拷贝出来到data中,在其后追加如下内容,重新 rasa train
东方航空 3 n
南方航空 3 n
国际航空 3 n
厦门航空 3 n
结果:解决!不再报warning了。
Bug2,中文分词bug
还是如上bug,一些车品牌的名称,分词不正确。此次把这些词加入结巴词典,dict中并指明路径,bug依然不能解决,加入的词条提高词频,还是不行。搜索发现分词结果并不存在原词典中。如下:
“志俊是” 这个词条,并不在原词典中。可是奇怪为何分词就成这样了?
envs/rasa3/lib/python3.8/site-packages/rasa/shared/utils/io.py:98: UserWarning: Misaligned entity annotation in message '桑塔纳志俊是什么样的车' with intent 'ask_one_car'. Make sure the start and end values of entities ([(0, 5, '桑塔纳志俊')]) in the training data match the token boundaries ([(0, 3, '桑塔纳'), (3, 6, '志俊是'), (6, 9, '什么样'), (9, 10, '的'), (10, 11, '车')]). Common causes:
1) entities include trailing whitespaces or punctuation
2) the tokenizer gives an unexpected result, due to languages such as Chinese that don't use whitespace for word separation
More info at https://rasa.com/docs/rasa/training-data-format#nlu-training-data
in message '添越是什么样的车' with intent 'ask_one_car'. Make sure the start and end values of entities ([(0, 2, '添越')]) in the training data match the token boundaries ([(0, 1, '添'), (1, 3, '越是'), (3, 6, '什么样'), (6, 7, '的'), (7, 8, '车')]). Common causes:
1) entities include trailing whitespaces or punctuation
2) the tokenizer gives an unexpected result, due to languages such as Chinese that don't use whitespace for word separation
解决:
该bug磨了两天。起初:jieba根目录下的dict.txt中,加入这些单词。训练可以了。
第二次训练,又不行了。继续报错这些
查看资料:https://github.com/RasaHQ/rasa/pull/6753
排查错误:
-
从这里看到,说要写词典的目录,而不是词典文件本身
参考:https://forum.rasa.com/t/tokenizer-jieba-dictionary-path-does-not-work/3667
-
jiebatokenizer.py中打印分词后结果,检查发现分词没问题
-
查看log,发现是训练crfentityexactor的时候总是报这个错
在crfexactor代码中找到token的地方, 打印出来发现依然没问题
最终解决:
各种改动后又复原,发现python main.py 没问题了。rasa train命令有问题。只好把__main__.py目录下的代码拷贝到源码中。训练,依然发现个别问题。查看token分词结果。发现:并不是每条训练数据报warning,依然是分词问题导致的。
1)奥迪A8会分成奥迪 A8, 哪怕词典中有这个词。 猜测必须 奥迪 A8 这两个单独词的词频会降低才能分出合成词
同理 所有中文+英文字母的,都中间分开了。
2)凌渡, 在句子不同位置会分成不同结果。
如上个别句子的分词有问题,不是全部有问题,具体就是需要挨个改词频,保证原单字词频小于组词的词频。 所以详细不纠结了。总之找到分词的影响了。
bug3, 启动服务时候报warning说加载不到模型
启动
rasa run --cors "*"
报如下:
root - Starting Rasa server on http://0.0.0.0:5005
2023-08-17 18:42:38 INFO rasa.core.processor - Loading model models/20230809-110408-flat-mile.tar.gz...
2023-08-17 18:42:38 ERROR rasa.core.agent - Could not load model due to Error deserializing graph schema. Can't find class for graph component type 'rasa.graph_components.providers.forms_provider.FormsProvider'..
2023-08-17 18:42:38 INFO root - Rasa server is up and running.
原因:
这是由于当前目录中models下的文件的rasa生成版本和已经安装的rasa版本不一致,无法加载
解决:
重新训练一组新模型
参考:https://forum.rasa.com/t/error-rasa-graph-components-providers-domain-without-response-provider-domainwithoutresponsesprovider/50745
Bug4:训练完模型执行的时候,到某些步骤说无法写入了
报错如下:
Traceback (most recent call last):
File "//miniconda3/envs/rasa3/lib/python3.8/logging/__init__.py", line 1084, in emit
stream.write(msg + self.terminator)
BlockingIOError: [Errno 35] write could not complete without blocking
Call stack:
前一个intent的utter_action内容比较长,到下一个intent后就报错如上了。
查答案:
https://github.com/RasaHQ/rasa/issues/11575
解决:
pip uninstall uvloop
Bug5: 总是不能根据story往下执行,会返回action_listen
如图,到这一步时候就不往下执行了
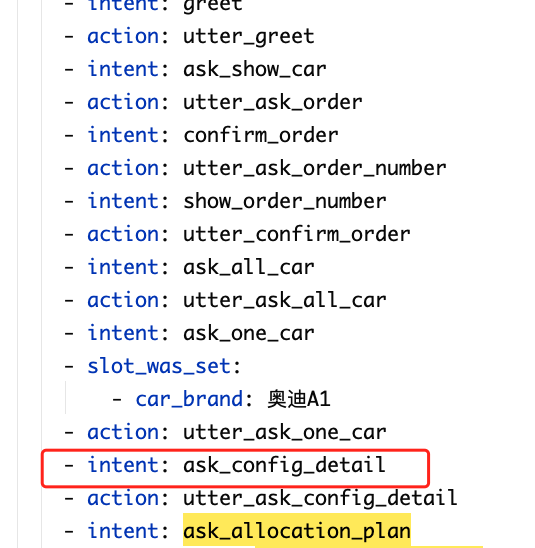
看intent预测都正常。从上一步就无法执行了。只好把上一步加入到rule中,这一步又不行了。一直rule不是办法。快把goog翻烂了。
https://forum.rasa.com/t/stories-are-not-working-if-there-is-rule-policy-in-the-config-file/47833/4
解决:
看了下stage总是在第10次左右就挂了。考虑是不是轮次太长了
把长story分割,分割成几个步骤的分别path,再一测试:ok了!没事了!!!!
真是。。。崩溃啊。磨了好几天的问题
Bug6,启动action后启动shell的时候说端口被占用
为了测试自定义actiond的效果。先编写action.py文件,然后
rasa run actions
报错说5055端口已经占用。可是代码中没有地方写这个端口。
于是指定端口启动action
rasa run actions -p 5005
ok,action 可以启动了。
再启动shell
rasa shell --debug --model models_vw4s
报错说端口已经被占用
( error while attempting to bind on address ('0.0.0.0', 5005): address already in use)
最终解决方法:
rasa run actions -p 5005 & rasa shell --model models_vw4s -p 5006 这样的方式启动。 action和shell要不同的端口
参考:
[1] https://rasa.com/docs/rasa/2.x/domain rasa官方文档
[2] https://zhuanlan.zhihu.com/p/475296948 rasa各个配置文件含义
[3] https://mp.weixin.qq.com/s?__biz=MzAxMjMwODMyMQ==&mid=2456341414&idx=2&sn=ce6b346718935cbea8822911e9e5b03b&chksm=8c2fb1a8bb5838beada7f7a55c0258d6e3e3c14515f169072fe8f5385502e8903eda7a26e92f&scene=21#wechat_redirect rasa专栏介绍
[4] https://blog.csdn.net/qnstar_/article/details/125330377 RASA-NLU的pipline各阶段说明
[5] https://www.likecs.com/show-204136203.html RASA 构建工程的教程
[6] https://www.likecs.com/show-308141008.html rasa做中文系统时候 slots,entities,actions,component等的详细设计(如何自己加组件)
[7] https://mp.weixin.qq.com/s/sJtDp58Eir49hr99QK-4BA rasa框架整理
[8] https://blog.csdn.net/qq_41475825/article/details/119646149 如何用pycharm调试rasa项目?
[9]https://www.jianshu.com/p/5d9aa2a444a3 rasa对话系统踩坑记
[10] https://edu.51cto.com/center/course/lesson/index?id=805713 rasa应用的视频教程
[11] https://rasa.leovan.tech/forms/ Rasa中文文档
[12] https://github.com/currywu123/RASA-FLASK-Chinese-Chatbot rasa项目