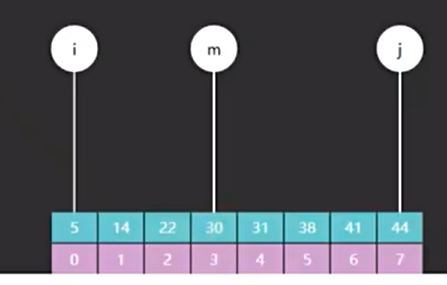
这个算法的前提是,数组是升序排列的
算法描述:
i和j是指针可以表示查找范围
m为中间值
当目标值targat比m大时,设置查找范围在m右边:i =m-1
当目标值targat比m小时,设置查找范围在m左边:j =m+1
当targat的值等于m时,返回m的下标
如果最终没找到就返回-1;
算法实现:
public int birthDay(int[] a,int target){
int i=0;
int j=a.length-1;
while(i<=j){
int m= (i+j)/2;
if(a[m]<target){
// 目标值在右边
i= m-1;
} else if (target<a[m]) {
// 目标值在左边
j = m - 1;
}else if (a[m] == target){
//找到
return m;
}
}
return -1;
}
public static void main(String[] args) {
int targat=4;
a1 a1= new a1();
int a[]= new int[]{2,4,6,8,9};
int num=a1.birthDay(a,targat);
System.out.println(num);
}问题一:为什么是i<=j ,而不是i<j?
因为i 和 j 指向的元素也会参与比较
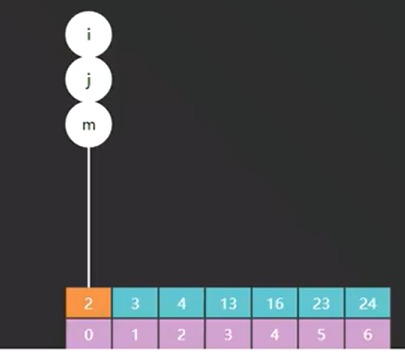
问题二:(i+j)/2有没有问题?
在 Java 中,表达式 int a = (i + j) / 2 的结果是向下取整。整数除法会丢弃小数部分 。但是如果遇到非常大的数字呢?
Integer.MAX_VALUE 是 2147483647,即 int 类型能够表示的最大值。
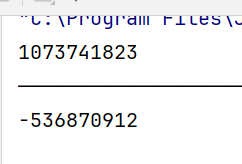
当第一次计算时:i + j 结果是 0 + 2147483647 = 2147483647。
当第二次计算时:i = 1073741824 和 j = 2147483647。
i + j 结果是 1073741824 + 2147483647 = 3221225471。
3221225471这个数字超过了整型能够表示的最大值,所以变成了负数:
public static void main(String[] args) {
int i= 0;
int j=Integer.MAX_VALUE;
int m=(i+j)/2;
System.out.println(m);
System.out.println("————————————————————————————————————————————");
i= m+1; //结果在右边
m= (i+j)/2;
System.out.println(m);
}
>>>移位运算符解决:
>>> : 将二进制数的每一位向右移动一位,丢弃最右边的位,同时在最左边填充零。
使得结果变为正整数
2^7 ------> 2^6 就可以代替/2
例如:
1001 =9
移位后:
0100 = 4
int类型范围解释:
在 32 位带符号整数中,最高位是符号位,0 表示正数,1 表示负数。
剩下的 31 位用于表示数值。
int整型数据类型有32位,因此,数据的范围不带符号可表示为【0,2^32】;
数据的范围带符号可表示为【-2^31,2^31-1】,那么这里我们为什么要减一呢?因为带符号时,一个符号占位也是一位byte。
那负数为啥不-1????
Java 的 int 类型范围是从 -2^31 到 2^31 - 1
是求补码的步骤:
- 确定原码:首先,写出整数的原码(即正数的二进制表示)。
- 取反:将原码中的每一位取反(0 变 1,1 变 0)。
- 加一:在取反后的结果上加 1,得到补码。
线性查找代码:
找到返回索引,找不到返回-1
这个和二分法比起来明明这个线性查找代码更加简洁明了,为什么要使用二分法呢?
public int LinearSearch(int[] a, int target){
for (int i = 0; i<a.length;i++){
if(a[i]==target){
return i;
}
}
return -1;
}
}事前分析法:
因为每个人电脑配置都不一样,所以运行时间是不一样的,所以运行时间不能评判算法的好坏,所以我们需要在运行前分析一下算法。
线性查找代码分析:
1.最差执行情况
2.假设每行语句的执行时间一样
当元素个数是n时:
最坏情况是查找到最后都没找到,所以 最坏情况return i;语句执行0次
| 数据元素个数n | 执行次数 |
| int i = 0; | 1 |
| i<a.length; | n+1 |
| i++ | n |
| a[i]==target | n |
| return -1; | 1 |
public int LinearSearch(int[] a, int target){
for (int i = 0; i<a.length;i++){
if(a[i]==target){
return i;
}
}
return -1;
}
}语句执行总次数:3n+3
二分法代码分析:
最差情况:查找范围在右侧,并且没找到
当元素个数是n时:
已经确定的执行语句和次数:
int i=0; 1
int j=a.length-1; 1
return -1; 1
public int birthDay(int[] a,int target){
int i=0;
int j=a.length-1;
while(i<=j){
int m= (i+j) >>> 1;
if(a[m]<target){
i= m-1;
} else if (target<a[m]) {
j = m - 1;
}else if (a[m] == target){
return m;
}
}
return -1;
}
eg: target=9 [2,3,4,5] 查找次数为 3 也就是说while循环执行了三次
不能得出整数,就向下取整
eg:log2(7)=2.x 就等于2
| 元素个数 | 循环次数 | |
| 4-7 | 3 | floor(log_2(4)) =2 +1 |
| 8-15 | 4 | floor(log_2(8)) =3 +1 |
| 16-31 | 5 | floor(log_2(16)) =4 +1 |
| 32-63 | 6 | floor(log_2(32)) =5 +1 |
得出规律:n为元素个数
循环次数L:floor(log_2(n)) +1
| 循环语句: | 循环次数 | |
| i<=j | L+1 | |
| int m= (i+j) >>> 1; | L | |
| a[m]<target | L | |
| target<a[m] | L | |
| j = m - 1; | L |
语句执行总次数:5L+4
(floor(log_2(n)) +1 )*5 + 4
化简一下:f(n)=5*log_2(n)+9
对比图象发现:当数据量大的时候还是二分法的执行次数少
时间复杂度O
抛开硬件软件,只考虑算法本身
如何表示时间复杂度??
- 线性查找算法的函数:fn=3*n+3
- 二分查找算法的函数:fn=floor(log_2(n))*5 +4
因为我们得出的这两个函数比较复杂,不能让人一眼就看出,所以我们要对fn进行化简,找到一个与它变化趋势相近的表示法
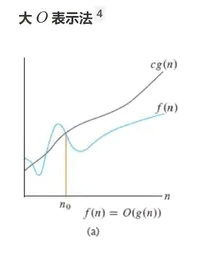
这里:
- c1代表一个常数
- f(n)时实际执行代码行数与n的函数
- g(n)经过花间,变化趋势与f(n)一致的函数
渐进上界:g(n)代表的是最差的一种情况
| 例一:
|
| 例二:
|
已知f(n),求g(n)
- 表达式中相乘的常量可以省略: fn = 3*n+3省略 3
- 多项式中数量规模更小的表达式(低次项): fn = n³+n² 中的n² 因为n²的变化远小于n³
- 不同底数的对数
渐进下界和渐进紧界:
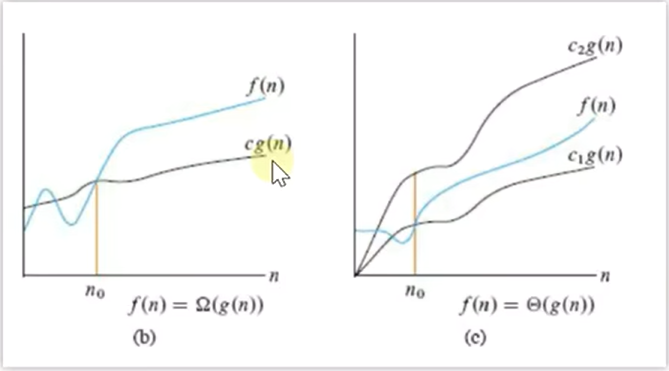
渐进下界:最优情况 Ω欧米噶
渐进紧界:两种情况都能代表 theta
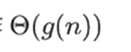
时间复杂度从低到高:
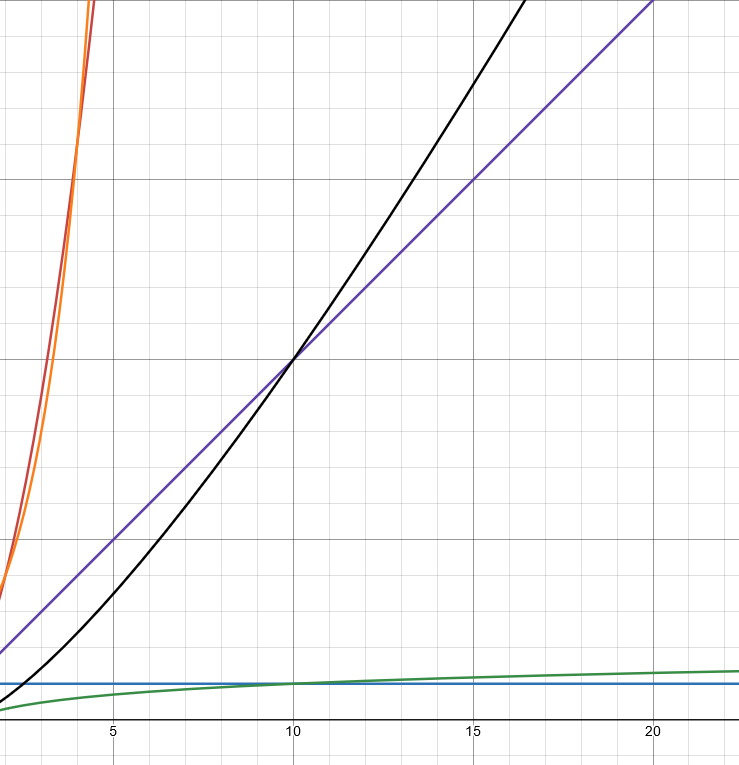
对应颜色:

空间复杂度:
用O表示:衡量一个算法,随着数据规模的增大,占用的额外空间成本
- 固定部分:与输入规模无关的内存空间,如固定数量的变量、常量、常数空间等。
- 可变部分:随着输入规模变化而变化的内存空间,如动态分配的数组、递归调用栈空间等。
二分查找:
需要常数个指针i,j,m,因此额外占用的空间是O(1)
public int birthDay(int[] a,int target){
int i=0;
int j=a.length-1;
while(i<=j){
int m= (i+j)/2;
if(a[m]<target){
i= m-1;
} else if (target<a[m]) {
j = m - 1;
}else if (a[m] == target){
return m;
}
}
return -1;
}