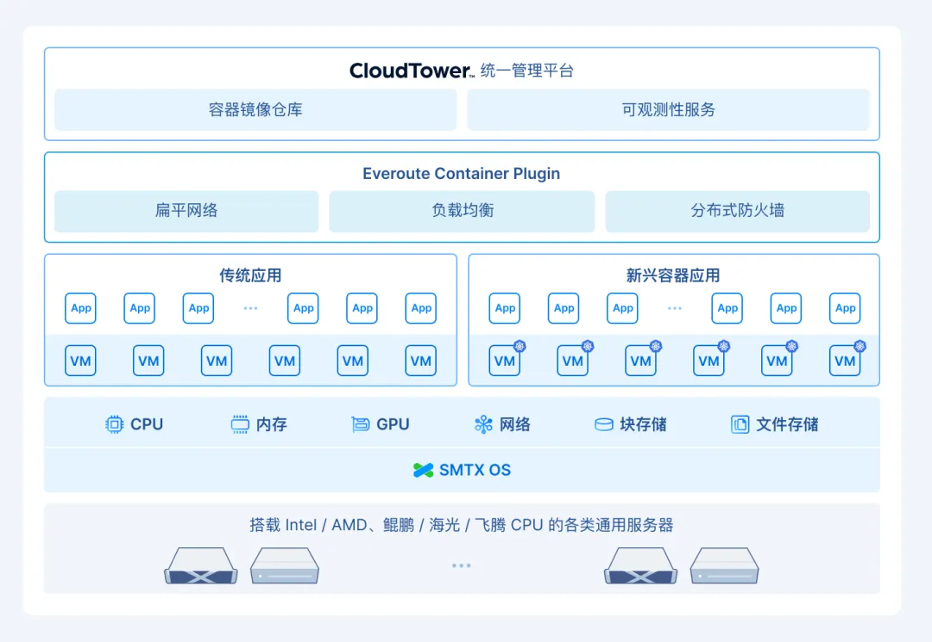
Ollama是一款开源工具,它允许用户在本地便捷地运行多种大型开源模型,包括清华大学的ChatGLM、阿里的千问以及Meta的llama等。目前,Ollama兼容macOS、Linux和Windows三大主流操作系统。本文将介绍如何通过Docker安装Ollama,并将其部署以使用本地大模型,同时接入one-api,以便通过API接口轻松调用所需的大规模语言模型。

硬件配置
由于大模型对硬件配置要求非常高,所以机器的配置越高越好,有独立显卡更佳,建议内存32G起步。博主是在一台独立服务器上部署,服务器配置如下:
- CPU:E5-2696 v2
- RAM:64G
- 硬盘:512G SSD
- 显卡:无
备注:我的独立服务器没有显卡,所以只能用CPU来跑。
Docker安装Ollama
Ollama现在已经支持Docker安装,极大的简化了服务器用户部署难度,这里我们使用docker compose工具来运行Ollama,先新建一个docker-compose.yaml,内容如下:

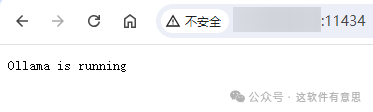
然后输入命令docker compose up -d或者docker-compose up -d运行,运行后访问:http://IP:11434,看到提示Ollama is running就说明成功了,如下图:
 99464807c614b7a2.png
99464807c614b7a2.png
如果您的机器支持GPU,可添加GPU参数支持,参考:https://hub.docker.com/r/ollama/ollama
使用Ollama部署大模型
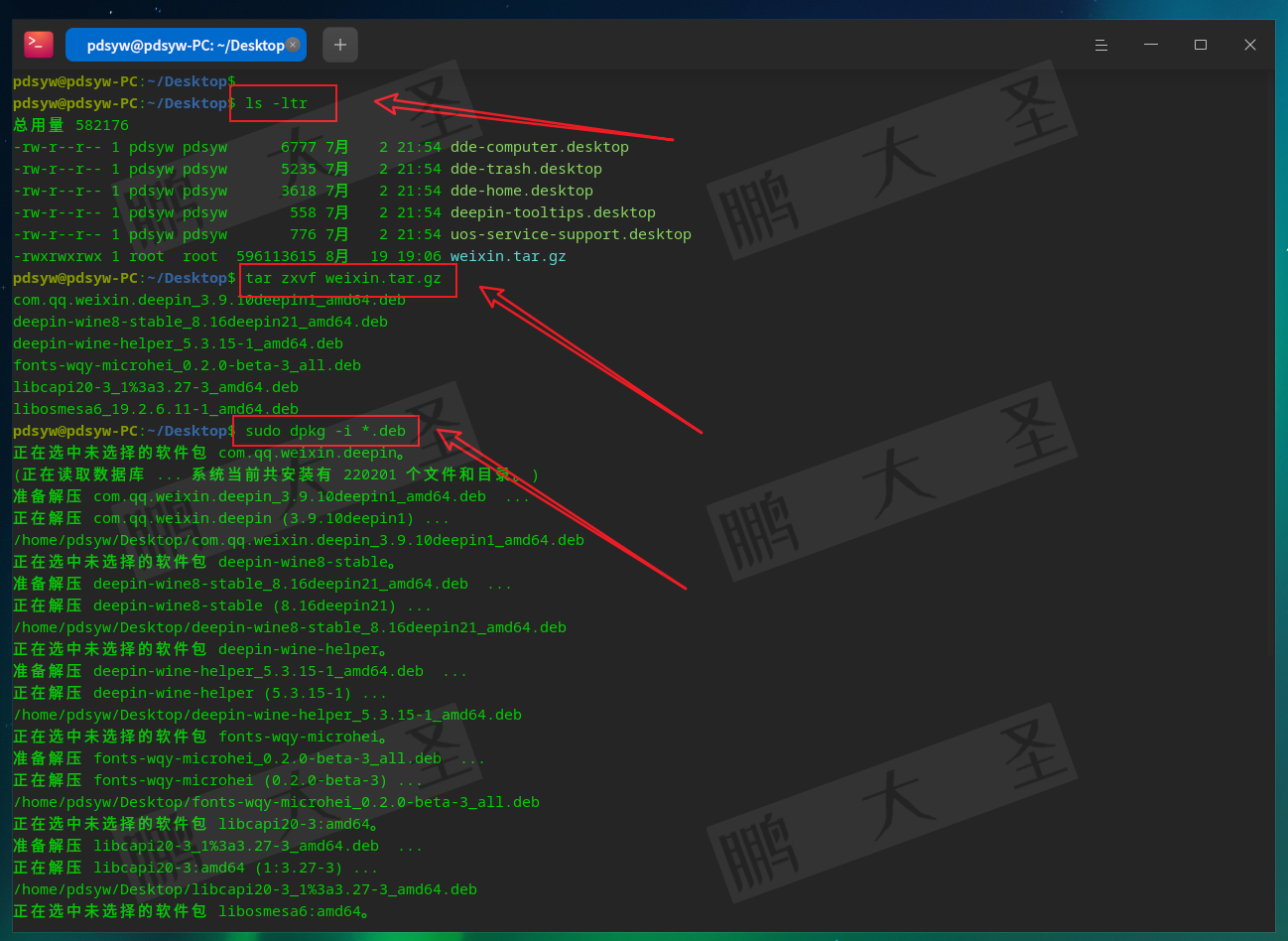
Ollama安装完毕后,还需要继续下载大模型,支持的大模型可以在Ollama官网找到:https://ollama.com/library。Ollama默认没有提供WEB界面,需要通过命令行来使用,先输入命令进入容器:
docker exec -it ollama /bin/bash
进入容器后,去上面官网找到你想要下载的大模型,比如我们下载一个阿里千问2的模型,命令如下:
ollama run qwen2
模型下载并运行完毕后可以通过命令行方式进行对话,如下图:
 a2d6975672604f0a.png
a2d6975672604f0a.png
Ollama常用命令
以下是Ollama一些常用命令:
- 运行一个指定大模型:
ollama run llama3:8b-text - 查看本地大模型列表:
ollama list - 查看运行中的大模型:
ollama ps - 删除本地指定大模型:
ollama rm llama3:8b-text
提示:更多命令也可以输入
ollama -h进行查看。
大模型体验
目前xiaoz下载了llama2/qwen2/glm4/llama3/phi3大模型进行了简单的使用体验,得出一个可能不太严谨和准确的使用感受:
llama模型对中文支持不友好(可以理解,毕竟时国外大模型)phi3:3.8b微软推出的小模型,支持多语言,实测3.8b比较弱智,可能是模型参数太少了,不知道提高到14b会不会好一些glm4/qwen2对中文支持比较友好- 模型参数越小越弱智,从
7b及以上开始基本可以正常理解和对话,更小的模型就经常犯错了 - 我上述配置,纯CPU来跑
7b模型,速度稍微有点慢
将Ollama接入one-api
one-api是一个开源AI中间件服务,可以聚合各家大模型API,比如OpenAI、ChatGLM、文心一言等,聚合后提供统一的OpenAI调用方法。举个例子:ChatGLM和文心一言的API调用方法并不相同,one-api可以对其进行整合,然后提供一个统一的OpenAI调用方法,调用时只需要改变模型名称即可,从而消除接口差异和降低开发难度。
one-api具体安装方法请参考官方项目地址:https://github.com/songquanpeng/one-api
通过one-api后台 >> 渠道 >> 添加一个新的渠道。
- 类型:Ollama
- 渠道API地址:填写Ollama WEB地址,比如
http://IP:11434 - 模型:你在Ollama上已经下载好的本地大模型名称
- 密钥:这个是必填项,由于Ollama默认不支持鉴权访问,所以这里随便填写即可
如下图:
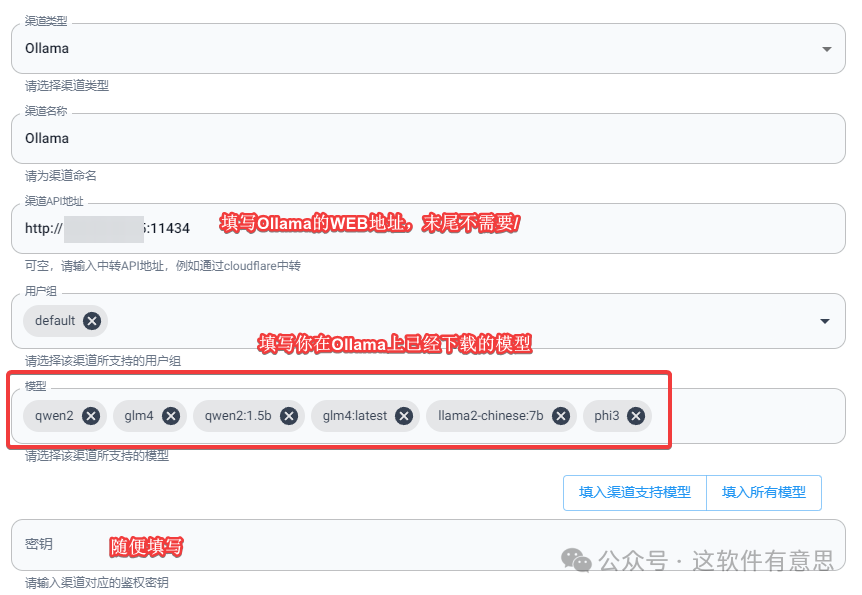 d06d26dfe39e97e6.png
d06d26dfe39e97e6.png
接入后,我们可以请求one-api然后传递具体的模型名称进行调用测试,命令如下:

ai.xxx.com改成你one-api的域名sk-xxx填写你在one-api创建的令牌
如果调用成功,则说明已经成功将Ollama接入到one-api。
遇到的问题
博主尝试使用stream的方式调用one-api Ollama时,返回空白,通过issues发现是one-api BUG导致,目前降级one-api版本为0.6.6解决,期待作者后续修复这个问题。
安全风险
由于Ollama本身没有提供鉴权访问机制,所以Ollama部署到服务器上存在安全隐患,知道你IP和端口的用户都可以进行API调用,非常不安全,生产环境我们大致可通过下面的一些方法来提高安全性。
方法一:Linux内置防火墙
- Docker部署Ollama时改为HOST网络
- 通过Linux内置防火墙限制只能指定IP访问11434端口
方法二:Nginx反向代理
- Docker部署Ollama时,映射IP改为
127.0.0.1 - 然后本机的Nginx反向代理
127.0.0.1:11434,并在nginx上设置黑名单(deny)和白名单(allow)IP
结语
Ollama作为一款开源工具,为用户提供了便捷的本地大模型部署和调用方式,其卓越的兼容性和灵活性使得在多种操作系统上运行大规模语言模型变得更加简易。通过Docker的安装与部署,用户可以快速上手并灵活使用各类大型模型,为开发和研究提供了强有力的支持。然而,由于Ollama缺乏内置的鉴权访问机制,用户在生产环境中应采取适当的安全措施,以防止潜在的访问风险。总的来说,Ollama在推动本地AI模型的应用和开发中,具备了极大的实用价值,未来若能完善鉴权机制,将无疑成为AI开发者的得力助手。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。