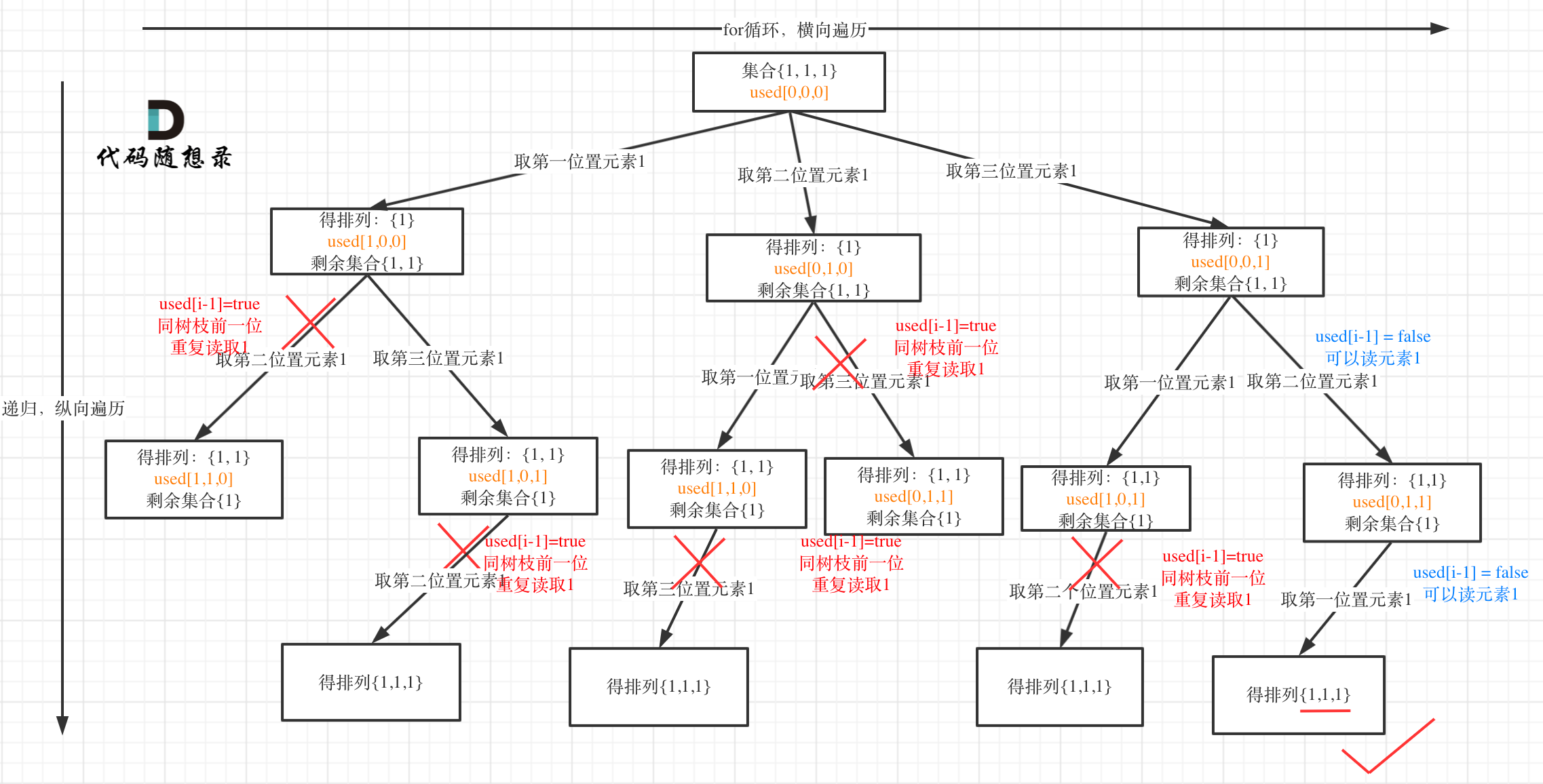
Redis基础
- 1. Redis 简介
- 2. Redis 应用
- 3. Redis 数据结构
- 3.1 String
- 3.2 hash
- 3.3 list
- 3.4 set
- 3.5 sorted set
- 4. Redis 为什么快?
- 5. Redis I/O 多路复用
- 6. Redis 6.0多线程
1. Redis 简介
Redis 是一种基于键值对的 NoSQL 数据库
Redis 中的 value 支持 string、hash、list、set、zset、Bitmaps(位图)、HyperLogLog(地图信息定位) 等多种数据结构
Redis 会将所有数据存在内存中,读写性能非常出色
Redis 可以将内存的数据利用快照和日志的形式保存到硬盘上,内存中的数据不会“丢失”
Redis 还提供了键过期、发布订阅、事务、流水线、Lua脚本等附加功能
2. Redis 应用
缓存:基本所有的 Web 应用都会使用 Redis 作为缓存,来降低数据源压力,提高响应速度

计数器:天然支持计数功能,计数性能好,可以用来记录浏览量、点赞量等
排行榜:Redis 提供列表和有序集合数据结构,可以构建各种排行榜系统
社交网络:点赞、点踩、粉丝、共同好友/喜好、推送、下拉刷新等
消息队列:Redis 提供了发布订阅功能和阻塞队列的功能,可以满足一般消息队列功能
分布式锁:分布式环境下,利用 Redis 实现分布式锁
3. Redis 数据结构

3.1 String
字符串最基础的数据结构。
字符串类型的值实际可以是字符串、数字,甚至是二进制,但是值最大不能超过512MB。
使用场景:
- 缓存功能
- 计数
- 共享 Session
- 限速
3.2 hash
哈希类型是指键值本身又是一个键值对结构。
使用场景:
- 缓存用户信息
- 缓存对象
3.3 list
列表(list)类型是用来存储多个有序的字符串。
列表是一种比较灵活的数据结构,它可以充当栈和队列的角色
使用场景:
- 消息队列
- 文章列表
3.4 set
集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一样的是,集合中不允许有重复元素,并且集合中的元素是无序的。
使用场景:
- 标签(tag)
- 共同关注
3.5 sorted set
有序集合中的元素可以排序。
但是它和列表使用索引下标作为排序依据不同的是,它给每个元素设置个权重(score)作为排序的依据。
使用场景:
- 用户点赞统计
- 用户排序
4. Redis 为什么快?
Redis 的速度非常的快,单机的 Redis 就可以支撑每秒十几万的并发,相对于MySQL 来说,性能是 MySQL 的几十倍。
速度快的原因主要有几点:
- 完全基于内存操作
- 使用单线程,避免了线程切换和竞态产生的消耗
- 基于非阻塞的IO多路复用机制
- C语言实现,基于基础的数据结构,Redis 大量的优化、性能极高
5. Redis I/O 多路复用
Redis 一直被大家熟知的就是它的单线程架构,虽然有的命令操作可以用后台线程或者子进程执行(比如数据删除,快照生成,AOF重写)。
但是,从网络 IO 处理到实际的读写命令处理,都是由单个线程完成的。
网络 IO 在系统层面上指的是数据从用户态到内核态的读写操作,多路是指多个 socket 连接。
复用是指一个或多个连接处理。一个服务端进程可以同时处理多个套接字描述符。
Redis 使用 IO 多路复用简单来说就是,单线程处理多个客户端连接的网络读写请求,并且能够保证不会阻塞主流程的一种机制。
6. Redis 6.0多线程
Redis6.0 的多线程是用多线程来处理数据的读写和协议解析,但是 Redis 执行命令还是单线程的
目的是因为 Redis 的性能瓶颈在于 网络IO 而非 CPU,使用多线程能提升 IO 读写的效率,从而整体提高 Redis 的性能。