小罗碎碎念
为了方便大家获取对应的代码和源数据,从本期推文开始,我将把对应的文件上传至Github仓库,感兴趣的同学自行获取。
仓库地址
https://github.com/Lxltxpku/Share
一、区域图
区域图是一种数据可视化工具,它通过在坐标轴上展示数据点并用颜色或阴影填充这些点下方的区域来表示数据的变化趋势。
这种图表类型特别适合展示随时间变化的数值变量,因为它不仅能够清晰地展示数据点的值,还能够直观地显示数据的波动范围和变化趋势。
在区域图中,X轴通常用来表示时间序列或有序的分类变量,而Y轴则用来展示对应的数值变量。通过将数据点按照X轴的顺序连接起来,形成一条折线,然后将这条折线下方的区域用颜色或阴影填充,可以更直观地展示数据的波动情况。
以比特币价格的演变过程为例,我们可以创建一个区域图来展示从2013年4月至2018年4月这段时间内比特币价格的变化。
代码演示
# Libraries
library(tidyverse) # 加载tidyverse包,提供数据整理和图形绘制功能
library(hrbrthemes) # 加载hrbrthemes包,提供一些美观的主题
library(plotly) # 加载plotly包,用于创建交互式图形
library(patchwork) # 加载patchwork包,用于组合多个图形
library(babynames) # 加载babynames包,用于处理婴儿名字数据
library(viridis) # 加载viridis包,提供一组连续的颜色调色板
# Load dataset from github
data <- read.table("https://raw.githubusercontent.com/holtzy/data_to_viz/master/Example_dataset/3_TwoNumOrdered.csv", header=T) # 从GitHub加载数据集
data$date <- as.Date(data$date) # 将数据集中的date列转换为日期格式
# plot
data %>%
ggplot( aes(x=date, y=value)) + # 使用ggplot2创建图形,设置x轴为日期,y轴为数值
geom_area(fill="#69b3a2", alpha=0.5) + # 添加面积图层,填充颜色为#69b3a2,透明度为0.5
geom_line(color="#69b3a2") + # 添加折线图层,颜色为#69b3a2
ggtitle("Evolution of Bitcoin price") + # 设置图形标题为"比特币价格演变"
ylab("bitcoin price ($)") + # 设置y轴标签为"比特币价格(美元)"
theme_minimal() # 使用最小化主题
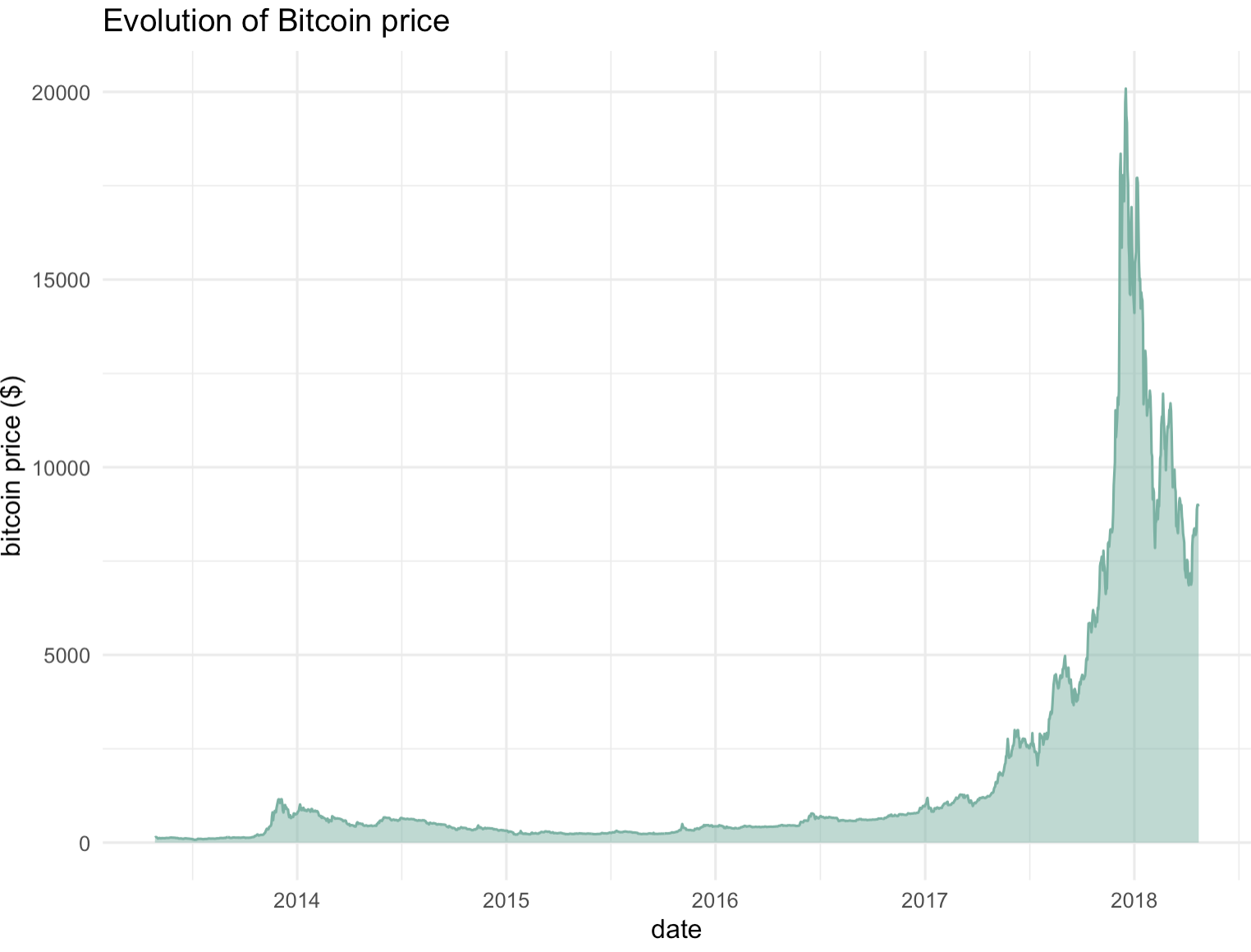
在这个区域图中,X轴表示时间,从2013年4月开始到2018年4月结束,而Y轴则表示比特币的价格。每个月的数据点通过直线段连接,形成一条折线,这条折线下方的区域则用特定的颜色填充,以突出显示价格的波动范围。
通过这样的区域图,我们可以很容易地看出比特币价格在这段时间内的总体趋势,比如是否有显著的上升或下降,以及价格波动的幅度。此外,区域图还可以帮助我们识别出一些关键的转折点或异常值,从而更好地理解比特币市场的动态。
二、用途
区域图用于展示数值变量的演变。有时,区域图因未优化数据墨比(data-ink ratio)而受到批评,数据墨比是一种数据可视化原则,它检查图表上没有无谓的墨迹使用。
确实,移除曲线下方的区域将得到一个传达相同信息的线形图。然而,在本人看来,区域图在展示演变方面做得非常好,填充区域使得模式更加明显。
区域图也可以用于展示多个变量的演变。最经典的方式是通过堆叠区域图,这将在另一部分讨论,但也可以使用小图表多重展示。
区域图的用途非常广泛,它不仅可以展示单个数值变量随时间的演变,还可以通过比较和堆叠的方式,同时展示多个变量的变化趋势。这种图表类型在数据分析和呈现中扮演着重要的角色,尤其是在需要强调数据变化模式和趋势时。
首先,区域图通过填充颜色或阴影,增强了数据点之间的视觉联系,使得数据的波动和趋势更加明显。这种视觉强化有助于观众快速识别数据的上升、下降或平稳阶段。例如,如果一个公司的季度收入数据显示在区域图中,观众可以一目了然地看出收入的增长或减少,以及增长或减少的幅度。
然而,区域图有时因为数据墨比不高而受到批评。数据墨比是爱德华·塔夫特提出的一个概念,它强调图表中的每一部分都应该传达信息,避免不必要的墨迹使用。在某些情况下,如果数据点之间的变化不是非常剧烈,或者观众更关注于数据点的精确值而非整体趋势,那么线形图可能是一个更简洁有效的选择。
尽管如此,区域图在展示多个变量的演变方面具有独特的优势。通过堆叠区域图,我们可以在一个图表中展示多个变量随时间的变化,并且这些变量的总和也可以清晰地呈现出来。例如,在市场研究中,堆叠区域图可以用来展示不同产品或服务在一段时间内的市场份额变化。
此外,区域图还可以通过小图表多重展示的方式来展示多个变量。这种方法通常用于展示不同类别或组别的数据,每个类别或组别都有自己的区域图,这些图表并排或堆叠显示,以便进行比较。
以下是一个示例,展示了几个婴儿名字在美国1880年至2015年间的频率演变。
# Load dataset from github
don <- babynames %>% # 从babynames包中加载数据集
filter(name %in% c("Ashley", "Amanda", "Mary", "Deborah", "Dorothy", "Betty", "Helen", "Jennifer", "Shirley")) %>% # 筛选出指定的名字
filter(sex=="F") # 筛选出女性名字
# Plot
don %>%
ggplot( aes(x=year, y=n, group=name, fill=name)) + # 使用ggplot2创建图形,设置x轴为年份,y轴为名字出现的次数,按名字分组并填充颜色
geom_area() + # 添加面积图层
scale_fill_viridis(discrete = TRUE) + # 设置填充颜色为viridis调色板的离散颜色
theme(legend.position="none") + # 移除图例
ggtitle("Popularity of American names in the previous 30 years") + # 设置图形标题为"过去30年美国名字的流行度"
theme_minimal() + # 使用最小化主题
theme(
legend.position="none", # 移除图例
panel.spacing = unit(0, "lines"), # 设置面板间距为0
strip.text.x = element_text(size = 8), # 设置分面标题字体大小为8
plot.title = element_text(size=13) # 设置图形标题字体大小为13
) +
facet_wrap(~name, scale="free_y") # 按名字分面,并允许每个分面的y轴范围自由调整
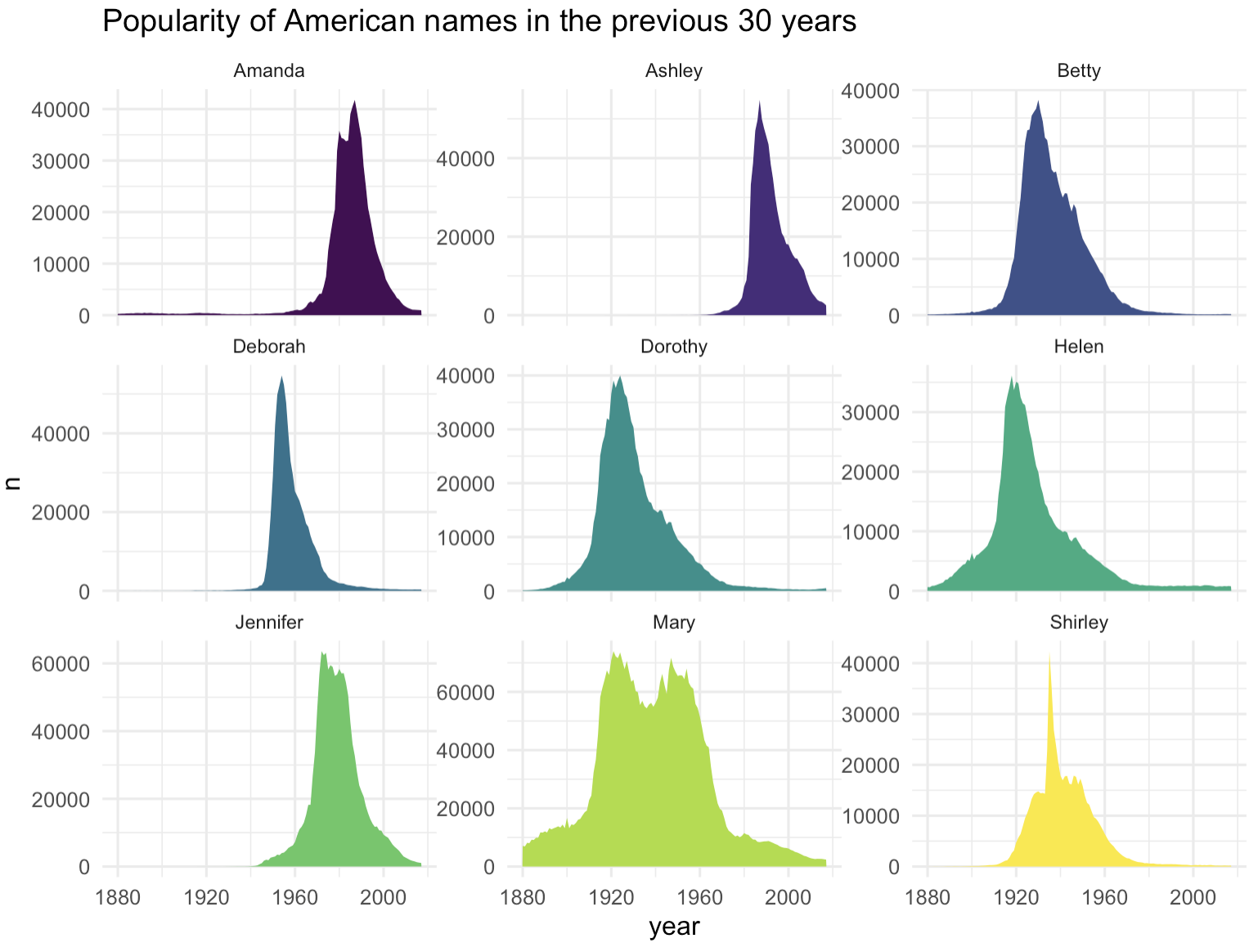
在展示1880年至2015年间美国几个婴儿名字的频率演变时,区域图可以有效地展示这些名字的流行趋势。通过将每个名字的频率变化用不同的颜色或阴影填充,我们可以清晰地看到哪些名字在某些时期特别流行,哪些名字的使用频率随时间减少。
这种展示方式不仅提供了丰富的视觉信息,还帮助我们理解社会文化和命名习惯的演变。
三、变体
如果数据点的数量较少,建议用点来表示每个单独的观测值。这样做可以更准确地理解观测值是在何时进行的:
data %>%
tail(10) %>% # 从数据集中取出最后10行数据
ggplot( aes(x=date, y=value)) + # 使用ggplot2创建图形,设置x轴为日期,y轴为数值
geom_line(color="#69b3a2") + # 添加折线图层,颜色为#69b3a2
geom_point(color="#69b3a2", size=4) + # 添加点图层,颜色为#69b3a2,大小为4
ggtitle("Cuting") + # 设置图形标题为"Cuting"
ylab("bitcoin price ($)") + # 设置y轴标签为"比特币价格(美元)"
theme_minimal() # 使用最小化主题
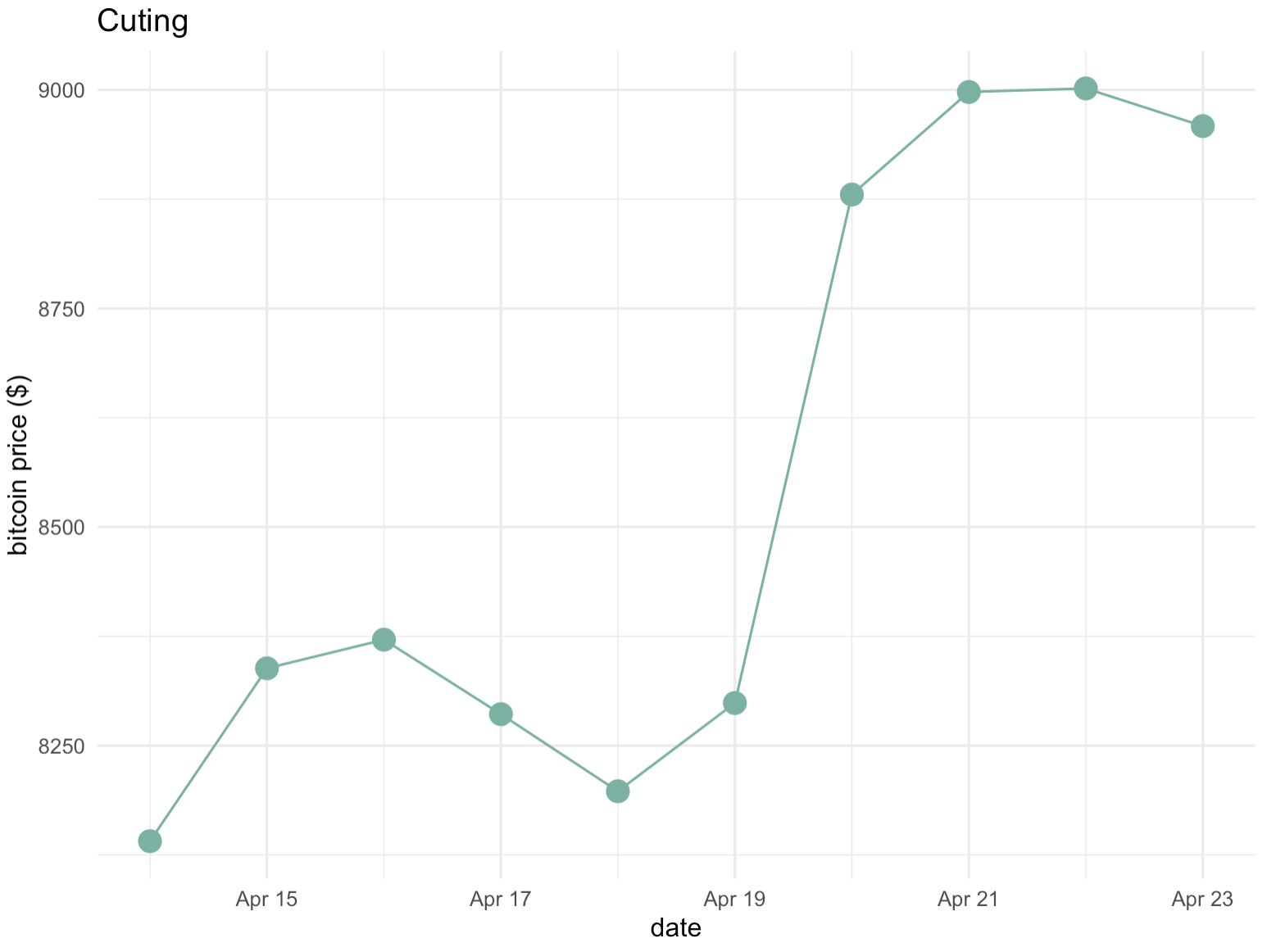
注意,线条也用于在散点图中显示趋势。以下是一个示例,使用了平滑的条件均值并展示了其周围的置信区间:
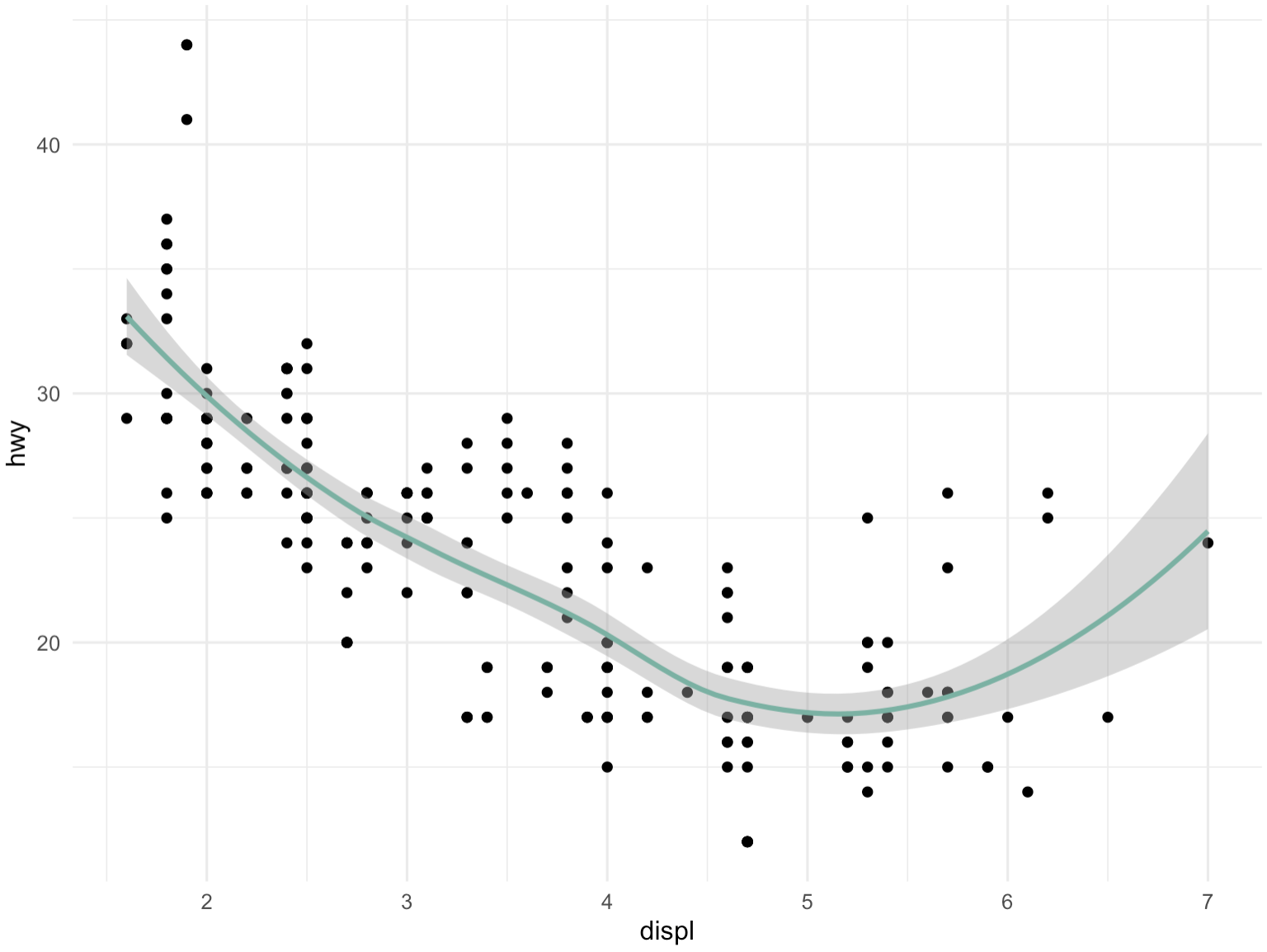
ggplot(mpg, aes(displ, hwy)) + # 使用ggplot2创建图形,数据集为mpg,x轴为displ(发动机排量),y轴为hwy(高速公路上的燃油效率)
geom_point() + # 添加散点图层,显示每个数据点的位置
geom_smooth(color="#69b3a2") + # 添加平滑曲线图层,颜色为#69b3a2,用于展示数据的趋势
theme_minimal() # 应用minimal主题,使图形具有更美观的外观








![polarctf靶场[CRYPTO]显而易见的密码、[CRYPTO]夏多的梦、[CRYPTO]再这么说话我揍你了、[CRYPTO]神秘组织M](https://i-blog.csdnimg.cn/direct/f8749a180b30467497e605843d1dbfd1.png)








![[创业之路-142] :生产 - 产品名称、型号、物料编码、批次、产品结构、BOM单、SN序列号、SOP、版本、回溯等常见概念之间的相互的结构化关系。](https://i-blog.csdnimg.cn/direct/1ad68cfb0acb41c79080f4dfdb065fa5.png)