除了运行 Appium 的基本条件外,还要一个日志输出库
安装: pip install loguru
思路分析
首先我们观察一下整个 app5 的交互流程,其首页分条显示了电影数据, 每个电影条目都包括封面,标题, 类别和评分 4 个内容, 点击一个电影条目, 就可以看到这个电影的详细介绍,包括标题,类别,上映时间,评分,时长,电影简介等内容
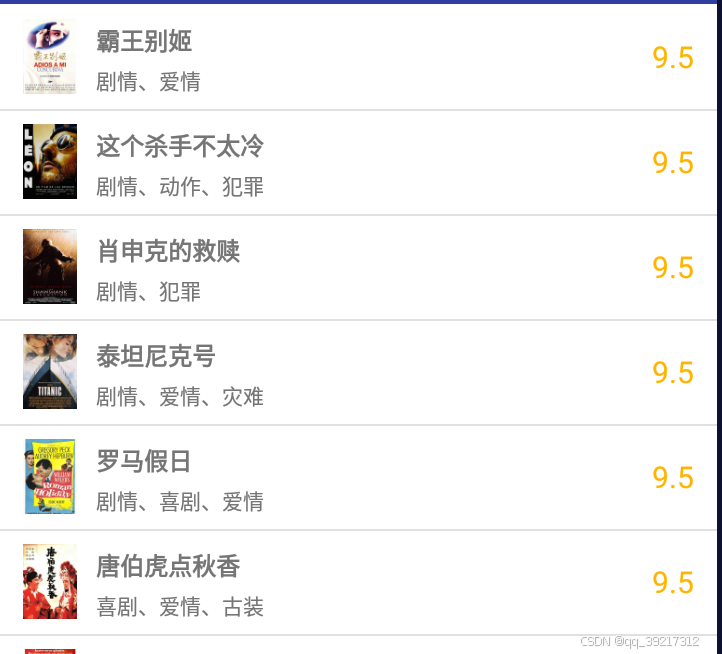

可见详情页远比首页内容丰富, 我们需要依次点击每个电影条目,抓取看到的所有内容,把所有电影条目的信息都抓取下来后回退到首页
另外,首页一开始只显示 10 个电影条目,需要上拉才能显示更多数据,一共 100 条数据,所以为了爬取所有数据,我们需要在适当的时候模拟手机上拉的操作,已加载更多的数据
综上,这里总结出基本爬取流程
遍历现有的电影条目,依次模拟点击每个电影条目,进入详情页
爬取详情页的数据,爬取完毕后模拟点击回退按钮的操作,返回首页
当首页的所有电影条目即将爬取完毕时,模拟上拉操作,加载更多数据
在爬取过程中,将已经爬取的数据记录下来,以免重复爬取
100 条数据爬取完毕后,终止爬取
基本实现
在编写代码的过程中,我们用 Appium 观察现有的 App 的源代码,以便编写节点的提取规则。 首先启动 Appium 服务,然后启动 Session , 打开电脑端的调试窗口
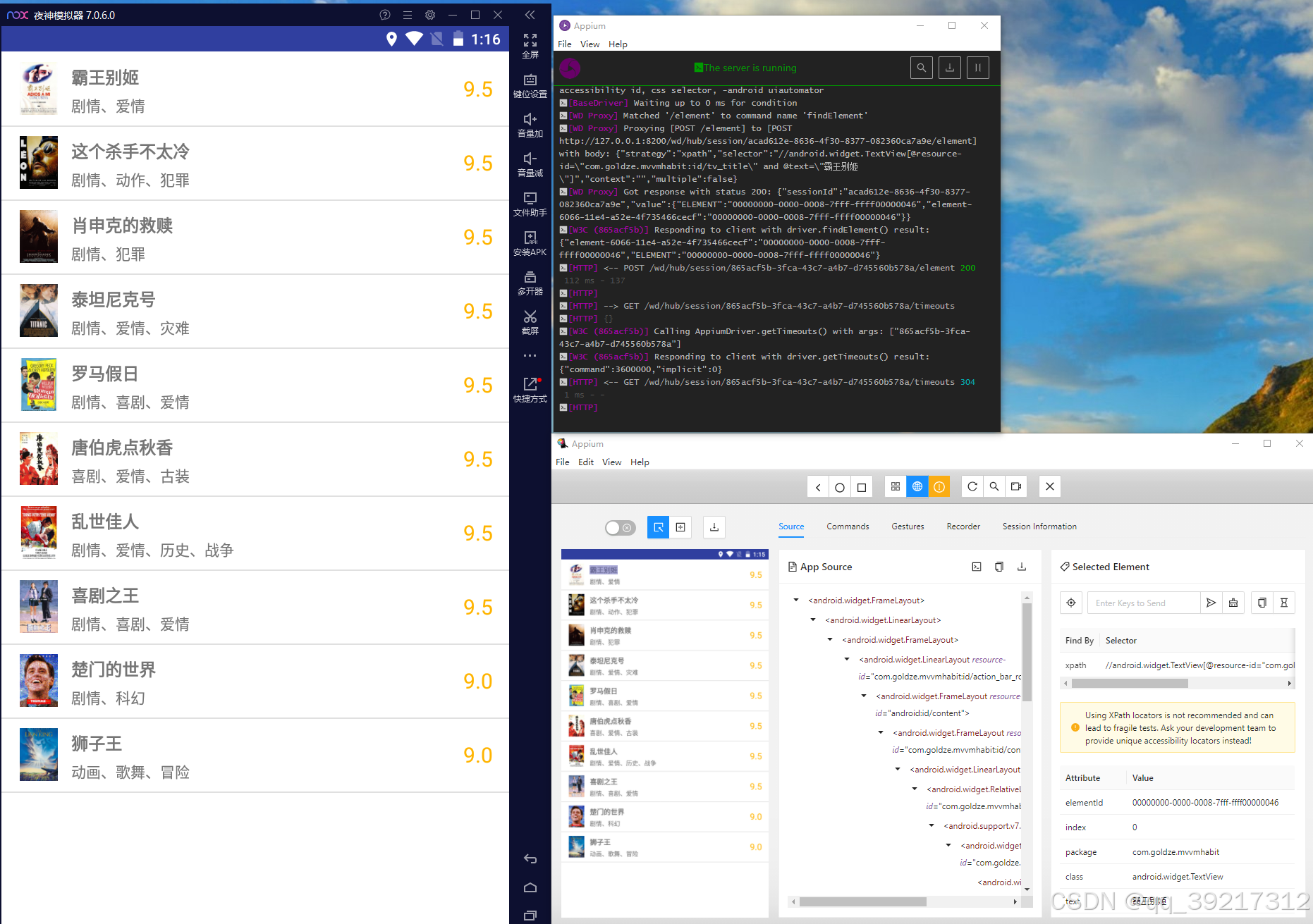
首先观察一些首页各个电影条目对应的 UI 树是怎样的。 通过观察可以发现,每个电影条目都是一个 android.widget.LinearLayout 节点, 该节点带有一个属性 resoutce-id 为 com.goldze.mvvmhabit:id/item , 条目内部的标题是一个 android.widget.TextView 节点,该节点带有一个属性 resource-id , 属性值是 com.goldze.mvvmhabit:id/tv_title, 我们可以选中所有的电影条目节点,同时记录电影标题去重
去重的目的: 因为对已经被渲染出来但是没有呈现在屏幕上的节点,我们是无法获取其信息的。在不断上拉爬取的过程中,我们同一时刻只能获取屏幕中能看到的所有电影条目的节点,被滑动出屏幕外的节点已经获取不到了。所有需要记录一下已经爬取的电影条目节点,以便下次滑动完毕后可以接着上一次爬取。由于此案例中的电影标题不存在重复,因此我们就用它来实现记录和去重
接下来做一些初始化声明
from appium import webdriver
from appium.options.android import UiAutomator2Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import NoSuchElementException
SERVER = 'http://localhost:4723/wd/hub'
DESIRED_CAPABILITIES = {
'platformName': 'Android',
'deviceName': 'LIO_AN00',
'appPackage': 'com.goldze.mvvmhabit',
'appActivity': '.ui.MainActivity',
'noReset': True
}
PACKAGE_NAME = DESIRED_CAPABILITIES['appPackage']
TOTAL_NUMBER = 100
这里我们首先声明了 SERVER 变量, 即 Appium 在本地启动的服务地址。 接着声明了 DESITED_CAPABILITIES , 这就是 Appium 启动示例 App 的配置参数,其中 deviceName 需要更改成自己手机的 model 名称, 可以使用 adb devices –l 通过 cmd 获取。另外,这里额外声明了一个变量 PACKAGE_NAME 即包名, 这是为后续编写获取节点的逻辑准备的。 最后声明 TOTAL_NUMBER 为 100 , 代表电影条目的总数为 100 , 之后以此为判断终止爬取
接下来我么声明 driver 对象, 并初始化一些必要的对象和变量
driver = webdriver.Remote(SERVER, options=UiAutomator2Options().load_capabilities(DESIRED_CAPABILITIES))
wait = WebDriverWait(driver, 30)
window_size = driver.get_window_size()
window_width, window_height = window_size.get('width'), window_size.get('height')
这里的 wait 变量就是一个 WebDriverWait 对象, 调用它的 until 方法可以实现如果查找到目标接节点就立即返回,如果等待 30 秒还查找不到目标节点就抛出异常。 我们还声明了 window_width, window_height 变量, 分别代表屏幕的宽高
初始化工作完成,下面爬取首页的所有电影条目
def scrape_index():
items = wait.until(EC.presence_of_all_elements_located((By.XPATH, f'//android.widget.LinearLayout[@resource-id="{PACKAGE_NAME}:id/item"]')))
return items
这里实现了一个 scrape_index 方法, 使用 XPath 选择对应的节点, 开头的 // 代表匹配根节点的所有子孙节点,即所有符合后面条件的节点都会被筛选出来, 这里对节点名称 android.widget.LinearLayout 和 属性 resource-id 进行了组合匹配。 在外层调用了 wait 变量的 until 方法,最后的结果就是如果符合条件的节点加载出来看, 就立即把这个节点赋值为 items 变量,并返回 items ,否则抛出超时异常
所以在正常情况下,使用 scrape_index 方法可以获得首页上呈现的所有电影条目数据
接下来就可以定义一个 main 方法来调用 scrape_index 方法了
from loguru import logger
def main():
elements = scrape_index()
for element in elements:
element_data = scrape_detail(element)
logger.debug(f'scraped data {element_data}')
if __name__ == '__main__':
main()
这里在 main 方法中首先调用 scrape_index 方法提取了当前首页的所有节点,然后遍历这些节点,并想通过一个 scrape_detail 方法提取每部电影的详情信息,最后返回并输出日志
那么问题明确了,scrape_detail 方法如何实现?大致思考一下,可以想到该方法需要做到如下三件事
模拟点击 element , 即首页的电影条目节点
进入详情页后爬取电影信息
点击回退按钮后返回首页
所以这个方法实现为
def scrape_detail(element):
logger.debug(f'scraping {element}')
element.click()
wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/detail')))
title = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/title'))).get_attribute('text')
categories = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/categories_value'))).get_attribute('text')
score = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/score_value'))).get_attribute('text')
minute = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/minute_value'))).get_attribute('text')
published_at = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/published_at_value'))).get_attribute('text')
drama = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/drama_value'))).get_attribute('text')
driver.back()
return {
'title': title,
'categories': categories,
'score': score,
'minute': minute,
'published_at': published_at,
'drama': drama
}
实现该方法需要先弄清楚详情页每个及诶蒂娜对应的节点名称, 属性都是怎样的,于是再次打开调试窗口,点击一个电影标题进入详情页, 查看器 DOM 树
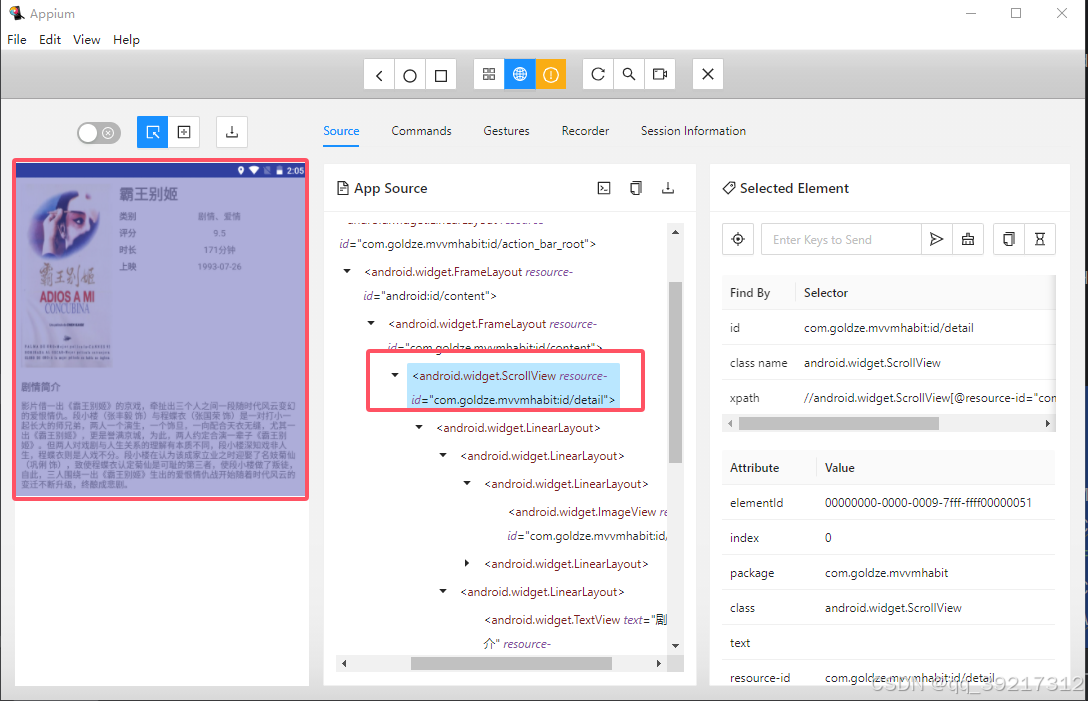
可以观察到整个详情页对应一个 android.widget.ScrollView 节点,其包含的 resource-id 属性值为 com.goldze.mnnmhabit:id/detail 。详情页上的标题,类别,评分,时长,上映时间,剧情简介页都有各自的节点名称和 resource-id , 这里就不展开描述了, 从 Appium 的 Source 面板即可查看
在 scrape_detail 方法中,首先调用了 element 的click 方法进入对应的详情页,然后等待整个详情页的信息(即 com.goldze.mnnmhabit:id/detail )加载出来,之后顺次爬取了标题,类别,评分,时长,上映时间,剧情简介,爬取完毕后抹蜜点击回退按钮,最后将所有爬取的内容构成一个字典返回
其实现在,我们已经可以成功获取首页最开始加载的几条电影信息了,执行一下代码
部分输出内容
2024-08-16 16:05:22.177 | DEBUG | __main__:scrape_detail:32 - scraping <appium.webdriver.webelement.WebElement (session="c9f0c1dc-d98a-45bc-b65f-60c5b3831219", element="00000000-0000-0015-7fff-ffff00000011")>
2024-08-16 16:05:24.149 | DEBUG | __main__:main:62 - scraped data {'title': '霸王别姬', 'categories': '剧情、爱情', 'score': '9.5', 'minute': '171分钟', 'published_at': '1993-07-26', 'drama': '影片借一出《霸王别姬》的京戏,牵扯出三个人之间一段随时代风云变幻的爱恨情仇。段小楼(张丰毅 饰)与程蝶衣(张国荣 饰)是一对打小一起长大的师兄弟,两人一个演生,一个饰旦,一向配合天衣无缝,尤其一出《霸王别姬》,更是誉满京城,为此,两人约定合演一辈子《霸王别姬》。但两人对戏剧与人生关系的理解有本质不同,段小楼深知戏非人生,程蝶衣则是人戏不分。段小楼在认为该成家立业之时迎娶了名妓菊仙(巩俐 饰),致使程蝶衣认定菊仙是可耻的第三者,使段小楼做了叛徒,自此,三人围绕一出《霸王别姬》生出的爱恨情仇战开始随着时代风云的变迁不断升级,终酿成悲剧。'}
上拉加载更多内容
现在在上面代码的基础上,加入上拉加载更多数据的逻辑,因此需要判断什么时候上拉加载数据。想想我们平时在浏览器浏览数据的时候是怎么操作的? 一般是在即将看完的时候上拉,那这里页一样,可以让程序在遍历到位于偏下方的电影条目的时候开始上拉。例如,当爬取的节点对应的电影条目差不多位于页面高度的 80% 时,就触发上拉加载,将 main 方法改写如下
def main():
elements = scrape_index()
for element in elements:
element_location = element.location
element_y = element_location.get('y')
if element_y / window_height > 0.5:
logger.debug(f'scroll up')
scroll_up()
element_data = scrape_detail(element)
logger.debug(f'scraped data {element_data}')
这里遍历是判断了 element 的位置,获取了其 y 的坐标值,当该值小于页面高度的 80% 时,触发上拉加载,加载的方法是 scroll_up 其定义如下
def scroll_up():
driver.swipe(window_width * 0.5, window_height * 0.8, window_width * 0.5, window_height * 0.5, 1000)
方法 driver.swipe(start_x, start_y, end_x, end_y, 时间)
start_x, start_y : 开始上拉的 横纵坐标
end_x, end_y:上拉到的位置的横纵坐标
时间:上拉用时多久
去重,终止和保存数据
在本节开始部分我们曾提到,需要额外添加根据标题进行去重和判断终止的逻辑,所以在遍历首页中每个电影条目的时候还需要提取一下标题,然后将其存入一个全局变量中
def get_element_title(element):
try:
element_title = element.find_element(by=By.ID, value=f'{PACKAGE_NAME}:id/tv_title').get_aribute('text')
return element_title
except NoSuchElementException:
return None
这里定义了一个 get_element_title 方法,该方法接收一个 element 参数, 即首页电影条目对应的节点对象,然后提取其标题文本并返回,最后将 main 方法修改如下
scraped_titles = []
def main():
while len(scraped_titles) < TOTAL_NUMBER:
elements = scrape_index()
for element in elements:
element_title = get_element_title(element)
if not element_title or element_title in scraped_titles:
continue
element_location = element.location
element_y = element_location.get('y')
if element_y / window_height > 0.5:
logger.debug(f'scroll up')
scroll_up()
element_data = scrape_detail(element)
scraped_titles.append(element_title)
logger.debug(f'scraped data {element_data}')
这里在 main 方法里添加了 while 循环, 入股哦爬取的电影条目数量尚未达到数量 TOTAL_NUMBER, 就接着爬取, 直到爬取完毕。 其中就调用 get_element_title 方法提取了电影标题,然后将已经爬取的电仪标题存储在全局变量 scraped_titles 中, 如果经判断, 当前节点对应的电影已经爬取过了, 就跳过, 否则接着爬取,爬取完毕后将标题存到 scraped_titles 变量里,这样就实现了去重
保存数据
最后,可以再添加一个保存数据的逻辑,将爬取的数据保存到本地 movie 文件夹中, 数据以 JSON 形式保存,代码如下
import os
import json
OUTPUT_FOLDER = 'movie'
os.path.exists(OUTPUT_FOLDER) or os.makedirs(OUTPUT_FOLDER)
def save_date(element_data):
with open(f'{OUTPUT_FOLDER}/{element_data.get("title")}.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(element_data, ensure_ascii=False, indent=2))
logger.debug(f'saved as file {element_data.get("title")}.json')
最后在 main 方法中添加调用逻辑即可
完整代码
from appium import webdriver
from appium.options.android import UiAutomator2Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import NoSuchElementException
from loguru import logger
import os
import json
SERVER = 'http://localhost:4723/wd/hub'
DESIRED_CAPABILITIES = {
'platformName': 'Android',
'deviceName': 'LIO_AN00',
'appPackage': 'com.goldze.mvvmhabit',
'appActivity': '.ui.MainActivity',
'noReset': True
}
OUTPUT_FOLDER = 'movie'
os.path.exists(OUTPUT_FOLDER) or os.makedirs(OUTPUT_FOLDER)
PACKAGE_NAME = DESIRED_CAPABILITIES['appPackage']
TOTAL_NUMBER = 100
scraped_titles = []
driver = webdriver.Remote(SERVER, options=UiAutomator2Options().load_capabilities(DESIRED_CAPABILITIES))
wait = WebDriverWait(driver, 30)
window_size = driver.get_window_size()
window_width, window_height = window_size.get('width'), window_size.get('height')
def scrape_index():
items = wait.until(EC.presence_of_all_elements_located(
(By.XPATH, f'//android.widget.LinearLayout[@resource-id="{PACKAGE_NAME}:id/item"]')))
return items
def scrape_detail(element):
logger.debug(f'scraping {element}')
element.click()
wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/detail')))
title = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/title'))).get_attribute('text')
categories = wait.until(
EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/categories_value'))).get_attribute('text')
score = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/score_value'))).get_attribute('text')
minute = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/minute_value'))).get_attribute(
'text')
published_at = wait.until(
EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/published_at_value'))).get_attribute('text')
drama = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/drama_value'))).get_attribute('text')
driver.back()
return {
'title': title,
'categories': categories,
'score': score,
'minute': minute,
'published_at': published_at,
'drama': drama
}
def scroll_up():
print(window_height)
print(window_height * 0.8)
print(window_height * 0.5)
driver.swipe(window_width * 0.5, window_height * 0.8, window_width * 0.5, window_height * 0.5, 1000)
def get_element_title(element):
try:
element_title = element.find_element(by=By.ID, value=f'{PACKAGE_NAME}:id/tv_title').get_attribute('text')
return element_title
except NoSuchElementException:
return None
def save_date(element_data):
with open(f'{OUTPUT_FOLDER}/{element_data.get("title")}.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(element_data, ensure_ascii=False, indent=2))
logger.debug(f'saved as file {element_data.get("title")}.json')
def main():
while len(scraped_titles) < TOTAL_NUMBER:
elements = scrape_index()
for element in elements:
element_title = get_element_title(element)
if not element_title or element_title in scraped_titles:
continue
element_location = element.location
element_y = element_location.get('y')
if element_y / window_height > 0.5:
logger.debug(f'scroll up')
scroll_up()
element_data = scrape_detail(element)
scraped_titles.append(element_title)
save_date((element_data))
logger.debug(f'scraped data {element_data}')
if __name__ == '__main__':
main()