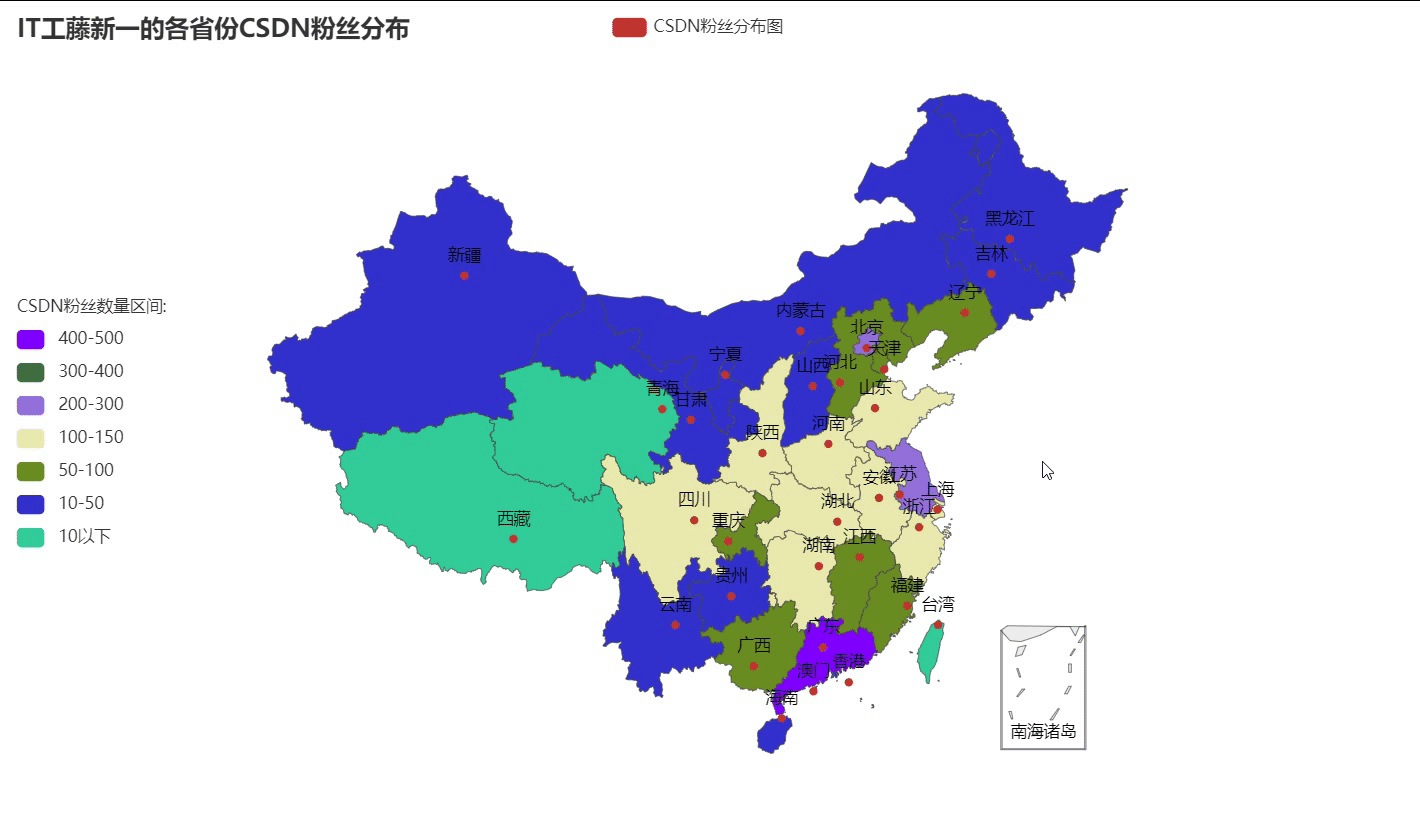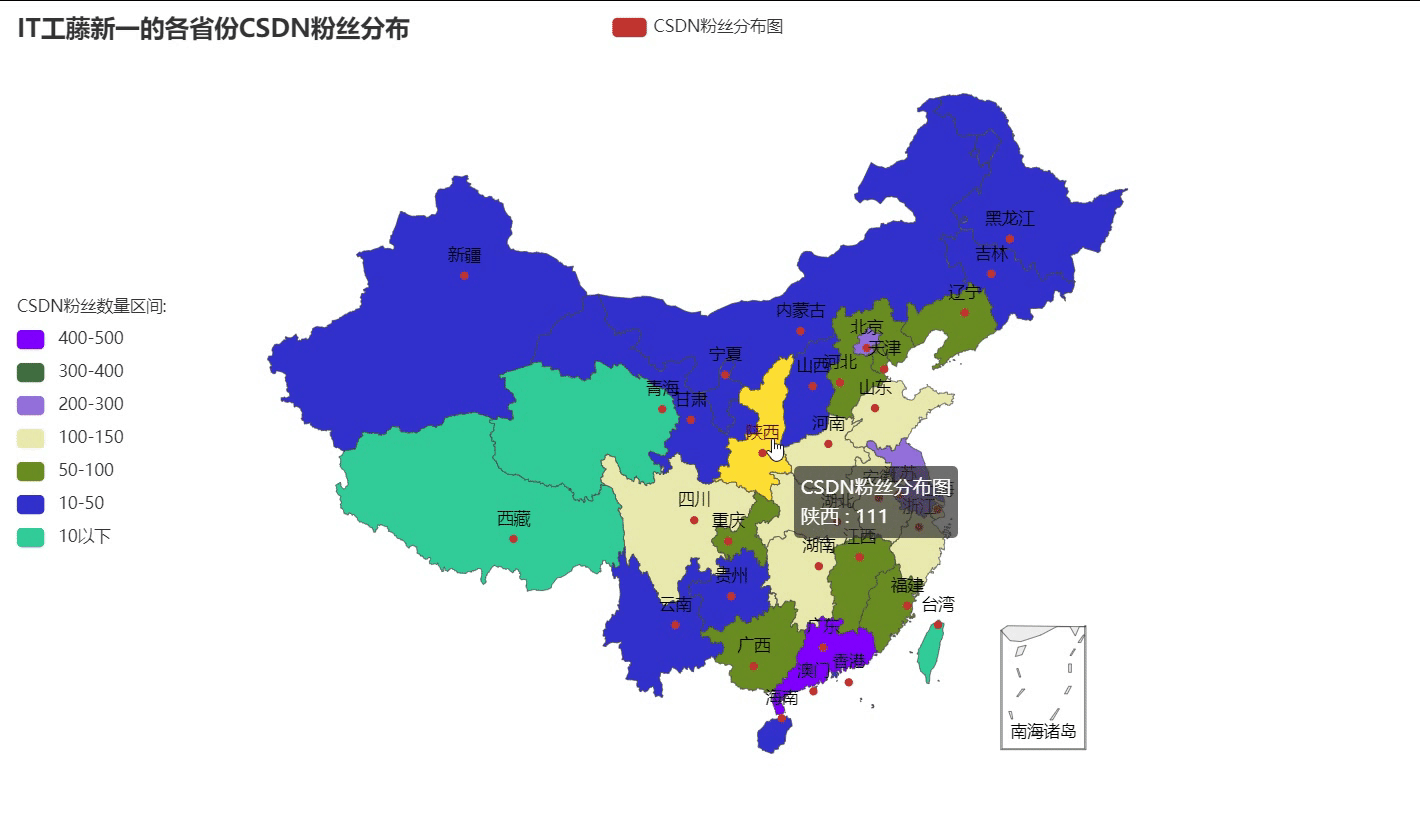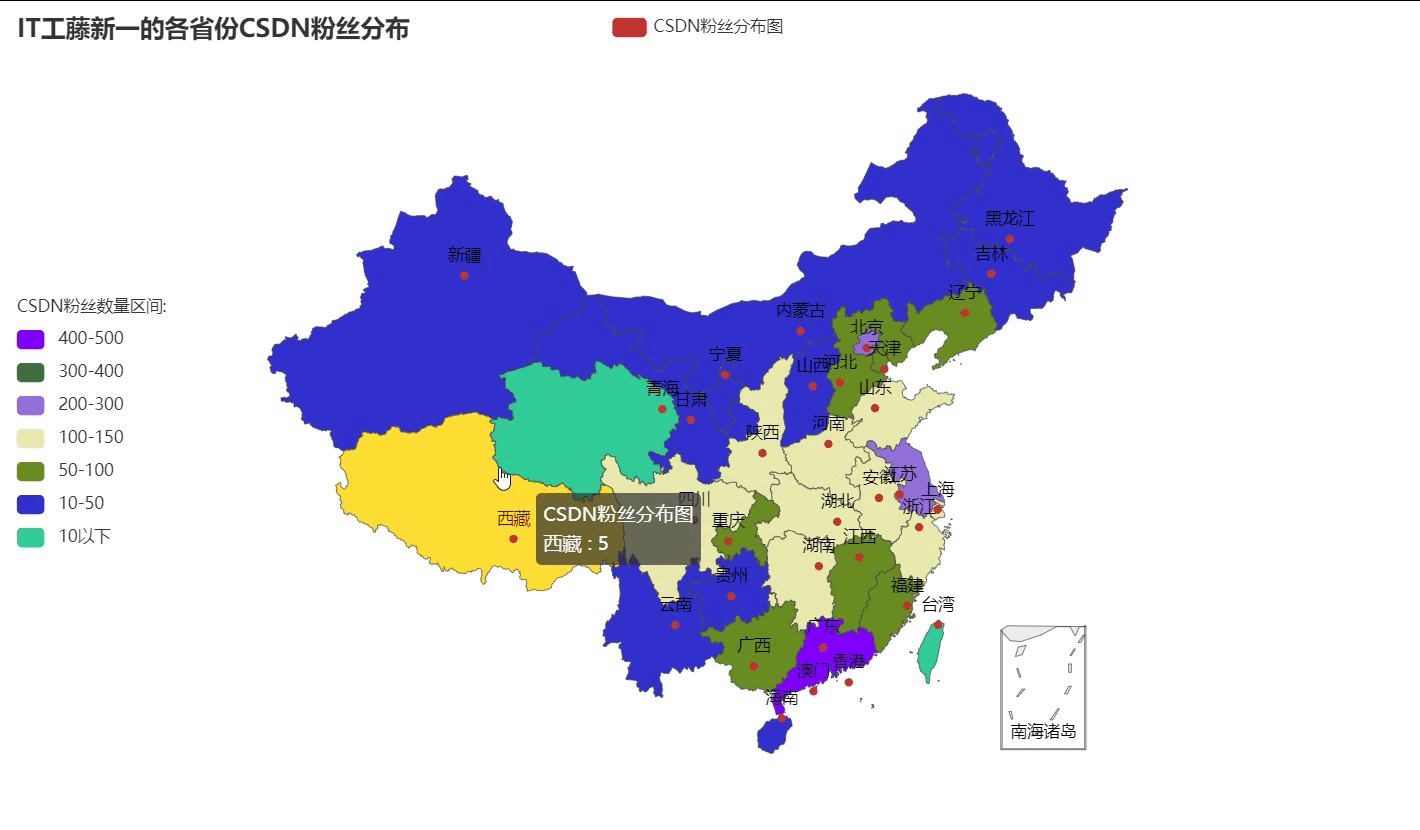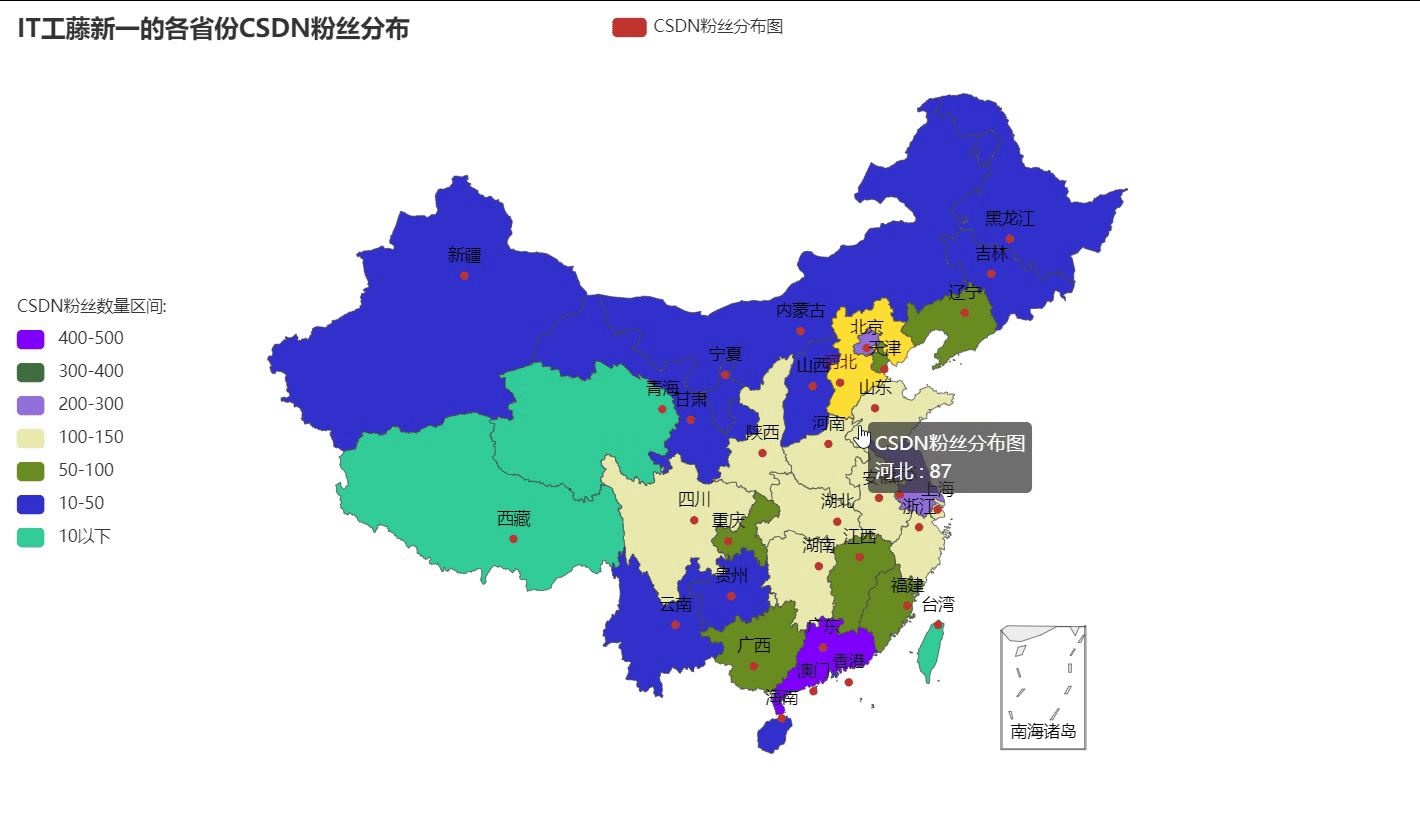
一、什么是DOM树
DOM树是一种结构,树是由DOM元素和属性节点组成的,DOM的本质是把html结构化成js可识别的树模型,有了树模型,就有了层级结构,层级结构是指的是元素和元素之间的关系父子、兄弟。
实例:
我的标题
我的链接二、使用BeatuifulSoup进行页面内容的获取
什么是BeatuifulSoup?
BeautifulSoup是一个Python库,用于解析HTML和XML文档中的数据(结构化数据)。
流程:
①浏览并检查网站/网页
要使用开发者工具导航,右键单击该网页,选择检查。
②创建用户代理
用户代理是客户端(通常是Web浏览器),用于代表用户向Web服务器发送请求。当从同一台机器/系统一次又一次地获取自动化请求时,Web服务器可能会猜测该请求是自动化发送的。它会阻止了该请求。因此,我们可以使用用户代理来伪造浏览器,访问特定网页,从而使服务器认为请求来自原始用户,而不是机器人。
# 创建 User-Agent (可选)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}# 将User-Agent作为参数与get()请求一起传递
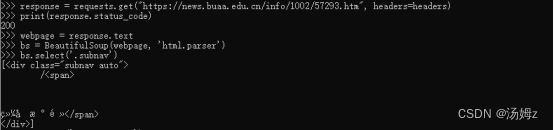
response=requests.get("https://news.buaa.edu.cn/info/1002/57293.htm",headers=headers)
③导入请求库
Requests 请求库允许我们发送 get 请求到Web服务器。
运作方式如下:
import requests 该库以一种易于处理的格式,处理从服务器请求网站的细节。
使用 requests.get(…) 方法访问网站,并将URL 作为参数传递, 以便函数知道要访问的位置。
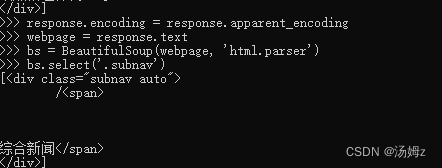
访问get请求的实际主体(返回值是一个请求对象,它还包含一些有用的元信息,如文件类型等),并使用 .text 属性将其存储在一个变量中。
# 存储网页内容
webpage = response.text
print(response.status_code)200
④使用 BeautifulSoup 库解析HTML
BeautifulSoup是一个Python库,用于解析HTML和XML文档中的数据(结构化数据)。
导入BeautifulSoup库。
创建BeautifulSoup对象。第一个参数表示HTML数据,而第二个参数是解析器。
# 从bs4导入BeautifulSoupfrom bs4 import BeautifulSoup# 从网页内容中创建一个BeautifulSoup对象
soup = BeautifulSoup(webpage, "lxml")
创建BeautifulSoup对象后,我们需要使用BeautifulSoup 库提供给我们的不同选项来导航和查找HTML文档中的元素,并从中抓取数据。
⑤使用 select() 方法,快速找到标签元素
soup.select(‘.subnav’)
三、实现截图