背景
由于日常工作需要对接各种第三方合作方,对接过程中的文档繁多、沟通不及时、问题排查繁琐以及工作具有重复性等问题愈发明显。合作方遇到对接问题需要提工单经门户网站–>产品部门接口人–>开发人员问题排查/修复–>产品部门接口人–>合作方收到回复,这种模式联调、验收流程较长。
考虑到前期对接过程中积累的问题日志、对接规范、指导手册、接口文档,如何让开发、产品、运营以及合作方有效利用这些知识?首先就想到了大模型,它具有强大的自然语言理解和文档整理能力,但其缺少对接流程的垂类领域知识?于是想到了RAG(检索增强生成技术)给两者建立了桥梁!
1. RAG技术介绍
RAG (Retrieval-Augmented Generation) 是一种结合了检索和生成的混合式深度学习模型,常用于处理复杂的自然语言处理任务。RAG模型通过将外部知识库中的信息与生成模型结合在一起,可以提供更准确和上下文相关的答案。具体来说,RAG由两个部分组成:
-
检索模块:负责从预先建立的知识库中检索与输入问题最相关的文档或信息片段。这通常通过向量检索技术实现,向量检索能够支持语义匹配,而不仅仅是关键词匹配,从而提高了检索的准确性。
-
生成模块:接收检索到的内容并生成最终的自然语言响应。这个模块通常基于大型生成模型(如 GPT-4),能够理解和生成复杂的自然语言。
这种技术的优势在于它能够利用海量的外部数据进行知识补充,从而提升回答的质量和准确性。这在动态性强、知识库更新频繁的场景中尤为重要。

2. RAG搭建常见流程
在实际应用中,搭建一个基于 RAG 的知识库通常包括以下几个步骤:
- 文档加载,并按一定条件切割成片段;
- 将切割的文本片段灌入向量数据库;
- 封装检索接口;
- 构建调用流程:Query -> 检索 -> Prompt -> LLM -> 回复。
3. 编码实现
下面用极少的代码快速搭建一个RAG系统,包括服务端和web界面,仅用于demo展示,生成级的 RAG 系统要复杂的多的多。
项目结构
核心代码
如果纯自己编码实现 RAG,小一千行代码是要的,这里只能借助成熟的大模型开发框架来简化开发过程,把重心放到流程上去,本例使用了 LangChain,关键代码给出注释,可自己咨询大模型进行理解和改进。
LangChain:一套在大模型能力上封装的工具框架(SDK),它为开发者提供了一系列工具和组件,以简化语言模型在复杂任务中的集成和应用,尤其是涉及到多步骤的流程和需要结合外部数据源的场景。
import uvicorn
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from dotenv import load_dotenv, find_dotenv
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.prompts import ChatPromptTemplate
from starlette.middleware.cors import CORSMiddleware
# 加载环境变量,读取本地 .env 文件,里面定义了 OPENAI_API_KEY
_ = load_dotenv(find_dotenv())
# llm
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 加载文档,可换成PDF、txt、doc等其他格式文档
loader = TextLoader('../docs/解答手册.md', encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_language(language="markdown", chunk_size=200, chunk_overlap=0)
texts = text_splitter.create_documents(
[documents[0].page_content]
)
# 选择向量模型,并灌库
db = FAISS.from_documents(texts, OpenAIEmbeddings(model="text-embedding-ada-002"))
# 获取检索器,选择 top-2 相关的检索结果
retriever = db.as_retriever(search_kwargs={"k": 2})
# 创建带有 system 消息的模板
prompt_template = ChatPromptTemplate.from_messages([
("system", """你是一个对接问题排查机器人。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
请用中文回答用户问题。
已知信息:
{context} """),
("user", "{question}")
])
# 自定义的提示词参数
chain_type_kwargs = {
"prompt": prompt_template,
}
# 定义RetrievalQA链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 使用stuff模式将上下文拼接到提示词中
chain_type_kwargs=chain_type_kwargs,
retriever=retriever
)
# 构建 FastAPI 应用,提供服务
app = FastAPI()
# 可选,前端报CORS时
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
# 定义请求模型
class QuestionRequest(BaseModel):
question: str
# 定义响应模型
class AnswerResponse(BaseModel):
answer: str
# 提供查询接口 http://127.0.0.1:8000/ask
@app.post("/ask", response_model=AnswerResponse)
async def ask_question(request: QuestionRequest):
try:
# 获取用户问题
user_question = request.question
print(user_question)
# 通过RAG链生成回答
answer = qa_chain.run(user_question)
# 返回答案
answer = AnswerResponse(answer=answer)
print(answer)
return answer
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
运行环境
代码采用 python3.11 版本运行,并安装了如下依赖:
# pip install -r requirements.txt
fastapi==0.112.1
langchain==0.2.14
langchain_community==0.2.12
langchain_openai==0.1.22
langchain_text_splitters==0.2.2
pydantic==2.8.2
python-dotenv==1.0.1
Requests==2.32.3
starlette==0.38.2
uvicorn==0.30.6
QA准备
按照自己熟悉的文档组织方式组织QA,并按照业务需求选择是将Q向量化,还是将QA一起向量化,本例采用如下格式组织QA,并且QA一起向量化。
### xx接口不通怎么办
请首先确认接口地址以及鉴权参数,可找coderjia进行排查
效果展示
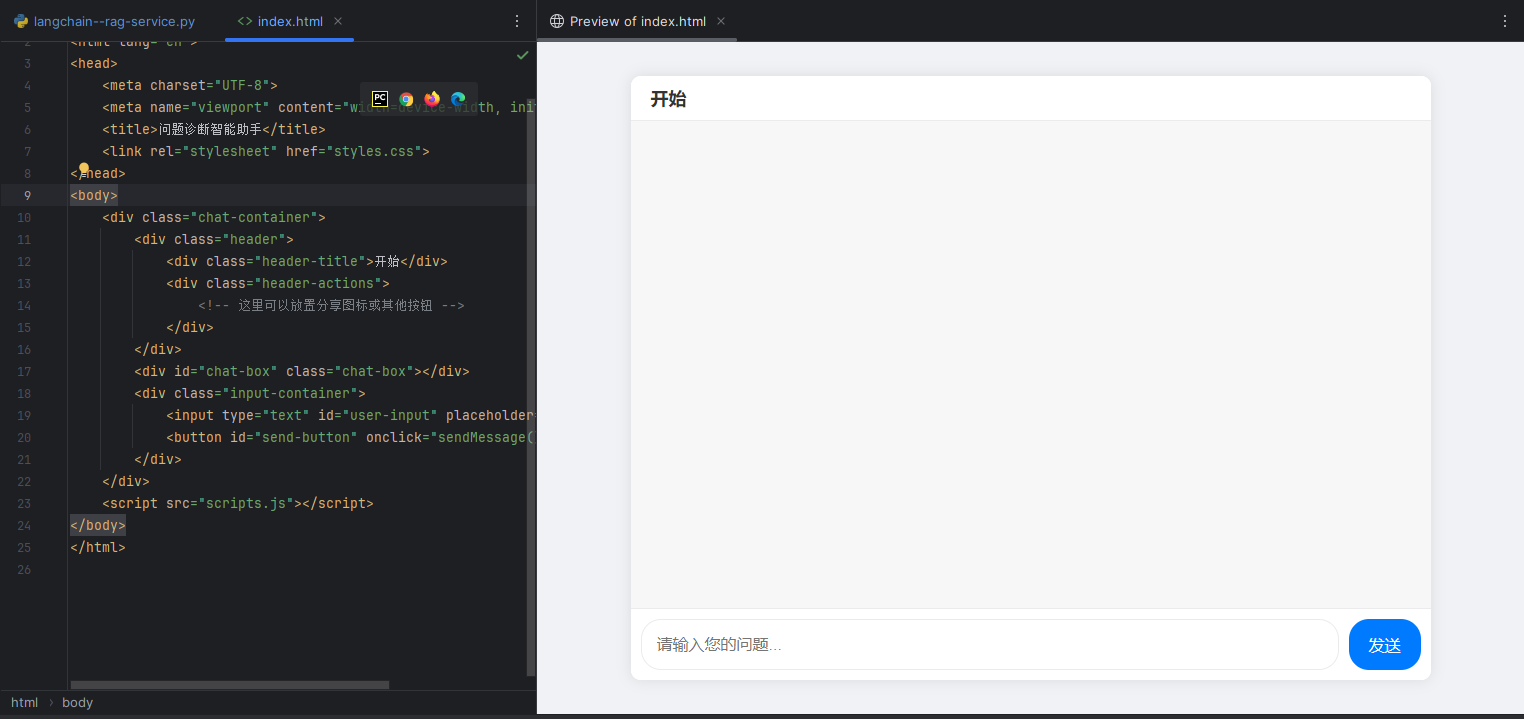
简陋的客户端界面:
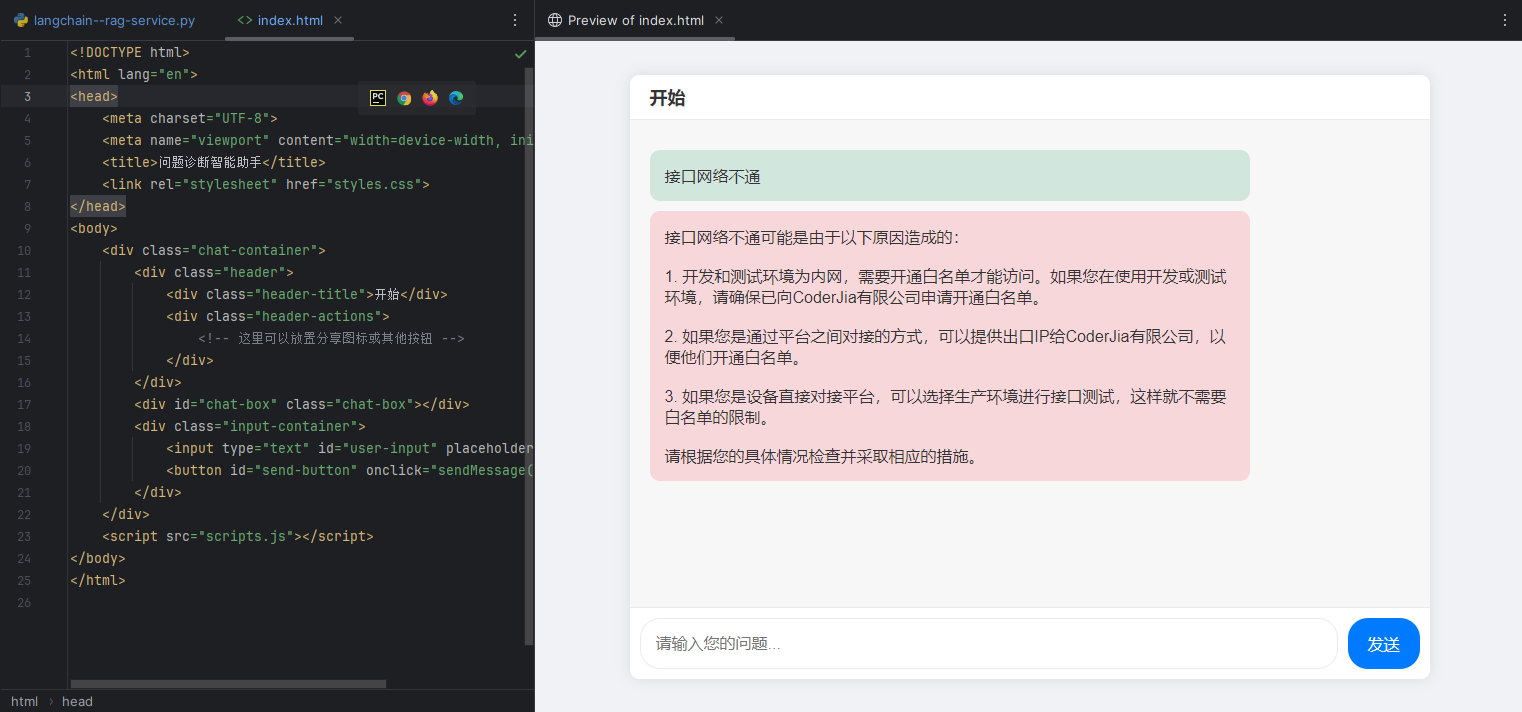
咨询知识库存在的知识:
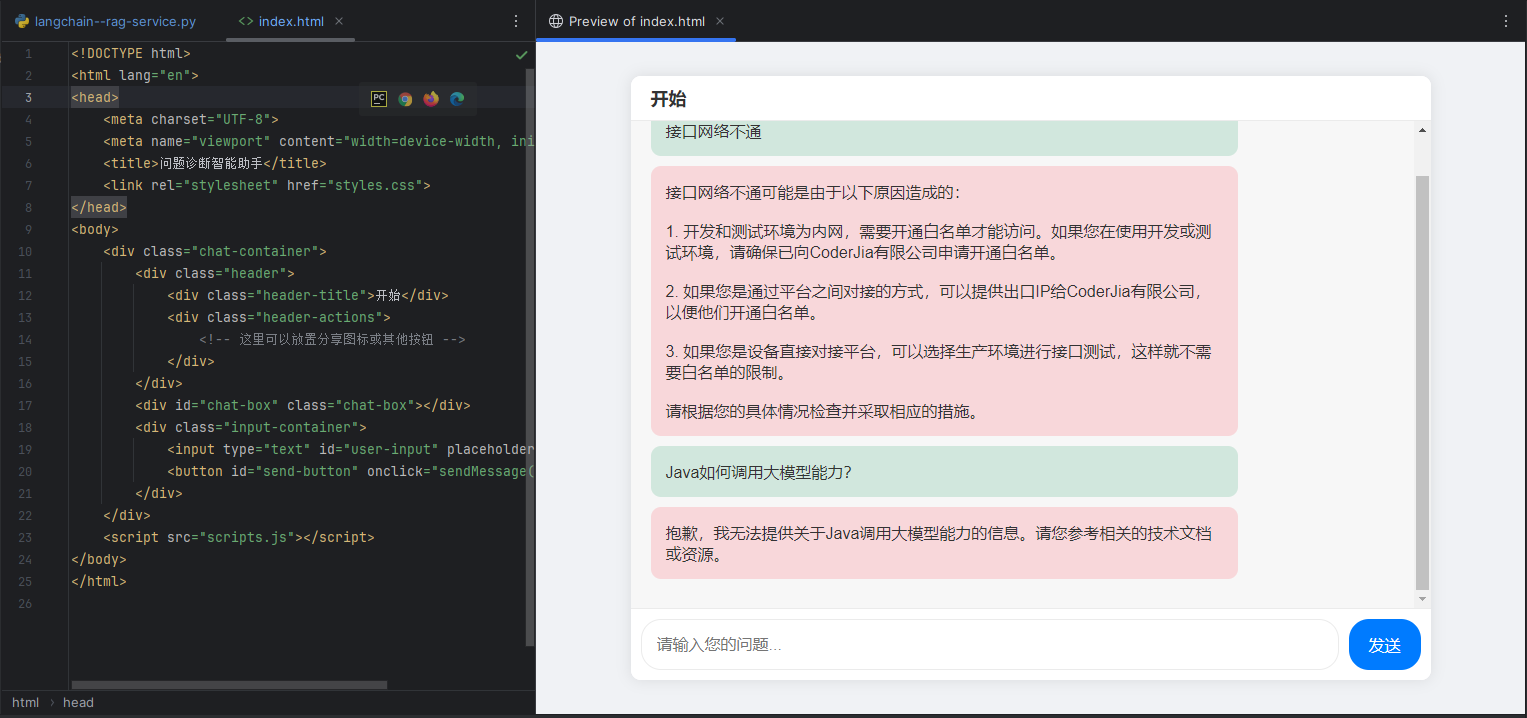
咨询知识库不存在的知识:
4. 总结与优化点
以上只是搭建搭建基于RAG的知识库最基本的步骤,实际应用时,有几点优化建议:
-
知识库的动态更新:随着时间的推移,知识库中的信息可能会过时或无效,因此需要设计自动化的知识更新机制,以保证系统回答的准确性和时效性。
-
模型微调:在不同的应用场景中,可能需要对调用的模型进行选择,或者对提示词进行优化,来引导模型生成更符合预期的输出。
-
混合检索策略:可以结合向量检索与传统的关键词检索策略,在保证检索精度的同时,提高召回率。
-
系统可扩展性:确保系统能够随着数据量和请求量的增加而扩展,避免性能瓶颈。使用分布式检索和生成技术是实现这一目标的关键。
-
用户反馈循环:引入用户反馈机制,定期分析用户的查询和系统的响应,持续改进模型和知识库,提升整体系统的智能水平。
更符合预期的输出。



















