在生命科学的奇妙世界中,基因恰似一本记录着生命奥秘的“天书”,它承载着生物体生长、发育、衰老乃至疾病等一切生命现象的关键信息。而重测序技术,则是开启基因“天书”奥秘的一把神奇钥匙。
试想,你手中有一本经典书籍的通用版本,但在不同的印刷批次中,可能会出现一些细微的错别字、排版差异,甚至独特的批注。基因的情况也是如此,尽管我们已经拥有了某个物种的参考基因组,但每个个体的基因组都可能与参考基因组存在差异。重测序技术的作用就在于此——它通过对已知基因组序列的物种进行个体或群体的基因组测序,然后将测得的序列与参考基因组进行比对,从而精准地找出其中的差异。这些差异或许微小,却可能蕴含着决定个体特征、适应性甚至疾病易感性的关键线索。
测序技术的发展
第一代测序技术
让我们把时光倒回20世纪70年代,第一代测序技术在这个时期应运而生。当时,Sanger和Gilbert这两位科学家分别建立了DNA双脱氧测序和化学测序技术,为基因测序领域奠定了坚实的基础。
先来看DNA双脱氧测序法,其核心原理是利用双脱氧核苷酸(ddNTP)来终止DNA链的延伸。在反应过程中,当ddNTP随机掺入到正在合成的DNA链中时,由于它缺乏继续延伸所需的化学基团,链的生长就此停止。这样,就会产生一系列不同长度的DNA片段。随后,通过电泳技术将这些片段按照大小分离,再利用放射自显影来阅读DNA序列。
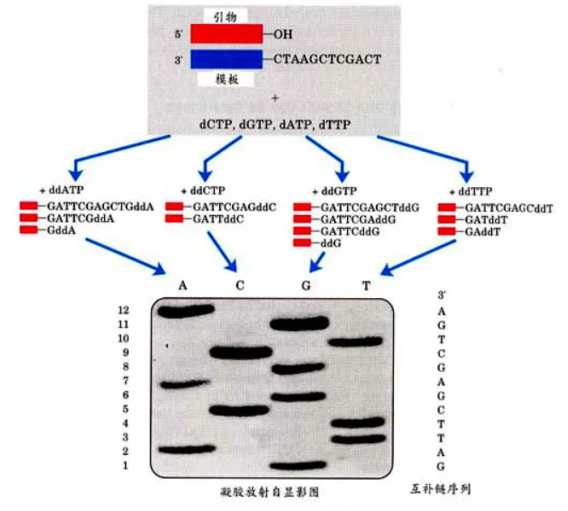
图1 DNA双脱氧测序法
而化学测序法的原理则有所不同,它是通过特定的化学反应,使DNA链在不同的碱基位置处发生断裂。同样地,经过电泳分离和放射自显影处理后,便能够确定DNA的序列。
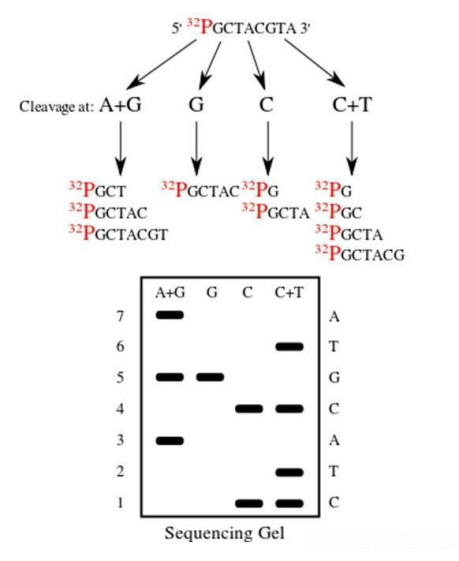
图2 化学测序法
第一代测序技术的特点十分鲜明,它的准确性非常高,这是其最大的优势所在。然而,该技术也存在一些明显的不足:a)通量较低,无法同时处理大量的样本;b)成本相对较高,对于大规模的基因组测序项目来说经济负担较重;c)操作过程较为繁琐,需要耗费大量的人力和时间;d)测序速度缓慢,难以满足快速获取基因信息的需求。一次测序只能读取几百个碱基对的序列信息,这在面对庞大的基因组时显得力不从心。尽管如此,第一代测序技术在当时依然为生命科学的研究提供了重要的工具,推动了遗传学等领域的发展。
第二代测序技术(高通量测序技术)
时间的车轮滚滚向前,来到了20世纪末至21世纪初,这一时期见证了第二代测序技术,也就是我们常说的高通量测序技术的崛起。
在技术层面,这一代测序技术呈现出了百花齐放的局面。罗氏454的焦磷酸测序技术率先登场,它巧妙地利用了焦磷酸的释放与检测来推断碱基的掺入,从而实现测序。紧随其后,Solexa的SBS测序技术(后续被Illumina公司收购,并发展成为如今广为人知的HiSeq等系列测序平台)也崭露头角,该技术通过边合成边测序的方式,在每一次碱基掺入时进行荧光信号检测,进而读取DNA序列。此外,Complete Genomics(CG)的DNB连接cPAL测序技术也加入了这一技术浪潮,最终被华大基因收购并发展成为华大智造的一系列BGI/MGI测序平台。还有 SOLiD 测序技术等,它们共同构成了第二代测序技术的多元格局。目前爱基测序平台有Illumina和华大MGI。
从原理上来说,这些技术有着共通之处,它们都是基于DNA合成或连接反应来进行测序。在具体操作中,首先将基因组DNA或RNA打断成小片段,然后连接上特定的接头,就像是给每个片段都装上了“把手”,方便后续的操作。接着,这些带有接头的片段被放置在固相表面上,在这里,无数个测序反应可以同时进行,也就是我们所说的多重平行测序反应。在测序过程中,每一个循环的数据都会通过成像的方法被捕捉下来,随着循环的不断进行,序列信息也就被逐步解析出来,从而实现了大规模、高通量的测序。
第二代测序技术的特点十分突出,最令人瞩目的是测序通量得到了大幅提升,相较于第一代测序技术,这是一次质的飞跃。同时,成本也显著降低,使得大规模基因组测序项目在经济上变得可行。它能够同时对大量DNA片段进行测序,一次运行可以产生数百万到数十亿条序列信息,这为生命科学研究开辟了广阔的道路。然而,任何技术都不是完美的,第二代测序技术的缺点在于测序读长短,这在一定程度上限制了对某些复杂基因组区域的精确分析。不过,瑕不掩瑜,第二代测序技术的出现,使得大规模基因组测序成为可能,极大地推动了生命科学各个领域的发展,从基础研究到临床应用,都留下了它深深的印记。
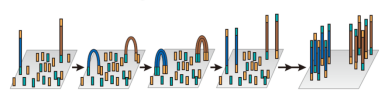
图3 Illumina扩增原理
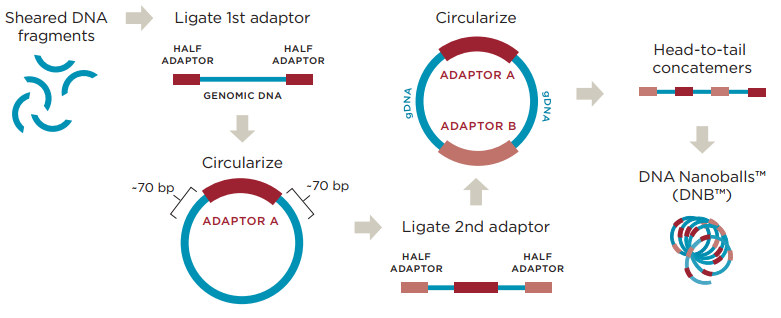
图4 华大扩增原理
第三代测序技术
21世纪以来,随着生命科学的不断探索与技术的飞速发展,第三代测序技术崭新登场,它犹如一颗璀璨的新星,照亮了基因测序领域的前行道路。
在技术层面,第三代测序技术以单分子测序技术为核心,其中最具代表性的当属PacBio RS测序技术和纳米孔测序技术。PacBio RS测序技术就像是一个敏锐的实时监控器,它基于单分子实时(SMRT)测序原理,在DNA聚合酶催化DNA合成的过程中,通过荧光标记的核苷酸发出的荧光信号,实时捕捉并监测DNA序列的合成过程,仿佛亲眼目睹每一个碱基的精准掺入。
图5 PacBio平台测序
而纳米孔测序技术则犹如一个神奇的电流探测器,它让DNA分子如同穿针引线般通过纳米孔,当不同的碱基依次通过这个微小的孔道时,会引起纳米孔电流的微妙变化,就像不同的钥匙插入锁孔产生的不同震动,通过敏锐地检测这些电流变化,就能准确地确定DNA序列。
图6 Nanopore平台测序
第三代测序技术的特点更是令人眼前一亮。它能够实现单分子水平的测序,无需再借助PCR扩增这一传统步骤,这就如同直接从源头获取信息,避免了扩增过程中可能引入的错误和偏差,保证了原始DNA分子的完整性与真实性。同时,它还具备检测特殊碱基修饰等信息的能力,为研究基因的表观遗传调控等复杂机制提供了有力支持。
此外,其测序读长较长,就像是拥有了一把更长的尺子,能够轻松跨越一些复杂的基因组区域,例如那些重复序列、高变异区域等,这极大地有助于基因组的精细组装和结构变异的精准检测,为研究人员呈现出更加完整、清晰的基因组画卷。
然而,如同每一枚硬币都有两面,第三代测序技术目前也存在一些亟待解决的问题。测序成本相对较高,这在一定程度上限制了其大规模应用的范围,就好比一件精美的手工艺术品,由于制作成本高昂,难以普及到大众手中。同时,其准确性还有待进一步提高,虽然已经能够满足许多研究需求,但在追求极致精确的科学道路上,仍有提升的空间。
重测序技术产品
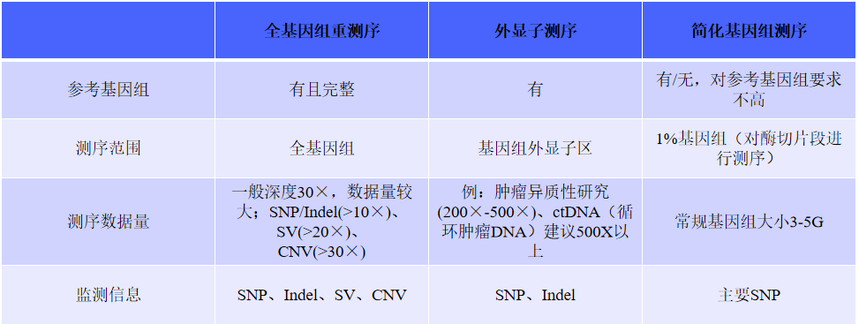
一、全基因组重测序——基因全景大扫描
全基因组重测序(Whole - Genome Resequencing,WGR)相当于对生物体基因组进行一次全面的“体检”,它的视野覆盖了基因组的每一个角落,无论是负责编码蛋白质的关键区域,还是曾被误解为“垃圾DNA”的部分,都在它的检测范围内。这就好比用高清摄像机对整个城市进行全方位、无死角的拍摄,不遗漏任何一个细节。
通过全基因组重测序,我们可以精准地检测出基因组中的各种变异类型。其中,单核苷酸多态性(SNP)就像是基因组中的“单个音符变化”,虽然微小,却可能影响生物性状;插入缺失(InDel)则像是“音符的增减”,对基因序列的长度产生影响;而结构变异(SV)和拷贝数变异(CNV)更是涉及基因组的“乐章重组”,可能导致基因功能的改变、基因表达的失调等复杂后果。
在个体水平上,全基因组重测序能够实现基因型多样性分析,揭示个体独特的基因组成;进行遗传进化分析,追溯个体的遗传起源与演化历程;筛选致病和易感性基因,为疾病的风险评估提供依据;开展单基因病筛查,精准定位由单个基因突变引起的疾病;以及实施癌症筛查,发现与癌症发生发展相关的基因变异,为早期诊断和治疗提供可能。
在群体水平上,通过对多个个体的全基因组重测序,可以挖掘出群体内丰富的遗传变异,为研究群体的遗传结构、基因流动、自然选择等提供海量数据,有助于我们深入了解生物的进化历史、适应性机制以及疾病的群体遗传学特征,为生命科学的众多领域带来新的突破和应用场景。
图7 个体与群体
二、外显子测序——聚焦关键“剧情”
在基因组这部浩瀚的“生命史诗”中,全外显子组测序(Whole Exon Sequencing,WES)就像是一位专注的“剧情推动者”追踪者,它专注于那些真正决定生物性状和功能的关键章节——外显子。外显子是基因中能够编码蛋白质的区域,它们虽然只占基因组的1%,但却承载着大约85%的致病突变,是疾病相关变异的“高发区”。
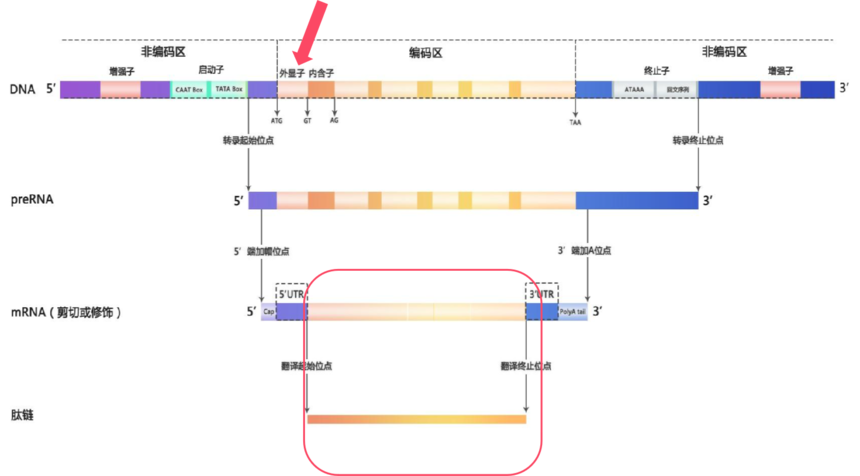
图8 真核生物基因结构
WES借助序列捕获技术,如同精准的“基因渔网”,将全基因组中外显子区域的DNA捕获并富集,随后进行高通量测序。这一过程就像是直接对外显子这些关键章节进行精细的“文字校对”,能够更准确地发现与蛋白质功能变异相关的遗传变异。
与全基因组重测序相比,外显子测序由于数据量较小,使得成本大幅降低,这就好比只精读关键部分而不是整本书,节省了大量时间和资源。同时,其在有效位点的测序深度却更高,意味着对这些关键区域的检测更加精细和准确。
在医学研究领域,WES堪称“疾病基因猎手”,常用于查找单基因病、复杂疾病的致病基因,以及检测肿瘤的体细胞突变。它是揭示疾病发生机制、寻找治疗靶点的重要工具。
WES在肿瘤研究方面具有独特优势。癌症异质性需要高深度测序来全面揭示其复杂性,建议达到200X以上有效深度,以确保对肿瘤基因组的精准解析。对于FFPE(甲醛固定石蜡包埋)样品,由于其在处理过程中可能造成DNA损伤,建议采用200 - 300X对应的数据量,以保证数据的可靠性和准确性。而在检测ctDNA(循环肿瘤DNA)时,为了捕捉到血液中微量的肿瘤DNA信号,建议达到500X及以上有效测序深度。这些精细的测序策略有助于我们深入理解肿瘤的发生、发展、转移和复发机制,以及评估药物疗效,为肿瘤的精准治疗和个性化医疗提供有力支持。
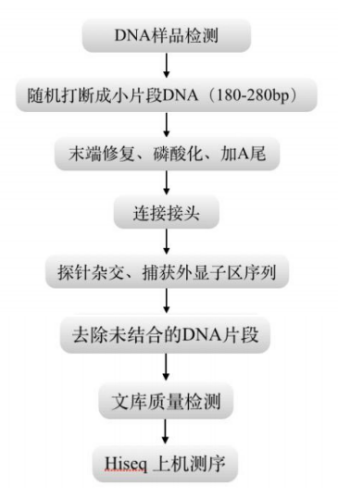
图9 WES测序流程
三、简化基因组测序 —— 高效抓重点
在基因组这片广袤的“信息海洋”中,简化基因组测序技术(Reduced Representation Genome Sequencing,RRGS)就像是一艘精准的“信息采集船”,它包括RRL、GBS、RAD-seq、ddRAD和2b-RAD等多种方法,通过限制性内切酶消化DNA来降低基因组复杂度,再利用测序技术进行遗传变异分析。这一过程相当于从海量信息中精心挑选出最具代表性的部分进行测序,就像是在繁杂的图书馆中挑选出关键的书籍来阅读,从而有效减少了测序的数据量,避免了不必要的信息干扰。
RRGS技术凭借其成本低、效率高的优势,成为了大规模样本测序的“利器”,能在短时间内对大量样本进行测序分析,这就好比一条高效的生产线,快速而稳定地输出精准的数据。在群体遗传学研究中,它更是发挥了巨大的作用,帮助我们深入地了解群体的遗传结构和多样性,揭示不同群体之间的演化关系和遗传差异,为生物进化研究和育种工作提供了宝贵的数据支持。
-
简化基因组测序手段的各自特点:
· RRL(Reduced Representation Libraries):
RRL操作相对简单,能够快速构建文库,就像是一个“快速启动的项目”,可以迅速投入运行并产生数据。但可能产生较多的非特异性片段,导致测序数据中有效信息占比相对较低,这就好比在采集的样本中夹杂了一些杂质,需要进一步的筛选和纯化。此外,它对酶切位点的依赖性较强,酶切位点的分布会影响所获得的基因组覆盖范围,这意味着在实验设计时需要充分考虑酶切位点的选择和分布,以确保获得具有代表性的基因组区域。
· RAD-seq(Restriction-site Associated DNA sequencing):
RAD-seq依赖机械剪切和酶切结合的方式,这种独特的组合使其适用于缺乏参考基因组的物种,就像是为那些“神秘的、未被充分研究”的生物量身定制的工具,能够在没有完整基因组信息的情况下,依然精准地获取关键的遗传信息,为研究这些物种的遗传多样性和适应性进化提供了可能。
· GBS(Genotyping By Sequencing):
GBS可以看作是一种简化版的复杂度降低方法,它仅使用一种限制性酶,从而大大简化了操作流程和成本,就像是一个“经济适用型”的测序方案,适用于多种物种的低成本基因分型,在大规模的群体筛查和遗传标记辅助育种中具有广泛的应用前景,能够快速、高效地为育种工作提供大量的遗传标记数据。
· ddRAD(double Digest Restriction-site Associated DNA):
ddRAD使用两种限制性酶进行消化,这种双酶切策略提供了更高的位点控制,就像是给基因组信息的采集安装了“双保险”,使得获取的遗传信息更加精准和全面。它适用于遗传连锁图谱构建和关联分析,在研究基因的连锁关系、定位重要农艺性状的基因位点等方面具有独特的优势,为作物和家畜的分子育种提供了有力的工具。
· 2b-RAD:
2b-RAD基于IIB型限制性内切酶,这种特殊的酶切方式能够生成等长标签,就像是生产出了一批标准化的“遗传信息标签”,便于统一分析和比较,适用于大规模研究和高密度遗传图谱构建。在需要处理大量样本和构建精细遗传图谱的研究中,2b-RAD能够高效地完成任务,为揭示复杂性状的遗传基础和开展精准育种提供了重要的技术支撑。
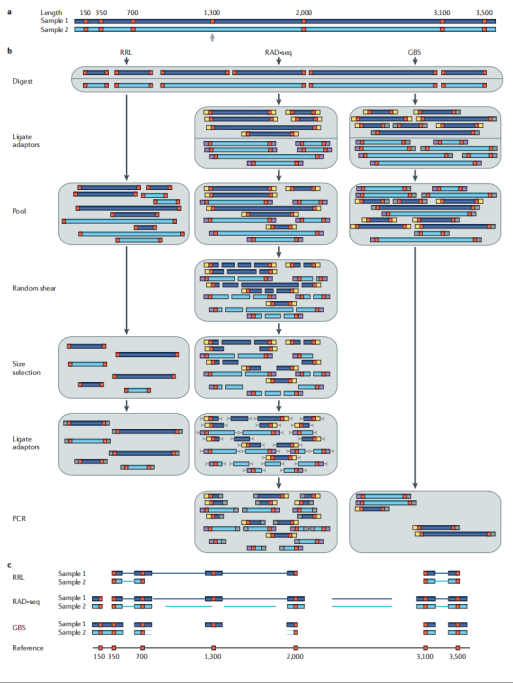
图10 简化基因组测序原理
重测序数据分析应用
一、群体进化研究
在生命科学的探索中,群体进化研究宛如一把开启物种历史奥秘的钥匙,它基于全基因组重测序技术或其他测序技术,为我们揭示生物群体的遗传奥秘。通过获取某物种自然群体各亚群的基因组信息,我们能够得到大量的SNP、InDel、SV和CNV等变异信息,进而深入研究群体的遗传结构、驯化机制、种群历史以及群体进化动态等生物学问题,勾勒出物种演化的壮丽画卷。
-
应用方向
物种起源与演化探究
通过分析不同物种或群体的重测序数据,我们可以重建物种的进化历程,确定物种的起源时间和地点,以及不同物种之间的亲缘关系。这就像为物种的家族树绘制详细的年轮,每一道刻痕都记录着时间的流逝和生命的变迁。
基因功能与调控网络研究
群体进化研究可以结合重测序数据和表达谱数据,推断基因的功能和调控网络。在不同环境或发育阶段下,群体中基因的变异和表达变化模式能够为理解基因的功能及其在生物体内的调控机制提供线索,为我们揭示生命活动的内在逻辑。
农业种植领域可进行作物遗传改良
在作物育种中,重测序数据可用于挖掘与重要农艺性状相关的基因和标记。例如,通过对大量水稻品种进行重测序,发现与产量、品质、抗病性等性状相关的基因位点,为分子标记辅助选择育种和基因编辑育种提供理论依据,助力农业的丰收与进步。
家畜品种选育
对于家畜,重测序数据有助于了解其遗传多样性和群体结构,鉴定与生长速度、肉质、繁殖性能等经济性状相关的基因。通过对猪、牛等家畜群体的重测序研究,能够有针对性地进行品种选育,提高养殖效益,为畜牧业的发展添砖加瓦。
医学领域可进行疾病遗传机制研究
对患者群体和健康群体进行全基因组重测序,对比分析两者之间的遗传差异,发现与疾病发生发展相关的基因突变和易感位点,为疾病的诊断、治疗和预防提供重要的科学依据,守护人类的健康。
-
材料选择
种群需具有长时间的进化或驯化历史,可选取全球范围内不同地区、不同品种样本研究该种群的动态历史;或者选取某特定地区不同品种样本,研究该种群在该地区的种群历史。
-
样本数量
至少3个群体,建议每个分群植物不少于15个,动物不少于10个,珍稀样品数量可适当减少。
-
测序深度
一般建议10×以上,珍稀样本可适当减少。
-
分析内容展示
① PCA(主成分分析)
通过数据降维分析主成分,揭示数据中的主要变异模式和样本间的关系。在群体进化研究中,用于分析群体遗传结构,直观地展示不同群体间的遗传差异和相似性,判断群体是否存在明显的遗传分化,以及个体在群体中的遗传位置等。
② 进化树
基于生物之间的遗传距离或相似性,通过一定的算法构建树形结构,以表示不同生物类群或个体之间的进化关系。树的节点代表祖先群体或物种,分支长度通常反映了进化距离或遗传差异的大小。
③ Structure 分析
基于群体遗传学的模型,利用个体的基因型数据,将群体中的个体按照遗传相似性划分成不同的遗传簇;用于研究群体的遗传混合、基因流和种群分化情况,确定群体中存在的潜在亚群数量和结构,分析个体在不同亚群中的遗传组成比例。
④ 选择性清除分析
当一个有利突变在群体中受到自然选择作用而迅速传播时,它会导致该突变位点及其附近的基因组区域的遗传多样性降低,这种现象称为选择性清除。通过比较不同群体或同一群体不同区域的遗传多样性、等位基因频率等指标,来识别基因组中可能受到正选择的区域。
⑤ π 分析
π 值是衡量群体内遗传多样性的一个指标,它表示群体中任意两个随机选择的 DNA 序列之间核苷酸差异的平均数。通过计算群体中基因或基因组区域的 π 值,了解该群体在特定区域的遗传多样性水平。评估群体的遗传变异程度,比较不同群体之间或同一群体不同区域的遗传多样性高低,分析遗传多样性在群体中的分布情况。
⑥ Fst 分析
是衡量群体间遗传分化程度的一个统计量,反映了群体间基因频率的差异程度。基于群体遗传学的 Hardy-Weinberg 平衡原理,通过比较群体内和群体间的基因多样性来计算。Fst 值的范围在 0 到 1 之间,值越大表示群体间的遗传分化程度越高。
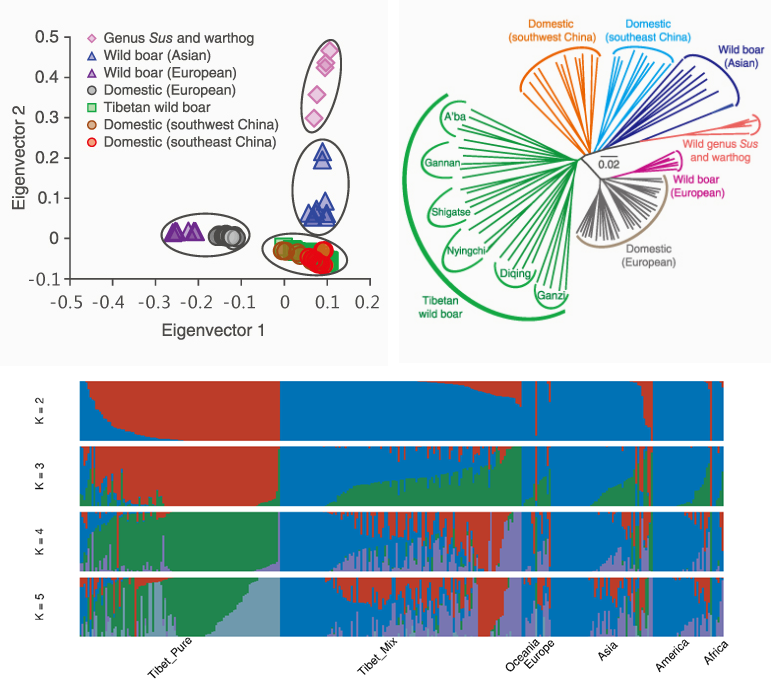
图11 PCA、进化树与structure分析
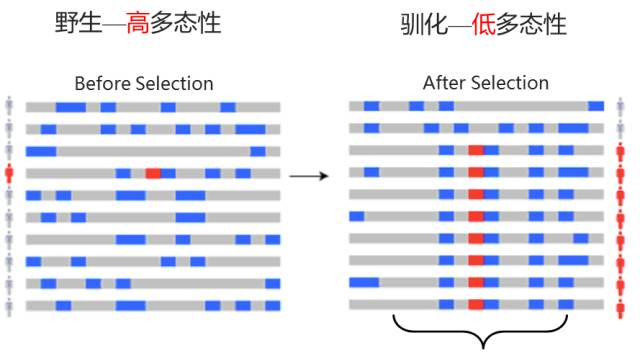
图12 选择性清除分析
二、全基因组关联分析GWAS
全基因组关联分析(Genome wide association study,GWAS)是一种在全基因组范围内对多个个体的遗传变异(标记)多态性进行检测,以获得基因型数据,并将这些基因型与可观测的性状(表型)在群体水平上进行统计学分析的方法。通过分析统计量或显著性 p 值,GWAS 能够筛选出最有可能影响特定性状的遗传变异(标记),进而挖掘出与性状变异相关的基因,为揭示复杂性状的遗传基础提供有力支持。
-
数据要求
表型数据
为了确保分析结果的可靠性和准确性,表型数据的收集应尽可能全面和精确。通常情况下,建议在多年份、多地点的条件下进行数据采集,并且每个处理或条件下的重复次数最好达到三次以上。这种设计有助于充分考虑环境因素对表型性状的影响,降低随机误差对实验结果的干扰,从而更真实地反映基因与性状之间的关联关系。
测序样本数量
样本数量的多少直接影响到 GWAS 的统计效力和结果的可信度。一般要求样本数大于 200,这样可以确保在统计分析中具有足够的功率来检测到微弱的基因效应,同时也有助于提高所发现关联信号的稳定性。此外,对于自然群体,应尽量选取来自各个地方的不同材料,包括野生型、栽培种以及地方品种等,以涵盖丰富的遗传多样性,增强研究结果的普遍性和代表性。在家系群体的研究中,则可选择全同胞家系或半同胞家系,以及多个亲本及其 F2 子代等作为研究对象,这样能够充分利用家系内的遗传连锁信息,提高定位基因的精度。
测序深度
测序深度与数据质量和分析准确性密切相关。一般建议测序深度达到 10× 以上,这样可以确保在大多数基因组区域获得可靠的测序数据,减少因测序深度不足导致的基因型误判。同时,适当的测序深度也有助于平衡研究成本和数据质量,使得在大规模样本测序的情况下,既能保证数据的可用性,又不会造成资源的过度浪费。
-
分析内容展示
曼哈顿图
曼哈顿图是一种直观展示 GWAS 结果的散点图,因形似曼哈顿摩天大楼而得名。在图中,横轴表示基因组的染色体位置,按照染色体的顺序依次排列,不同染色体通常用不同的颜色加以区分;纵轴则表示 -log10(P),P 值越小,对应的纵轴值越高,表明该位置的遗传变异与目标性状的关联越显著。研究人员可以通过观察曼哈顿图,快速锁定基因组中具有显著关联信号的区域,这些区域中的变异位点即为可能影响性状的关键候选位点,为进一步的功能验证和基因挖掘提供了明确的方向。在实际研究中,尤其是对于数量性状的分析,如果曼哈顿图中出现成簇的显著性位点,往往更具生物学意义,因为多个相邻的显著位点可能共同作用于性状的形成和变异,而单一位点的显著性可能存在假阳性风险,需要谨慎对待。
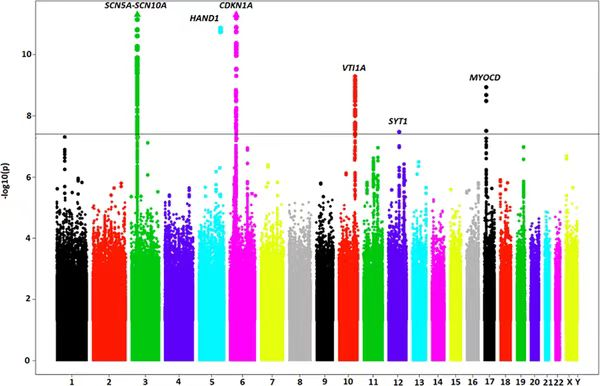
图13 曼哈顿图
QQ 图
QQ 图(quantile-quantile plot),即分位图,是评估 GWAS 分析结果质量的重要工具,主要用于判断观察到的 P 值分布与期望的 P 值分布之间的差异,从而帮助研究人员识别潜在的假阳性或假阴性结果。在 QQ 图中,若观察到的 P 值与期望 P 值一致,数据点将沿对角线(y=x)分布,这表明分析过程中没有明显的系统性偏差,所有的显著性结果均可认为是随机产生的。然而,当数据点偏离对角线时,存在两种情况:一种是向上偏离,即数据点位于对角线之上,这表示观察到的 P 值比期望的更小,意味着存在真实的显著关联信号,可能是由基因与性状之间的实际关联所导致;另一种是向下偏离,数据点位于对角线之下,这可能暗示着存在系统性偏差,例如群体结构未得到充分校正、实验操作中的技术误差等,这些因素可能会干扰分析结果的准确性,导致真正的关联信号被掩盖或弱化。因此,通过仔细分析 QQ 图的形状和特征,研究人员可以对 GWAS 结果的可靠性和有效性进行更为全面和深入的评估,为后续的结论和解释提供更为坚实的依据。
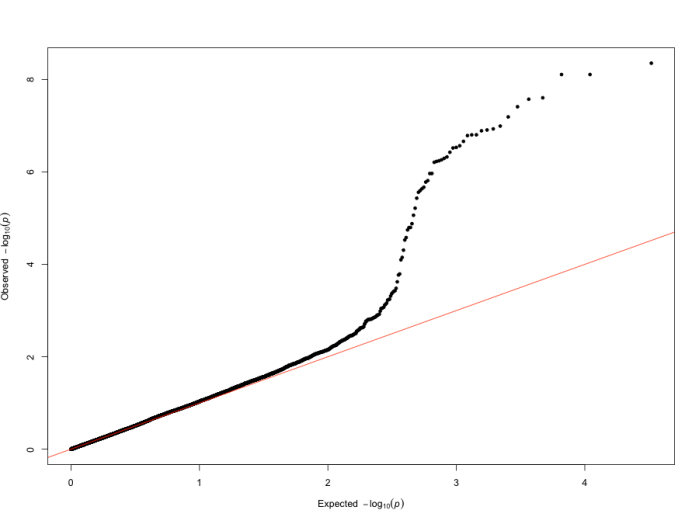
图14 QQ图
注:更加详细的GWAS介绍点击:https://mp.weixin.qq.com/s/ALd4ZxOymKKRbqPItFrRTQ
三、遗传图谱构建和QTL定位
-
遗传图谱
遗传图谱(Genetic map),也称为遗传连锁图(Genetic linkage map),是通过分析遗传标记之间的连锁关系而建立起来的染色体图谱。遗传距离通常用厘摩(cM)来表示,它反映了基因或标记之间在减数分裂过程中发生交换和重组的概率。在植物遗传学研究中,遗传图谱帮助揭示基因在染色体上的相对位置和遗传连锁关系。
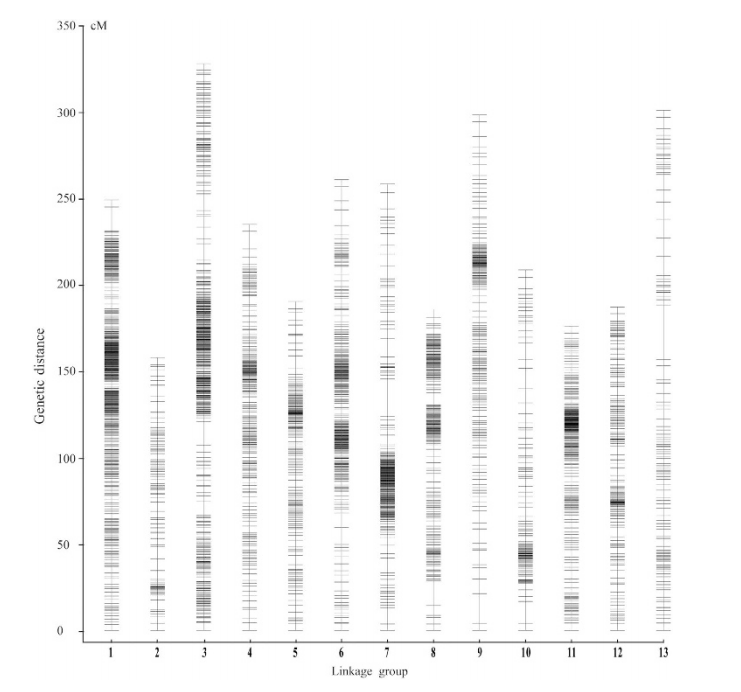
图15 SNP图谱的13个连锁群中的分布[1]
测序样本
选择亲本和构建分离群体:选择具有明显性状差异且纯合的亲本进行杂交,获得 F1 代。然后让 F1 代自交或与亲本回交等,构建 F2 代、回交群体(BC)等分离群体。这些群体中的个体在基因组合上存在差异,是遗传图谱构建的基础材料。

测序深度
建议最少10×以上。对于大多数物种,10x-20x的深度结合合适的统计方法和参考panel等能获得较好的效果来推断群体的遗传特征等;对于具有复杂结构的基因组(如杂合度高的群体或多倍体生物),可能需要更高的测序深度,30x甚至更高,以确保准确捕捉到所有变异。
-
QTL定位
数量性状位点(Quantitative Trait Locus,QTL),是指控制数量性状的基因在基因组中的位置。QTL定位是根据分子标记与目标性状的连锁关系,通过统计方法来定位与目标性状相关染色体区域,这些区域可能包含导致目标性状表型变异的基因。广泛应用于基因组研究、品种改良和基因定位等领域。

图16 QTL准备及分析流程
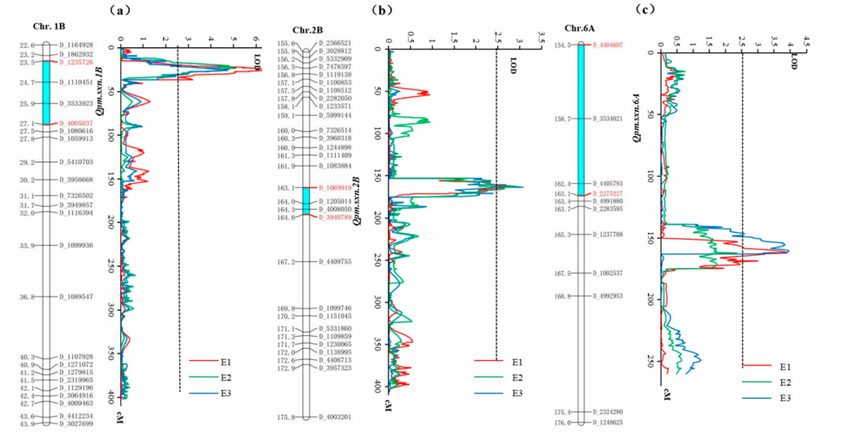
图17 1B(a)、2B(b)和 6A(c)号染色体上白粉病(PM)的数量性状基因座(QTL)及遗传连锁图谱[2]
基于连锁关系的QTL定位
QTL定位到的区间往往包含较多候选基因,可以采用以下辅助研究方法来筛选和验证区间内的候选基因:
-
构建次级分离群体:通过进一步构建更小的分离群体,可以更精细地定位QTL区间,缩小候选基因的范围。
-
结合公共数据库查看功能注释信息:利用已有的基因功能注释数据库,对QTL区间内的基因进行功能分析,筛选出可能与目标性状相关的基因。
-
同源基因分析:通过比较不同物种中的同源基因,寻找可能的功能保守基因,这些基因可能在目标性状的形成中起关键作用。
-
转录组分析:通过对目标性状相关组织或时期的转录组数据进行分析,了解QTL区间内基因的表达模式,筛选出可能与性状变异相关的差异表达基因。
-
基因编辑:利用基因编辑技术对候选基因进行功能验证,通过敲除或编辑基因,观察对目标性状的影响,从而确定基因的功能。
针对高通量测序,爱基百客拥有全基因重测序、全外显子测序、宏基因组和RAD等产品,欢迎有相关研究需求的老师前来咨询~
-
参考文献
【1】Zhang, H., Miao, H., Li, C., Wei, L., Duan, Y., Ma, Q., Kong, J., Xu, F., & Chang, S. (2016). Ultra-dense SNP genetic map construction and identification of SiDt gene controlling the determinate growth habit in Sesamum indicum L. Scientific reports, 6, 31556. https://doi.org/10.1038/srep31556
【2】Zhao, Z., Qiu, Y., Cao, M., Bi, H., Si, G., & Meng, X. (2024). Quantitative Trait Loci Mapping for Powdery Mildew Resistance in Wheat Genetic Population. Genes, 15(11), 1438. https://doi.org/10.3390/genes15111438