注:源码在最后,只是一次实验记录,不合理的地方自行修改。
一 研究背景及意义
21世纪以来,随着科学技术的进步,人们的生活水平也随之大幅提升提高。在科技和经济快速发展下,全球已经进入了大数据时代。大数据背景下人们日常生活中产生的数据与以往的数据不同,这些数据有着体量(Volume)大、速度(Velocity)快、多样性(Variety)、价值(Value)和真实性(Veracity)五个特点,这些海量数据已经成为重要的数据资源。然而面对着爆发式增长的数据,人们也发现了其复杂性日益突出,如当个数据价值量低,整体数据价值高等问题。采用传统的人工数据处理方式不仅需要大量的人力及时间成本,而且难以应对日益复杂的数据变化。
在大数据背景下,商业数据已然成为不可或缺的数据资源。得益于计算机技术的日益强大,计算机能够捕捉到的商业数据也越来越多。如何利用好这些数据成为了众多学者研究的关注焦点。本文以牛油果销售数据可视化分析为例,探索基于Python语言技术对牛油果销售数据进行可视化分析为商业领域解决数据分析难题提出新方法。
二 相关理论基础
2.1 数据可视化
数据可视化是将数据以图形化的方式呈现,通过图表、图像或其他视觉元素,将抽象的数据转化为直观的形式,以便用户更容易理解和分析。其通过视觉化手段揭示数据之间的模式、趋势和关系,帮助研究者发现数据背后的深层含义和洞察数据之间的联系。数据可视化技术的进步不仅提高了数据分析的效率和准确性,也促进了信息的共享和理解,成为现代数据驱动决策和研究的重要支柱。
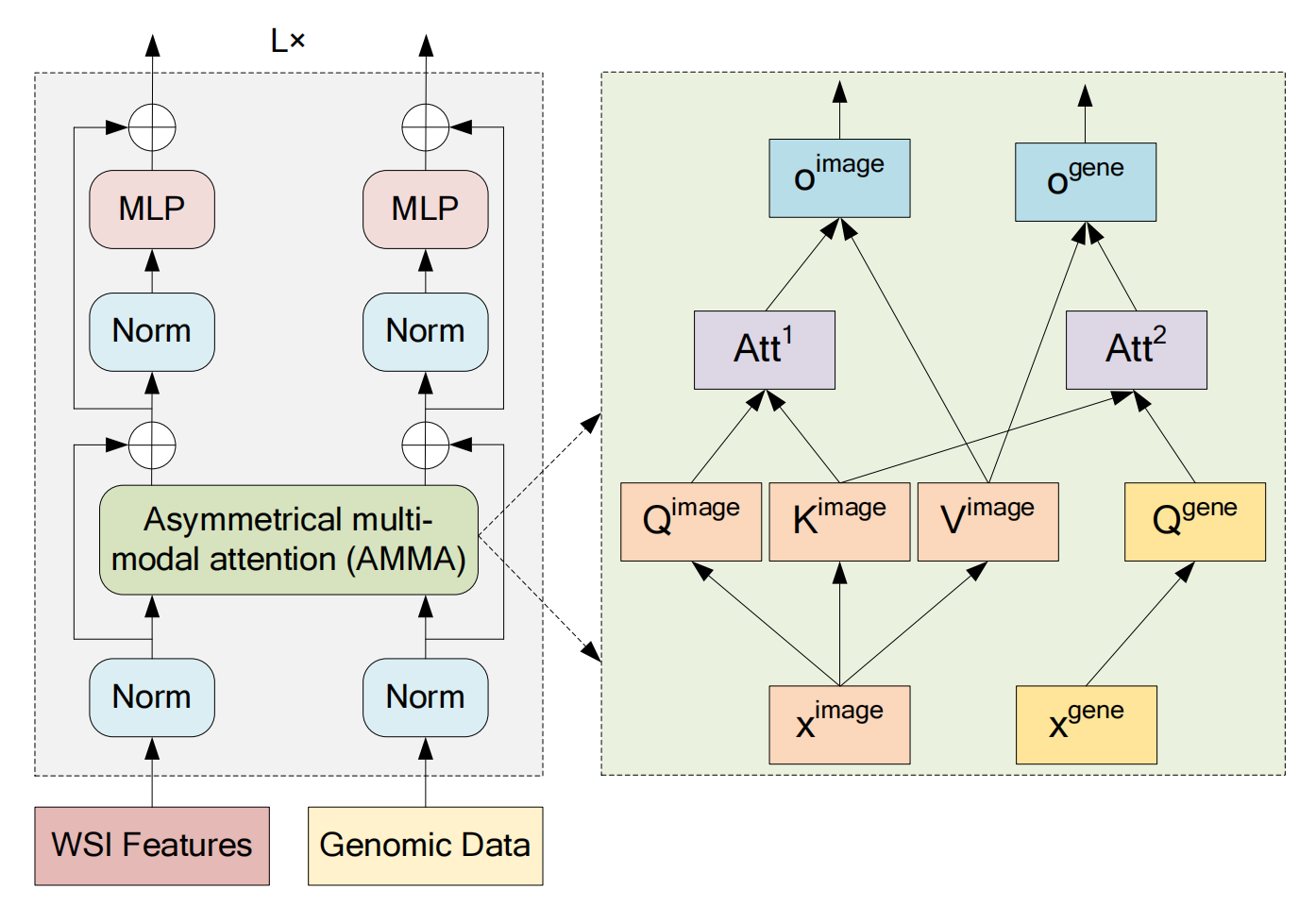
三 可视化实验设计
3.1 数据集简介
本文实验数据集来源于Kaggle数据集,数据地址:
https://www.kaggle.com/datasets/neuromusic/avocado-prices。
为2015-2018 年牛油果价格和销量,该数据于2018年5月从Hass Avocado Board网站收集而来。通过对2015年至2018年3月全美牛油果零售量和价格进行扫描,收集了18249条实验数据。每条记录由14个特征变量。
3.2 实验环境搭建
3.2.1 实验环境配置
本文实验主要涉及到牛油果价格和销量数据可视化的开发,在采用实验的方式,实验采用的电脑设备为Windows操作系统。实验环境采用了 Pyhton 编程语言以及相关的机器学习框架,实验平台为conda 23.7.4。相关系数如表3-1所示:
表3-1实验环境的相关系数
| 设备 | 电脑 配置参数 |
| 操作系统 | Windows |
| 内存 | 16G |
| CPU型号 | Intel(R) Core(TM) i5-10200H CPU @ 2.40GHz |
| GPU型号 | NVIDIA GeForce GTX 1650 |
| 硬盘 | 系统盘:512 GB 机械硬盘:1T |
| 开发语言 | Python 3.9.19 |
| 实验平台 | conda 23.7.4 |
3.3可视化分析实验设计
3.3.1数据读取
导入实验使用所需包。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import warnings
import datetime
import scipy
import jinja2
from sklearn.preprocessing import LabelEncoder
from scipy import stats
from scipy.stats import *
warnings.filterwarnings('ignore')
sns.set_style('whitegrid')
plt.rcParams['figure.dpi'] = 100读取实验数据,并且查看有关数据集的一些基本信息,读取结果如图3.1所示:
df = pd.read_csv(r'C:\\Users\\leglon\\Desktop\\牛油果\\avocado.csv')
#显示前五行
#df.head()
df.head().style.background_gradient(cmap='Greens').set_properties(**{'font-family': 'Segoe UI'}).hide_index()
图3.1 读取到的数据集前5行信息
查看数据基本信息,对特征信息进行输出,如图3.2所示:
#查看数据基本信息
df.info()
图3.2数据基本信息图
3.3.2 数据预处理
数据预处理在数据分析和机器学习中是一项至关重要的步骤,它涉及去除或修正数据中的错误、缺失值和噪音,以确保数据的准确性、完整性和一致性。这个过程不仅仅是简单的数据清洗,更是为了优化数据以便后续分析和建模能够达到更高的效果和准确度。对实验数据进行查找是否有缺失值,如图3.3所示:
#查看是否有缺失值
df.isnull().sum()
图3.3缺失值查找
从输出结果来看,此数据完好,没有任何缺失值。
3.3.3总销量与平均价格可视化
将总销量和平均价格进行可视化有助于深入理解牛油果的销售市场表现,如图3.4所示:
# 绘制散点图,总销量对比平均价格
fig, ax = plt.subplots()
ax.scatter(df['Total Volume'],df['AveragePrice'])
ax.set_title('Price and Volume')
ax.set_xlabel('Total Volume')
ax.set_ylabel('AveragePrice')
图3.4 总销量和平均价格进行可视化
从图3.4中,通过可视化分析得出平均价格在0.5到1.0之间的总销售额最高。
3.3.4 对4046、4225和4770进行可视化分析
通过对4046、4225和4770进行可视化分析,可以直观地看到三个无名类型的具体数值,方便分析。其可视化如图3.5所示:
# 每个类型唯一值的数量
unique_counts = [df['4046'].nunique(), df['4225'].nunique(), df['4770'].nunique()]
plu_codes = ['4046', '4225', '4770']
barplot = sns.barplot(x=plu_codes, y=unique_counts, palette='viridis')
plt.title('Number of Unique Values for Codes')
plt.xlabel('Codes')
plt.ylabel('Number of Unique Values')
#在条形图的顶部添加数据值
for i, count in enumerate(unique_counts):
barplot.text(i, count + 0.1, str(count), ha='center', va='bottom')
plt.show()
图3.5 4046、4225和4770可视化分析图
3.3.4 聚类可视化
聚类可视化分析能够帮助识别数据中的潜在模式和结构,通过将相似的数据点组成簇展示出来,帮助快速理解数据集的复杂性和内在关系。牛油果销售数据聚类可视化代码如图3.6所示,可视化结果如图3.6所示:
#聚类分析
colors = {'conventional': 'blue', 'organic': 'yellow'}
numerical_cols = df.select_dtypes(include=['float64', 'int64']).columns
fig = plt.figure(figsize=(16, 6 * len(numerical_cols)))
for i, col in enumerate(numerical_cols):
ax1 = fig.add_subplot(len(numerical_cols), 3, i + 1)
for avocado_type, color in colors.items():
mask = df['type'] == avocado_type
ax1.scatter(df.loc[mask, col], df.loc[mask, 'AveragePrice'], c=color, label=avocado_type)
ax1.set_xlabel(col)
ax1.set_ylabel('Average Price ($)')
ax1.set_title(f'Relationship between {col} and Average Price')
ax1.grid()
ax1.legend()
plt.tight_layout()
plt.show()
图3.6 牛油果销售数据聚类可视化结果图
3.3.5 conventional和organic占比与平均价格可视化
conventional和organic产品占比与其平均价格进行可视化,展示出conventional和organic产品在市场中的占比变化和价格,可以帮助理解消费者偏好的变化和市场的发展趋势。其可视化结果如图3.7,从图中可以看出organic产品更加受欢迎。
# 计算每种牛油果的平均价格和占比
avg_price_conventional = df[df['type']=='conventional']['AveragePrice'].mean()
avg_price_organic = df[df['type']=='organic']['AveragePrice'].mean()
avg_price_df = pd.DataFrame({'Type': ['Conventional', 'Organic'], 'Average Price': [avg_price_conventional, avg_price_organic]})
fig = px.pie(avg_price_df, names='Type', values='Average Price', hole=0.055, color_discrete_sequence=px.colors.qualitative.Set2)
fig.update_traces(textposition='inside', textinfo='percent+label')
fig.update_layout(title='Average Avocado Price by Type')
fig.show()
图3.7 不同性别在不同型号上的购物情况可视化图
3.3.6不同地区的销售情况可视化
通过分析和可视化展示不同地区的销售情况可视化可以直观地比较不同地区的销售量、销售额或市场份额。有助于识别出销售表现较好和较差的地区,并分析出现这些差异的原因。并且对高销售量的地区,企业可以优化资源分配,加大对这些地区的市场推广力度。不同地区的销售情况可视化如图3.8所示:
# 按“地区”分组,并计算每个地区的平均“平均价格”
region_means = df.groupby('region')['AveragePrice'].mean()
colors = px.colors.qualitative.Set2
fig = px.pie(values=region_means, names=region_means.index, color=region_means.index, color_discrete_sequence=colors)
fig.update_traces(textposition='inside', textinfo='percent+label')
#fig.update_layout(title='Average Avocado Prices by Region (Conventional vs. Organic)')
fig.show()
图3.8 不同地区的销售情况可视化图
3.3.7 各种包类型的占比可视化
通过图3.9对各种包类型的占比可视化,看出Small Bags类型的牛油果包装最受欢迎,帮助企业可以了解到那种类型的产品售卖较好,哪种较差。
# 计算所有行中每种包类型的占比
total_small_bags = df['Small Bags'].sum()
total_large_bags = df['Large Bags'].sum()
total_xlarge_bags = df['XLarge Bags'].sum()
sizes = [total_small_bags, total_large_bags, total_xlarge_bags]
labels = ['Small Bags', 'Large Bags', 'XLarge Bags']
colors = ['lightcoral', 'lightskyblue', 'lightgreen']
plt.figure(figsize=(4, 4))
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=140)
plt.title('Distribution of Bag Types')
plt.show()
图3.9 各种包类型的占比可视化
3.3.8 平均价格的波动频率可视化
# 可视化平均价格的波动频率
plt.figure(figsize=(10, 6))
plt.hist(df['AveragePrice'], bins=20,color='orange')
plt.xlabel('Average Price ($)')
plt.ylabel('Frequency')
plt.title('Distribution of Average Avocado Prices')
图3.10不同季节下各商品种类的销售情况可视化图
如图3.10,对平均价格的波动频率可视化展示,有助于识别市场趋势、发现异常波动、支持风险管理、优化投资策略,并为企业和工作人员提供决策依据,帮助更好地理解价格行为和市场动态。从图中可以看出平均价格在1.0到1.5之间上升最高。
3.3.9 各因素随时间变化情况可视化
如下图3.11各因素随时间变化情况可视化所示,通过对各类型因素随时间变化情况可视化能够直观展示数据的动态趋势,帮助识别周期性模式和异常变化,为预测未来发展、制定决策和优化策略提供有力支持,同时便于沟通复杂信息,使得分析结果更易于理解和应用。
#平均价格、销售量、总的包类型和各种型号的包装类型随时间的售卖情况
df['Date'] = pd.to_datetime(df['Date'])
l1 = ['AveragePrice', 'Total Volume', 'Total Bags','Small Bags','Large Bags','XLarge Bags']
fig, ax = plt.subplots(nrows=3, ncols=1, figsize=(20, 15))
for i in range(len(l1)):
plt.subplot(6, 1, i+1)
sns.lineplot(x='Date', y=l1[i], data=df)
title = l1[i] + ' vs Date'
plt.title(title)
plt.xlabel('Date')
plt.ylabel(l1[i])
plt.tight_layout()
plt.show()
图3.11各因素随时间变化情况可视化结果图
四 总结与展望
随着大数据时代的到来,商业数据的分析和利用变得尤为重要。本文通过对牛油果销售数据的可视化分析,展示了如何运用数据可视化技术来挖掘和理解数据中的潜在模式和趋势。
首先,通过对牛油果销售数据的分析,我们能够深入了解不同类型牛油果的销售情况、价格波动、地区差异以及消费者偏好等关键因素。从总销量和平均价格的可视化分析,发现了价格与销量之间的相关性;对不同类型牛油果(如4046、4225和4770)的详细分析,识别出不同品类的市场表现;聚类分析则揭示了数据中的潜在模式,为市场细分和精准营销提供了依据。对conventional和organic产品的占比与价格分析,显示出消费者对有机产品的偏好变化。对不同地区的销售情况分析,为企业优化市场策略和资源分配提供了重要参考等。
其次,本文采用了Python编程语言和相关的可视化框架,展示了其在商业数据可视化分析中的应用,也为后续研究和实际应用提供了技术支持和方法论参考。
综上所述,数据可视化为商业数据分析提供了强大的工具和方法,通过不断创新和优化,我们可以更好地挖掘数据价值,助力商业决策和市场发展。
五 源码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import warnings
import datetime
import scipy
import jinja2
from sklearn.preprocessing import LabelEncoder
from scipy import stats
from scipy.stats import *
warnings.filterwarnings('ignore')
sns.set_style('whitegrid')
plt.rcParams['figure.dpi'] = 100
df = pd.read_csv(r'C:\\Users\\leglon\\Desktop\\牛油果\\avocado.csv')
#显示前五行
#df.head()
df.head().style.background_gradient(cmap='Greens').set_properties(**{
'font-family': 'Segoe UI'}).hide_index()
#查看数据基本信息
df.shape
#查看数据基本信息
df.info()
#查看是否有缺失值
df.isnull().sum()
# 绘制散点图,总销量对比平均价格
fig, ax = plt.subplots()
ax.scatter(df['Total Volume'],df['AveragePrice'])
ax.set_title('Price and Volume')
ax.set_xlabel('Total Volume')
ax.set_ylabel('AveragePrice')
# 每个类型唯一值的数量
unique_counts = [df['4046'].nunique(), df['4225'].nunique(),
df['4770'].nunique()]
plu_codes = ['4046', '4225', '4770']
barplot = sns.barplot(x=plu_codes, y=unique_counts, palette='viridis')
plt.title('Number of Unique Values for Codes')
plt.xlabel('Codes')
plt.ylabel('Number of Unique Values')
#在条形图的顶部添加数据值
for i, count in enumerate(unique_counts):
barplot.text(i, count + 0.1, str(count), ha='center', va='bottom')
plt.show()
#聚类分析
colors = {'conventional': 'blue', 'organic': 'yellow'}
numerical_cols = df.select_dtypes(include=['float64',
'int64']).columns
fig = plt.figure(figsize=(16, 6 * len(numerical_cols)))
for i, col in enumerate(numerical_cols):
ax1 = fig.add_subplot(len(numerical_cols), 3, i + 1)
for avocado_type, color in colors.items():
mask = df['type'] == avocado_type
ax1.scatter(df.loc[mask, col], df.loc[mask, 'AveragePrice'],
c=color, label=avocado_type)
ax1.set_xlabel(col)
ax1.set_ylabel('Average Price ($)')
ax1.set_title(f'Relationship between {col} and Average Price')
ax1.grid()
ax1.legend()
plt.tight_layout()
plt.show()
# 计算每种牛油果的平均价格和占比
avg_price_conventional =
df[df['type']=='conventional']['AveragePrice'].mean()
avg_price_organic = df[df['type']=='organic']['AveragePrice'].mean()
avg_price_df = pd.DataFrame({'Type': ['Conventional', 'Organic'],
'Average Price': [avg_price_conventional, avg_price_organic]})
fig = px.pie(avg_price_df, names='Type', values='Average Price',
hole=0.055, color_discrete_sequence=px.colors.qualitative.Set2)
fig.update_traces(textposition='inside', textinfo='percent+label')
fig.update_layout(title='Average Avocado Price by Type')
fig.show()
# 按“地区”分组,并计算每个地区的平均“平均价格”
region_means = df.groupby('region')['AveragePrice'].mean()
colors = px.colors.qualitative.Set2
fig = px.pie(values=region_means, names=region_means.index,
color=region_means.index, color_discrete_sequence=colors)
fig.update_traces(textposition='inside', textinfo='percent+label')
#fig.update_layout(title='Average Avocado Prices by Region
(Conventional vs. Organic)')
fig.show()
# 计算所有行中每种包类型的占比
total_small_bags = df['Small Bags'].sum()
total_large_bags = df['Large Bags'].sum()
total_xlarge_bags = df['XLarge Bags'].sum()
sizes = [total_small_bags, total_large_bags, total_xlarge_bags]
labels = ['Small Bags', 'Large Bags', 'XLarge Bags']
colors = ['lightcoral', 'lightskyblue', 'lightgreen']
plt.figure(figsize=(4, 4))
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%',
startangle=140)
plt.title('Distribution of Bag Types')
plt.show()
# 可视化平均价格的波动频率
plt.figure(figsize=(10, 6))
plt.hist(df['AveragePrice'], bins=20,color='orange')
plt.xlabel('Average Price ($)')
plt.ylabel('Frequency')
plt.title('Distribution of Average Avocado Prices')
#平均价格、销售量、总的包类型和各种型号的包装类型随时间的售卖情况
df['Date'] = pd.to_datetime(df['Date'])
l1 = ['AveragePrice', 'Total Volume', 'Total Bags','Small
Bags','Large Bags','XLarge Bags']
fig, ax = plt.subplots(nrows=3, ncols=1, figsize=(20, 15))
for i in range(len(l1)):
plt.subplot(6, 1, i+1)
sns.lineplot(x='Date', y=l1[i], data=df)
title = l1[i] + ' vs Date'
plt.title(title)
plt.xlabel('Date')
plt.ylabel(l1[i])
plt.tight_layout()
plt.show()








![[星瞳科技]OpenMV如何进行串口通信?](https://img-blog.csdnimg.cn/img_convert/f42050a631bd50a6e36d27b6036e95fe.jpeg)