文章目录
- IP协议
- 1.网络层 & IP协议基本概念
- 2.IP协议格式
- 2.1报头各字段简介
- 2.2IP如何将报头与有效载荷进行分离?
- 2.3IP如何决定将有效载荷交付给上层的哪一个协议?
- 2.4源IP与目的IP
- 2.5八位生存时间
- 2.6分片与组装
- 3.网段划分
- 3.1IP地址构成
- 3.2DHCP协议
- 3.3为什么要进行网段划分?
- 3.4网段划分方案
- 4.IP地址数量限制
- 5.私有IP和公网IP
- 6.路由器
- 7.路由
- 7.1路由的过程
- 7.2具体过程
IP协议
我们之前在学习传输层协议Tcp协议的时候说过:Tcp协议保证数据传输的可靠性,而网络层协议IP协议在数据传输中扮演什么角色呢?
1.网络层 & IP协议基本概念
-
网络层:负责在复杂的网络环境中确定一个合适的路径。
-
IP协议全称为“网际互连协议(Internet Protocol)”,IP协议是TCP/IP体系中的网络层协议。
这种在网络环境中确定路径的行为被称为“路由”,所以网络层在数据传输的过程中提供让数据找到对方主机的一种能力,而传输层+网络层,即TCP协议+IP协议一起确保了数据能够可靠地发送给对端主机。
我们都见过IP地址,假设IP地址为 123.122.122.4 ,其实IP地址是由两部分构成的,即IP=目标子网+目标主机。对于这个IP地址来说,目标子网就是 123.122.122.0,目标主机就是 4,其实这样也很好理解,假设你要去 外地城市旅游,你一定是先乘坐某一种交通工具到达目的城市,然后再到达目的景点。
主机和路由器
- 主机:配有IP地址,但是不进行路由控制的设备。但实际现在几乎不存在不进行路由控制的设备了,就连你的笔记本也会进行路由控制。
- 路由器:既配有IP地址,又能进行路由控制。实际现在主流的路由器已经不仅仅具有路由的功能了,它甚至具备某些应用层的功能。
- 节点:主机和路由器的统称。
2.IP协议格式
2.1报头各字段简介
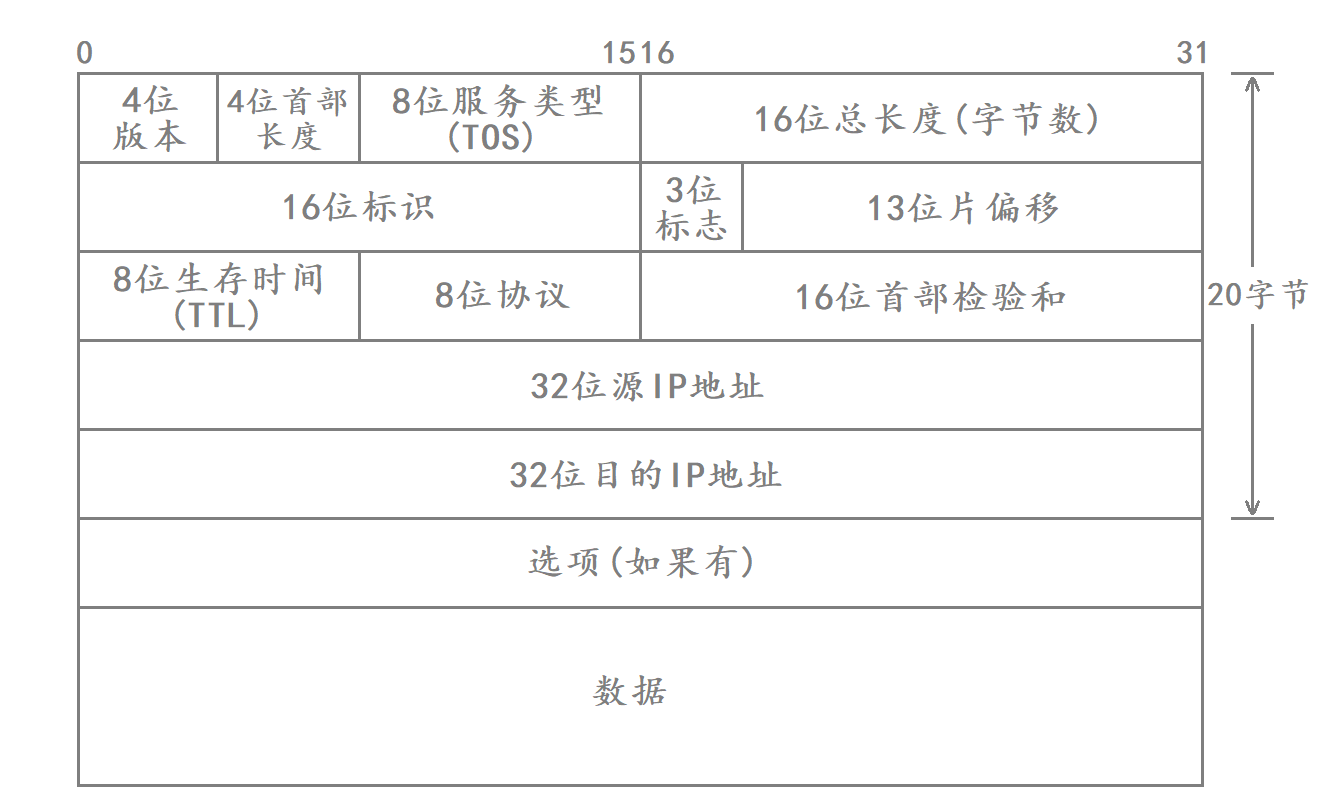
- 4位版本号(version):指定IP协议的版本(IPv4/IPv6),对于IPv4来说,就是4。
- 4位首部长度(header length):表示IP报头的长度,以4字节为单位。
- 8位服务类型(Type Of Service):3位优先权字段(已经弃用),4位TOS字段,和1位保留字段(必须置为0)。4位TOS分别表示:最小延时,最大吞吐量,最高可靠性,最小成本。这四者相互冲突,只能选择一个。比如对于ssh/telnet这样的应用程序,最小延时比较重要,而对于ftp这样的程序,最大吞吐量比较重要。
- 16位总长度(total length):IP报文(IP报头+有效载荷)的总长度,用于将各个IP报文进行分离。
- 16位标识(id):唯一的标识主机发送的报文,如果数据在IP层进行了分片,那么每一个分片对应的id都是相同的。
- 3位标志字段:第一位保留,表示暂时没有规定该字段的意义。第二位表示禁止分片,表示如果报文长度超过MTU,IP模块就会丢弃该报文。第三位表示“更多分片”,如果报文没有进行分片,则该字段设置为0,如果报文进行了分片,则除了最后一个分片报文设置为0以外,其余分片报文均设置为1。
- 13位片偏移(framegament offset):分片相对于原始数据开始处的偏移,表示当前分片在原数据中的偏移位置,实际偏移的字节数是这个值× 8得到的。因此除了最后一个报文之外,其他报文的长度必须是8的整数倍,否则报文就不连续了。
- 8位生存时间(Time To Live,TTL):数据报到达目的地的最大报文跳数,一般是64,每经过一个路由,TTL–,一直减到0还没到达,那么就丢弃了,这个字段主要是用来防止出现路由循环。
- 8位协议:表示上层协议的类型。
- 16位首部检验和:使用CRC进行校验,来鉴别数据报的首部是否损坏,但不检验数据部分。
- 32位源IP地址和32位目的IP地址:表示发送端和接收端所对应的IP地址。
- 选项字段:不定长,最多40字节。
IP报头在内核当中本质就是一个位段类型,给数据封装IP报头时,实际上就是用该位段类型定义一个变量,然后填充IP报头当中的各个属性字段,最后将这个IP报头拷贝到数据的首部,至此便完成了IP报头的封装。
2.2IP如何将报头与有效载荷进行分离?
与TCP相同,当IP获取到一个报文后,虽然IP不知道报头的具体长度,但IP报文的前20个字节是IP的基本报头,并且这20字节当中涵盖4位首部长度。
因此IP是这样分离报头与有效载荷的:
- 当IP从底层获取到一个报文后,首先读取报文的前20个字节,并从中提取出4位的首部长度,此时便获得了IP报头的大小 size。
- 如果 size 的值大于20字节,则需要继续从报文当中读取 size−20 字节的数据,这部分数据就是IP报头当中的选项字段。
- 读取完IP的基本报头和选项字段后,剩下的就是有效载荷了。
需要注意的是,IP报头当中的4位首部长度描述的基本单位与TCP报头当中的4位首部长度一样,都是以4字节为单位进行描述的,这也恰好是报文的宽度。
4位二进制的取值范围是0000 ~ 1111,因此IP报头的最大长度为15 × 4 = 60 15\times 4=6015×4=60字节,因为基本报头的长度是20字节,所以IP报头中选项字段的长度最多是40字节。
如果IP报头当中不携带选项字段,那么IP报头的长度就是20字节,此时报头当中的4位首部长度字段所填的值就是20 ÷ 4 = 5,即0101。
2.3IP如何决定将有效载荷交付给上层的哪一个协议?
基于IP协议的传输层协议不止一种,因此当IP从底层获取到一个报文并对其进行解包后,IP需要知道应该将分离后得到的有效载荷交付给上层的哪一个协议。
在IP报头当中有一个字段叫做8位协议,该字段表示的就是上层协议的类型,IP就是根据该字段判定应该将分离出来的有效载荷交付给上层的哪一个协议的。该字段是发送方的IP层从上层传输层获取到数据后填充的,比如是上层TCP交给IP层的数据,那么该数据在封装IP报头时的8位协议填充的就是TCP对应的编号。
2.4源IP与目的IP
IP报头当中的32位源IP地址和32位目的IP地址,分别代表的就是该报文的发送端和接收端对应的IP地址。
网络传输的基本模式是请求与响应,那么报文就需要在网络通信的过程中始终明确我从哪里来(以便响应),我到哪里去(以便请求),源IP与目的IP解决的就是在网络世界中唯一标识主机。
理解socket编程
在进行socket编程的时候,当一端想要发送数据给另一端时,必须要指明对端的IP地址和端口号,也就是发送数据的目的IP地址和目的端口号。
其中这里的IP地址就是给网络层的IP用的,用于数据在网络传输过程中的路由转发,而这里的端口号就是给传输层的TCP或UDP用的,用于指明该数据应该交给上层的哪一个进程。
发送数据时我们不需要指明发送数据的源IP地址和源端口号,因为传输层和网络层都是在操作系统内核当中实现的,数据在进行封装时操作系统会自行填充上对应的源IP地址和源端口号。
2.5八位生存时间
报文在网络传输过程中,可能因为某些原因导致报文无法到达目标主机,比如报文在路由时出现了环路的情况,或者目标主机已经异常离线了,此时这个报文就成了一个废弃的游离报文。
为了避免网络当中出现大量的游离报文,于是在IP的报头当中就出现了一个字段,叫做8位生存时间(Time To Live,TTL)。8位生存时间代表的是报文到达目的地的最大报文跳数,每当报文经过一次路由,这里的生存时间就会减一,当生存时间减为0时该报文就会被自动丢弃,此时这个报文就会在网络中消散。
2.6分片与组装
MAC帧作为数据链路层的协议,它会将IP传下来的数据封装成数据帧,然后发送到网络当中。但MAC帧携带的有效载荷的最大长度是有限制的,也就是说IP交给MAC帧的报文不能超过某个值,这个值就叫做最大传输单元(Maximum Transmission Unit,MTU),这个值的大小一般是1500字节。
在Linux下使用ifconfig命令可以查看对应的MTU。
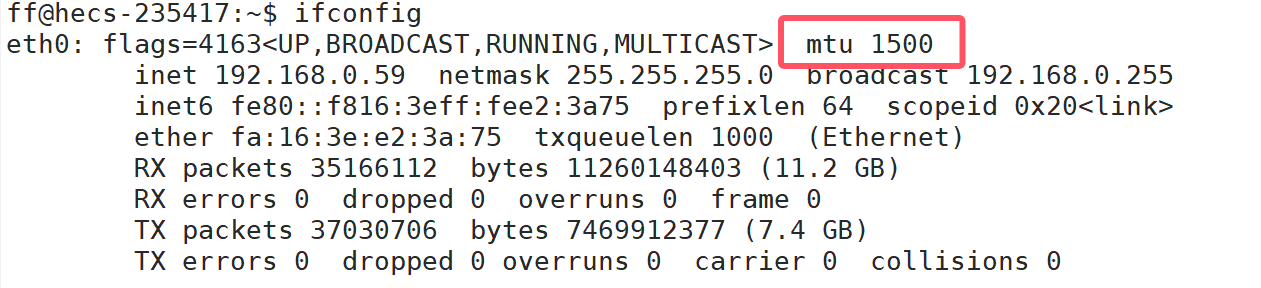
由于MAC帧无法发送大于1500字节的数据,因此IP层向下交付的数据的长度不能超过1500字节,这里所说的数据包括IP的报头和IP的有效载荷。
所以如果IP层要传输的数据大于1500字节,就需要先在IP层将该数据进行分片,然后再将分片后的数据交给链路层发送,对端网络层收到后会将数据进行组装。
数据的分片不是经常需要做的,实际在网络通信过程中不分片才是常态,即不建议分片。
之前我们在学习TCP协议时存在有一个滑动窗口的概念,当时我提出了一个疑问:为什么不能将滑动窗口中的数据一次性发送出去,而反而要将滑动窗口分为若干个小块,每次发送仅发送窗口中的一小块,实际上就是因为链路层MAC帧报文的最大传输单元问题。
以上策略其实就是为了防止IP层数据过大需要分片的情况,但是如果传输层还是将过大的数据交给了IP层,IP层就会对该部分数据进行分片,分片会有什么风险呢?
只有当接收端收到了全部的分片报文并将其成功组装起来,才认为该数据被对方可靠的收到了。但如果众多的分片报文当中有一个报文出现了丢包,就会导致接收端就无法将报文成功组装起来,这时接收端会将收到的分片报文全部丢弃,此时传输层TCP会因为收不到对方应答而进行超时重传。
假设在网络传输时丢包的概率是万分之一,如果将数据拆分为一百份进行发送,那么此时丢包的概率就上升到了百分之一。因为只要有一个分片报文丢包了也就等同于这个报文整体丢失了,因此分片会增加传输层重传数据的概率。
如何尽可能避免分片?
实际数据分片的根本原因在于传输层一次向下交付的数据太多了,导致IP无法直接将数据向下交给MAC帧,如果传输层控制好一次交给IP的数据量不要太大,那么数据在IP层自然也就不需要进行分片。
因此TCP作为传输控制协议,它需要控制一次向下交付数据不能超过某一阈值,这个阈值就叫做MSS(Maximum Segment Size,最大报文段长度)。
- 通信双方在建立TCP连接时,除了需要协商自身窗口大小等概念之外,还会协商后续通信时每一个报文段所能承载的最大报文段长度MSS。
- MAC帧的有效载荷最大为MTU,TCP的有效载荷最大为MSS,由于TCP和IP常规情况下报头的长度都是20字节,因此一般情况下 MSS = MTU - 20 - 20,而MTU的值一般是1500字节,因此MSS的值一般就是1460字节。
所以一般建议TCP将发送的数据控制在1460字节以内,此时就能够降低数据分片的可能性。之所以说是降低数据分片的可能性,是因为每个网络的链路层对应的MTU可能是不同的,如果数据在传输过程中进入到了一个MTU较小的网络,那么该数据仍然可能需要在路由器中进行分片。
注意:
- 数据的分片和组装发生在IP层,不仅源端主机可能会对数据进行分片,数据在路由过程中的路由器也可能对数据进行分片。因为不同网络的MTU是不一样的,如果传输路径上的某个网络的MTU比源端网络的MTU小,那么路由器就可能对IP数据报再次进行分片。
- 在分片的数据中,每一个分片在IP层都会被添加上对应的IP报头(因为每个分片都必须知道源目的IP和分片的具体信息,这些信息都在IP报头中),而传输层添加的报头只会出现在第一个分片中,因此网络中传输的数据包可能没有传输层的报头。
- 数据的分片和组装都是在IP层完成的,上层的传输层和下层的链路层并不关心。
(1)具体分片过程
假设IP层要发送4500字节的数据,由于该数据超过了MAC帧规定的MTU,因此IP需要先将该数据进行分片,然后再将一个个的分片交给MAC帧进行发送。
IP报头如果不携带选项字段,那么其大小就是20字节,假设IP层添加的IP报头的长度就是20字节,并按下列方式将数据分片后形成了四个分片报文:
| 分片报文 | 总字节数 | IP报头字节数 | 数据字节数 |
|---|---|---|---|
| 1 | 1500 | 20 | 1480 |
| 2 | 1500 | 20 | 1480 |
| 3 | 1500 | 20 | 1480 |
| 4 | 80 | 20 | 60 |
需要注意的是,分片后的每一个分片数据都需要封装上对应的IP报头,因此4500字节的数据至少需要分为四个分片报文进行发送。
分片报文到达对方的IP层后需要被重新组装起来,因此IP层在对数据进行分片时需要记录分片的信息,而IP报头当中的16位标识、3位标志和13位片偏移实际就是与数据分片相关的字段。
- 16位标识:唯一标识主机发送的报文,如果数据在IP层进行了分片,那么每一个分片报文的16位标识是相同的。
- 3位标志:第一位保留,表示暂时没有规定该字段的意义。第二位表示禁止分片,表示如果报文长度超过MTU,IP模块就会丢弃该报文。第三位表示“更多分片”,如果报文没有进行分片,则该字段设置为0,如果报文进行了分片,则除了最后一个分片报文设置为0以外,其余分片报文均设置为1。
- 13位片偏移:分片相对于原始数据开始处的偏移,表示当前分片在原数据中的偏移位置,实际偏移的字节数是这个值 × 8 得到的。因此除了最后一个报文之外,其他报文的长度必须是8的整数倍,否则报文就不连续了。
为什么偏移字节数必须是 8的整数倍 ?
IP报文长度用 16位 表示,片偏移用 13 位标识,为了让 13位片偏移 能够表示总的报文长度,在填充片偏移字段时要对真实偏移量 / 8,即让真实偏移量 >> 3 ,未来在提取真实偏移量时,对 片偏移 * 8,即片偏移 << 3,由于偏移字节数必须是 8 的整数倍,所以真实偏移量的后三位一定是0,比如 111 1000 =120是8的整数倍,这样后三位为0,右移3位不会丢失精度。
由于上述四个分片同属一个报文,所以各片对应的16位标识都是一样的,假设四个分片报文的16位标识都是123,则这四个报文对应的16位标识、3位标志中的“更多分片”和13位片偏移分别如下:
| 分片报文 | 总字节数 | IP报头字节数 | 数据字节数 | 16位标识 | “更多分片” | 13位片偏移 |
|---|---|---|---|---|---|---|
| 1 | 1500 | 20 | 1480 | 123 | 1 | 0 |
| 2 | 1500 | 20 | 1480 | 123 | 1 | 185 |
| 3 | 1500 | 20 | 1480 | 123 | 1 | 370 |
| 4 | 80 | 20 | 60 | 123 | 0 | 555 |
分片报文2在原始数据开始处的偏移字节数是1480(去掉报头),其对应的13位片偏移的值就是1480 ÷ 8 = 185 。
(2)具体组装过程
MAC帧交给IP层的数据可能来自世界各地,这些数据可能是经过分片后发送的,也可能是没有经过分片直接发送的,因此IP必须要通过某种方式来区分收到的各个数据。
- IP报头当中有32位源IP地址,源IP地址记录了发送端所对应的IP地址,因此通过IP报头当中的32位源IP地址就可以区分来自不同主机的数据。
- IP报头当中有16位标识,未分片的数据各自的16位标识都是不同的,而由同一个数据分片得到的各个分片报文所对应的16位标识都是相同的,因此通过IP报头当中16位标识就可以判断哪些报文是没有经过分片的独立报文,哪些报文是经过分片后的分片报文。
因此IP可以通过IP报头当中的32位源IP地址和16位标识,将经过分片的数据各自聚合在一起,聚合在一起后就可以开始进行组装了。
对于各个分片报文来说:
- 第一个分片报文中的13位片偏移的值一定为0。
- 最后一个分片报文中的“更多分片”标志位一定为0。
- 对于每一个分片报文来说,当前报文的13位片偏移加上当前报文的数据字节数 ÷ 8 所得到的值,就是下一个分片报文的所对应的13位片偏移。
根据分片报文的这三个特点就能够将分片报文合理的组装起来。
- 先找到分片报文中13位片偏移为0的分片报文,然后提取出其IP报头当中的16位总长度字段,通过计算即可得出下一个分片报文所对应的13位片偏移,按照此方式依次将各个分片报文拼接起来。
- 直到拼接到一个“更多分片”标志位为0的分片报文,此时表明分片报文组装完毕。
如果分片报文丢包,接收端有能力判断是否收到了全部分片报文,比如假设某组分片报文对应的16位标识值为x:
- 如果分片报文中的第一个分片报文丢包了,那么接收端收到的分片报文中就找不到对应16位标识为x,并且13位片偏移为0的分片报文。
- 如果分片报文中的最后一个分片报文丢包了,那么接收端收到的分片报文中就找不到对应16为标识为x,并且“更多分片”标志位为0的分片报文。
- 如果分片报文中的其它分片报文丢包了,那么接收端在进行分片报文的组装时就会找不到对应13位片偏移为特定值的分片报文。
需要注意的是,未分片报文的“更多分片”标志位为0,最后一个分片报文的“更多分片”标志位也为0,但当接收端只收到分片报文中的最后一个分片报文时,接收端不会将其识别成一个未分片的报文,因为未分片的报文所对应的13位片偏移的值也应该是0,而最后一个分片报文所对应的13位片偏移的值不为0。
因此只有当一个报文的13位片偏移为0,并且该报文的“更多分片”标志位也为0时,该报文才会被识别成一个没有被分片的独立报文,否则该报文就会被识别成一个分片报文。
3.网段划分
3.1IP地址构成
IP地址由网络号和主机号两部分构成:
- 网络号:保证相互连接的两个网段具有不同的标识。
- 主机号:同一网段内,主机之间具有相同的网络号,但是必须有不同的主机号。
可以在IP地址的后面加一个 /,并在 / 后面加上一个数字,这就表示从头数到第几位为止属于网络标识。
例如,下图中路由器连接了两个网段。对于网络标识来讲,同一网段内主机的网络标识是相同的,不同网段内主机的网络标识是不同的。而对于主机标识来讲,同一网段内主机的主机标识是不同的,不同网段内主机的主机标识是可以相同的。

- 不同的子网其实就是把网络号相同的主机放到一起。
- 如果在子网中新增一台主机,则这台主机的网络号和这个子网的网络号一致,但是主机号必须不能和子网中的其他主机重复。
3.2DHCP协议
实际手动管理IP地址是一个非常麻烦的事情,当子网中新增主机时需要给其分配一个IP地址,当子网当中有主机断开网络时又需要将其IP地址进行回收,便于分配给后续新增的主机使用。
因此对于IP地址的分配和回收一般不会手动进行,而是采用DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)技术。
DHCP通常被应用在大型的局域网环境中,其主要作用就是集中地址管理、分配IP地址,使网络环境中的主机动态获得IP地址、Gateway地址、DNS服务器地址等信息,并能够提升地址的使用率。
DHCP是一个基于UDP的应用层协议,一般的路由器都带有DHCP功能,因此路由器也可以看作一个DHCP服务器。
当我们连接WiFi时需要输入密码,本质就是因为路由器需要验证你的账号和密码,如果验证通过,那么路由器就会给你动态分配了一个IP地址,然后你就可以基于这个IP地址进行各种上网动作了。
3.3为什么要进行网段划分?
当IP要将数据跨网络从一台主机发送到另一台主机时,其实不是直接将数据发送到了目标主机,而是先将数据发送到目标主机所在的网络,然后再将数据发送到目标主机。
因此数据在路由时的第一目的并不是找到目标主机,而是找到目标网络所在的网络,然后再在目标网络当中找到目标主机。
数据路由时之所以不一开始就以找目标主机为目的,因为这样效率太低了。
查询的过程本质是排除的过程,如果一开始就以找目标主机为目的,那么在查找的过程中一次只能排除一个主机。而如果一开始先以找目标网络为目的,那么在查找过程中就能一次排除大量和目标主机不在同一网段的主机,这样就可以大大提高检索的效率。
因此,为了提高数据路由的效率,我们对网络进行了网段划分。
3.4网段划分方案
过去曾经提出一种划分网络号和主机号的方案,就是把所有IP地址分为五类,如下图所示:

因此,各类IP地址的取值范围如下:
- A类:0.0.0.0到127.255.255.255。
- B类:128.0.0.0到191.255.255.255。
- C类:192.0.0.0到223.255.255.255。
- D类:224.0.0.0到239.255.255.255。
- E类:240.0.0.0到247.255.255.255。
随着Internet的飞速发展,这种划分方案的局限性很快显现出来,大多数组织都申请B类网络地址,导致B类地址很快就分配完了,而A类却浪费了大量地址;
- 比如一些学校、公司、实验室等组织想要申请自己的局域网,由于A类地址的网络号只占7个比特位,因此A类地址可申请的网络只有 2^7 =128 个,于是大多数组织都选择申请B类地址。
- 由于B类地址的主机号占16个比特位,因此理论上一个B类网络当中允许有65536台主机。
- 但实际网络架设中,一般不会存在一个局域网当中有这么多主机的情况,也就意味着大量的IP地址实际都被浪费掉了。
为了避免这种情况,于是又提出了新的划分方案,称为CIDR(Classless Interdomain Routing):
- 在原有的五类网络的基础上继续进行子网划分,这也就意味着需要借用主机号当中的若干位来充当网络号(这样就避免了IP地址被大量浪费),此时为了区分IP地址中的网络号和主机号,于是引入了**子网掩码(subnet mask)**的概念。
- 每一个子网都有自己的子网掩码,子网掩码实际就是一个32位的正整数,通常用一串“0”来结尾。
- 将IP地址与当前网络的子网掩码进行“按位与”操作,就能够得到当前所在网络的网络号。
- 比如在某一子网中将IP地址的前24位作为网络号,那么该网络对应的子网掩码的32个比特位中的前24位就为1,剩下的8个比特位为0,此时子网掩码用点分十机制表示就是255.255.255.0。
- 假设该子网当中有一台主机对应的IP地址是192.168.128.10,那么将这个IP地址与该网络对应的子网掩码进行“按位与”操作后得到的就是192.168.128.0,这就是这个子网对应的网络号。
- 实际在用子网掩码与子网当中主机的IP地址进行“按位与”操作时,本质就是保留了主机IP地址中前24个比特位的原貌,将剩下的8个比特位的值清0了而已,也就是将主机号清0了,所以“按位与”后的结果就是该网络对应的网络号。
需要注意的是,子网划分不是只能进行一次,我们可以在划分出来的子网的基础上继续进行子网划分。
因此一个数据在路由的时候,随着数据不断路由进入更小的子网,其网络号的位数是在不断变化的,准确来说其网络号的位数是在不断增加的,这也就意味着IP地址当中的主机号的位数在不断减少。最终当数据路由到达目标主机所在的网络时,就可以在该网络当中找到对应的目标主机并将数据交给该主机,此时该数据的路由也就结束了。
特殊的IP地址
并不是所有的IP地址都能够作为主机的IP地址,有些IP地址本身就是具有特殊用途的。
- 将IP地址中的主机地址全部设为0,就成为了网络号,代表这个局域网。
- 将IP地址中的主机地址全部设为1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包。
- 127.*的IP地址用于本机环回(loop back)测试,通常是127.0.0.1。
也就是说,IP地址中主机号为全0的代表的是当前局域网的网络号,IP地址中主机号为全1的代表的是广播地址,这两个IP地址都是不能作为主机的IP地址的。因此在某个局域网中最多能存在的主机个数是 (2 ^ 主机号位数)- 2 。
本机环回
本机环回会将数据贯穿网络协议栈,但最终并不会将数据发送到网络当中,相当于本机环回时不会将数据写到网卡上面。
本机环回的目的就是将数据自顶向下贯穿协议栈,进行一次数据封装的过程的过程,然后再自底向上贯穿协议栈,进行一次数据的解包和分用,用于测试本地的网络功能是否正常。
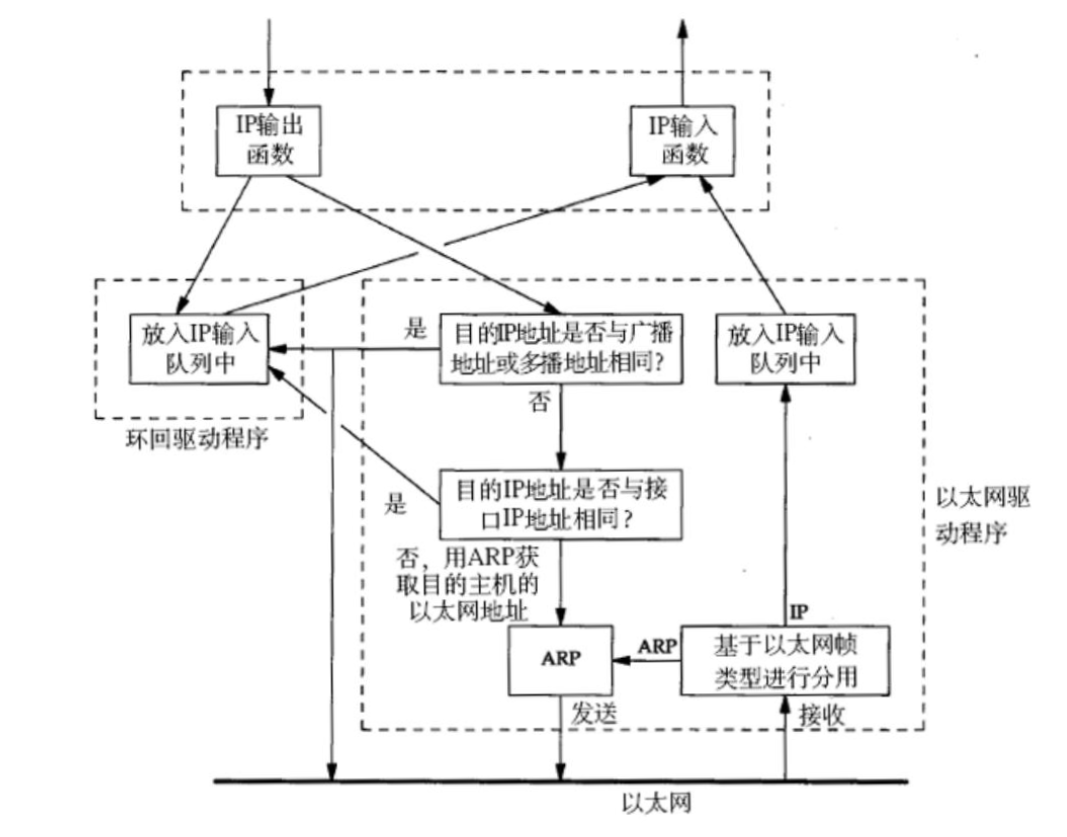
本机环回的基本原理:
- 当数据到达IP层需要继续向下交付时,如果是环回程序,那么IP输出函数会将该数据放入到IP输入队列当中,然后再由IP输入函数读取上去。
- 而IP输入函数将数据读取上去的本应该是链路层交付上来的数据,因此该数据后续就会被当作从网络中读取上来的数据看待,各层协议会对该数据依次进行解包和分用。
- 如果不是环回程序的话,那么接下来就会判断该数据对应的目的IP地址是否为广播或多播地址,或者目的IP地址是否与本主机的IP地址相同,如果是则也会将该数据放入到IP输入队列当中,等待IP输入函数将其读走。
- 只有判断程序不是环回程序,并且也不是广播或多播,或发给本主机的数据后,才会用ARP获取该数据目的主机的以太网地址并进行后续数据发送的操作。
4.IP地址数量限制
我们知道,IP地址(IPv4)是一个4字节32位的正整数,因此一共有 2^32 个IP地址,也就是将近43亿个IP地址。但TCP/IP协议规定,每个主机都需要有一个IP地址。
这意味着,一共只有43亿台主机能接入网络么?
实际上,由于一些特殊的IP地址的存在,数量远不足43亿;另外IP地址并非是按照主机台数来配置的,而是每一个网卡都需要配置一个或多个IP地址(比如跨子网的路由器需要两个网卡即两个IP)。
所以IP地址其实早就不够用了,CIDR在一定程度上缓解了IP地址不够用的问题(提高了利用率,减少了浪费,但是IP地址的绝对上限并没有增加),仍然不是很够用。这时候有三种方式来解决:
- 动态分配IP地址:只给接入网络的设备分配IP地址,因此同一个MAC地址的设备,每次接入互联网中,得到的IP地址不一定是相同的,避免了IP地址强绑定于某一台设备。
- NAT技术:能够让不同局域网当中同时存在两个相同的IP地址,NAT技术不仅能解决IP地址不足的问题,而且还能够有效地避免来自网络外部的攻击,隐藏并保护网络内部的计算机。
- IPv6:IPv6用16字节128位来表示一个IP地址,能够大大缓解IP地址不足的问题。注意IPv6并不是IPv4的简单升级版,它们是互不相干的两个协议,彼此并不兼容。
5.私有IP和公网IP
如果一个组织内部组建局域网,IP地址只用于局域网内的通信,而不直接连到Internet上,理论上使用任意的IP地址都可以,但是RFC 1918规定了用于组建局域网的私有IP地址。
- 10.,前8位是网络号,共16,777,216个地址。
- 172.16.到172.31.,前12位是网络号,共1,048,576个地址。
- 192.168.,前16位是网络号,共65,536个地址。
包含在这个范围中的,都称为私网IP,其余的则称为公网IP(或全局IP)。
是不是感觉到192.168这串数字非常熟悉,没错这就是一般的家庭网络所使用的私网IP地址,这个IP地址并不是公网IP,该IP地址仅在你所处的局域网内有效。
如果你现在的手机连接的是家庭wifi,你可以看一下手机此时的IP地址:
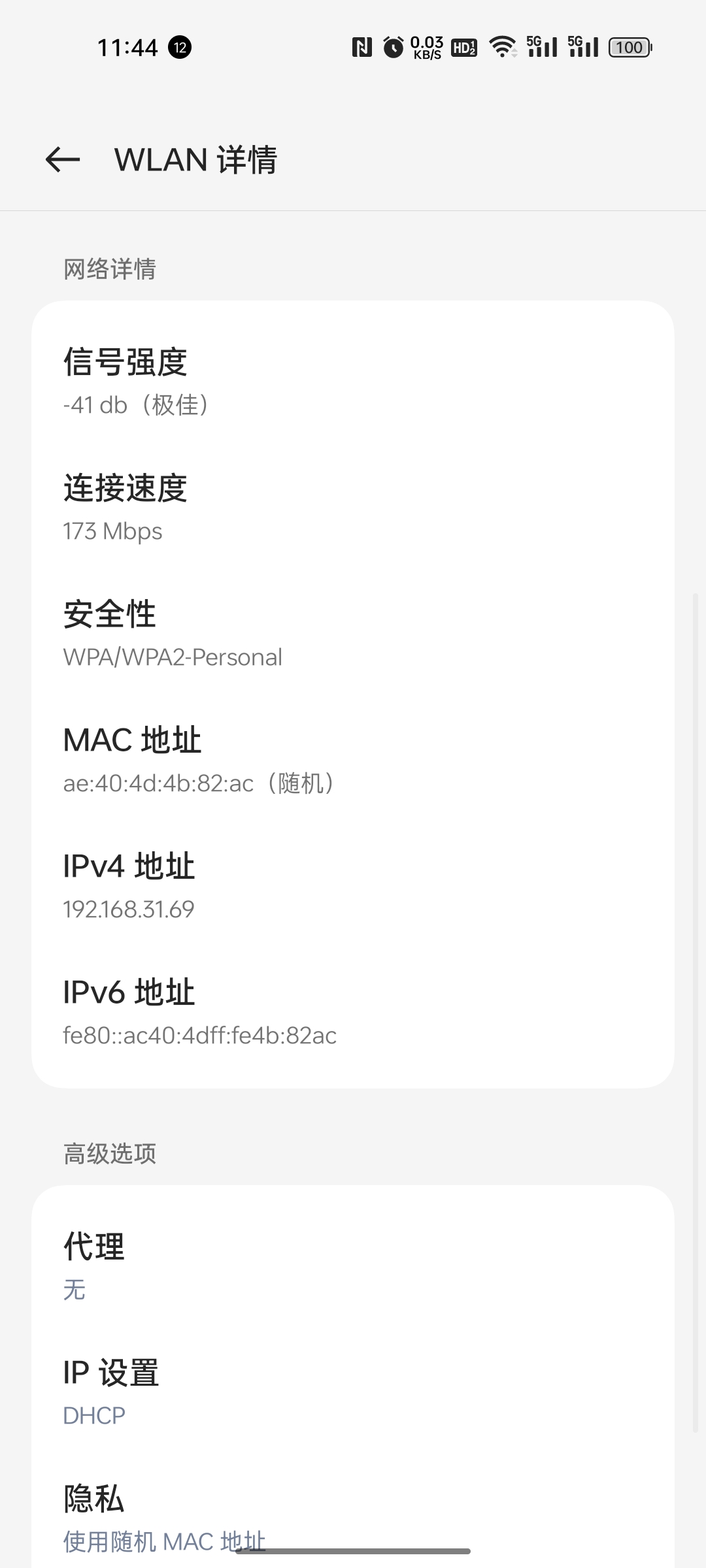
电脑也是一样,在cmd窗口中输入ipconfig命令查看当前IP:

那再来看一下云服务器的IP地址情况:
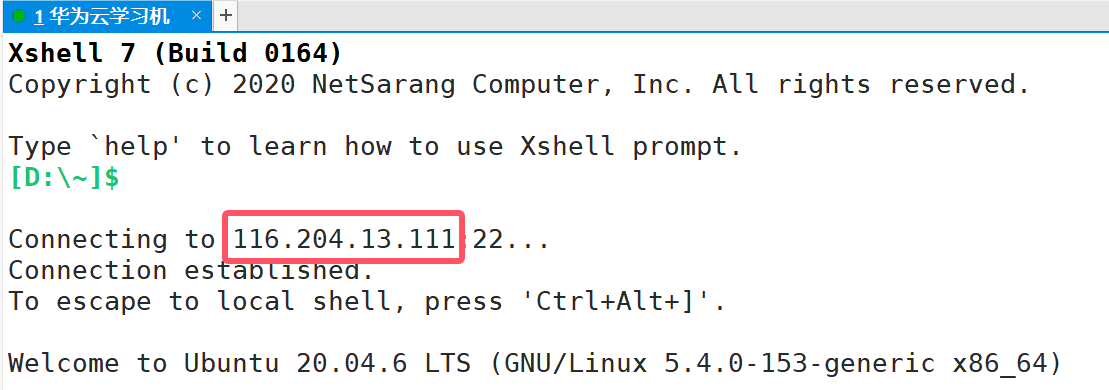
很明显116开头的IP是公网IP地址。
通过ifconfig命令来查看我们这台机器的私网IP:
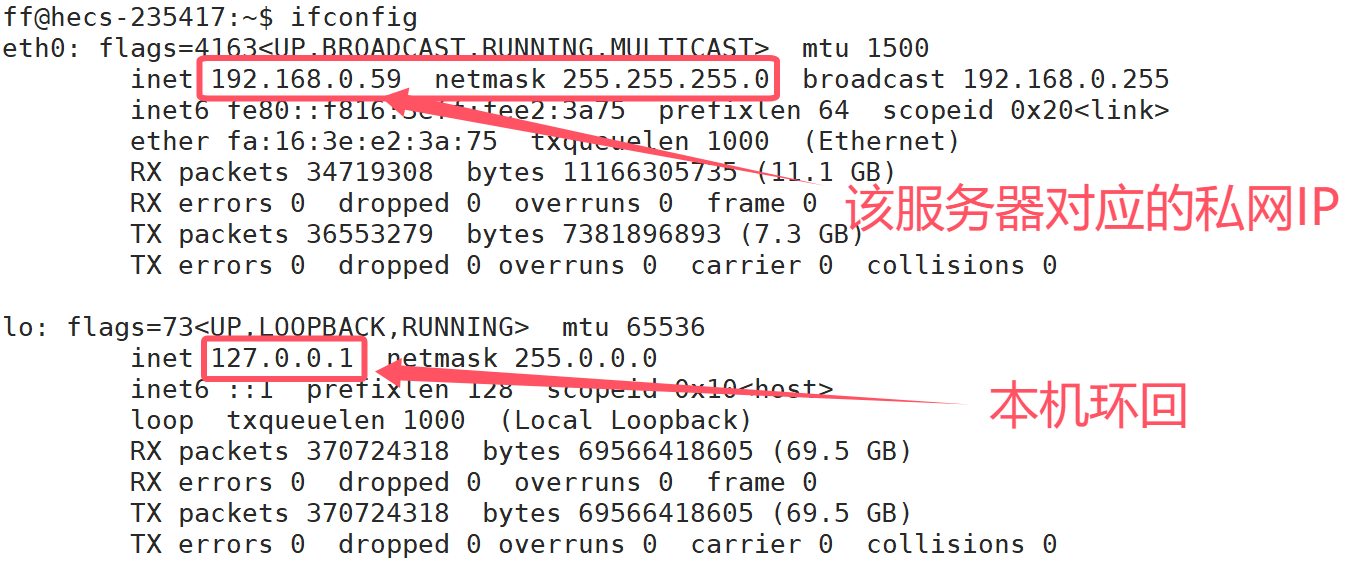
那我的设备想要发送数据给云服务器,目的IP是填云服务器的私网IP:192.168.0.59 么?
答案是否定的,因为私网IP仅在子网内有效,我与云服务器处于不同的子网内,想要发送数据给云服务器必须知道云服务器的公网IP,即 116.204.13.111。所以这一过程一定会跨子网,那如何跨越子网呢?
6.路由器
路由器可以完成数据转发,将数据从一个网络传输到另一个网络。
路由器是连接两个或多个网络的硬件设备,在路由器上有两种网络接口,分别是LAN口和WAN口:
- LAN口(Local Area Network):表示连接本地网络的端口,主要与家庭网络中的交换机、集线器或PC相连。
- WAN口(Wide Area Network):表示连接广域网的端口,一般指互联网。
我们将LAN口的IP地址叫做LAN口IP,也叫做子网IP,将WAN口的IP地址叫做WAN口IPO,也叫做外网IP。
我们使用的电脑、家用路由器、运营商路由器、广域网以及我们要访问的服务器之间的关系大致如下:
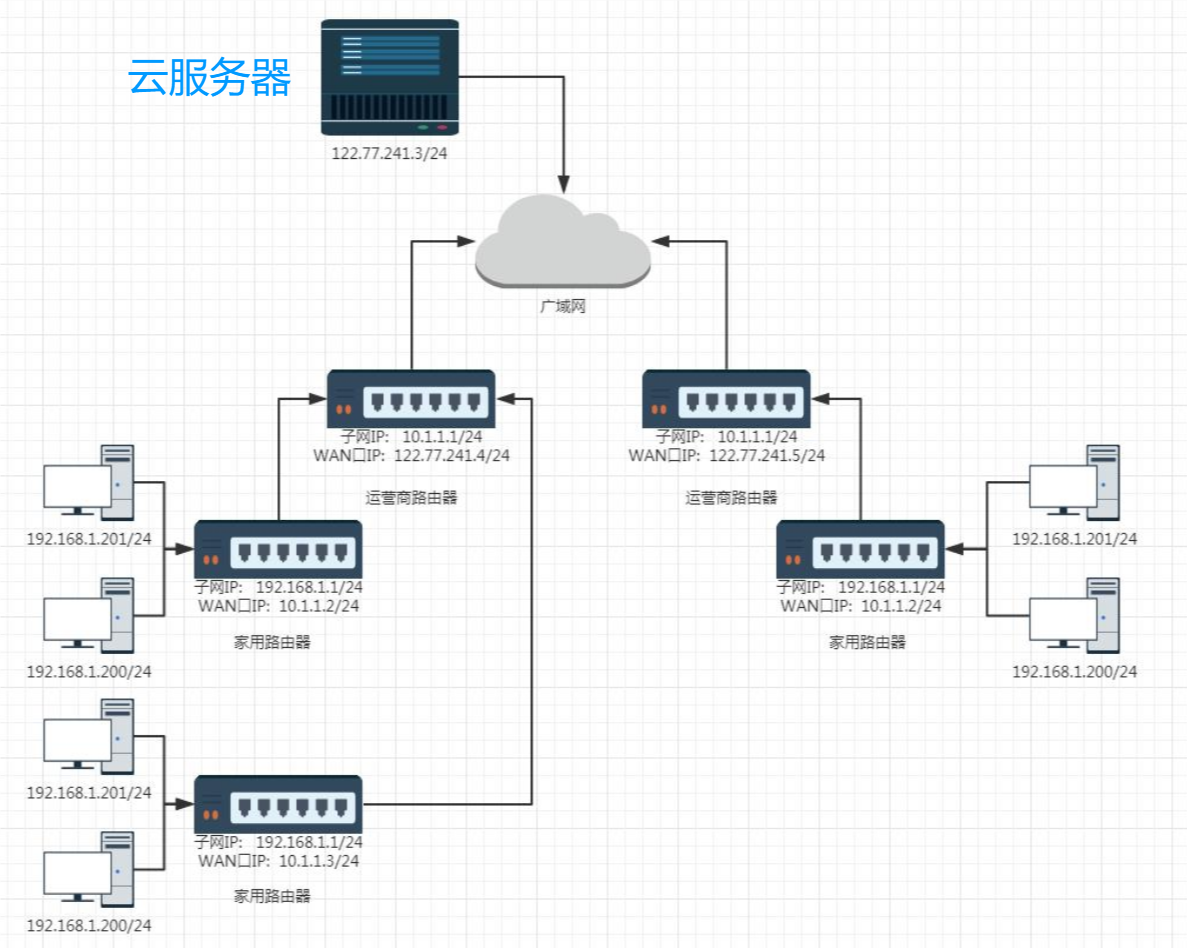
不同的路由器,子网IP其实都是一样的(通常都是192.168.1.1),子网内的主机IP地址不能重复,但是子网之间的IP地址就可以重复了。
每一个家用路由器,其实又作为运营商路由器的子网中的一个节点,这样的运营商路由器可能会有很多级,最外层的运营商路由器的WAN口IP就是一个公网IP了。
如果希望我们自己实现的服务器程序,能够在公网上被访问到,就需要把程序部署在一台具有外网IP的服务器上,这样的服务器可以在阿里云/华为云上进行购买。
由于私网IP不能出现在公网当中,因此子网内的主机在和外网进行通信时,路由器会不断将数据包IP首部中的源IP地址替换成路由器的WAN口IP,这样逐级替换,直到数据包中的源IP地址替换为一个公网IP,这种技术称为NAT(Network Address Translation,网络地址转换)。
所以NAT技术在某种程度上缓解了IP地址不足的问题:通过路由器可以维护多个子网,子网内又可以维护多个设备,这样大量的个人设备使用私网IP即可,不占用有限的公网IP。
两个局域网当中的主机不能不跨公网进行通信
- 两个局域网当中的主机理论上是不能不跨公网进行通信的,因为一个主机要将数据发送给另一台主机的前提是得先知道另一台主机的IP地址。
- 即便现在这个主机知道了另一台主机的IP地址,但有可能这两台主机的IP地址是一样的,因为它们的IP地址都是私网IP地址。
- 所以数据要从一个局域网发送到另一个局域网,如果不经过公网是基本上不可能的。我们在和别人聊天的时候,也不是直接将数据从一个局域网直接发送到了另一个局域网,而是先将数据经过公网发送到了服务器,然后再由服务器将数据经过公网转发到了另一个局域网。
但实际确实存在一些技术能够使数据包在发送过程中不进行公网IP的替换,而将数据正确送到目标主机,这种技术叫做内网穿透,也叫做NAT穿透。
运营商
可以看到一般我们使用网络都是处于某一子网内,而子网对外连接的渠道就是通过路由器,而家用路由器也是在更大型路由器维护的子网下的一个节点而已,这个更大型的路由器其实就是运营商提供的,所以我们一切的网络行为都绕不开运营商,我们访问服务器的数据并不是直接发送到了对应的服务器,而是需要经过运营商建设的各种基站以及各种路由器,最终数据才能到达对应的服务器。
也就是说,用户上网的数据首先必须经过运营商的相关网络设备,然后才能发送到互联网公司对应的服务器。因此所谓的网段划分、子网划分等工作实际都是运营商做的。
7.路由
7.1路由的过程
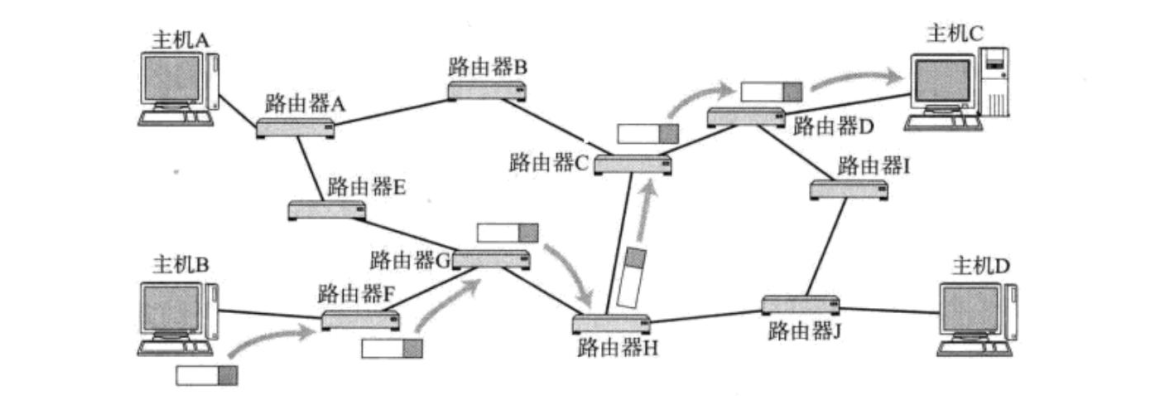
数据在路由的过程中,实际就是一跳一跳(Hop by Hop)的“问路”过程。所谓“一跳”就是数据链路层中的一个区间,具体在以太网中指从源MAC地址到目的MAC地址之间的帧传输区间。

IP数据包的传输过程中会遇到很多路由器,这些路由器会帮助数据包进行路由转发,每当数据包遇到一个路由器后,对应路由器都会查看该数据的目的IP地址,并告知该数据下一跳应该往哪跳。
路由器的查找结果可能有以下三种:
- 路由器经过路由表查询后,得知该数据下一跳应该跳到哪一个子网。
- 路由器经过路由表查询后,没有发现匹配的子网,此时路由器会将该数据转发给默认路由。
- 路由器经过路由表查询后,得知该数据的目标网络就是当前所在的网络,此时路由器就会将该数据转给当前网络中对应的主机。
7.2具体过程
每个路由器内部会维护一个路由表,我们可以通过route命令查看云服务器上对应的路由表。

字段解释:
Destination代表的是目标网络或主机的IP地址。如果这一列显示为default(或0.0.0.0),则表示这是一个默认网关,用于发送那些没有明确路由规则的数据包。Gateway代表的是下一跳地址,如果目标是本地网络上的主机,则这一列通常显示为*,表示不需要通过网关。Genmask代表的是子网掩码。Flags代表的是标志位,用于表示路由的各种属性。常见的标志包括:U(路由是活动的)、H(目标是一个主机地址)、G(需要通过网关发送数据,没有G标志的条目表示目的网络地址是与本机接口直接相连的网络,不必经路由器转发)。多个标志可能同时出现,例如UG表示该路由既需要通过网关发送数据,又是活动的。Iface代表的是发送接口。
当IP数据包到达路由器时,路由器就会用该数据的目的IP地址,依次与路由表中的子网掩码Genmask进行“按位与”操作,然后将结果与子网掩码对应的目的网络地址Destination进行比对,如果匹配则说明该数据包下一跳就应该跳去这个子网,此时就会将该数据包通过对应的发送接口Iface发出。
如果没有找到匹配的目的网络地址,此时路由器就会将这个数据包发送到默认路由,也就是路由表中目标网络地址中的default。可以看到默认路由对应的Flags是UG,实际就是将该数据转给了另一台路由器,让该数据在另一台路由器继续进行路由。
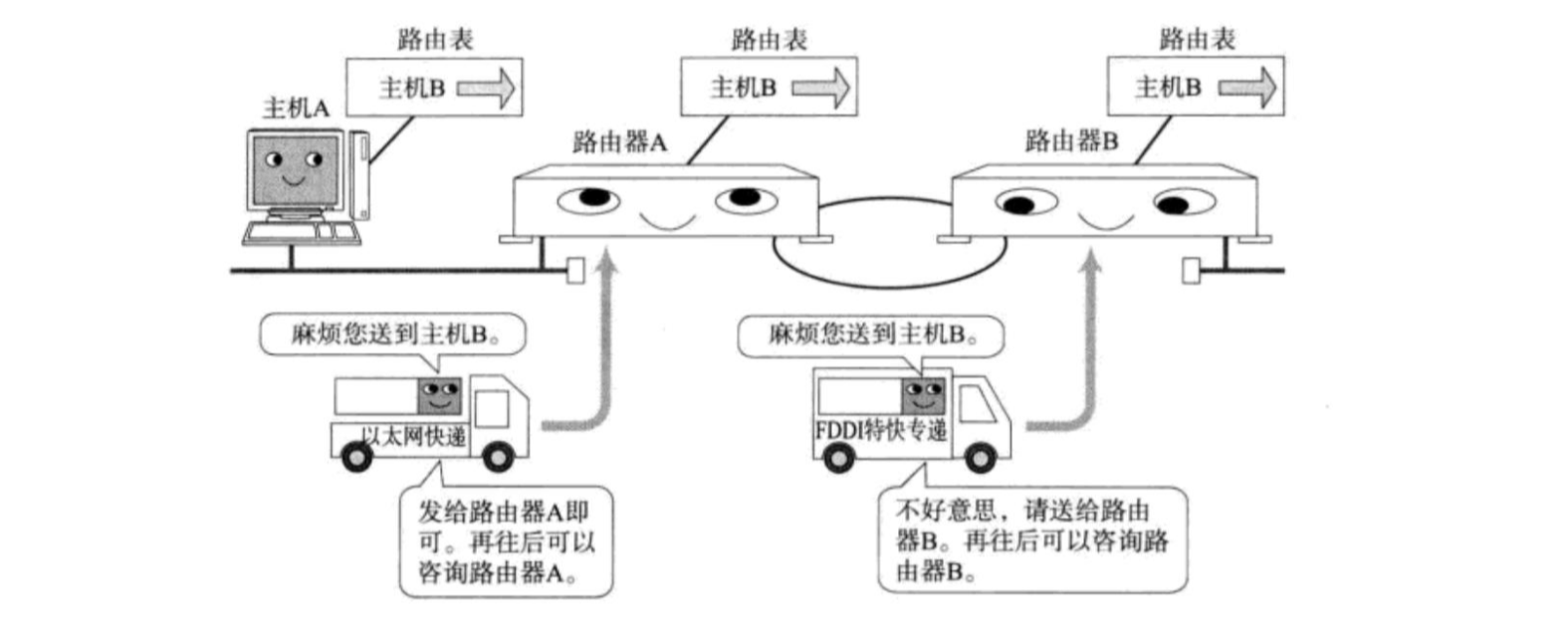
数据包不断经过路由器路由后,最终就能到达目标主机所在的目标网络,此时就不再根据该数据包目的IP地址当中的网络号进行路由了,而是根据目的IP地址当中的主机号进行路由,最终根据该数据包对应的主机号就能将数据发送给目标主机了。
路由表生成算法
路由可分为静态路由和动态路由:
- 静态路由:是指由网络管理员手工配置路由信息。
- 动态路由:是指路由器能够通过算法自动建立自己的路由表,并且能够根据实际情况进行调整。
路由表相关生成算法:距离向量算法、LS算法、Dijkstra算法等。
博观而约取,厚积而薄发。 —苏轼


















