【JAVA入门】Day23 - 查找算法
文章目录
- 【JAVA入门】Day23 - 查找算法
- 一、基本查找
- 二、二分查找 / 折半查找
- 三、分块查找
查找算法我们常用的有:
- 基本查找
- 二分查找 / 折半查找
- 分块查找
- 插值查找
- 斐波那契查找
- 树表查找
- 哈希查找
这里我们着重讲解前三种,其他查找方式除了树表查找,都是前三种的扩展。
一、基本查找
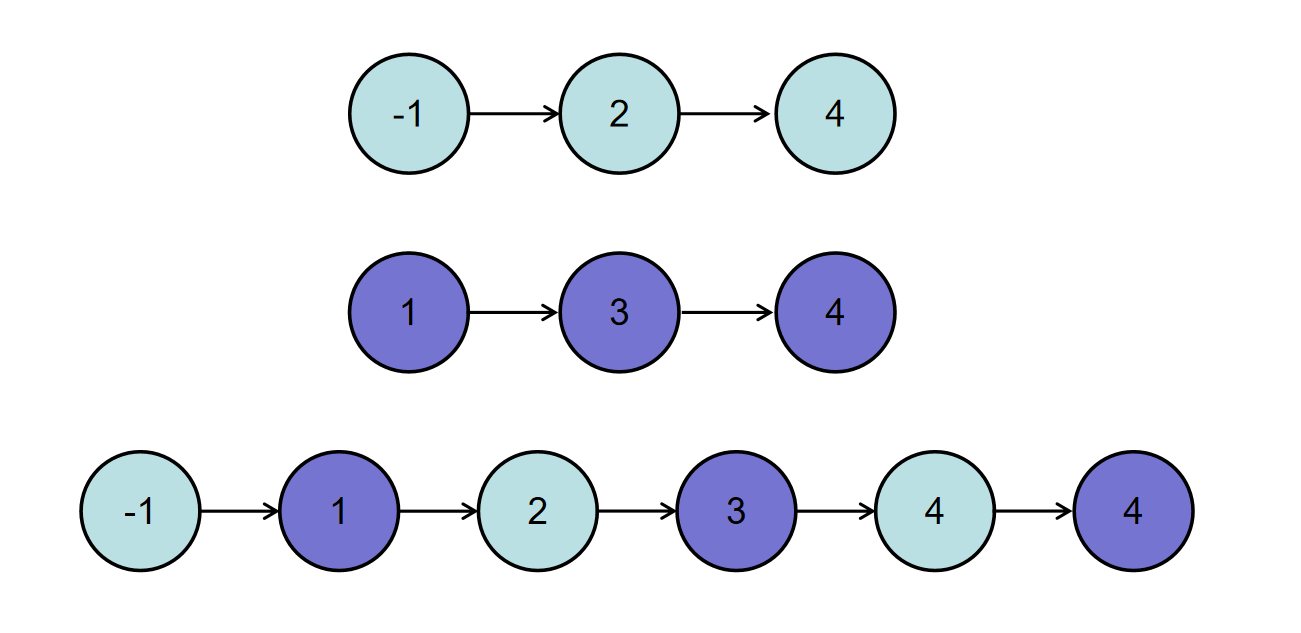
131 127 147 81 103 23 7 79
在一堆数据中找出想要的数据,只需要将它们放入一个容器中,挨个遍历,直到找到想要的数据。
package BasciSeach;
public class BasicSearchDemo1 {
public static void main(String[] args) {
//从0索引开始挨个往后查找
//基本查找/顺序查找
//数据:{131, 127, 147, 81, 103, 23, 7, 79}
//需求:是否存在
int[] arr = {131, 127, 147, 81, 103, 23, 7, 79};
int num = 18;
boolean result = basicSearch(arr, num);
System.out.println(result);
}
//参数:
//一:数组
//二:要查找的元素
public static boolean basicSearch(int[] arr, int num) {
//利用基本查找number是否在数组中存在
for(int i = 0; i < arr.length; i++) {
if(arr[i] == num){
return true;
}
}
return false;
}
}
利用基本查找,返回元素的索引(不考虑有无重复元素)。
package BasciSeach;
public class BasicSearchDemo2 {
public static void main(String[] args) {
//从0索引开始挨个往后查找
//基本查找/顺序查找
//数据:{131, 127, 147, 81, 103, 23, 7, 79}
//需求:返回索引
int[] arr = {131, 127, 147, 81, 103, 23, 7, 79};
int num = 7;
int index = basicSearch(arr, num);
if(index > 0) {
System.out.println(index);
}else{
System.out.println("未找到元素");
}
}
//参数:
//一:数组
//二:要查找的元素
public static int basicSearch(int[] arr, int num) {
//利用基本查找number是否在数组中存在
for(int i = 0; i < arr.length; i++) {
if(arr[i] == num){
return i;
}
}
return -1;
}
}
利用基本查找,返回元素的所有索引(考虑有重复元素)。
package BasciSeach;
import java.util.ArrayList;
public class BasicSearchDemo3 {
public static void main(String[] args) {
//利用基本查找,返回元素的索引(考虑有重复元素)
//返回所有索引
int[] arr = {131, 127, 147, 81, 103, 23, 7, 81};
int num = 81;
ArrayList<Integer> list = basicSearch(arr, num);
System.out.print("[");
for(int i = 0; i < list.size(); i++) {
if(i < list.size() - 1) {
System.out.print(list.get(i) + ", ");
}else{
System.out.print(list.get(i));
}
}
System.out.print("]" + "\n");
}
//心得:
//如果要返回多个数据的话,可以放入集合中
public static ArrayList<Integer> basicSearch(int[] arr, int num) {
ArrayList<Integer> list = new ArrayList<>();
for(int i = 0 ; i < arr.length; i++) {
if(arr[i] == num) {
list.add(i);
}
}
return list;
}
}
二、二分查找 / 折半查找
二分查找的数据有前提要求:数据必须是有序的。可以是从小到大排列,也可以是从大到小排列。
二分查找的核心逻辑就是:每次排除一半的查找范围。因此查找效率比基本查找快很多。
定义两个变量,min 指向 0 索引,max 指向 最大索引,(max + min)/ 2 可以得到中间的索引 mid。此时看该索引和要查找的数据大小关系,如果它比要查找的数据大,那么该数据所在的范围一定在 mid 索引的左半边,此时可以直接令 max = mid - 1,缩小索引范围;如果它比要查找的数据小,那么该数据所在范围一定在 mid 索引的右半边,此时可以直接令 min = mid + 1,缩小索引范围。重复此流程,直到max == min,此时就能找到所找的数据。如果要被查找的数据不存在,程序就会继续执行刚刚的逻辑,此时会发生 min > max,循环结束。
package BasciSeach;
public class BinarySearchDemo1 {
public static void main(String[] args) {
//二分查找
//{7, 23, 79, 81, 103, 127, 131, 147}
int[] arr = {7, 23, 79, 81, 103, 127, 131, 147};
int number = 81;
System.out.println(binarySearch(arr, number));
}
public static int binarySearch(int[] arr, int number) {
//1.定义两个变量记录要查找的范围
int min = 0;
int max = arr.length - 1;
//2.利用循环不断去找要查找的数据
while(true) {
if(min > max) {
System.out.println("要查找的数据不存在!");
return -1;
}
//3.找到min和max的中间位置
int mid = (min + max) / 2;
//4.拿着mid指向的元素跟要查找的元素进行比较
//4.1number在mid左边
//4.2number在mid右边
//4.3number跟mid指向的元素一样
if(arr[mid] > number) {
max = mid - 1;
}else if(arr[mid] < number) {
min = mid + 1;
}else if(arr[mid] == number) {
return mid;
}
}
}
}
二分查找最大的优势就是能提高查找的效率,但是它要求数据必须是有序的。
如果数据是乱序,先排序再使用二分查找得到的索引没有任何意义,只能知道这个数据是否存在。因为排序之后,数字的位置可能就发生变化了,新的索引没有参考价值。
二分查找的效率其实可以进一步优化,将 mid 的计算方法改进,如下公式:
mid = min + (key - arr[min]) / (arr[max] - arr[min]) * (max - min);
其中,key 是要查找的数据。此时这种查找方式就不叫二分查找了,而是叫做插值查找。
还可以利用数学中的黄金分割点的概念进行改进:
mid = min + 黄金分割点左半边长度 - 1
此时这种查找方法就不叫二分查找了,而是叫做斐波那契查找。
三、分块查找
如果一组数据:块间有序,块内无序。这个时候我们可以应用分块查找。
分块查找的原则在于:
- 前一块中的最大数据,小于后一块中的所有数据(块内无序,块间有序)。
- 块数数量一般等于数字的总个数开根号。比如:16个数字一般分为4块左右。
块对象的定义一般如下所示:
class Block { //块
int max; //块中的最大值
int startIndex; //起始索引
int endIndex; //结束索引
}
将块对象放到一个数组中统一管理,这个数组一般叫做索引表。通过索引表,我们就能确定要查找的值存在于哪一块当中。


比如上面的数据,我们可以轻易地发现,30就在第三个块当中(这个块级寻找的过程可以用基本查找或二分查找实现)。然后,我们再在块内使用遍历,就可以轻易找到要查找的数据30。
package BasciSeach;
public class BlockedSearchDemo1 {
public static void main(String[] args) {
//1.创建数组blockArr存放每一个块对象的信息
//2.先查找blockArr确定要查找的数据属于哪一块
//3.再单独遍历这一块数据即可
int[] arr = {16, 5, 9, 12, 21, 18,
32, 23, 37, 26, 45, 34,
50, 48, 61, 52 ,73, 66};
//1.把数据分块
//分几块:总数开根号 √18 = 4.24 块左右
//每块里 18 / 4 = 4.5 个
//创建三个块的对象
Block b1 = new Block(21,0,5);
Block b2 = new Block(32,6,11);
Block b3 = new Block(50,12,17);
//定义数组用来管理三个块的对象(索引表)
Block[] blockArr = {b1, b2, b3};
//定义一个变量用来记录要查找的元素
int number = 32;
//调用方法,传递索引表,数组,要查找的元素,返回要查找的数据索引
int index = getIndex(blockArr, arr, number);
//打印
System.out.println(index);
}
//利用分块查找的原理,查询number的索引
private static int getIndex(Block[] blockArr, int[] arr, int number) {
//1.确定number在哪一块中,找到这一块的索引
int indexBlock = findIndexBlock(blockArr, number);
if(indexBlock == -1){
//表示number过大,不在任何一块当中
return -1;
}
//获取这一块的起始索引和结束索引
int startIndex = blockArr[indexBlock].getStartIndex();
int endIndex = blockArr[indexBlock].getEndIndex();
//遍历这一部分的数组
for(int i = startIndex; i <= endIndex; i++) {
if(arr[i] == number) {
return i;
}
}
//遍历完整块都没找到,返回-1
return -1;
}
//定义一个方法,用来确定number在哪一块中
private static int findIndexBlock(Block[] blockArr, int number) {
/*//创建三个块的对象
Block b1 = new Block(21,0,5);
Block b2 = new Block(32,6,11);
Block b3 = new Block(50,12,17);*/
//从0索引开始遍历blockArr,如果number小于max,那么就表示number是在这一块当中的
for (int i = 0; i < blockArr.length; i++) {
if(number <= blockArr[i].getMax()) {
return i;
}
}
//当前数字过大,每一块中都找不到
return -1;
}
}
class Block {
private int max;
private int startIndex;
private int endIndex;
public Block() {
}
public Block(int max, int startIndex, int endIndex) {
this.max = max;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
public int getMax() {
return max;
}
public int getStartIndex() {
return startIndex;
}
public int getEndIndex() {
return endIndex;
}
}
如果数据本身没有规律。只需要保证数据间尚无交集,就可以完成分块。我们可以新增一个 min 变量,来记录每块中最小的值。

如果查找的过程中还需要添加新数据呢?常见需求:在1~1000之间获取100个随机数,要求这些数据不重复,那就需要每添加一个数据就进行一次查找,查看该数据是否已经存在。这个时候就可以利用分块查找,把这100个数据分成10块,每一块规定要存储数据的范围。

将要生成的数据放在相应块中,在各块中再进行遍历查找。这种查找方式作为分块查找的改进,被重新命名为哈希查找。








![[星瞳科技]OpenMV如何进行串口通信?](https://img-blog.csdnimg.cn/img_convert/f42050a631bd50a6e36d27b6036e95fe.jpeg)