10个帮助你完全理解数据集的Pandas 函数
长按关注《Python学研大本营》,加入读者群,分享更多精彩 扫码关注《Python学研大本营》,加入读者群,分享更多精彩
Pandas是用于探索性数据分析 (EDA)的最佳 Python 模块。
许多初级数据科学家认为他们需要处理的大部分问题都来自花哨的深度学习模型。
然而,实际上,很多问题都来自数据。
探索和清理数据听起来很无聊,而且不像训练最先进的 AI 模型那么酷。但如果你想成为一名专业的数据科学家,探索性数据分析和数据预处理也是必不可少的技能。
幸运的是,有许多很棒的工具可以帮助您了解数据集。著名的 Python 数据处理模块 Pandas 就是其中之一。
本文将介绍 Pandas 的 10 个超级有用的功能,这些功能经常用于探索性数据分析目的。
首先,让我们导入 Pandas 模块并使用著名的“ Netflix Movies and TV Shows ”数据集作为示例数据制作一个 DataFrame。
(https://www.kaggle.com/datasets/shivamb/netflix-shows?resource=download)
import pandas as pd
df = pd.read_csv('netflix_titles.csv')
1. head() 或 tail():检查 DataFrame的前五行 或最后五行
当您收到一个新数据集时,没有什么比直接查看数据表更直观的了。
但是,有时数据集太大而无法逐行遍历。通过检查 DataFrame 的前 5 行或后 5 行来获得第一印象是个好主意。至少,它可以帮助您了解数据的基本结构。
在 Pandas 中,head()和tail()函数用于此目的:
df.head()

执行 head() 函数的结果
df.tail()

tail() 函数的执行结果
2.形状:了解行数和列数
因为 Pandas DataFrame 是一个二维表。这张表格的“形状”对我们来说是重要的信息。我们可以直接通过shape属性获取:
df.shape
输出是:
(8807, 12)
它告诉我们这个数据集有 8807 行和 12 列。
3. columns:列出所有的列名
该columns属性可以告诉您 DataFrame 的所有列的名称。
df.columns
输出是:
Index(['show_id', 'type', 'title', 'director', 'cast', 'country', 'date_added','release_year', 'rating', 'duration', 'listed_in', 'description'],dtype='object')
4. index:获取索引的范围
同样,您可以通过该index属性了解 DataFrame 的索引范围:
df.index
它将打印以下信息:
RangeIndex(start=0, stop=8807, step=1)
5. info():获取有关 DataFrame 的更多详细信息
Pandas 中还有另一个函数可以为您提供有关 DataFrame 的更多详细信息 - info().
df.info()
执行上述函数后的结果如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8807 entries, 0 to 8806
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 show_id 8807 non-null object
1 type 8807 non-null object
2 title 8807 non-null object
3 director 6173 non-null object
4 cast 7982 non-null object
5 country 7976 non-null object
6 date_added 8797 non-null object
7 release_year 8807 non-null int64
8 rating 8803 non-null object
9 duration 8804 non-null object
10 listed_in 8807 non-null object
11 description 8807 non-null object
dtypes: int64(1), object(11)
memory usage: 825.8+ KB
6. describe():数值列的基本统计分析
如果某一列的数据是数值型的,我们可以通过该describe()函数得到一些基本但重要的统计指标,比如均值/最小值/最大值、标准差等。
df.describe()
上述代码的结果如下:
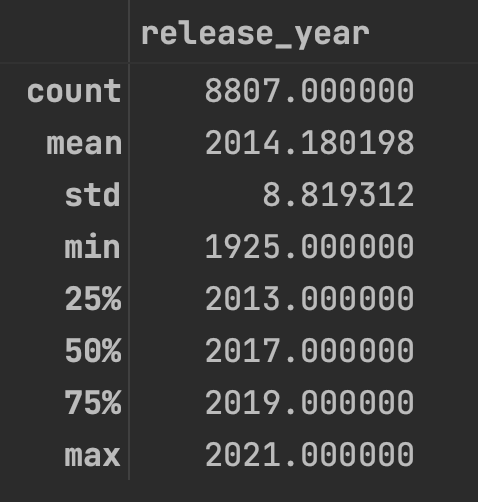
Pandas DataFrame 的“describe”函数的结果
7. isna():检测DataFrame的缺失值
处理缺失值是一件令人头疼的事情。好消息是 Pandas 有一个功能可以帮助我们方便地检测缺失值—— isna().
df.isna()
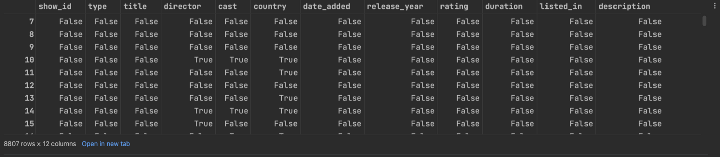
Pandas isna() 函数的结果
如上所示,该isna()函数将返回一个 DataFrame,其中包含与原始 DataFrame 大小相同的布尔值。所有为NA值的单元格,例如None或numpy.NaN将是True。和其他单元格会False。
有时,返回相同大小的大型 DataFrame 并不是一个好主意。我们可以在方法any()之后添加函数isna()来了解列是否包含NA值:
df.isna().any()
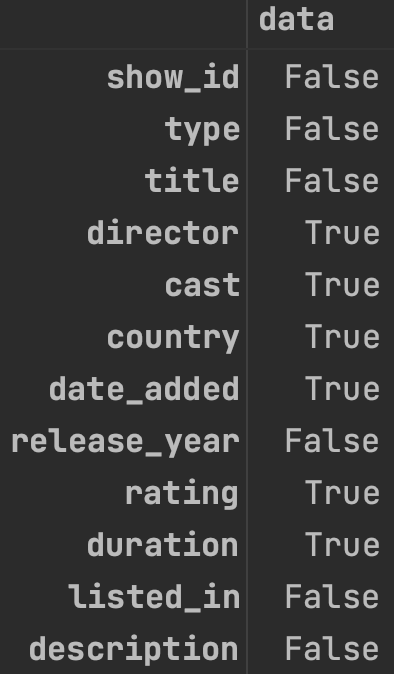
isna().any() 函数的结果
顺便说一下,isnull()函数是Pandas中isna()函数的别名,它们的工作方式相同。
当然,notna()功能是相反的。它是检测现有(非缺失)值。
8. unique():获取一列的所有唯一值
对于分类列,最好知道它的所有不同值。该unique()功能可以为您提供预期的结果。
例如,我们想知道该country列的所有唯一国家名称:
df.country.unique()
结果是:
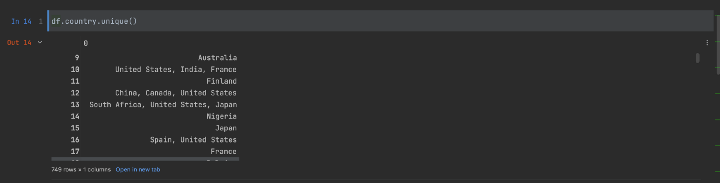
执行Pandas“独特”功能的结果
9. value_counts():获取DataFrame中唯一值的计数
此外,如果我们想知道分类列的每个不同值的计数,我们可以使用以下value_counts()方法:
df.value_counts('country')
同样,让我们执行上面的代码:
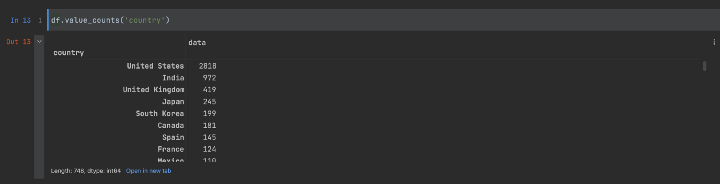
运行 value_counts() 函数的结果
10. query():随心所欲地探索 DataFrame
对于更复杂的数据探索任务,query()函数是终极工具。借助它,您可以像使用 SQL 查询数据库表一样方便地查询 Pandas DataFrames。
例如,让我们执行一个简单的查询:
df.query('release_year>=2021')
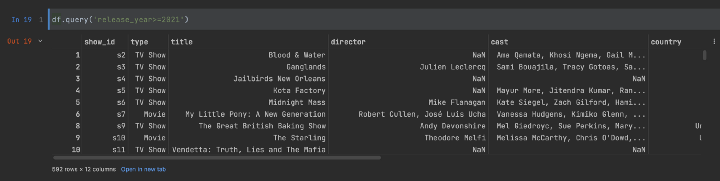
查询结果
您甚至可以添加多个条件:
df.query('release_year>=2021 & type=="Movie"')
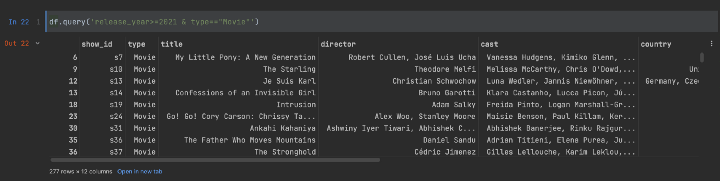
多条件查询结果
推荐书单
《Pandas1.x实例精解》

本书详细阐述了与Pandas相关的基本解决方案,主要包括Pandas基础,DataFrame基本操作,创建和保留DataFrame,开始数据分析,探索性数据分析,选择数据子集,过滤行,对齐索引,分组以进行聚合、过滤和转换,将数据重组为规整形式,组合Pandas对象,时间序列分析,使用Matplotlib、Pandas和Seaborn进行可视化,调试和测试等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。 本书适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
链接(双十一半价):https://u.jd.com/UKjx4et
精彩回顾
《Pandas1.x实例精解》新书抢先看!
【第1篇】利用Pandas操作DataFrame的列与行
【第2篇】Pandas如何对DataFrame排序和统计
【第3篇】Pandas如何使用DataFrame方法链
【第4篇】Pandas如何比较缺失值以及转置方向?
【第5篇】DataFrame如何玩转多样性数据
【第6篇】如何进行探索性数据分析?
【第7篇】使用Pandas处理分类数据
【第8篇】使用Pandas处理连续数据
【第9篇】使用Pandas比较连续值和连续列
【第10篇】如何比较分类值以及使用Pandas分析库
长按关注《Python学研大本营》
长按二维码,加入Python读者群
扫码关注《Python学研大本营》,加入读者群,分享更多精彩