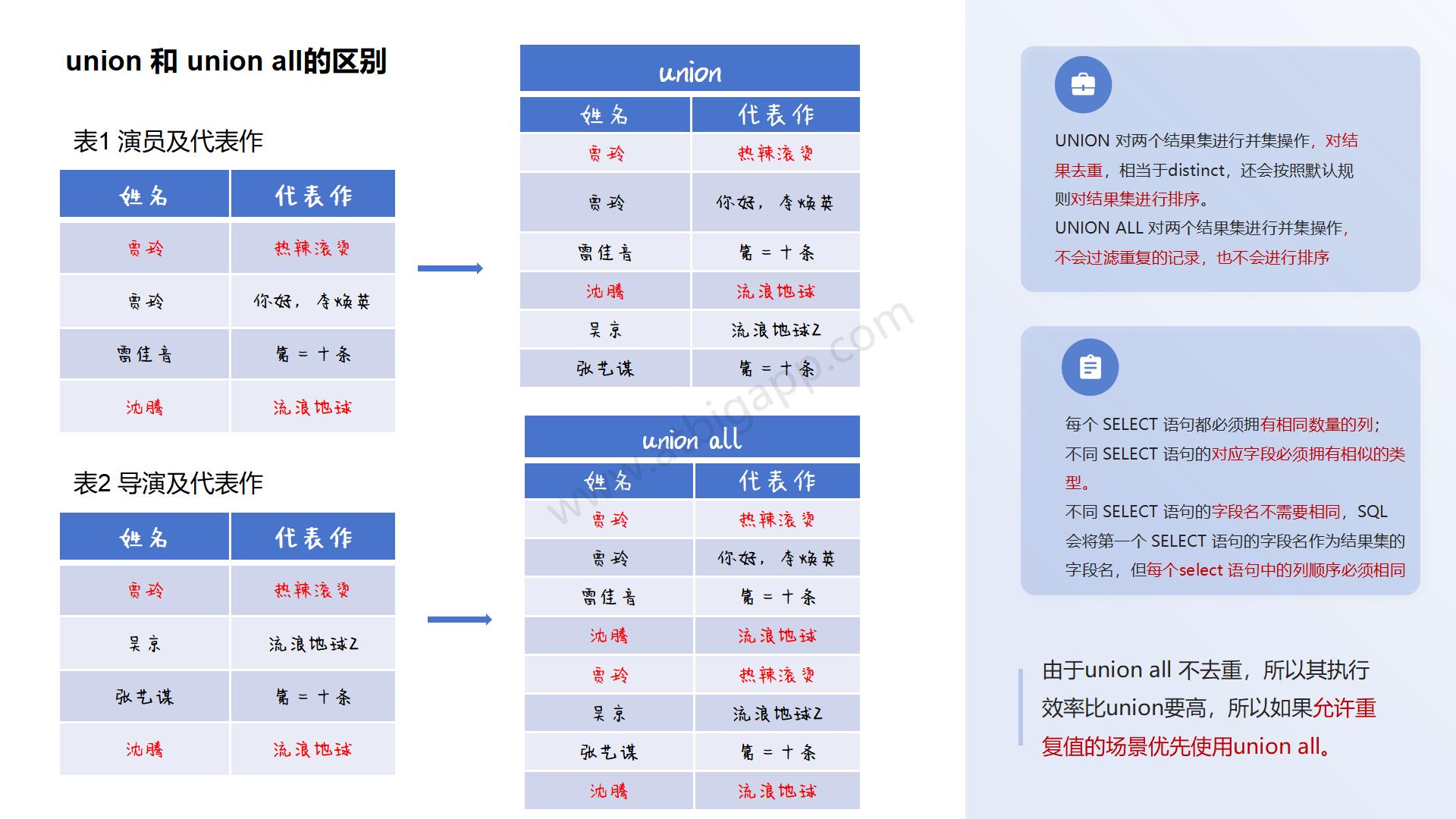
文章目录
- 前言
- 一、Chains
- 二、LLMChain⭐
- 1.LLMChain介绍
- 2.LLMChain案例
- 三、SimpleSequentialChain⭐
- 1.SimpleSequentialChain介绍
- 2.SimpleSequentialChain案例
- 四、SequentialChain⭐
- 1.SequentialChain介绍
- 2.SequentialChain案例
- 五、RouterChain⭐
- 1.RouterChain介绍
- 2.RouterChain案例
- 六、TransformChain⭐
- 1.TransformChain介绍
- 2.TransformChain案例
- 七、文档处理链
- 1.StuffDocumentsChain
- 2.RefineDocumentsChain
- 3.MapReduceDocumentsChain
- 4.MapRerankDocumentsChain
- 八、自定义链
前言
Langchain框架的Chains组件,是构建智能对话与任务式应用的关键。本文聚焦Chains,从基础概念到高级应用全面解析。您将了解LLMChain、SequentialChain等类型,它们如何协同工作以处理复杂任务。通过具体案例,展示Chains在文本处理、流程管理、数据变换中的强大能力。
同时,探讨RouterChain的智能路由决策与TransformChain的数据处理能力,以及文档处理链在信息处理中的独特价值。此外,介绍如何自定义链,满足个性化需求。
一、Chains
Chains 在Langchain中是一个处理单元,负责接收输入数据、执行特定操作并输出结果。 每个Chain可以独立工作,也可以与其他Chain组合,形成复杂的处理流程。这种设计模式使得数据处理变得模块化和可复用,有助于构建高效、灵活且易于维护的应用。
在简单应用中,单独使用LLM是可以的,但更复杂的应用需要将LLM进行链接。例如,我们可以创建一个链,该链接收用户输入,使用PromptTemplate对其进行格式化,然后将格式化后的响应传递给LLM。链允许我们将多个组件组合在一起创建一个单一的、连贯的应用。
四个常用的链:
- LLMChain:一个链,将一个LLM和一个PromptTemplate组合在一起。
- SimpleSequentialChain:一个简单的链,将一个链的输出作为下一个链的输入。
- SequentialChain:一个更复杂的链,允许我们定义多个链,并将它们链接在一起。
- ConversationChain:一个链,将一个LLM和一个ConversationPromptTemplate组合在一起。
二、LLMChain⭐
1.LLMChain介绍
LLMChain 是一个在语言模型周围添加功能的简单链,它被广泛地应用于LangChain中,包括其他链和代理。LLMChain由一个PromptTemplate和一个语言模型(LLM或聊天模型)组成。它接受用户输入,使用PromptTemplate进行格式化,然后将格式化后的响应传递给LLM。
2.LLMChain案例
from langchain_community.llms import Tongyi
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import LLMChain
prompt_template = PromptTemplate.from_template("你是一个大厨,如何制作{food_name}?")
model = Tongyi()
chain = LLMChain(llm=model, prompt=prompt_template,verbose=True)
ret = chain.invoke({"food_name": "烤鱼"})
print(ret)

三、SimpleSequentialChain⭐
1.SimpleSequentialChain介绍
SimpleSequentialChain 是Langchain框架中的一种顺序链类型,它的主要特点是每个步骤都具有单一输入/输出,并且一个步骤的输出是下一个步骤的输入。
2.SimpleSequentialChain案例
from langchain_community.llms import Tongyi
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.chains import SimpleSequentialChain
llm = Tongyi()
# 第一个链
prompt_template1 = PromptTemplate.from_template("使下面文本{text}转成小写")
chain_1 = LLMChain(llm=llm, prompt=prompt_template1, verbose=True)
# 第二个链
prompt_template2 = PromptTemplate.from_template("只去掉{text_x}文本中的标点符号,然后输出转换后的文本,其他任何内容都不要改变")
chain_2 = LLMChain(llm=llm, prompt=prompt_template2, verbose=True)
# 构造 SimpleSequentialChain
chain_ss = SimpleSequentialChain(chains=[chain_1, chain_2], verbose=True)
ret = chain_ss.invoke("Hello,World!!!")
print(ret)


四、SequentialChain⭐
1.SequentialChain介绍
SequentialChain 是LangChain库中的一个重要概念,它允许用户将多个链(Chain)按照特定的顺序连接起来,形成一个处理流程。
对比:
SimpleSequentialChain:这是SequentialChain的最简单形式,其中每个步骤都具有单一输入/输出,并且一个步骤的输出是下一个步骤的输入。SequentialChain:更通用形式的顺序链,允许多个输入/输出,可以处理更复杂的场景。
2.SequentialChain案例
# SequentialChain
from langchain.chains.llm import LLMChain
from langchain_community.llms import Tongyi
from langchain.prompts import ChatPromptTemplate
from langchain.chains.sequential import SequentialChain
llm = Tongyi()
#chain 1 任务:翻译成中文
first_prompt = ChatPromptTemplate.from_template("把下面内容翻译成中文:\n\n{content}")
chain_one = LLMChain(
llm=llm,
prompt=first_prompt,
verbose=True,
output_key="Chinese_Rview",
)
#chain 2 任务:对翻译后的中文进行总结摘要 input_key是上一个chain的output_key
second_prompt = ChatPromptTemplate.from_template("用一句话总结下面内容:\n\n{Chinese_Rview}")
chain_two = LLMChain(
llm=llm,
prompt=second_prompt,
# verbose=True,
output_key="Chinese_Summary",
)
#chain 3 任务:智能识别语言 input_key是上一个chain的output_key
third_prompt = ChatPromptTemplate.from_template("下面内容是什么语言:\n\n{Chinese_Summary}")
chain_three = LLMChain(
llm=llm,
prompt=third_prompt,
# verbose=True,
output_key="Language",
)
#chain 4 任务:针对摘要使用指定语言进行评论 input_key是上一个chain的output_key
fourth_prompt = ChatPromptTemplate.from_template("请使用指定的语言对以下内容进行回复:\n\n内容:{Chinese_Summary}\n\n语言:{Language}")
chain_four = LLMChain(
llm=llm,
prompt=fourth_prompt,
verbose=True,
output_key="Reply",
)
#overall 任务:翻译成中文->对翻译后的中文进行总结摘要->智能识别语言->针对摘要使用指定语言进行评论
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four],
verbose=True,
input_variables=["content"],
output_variables=["Chinese_Rview", "Chinese_Summary", "Language"],
)
content = "I am a student of Cumulus Education, my course is artificial intelligence, I like this course, because I can get a high salary after graduation"
overall_chain.invoke(content)

五、RouterChain⭐
路由链(RouterChain) 在LangChain框架中扮演着重要的角色,它主要用于根据输入的Prompt选择并执行具体的某个链。 这种机制在处理具有不确定性和多样性的输入时尤为有效,能够灵活地根据输入内容路由到最合适的处理链上。
1.RouterChain介绍
路由链(RouterChain) 是由LLM(大语言模型)根据输入的Prompt去选择具体的某个链。 在路由链中,一般会存在多个Prompt,这些Prompt结合LLM的推理能力来决定下一步应该选择哪个链进行处理。
路由链的组成:
路由链一般涉及到两个核心类:LLMRouterChain和MultiPromptChain。
LLMRouterChain:使用LLM(大语言模型)来路由到可能的选项中。它接收用户输入,通过Prompt的形式让大语言模型进行推理,从而决定下一步应该选择哪个链。MultiPromptChain:该链用于在多个提示词之间路由输入。当你有多个提示词并且只想路由到其中一个时,可以使用这个链。它负责构建多提示词和RouterChain,选择下一个要调用的链,并处理路由逻辑。
2.RouterChain案例
# RouterChain
from langchain.chains.llm import LLMChain
from langchain_community.llms import Tongyi
llm = Tongyi()
from langchain.prompts import PromptTemplate
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
from langchain.chains.router import MultiPromptChain
#物理链
physics_template = """您是一位非常聪明的物理教授.\n
您擅长以简洁易懂的方式回答物理问题.\n
当您不知道问题答案的时候,您会坦率承认不知道.\n
下面是一个问题:
{input}"""
physics_prompt = PromptTemplate.from_template(physics_template)
## 物理的任务
physicschain = LLMChain( llm=llm,prompt=physics_prompt)
#数学链
math_template = """您是一位非常优秀的数学教授.\n
您擅长回答数学问题.\n
您之所以如此优秀,是因为您能够将困难问题分解成组成的部分,回答这些部分,然后将它们组合起来,回答更广泛的问题.\n
下面是一个问题:
{input}"""
math_prompt = PromptTemplate.from_template(math_template)
##数学的任务
mathschain = LLMChain(llm=llm, prompt=math_prompt,)
# 默认任务
default_chain = ConversationChain(
llm = llm,
output_key="text"
)
# 组合路由任务
destination_chains = {}
destination_chains["physics"] = physicschain
destination_chains["math"] = mathschain
# 定义路由Chain
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations="physics:擅长回答物理问题\n math:擅长回答数学问题")
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser()
)
router_chain = LLMRouterChain.from_llm(
llm,
router_prompt
)
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True
)
question = "什么是牛顿第一定律?"
print(router_chain.invoke(question))
print(chain.run(question))
# question = "2+2等于几?"
# print(router_chain.invoke(question))
# print(chain.run("2+2等于几?"))


六、TransformChain⭐
TransformChain 的核心功能是将给定的数据按照某个特定的函数进行转换,然后将转换后的结果输出给LLM。 这使得在将数据发送给LLM之前,可以根据需要对数据进行各种操作,如替换字符串、截取文本等。
1.TransformChain介绍
TransformChain 允许用户定义自定义的转换函数,这些函数可以应用于chains之间的数据。这意味着,当数据从一个chain传递到另一个chain时,TransformChain可以提供一个或多个转换步骤,以修改或格式化数据,使其符合下一个chain的输入要求。
2.TransformChain案例
下面的例子是创建一个虚拟转换,它接收一个超长的文本,将文本过滤为仅保留第三个段落,然后将其传递给 LLMChain 进行摘要生成。
# TransformChain --- 通用的转换链
from langchain.chains.llm import LLMChain
from langchain_community.llms import Tongyi
llm = Tongyi()
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.chains.transform import TransformChain
from langchain.chains.sequential import SimpleSequentialChain
# 第一个任务
def transform_func(inputs:dict) -> dict:
text = inputs["text"]
shortened_text = "\n".join(text.split("\n")[3:4])
return {"output_text":shortened_text}
# 1.创建转换链实例
transform_chain = TransformChain(
input_variables=["text"],
output_variables=["output_text"],
transform=transform_func
)
# 第二个任务
template = """对下面的文字进行总结:
{output_text}
总结:"""
# 创建提示词模板
prompt = PromptTemplate(
input_variables=["output_text"],
template=template
)
llm_chain = LLMChain(
llm = Tongyi(),
prompt=prompt
)
#使用顺序链连接起来
squential_chain = SimpleSequentialChain(
chains=[transform_chain,llm_chain],
verbose=True
)
with open("news.txt",encoding='utf-8') as f:
letters = f.read()
squential_chain.invoke(letters)

七、文档处理链
1.StuffDocumentsChain
StuffDocumentsChain 是LangChain框架中的一个关键组件,用于处理文档并将其内容整合成单一提示(prompt),再传递给大语言模型(LLM)以获取答案或响应。该组件在文档处理任务中尤为重要,尤其是在需要将多个文档内容作为一个整体输入给LLM时。
核心特点:
- 整合文档: 能够将多个文档的内容整合成一个单一的提示,简化与大模型的交互。
- 保持上下文: 确保LLM在处理时能够考虑到多个文档之间的上下文关系,从而提高回答的准确性和相关性。
- 高效利用: 减少调用LLM的次数,因为所有相关文档内容都整合在一个提示中。
适用场景:
- 当需要处理多个相互关联的文档,并将它们作为整体输入给LLM进行摘要、问答等任务时。
- 文档拆分较小、一次处理的文档数量较少的场景,以避免超出LLM的token限制。
注意事项:
- 需要注意文档的数量和长度,避免超出LLM的上下文窗口限制,这可能导致信息丢失或模型性能下降。
- 在处理大量或长篇文档时,可能需要考虑文档分割或简化的策略。
协同工作:
StuffDocumentsChain通常与其他LangChain组件(如LLM加载器、文档加载器等)一起使用,构建完整的文档处理流程。 这种协同工作确保了从文档加载到最终答案生成的整个流程能够顺畅进行。
总之,StuffDocumentsChain通过其独特的文档整合能力,为LangChain框架中的文档处理任务提供了高效、简洁的解决方案,同时确保了上下文的完整性和与大模型交互的便利性。
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
from langchain_community.document_loaders import PyPDFLoader,TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.llms import Tongyi
llm = Tongyi()
# 1 定义prompt模板
prompt_template = """对以下文字做简洁的总结:{text}"""
prompt = PromptTemplate.from_template(prompt_template)
# 2 定义任务
llm_chain = LLMChain(llm=llm, prompt=prompt)
# 3、定义chain
stuff_chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_variable_name="text",
)
loader = TextLoader("news.txt",encoding='utf-8')
docs = loader.load()
print(stuff_chain.run(docs))
其中,news.txt 为 爬虫爬取到的一些新闻

2.RefineDocumentsChain
RefineDocumentsChain是LangChain框架中的一个关键组件,旨在通过顺序和迭代的方式处理多个文档,以生成一个综合了所有文档信息的更准确、全面的答案。以下是该组件的总结:
基本概念
- 作用: 基于多个文档生成一个综合答案,通过迭代方式不断改进答案质量。
- 使用场景: 适用于需要综合多个文档信息来回答复杂问题的场景,如问答系统。
工作原理
- 初始处理: 首先处理第一个文档,生成初始答案。
- 迭代处理: 随后,按顺序处理剩余的每个文档。每次处理时,将当前文档的内容和之前生成的答案作为上下文,生成新的答案。这个过程不断重复,直到所有文档都被处理。
- 信息传递: 在处理每个文档时,都会考虑之前文档的内容和结果,确保生成的答案能够综合所有文档的信息。
优点
- 准确性: 通过综合多个文档的信息,生成的答案通常更准确、全面。
- 可解释性: 顺序和迭代的处理过程使得答案的生成过程更加透明,易于理解和解释。
注意事项
- 文档数量: 虽然可以处理多个文档,但文档数量过多可能导致处理时间增加。因此,在实际应用中可能需要考虑文档筛选或合并。
- 上下文窗口限制: 受到大模型上下文窗口大小的限制,如果文档总长度超过此限制,可能需要分割文档或采用其他方法处理。
RefineDocumentsChain通过其独特的迭代和顺序处理方式,为处理多个文档并生成综合答案提供了一种高效、准确的方法。
示例:
假设有一个问答系统,用户的问题涉及三个文档A、B和C。使用RefineDocumentsChain处理这些文档时,首先基于文档A生成初始答案。然后,在处理文档B时,会将文档B的内容和之前生成的答案作为上下文,生成一个新的答案。最后,在处理文档C时,同样会将文档C的内容和之前生成的答案作为上下文,生成最终的答案。这样,最终的答案就能够综合文档A、B和C的信息。
from langchain.chains.combine_documents.refine import RefineDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
from langchain_community.document_loaders import PyPDFLoader, TextLoader
from langchain_community.llms.tongyi import Tongyi
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
llm = Tongyi()
# 加载问答
# loader = PyPDFLoader("doc/demo.pdf")
loader = TextLoader("news.txt",encoding='utf-8')
docs = loader.load()
#split
text_splitter = CharacterTextSplitter(separator="\n",chunk_size=400, chunk_overlap=0)
split_docs = text_splitter.split_documents(docs)
print(split_docs)
prompt_template = """对以下文字做简洁的总结:
{text}
简洁的总结:"""
prompt = PromptTemplate.from_template(prompt_template)
refine_template = (
"你的任务是产生最终摘要\n"
"我们已经提供了一个到某个特定点的现有回答:{existing_answer}\n"
"我们有机会通过下面的一些更多上下文来完善现有的回答(仅在需要时使用).\n"
"------------\n"
"{text}\n"
"------------\n"
"根据新的上下文,用中文完善原始回答.\n"
"如果上下文没有用处,返回原始回答。"
)
refine_prompt = PromptTemplate.from_template(refine_template)
chain = load_summarize_chain(
llm=llm,
chain_type="refine",
question_prompt=prompt,
refine_prompt = refine_prompt,
return_intermediate_steps=True,
input_key = "documents",
output_key = "output_text",
)
result = chain.invoke({"documents":split_docs})
print("result:\n",result)
print('result["output_text"]:\n',result["output_text"])
print('result["intermediate_steps"][:3]',"\n\n".join(result["intermediate_steps"][:3]))

3.MapReduceDocumentsChain
MapReduceDocumentsChain 是LangChain框架中的一个高效处理大规模文档数据的组件,它借鉴了MapReduce的并行处理思想,并结合了大型语言模型(LLM)的文档处理能力。以下是关键点总结:
基本概念
- 作用: 用于处理大量文档,通过并行处理提高效率,并通过简化和聚合生成综合结果。
- 使用场景: 适用于文档数量众多且可以分割成独立部分进行并行计算的场景。
工作原理
Map阶段:
- 将文档集合分割成多个块,每块独立并行处理。
- 使用LLM对每个文档块进行处理,提取关键信息或生成初步结果。
Reduce阶段:
- 收集Map阶段的所有初步结果。
- 通过ReduceDocumentsChain或其他组件对结果进行简化、聚合或进一步处理。
- 最终生成包含所有文档信息的综合输出。
优点
- 并行处理: 显著提高处理大规模文档数据的效率。
- 简化文档: 将复杂文档简化为更易处理的格式。
- 灵活性: 可与其他LangChain组件结合,构建复杂处理流程。
注意事项
- 文档数量: 处理极大量文档时,需考虑更高效的分割和并行策略。
- 上下文窗口限制: 避免信息丢失,可能需要分块处理过长文档或文档集合。
与其他组件的协同
LLM:依赖LLM进行文档处理,LLM的选择和配置影响性能和效果。ReduceDocumentsChain:Reduce阶段常用此组件简化和聚合初步结果,其选择和配置影响最终输出的质量和准确性。
总之,MapReduceDocumentsChain是一个结合MapReduce并行处理和LLM文档处理能力的强大组件,适用于处理大规模、复杂的文档数据,能够显著提高处理效率和结果质量。
from langchain.chains.combine_documents.map_reduce import MapReduceDocumentsChain
from langchain.chains.combine_documents.reduce import ReduceDocumentsChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.prompts import PromptTemplate
from langchain_community.llms.tongyi import Tongyi
from langchain.chains.llm import LLMChain
from langchain_community.document_loaders import PyPDFLoader,TextLoader
from langchain.text_splitter import CharacterTextSplitter
llm = Tongyi()
#load pdf
# loader = PyPDFLoader("doc/demo.pdf")
loader = TextLoader("news.txt",encoding='utf-8')
docs = loader.load()
text_splitter = CharacterTextSplitter(separator="\n",chunk_size=400, chunk_overlap=0)
split_docs = text_splitter.split_documents(docs)
#map chain
map_template = """对以下文字做简洁的总结:
"{content}"
简洁的总结:"""
map_prompt = PromptTemplate.from_template(map_template)
# 定义任务
map_chain = LLMChain(
llm=llm, #llm
prompt=map_prompt,
)
#reduce chain
reduce_template = """以下是一个摘要集合:
{doc_summaries}
将上述摘要与所有关键细节进行总结.
总结:"""
reduce_prompt = PromptTemplate.from_template(reduce_template)
# 定义reduce任务
reduce_chain = LLMChain(
prompt=reduce_prompt,
llm=llm,
)
# stuff chain
stuff_chain = StuffDocumentsChain(
llm_chain=reduce_chain,
document_variable_name="doc_summaries",
)
# reduce chain
reduce_final_chain = ReduceDocumentsChain(
combine_documents_chain=stuff_chain,
#超过4000个token就会切入到下一个stuff_chain
collapse_documents_chain=stuff_chain,
token_max=4000,
)
# map reduce chain
map_reduce_chain = MapReduceDocumentsChain(
llm_chain=map_chain,
document_variable_name="content",
reduce_documents_chain=reduce_final_chain,
)
# 默认使用了hugging face上的 GPT-2 模型,下载有问题会报错
summary = map_reduce_chain.invoke(split_docs)
print(summary)
4.MapRerankDocumentsChain
MapRerankDocumentsChain 和 MapReduceDocumentsChain 类似,先通过 LLM 对每个 document 进行处理,每个答案都会返回一个 score,最后选择 score 最高的答案。MapRerank 和 MapReduce 类似,会大批量的调用 LLM,每个 document 之间是独立处理。
from langchain.chains.combine_documents.map_reduce import MapReduceDocumentsChain
from langchain.chains.combine_documents.reduce import ReduceDocumentsChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.prompts import PromptTemplate
from langchain_community.llms.tongyi import Tongyi
from langchain.chains.llm import LLMChain
from langchain_community.document_loaders import PyPDFLoader,TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
#load
# loader = PyPDFLoader("doc/demo.pdf")
llm = Tongyi()
loader = TextLoader("news.txt",encoding='utf-8')
docs = loader.load()
#split
text_splitter = CharacterTextSplitter(separator="\n",chunk_size=200, chunk_overlap=0)
split_docs = text_splitter.split_documents(docs)
chain = load_qa_with_sources_chain(
llm,
chain_type="map_rerank",
metadata_keys=['source'],
return_intermediate_steps=True
)
# print(chain)
query = "中文回答这篇文章的主要内容是什么?"
result = chain.invoke({"input_documents":split_docs,"question":query})
print(result)

八、自定义链
示例代码自定义了一个名为 wiki_article_chain 的类,它继承自 Chain 类,用于开发一个维基百科文章生成器。这个类利用了一个语言模型(BaseLanguageModel)和一个提示模板(BasePromptTemplate)来生成文章。
from typing import List, Dict, Any, Optional
from langchain.callbacks.manager import CallbackManagerForChainRun
from langchain.chains.base import Chain
from langchain.prompts.base import BasePromptTemplate
from langchain.base_language import BaseLanguageModel
class wiki_article_chain(Chain):
"""开发一个wiki文章生成器"""
prompt: BasePromptTemplate
llm: BaseLanguageModel
out_key: str = "text"
@property
def input_keys(self) -> List[str]:
"""将返回Prompt所需的所有键"""
return self.prompt.input_variables
@property
def output_keys(self) -> List[str]:
"""将始终返回text键"""
return [self.out_key]
def _call(
self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Dict[str, Any]:
"""运行链"""
prompt_value = self.prompt.format_prompt(**inputs)
# print("prompt_value:",prompt_value)
response = self.llm.generate_prompt(
[prompt_value], callbacks=run_manager.get_child() if run_manager else None
)
# print("response:",response)
if run_manager:
run_manager.on_text("wiki article is written")
return {self.out_key: response.generations[0][0].text}
@property
def _chain_type(self) -> str:
"""链类型"""
return "wiki_article_chain"
from langchain_community.llms import Tongyi
from langchain.prompts import PromptTemplate
llm = Tongyi()
prompt = PromptTemplate(
template="写一篇关于{topic}的维基百科形式的文章",
input_variables=["topic"]
)
chain = wiki_article_chain(
llm=llm,
prompt=prompt
)
# chain.run(topic="人工智能")
ret = chain.invoke({"topic": "人工智能"})
print(ret)
# 使用invoke方法时提供了更多的灵活性,因为它允许你动态地构建输入字典,并在需要时添加或修改键值对。
# 而run方法则更适合于输入参数已知且固定的情况。