目录
表空间文件
表空间文件结构
行格式
Compact 行格式
变长字段列表
NULL值列表
记录头信息
列数据
溢出页
数据页
当我们使用MYSQL存储数据时,数据是如何被组织起来的?索引又是如何组织的?在本文我们将会解答这些问题。
表空间文件
当我们建立一个表后,会生成两个文件:.frm文件,.ibd文件(实际上每个存储引擎下生成的文件不同,本文主要以 InnoDB为例)。假设建立一个名为 test 表,会生成这两个文件:
test.frm
test.ibd.frm 文件用于存储表结构定义的文件。包含了表的列定义、索引定义、约束条件以及其他与表结构相关的元数据信息。
.ibd 文件用于存储表的数据和索引,包含了表的实际数据行以及各种索引数据结构。也叫做表空间文件。
表空间文件负责了实际数据的存储。
表空间文件结构
表空间文件的由以下部分组成:段(Segment),区(Extent),页(Page),行(Row)

段(Segment):
表空间文件由各种段组成,如数据段,索引段,回滚段等。
数据段:存储表的数据,负责实际数据的存储,存储的是B+树索引的叶子节点。
索引段:存储B+树的索引节点,也就是非叶子节点。
回滚段:回滚段实际就是 undolog的存储结构,主要用于存储 undo log 以及管理与事务回滚相关的信息。
区(Extent):
区的存在实际上是为了便于顺序IO,提高IO的效率。
在 InnoDB 中以 B+树 的形式组织数据,无论有没有建立索引,都会默认为主键(如何没有主键会有隐藏主键字段)建立B+索引。
在B+索引的每个节点都是一个页,一个页的大小为 16 KB,而B+树的每一层的节点都会链接为双向链表,使得每一层节点之间逻辑连续,但在物理上并不连续,这就会导致在搜索时会产生大量的随机IO(随机IO速度远小于顺序IO)。
为了解决这一点,MYSQL在有大量数据的表空间时分配空间时会以区为单位分配,一个区的小为 1 MB,远大于一个页的大小,这样同一层节点不仅在逻辑上连续也在物理上连续,搜索时也就不是随机IO而为顺序IO,提升了IO效率。
页(Page):
InnoDB中一个页的大小为 16 KB,页是InnoDB管理资源的最小单位,读取和写入数据时都是页为单位,也就是说即使只读取/写入一行数据也会读取/写入一整个页,实际上这是一种提升IO效率的方式,感兴趣的读者可以搜索一下局部性原理与MYSQL的BufferPool。
页的类型有很多种:数据页,溢出页,undolog页等等,在下文我们会详细解释。
行(Row):
数据库的记录以行为单位存储,不同的格式有不同的存储结构,下面我们来详细了解行的格式。
行格式
在MYSQL中常见的行格式有很多种:
- Compact 行格式
- 这是 MySQL 5.0 版本开始引入的默认行格式。它采用了紧凑的存储方式,对于固定长度的字段,会按照定义的顺序依次存储,节省了存储空间。对于可变长度的字段,会在记录的开头使用额外的字节来记录每个可变长度字段的长度。
- 适用于大多数常规的数据库表,尤其是包含较多固定长度字段的表,能够有效地利用存储空间,提高查询效率。
- Redundant 行格式
- 是 MySQL 5.0 之前的默认行格式。它的存储方式相对简单,每行记录都包含了一些固定的头部信息和字段数据。与 Compact 行格式相比,Redundant 行格式在存储可变长度字段时,使用了更多的空间来记录字段长度信息,因此会占用更多的存储空间。
- 主要用于与旧版本的 MySQL 兼容。如果数据库中存在一些历史表,并且对兼容性有要求,可能会使用 Redundant 行格式。
- Dynamic 行格式
- 从 MySQL 5.7 版本开始引入。它与 Compact 行格式类似,但对于可变长度字段的存储方式有所不同。Dynamic 行格式会将长度超过一定阈值的可变长度字段存储在数据页的外部,只在数据页中保留一个指向外部存储位置的指针,这样可以减少数据页中碎片的产生,提高数据页的利用率。
- 特别适用于包含大文本字段(如 VARCHAR、TEXT 等)或 BLOB 类型字段的表。当这些字段的值较大时,使用 Dynamic 行格式可以有效地避免数据页的分裂和碎片问题,提高数据库的性能。
- Compressed 行格式
- 同样是在 MySQL 5.7 版本引入。这种行格式在存储数据时会对数据进行压缩,以减少存储空间的占用。它使用了 zlib 压缩算法对数据页进行压缩,从而可以大大降低数据在磁盘上的存储量。
- 适用于对存储空间要求较高的场景,如数据仓库或一些需要长期保存大量历史数据的数据库。通过压缩数据,可以减少磁盘 I/O 操作,提高查询性能,同时也降低了存储成本。
Compact 行格式
本文我们主要了解Compact 行格式,Compact 行格式由四部分组成:变长字段列表,NULL值列表,记录头信息,行数据。
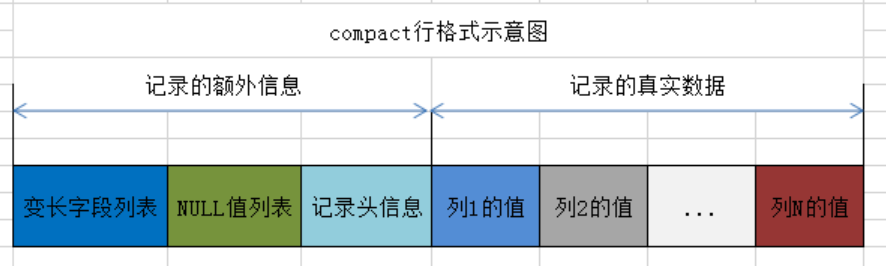
变长字段列表
在MYSQL中存在一些变长字段,比如VARCHAR,TEXT。这些字段的长度并不固定,但长度都记录在变长字段列表中。
变长字段的长度信息会按照列的逆序存储在变长字段列表中。每个变长字段的长度使用 1 个或 2 个字节来表示,具体取决于字段的最大长度和实际长度:
- 字段最大长度小于等于 255 字节:使用 1 个字节来存储该字段的实际长度。
- 字段最大长度大于 255 字节:当实际长度小于 128 字节时,使用 1 个字节存储;当实际长度大于等于 128 字节时,使用 2 个字节存储。
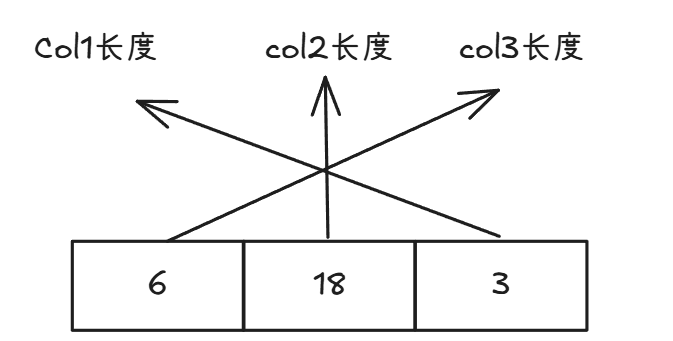
假设有下面一张表
CREATE TABLE test_table (
col1 VARCHAR(10),
col2 VARCHAR(200),
col3 VARCHAR(300)
);当插入一行数据 ('abc', 'defghijklmnopqrst', 'uvwxyz') 时,变长字段列表的存储情况如下:
col3的实际长度为 6 字节,由于其最大长度 300 大于 255 且实际长度小于 128,所以用 1 个字节存储长度 6。col2的实际长度为 18 字节,同理用 1 个字节存储长度 18。col1的实际长度为 3 字节,其最大长度 10 小于等于 255,用 1 个字节存储长度 3。
实际存储情况如下:
这里需要注意如果变长字段为NULL值,变长字段列表不会记录该列的长度信息。
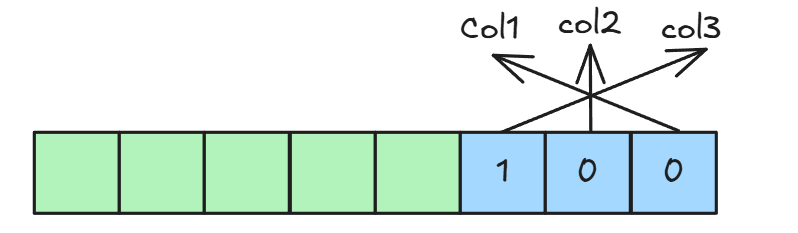
NULL值列表
NULL值列表用于标识行数据中的NULL值,为了节约空间列数据并不存储NULL值,而是由NULL值列表标识是否为NULL。NULL值列表以位为基本单位,一个位标记一个允许为NULL值的列。
- 二进制位的值为
1时,代表该列的值为NULL。 - 二进制位的值为
0时,代表该列的值不为NULL。
NULL值列表的长度是按照字节进行存储,不足一个字节会补足到一个字节。比如,若表中只有 3 个可允许为NULL的列,NULL值列表仍然会占用 1 个字节(8 位),只是高 5 位没有实际意义。与变长列表相同,NULL值列表也是倒序存储。
假设有一个表 test_table 包含三列 col1、col2、col3,且都允许为 NULL:
CREATE TABLE test_table (
col1 INT NULL,
col2 VARCHAR(10) NULL,
col3 DECIMAL(10, 2) NULL
);当插入一行数据,其中 col1 和 col2 为 NULL,col3 有值时,NULL值列表如下:
实际上变长字段列表与NULL值列表并不是任何表中都存在,如果表中所有列都被定义为 NOT NULL,即不允许存储 NULL 值,那么就不会有 NULL 值列表。同理如果表中所有列都是固定长度的数据类型,那么就不需要变长字段列表。
记录头信息
记录头信息存储的是数据记录的一些元数据,主要有以下数据:
| 名称 | 长度 | 说明 |
|---|---|---|
预留位1 | 1 | 目前未使用 |
预留位2 | 1 | 目前未使用 |
delete_mask | 1 | 删除标记位,值为 1 表示该记录已被删除,但还未被真正从磁盘中移除,属于逻辑删除。后续会通过页合并等操作进行物理删除。 |
min_rec_mask | 1 | 仅在 B+ 树的非叶子节点中使用,用于标记该记录是否为最小的记录。 |
n_owned | 4 | 表示该记录拥有的记录数。InnoDB 为了提高记录查找效率,会将页中的记录分组,每组记录有一个带头记录,n_owned 记录了带头记录所在组的记录数量。 |
heap_no | 13 | 表示该记录在页中的堆(Heap)中的位置编号。在 InnoDB 中,新插入的记录会按照一定规则分配一个 heap_no 编号。 |
record_type | 3 | 记录类型,常见取值及含义如下: 0:普通记录 1:B+ 树非叶子节点记录 2:Infimum 记录(页中最小的虚拟记录) 3:Supremum 记录(页中最大的虚拟记录) |
next_record | 16 | 指向下一条记录的相对偏移量。通过 next_record 可以将页中的记录串联成一个单向链表,方便进行记录的遍历和查找。 |
这里重点介绍两个属性:delete_mask,next_record。
delete_mask 是一个一位的标志位,主要用于逻辑删除,当我们执行一个删除操作时,并不会在物理上将行记录删除,只会将记录的 delete_mask 标志位置为 1,表示该记录已被删除。在后续的查询操作中,数据库会忽略 delete_mask 为 1 的记录。
这些被逻辑删除的记录会在后续合适的时机被真正从磁盘中移除,比如在进行页合并、页分裂或者垃圾回收操作时。这样做的可以避免频繁的磁盘 I/O 操作,提高性能。
next_record 是一个长度为 16 位的属性,它存储的是指向下一条记录的相对偏移量。指向的是下一条记录的记录头信息和列数据之间的位置。通过 next_record,InnoDB 将页中的记录串联成一个单向链表,从而方便进行记录的遍历和查找。
列数据
列数据分两部分,一部分为隐藏字段,另一部分即表中各列具体存储的数据。

隐藏字段主要用于MVCC机制,不了解的同学可以参考这篇博客:MYSQL多版本并发控制(MVCC)_支持多版本并发控制-CSDN博客
至此行格式我们介绍完毕,下面我们来了解一下各种页。
溢出页
首先就是溢出页,溢出页是用于存储超过单个页面容量的数据的一种机制。MySQL 的数据存储是以页为单位的,默认页大小通常是 16KB。当某些数据类型(如 TEXT、BLOB 等)存储的内容过长,超过了一个页所能容纳的大小时,就会使用溢出页来存储额外的数据。
溢出页与普通的数据页结构类似,但在存储逻辑上有所不同。在campact格式中,当数据需要溢出时,会在原数据页中保留一部分数据,然后通过一个20位的指针指向溢出页。剩余的数据存放在溢出页中。
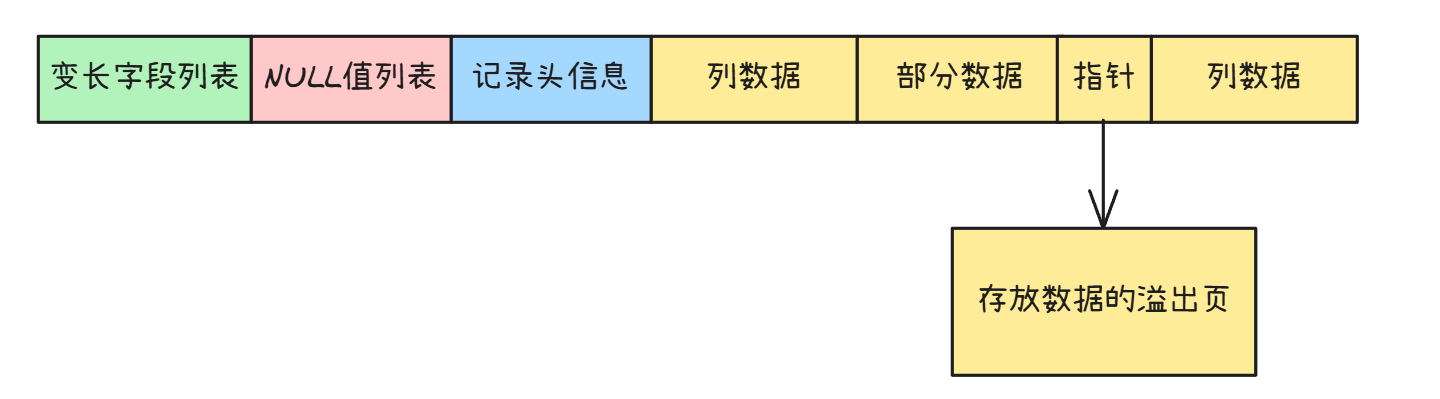
在其他行格式中处理方法类似,但只保留指针,不在原数据页中存放数据:
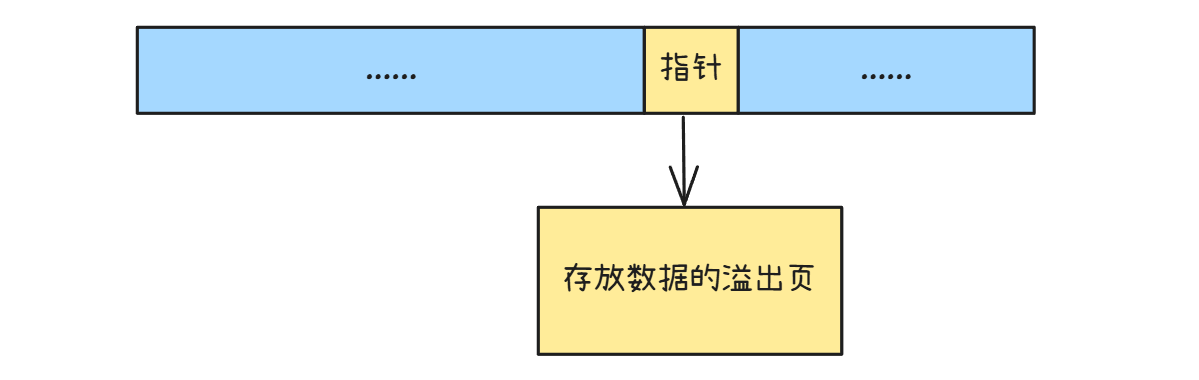
如果一个溢出页放不下,溢出页之间会通过双向链表进行链接,以便能够顺序地访问所有溢出的部分。这样,即使数据分布在多个溢出页上,也可以通过链表结构高效地遍历和读取。
数据页
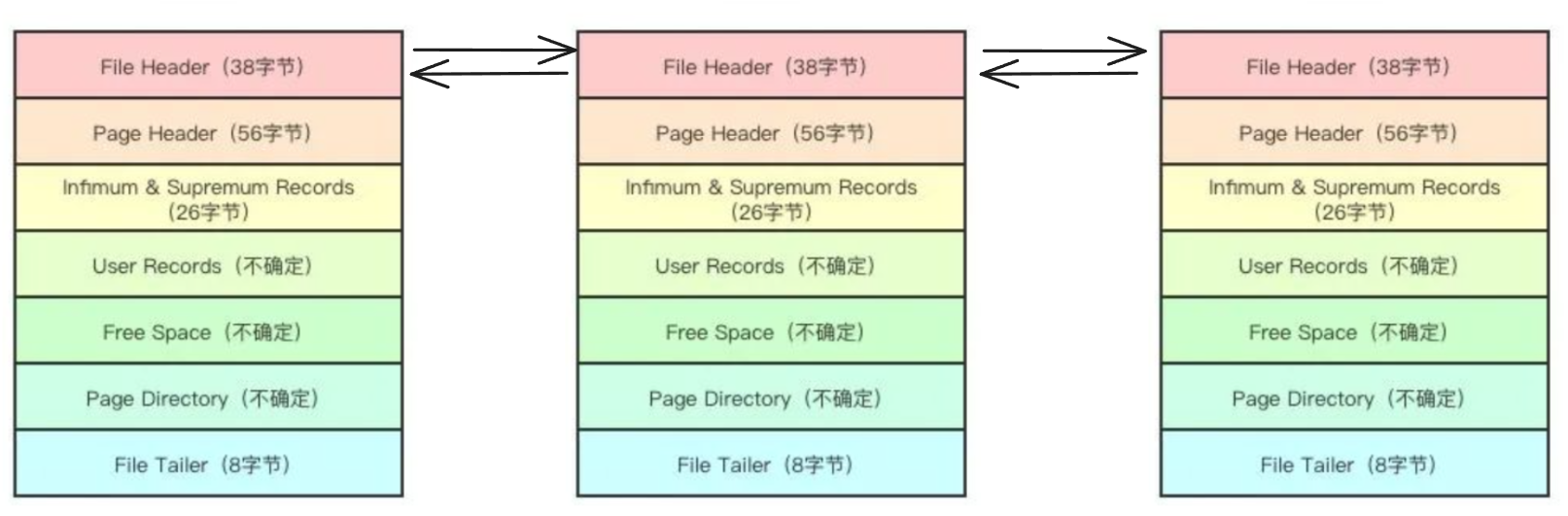
数据页是 InnoDB 存储的基本单位,B+索引一个节点就是一个数据页。数据页的结构如下:

- 文件头部(File Header):包含了一些关于页的通用信息,用于页的管理和识别。
- 页头部(Page Header):记录了页的状态信息和一些与页内数据组织相关的信息。
- 最大和最小记录(Infimum and Supremum Records):虚拟的记录,分别位于页的开头和结尾,用于界定页内记录的范围。
- 用户记录(User Records):实际存储用户数据的部分,这些记录按照主键顺序排列。
- 空闲空间(Free Space):页中尚未被使用的部分,用于存储新插入的记录。
- 页目录(Page Directory):页目录是一个数组,用于快速定位页内的记录。
- 文件尾部(File Trailer):用于校验页的完整性。
文件头部主要有以下字段:页校验和,页号,上一页号和下一页号,页类型。页校验和主要用于校验页的完整性。每个页都有一个唯一的编号,用于在表空间中定位该页。上一页号与下一页号实际上将数据页组成了一个链表结构,使数据逻辑上连续。
在数据页的用户记录中,行数据同样以链表方式按主键大小顺序连接起来。这一点我们在行格式已经结束了,那么如果要在页内检索数据怎么能快速定位呢?肯定有不少同学想到了二分搜索,但实际上行数据是以单链表的形式组织起来的,这时页目录就可以有效帮助进行检索。页目录的结构如下:
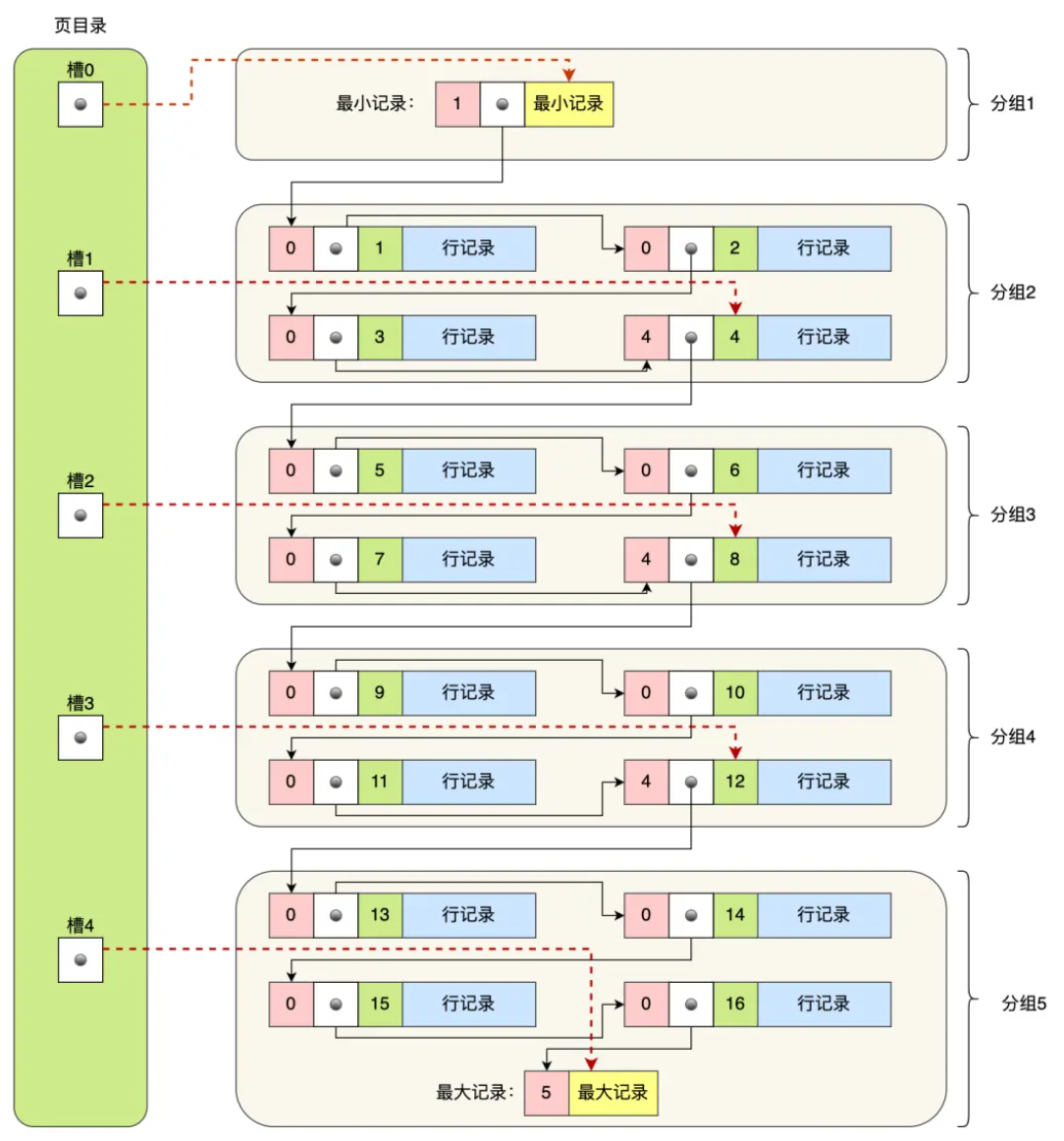
页目录将页内的记录分成若干个组,每个组的最后一条记录的偏移量会被记录在页目录中。通过二分查找页目录,可以快速定位到目标记录所在的组,然后在该组内进行线性查找。
参考:
从数据页的角度看 B+ 树 | 小林coding
MySQL 一行记录是怎么存储的? | 小林coding
![[Windows] 音速启动 1.0.0.0](https://i-blog.csdnimg.cn/direct/d5a80902c1ab40db9761b301723dc765.png)