目录
1.Redis持久化
1.1 RDB快照
1.2AOF
1.3混合持久化
2.Redis主从架构
2.1主从工作原理
2.1.1全量复制
2.1.2增量复制
3.Redis哨兵高可用架构
3.1哨兵架构模型
3.2哨兵模式的作用
3.3故障转移机制
3.4主节点选举机制
4.Redis管道-pipeline
1.Redis持久化
有两种持久化策略:
- RDB(Redis DataBase) :简而言之,就是在指定的时间间隔内,定时的将 redis 存储的数据生成Snapshot快照并存储到磁盘等介质上;
- AOF(Append Of File) :将 redis 执行过的所有写指令记录下来,在下次 redis 重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
1.1 RDB快照
在默认情况下,Redis将内存数据库快照保存在名字为dump.rdb的二进制文件中。(redis中,RDB是默认开启的)
Redis借助操作系统提供的写时复制机制(Copy On Write,COW),在生成快照的同时,依然可以正常处理写命令。
写入RDB文件是由bgsave子线程完成的,bgsave子线程是由主线程fork生成的,它可以共享主线程的所有内存数据。bgsave子进程运行后,开始读取主线程的内存数据,并把他们写入RDB文件。
如果主线程要修改一块数据,由COW机制,这块数据会被复制一份,生成该数据的副本,然后,bgsave子进程会把这块数据写入RDB文件中(这就是快照的概念,保存了原始数据),在这个过程中,主线程仍然可以直接修改副本数据。
1.2AOF
Redis 增加了一种完全耐久的持久化方式: AOF 持久化,将修改的每一条指令记录进文件appendonly.aof中(先写入os cache,每隔一段时间 fsync刷到磁盘)。AOF使用的是resp协议格式数据。
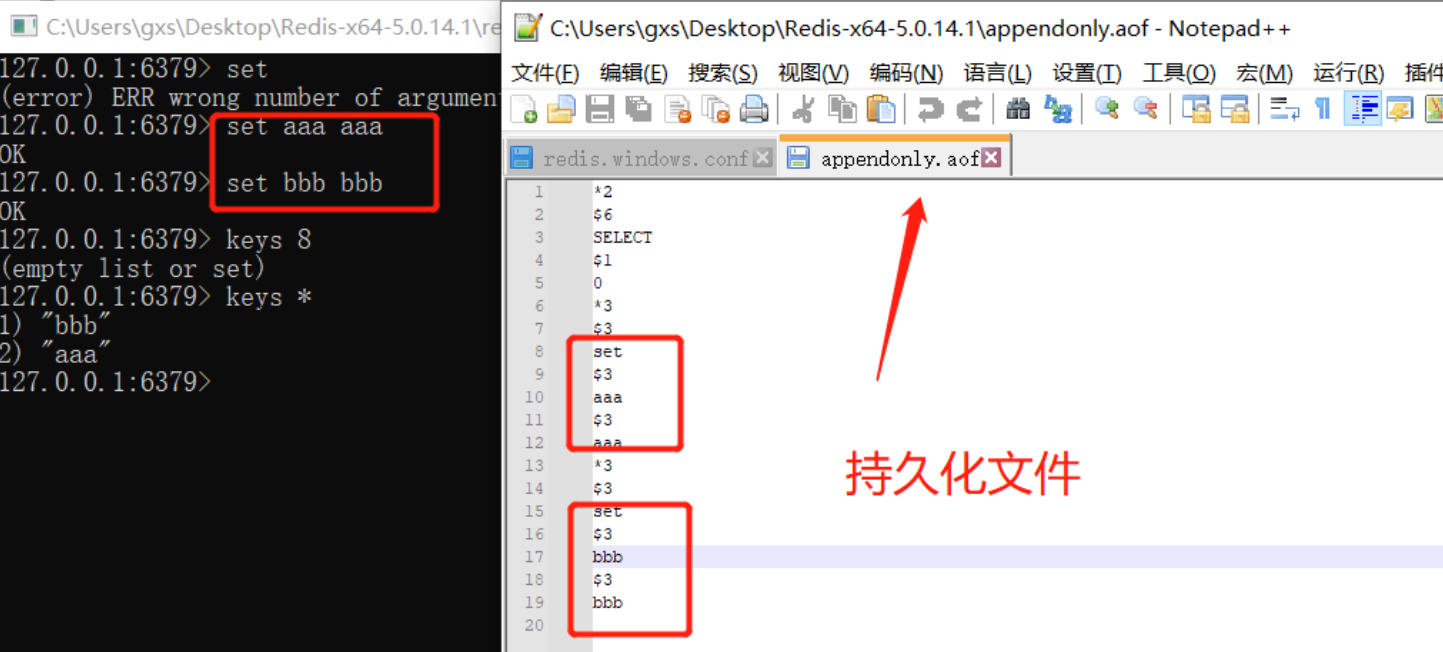
RDB和AOF的比较:
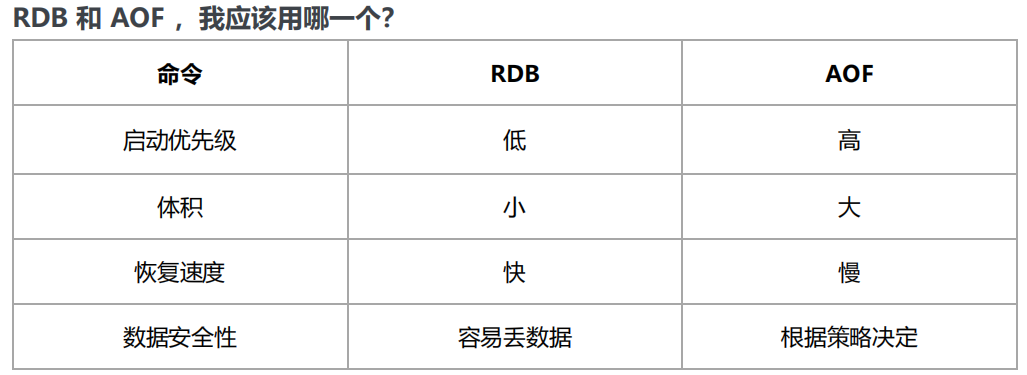
说明:因为RDB是二进制文件存储的数据本身,所以恢复速度快;而AOF存储的是指令本身,恢复的时候相当于重演指令,所以速度慢一些。RDB并不会立刻把用户修改的数据写入磁盘,所以存在数据丢失的问题,AOF也可能存在数据丢失的问题,但是AOF的策略可以强制用户每次执行指令的时候,先执行AOF操作,将指令写到磁盘,这样就不会产生数据丢失问题。
1.3混合持久化
重启 Redis 时,我们很少使用 rdb 来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重放,但是重放 AOF 日志性能相对 rdb 来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很长的时间。
Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。
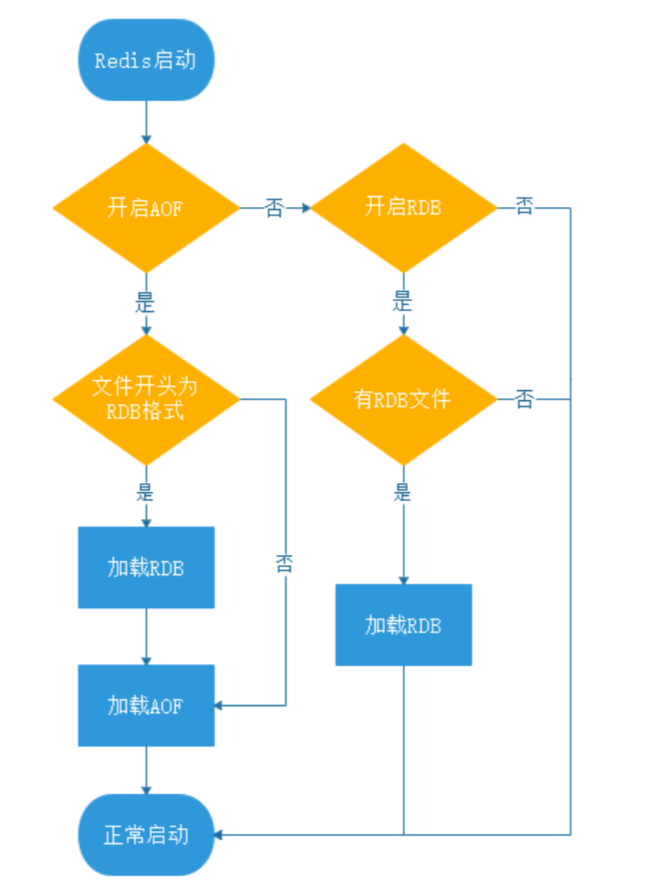
混合持久化AOF文件结构如下:

混合持久化的加载流程如下:
2.Redis主从架构
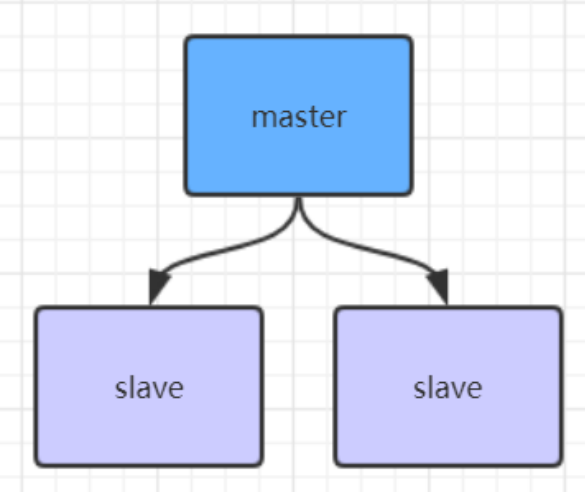
2.1主从工作原理
2.1.1全量复制
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC命令给master请求复制数据。
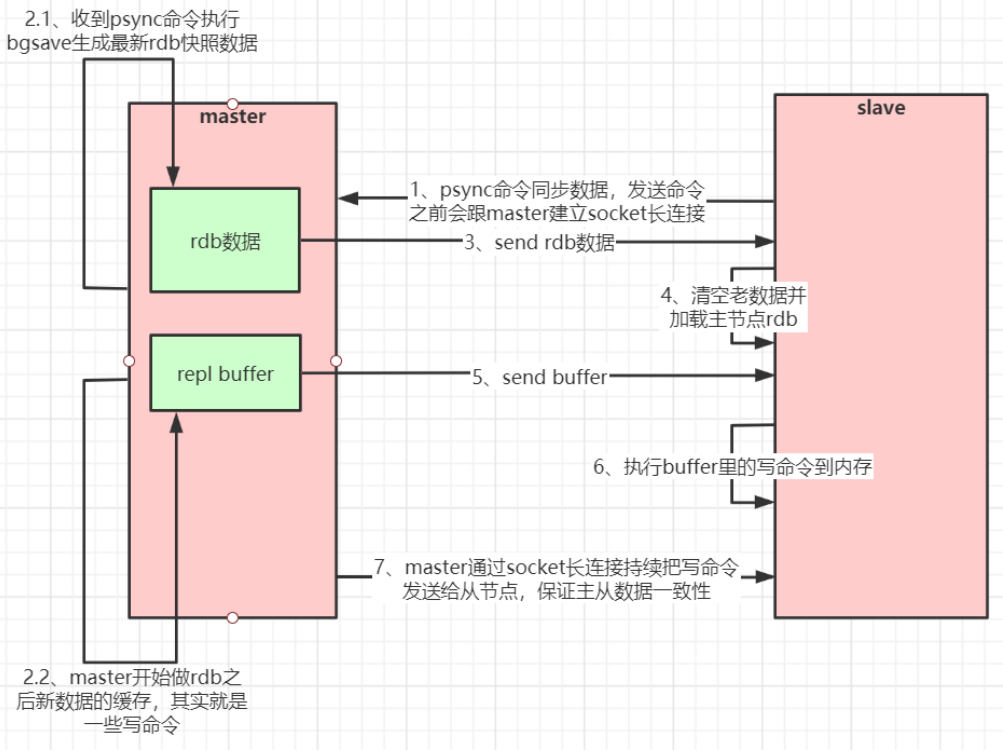
2.1.2增量复制
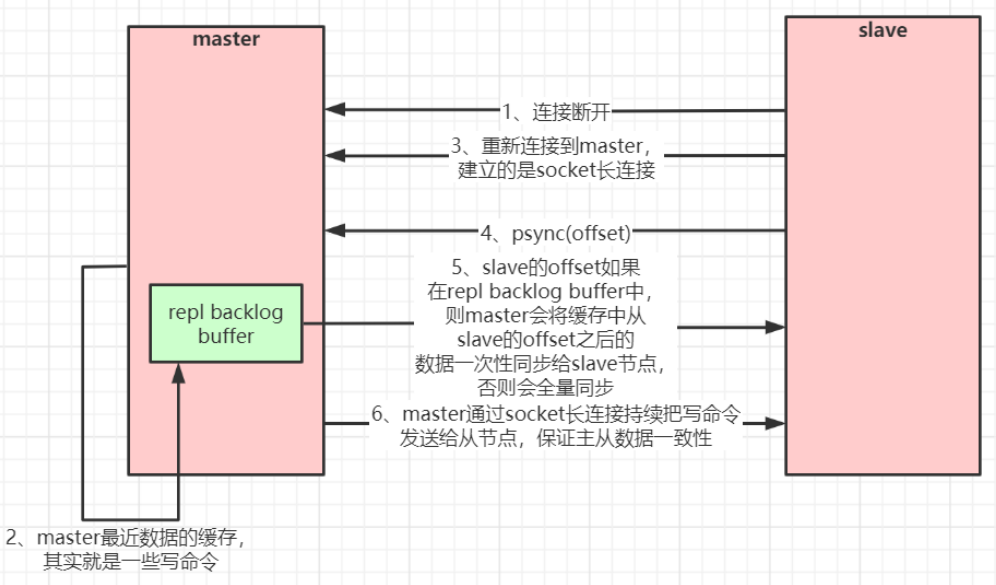
从redis2.8版本开始,redis改用可以支持部分数据复制的命令PSYNC去master同步数据,slave与master能够在网络连接断开重连后只进行部分数据复制(断点续传)。
master会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的slave都维护了复制的数据下标offset和master的进程id,因此,当网络连接断开后,slave会请求master继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制。
3.Redis哨兵高可用架构
3.1哨兵架构模型
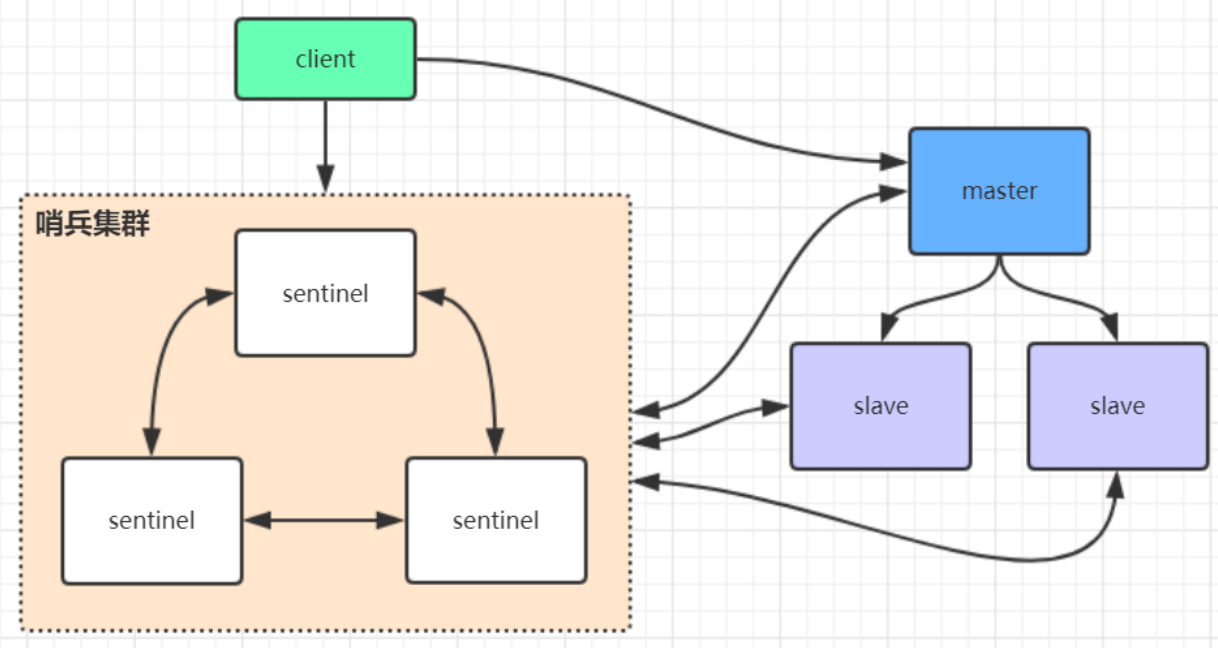
哨兵模式的核心功能是在主从复制的基础上,引入了主节点的自动故障转移。
哨兵结构由两部分组成,哨兵节点和数据节点
哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据。
数据节点:主节点和从节点都是数据节点。
3.2哨兵模式的作用
1)监控:哨兵会不断地检查主节点和从节点是否运作正常。
2)自动故障转移:当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其它从节点改为复制新的主节点。
3)通知(提醒):哨兵可以将故障转移的结果发送给客户端。
3.3故障转移机制
1.由哨兵节点定期监控发现主节点是否出现了故障。
每个哨兵节点每隔1秒会向主节点、从节点及其它哨兵节点发送一次ping命令做一次心跳检测。
如果主节点在一定时间范围内不回复或者是回复一个错误消息,那么这个哨兵就会认为这个主节点主观下线了(单方面的)。
当超过半数哨兵节点认为该主节点主观下线了,这样就客观下线了。
2.当主节点出现故障,此时哨兵节点会通过Raft算法(选举算法)实现选举机制共同选举出一个哨兵节点leader,来负责处理主节点的故障转移和通知。
所以整个运行哨兵的集群的数量不得少于3个节点。
3.由leader哨兵节点执行故障转移。
(客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。)
3.4主节点选举机制
1)过滤掉不健康的(已下线的)没有回复哨兵 ping 响应的从节点。
2)选择配置文件中从节点优先级配置最高的。(replica-priority,默认值为100)
3)选择复制偏移量最大,也就是复制最完整的从节点。
4.Redis管道-pipeline
客户端可以一次性发送多个请求而不用等待服务器的响应,待所有命令都发送完后再一次性读取服务的响应,这样可以极大的降低多条命令执行的网络传输开销,管道执行多条命令的网络开销实际上只相当于一次命令执行的网络开销。
需要注意到的是,用pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。
pipeline中发送的每个command都会被server立即执行,如果执行失败,将会在此后的响应中得到信息;也就是pipeline并不是表达“所有command都一起成功”的语义,管道中前面命令失败,后面命令不会有影响,继续执行。